Django - 5.1 에는 "connection pool" 이 있어요?!? (Persistent Connections는 어쩌고?!)
Django Basic to Advanced
[ 글의 목적: django connection pool 히스토리, 과거의 노력, 그리고 고민되어야 하는 부분에 대한 기록 ]
Django Connection Pool
드디어 django 에
connection pool이 생겼어요!!(사실 거의 4달짜리 뒷북이다ㅎㅎ)
5.1 릴리즈 노트 를 보다가 아주 내눈을 가져간 connection-pool 부분이 있었다. 개인적으로 진짜 업데이트 안할 것 같은 부분이 업데이트 되다니, 역시 시대에 따라 철학도 유기적으로 변화해야 오랜시간 사랑받는 오픈소스가 되는게 아닐까 한다.
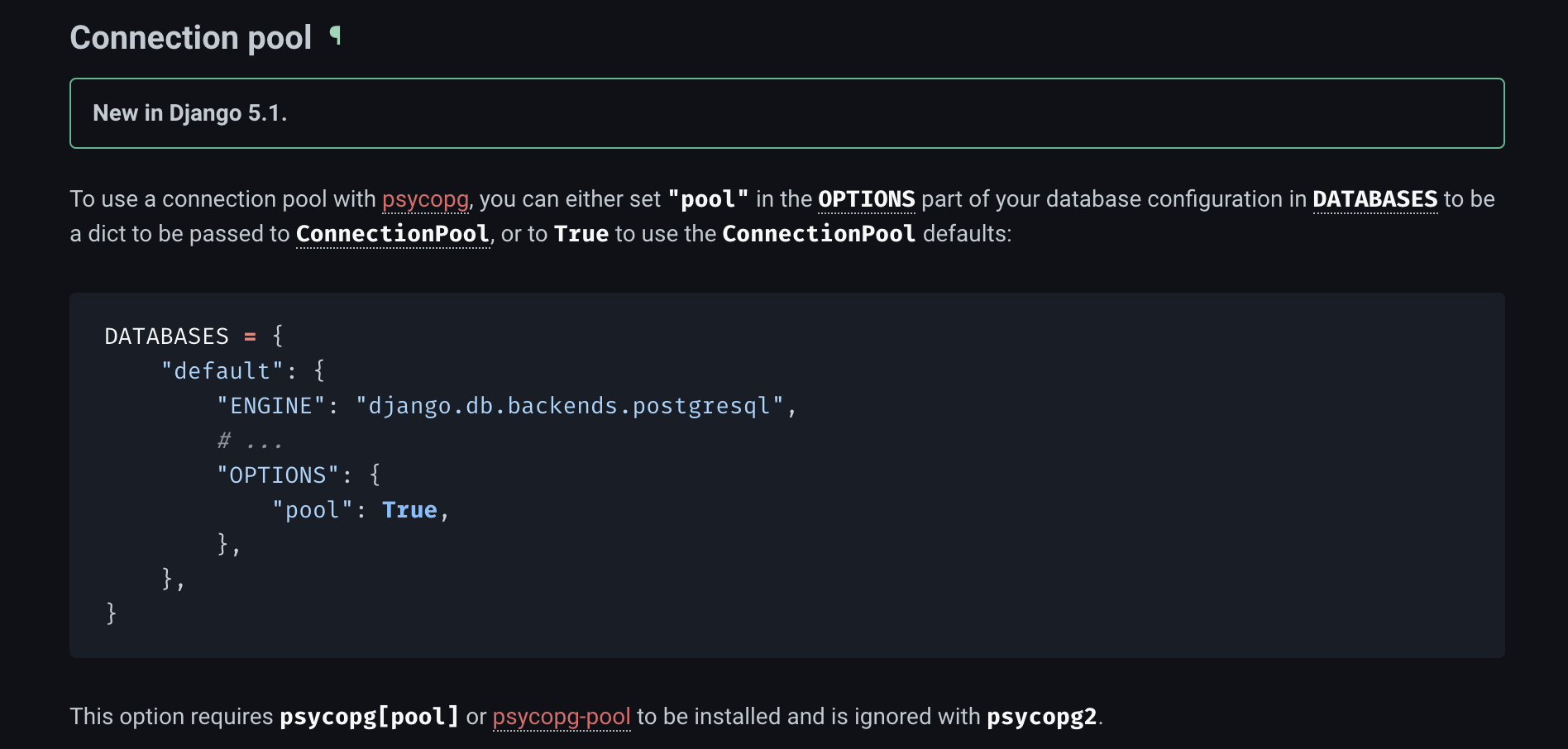
1. Connection Pooling
-
일단 "DBMS connection pool" 은 단순하게 말해 "미리 DBMS와 연결이 맺어두고, pool 만들어서 재사용 가능한 상태로 세팅하는 것" 이다.
-
DBMS 도 "DB를 위한
서버" 이다. 그러니 당연하게도API등의backend에는 "연결"이 필요하다. 그리고 그 연결은 일반적으로TCP/IPprotocol 로 연결된다.
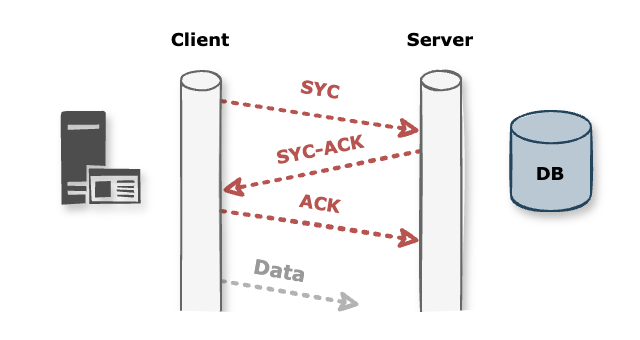
-
3-way handshaking을 하다보니,ACK까지 당연하게 오버헤드가 발생 한다. 그러니 미리 "성공한 커넥션" 을 만들어두고 재사용하면, 그 오버헤드를 줄이고 응답 시간을 단축할 수 있게 된다. -
(Database와 Database Management System, 두 단어를 계속 구분하고 싶은게, 전자로 단어를 계속 사용하다보면 마치 단순한 파일시스템을 바로 사용하는 기분이 든다.)
1) DBCP
-
대게
web server/web application server/DBCP/DBMS등으로 layer 를 (관심사 분리) 나누려다 보니 "DBCP" 라는 이름의 layer 로 많이 존재해왔고, 특히 jvm & spring 이 강력하다 보니 Apache Commons DBCP 가 유명하다. -
naver D2 Commons DBCP 이해하기 글과 같이 유수의 규모있는 서버 사이드에서 많은 layer 중 하나로 여전히 껴있지 않을까? 생각된다.
2) 왜 django 는 없었는가? (not official)
-
일단 django 의 default 설정은 "요청마다 연결을 맺고, commit 이후에는 끊는다."
-
Why doesn't django support connection pool? 글의 장고 토론 글 - Database pooling vs. persistent connections 을 참조 하면 알 수 있듯,
"pooling 까지 framework 가 간섭해야 하는가?"이다. 다른 "관심사" 에 가깝다고 보며, 이미 "충분한 써드파티" 가 있다는 얘기가 많다. -
그도 그럴것이 django 와 가장 찰떡인
postgresql은pgbouncer라는 아주 유명한 "connection pooler" 가 있다. (너와 나의 연결고리! DB Connection Pooler — PgBouncer 글을 가볍게 읽어보는 것을 추천한다.) -
뿐만 아니라 위에서 언급한
Apache Commons DBCP와 같이 이미 connection pool을 관리하는 써드파티는 많다! (사실 더 중요한건, DBMS 마다 커넥션 관리 방식이 다 다르다!)
3) 그런데 왜 5.1 에서?
-
일단 psql 대상으로만 적용 가능한 풀링 설정 이다. 더 정확하게는
psycopg라이브러리psycopg_pool의ConnectionPool을 활용한다. -
가장 많은 조합인 [ django + psql ] 을 위해 선제적으로 적용해 본 것으로 보이고, 깃헙 이슈나 토론에서 해당 토픽은 계속해서 논의가 이뤄졌었다.
-
이제 많은 상용 application 들이 cloud server 에서 배포된다. 그러니 DBMS layer 에 대해서 특히
PaaS형태를 선호하게 된다. 그러면서 해당 layer 에 depth 있는 control owner-ship 을 가지기 힘들다. (AWS RDS에서는 이를 위해RDS Proxy서버를 하나 더 쓰는 경우가 매우 많다.) -
그러다 보니 자연스럽게 application layer 에서 이를 컨트롤하기 위해, 많은 F/W & DBMS drive library 가 connection pooling 을 지원한다. (
SQLAlchemy,HikariCP, node 에서pg - pool등) -
이를 다분히 신경쓰고, psql 먼저 선제적으로 적용하지 않았을까 생각한다.
2. Django Connection Pool 실전
1) 본디 Persistent Connections 이 있었음을
-
django는 커넥션 풀링 대신
Persistent Connections(지속 연결)이라는 방법이 있었다. -
한 번 연결한 커넥션을 곧바로 종료하지 않고 일정 시간이 지난 후에 종료되도록 하여 이어지는 요청에서도 커넥션을 재사용 하도록 하는 세팅이었다. 아래와 같이
CONN_MAX_AGE와 같은 간단한 attribute 추가로 사용 가능했다.
DATABASES = {
"default": {
"ENGINE": "django.db.backends.postgresql",
# ... 생략 ...
"CONN_MAX_AGE": 60, # 최대 수명 시간 (초 단위)
}
}기본값은 0이고 이 값이 0보다 크면 커넥션을 열고 닫는 대신 해당 시간동안 커넥션을 열고 닫지 않고 재사용 한다. 무제한으로 열린 상태를 유지시키고 싶으면None으로 설정하면 된다.
2) Persistent Connections 의 주의점
-
django 는 기본적으로 스레드(Thread)마다 데이터베이스 커넥션을 관리 한다. 당연히 gunicorn 등의 worker, 여러 process 로 fork 해서 운영하면 스레드마다 데이터베이스 커넥션이 생성된다! (당연하게 스레드 간에는 커넥션이 공유되지 않는다!)
-
그런데 DBMS 자체에서 커넥션 수가 제한되어 있을 때는 당연히 이슈가 있을 수 있고, 러닝하는 스레드 개수 이상은 만들 수 있어야 한다. 그리고 아주 빈번하고 짧은 connection open 이 일어난다면
"too many connections"같은 귀여운? 에러를 마주할 수 있다.
3) Persistent Connections 생명 주기
-
이 "지속 연결" 의 생명 주기를 보려면 기본적으로 django 가 DBMS connection 을 어떻게 관리하는지 알아야 한다.
(lazy loading, lazy connection 얘기는 각설) -
BaseDatabaseWrapperclass 에서connectmethod 를 보면 "Connect to the database. Assume that the connection is closed" 주석과 같이, 이미 모든 연결이 닫혔다고 생각하고connect를 한다. 그리고 그connect내부에CONN_MAX_AGE값 기반으로self.close_at변수를 세팅해 둔다.
max_age = self.settings_dict["CONN_MAX_AGE"]
self.close_at = None if max_age is None else time.monotonic() + max_age- 그리고
request_started와request_finished시그널에close_old_connectionsmethod 가 등록되어 있다.
# 코드 링크 >> https://github.com/django/django/blob/871e1ee5ff0b75aee5dd1bd3e88e349ca0ddc60d/django/db/__init__.py#L57-L63
# their lifetime.
def close_old_connections(**kwargs):
for conn in connections.all(initialized_only=True):
conn.close_if_unusable_or_obsolete()
signals.request_started.connect(close_old_connections)
signals.request_finished.connect(close_old_connections)- 그러면 이를 "사용자 요청" 관점에서 DBMS connection 생명 주기를 보면 아래와 같다.
- 요청 시작
request_started시그널 실행.- 기존 연결을 정리하기 위해
close_old_connections()호출.
- 연결 확인
ensure_connection()에서 현재 연결 상태를 확인:- 연결이 없으면 새 연결 생성.
- 연결이 있으면
CONN_MAX_AGE확인:- 만료되었으면 새 연결 생성.
- 만료되지 않았으면 기존 연결 재사용.
- 데이터베이스 작업
- ORM 또는 Raw Query를 통해 데이터베이스 작업 수행. (비즈니스 로직 실행)
- 요청 종료
request_finished시그널 실행.close_if_unusable_or_obsolete()호출:- 오래된 연결을 닫거나, 유효한 연결은 유지.
- 연결 종료 또는 유지
CONN_MAX_AGE에 따라 연결을 닫거나 유지.
4) 실제 5.1 에서의 pool 코드
- 실제 5.1 에서의 pool 코드는 아래와 같다. 더 근본적으로는
psycopg라이브러리에서 어떻게 작동하는지 보는게 좋다.
# https://github.com/django/django/blob/2f6b096b83c55317c7ceef2d8d5dc3bee33293dc/django/db/backends/postgresql/base.py#L185-L223
# ... 생략 ...
@property
def pool(self):
pool_options = self.settings_dict["OPTIONS"].get("pool")
if self.alias == NO_DB_ALIAS or not pool_options:
return None
if self.alias not in self._connection_pools:
if self.settings_dict.get("CONN_MAX_AGE", 0) != 0:
raise ImproperlyConfigured(
"Pooling doesn't support persistent connections."
)
# Set the default options.
if pool_options is True:
pool_options = {}
try:
from psycopg_pool import ConnectionPool
except ImportError as err:
raise ImproperlyConfigured(
"Error loading psycopg_pool module.\nDid you install psycopg[pool]?"
) from err
connect_kwargs = self.get_connection_params()
# Ensure we run in autocommit, Django properly sets it later on.
connect_kwargs["autocommit"] = True
enable_checks = self.settings_dict["CONN_HEALTH_CHECKS"]
pool = ConnectionPool(
kwargs=connect_kwargs,
open=False, # Do not open the pool during startup.
configure=self._configure_connection,
check=ConnectionPool.check_connection if enable_checks else None,
**pool_options,
)
# setdefault() ensures that multiple threads don't set this in
# parallel. Since we do not open the pool during it's init above,
# this means that at worst during startup multiple threads generate
# pool objects and the first to set it wins.
self._connection_pools.setdefault(self.alias, pool)
return self._connection_pools[self.alias]
# ... 생략 ...-
그리고 psql 에만 선제적 적용이다 보니
django/django/db/backends/postgresql/base.py에서만 확인 가능하고, 연결을 맺는 것, 끊는 것에서 단순한 connection 이 아니라 pool 자체를 끊고 맺는 것으로 바뀌어 있다. -
그렇기 때문에 [ "사용자 요청" 관점에서 DBMS connection 생명 주기 ] 는 거의 본질적으로 같다. 달라지는 부분은 "2. 연결 확인" 이 아래와 같이 바뀔 것이다.
- ConnectionPool 생성 및 확인
- ConnectionPool 객체가 존재하지 않으면 새 풀을 생성
- 이때 CONN_MAX_AGE가 0인지 확인
- 0이 아니면 풀링과 Persistent Connections은 동시에 사용할 수 없으므로 오류 발생.
- 0이면 풀링을 활성화하여 연결 객체를 관리
- 연결 사용
- ConnectionPool이 기존 연결을 재사용하거나 새 연결을 생성
- 선택적으로 건강 상태 체크(health check)를 수행하여 연결 유효성을 검사
5) 실전 pool 활용
- 세팅은 진짜 간단하다.
DATABASES세팅에 "options > pool" 값을 아래와 같이 활용하면 된다. 그냥"pool": True,을 사용할 경우psycopg의 default ConnectionPool 설정을 따라간다.
DATABASES = {
"default": {
"ENGINE": "django.db.backends.postgresql",
# ...
"OPTIONS": {
"pool": {
"min_size": 2, # pool 최소 크기
"max_size": 4, # pool 최대 크기
"timeout": 10, # 연결 대기 시간 (초)
}
},
},
}무작정 풀을 늘리는게 능사가 아니다.
-
당연한 얘기지만 이는 적당한 trade-off 가 필요하다. 늘리면 DB의 컴퓨팅 리소스가 소모된다. 그리고 DBMS 종류마다 소모되는 정도와 가능한 pool-size 도 다르다. (여기서는 psql 만 체크해 보자!)
-
AWS RDS 기준으로는 https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_Limits 를 참조하면
max_connections값의 임계값이 있다. -
그리고 DB의 커넥션당 약 10MB의 메모리가 필요하다는 것을 알 수 있다. (MySQL: 커넥션당 약 12 MB, PostgreSQL: 커넥션당 약 9.1 MB, Oracle: 커넥션당 약 9.4 MB ...)
-
psql 은 매 커넥션당 약 9mb (9531392 byte) 가 소모되며, 커넥션이 10개만 되어도 사실 약
100mb의 리소스가 소모된다.
배포환경 / 멀티프로세스 환경에서는 어떤가
-
django 의 단순한 thread 의 connection 얘기는 skip 하고,
gunicorn등을 기반으로 배포했을때worker마다pool을 가지게 된다. -
즉, 배포시 멀티프로세스 환경이라면, 당연히 프로세스마다 개별적으로
pool을 가지고 있게 된다.pool을 4개 사용하고, worker 가 3 개인 배포 환경이면 3 * 4, 총 12개의 pool size 형태가 되는 것이고, 120mb 가까운 리소스가 필요하다. -
이를
k8s,EKS등 오케스트레이션 환경 하위에서는 기하급수적으로 달라질 수 있다. 이 부분이 유의가 필요해 보인다.
근데 사실 반쪽짜리 pool 이다.
-
모두가 알다시피 이건 DBMS level 에서 control 하는 pool 이 아니다.
django는psycopg_pool.ConnectionPool에 의존하고,psycopg_pool.ConnectionPool는 연결 객체를 메모리 내 큐(queue)에 저장하고, 연결의 생성, 재사용, 해제를 메모리 상에서 tracking 한다. -
그리고 사실 간단한(아니 심플한)
lock매커니즘으로 메모리 수준의 queue 를 관리한다.
아니 그러면 어쩌라는건가!
-
답은 뻔하다,, 상황에 맞게 적절하게 trade-off 를 해야한다. 해당 application 에서 단순 query 처리량, 빈도가 매무 빈번해서 dbms connection 에 대한 오버헤드가 눈에 띈다면 가용가능한 선에서, 배포 환경의 worker 수를 신경 쓰며, DBMS 의 처리 가능한 메모리양과 max_conn 개수를 고려하여 선택하면 된다!
-
그리고 진짜 대규모, 대용량 처리 엔터프라이즈에는 이런 개별적인 application level 의 pool 관리는 하지 않는게 좋다고 생각한다.
-
오히려 이런 application level 의 pool 들이 나중에 "서버에서 메모리 수준의 부하" 가 될 수 있고, 누수의 가능성도 있다.
-
특히 지금 비동기 환경이나 celery 등의 환경에서는 적용할때 주의할 필요가 있어보인다. (issue 들 참조)
앞으로 django 의 pool 관리가 어떻게 바뀌는지 더 지켜보는게 좋을 것 같다!
출처



PSQL 연결 중 DB 연결 방식을 어떻게 가져갈지 고민했었는데, 현우님 글을 보고 더 깊이 고민해볼 필요가 있을 것 같아요! 현재는 Pool로만 연결해 둔 상태인데, 옵션도 고려해서 적용해 봐야겠습니다 😊 이게 바로 아는 것으 힘...
유익한 포스팅 잘 읽었습니다! 감사합니다!