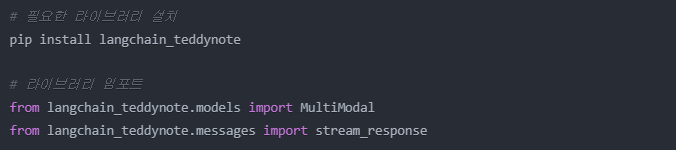
멀티모달이란
여러 형태의 데이터 (텍스트, 이미지, 오디오, 비디오 등)를
통합적으로 처리할 수 있는 AI 모델이다.환경설정
텍스트와 이미지를 처리할 수 있는 GPT-4 Vision 모델을 사용한다.

이미지 처리하기
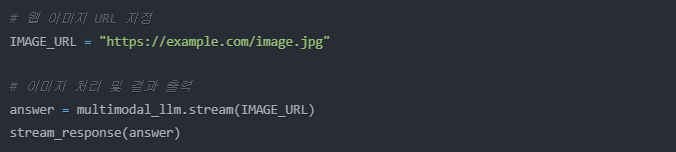
이미지는 두 가지 방법으로 처리할 수 있다.
웹 이미지 URL로 처리하기
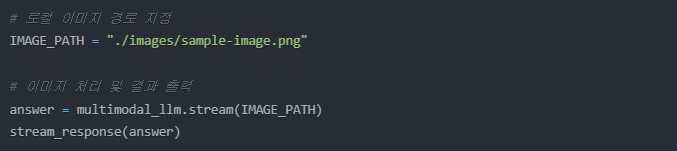
로컬 이미지 파일로 처리하기
실행 결과 예시

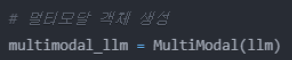
MultiModal 객체 이해하기
MultiModal 클래스는 이미지와 텍스트를 함께 처리할 수 있는 기능을 제공한다.
여기서 MultiModal은 클래스 이름이고
multimodal_llm은 생성된 객체를 저장하는 변수이다.
llm은 앞서 설정한 GPT-4 모델을 부르기 쉽게 저장한 변수이다.

성문이