카프카 클러스터와 파이썬 (1) - python kafka with kafka cluster, consumer & producer & docker compose 파헤치기

[ 글의 목적: clustering infra 목적과 그 기반으로 kafka clustering을 구성해 실제 python based stack에서 활용하는 방법에 대해 분석 및 기록 ]
Kafka cluster with python
Kafka cluster infra를 docker compose file로 구성하고, 다루고, 주요 설정값을 살펴보자. 그리고 python code 기반으로 consumer & producer 를 만들고 직접 고가용성을 테스트하고, kafka managing을 위한 GUI tool을 살펴보자!
우선 등장하게 될 예제는 https://github.com/Nuung/django-all-about 레포 기준으로 진행한다.
1. kafka cluster
-
일단 "clustering"은 "HA(High Availability): 고가용성" 을 위해 구성한 infrastructure 이다.
-
가용성은 "시스템 고장 발생 시 얼마나 빠른 시간내에 복구(또는 원복, 정상 상태)되어 다시 정상적으로 서비스할 수 있는 상태인지 분석하는 척도" 이다. HA 구성이란 이런 가용성을 "극대화" 시키는 구성을 말한다. 대표적으로 클러스터링, 이중화, 레이드 구조가 있다.
-
그 중 클러스터링이란 "서버를 하나의 시스템처럼 관리 운영하기 위해 사용하는 기술" 이다. 기본적인 컨셉은 "오류나 유지관리 작업으로 인해 클러스터의 노드 중 하나가 사용되지 않는다면 즉시 다른 서버(노드)에서 서비스를 제공하기 시작한다(main 변경). 이 서비스에 대한 ACCESS가 끊이지 않고 계속 지원됨으로 사용자는 장애사실을 알 수 없다."
-
즉 가변적 업무부하를 처리하거나 서비스 연속성을 저해하는 고장 발생 시 운영이 계속되도록 여러대의 컴퓨터시스템 기능을 서로 연결하는 메커니즘이다. 두대 이상 컴퓨터를 마치 하나의 컴퓨터 처럼 동작하도록 연결하여 병렬 처리나 부하 배분 및 고장 대비 등 목적에 사용 할 수 있다.
-
카프카 클러스터의 가장 큰 특징은 "각 브로커들이 클러스터 전체 데이터의 일부분을 가지고 있다는 것이다!" 이는 카프카의 구성 요소인 토픽, 파티션과 연관이 있다. 논리적인 단위인 토픽은 메시지 저장의 단위인 파티션으로 쪼개져 구성되고, 파티션은 복제(replication)를 통해 여러 브로커에 산개되어 구성되기 때문이다.
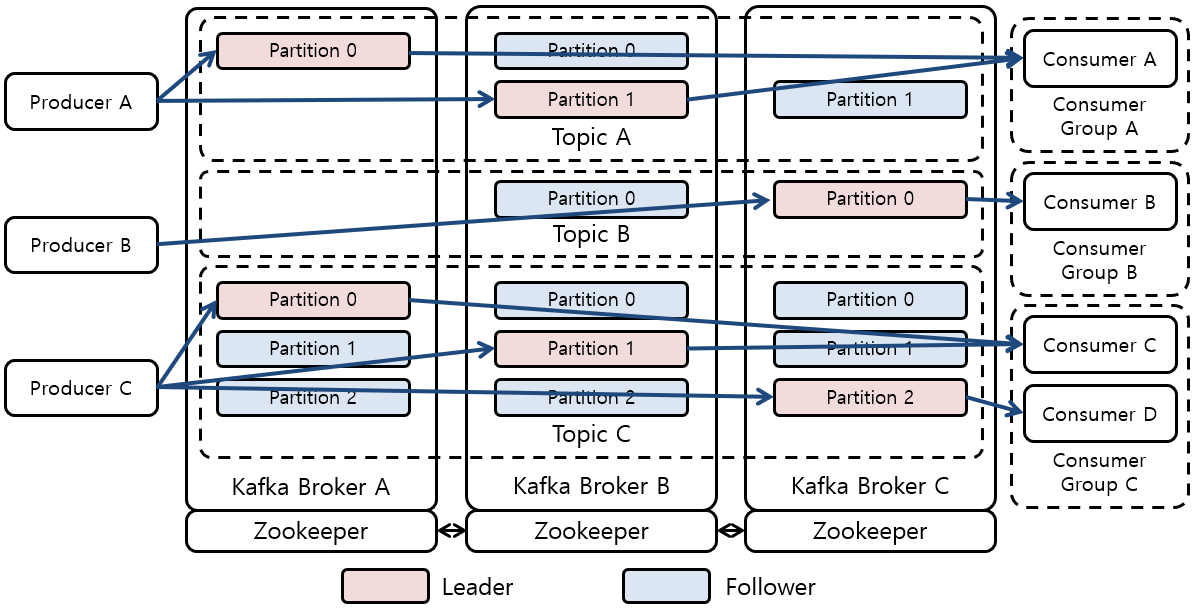
1) kafka clustering compose file
스크롤 압박 주의, 일단 완성본을 보고 TOP-DOWN 방식으로 살펴보자.
version: "3.5"
services:
daa-zoo1:
image: zookeeper:3.8.0
hostname: daa-zoo1
container_name: daa-zoo1
ports:
- "2181:2181"
volumes:
- ../zookeeper/data/1:/data
- ../zookeeper/datalog/1:/datalog
- ../zookeeper/logs/1:/logs
networks:
- daa-kafka-cluster-network
environment:
ZOOKEEPER_SERVER_ID: 1
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_SERVERS: server.1=daa-zoo1:2888:3888 server.2=daa-zoo2:2888:3888 server.3=daa-zoo3:2888:3888
daa-zoo2:
image: zookeeper:3.8.0
hostname: daa-zoo2
container_name: daa-zoo2
ports:
- "2182:2182"
volumes:
- ../zookeeper/data/2:/data
- ../zookeeper/datalog/2:/datalog
- ../zookeeper/logs/2:/logs
networks:
- daa-kafka-cluster-network
environment:
ZOOKEEPER_SERVER_ID: 2
ZOOKEEPER_CLIENT_PORT: 2182
ZOOKEEPER_SERVERS: server.1=daa-zoo1:2888:3888 server.2=daa-zoo2:2888:3888 server.3=daa-zoo3:2888:3888
daa-zoo3:
image: zookeeper:3.8.0
hostname: daa-zoo3
container_name: daa-zoo3
ports:
- "2183:2183"
volumes:
- ../zookeeper/data/3:/data
- ../zookeeper/datalog/3:/datalog
- ../zookeeper/logs/3:/logs
networks:
- daa-kafka-cluster-network
environment:
ZOOKEEPER_SERVER_ID: 3
ZOOKEEPER_CLIENT_PORT: 2183
ZOOKEEPER_SERVERS: server.1=daa-zoo1:2888:3888 server.2=daa-zoo2:2888:3888 server.3=daa-zoo3:2888:3888
daa-kafka1:
image: wurstmeister/kafka:2.13-2.8.1
hostname: daa-kafka1
container_name: daa-kafka1
ports:
- "9092:9092"
- "19092"
volumes:
- ../kafka/logs/1:/kafka/logs
networks:
- daa-kafka-cluster-network
environment:
KAFKA_BROKER_ID: 1
KAFKA_PRODUCER_MAX_REQUEST_SIZE: 536870912
CONNECT_PRODUCER_MAX_REQUEST_SIZE: 536870912
KAFKA_LISTENERS: INSIDE://daa-kafka1:19092,OUTSIDE://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: INSIDE://daa-kafka1:19092,OUTSIDE://127.0.0.1:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
KAFKA_ZOOKEEPER_CONNECT: "daa-zoo1:2181,daa-zoo2:2182,daa-zoo3:2183"
KAFKA_LOG_DIRS: "/kafka/logs"
KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=daa-kafka1 -Dcom.sun.management.jmxremote.rmi.port=9992"
JMX_PORT: 9992
depends_on:
- daa-zoo1
- daa-zoo2
- daa-zoo3
daa-kafka2:
image: wurstmeister/kafka:2.13-2.8.1
hostname: daa-kafka2
container_name: daa-kafka2
ports:
- "9093:9093"
- "19093"
volumes:
- ../kafka/logs/2:/kafka/logs
networks:
- daa-kafka-cluster-network
environment:
KAFKA_BROKER_ID: 2
KAFKA_PRODUCER_MAX_REQUEST_SIZE: 536870912
CONNECT_PRODUCER_MAX_REQUEST_SIZE: 536870912
KAFKA_LISTENERS: INSIDE://daa-kafka2:19093,OUTSIDE://0.0.0.0:9093
KAFKA_ADVERTISED_LISTENERS: INSIDE://daa-kafka2:19093,OUTSIDE://127.0.0.1:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
KAFKA_ZOOKEEPER_CONNECT: "daa-zoo1:2181,daa-zoo2:2182,daa-zoo3:2183"
KAFKA_LOG_DIRS: "/kafka/logs"
KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=daa-kafka2 -Dcom.sun.management.jmxremote.rmi.port=9992"
JMX_PORT: 9992
depends_on:
- daa-zoo1
- daa-zoo2
- daa-zoo3
daa-kafka3:
image: wurstmeister/kafka:2.13-2.8.1
hostname: daa-kafka3
container_name: daa-kafka3
ports:
- "9094:9094"
- "19094"
volumes:
- ../kafka/logs/3:/kafka/logs
networks:
- daa-kafka-cluster-network
environment:
KAFKA_BROKER_ID: 3
KAFKA_PRODUCER_MAX_REQUEST_SIZE: 536870912
CONNECT_PRODUCER_MAX_REQUEST_SIZE: 536870912
KAFKA_LISTENERS: INSIDE://daa-kafka3:19094,OUTSIDE://0.0.0.0:9094
KAFKA_ADVERTISED_LISTENERS: INSIDE://daa-kafka3:19094,OUTSIDE://127.0.0.1:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
KAFKA_ZOOKEEPER_CONNECT: "daa-zoo1:2181,daa-zoo2:2182,daa-zoo3:2183"
KAFKA_LOG_DIRS: "/kafka/logs"
KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=daa-kafka3 -Dcom.sun.management.jmxremote.rmi.port=9992"
JMX_PORT: 9992
depends_on:
- daa-zoo1
- daa-zoo2
- daa-zoo3
daa-kafka-manager:
image: hlebalbau/kafka-manager:2.0.0.2
container_name: daa-kafka-manager
restart: on-failure
environment:
ZK_HOSTS: "daa-zoo1:2181,daa-zoo2:2182,daa-zoo3:2183"
APPLICATION_SECRET: "random-secret"
KM_ARGS: -Djava.net.preferIPv4Stack=true
command:
- "-Dcmak.zkhosts=daa-zoo1:2181,daa-zoo2:2182,daa-zoo3:2183"
- "-DbasicAuthentication.enabled=true"
- "-DbasicAuthentication.username=kafka-admin"
- "-DbasicAuthentication.password=kafka-admin#"
ports:
- "9000:9000"
networks:
- daa-kafka-cluster-network
depends_on:
- daa-zoo1
- daa-zoo2
- daa-zoo3
- daa-kafka1
- daa-kafka2
- daa-kafka3
networks:
daa-kafka-cluster-network:
driver: bridge-
핵심은
zookeeper (zoo)컨테이너 한덩이wurstmeister/kafka이미지 기반 컨테이너 한덩이이다.zoo는 "kafka의 브로커관리(부트스트랩서버) & 모니터링" 등을 한다. 우선 kafka 자체에 대한 세부 설명은 해당 시리즈 전 글 카프카(Kafka)란?, 메세지 큐 들여다시보기 로 대체하겠다. -
클러스터링을 관리하는 zoo는 kafka 서버개수와 무조건 매치할 필요는 없다. 하지만 clustering을 구성할땐 "최소 3개 이상을 추천"한다. 왜냐면 "한 서버가 죽었을 때 의사결정을 할 때" 를 대비해서이다. 영어로
quorum표현하는데 다시 나중에 자세히 살펴보자. -
또한 kafka 서버 개수는 clustering을 시작할땐 3개 정도로 시작하라고 추천한다. 어짜피 kafka server는 data의 양과 처리되어야 하는 traffic 양에 영향을 받기 때문에 모니터링하면서 kafka 서버 개수를 늘리는 것이 바람직하다.
-
docker compose -f 위컴포즈파일저장이름.yaml -p daa-kafka-cluster-app up -d로 러닝을 바로 해보자! 이 글에서 등장하는 코드들의 더 정확한 실행을 하고 싶으면, 글 가장 위에서 언급한 repo를 체크하면 된다.
2) zookeeper 설정 뜯어보기
daa-zoo1:
image: zookeeper:3.8.0
hostname: daa-zoo1
container_name: daa-zoo1
ports:
- "2181:2181"
volumes:
- ../zookeeper/data/1:/data
- ../zookeeper/datalog/1:/datalog
- ../zookeeper/logs/1:/logs
networks:
- daa-kafka-cluster-network
environment:
ZOOKEEPER_SERVER_ID: 1
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_SERVERS: server.1=daa-zoo1:2888:3888 server.2=daa-zoo2:2888:3888 server.3=daa-zoo3:2888:3888-
사실 주키퍼에 대해 스치듯 지나가는 사람이 많을 것이다. 주키퍼에 대한 글 을 먼저 읽고 설정을 다시 살펴보자.
-
사실 거의 최소한의 설정값들이다. 설정값들이 늘어날 경우
environment를 따로 file로 빼서 관리하면 된다. -
일단 zoo1의
CLIENT_PORT는2181로 시작해서 세팅하고+1되는 형태다. (일반적으로 2181로 세팅한다. 아마 example 들의 영향이 아닐까),ZOOKEEPER_SERVERS는2888:3888이 default 세팅이다. -
그럼
ZOOKEEPER_SERVERS뭘까? "데이터 동기화 및 쿼럼 유지를 위해" 서로 통신하는 데 사용된다.<leaderport>:<electionport>의 형태다.- Quorum(쿼럼)은 분산 시스템에서 작업을 수행하기 위해 분산 트랜잭션이 얻어야 하는 최소 투표 수
- 그래서 외부에 공개할 필요는 없는 포트다. Internal network에서만 서로 해당 포트에 접근할 수 있으면 된다.
-
zookeeper는 quorum을 위한 consensus protocol - Zab (ZooKeeper Atomic Broadcast) 을 사용한다. 주키퍼는 "리더(leader)와 팔로워(follower)를 선출"한다. 리더 주키퍼는 공유 데이터 & 업데이트 사항을 팔로워에게 "broadcasting" 을 한다. 팔로워는 그 값을 동기화 한다.
-
이 때 사용되는 내부 포트들이
2888:3888이 되는 것이다.2888은 zookeeper가 팔로워 들이 리더와 각 통신하는 포트가 되고,3888은 zookeeper가 각자의 state를 "동기화" 할때, 즉 팔로워들이 자신의 상태 (공유 데이터 등)가 리더의 상태와 같은지 체크한다. 그리고 리더를 선출한다. 두 포트가 동시에 사용된다고 생각하면 된다. 그리고 zoo 3대 이상 안쓰면 3888은 쓸 필요가 없다.그 외 디테일 사항은 글 최하단 부 출처글로 대신한다.
3) kafka 설정 뜯어보기
daa-kafka1:
image: wurstmeister/kafka:2.13-2.8.1
hostname: daa-kafka1
container_name: daa-kafka1
ports:
- "9092:9092"
- "19092"
volumes:
- ../kafka/logs/1:/kafka/logs
networks:
- daa-kafka-cluster-network
environment:
KAFKA_BROKER_ID: 1
KAFKA_PRODUCER_MAX_REQUEST_SIZE: 536870912
CONNECT_PRODUCER_MAX_REQUEST_SIZE: 536870912
KAFKA_LISTENERS: INSIDE://daa-kafka1:19092,OUTSIDE://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: INSIDE://daa-kafka1:19092,OUTSIDE://127.0.0.1:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
KAFKA_ZOOKEEPER_CONNECT: "daa-zoo1:2181,daa-zoo2:2182,daa-zoo3:2183"
KAFKA_LOG_DIRS: "/kafka/logs"
KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=kafka -Dcom.sun.management.jmxremote.rmi.port=9992"
JMX_PORT: 9992
depends_on:
- daa-zoo1
- daa-zoo2
- daa-zoo3- 일단
confluentincimage가 아니라wurstmeister이미지다. 어떤 이미지를 사용하느냐에 따라 설정값이나 설정값이름이 달라질 수 있다.- 두 base image의 가장 큰 차이는 후자는 minimalist kafka installation
- 전자는 full-featured kafka installation (ex. Kafka Connect, Kafka Streams, and the Confluent Schema Registry.) 을 제공한다. 대규모 엔터프라이즈 환경을 고려한다면 전자가 유리하다.
kafka env값은 중요하다!
-
KAFKA_BROKER_ID: 카프카 클러스터에서 각 kafka는 broker를 위한 Unique integer identifier 값을 가져야 한다. -
KAFKA_PRODUCER_MAX_REQUEST_SIZE: Maximum size of a request that a Kafka producer can send to a broker, in bytes. -
CONNECT_PRODUCER_MAX_REQUEST_SIZE: Maximum size of a request that Kafka Connect producer can send to a broker, in bytes.
kafka Listners vs Advertised Listners
-
카프카는 (기본적으로) "분산 시스템" 이다. 클라이언트(프로듀서, 컨슈머)는 분산된 파티션에 접근하여
write/read를 수행한다. 카프카가 클러스터로 묶인 경우, 카프카 리더만이 write/read 요청을 받는데, 클라이언트는 클러스터의 브로커 중 누가 리더인지 알아야 하기 때문에write/read요청에 앞서 해당 파티션의 리더가 누구인지 알 수 있는 메타데이터를 요청한다. 이 메타데이터 요청은 클러스터의 브로커 중 아무나 받아서 응답할 수 있다. 메타데이터 요청을 받은 브로커는 요청된 파티션의 리더가 어떤 브로커인지와 그 브로커에게 접근할 수 있는 엔드포인트를 반환한다. 그러면 클라이언트는 이 반환된 메타데이터를 가지고 실제 요청을 수행한다. -
이게 OS에 직접 설치되는 경우, 머신 설정을 따라가면 되는데 VM 또는 docker와 같은 Cloud 환경에서는 네트워크가 복잡해진다. IN-OUT 이 달라져야 한다! 그리고 성능 및 기타 비용을 고려할 때, 내부에서는 plaintext로, 외부에서는 SSL로 통신하도록 하는 등의 구분이 필요할 수 있다.
-
KAFKA_LISTENERS: listeners- 카프카 브로커가 내부적으로 바인딩하는 주소.
CLIENT:...,INTERNAL:...,INSIDE:..., 라는 명칭을 많이 쓴다.- 같은 네트워크 환경에서 "내부적"으로 통신하는 바인딩 주소 값이다.
-
KAFKA_ADVERTISED_LISTENERS: advertised.listeners- 카프카 프로듀서, 컨슈머에게 노출할 주소. 설정하지 않을 경우 디폴트로 listners 설정이 적용된다.
- 다른 네트워크에서 접근할때 "외부적"으로 통신하는 바인딩 주소 값이다.
-
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP- 내부 / 외부에서 사용하려는 프로토콜을 명시한다. 앞서 언급했듯이, 내부에서는 plaintext, 외부 ssl을 원할 수 있다. 그럴때 사용한다.
- 여기서는 내/외부 모두 plaintext를 사용한다.
-
KAFKA_INTER_BROKER_LISTENER_NAME- 카프카 브로커가 내부적으로 바인딩하는 주소에서 사용하는 "이름" 값이다.
- 필수 설정값은 아니고
KAFKA_LISTENERS에서 다양한 이름을 사용할 수 있기에 따로 추가 설정할 수 있다. - 여기까지 봐왔듯 1-4까지 설정값에서 사용하는 "리스너이름" 역시 통일해야 한다.
-
KAFKA_ZOOKEEPER_CONNECT- cluster에서 사용하는 zookeeper의 list를 모두 명시해야 한다.
- 콤마와
<hostname>:<port>로 구분된다.
-
다시 예를 들어, Kafka 서버가 3개의 랜카드를 장착중이고 A,B,C 라는 IP를 각각 부여 받아 사용중이고, 해당 서버에는 Kafka 서비스와, 그 Kafka의 Topic을 구독중인 별도의 Test라는 서비스가 실행중이라고 생각하자.
-
Test 서비스는 Kafka 서비스와 같은 PC에서 구동중이기에 localhost 또는 127.0.0.1 이라는 주소로 kafka에 접근이 가능하다.
-
A,B,C 라는 IP로 접근을 하려는 외부 서비스들이 있을 경우 특정 IP로 접근한 요청들은 Kafka에 접근하지 못하게 해야하는 경우가 있을 수 있다. 또는 특정 IP만 접근하도록 하고 싶을 수 있다.
-
localhost로 접근하는 내부 서비스와 B라는 IP로 접근하는 외부 서비스만 Kafka에 접근 할 수 있게 하고 싶은경우, 아래 설정값을 세팅하게 되는 것이다.
listeners=PLAINTEXT://localhost:9092
advertised.listeners==PLAINTEXT://B:9092당신의 kafka cluster가 외부 네트워크 code level에서 producing or consuming이 안된다면 당장 advertised.listeners 설정 값을 봐야한다!
kafka 로깅과 extention (ex. UI monitoring ...) 설정값
-
KAFKA_LOG_DIRS: Directory where Kafka broker logs will be stored. -
KAFKA_LOG4J_LOGGERS: Comma-separated list of loggers and their respective log levels. For example,kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFOsets the log level to INFO for three different loggers. -
KAFKA_JMX_OPTS: Java Management Extensions (JMX) options to enable remote management of the Kafka broker. These options include setting the JMX remote port, disabling authentication and SSL, and specifying the hostname for JMX RMI connections. -
JMX_PORT: The port on which to expose the JMX remote management interface.
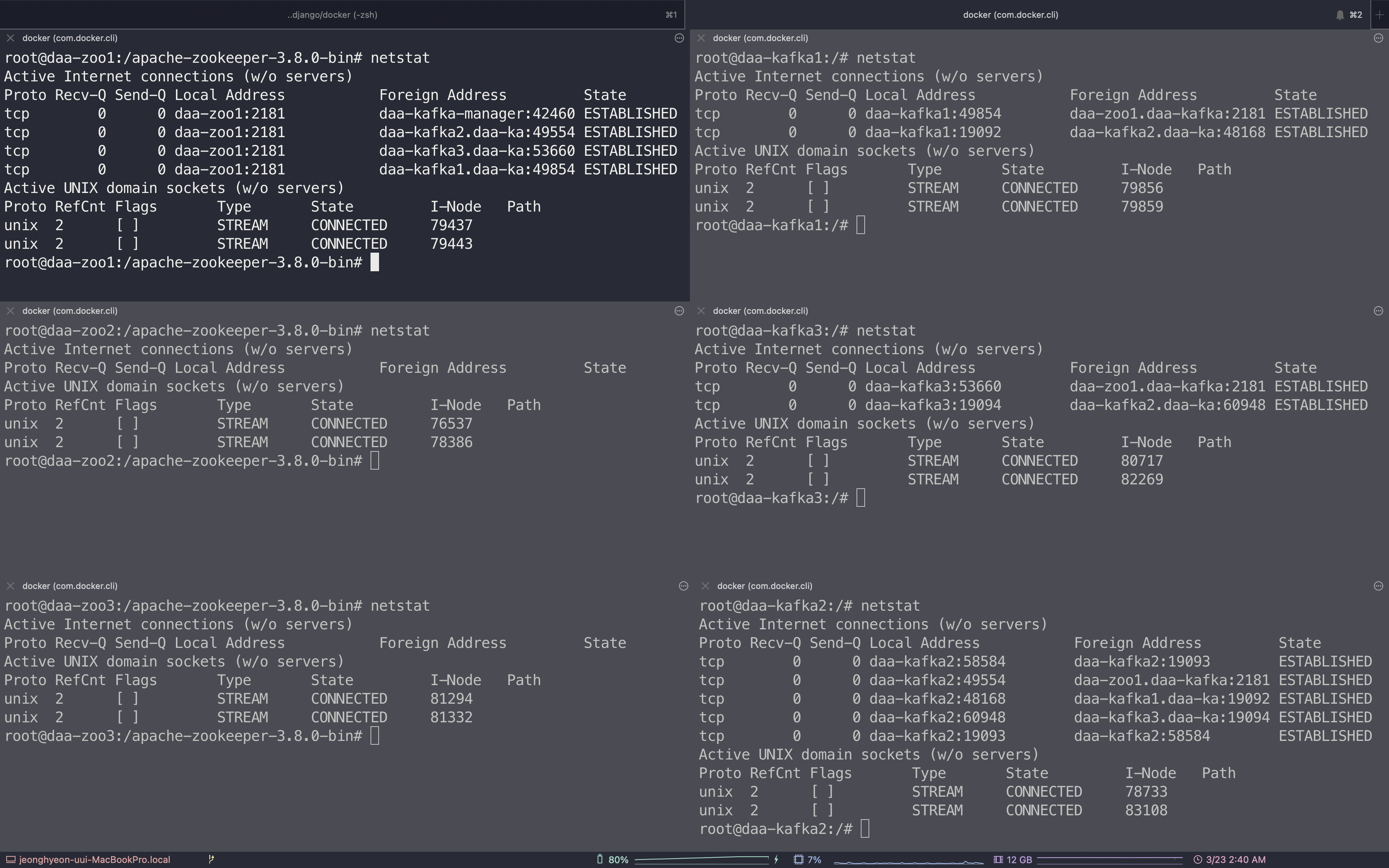
4) kafka shell 기반으로 producing & consuming 해보기
일단 각 kafka의 JMX_PORT 설정과 daa-kafka-manager를 잠깐 꺼두고 실행하자!
TOPIC 만들기
-
docker exec -it daa-kafka1 /bin/bash로 container shell에 접근한다. -
kafka-topics.sh --create --zookeeper daa-zoo1:2181 --replication-factor 3 --partitions 3 --topic my-topic로 my-topic을 만든다. 셸의 위치는/opt/kafka/bin/에 기본으로 존재하나, path가 잡혀있어서 이동할 필요는 없다. -
Created topic my-topic.을 받았으면 성공이다. -
kafka-console-producer.sh --broker-list localhost:9092 --topic my-topic로 my-topic 에 producing mode로 들어간다. > 와 함께 시작된다.

- 아무 메시지나 넣어주자. 참고로 여기서 node connection issue가 생긴다면 compose file에서
KAFKA_ADVERTISED_LISTENERS값 설정을 체크해 보자!!
-
이제
docker exec -it daa-kafka2 /bin/bash로 2번 kafka node container shell에 접근한다. -
kafka-console-consumer.sh --topic my-topic --from-beginning --bootstrap-server localhost:9093로 my-topic 에 consuming mode로 들어간다!
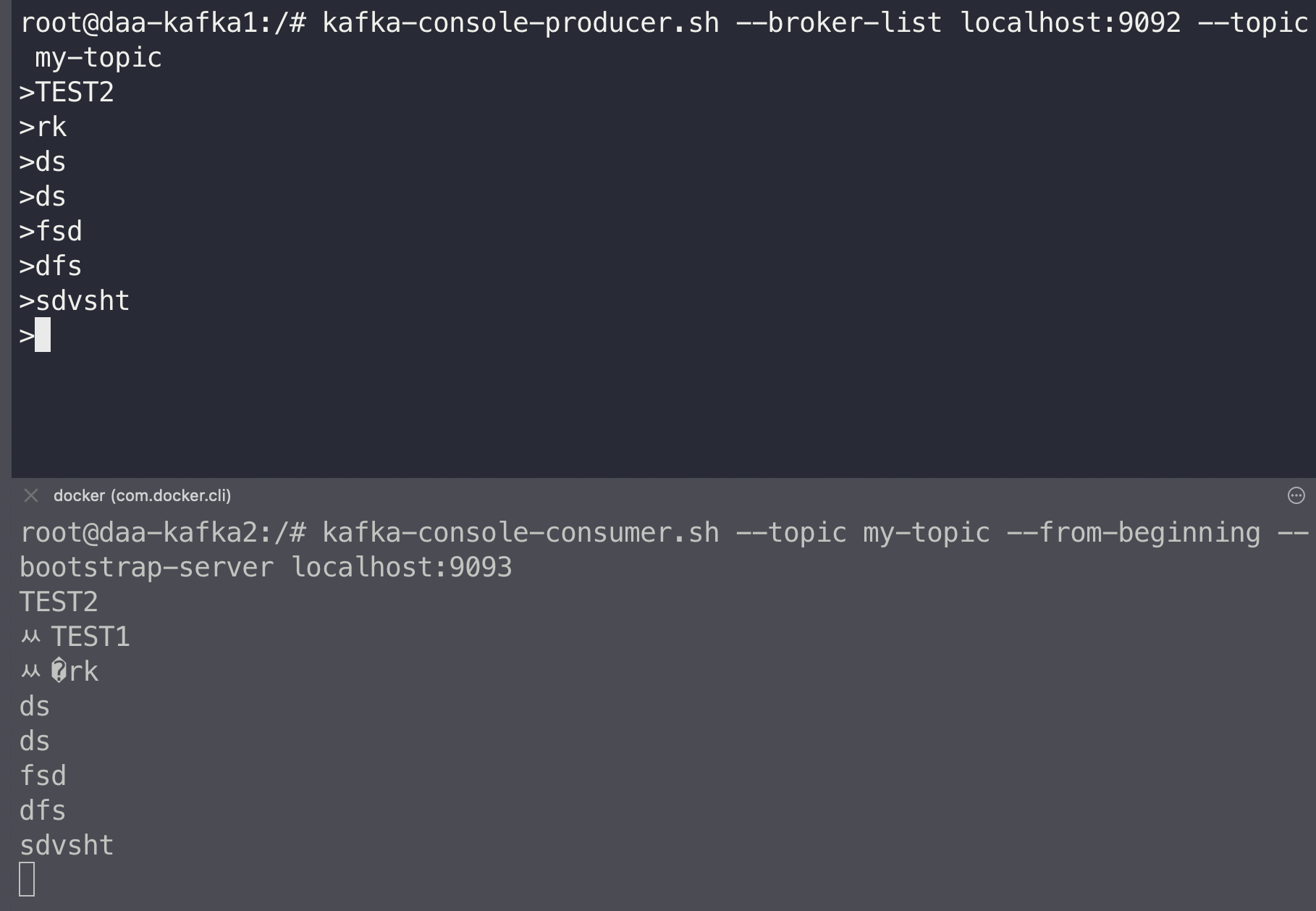
- clustering 환경에서 node가 죽었을 때 leader 가 바뀌고 선출되는 것은 python 기반으로 producer & consumer 를 만들고 직접 node를 죽여가면서 살펴보자!
이제 이 cluster들을 가지고 python code level에서 control 해보자! python based code로 (1) producing하고 consuming해보자! (2) 그리고 실제 하나의 노드가 죽었을 때 어떻게 되는지 실시간 체크를 해보자. 마지막으로 (3) kafka-manager를 활용해 보자
2. python & Kafka cluster
kafka-python library를 활용한다. pip install kafka-python
1) cluster producer
from kafka import KafkaProducer
import json
class MessageProducer:
def __init__(self, broker, topic):
self.broker = broker
self.topic = topic
self.producer = KafkaProducer(
bootstrap_servers=self.broker,
value_serializer=lambda x: json.dumps(x).encode("utf-8"),
acks=0,
api_version=(2, 5, 0),
retries=3,
)
def send_message(self, msg, auto_close=True):
try:
future = self.producer.send(self.topic, msg)
self.producer.flush() # 비우는 작업
if auto_close:
self.producer.close()
future.get(timeout=2)
return {"status_code": 200, "error": None}
except Exception as exc:
raise exc
# 브로커와 토픽명을 지정한다.
broker = ["localhost:9092", "localhost:9093", "localhost:9094"]
topic = "my-topic"
pd = MessageProducer(broker, topic)
msg = {"name": "John", "age": 30}
res = pd.send_message(msg)
print(res)-
일단 cluster host, bootstrap_servers를
list로 만들어서KafkaProducerclass instance를 만들어주는 것이 핵심이다. 물론 "시리얼라이징" 할 형태, json 형태로 할 것이라,json.dumps(x).encode("utf-8")와 같이 세팅한다. -
실제 해당 라이브러리도 kafka official docs 기반으로 만들어진 것이라, 깊은 사용은 꼭 참고할 필요가 있다.

-
그리고 라이브러리 파일에 주석이 아주아주 친절하게 되어있다. KafkaProducer object config 값에서
acks는 꽤 중요한 설정값이다.(0, 1, "all")중 하나가 될 수 있고, default 값은 1이다. 설명은 아래와 같다.-
0: Producer will not wait for any acknowledgment from the server. The message will immediately be added to the socket buffer and considered sent. No guarantee can be made that the server has received the record in this case, and the retries configuration will not take effect (as the client won't generally know of any failures). The offset given back for each record will always be set to -1.
-
1: Wait for leader to write the record to its local log only. Broker will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost.
-
all: Wait for the full set of in-sync replicas to write the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee.
-
-
데이터의 수/발신과 신뢰성이 중요한 환경에서는 1로 세팅하고 병목이나 퍼포먼스를 지켜보는 것이 좋을 것 같다. 일단 테스트를 위해 0으로 세팅했다.
send
-
kafka는 기본적으로, 당연히, "비동기 컨셉" 이다. 그렇기 때문에
send행위 자체가 "asynchronous" 하다는 것을 명심해야한다. -
그리고 전송하려는 메시지,
value값은 bytes 여야 한다. 바이트로 전송하지 세팅하지 않으면, KafkaProducer instance에 정의한value_serializer에 의해 serializable to bytes 로 casting 된다. -
flushmethod는 producer를 closing하기 전에 전송한 메시지를 모두 제대로 전송했는지 보장하기 위해 사용한다. 여기서 ack이랑 혼동이 있으면 안된다. 우리는send라는 비동기 행위로 kafka에게 message를 전송한다. 근데 비동기 작업을 위한 memorry buffer 세팅을 하고, 비동기 작업 중 시스템이 먼저 끝나면? code level에서 stop이 된다. -
실제로 producer & consumer 를 동시에 돌리면서 producing을 반복하면
flush없는 코드에서는 programe이 먼저 끝나서 message를 못전송하는 케이스를 분명 볼 수 있다. 즉flush는 kafka가 주는 ack를 기다린다는 의미가 아니라, code level에서의 기다림을 말한다. 더 자세한 얘기는 github 토론을 잠깐 살펴보자 -
참고로
poll이 실제로 producing할 message가 담긴 queue의 데이터를 가져오는 method이고flush는 calls poll() until len() is zero or the optional timeout elapses.
2) cluster consumer
from kafka import KafkaConsumer
class MessageConsumer:
def __init__(self, broker, topic):
self.broker = broker
self.consumer = KafkaConsumer(
topic, # Topic to consume
bootstrap_servers=self.broker,
value_deserializer=lambda x: x.decode(
"utf-8"
), # Decode message value as utf-8
group_id="my-group", # Consumer group ID
auto_offset_reset="earliest", # Start consuming from earliest available message
enable_auto_commit=True, # Commit offsets automatically
)
def receive_message(self):
try:
for message in self.consumer:
print(message)
except Exception as exc:
raise exc
# 브로커와 토픽명을 지정한다.
broker = ["localhost:9092", "localhost:9093", "localhost:9094"]
topic = "my-topic"
cs = MessageConsumer(broker, topic)
cs.receive_message()- consumer 역시 docs가 굉장히 잘되어 있다.
-
가장 기본적인 컨슈밍할 topic값, producer가 시리얼라징한 데이터를 de시리얼라이징하기 위한 인자값
value_deserializer, 그리고 당연히 브로커 -bootstrap_servers세팅이 기본 핵심이다.group_id값은 우리가 컨슈머를 묶어서 사용하고, 특정 컨슈머를 그룹화 하기 위해 사용한다. -
컨슈밍 방법은 아주 단순하다.
KafkaConsumerclass instanc,consumer를 for loop로, 또는 while 로 iterating 하면된다.
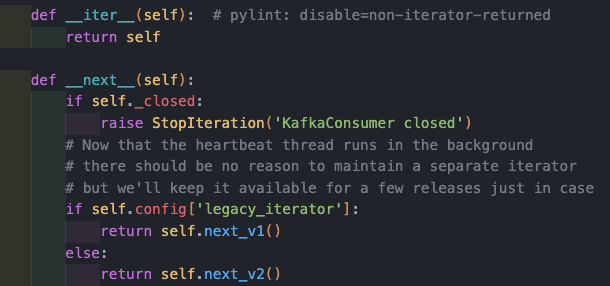
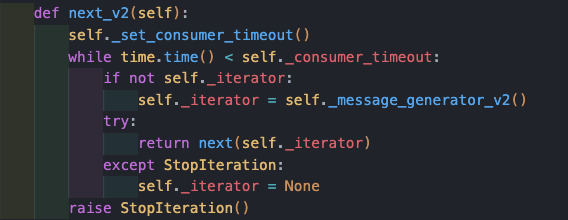
_message_generator_v2에서는poll을 호출한다. 아래와 같다.
def poll(self, timeout_ms=0, max_records=None, update_offsets=True):
... # 생략
# Poll for new data until the timeout expires
start = time.time()
remaining = timeout_ms
while True:
records = self._poll_once(remaining, max_records, update_offsets=update_offsets)
if records:
return records
elapsed_ms = (time.time() - start) * 1000
remaining = timeout_ms - elapsed_ms
if remaining <= 0:
return {}-
크게 이터레이팅을 정의하면서 딱 timeout 만큼 while을 돌다가 안에서
_poll_once성공할때 까지while True를 한다. -
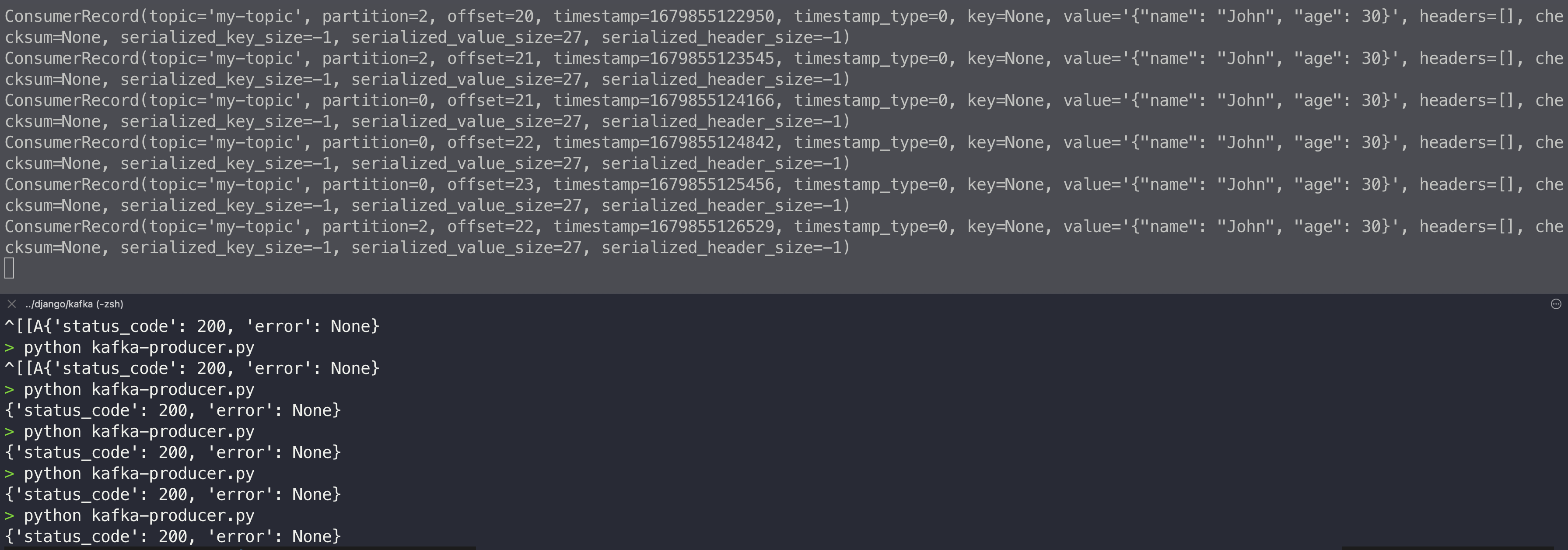
이제
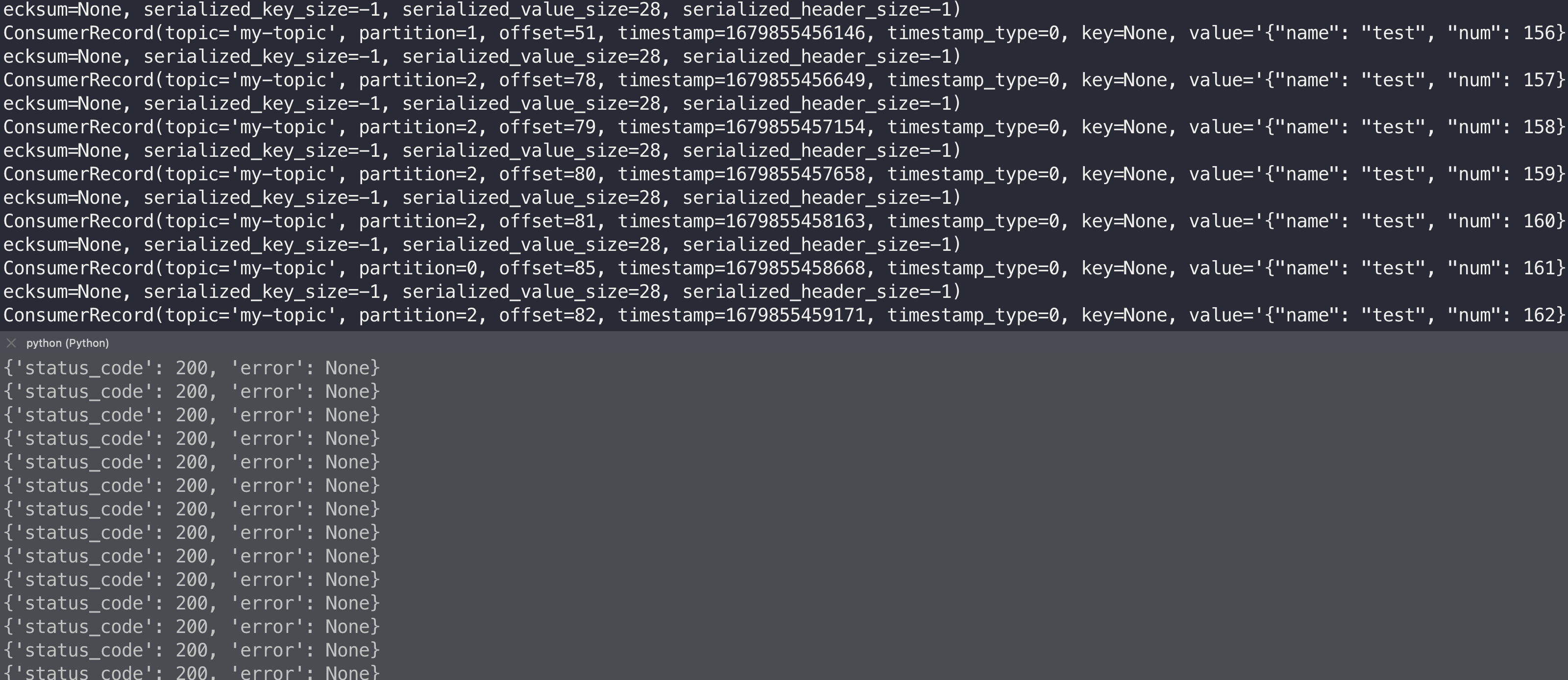
kafka-consumer.py를 실행한 채로kafka-producer.py를 계속 돌리면 아래와 같은 결과값(출력)을 얻게 된다.
-
ConsumerRecord값을 가져오며valueproperty에 역직렬화(deserialization)된 우리가 producing한 message가 저장되어 있다. -
그리고 해당 instance의 기본적인 property값은
ConsumerRecord(topic='my-topic', partition=0, offset=1477, timestamp=1679903966755, timestamp_type=0, key=None, value='{"name": "test", "num": 2958}', headers=[], checksum=None, serialized_key_size=-1, serialized_value_size=29, serialized_header_size=-1)와 같다.offset값과partitionnumber 값도 저장되어 있는 것을 확인할 수 있다.
3) client는 계속 돌고, kafka node가 하나 죽으면?
- 우선 producing을 계속하게 원래 코드에 아래 부분만 추가해 보자.
...
while True:
cnt += 1
msg = {"name": "test", "num": cnt}
res = pd.send_message(msg, False)
print(res)
sleep(0.5)- 그리고 client 는 계속 러닝시켜 둔다. 그리고 "leader" 가 아닌 node를 하나 죽여보자, producing, consuming은 계속되는 것을 확인할 수 있다.
-
다시 살리면? 알아서 sync를 맞추며 살아난다! (docker log를 보면서 진행하면 더 좋다.) 그러면 leader를 죽이면? 다시 leader를 선출하고, 변경하며 진행된다. 그리고 다시 노드를 하나 더 죽이면 이제 잠깐 consuming은 주춤하게 된다.
-
주춤하는 이유는 (1) 리더 선출을 위해서, (2) location of latest offset for each partition 를 알기 위해서 정도이다. 여기서 또 producing의 ack 값이 중요하게 작용할 수 있다.
-
위에서 ack를 0으로 세팅해 커넥션이 열리고 전송만 성공하면 계속 producing을 하게 되어있다. 만약 ack를 1로 세팅하고 producing 하는 상태에서, leader node가 죽으면, 잠시동안 순단이 있을 수 있다. (1) 리더 선출 하는 동안 ack를 제대로 전달하지 못할 가능성이 있기 때문이다!
3. Kafka Manager 활용하기
데이터 파이브라이닝 구축에 kafka cluster interface가 점점 대중화되어가다 보니, 지금도 kafka를 매니징할 수 있는 좋은 GUI tool들이 쏟아져 나오고 있다. Kafka-UI Tool 을 이용하여 Kafka 관리하기 글을 꼭 한 번 참고하여 상황에 맞는 GUI tool을 세팅하는게 좋을 것 같다.
1) apache kafka manager, CMAK 살펴보기
daa-kafka-manager:
image: hlebalbau/kafka-manager:2.0.0.2
container_name: daa-kafka-manager
restart: on-failure
environment:
ZK_HOSTS: "daa-zoo1:2181,daa-zoo2:2182,daa-zoo3:2183"
APPLICATION_SECRET: "random-secret"
KM_ARGS: -Djava.net.preferIPv4Stack=true
command:
- "-Dcmak.zkhosts=daa-zoo1:2181,daa-zoo2:2182,daa-zoo3:2183"
- "-DbasicAuthentication.enabled=true"
- "-DbasicAuthentication.username=kafka-admin"
- "-DbasicAuthentication.password=kafka-admin#"
ports:
- "9000:9000"
networks:
- daa-kafka-cluster-network
depends_on:
- daa-zoo1
- daa-zoo2
- daa-zoo3
- daa-kafka1
- daa-kafka2
- daa-kafka3-
docker compose file에 위 image & container와 kafka의
KAFKA_JMX_OPTS,JMX_PORT를 보았을 것이다. 지금은 "CMAK" 이라고 불리고, 저장소 링크는 여기를 클릭!. -
ZK_HOSTS세팅으로 주키퍼 host를 콤마기준 string값으로 세팅하고,command로 manager가 실행될때 http basic authentication 을 활용하기 위해DbasicAuthentication.세팅을 해준다.
KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=kafka -Dcom.sun.management.jmxremote.rmi.port=9992"
JMX_PORT: 9992- 그리고 kafka에게 필요한 추가 세팅은 JMX(Java Management eXtensions) 를 해준다. 참고로 java는 jvm위에서 런타임을 가지고, java는 이런점을 잘 활용해 agent 형태로 메모리, 사용량, 퍼포먼스, 네트워크 등을 체크할 수 있도록 감시 관리를 위한 도구를 제공하는 자바 API가 있다. 참고로 이 세팅은 필수가 아니다. kafka mager에서 제공하는 다양한 세팅을 핸들링하려면 JMX 세팅을 하는것을 추천한다. 간단하게 offset이나 파티셔닝만 보고싶으면 할 필요가 없다.
2) CMAK 실행과 cluster 세팅
localhost:9000에 접근하면 아래와 같은 페이지가 보인다! 참고로 http basic auth를 세팅했으면 login 창이 먼저 뜰 것이다.Add Cluster로 직접 클러스터를 추가하자.
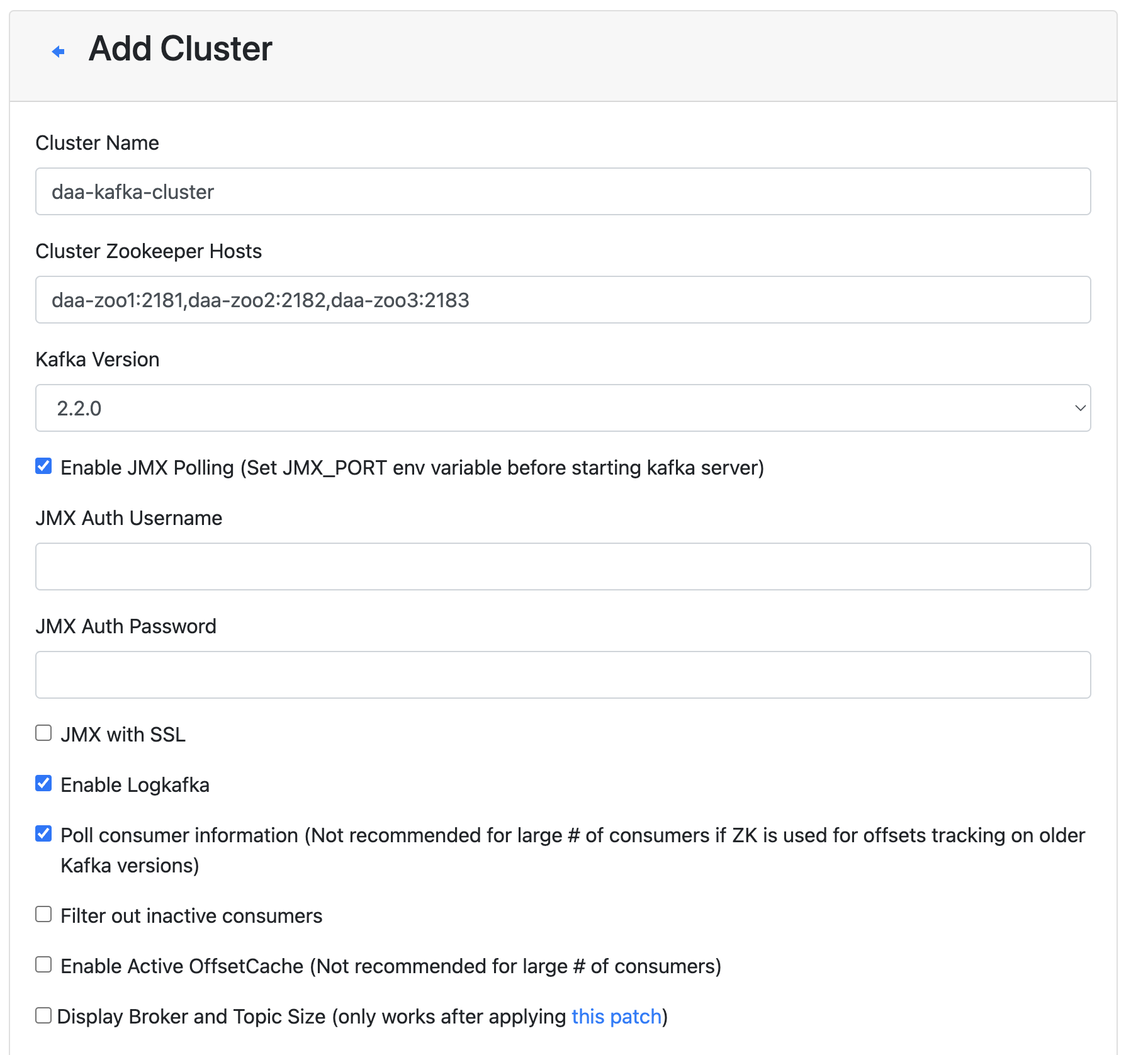
- 그리고 아래 사진과 같이 최소한의 세팅을 해주자. JMX Polling을 하기위해 각 kafka node에
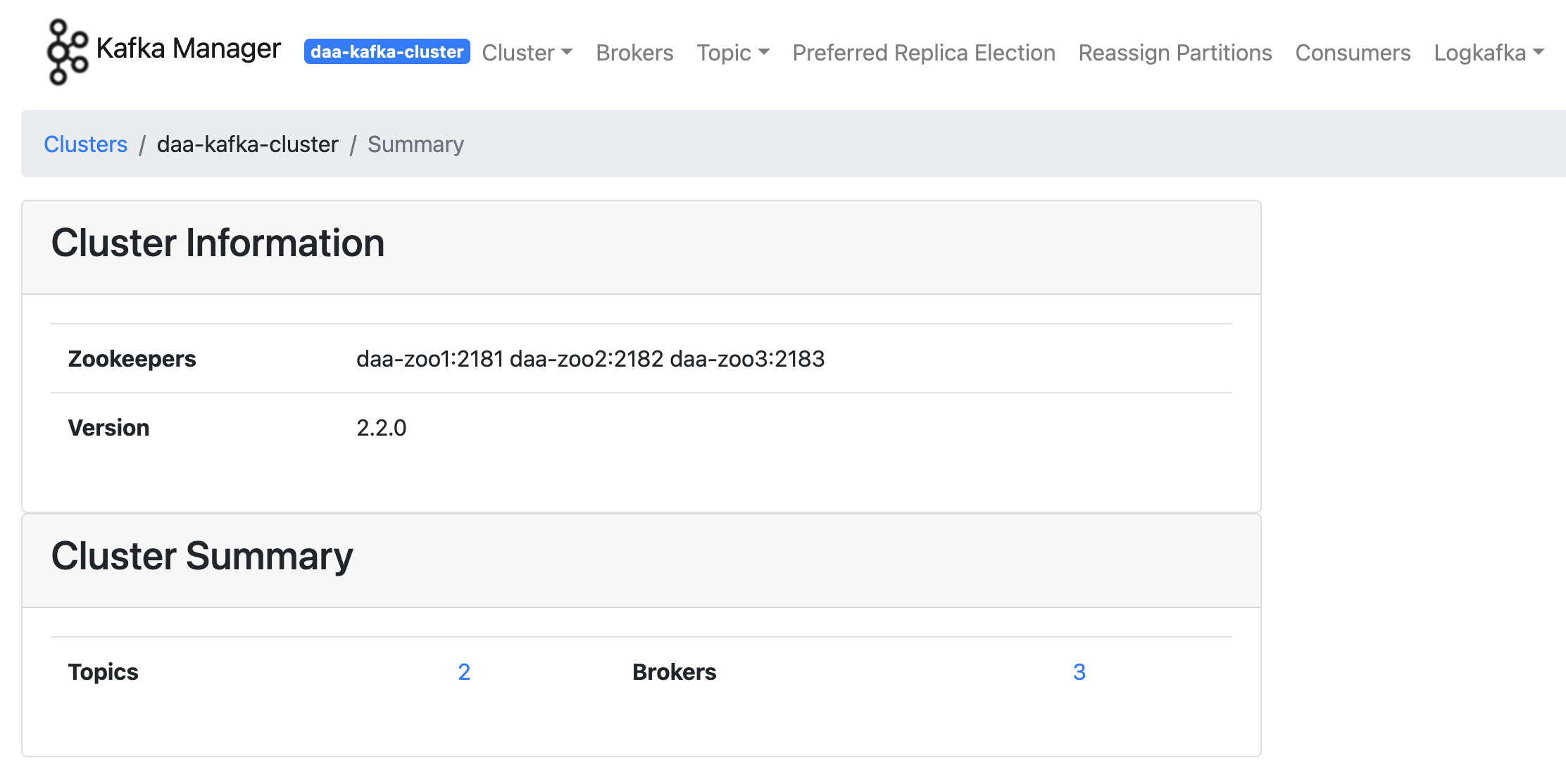
9992port를 세팅했다.Done이후 세팅한 cluster에 접근하면 아래 2번째 사진과 같이 뜬다.
- 일단 위에서 만든 producing & consuming을 계속 돌려보자. 그리고
Brokers로 접근하면 JMX 덕에 볼수 있는 Bytes in&out을 볼 수 있고, 메트릭 정보를 바탕으로 퍼포먼스 체크도 가볍게 가능하다.
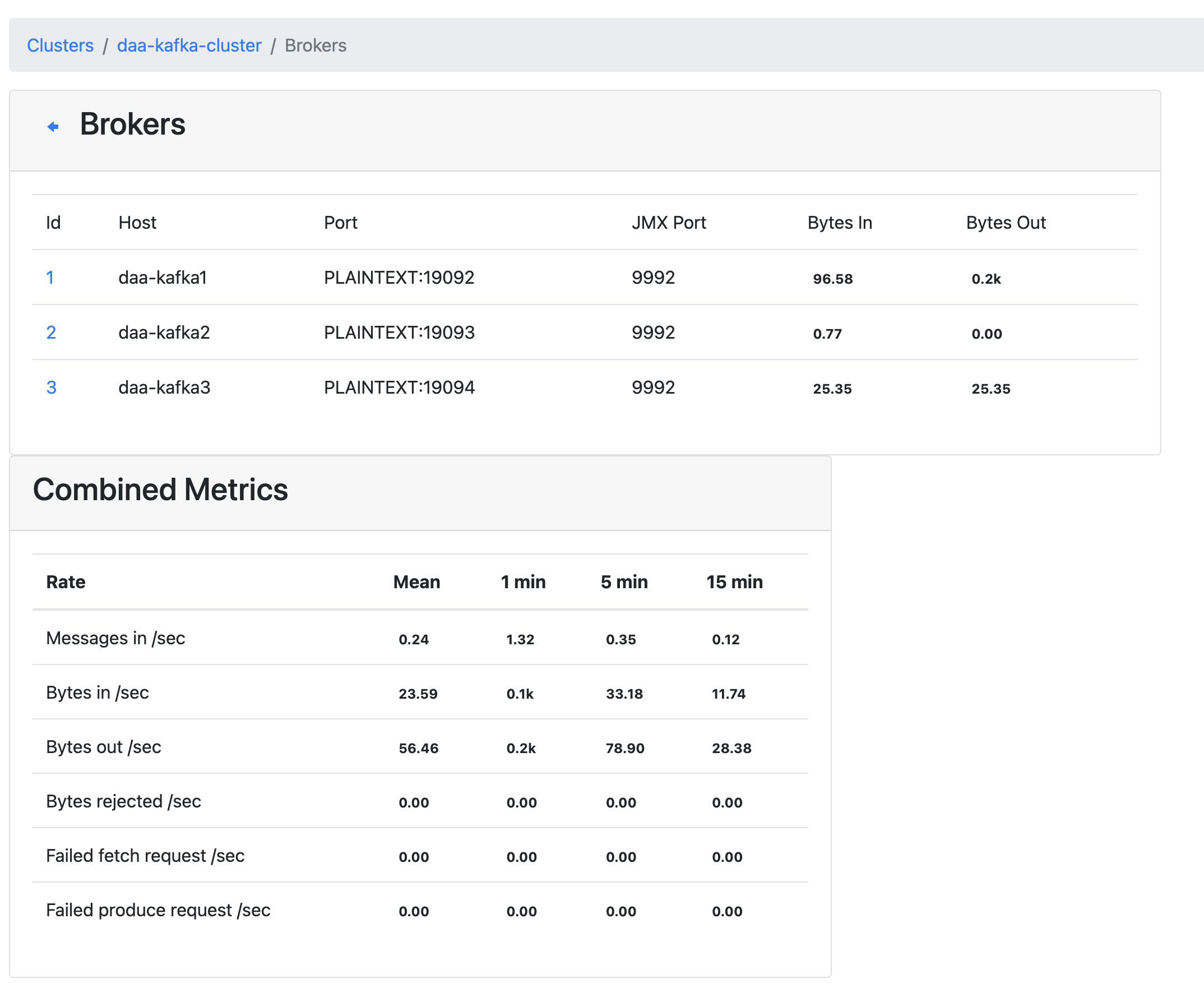
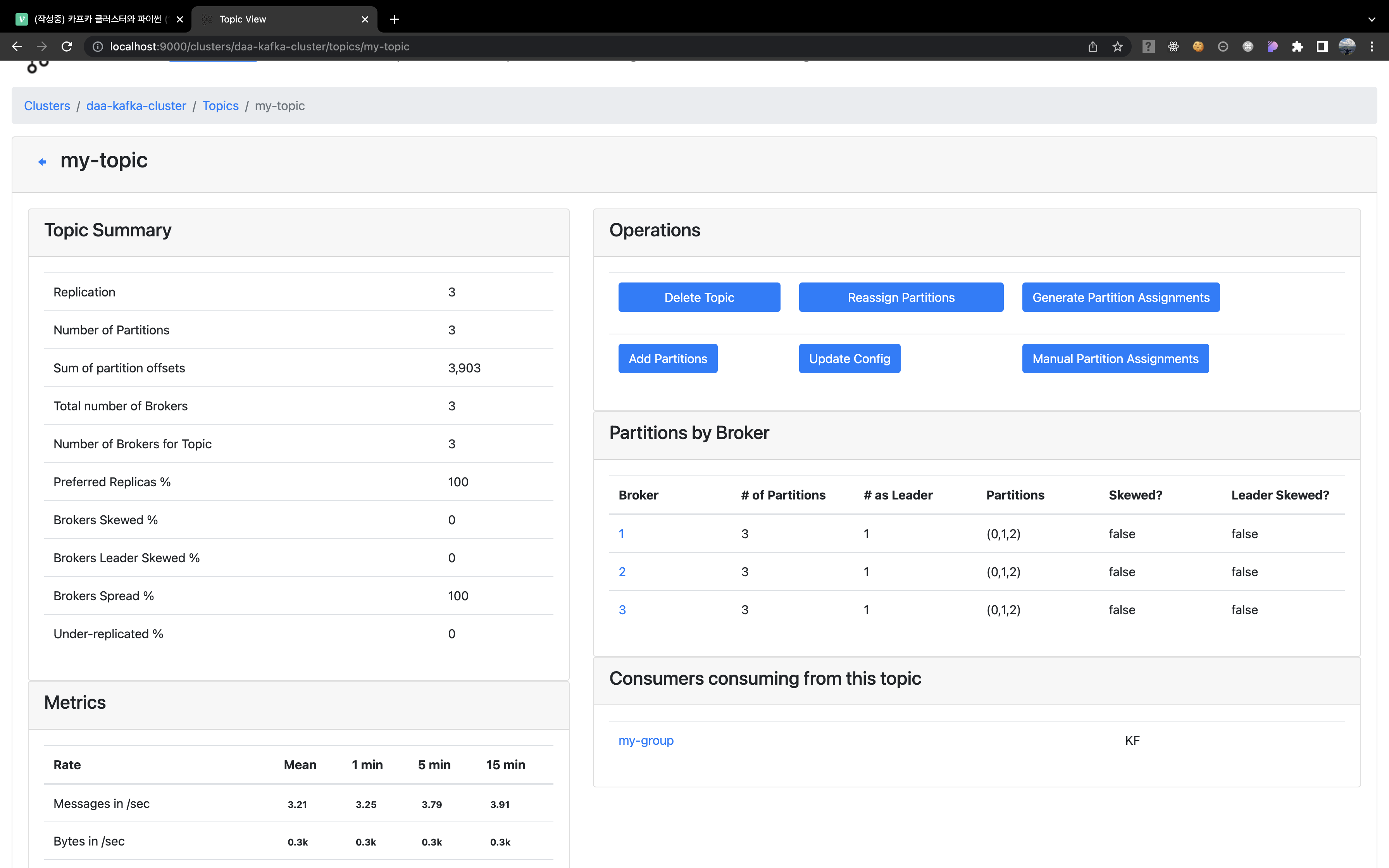
TOPIC 살펴보기
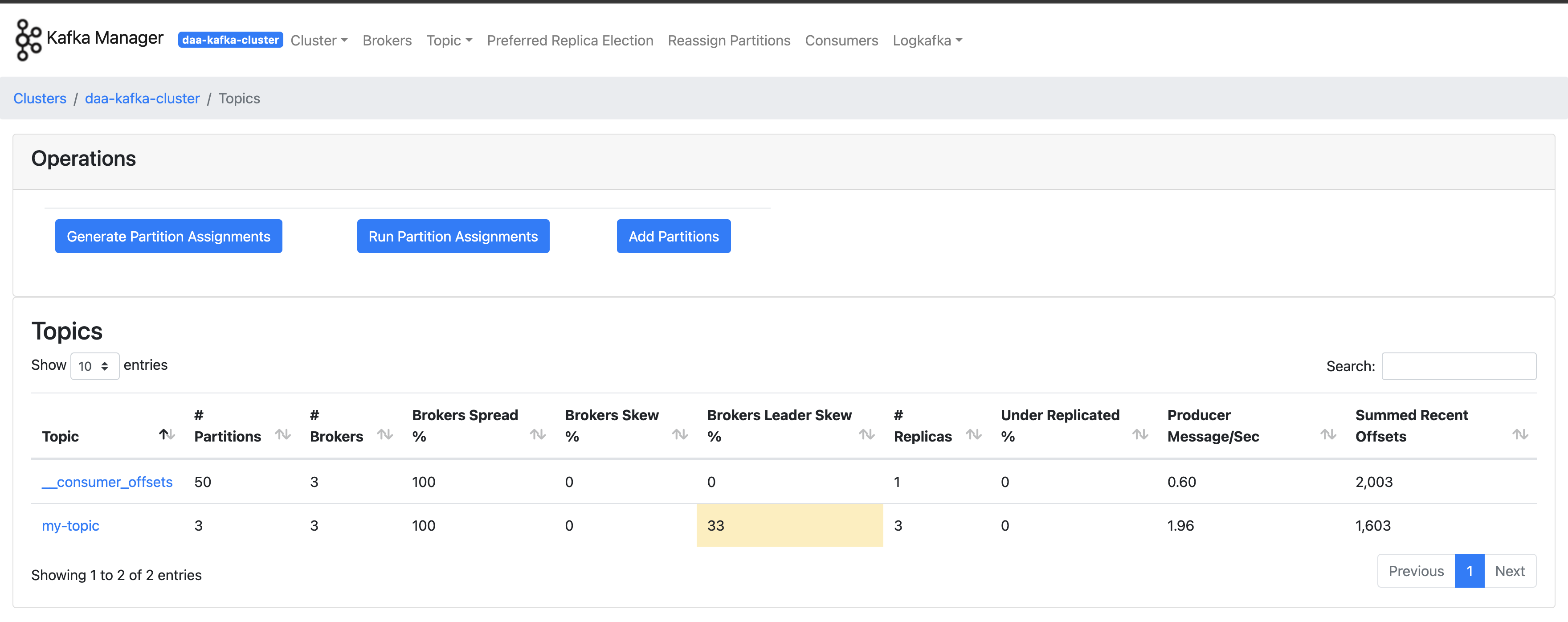
- topic 항목으로 가면 실시간으로 topic 대상 cosuming & producing 현황을 볼 수 있다. 여기서
Sum of partition offsets값이 러프하게 실시간으로 체크가능한 producing된 전체 message 개수라고 생각하면 편하다.
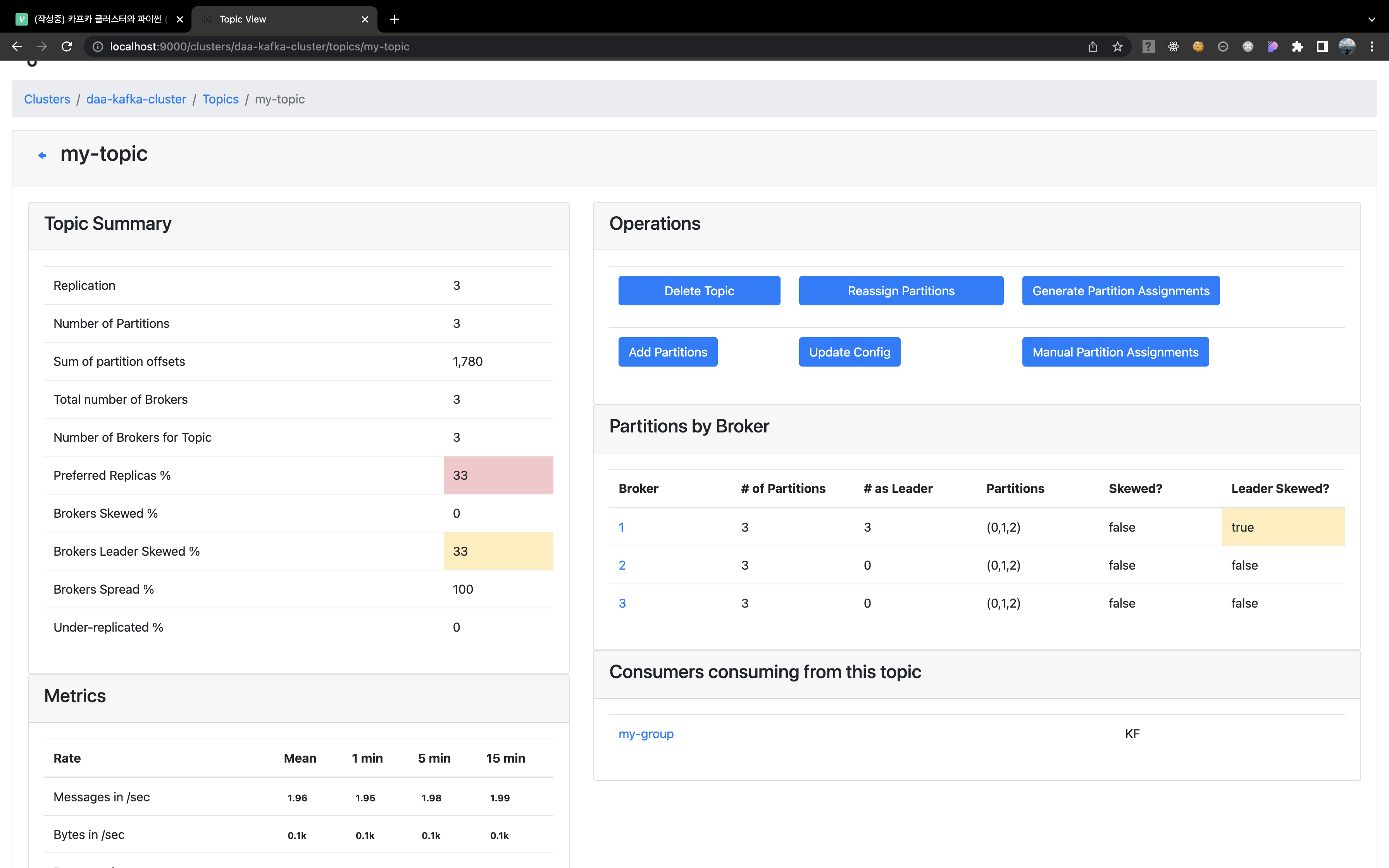
- 특정 topic을 클릭해 접근하면 누가 리더인지, 파티셔닝 상태는 어떻게 되는지도 살펴볼 수 있다. 우리가 consuming 하는 process 에서 group id를 세팅해 둬서 그룹도 뜬다. 우리가 위에서 테스트한 "kafka node 죽이기!" 를 해당 매니저 GUI와 함께 모니터링하면서 체크하면 더 확실하게 어떻게 leader가 바뀌는지 볼 수 있다.
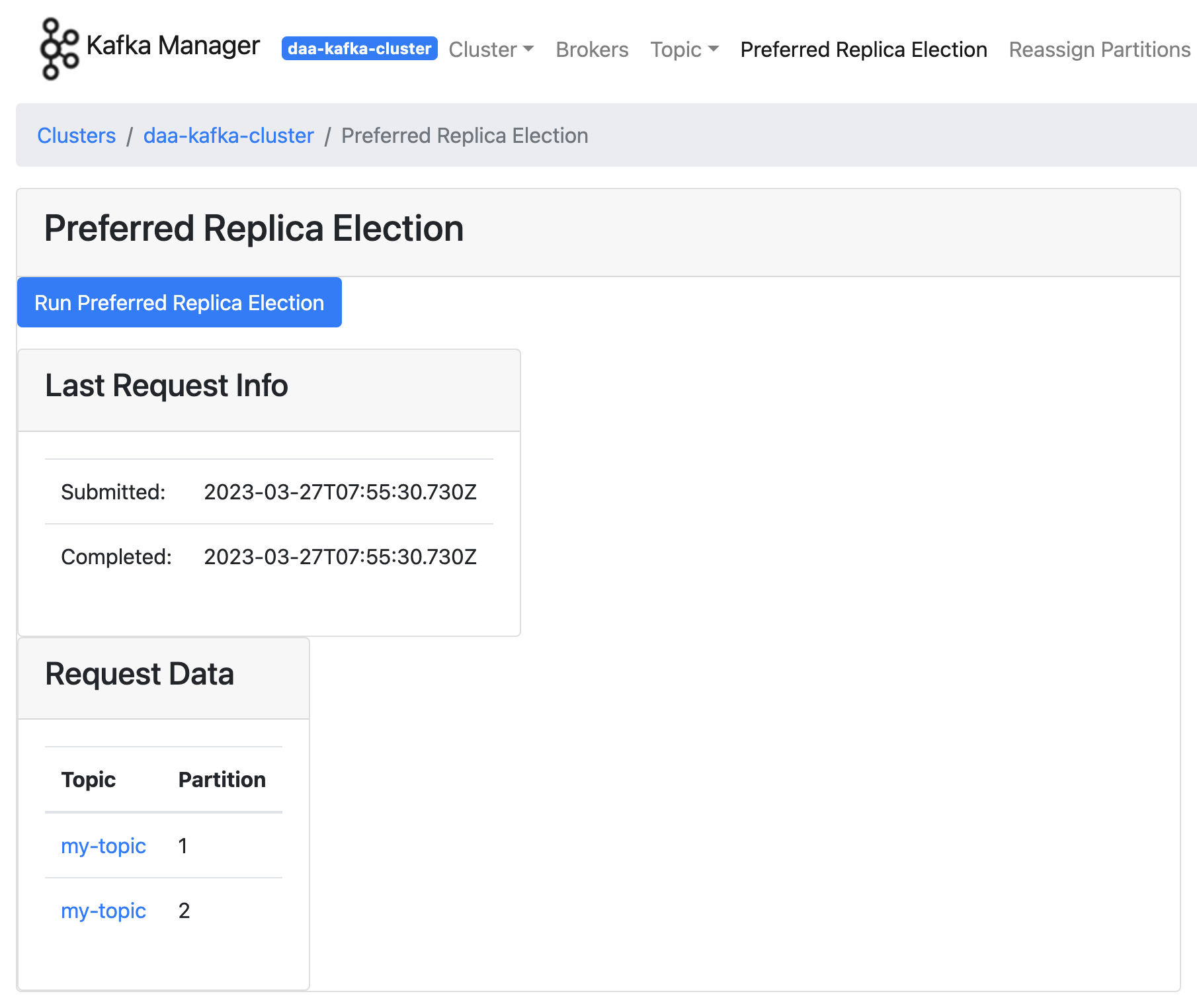
-
여기서 첫번째 가장 핵심 기능은 "Preferred Replica Election" 이다. 카프카를 운영하면서 가져야할 첫 번째 관점은 "메시지 유실율을 거의 0%에 가깝게" 이다. 카프카 운영 - Preferred Replica Election 글을 추천한다.
-
해당 글에서 가장 먼저 언급한 카프카 클러스터링을 다시 생각해보면, 리더 파티션은 복제된 파티션 중 "유일하게 메세지 쓰기와 읽기 작업을 담당하여 수행"하며, "팔로워들은 리더가 쓰기 작업을 완료한 메세지들을 복제(replication)" 한다. 그리고 혹시 모를 장애에 대응하기 위해 "복제 파티션을 여러 브로커에 위치시킨다." 그리고 이러한 세팅은 운영자가 수동적으로 위치를 지정해줄 필요도 있다!
-
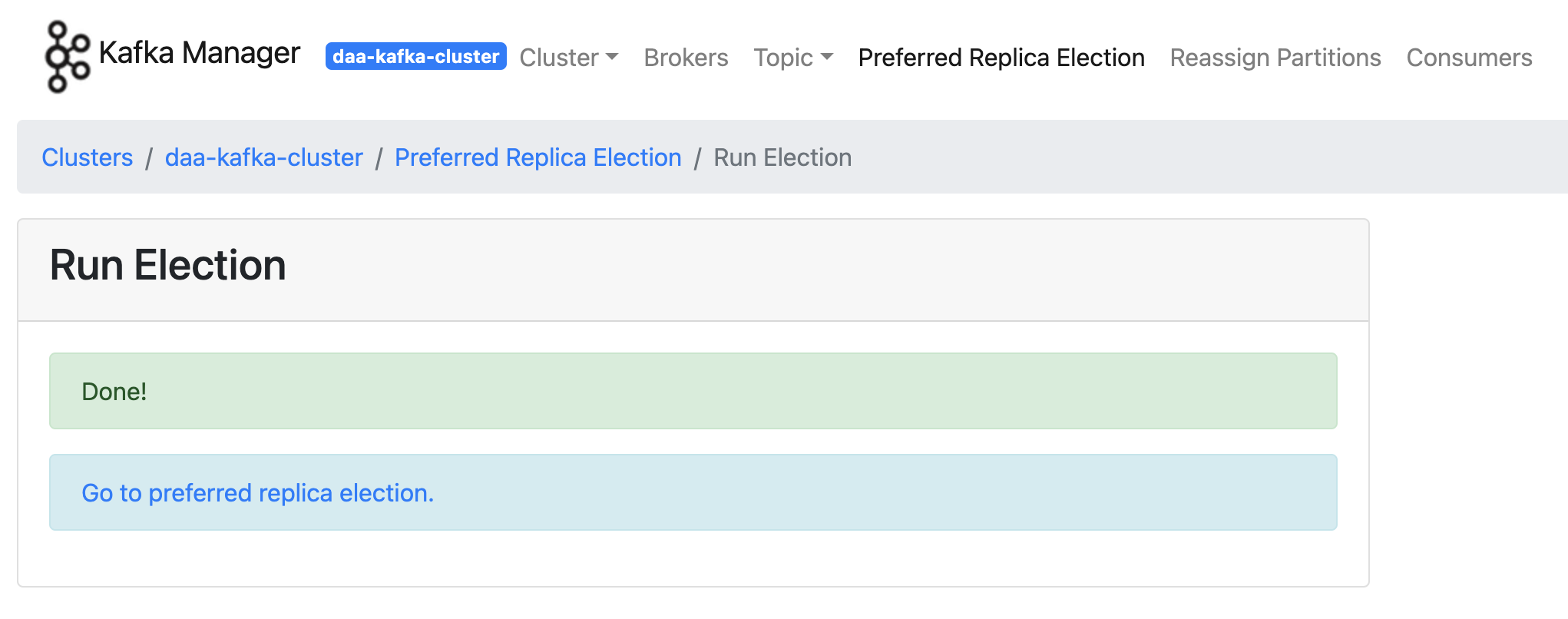
이런 행위를 "Preferred Replica Election" 통해 할 수 있다. 세팅하기를 하고 아래 사진 흐름과 같이 topic 확인까지하면
Preferred Replicas %,Brokers Spread %수치가 100 으로 바뀐것을 확인할 수 있다.
- 많은 부분을 살펴볼 필요가 있지만, kafka clustering을 활용하기 위한 기본적인 설정값과 이유, 그리고 장애 대비를 위한 최소한의 세팅까지 manager를 통해 체크했다. 더 많은 내용은 따로 특정 주제를 타겟팅해 시리즈에서 다룰 예정이다.
출처
- https://blog.naver.com/pyoyr/50031514702
- https://ssup2.github.io/theory_analysis/Kafka_Cluster_Replication/
- https://zookeeper.apache.org/doc/r3.3.3/zookeeperAdmin.html
- https://zookeeper.apache.org/doc/r3.3.3/zookeeperAdmin.html#sc_configuration
- https://docs.confluent.io/platform/current/zookeeper/deployment.html#post-deployment
- https://www.confluent.io/blog/kafka-listeners-explained/
- https://brunch.co.kr/@timevoyage/77
- https://always-kimkim.tistory.com/entry/%EC%B9%B4%ED%94%84%EC%B9%B4-%EC%9A%B4%EC%98%81-Preferred-Replica-Election

4개의 댓글

진짜 엄청나게 도움 되는 글................ 글 자체가 굉장히 촘촘하고 친절해요 개념까지 완벽하게 쉽게 풀어쓴 진짜 완벽한 가이드..!!!!!!!!!!!!!!!!!!!!!!!!!! 너무 감사합니다
진짜 좋은 글 너무 감사합니다...
외부 서버에서 구축하려다 보니 좀 애를 먹긴 했지만 정말 많은 도움이 됐습니다!