카프카 클러스터와 파이썬 (2) - Debezium & Postgresql & Django, log based CDC 만들기 (source & sink connector)
[ 글의 목적: kafka clustering & connect (debezium) 을 활용해 DB 변화를 catch 하는 Change Data Capture를 기반으로 DB duplication을 위한 접근법과 "사용법"에 대한 기록 ]
kafka cluster and CDC
change data capture는 특정 DBMS의 data 변화 감지를 하는 것이다. log-based 로 접근하면 어떤 데이터가 어떻게 변했는지, CUD에 대한 정보를 모두 얻을 수 있다. 여기서 log는 postgresql의 wal file을 중심으로 살펴보고 해당 CDC를 기반으로 duplicated 된 DB 구성을 직접 해보자!
🔥 우선 등장하게 될 예제는 https://github.com/Nuung/django-all-about 레포 기준으로 진행합니다. 그리고 꼭 동일 시리즈 내의 이전 글 카프카 클러스터와 파이썬 (1) - python kafka with kafka cluster, consumer & producer & docker compose 파헤치기 를 먼저 확인하고 읽어 주시길 바랍니다!!
1. CDC (Change Datat Capture)

사진 출처: 네이버 엔지니어링 - 막힌 데이터의 혈을 뚫자! Pay 플랫폼 CDC 적용 사례
-
CDC는 위에서 소개한 것과 같이 "특정 DBMS의 data 변화 감지" 가 핵심이다. 해당 변화를 감지해서 duplication set을 만들고 sharding을 할지, 아니면 특정 event가 일어나는 trigger로써, 아니면 cache server와의 데이터 일관성 보장을 위해, 아니면 logging으로써 등 활용 방법은 다양하다. 더 자세한 활용법이 궁금하다면 위 링크의 영상을 꼭 보자!
-
현재 상태는 "과거로부터 발생한 모든 변경 사항의 누적합" 과 같다. Distributed computing 에서 고가용성(High availability)을 위해 사용하는 "Eventual consistency" 을 생각해보자.
-
이렇게 이기종으로 분리해 서로 결합도가 낮고, 확장에 서로 영향을 주지 않기 때문에 확장성도 좋은 시스템을 만들 수 있다. 구현하는 형태에 따라 크게 Pull 방식과 Push 방식 으로 나누어 진다.
1) 대표적인 구현 형태
pull 방식
-
타깃 시스템의 주기적인 풀링으로 변경 사항이 있는지 확인하는 방법이다. 상대적으로 쉽게 구현할 수 있다는 장점이 있지만, 실시간성이 떨어진다는 단점 또한 있다.
-
대표적으로 logstash의 query based cdc가 pull 방식의 cdc이다. - Elasticsearch - ELK stack & Postgresql & Logstash, query based CDC 만들기 by docker compose
push 방식
-
소스 시스템이 변경이 발생할때마다 타깃 시스템에 알려주는 방법이다. Pull 방식에 비해 소스 시스템이 많은 작업을 해야 하고, 타깃 시스템에 문제가 발생한다면 변경 이벤트에 누락 이 발생할 수 있지만, 실시간성 이 뛰어나다는 장점이 있습니다.
-
이 push 방식에 kafka를 곁들이면 "이벤트 누락의 단점" 을 어느정도 보완할 수 있다. DB로부터 데이터의 변경 이벤트를 감지해서 Kafka 이벤트를 발행해 주는 것이 바로 Debezium 이다.
왜 Application Layer 활용안함?
-
많은 framework들이 DB의 변화 감지, 특정 event를 감지하는 기능이 있다. (django에서는 signal) 허나 이런 Application Layer 대신 Persistence Layer 를 사용하는 이유는 DB 자체의 관점에서 event를 감지할 수 있기 때문이다.
-
즉, application event는 application 내부에서만 일어나는 event에 대해 catch가 가능하다. 하지만 persistence 계층에서는 application과 무관하게 외부 접근, 즉 직접 DBMS에 붙어서 편집하는 경우도 모두 check가 가능하다는 것이다.
2) Transaction Log
-
여기서는 DBMS log-based CDC를 세팅할 예정이기 때문에 "DBMS log" 에 대해 알아야 한다. 여기서는 핵심만 살펴보자!
-
Transaction Log 또는 데이터베이스 로그(database log, 바이너리 로그라고도 함)는 데이터베이스에서 충돌이나 하드웨어 고장이 있었다고 해도 데이터베이스 관리 시스템의 ACID 특성을 보장하기 위한 이력을 말한다.
-
모든 데이터베이스에는 "데이터 파일"과 분리된 로그 파일에 저장된 "트랜잭션 로그"가 있다. 트랜잭션 로그는 기본적으로 모든 데이터베이스 수정 사항을 기록한다. 오류가 발생하면 트랜잭션을 되돌리거나 복원할 수 있으며 데이터 손상도 방지할 수 있다.
COMMIT,REDO,ROLLBACK등의 command 가 대표적인 활용 예시다!
Postgresql의 transaction log : 공식문서
-
psql의 transaction log는
Write-Ahead Logging(wal)이라는 파일로 생성되며 "트랜잭션 로그를 데이터 변경 작업 전에 미리 기록하는 방식" 이다. -
즉 트랜잭션의 변경 작업을 물리적으로 디스크에 반영하기 전에, 해당 변경 내용을 WAL에 기록한다. 그래서 로그에 기록된 것들만 data file에 반영이 된다.
-
WAL Segment,Checkpoint,Dirty Pages등의 개념이 존재한다. 해당 프로젝트에서는 debezium을 활용해 이 wal file을 read해야하기 때문에 psql의 wal file conf가 중요하다. -
psql로 psql shell에 붙어서SHOW data_directory;를 입력하면 "데이터 디렉토리" 가 어딘지 알 수 있다.
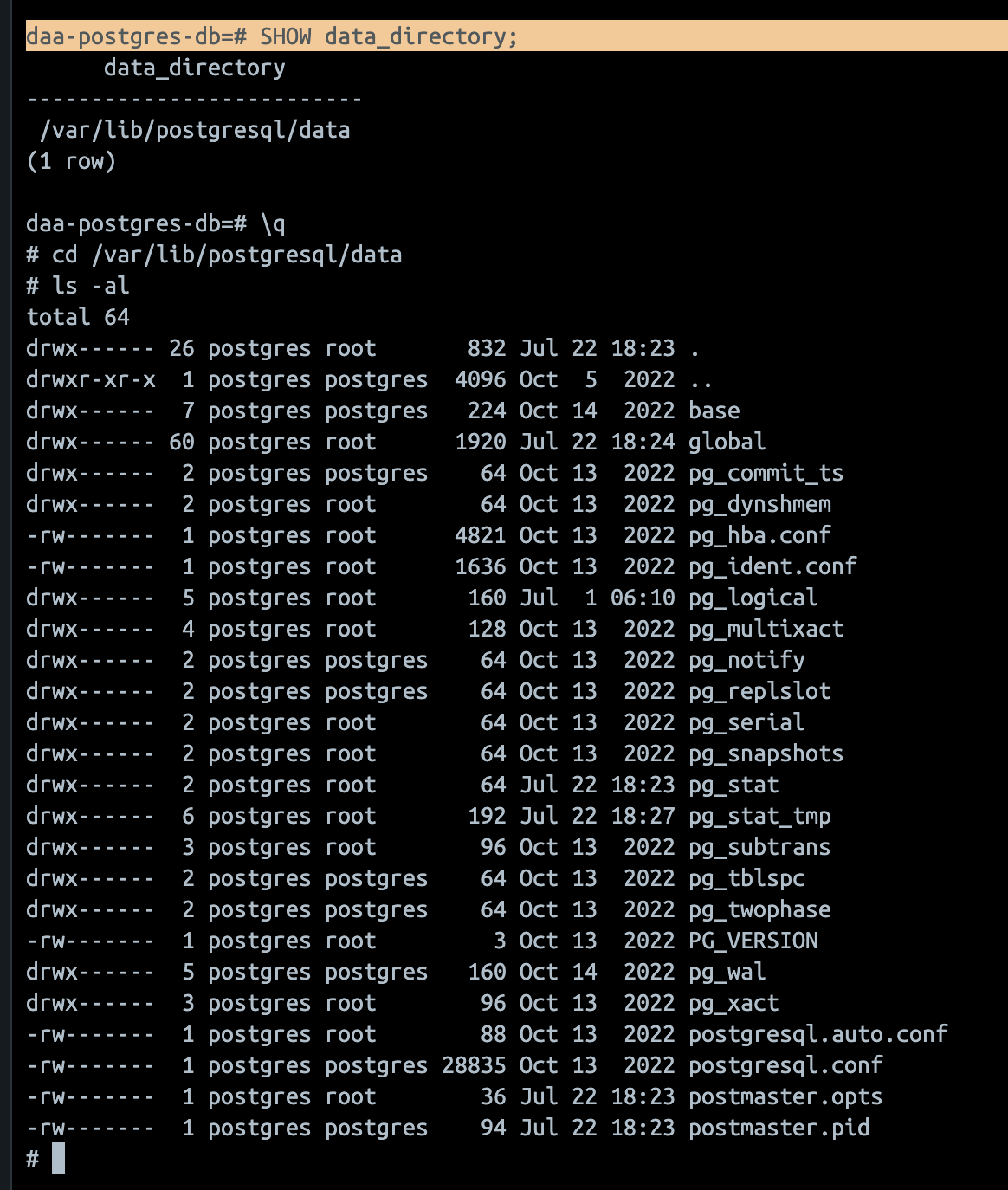
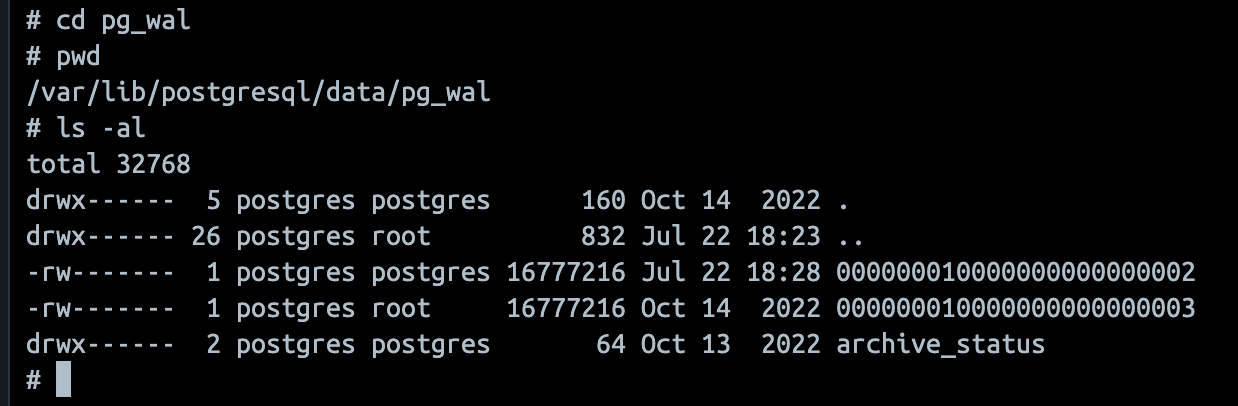
- 위 사진처럼 데이터 디렉토리를 따라가면 wal log file을 볼 수 있고, 파일 이름은 아래와 같은 규칙을 따른다. 자체 규칙이 있으니 출처를 따라가서 꼭 읽어보는 것을 추천한다.
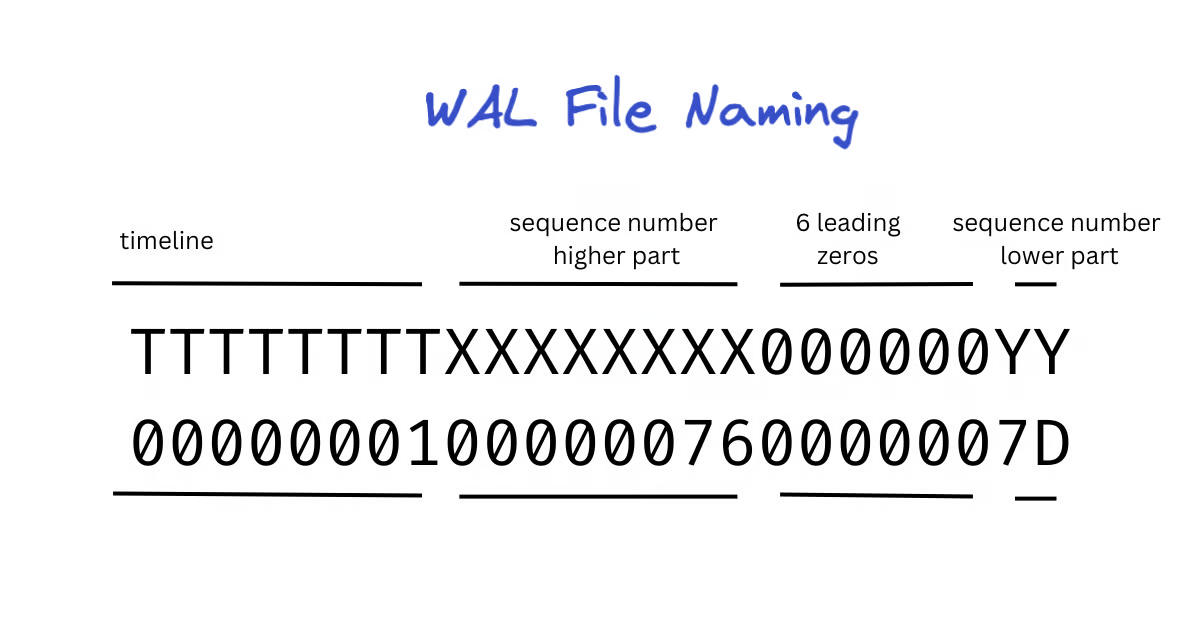
사진 출처: Postgres WAL Files and Sequence Numbers
- 그리고 write ahead 매커니즘은 원리와 내부 메모리 관리 등의 관점에서 깊게 알아야할 충분한 가치가 있다. 시간이 된다면 위 링크된 공식문서 정독과 위 키워드 서치를 꼭 추천한다!
2. Debezium과 Kafka로 Psql CDC 구축하기
Streaming Database Changes with Debezium by Gunnar Morling - Debezium에 대한 설명이 가득담긴 youtube 이며, official session이다.
1) Debezium과 Kafka connect
-
Debezium은 오픈 소스 분산 플랫폼으로, 데이터베이스의 변경 데이터 캡처 (Change Data Capture, CDC)를 위해 설계되었다! 기본적으로 DBMS의 transaction log를 읽고 다른 시스템 (이기종)에 스트리밍 한다.
-
이름은 여러 데이터베이스의 약어와 같은 "DB" 와 주기율표의 많은 요소 이름에 사용되는 "-ium" 접미사 의 조합이다.
-
기본적으로 Kafka와 Kafka Connect API를 기반으로 작동한다. Kafka connect는 카프카용 데이터 통합 프레임워크이다. Kafka connector에는 Source connector 와 Sink connector 가 있다. 간단히 말하면 Source Connector는 Producer의 역할, Sink connector는 Consumer 역할을 한다.
Connect: "Connector"를 동작하게 하는 processSource Connector: 외부시스템 -> connect -> kafkaSink Connector: kafka -> connect -> 외부 시스템
-
Connect는 "단일 모드(Standalone)" 와 "분산 모드(Distributed)" 로 이루어져있다. 단일 모드는 connect를 하나만 사용하는 반면, 분산 모드는 여러개의 connect를 한개의 cluster로 구성해 사용하는 모드로, "고가용성 보장"을 위해 사용한다.
-
즉 Debezium은 카프카 커넥터의 집합이다! docker 환경 구성을 위해 Debezium 공식 docker image 를 활용한다.
-
Debezium은 다양한 커넥터들을 제공한다. Debezium의 목표는 다양한 DBMS의 변경 사항을 캡쳐하고 유사한 구조의 변경 이벤트를 produce 하는 커넥터 라이브러리를 구축하는 것이다. 현재는 MongoDB, MySQL, PostgreSQL, SQL Server, Oracle, Db2, Cassandra 등을 지원한다.
-
커넥터와 고가용성에 대한 내용은 CDC & CDC Sink Platform 개발 1편 - CDC Platform 개발 글로 대체한다.
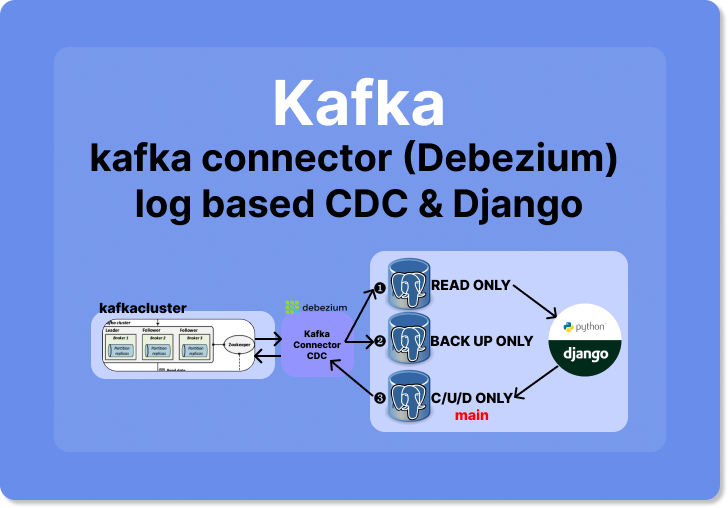
그래서 최종 결과물은?
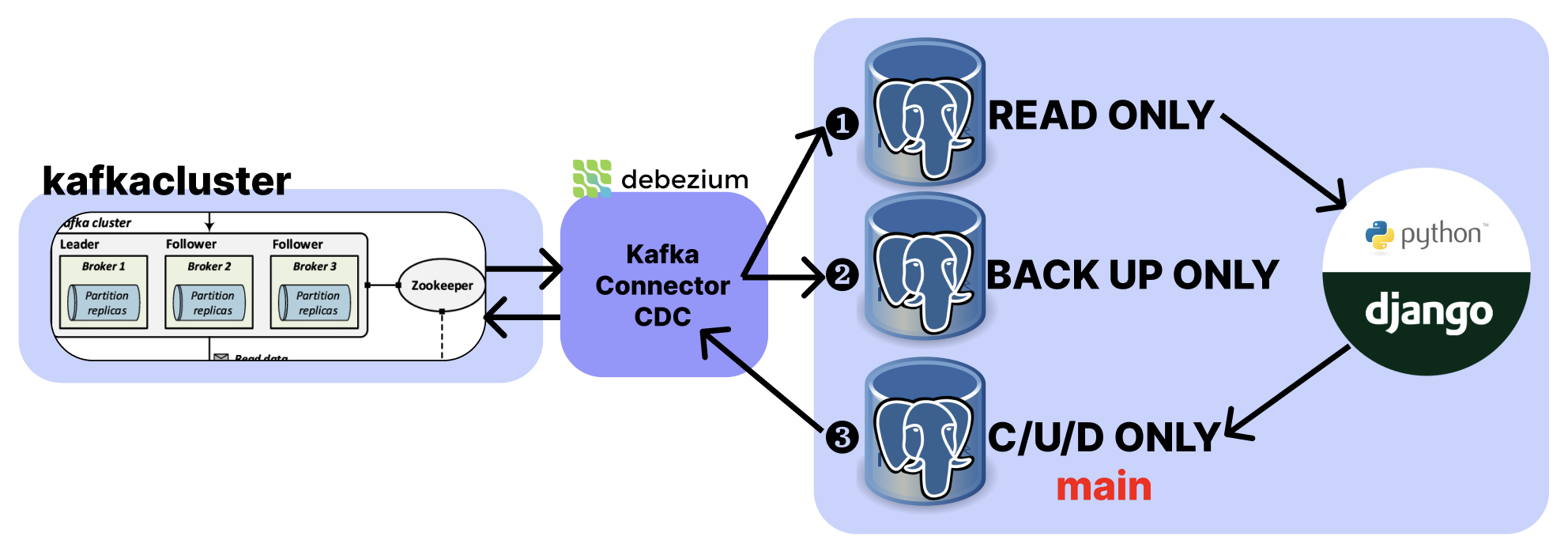
-
다른 3개의 postgresql 서버에 DB Replication을 할 것이다. 그리고 django의 DB routing 을 통해서 ❶
READ ONLY& ❸C/U/D ONLY를 분리할 것이다. ❷ DB 는 백업본 전용 추가 DB Replication 이다. -
여기서 잊지말아야 할 점은, 특별한 트랜잭션은 ❸
C/U/D ONLY대상으로 일어나야 CDC가 catch를 해서 ❶, ❷ 에게 전달한다. 즉 ❸ 번이 main DB 가 되어야 한다. django application에서 db routing 할 때 꼭 명심해야 하는 부분이다! -
참고로 duplication이 목적이라면 postgresql이 자체적으로 제공하는 "스트리밍 복제" 기능을 활용하면 된다. 여기서는 이 기능을 사용하지 않고 debezium으로 duplication set을 구성함과 동시에 log-based CDC에 대해 알아보는게 목표다!
2) Debezium docker compose 세팅
🔥 우선 등장하게 될 예제는 https://github.com/Nuung/django-all-about 레포 기준으로 진행합니다.
(1) 우선 psql 3대와 이전 글 레포에서 세팅한 compose file에 debezium/connect 추가 세팅!
- 위 깃허브 레포
docker/docker-compose.yml참조
...생략
# ========================================================
# Databases - postgresql
# ========================================================
# main - select only
daa-postgres:
image: postgres:latest
hostname: daa-postgres
container_name: daa-postgres
restart: always
ports:
- "5432:5432"
environment:
POSTGRES_USER: "nuung"
POSTGRES_PASSWORD: daa123!
POSTGRES_DB: daa-postgres-db
volumes:
- ../postgresql/data/:/var/lib/postgresql/data
networks:
- django-all-about-app
# sub - insert & update & delete only
daa-postgres-sub:
image: postgres:latest
hostname: daa-postgres-sub
container_name: daa-postgres-sub
restart: always
ports:
- "5433:5432"
environment:
POSTGRES_USER: "nuung"
POSTGRES_PASSWORD: daa123!
POSTGRES_DB: daa-postgres-db
volumes:
- ../postgresql-sub/data/:/var/lib/postgresql/data
networks:
- django-all-about-app
# backup - backup only
daa-postgres-backup:
image: postgres:latest
hostname: daa-postgres-backup
container_name: daa-postgres-backup
restart: always
ports:
- "5434:5432"
environment:
POSTGRES_USER: "nuung"
POSTGRES_PASSWORD: daa123!
POSTGRES_DB: daa-postgres-db
volumes:
- ../postgresql-backup/data/:/var/lib/postgresql/data
networks:
- django-all-about-app
...생략- 위 깃허브 레포
docker/kafka-cluster-compose.yml참조!
...생략
daa-kafka-connect:
image: debezium/connect
hostname: daa-kafka-connect
container_name: daa-kafka-connect
# restart: always
ports:
- "8083:8083"
links:
- daa-kafka1
- daa-kafka2
- daa-kafka3
environment:
- BOOTSTRAP_SERVERS=daa-kafka1:19092,daa-kafka2:19093,daa-kafka3:19094
- GROUP_ID=1
- CONFIG_STORAGE_TOPIC=connect_configs
- OFFSET_STORAGE_TOPIC=connect_offsets
- STATUS_STORAGE_TOPIC=connect_statuses
volumes:
- ../debezium/debezium-config.json:/kafka/connectors/debezium-config.json
networks:
- daa-kafka-cluster-network
...생략GROUP_ID: Kafka Connect 워커가 속한 그룹의 ID 세팅CONFIG_STORAGE_TOPIC: Kafka Connect의 "설정 정보"를 저장할 Kafka 토픽 이름 세팅OFFSET_STORAGE_TOPIC: Kafka Connect의 "오프셋 정보"를 저장할 Kafka 토픽 이름 세팅STATUS_STORAGE_TOPIC: Kafka Connect의 "상태 정보"를 저장할 Kafka 토픽 이름 세팅- 잘 보면 kafka node들과의 통신 port 역시
KAFKA_LISTENERS로 세팅한 19092... 포트로 세팅되어 있다!
2023-07-25 15:10:40,298 INFO || [Worker clientId=connect-1, groupId=1] Cluster ID: OqTG23wdRYibjXCLlhZcUw [org.apache.kafka.clients.Metadata]
2023-07-25 15:10:40,299 INFO || [Worker clientId=connect-1, groupId=1] Discovered group coordinator daa-kafka1:19092 (id: 2147483646 rack: null) [org.apache.kafka.connect.runtime.distributed.W- 위와 같은 로그를 본다면 일단 debezium의 connect 프로세스 (서비스)를 성공적으로 구동한 것이다.
(2) debezium/connect docker 에 shell 붙어보자
docker exec -it 4881fe51c373 /bin/bash와 같이 shell에 붙어서 설치된 plugins들을 체크한다.curl --location --request GET 'localhost:8083/connector-plugins'
[
{
"class": "io.debezium.connector.db2.Db2Connector",
"type": "source",
"version": "2.2.0.Alpha3"
},
{
"class": "io.debezium.connector.mongodb.MongoDbConnector",
"type": "source",
"version": "2.2.0.Alpha3"
},
{
"class": "io.debezium.connector.mysql.MySqlConnector",
"type": "source",
"version": "2.2.0.Alpha3"
},
{
"class": "io.debezium.connector.oracle.OracleConnector",
"type": "source",
"version": "2.2.0.Alpha3"
},
{
"class": "io.debezium.connector.postgresql.PostgresConnector",
"type": "source",
"version": "2.2.0.Alpha3"
},
{
"class": "io.debezium.connector.spanner.SpannerConnector",
"type": "source",
"version": "2.2.0.Alpha3"
},
{
"class": "io.debezium.connector.sqlserver.SqlServerConnector",
"type": "source",
"version": "2.2.0.Alpha3"
},
{
"class": "io.debezium.connector.vitess.VitessConnector",
"type": "source",
"version": "2.2.0.Alpha3"
},
{
"class": "org.apache.kafka.connect.mirror.MirrorCheckpointConnector",
"type": "source",
"version": "3.4.0"
},
{
"class": "org.apache.kafka.connect.mirror.MirrorHeartbeatConnector",
"type": "source",
"version": "3.4.0"
},
{
"class": "org.apache.kafka.connect.mirror.MirrorSourceConnector",
"type": "source",
"version": "3.4.0"
}
]- 원래 On-promise 형태로 직접 설치하면 플러그인을 모두 설치하고 세팅해야 하지만 도커 이미지에 이미 다 세팅이 되어있다. 이제 사용할 기본적인 준비는 다 끝난 것이다.
(3) 중요한건 debezium-config.json 파일에서 정의하고 생성할 "Source Connector" 이다.
debezium-config.json라는 파일에 Source Connector를 정의 했다. 그리고 볼륨으로 잡아줬다. 내용은 아래와 같다! 여러 가지 설정이 혼합되어 있다! 원하는 대로 골라 쓰면 된다.
{
"name": "daa-kafka-debezium-connector", // 커넥터 이름
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector", // 커넥터 클래스
"database.hostname": "host.docker.internal", // PostgreSQL 호스트 주소
"database.port": "5432", // PostgreSQL 포트 번호
"database.user": "nuung", // PostgreSQL 사용자 이름
"database.password": "daa123!", // PostgreSQL 비밀번호
"database.dbname": "daa-postgres-db", // PostgreSQL 데이터베이스 이름
"database.server.name": "daa-postgres-db", // Kafka에 쓰여질 서버 이름
"plugin.name": "pgoutput", // pgoutput 플러그인 활성화, 논리적 복제를 위한 플러그인
"table.whitelist": "*", // 변경 사항을 캡처할 테이블 이름 (all)
"transforms": "unwrap,route",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.route.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.route.regex": "([^.]+)\\.([^.]+)\\.([^.]+)",
"transforms.route.replacement": "$3",
"topic.prefix": "psql_" // 커넥터가 생성하는 Kafka 토픽의 이름 앞에 붙을 접두사 설정
}
}-
host.docker.internal는 같은 host를 공유하고 있을때 유효하므로, 운영할때는 target host를 제대로 명시해주자. target이 다른 host의 docker 내부라면 NAT로 진입하는 앞단 서버로 세팅하자! -
transforms관련 설정들을 그대로 세팅하면,transforms.route.replacement에 의해서 prefix 대신 topic name 자체가 "table 이름" 으로 생성된다. 해당 부분 꼭 유의! -
transforms 관련 설정들은
transforms값을 필두로, CDC가 캡처한 데이터를 가공 또는 라우팅 등을 수행하는 설정 값들이다. 여기 프로젝트에서는 활용하지 않지만 아래와 같이 간략하게 설명만 남겨두려고 한다. transforms 관련 설정 전부 지우고 진행해도 무방하다!
-
"transforms": "unwrap,route"
- unwrap: 커넥터로부터 받은 메시지 중 실제 데이터를 추출하여 사용한다.
- route: 메시지를 특정 토픽에 라우팅하는 역할을 한다. (라우팅을 사용하겠다는 의미)
-
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState"
- unwrap 변환을 구현하는 클래스로, 이 설정은 변경 데이터를 추출하여 메시지에 포함되지 않은 데이터를 가져올 때 사용한다.
- 여기서는 io.debezium.transforms.ExtractNewRecordState 클래스를 사용하여 변경 데이터를 추출한다.
-
"transforms.route.type": "org.apache.kafka.connect.transforms.RegexRouter"
- route 변환을 구현하는 클래스로, 이 설정은 메시지를 특정 토픽으로 라우팅한다.
- 여기서는 org.apache.kafka.connect.transforms.RegexRouter 클래스를 사용하여 정규표현식을 이용하여 토픽을 선택합니다.
-
"transforms.route.regex": "([^.]+)\.([^.]+)\.([^.]+)"
- route 변환에서 사용되는 정규표현식으로, 변경 데이터의 테이블 정보를 추출하여 토픽을 결정하는데 사용된다.
- 이 정규표현식은 세 개의 그룹으로 구성되어 있으며,
database.schema.table형태의 테이블 정보를 추출한다.
-
"transforms.route.replacement": "$3"
- route 변환에서 사용되는 치환 문자열로, 정규표현식에서 추출한 세 번째 그룹인 table 정보를 사용하여 토픽 이름을 결정한다.
- 여기서는 $3을 사용하여 세 번째 그룹인 table 정보를 토픽 이름으로 사용하게 된다.
- 참고로 docker 볼륨 잡아준다고 해서 바로 해당 파일을 인식하는 것이 아니다. (방법은 있지만), 위에서 plugin을 확인 한 것과 같이, 위 내용을 바탕으로 "8083"에 rest API 를 call 해야한다.
POSTmethod로end-point는/connectors이다.
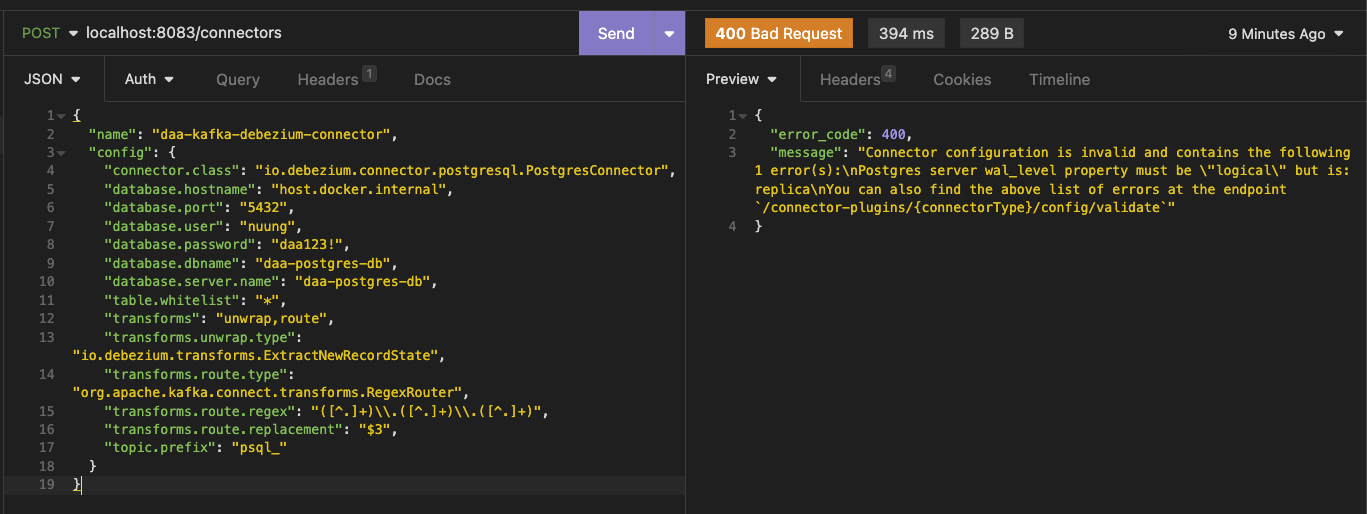
{
"error_code": 400,
"message": "Connector configuration is invalid and contains the following 1 error(s):\nPostgres server wal_level property must be \"logical\" but is: replica\nYou can also find the above list of errors at the endpoint `/connector-plugins/{connectorType}/config/validate`"
}- 하지만 바로하면 안된다. 바로 DBMS에서 또 세팅해줄게 있기 때문이다!
3) psql 세팅 & Source Connector 생성
-
추가 세팅한 3대의 psql은 모두 볼륨이 -
../postgresql/data/:/var/lib/postgresql/data와 같은 형태로 세팅되어 있고, 우리가 수정해야 할postgresql.conf여기에 있다. 위 docker 세팅이 모두 동일하다면,postgresql/data,postgresql-sub/data,postgresql-backup/data에서 conf file을 찾을 수 있다. -
다시 위 그림을 잠시 보고 오면, "3번" DB가
INSERT,UPDATE,DELETE의 DML 이 일어나는 main DB 이다. 그러면 wal file을 가져와야 할 주체는? 3번 DB가 되어야 하는 것이다. -
나의 도커 세팅 중심으로,
postgresql/data하위의postgresql.conf를 수정해야 한다.
(1) main wal file이 생기는 DB의 conf 수정하기
-
wal_level = logical: CDC를 위해 wal_level을 logical로 변경해야 한다. wal_level은 Write-Ahead Logging(WAL)에 어떤 정보를 기록할지를 결정하는 설정이다. logical 값은 논리적 복제를 위해 변경 사항을 캡처하는 데 필요한 설정 이다. -
max_wal_senders = 10,max_replication_slots = 10: 이 값들은 데이터베이스에 연결되는 클라이언트 수와 복제 슬롯의 최대 개수를 세팅한다. sender는 WAL 발신자가 WAL을 수신자로 보내기 위해 데이터베이스에서 실행되는 프로세스이다. -
max_logical_replication_workers = 4: wal_level이 logical인 경우 max_logical_replication_workers를 설정해야 한다. 이 값은 "논리적 복제 작업자(worker)의 최대 개수"를 세팅한다. -
hot_standby = on: CDC를 위해 hot_standby를 on으로 변경해야 한다. 이 설정은 "원격 스탠바이 서버가 로그 스트리밍을 사용하여 데이터를 읽을 수 있도록" 해준다.
- 그리고 main psql을 restart 해주자!
(2) connector server에 다시 API call
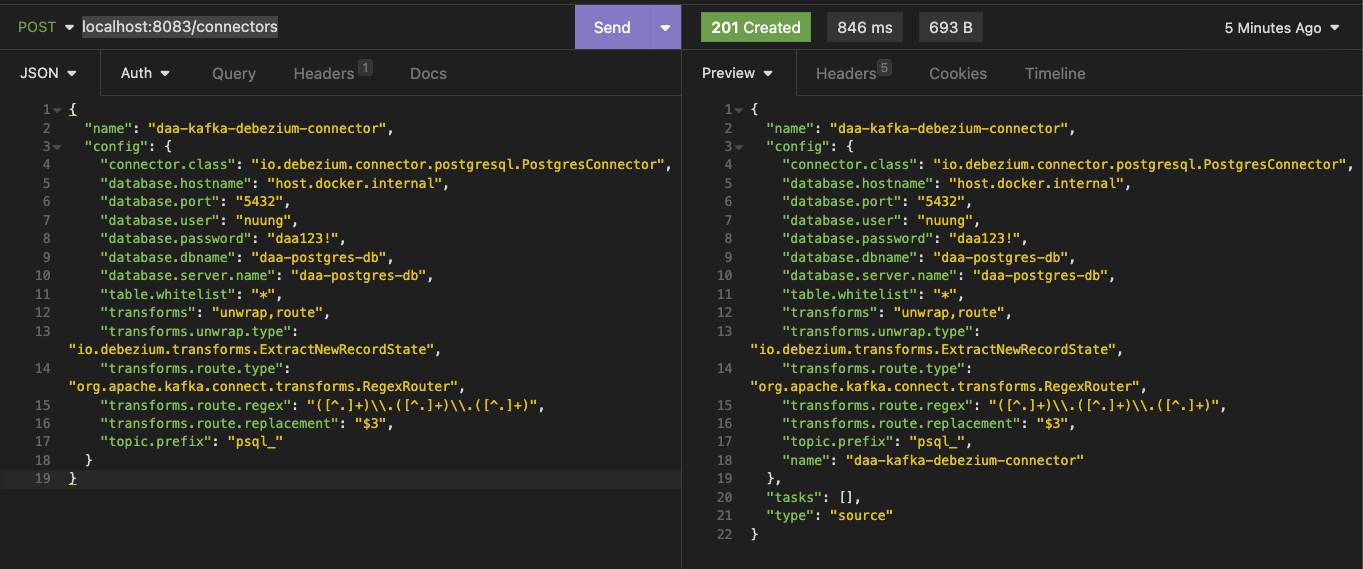
- 위 호출에 성공하면 psql의 log에
2023-07-25 16:03:16.791 UTC [38] STATEMENT: CREATE_REPLICATION_SLOT "debezium" LOGICAL decoderbufs라고 찍힌다! 동시에 debezium은 아래와 같은 log가 찍힌다.
2023-07-25 16:03:15,896 INFO || 192.168.112.1 - - [25/Jul/2023:16:03:15 +0000] "POST /connectors HTTP/1.1" 201 693 "-" "insomnia/2023.4.0" 820 [org.apache.kafka.connect.runtime.rest.RestServer]
2023-07-25 16:03:15,900 INFO || Creating connector daa-kafka-debezium-connector of type io.debezium.connector.postgresql.PostgresConnector [org.apache.kafka.connect.runtime.Worker]
2023-07-25 16:03:15,901 INFO || SourceConnectorConfig values:
config.action.reload = restart
connector.class =
(...생략...)
2023-07-25 16:03:15,921 INFO || Instantiated connector daa-kafka-debezium-connector with version 2.2.0.Alpha3 of type class io.debezium.connector.postgresql.PostgresConnector [org.apache.kafka.connect.runtime.Worker]
2023-07-25 16:03:15,922 INFO || Finished creating connector daa-kafka-debezium-connector [org.apache.kafka.connect.runtime.Worker]- 그리고
/connectors로 GET request 던지면 아래와 같이 등록되어 있음을 확인할 수 있다.
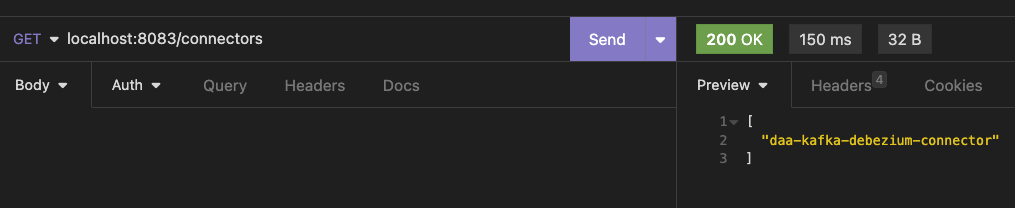
- 이 name을 다시 GET request (
/connectors/daa-kafka-debezium-connector) 를 던지면 아래와 같은 응답을 받을 수 있다. 참고로DELETE로 던지면 해당 connector 삭제해 준다!
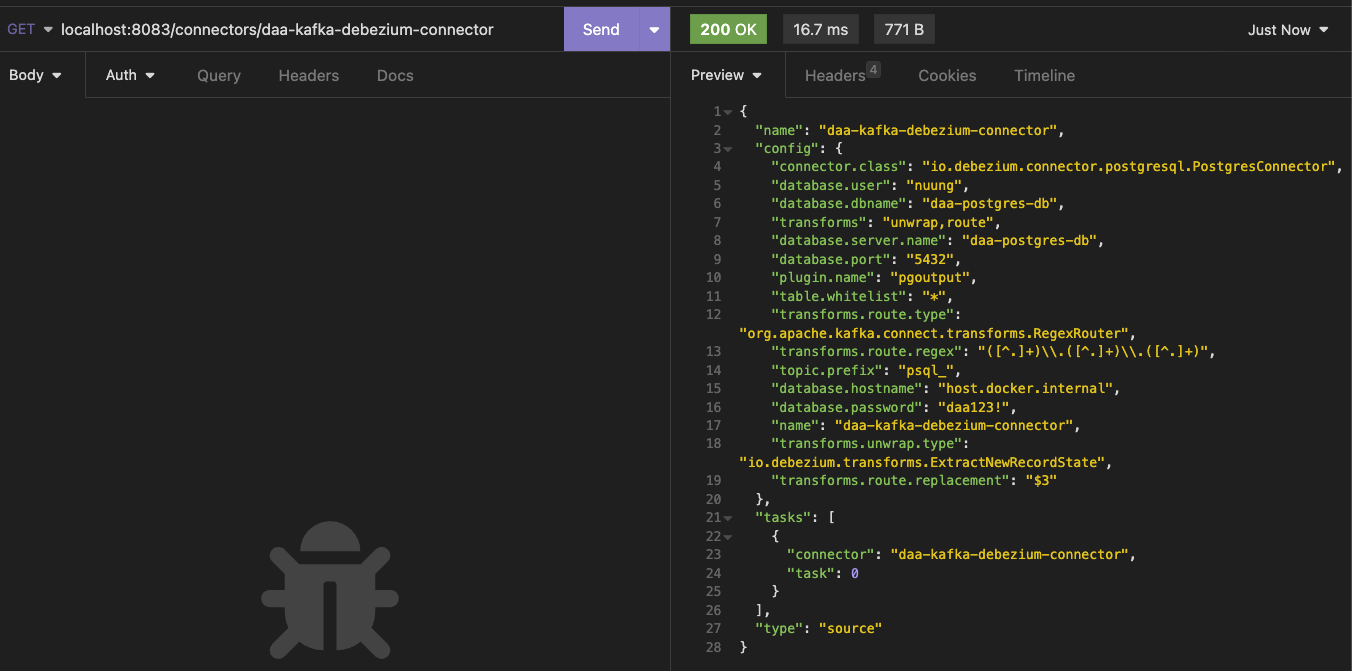
- 이제 CDC source 가 되는 db에 붙어서 아무거나 수정해보자! 그러면 debezium container log가 아래와 같이 시작된다!
2023-07-25 16:37:56,820 INFO || 1 records sent during previous 00:00:30.062, last recorded offset of {server=psql_} partition is {transaction_id=null, lsn_proc=39171600, messageType=UPDATE, lsn_commit=39171544, lsn=39171600, txId=3477, ts_usec=1690303076245611} [io.debezium.connector.common.BaseSourceTask]- 이전에 세팅한 kafka-manager와 같이 체크하면 비쥬얼적으로 더 제대로 확인할 수 있다.
4) python으로 CDC event consuming 해보기
레포 기준으로 debezium > cdc_test.py 참조
- 위 구성으로 CDC 구성과 event producing (by debezium connector) 세팅은 완료되었다. 고로 kafka로 target topic을 직접 consuming 하면 그 event를 가져와서 활용할 수 있는 것이다! (
kafka-python모듈을 활용했다)
from kafka import KafkaConsumer, KafkaAdminClient
from kafka.errors import TopicAuthorizationFailedError
class KafkaCon:
def __init__(self, brokers: list) -> None:
self.brokers = brokers
self.admin_client = KafkaAdminClient(bootstrap_servers=brokers)
def find_topics_with_prefix(self, prefix: str = None) -> list:
"""prefix로 시작하는 토픽을 찾습니다."""
topic_metadata = self.admin_client.list_topics()
if not prefix:
return topic_metadata
topics_with_prefix = []
for topic in topic_metadata:
if topic.startswith(prefix):
topics_with_prefix.append(topic)
return topics_with_prefix
def get_topic_metadata(self, topic: str):
"""토픽의 메타데이터 조회를 위한 함수를 정의합니다."""
try:
topic_metadata = self.admin_client.describe_topics([topic])
return topic_metadata
except TopicAuthorizationFailedError:
print(
f"Topic '{topic}' does not exist or you don't have permission to access it."
)
return None
class MessageConsumer(KafkaCon):
def __init__(self, brokers, topic: str) -> None:
super().__init__(brokers)
self.consumer = KafkaConsumer(
topic, # Topic to consume
bootstrap_servers=self.brokers,
value_deserializer=lambda x: x.decode(
"utf-8"
), # Decode message value as utf-8
group_id="psql-cdc", # Consumer group ID
auto_offset_reset="earliest", # Start consuming from earliest available message
enable_auto_commit=True, # Commit offsets automatically
)
def receive_message(self, pattern: str = None):
if pattern:
self.consumer.subscribe(pattern=pattern)
try:
for message in self.consumer:
print(message)
except Exception as exc:
raise exc
# 브로커와 토픽명을 지정한다.
brokers = ["localhost:9092", "localhost:9093", "localhost:9094"]
topic = "test_checkedcrn"
cs = MessageConsumer(brokers, topic)
print(cs.find_topics_with_prefix())
print(cs.get_topic_metadata(topic))
cs.receive_message()
-
간단하게
test_checkedcrn라는 table을 수정할 것이기에 topic으로 잡고, consumer는 kafka manager를 활용해 더 체크하기 위해 group을 줬다. -
전체 토픽 리스트를 살펴보고, target topic의 meta data를 가져온 뒤에 consuming을 시작한다. 바로 시작하면 아래와 같다.
> python cdc_test.py
['connect_offsets', 'test_checkedcrn', 'test_post', 'connect_statuses', 'auth_permission', 'django_migrations', '__consumer_offsets', 'django_content_type', 'django_celery_beat_crontabschedule', 'test_cart', 'my-topic', 'django_admin_log', 'django_celery_beat_periodictasks', 'token_blacklist_outstandingtoken', 'test_product', 'user_user', 'products_itemcategory', 'django_session', 'connect_configs', 'django_celery_beat_periodictask']
[{'error_code': 0, 'topic': 'test_checkedcrn', 'is_internal': False, 'partitions': [{'error_code': 0, 'partition': 0, 'leader': 1, 'replicas': [1], 'isr': [1], 'offline_replicas': []}]}]- 이때
test_checkedcrntable을 바로 수정하면 아래와 같이 메시지를 받을 수 있다.
ConsumerRecord(topic='test_checkedcrn', partition=0, offset=150,
timestamp=1690394357069, timestamp_type=0,
key=b'{"schema":{"type":"struct","fields":[{"type":"int64","optional":false,"default":0,"field":"id"}],
"optional":false,"name":"psql_.public.test_checkedcrn.Key"},
"payload":{"id":564}}', value='{"schema":{"type":"struct","fields":
[{"type":"int64","optional":false,"default":0,"field":"id"},
{"type":"string","optional":false,"field":"registration_number"},
{"type":"boolean","optional":false,"field":"is_closed"},
{"type":"string","optional":false,"name":"io.debezium.time.ZonedTimestamp","version":1,"field":"created_at"},
{"type":"string","optional":false,"name":"io.debezium.time.ZonedTimestamp","version":1,"field":"updated_at"}],
"optional":false,"name":"psql_.public.test_checkedcrn.Value"},"payload":
{"id":564,"registration_number":"6457907588","is_closed":false,"created_at":"2023-03-06T17:19:54.570055Z",
"updated_at":"2023-03-06T17:19:54.570081Z"}}', headers=[],
checksum=None, serialized_key_size=178, serialized_value_size=658,
serialized_header_size=-1)-
table의 schema 정보와 더불어 바뀐뒤의 데이터셋도 전달이되는 모습을 볼 수 있다. 이를 통해 이기종의 DB에 밀어넣을 수 있고, cosuming과 특정 event을 연결해서 CDC를 활용한 이벤트를 만들 수 있다.
-
우아한 기술 블로그 - CDC 너두 할 수 있어(feat. B2B 알림 서비스에 Kafka CDC 적용하기) 역시 이런 환경으로 CDC를 바탕으로 B2B 알림 서비스를 구축했다.
5) psql 세팅 & Sink Connector 생성
가장 삽질을 많이 한 부분,, sink connector에 대한 혼재된 정보가 너무너무 많다. 특히 docker image를 kafka는 "wurstmeister" 거에 connector는 "debezium/connect"를 base로 하다 보니 confluent와 너무 docs와 guide가 혼제되어 있다.
이럴 때일수록 본질을 잘 알아야 하는 것이구나..🥹🥲😭
-
이제 main DB 대상으로 Source Connector (
daa-kafka-debezium-connector) 까지 세팅을 완료 했으니, wal file 기반으로 kafka에게 해당하는 topic으로 계속 producing을 할 것이다. -
이 topic을 consuming 해서 SELECT 전용 DB와 BACK-UP 전용 DB에게 duplication을 하도록 해야한다! 여기서도 동일하게 debezium을 활용해 위에서 언급한 "consuming 전용, sink connector 를 구성해 보자!
🔥 일단 sink connector를 생성하기 전, 아래 사항을 꼭 체크!
-
docker compose에 추가된
daa-kafka-connectservice 볼륨 추가와 해당 볼륨으로 잡아줄 pulgin jar 파일 설치가 필요!! -
sink connector는 topic과 내용에 대해서 민감하게 작용하기 때문에, 특히 transform 세팅을 했었다면! source connector 부터 새로 세팅하는 것을 추천!!
(1) Debezium connector for JDBC
-
sink connector는 기본적으로 jdbc 기반으로 된 것을 사용한다. Debezium 공식문서 에서 custom으로 만들어 둔 sink jdbc plugin을 꼭 다운로드 받아야 한다.
-
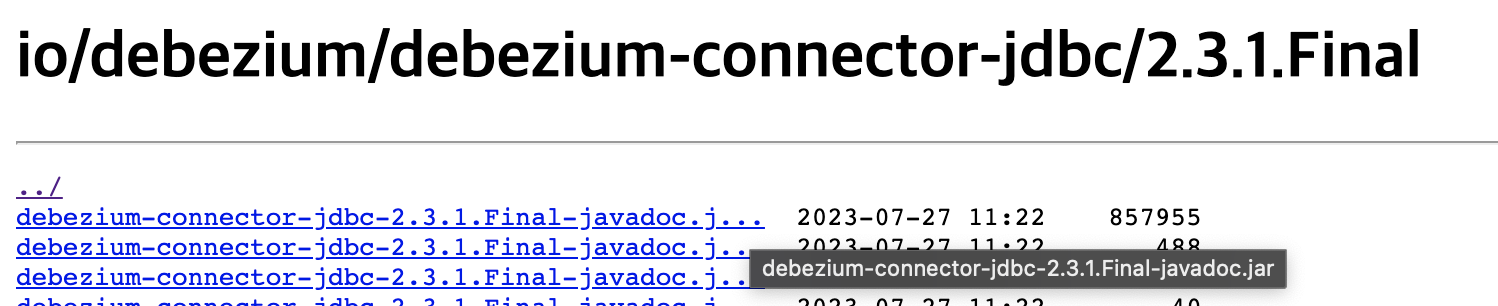
여기 링크 에는 debezium 공식 plugin이 list up 되어있다. 그 중
debezium-connector-jdbc>debezium-connector-jdbc-2.3.1.Final-plugin.tar.gz를 사용했으며, 이는 본인에게 맞는 것으로 고르면 될 듯 하다. (버전 체크 필요)
(2) docker compose file 수정
- 위 jar잡아준 plugin을 이제
daa-kafka-connect서비스 (debezium/connect이미지) 에게 밀어넣어줘야 한다.
...생략
daa-kafka-connect:
image: debezium/connect
hostname: daa-kafka-connect
container_name: daa-kafka-connect
# restart: always
ports:
- "8083:8083"
links:
- daa-kafka1
- daa-kafka2
- daa-kafka3
environment:
- BOOTSTRAP_SERVERS=daa-kafka1:19092,daa-kafka2:19093,daa-kafka3:19094
- GROUP_ID=1
- CONFIG_STORAGE_TOPIC=connect_configs
- OFFSET_STORAGE_TOPIC=connect_offsets
- STATUS_STORAGE_TOPIC=connect_statuses
- CONNECT_PLUGIN_PATH=/kafka/connect
volumes:
- ../debezium/debezium-config.json:/kafka/connectors/debezium-config.json
- ../debezium/debezium-connector-jdbc:/kafka/connect/debezium-connector-jdbc
networks:
- daa-kafka-cluster-network
...생략-
여기서 꼭 주의할 부분이 "CONNECT_PLUGIN_PATH" 이다. docker 내부에서 custom pulgin을 위해 jar추가해 줄 때, (여러가지 방법이 있지만) 보통 volume을 잡을 것이다.
-
하지만 기본 connector plugin을 제외하면 안된다. 즉 기본 plugin 경로를 찾아야 하는 것이다. 경로를 찾기 위해 환경 변수 default 값이 있겠거나 해서 체크해 봤지만 비어있었다. (아래사진)
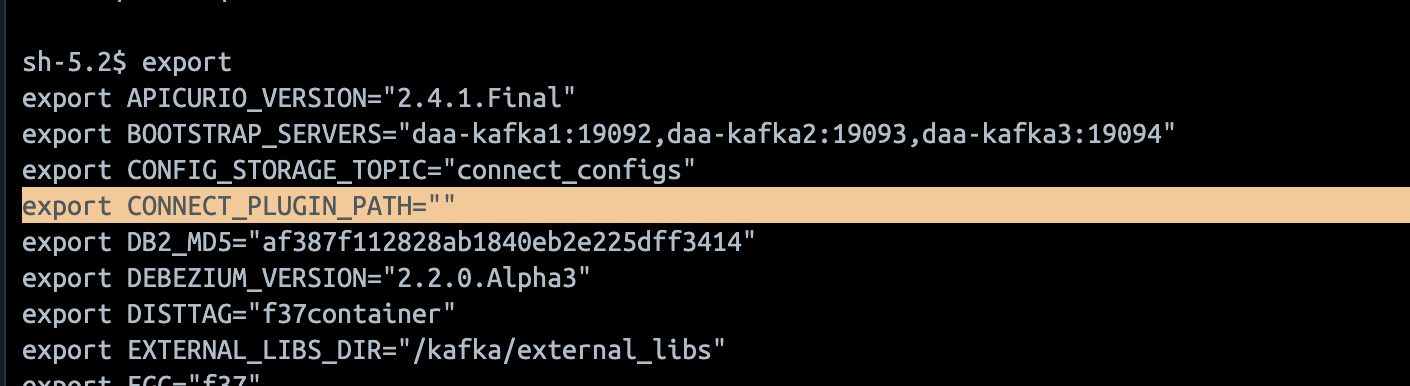
-
그래서
find로 jar file tracking을 해봤는데,/kafka/connect로 잡혀있었다. 그리고 어떤 jar 묶음인지 디렉토리들로 구성되어 있었다. 그래서/kafka/connect/debezium-connector-jdbc로 컨테이너 내부 경로로 볼륨을 잡아주었다. -
그래서 기본 위치 "하위에 볼륨을 잡되", 환경 변수 줄때는 기본 위치로 잡아주어야 한다.
-
ClassNotFoundException: io.debezium.util.IoUtil또는java.lang.NoClassDefFoundError: io/debezium/util/IoUtil를 마주한다면 꼭 해당 설정 값을 체크해보자!
(3) source 다시 만들기 & sink 구성하기!
-
일단 기존에 source connector를 만들고 다양하게 테스트를 했다면, consuming 테스트도 진행했다면, source 도 다시 만드는 것을 추천한다. 특히 transform 세팅을 했었다면 말이다.
-
그리고 sink가 될 target DBMS의 DB는 말끔하게 비운 상태로, docker 환경이 동일하다면 그냥 볼륨 잡힌 data 다 날리고, 진행하는 것을 추천한다.
// 아래는 source, 아주 기본적인 설정값들만 살렸다.
{
"name": "daa-kafka-debezium-connector-test",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "host.docker.internal",
"database.port": "5432",
"database.user": "nuung",
"database.password": "daa123!",
"database.dbname": "daa-postgres-db",
"database.server.name": "daa-postgres-db",
"plugin.name": "pgoutput",
"table.whitelist": "*",
"topic.prefix": "psql"
}
}
// 아래가 sink
{
"name": "daa-kafka-debezium-sink-conn-1",
"config": {
"connector.class": "io.debezium.connector.jdbc.JdbcSinkConnector",
"connection.url": "jdbc:postgresql://host.docker.internal:5433/daa-postgres-db",
"connection.username": "nuung",
"connection.password": "daa123!",
"topics.regex": "psql.*",
"auto.create": "true",
"insert.mode": "upsert",
"delete.enabled": "true",
"primary.key.mode": "record_key",
"schema.evolution": "basic",
"transforms": "unwrap,route",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.route.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.route.regex": "([^.]+)\\.([^.]+)\\.([^.]+)",
"transforms.route.replacement": "$3"
}
}-
host.docker.internal에 대한 얘기는 위에서 최초로 source connector 만들때 설명과 동일하다. -
기본 설정에 source에
전체 테이블 + prefix(psql)세팅을 해두었다. 그리고 따로 schema 설정을 안하면, psql 기준<topic-prefix>.<schema>.<table-name>로 topic이 만들어진다. -
그대로 sink connector가 소비하면, table이름이 그대로
topic-prefix.schema.table-name로 저장된다.
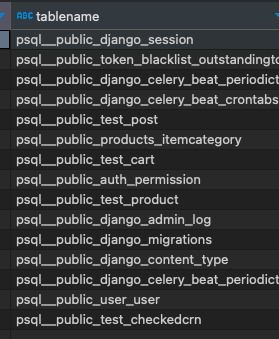
- 그래서
transforms과route세팅이 필요하며, 가장 뒤table-name만 가져오도록 세팅했다. sink connector를 만들면 다음과 같은Marking processed record for...log가 찍히며 전체 테이블 데이터가 동기화 된다.
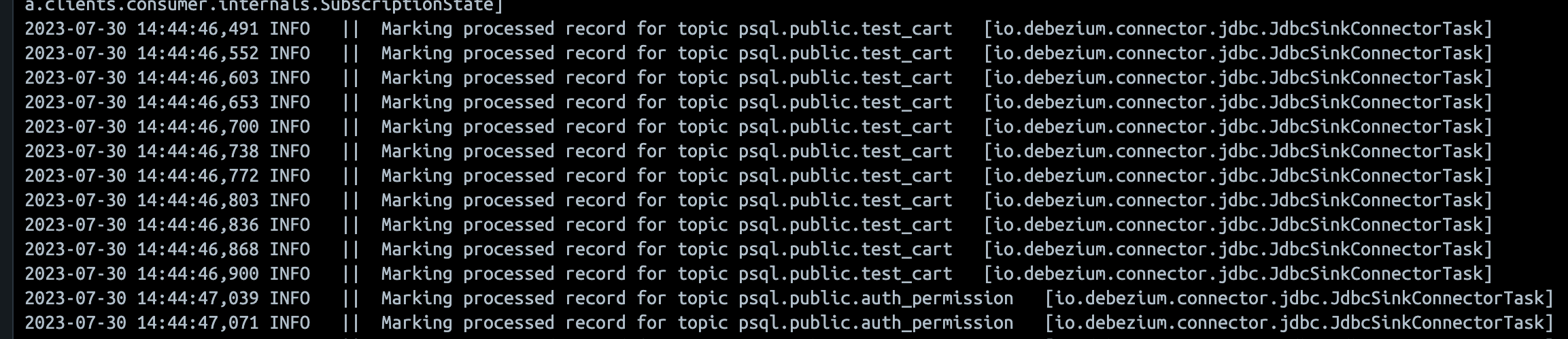
- 참고로 레코드(행) 개수가 0인 table은 바로 동기화가 안되며, sink를
"auto.create": "true"로 세팅했기 때문에 데이터가 하나라도 insert 되면 바로 table 동기화와 데이터밀어넣기가 동기화 된다.
SELECT *
FROM pg_catalog.pg_tables
WHERE schemaname != 'pg_catalog'
AND schemaname != 'information_schema';-
sub db로 위 sql을 던져보고 table 동기화가 잘 되었는지 체크하자. 만약 DBMS에 붙을때 (user or 권한 관련 issue) connection 이슈가 있다면 볼륨으로
잡힌 경로 > data > pg_hba.conf에host all all all scram-sha-256를 추가해주자. 이 세팅은 DBMS에서 같은 network 환경 외 외부 환경 접근 시 host 접근 권한에 대한 설정이다. pg_hba.conf 설정하기 -
그리고 위 sink 설정 그대로, port만 변경해서 backup DB을 target으로 하는 sink connector를 추가하면 또 역시 그대로 동기화 해준다. 총 3개의 connector, 아래 사진과 같이 구성이 완료되었다!

-
이제 main DB를 대상으로 C/R/U/D testing을 해보면 기가막히게 동기화되는 것을 확인할 수 있을 것이다 :)
-
debezium의 source 또는 sink connector(이하 프로세스/워커)는 다 개별 "오프셋 값(토픽 어디까지 읽었는지)" 을 가지고 있다. 즉 source를 추가해도 topic이 유실되지 (너무 오래되어서 예전 데이터를 아예 삭제한다던지 등) 않았다면, 해당 source는 "offset이 0인" 상태이므로 자동적으로 모두 topic을 만들어서 구성한다.
-
이는 sink 역시 동일하다. 그래서 (그림기준) 3번 DB를 통해 만들어진 topic을 consuming하는 1번 전용 sink connector를 만들고 나서 2번 전용 sink connector를 만들때도 역시 동일하게 offset 0부터 동기화 시작하기 때문에 모두 똑같이 동기화가 되는 것이다!
6) Django application
- 이제 모든 준비는 끝났다. (사실 여기까지 오는데에 몇 주간의 삽질을,, 🥹) 3대의 DB가 SELECT 전용, I/U/D 전용 (main), BACK-UP 전용으로 이기종 서버 형태로 구성되었다. 이제 django application에서도 적용시켜보자!
(1) DB routing 세팅
- django는 config(settings)에서
DATABASE_ROUTERS를 세팅할 수 있다. 그리고 여러개를 말이다.
DATABASE_ROUTERS = [
"config.order_dbrouter.MultiDBRouter",
"config.dbrouter.MultiDBRouter",
]-
기존에 특정 테이블만 따로 다른 DB에 저장하기 위해
order_dbrouter가 있었으며Model의app_label값이orders라면 MAIN DB의 다른 DB를 사용하도록 세팅하였다. (단일 DBMS의 다중 DB활용) -
여기에 추가할 부분은 "SELECT" 만 똑 떼어내서 SUB DB로 보내는 것 이다. 위 설정에서
config.dbrouter.MultiDBRouter부분을 세팅해줄 파일을 아래와 같이 만들자
# dbrouter.py
class MultiDBRouter:
"""
A router to control all database operations on models in the
auth and contenttypes applications.
"""
def db_for_read(self, model, **hints):
"""
Attempts to read auth and contenttypes models go to orders.
"""
return "read"- 구현을 하지 않은 부분은 자동으로 return None이 되며, 역시 default DB로 가도록 세팅 된다.
(2) 결과 & 테스트
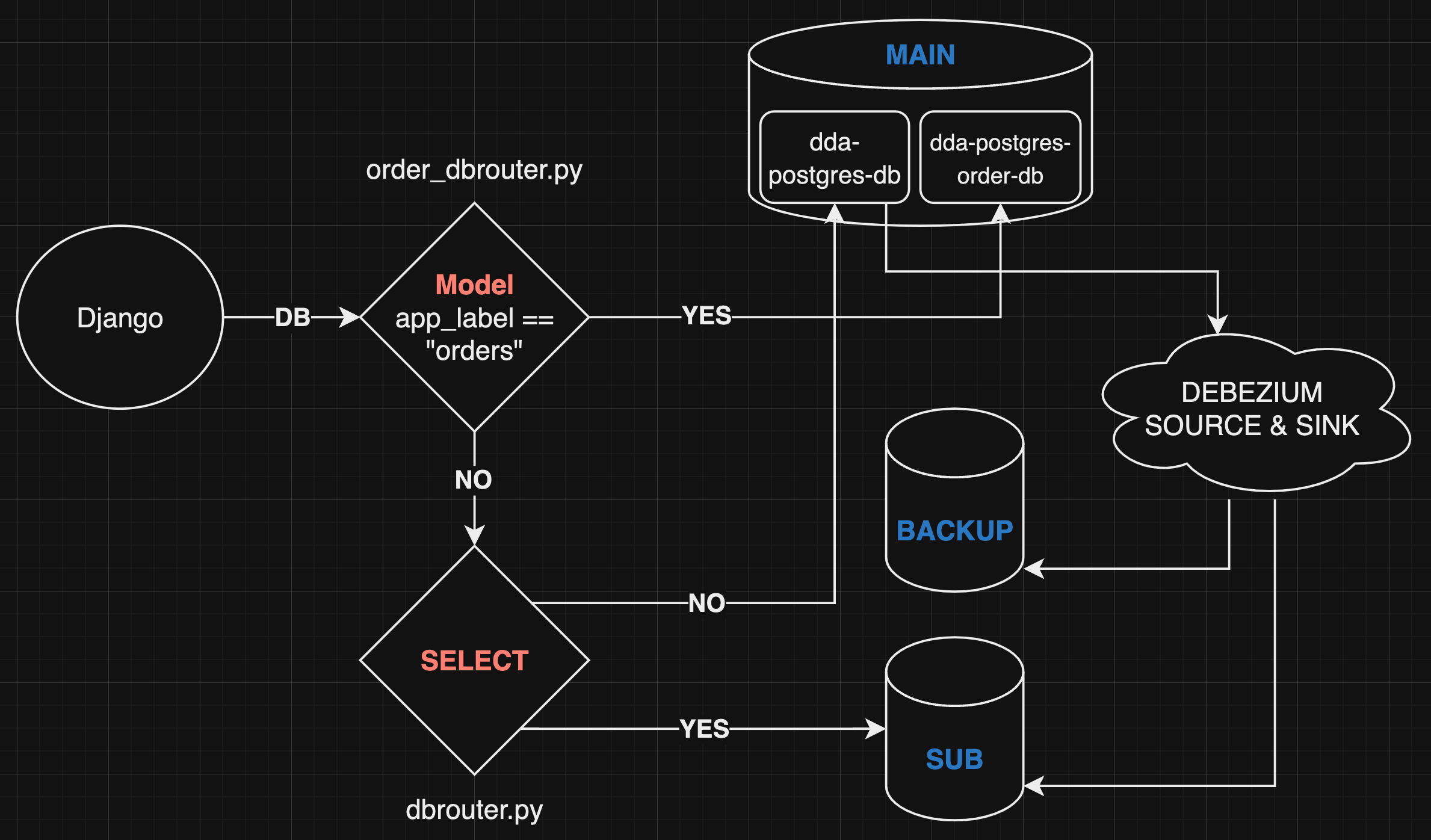
-
우리가 위와 같이 세팅하면 django application에서는 위와 같이 ORM - model 부터 select query 날리기까지 flow가 추가된다.
-
하지만 꼭 주의할 점이 있다. "auto.create" 설정을 주어도 비어있는 테이블을 동기화 하지 않는다. 하지만 django level에서 데이터가 비어있어도 join을 던지는 query가 굉장히 빈번하다. (특히 모듈 / 라이브러리 등에 의해 추가되는 table들) 이 경우 아래 사진과 같이
ProgrammingError가 뜰것이다.

- 그래서 불편하지만,, 이런 테이블들은 최초 설정시 create는 자동으로 해주는 것이 좋다. 아니면 편법으로 비어있는 테이블 발견할 때 마다, 비어있는 값 insert 이후 delete 하는 것도 추천한다.
마무리 & 출처
kafka connector를 기반으로 하는 connector plugin 집합인 debezium 을 활용해서 DB 3대를 source & sink connector로 동기화 세팅을 했다. 그리고 django DB Router를 활용해
SELECT only&Other로 구분해 select의 부하를 (전체 DB 관점에서) 압도적으로 줄일 수 있었다.
-
하지만 여기서 다루지 못한것은 debezium은 기본적으로 connector들을 "distributed" 작업으로 구성할 수 있게 한다. task 개수를 조절하고 분산 세팅은 다른 글들로 대체한다.
-
아쉬운 부분은 비어있는 table에 대한 duplication을 마무리 못한 부분이다. debezium docs & 구글링으로는 설정값에 대한 부분을 찾지 못했다..
-
하지만 default 와 sub & back DBMS의
daa-postgres-dbDB 에 존재하는 table 차이를 체크하고, default로 부터 table을 가져와서 create를 해주는 script 또는 python code를 만들면 해결할 수 있을 것이라고 생각한다.
출처
- Kafka official docs - connect
- 네이버 엔지니어링 - 막힌 데이터의 혈을 뚫자! Pay 플랫폼 CDC 적용 사례
- https://www.mssqltips.com/sqlservertutorial/3301/introduction-to-the-sql-server-transaction-log-tutorial/
- https://www.crunchydata.com/blog/postgres-wal-files-and-sequuence-numbers
- Debezium official docs
- Debezium official docs - postgresql
- Debezium official docs - jdbc sink connector - sink DB를 사용할 예정이라면 해당 docs를 꼭 확인!!
- https://access.redhat.com/documentation/ko-kr/red_hat_integration/2022.q1/html/debezium_user_guide/debezium-connector-for-postgresql - 레드헷 페이지인데, Debezium과 Psql에 대한 내용, 꽤 고수준까지 Deep Dive할 수 있다.
- https://techblog.woowahan.com/10000/
- https://github.com/debezium/debezium
- https://github.com/yzevm/sync-postgresql-with-elasticsearch-example

유익한 글이었습니다.