stream이란
AI 모델의 생각과 답변 과정을 실시간으로 볼 수 있게 해주는 메서드이다.
마치 내가 카톡을 보내는 것처럼 AI가 답변하는 단어가 실시간으로 나타난다.
invoke와의 차이점
invoke는 AI가 답변을 작성할 때까지 기다렸다가 답변을 모두 작성했을 때 한 번에 뜨는 반면 stream은 답변이 단어나 구절 단위로 실시간 출력된다.
invoke :

stream :

문법
stream을 사용할 때에는 [for chunk in llm.stream] 과 같은 문법을 사용하는데 실생활로 비유를 하면 아래의 사진과 같다.
for chunk in : 답변을 작은 조각들로 나눠서 하나씩 받기
llm.stream() : AI한테 실시간으로 말해달라고 요청하기
chunk.content : 각 조각의 실제 내용을 가져오기
end="" : 줄바꿈 없이 이어서 출력하기

for chunk in
stream을 사용할 때에는 꼭 for chunk in ... 을 사용해야 하는 걸까 ?
for chunk in 유무에 따른 stream 결과값을 한 번에 보기 위한 코드
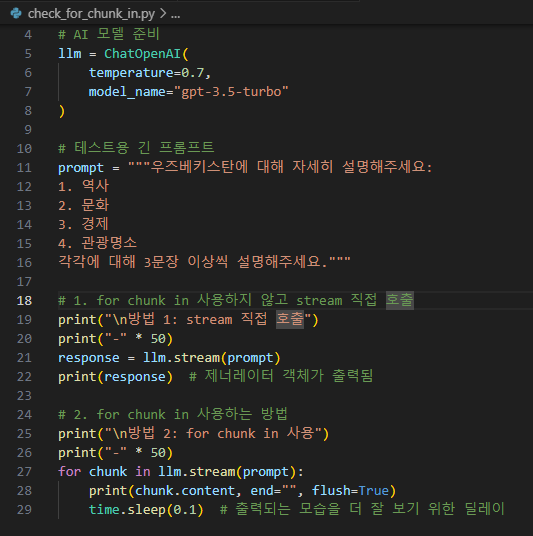
for chunk in을 사용하지 않았을 때와 사용했을 때의 출력값이다.

for chunk in을 사용하지 않았을 때에는 결과 값이 이상한 것을 볼 수 있는데 저게 Python의 제네레이터 객체라고 한다.
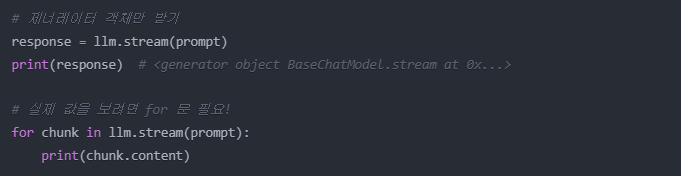
제너레이터란
데이터의 시퀀스(순서가 있는 데이터)를 한 번에 하나씩 반환하는 특별한 객체이다.
메모리를 효율적으로 사용하기 위해 설계되었다.
for 루프로 순회할 때 실제 값을 얻을 수 있다.
유튜브 동영상 스트리밍을 예로 들면 :

또 다른 예로는 :

한 번에 전체 틀을 불러오지 않고 필요한 부분만 그때 그때 불러온다는 말이다.
제너레이터 장점
따라서 제너레이터는 메모리를 아끼며, 실시간으로 처리하고,
필요할 때만 데이터를 만들어서 효율적은 프로그래밍을 가능하게 한다.실용적인 예시
AI와 대화하는 프로그램 :
실시간으로 글 써주는 프로그램 :

동기 스트리밍은
마치 스무고개 처럼 첫번째 질문이 끝나야 다음 질문을 할 수 있는 것처럼
하나의 질문이 끝나야 다음 질문을 할 수 있고 (순차적으로 처리)
그 질문이 chunk나 token 별로 쪼개져 나오는 특징이 있다.
