LogProb 활성화
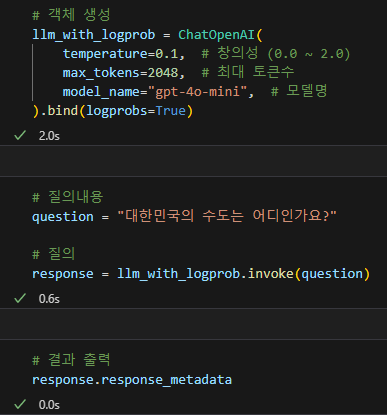
출력값
{'token_usage': {'completion_tokens': 9,
'prompt_tokens': 16,
'total_tokens': 25,
'completion_tokens_details': {'accepted_prediction_tokens': 0,
'audio_tokens': 0,
'reasoning_tokens': 0,
'rejected_prediction_tokens': 0},
'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}},
'model_name': 'gpt-4o-mini-2024-07-18',
'system_fingerprint': 'fp_d02d531b47',
'finish_reason': 'stop',
'logprobs': {'content': [{'token': '대한',
'bytes': [235, 140, 128, 237, 149, 156],
'logprob': -2.7014437e-05,
'top_logprobs': []},
{'token': '민국',
'bytes': [235, 175, 188, 234, 181, 173],
'logprob': -6.704273e-07,
'top_logprobs': []},
{'token': '의',
'bytes': [236, 157, 152],
'logprob': -2.188868e-05,
'top_logprobs': []},
{'token': ' 수도',
'bytes': [32, 236, 136, 152, 235, 143, 132],
'logprob': -5.6100132e-05,
'top_logprobs': []},
{'token': '는',
'bytes': [235, 138, 148],
'logprob': -6.217952e-05,
'top_logprobs': []},
{'token': ' 서울',
'bytes': [32, 236, 132, 156, 236, 154, 184],
'logprob': -0.00013703208,
'top_logprobs': []},
{'token': '입니다',
'bytes': [236, 158, 133, 235, 139, 136, 235, 139, 164],
'logprob': -0.0030925125,
'top_logprobs': []},
{'token': '.',
'bytes': [46],
'logprob': -1.9361265e-07,
'top_logprobs': []}],
'refusal': None}}
기본 정보

토큰별 분석

bytes 정보
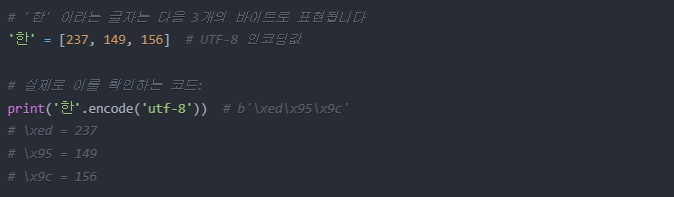
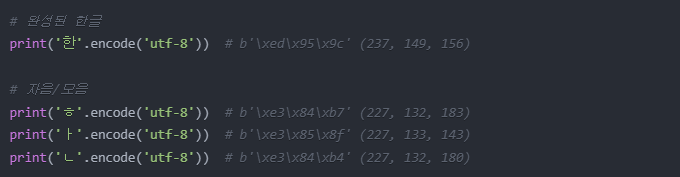
한글은 UTF-8 인코딩으로 여러 바이트로 표현된다
예: [235, 140, 128]은 '대'를 표현하는 바이트 값들이다.