
[ 글의 목적: psql 기반 timesacleDB 의 "활용" 에 초점 맞추고, django 에서 간단한 실습 기록 ]
timesacleDB
timesacle DB 는
PostgreSQL을 기반의 오픈소스 시계열(Time-series) RDBMS 이다. 공식홈페이지 에서는 "Over 3 million Timescale databases power loT, sensors, Al, dev tools, crypto, and finance apps — all on Postgres. We use Postgres for everything; now you can too." 이라고 소개되어 있다.
1. timesacleDB 톺아보기
[PS.] 해당 글은 시계열 데이터 부터 timesacleDB 기본 컨셉과 하이퍼테이블, 심플한 수준의 raw SQL, 심플한 수준으로 django ORM 에서 사용하는 것 정도가 주된 내용이다. continuous aggregation 이나 더 고차원적인 내용은 다른 글에서 다룰 예정이다.
1) 시계열 데이터
- 시계열 데이터는 "시간을 통해 순차적으로 발생한 관측치의 집합" 을 의미한다. 그리고 그 관측치들은 서로 "연결성, 관련" 이있고, 더 정확하게는 "고정된 시간 구간의 관측치" 여야 유의미한 시계열 데이터 이며, 시차(Time lag)가 동일해야 한다. (불규칙한 시간 구간을 유의미한 시계열 데이터로 볼 순 없다.)
-
교과서에 나올법한 시계열 데이터 자체에 대한 논의보단, 이 시계열 데이터는 특성상 스트리밍 데이터와 닮아 있다. 즉
immutability가 있다. (한 번 삽입되면 불변성을 가지는 데이터) -
고로 주된 작업은
INSERT와DELETE이며UPDATE가 아니다. 그리고 "시간 범위에 따른 집계 연산" 을 자주 하게 된다.
2) 기존 시계열 데이터 처리 DBMS
-
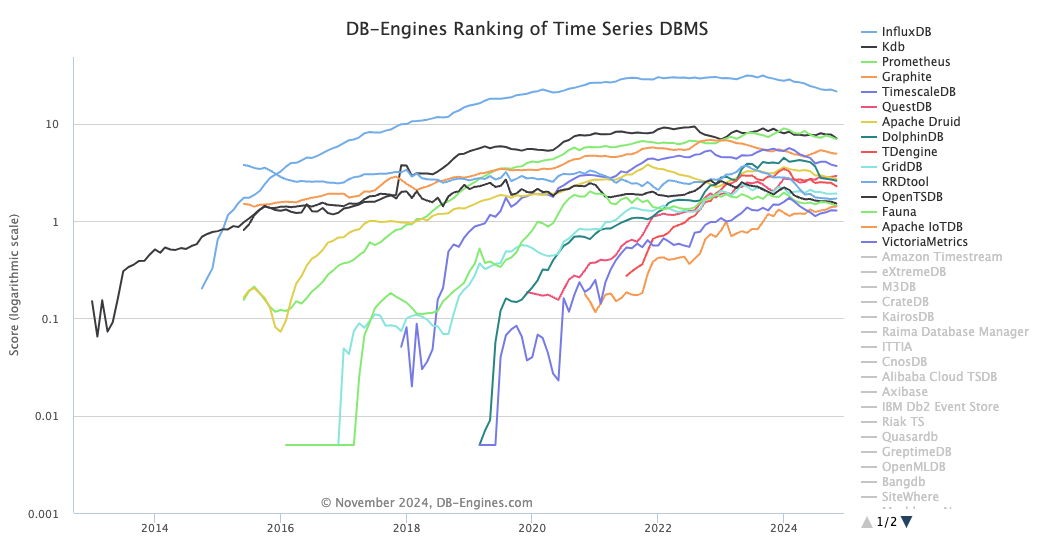
최근에는 아주 다양한 형태의 데이터를 처리하고, 처리량 자체도 늘어나서 이런 시계열 DBMS 성장세는 지속적으로 늘어나고 있다. 출처 - DB-Engines Ranking - Trend of Time Series DBMS Popularity
-
아마 가장 유명한것은
influxdb아닐까! (테크 회사들 세션에서 빠지지 않고 등장하는 시계열 처리 DBMS 라고 기억된다 ㅎㅎ) -
아주 급격한 성장은 20년~22년도 빅데이터와 AI 화두가 계속 나오면서 급격하게 성장했고, 22년 부터는 OpenAI 의 GPT public 공개 부터 점진적 성장세도 보여주고 있다.
3) 왜 timesacleDB ?
velog-dashboard v2 에서 사용해 보려고 한다!
-
이번 velog-dashboard v2 에 사용해보려고 한다. v1 에서는 velog 의 통계적 데이터를
no-sql&mongodb를 활용했는데, 이번에는RDBMS를 기반으로 활용해 보려고 한다. (v1 보다 욕심이 많아진 v2 이기때문에 core DBMS 를 psql, RDBMS 로 잡았다.) -
timesacleDB에서 강조하는 하이퍼 테이블 을 활용해 보려고 한다. 기본적으로 "시간과 공간" 에 대한 파티셔닝 셋업이 잘 되어 있기 때문에, 대량의 시계열 데이터 SELECT 에 좋은 퍼포먼스를 보여준다. -
물론 psql 만으로도 할 수 는 있다. 하지만
trigger나, 특정 트랜잭션을 cron 성격으로 매번 처리 & 관리해줘야 한다. (테이블 횡적 분할, record 파티셔닝 등) 혹여나 생길지 모르는 스케일링 관점에서도 다중 노드 형태로 상대적으로 편하게 확장 가능하다.
4) 하이퍼 테이블
TimescaleDB 이 가장 강조하는 부분은 "하이퍼 테이블" 이다. 공식 문서에서는 이렇게 소개한다. "Hypertables are PostgreSQL tables that automatically partition your data by time. You interact with hypertables in the same way as regular PostgreSQL tables, but with extra features that makes managing your time-series data much easier."
추상화된 테이블
-
말이 어렵지만, 결론적으론 기본적인
psql에서 테이블 처럼 동일하게 컨트롤 할 수 있게 된다. -
추상화 계층 내면에는 시간 기준 (또는 수동으로 다른 기준으로) 여러개의 데이터 파티션 (청크라고 부름) 으로 나누고 인덱싱하고 이에 필요한 관리 작업을 한다. 사용자는 그냥 하이퍼테이블을 만들기만 하면 된다!
청크(Chunk)
-
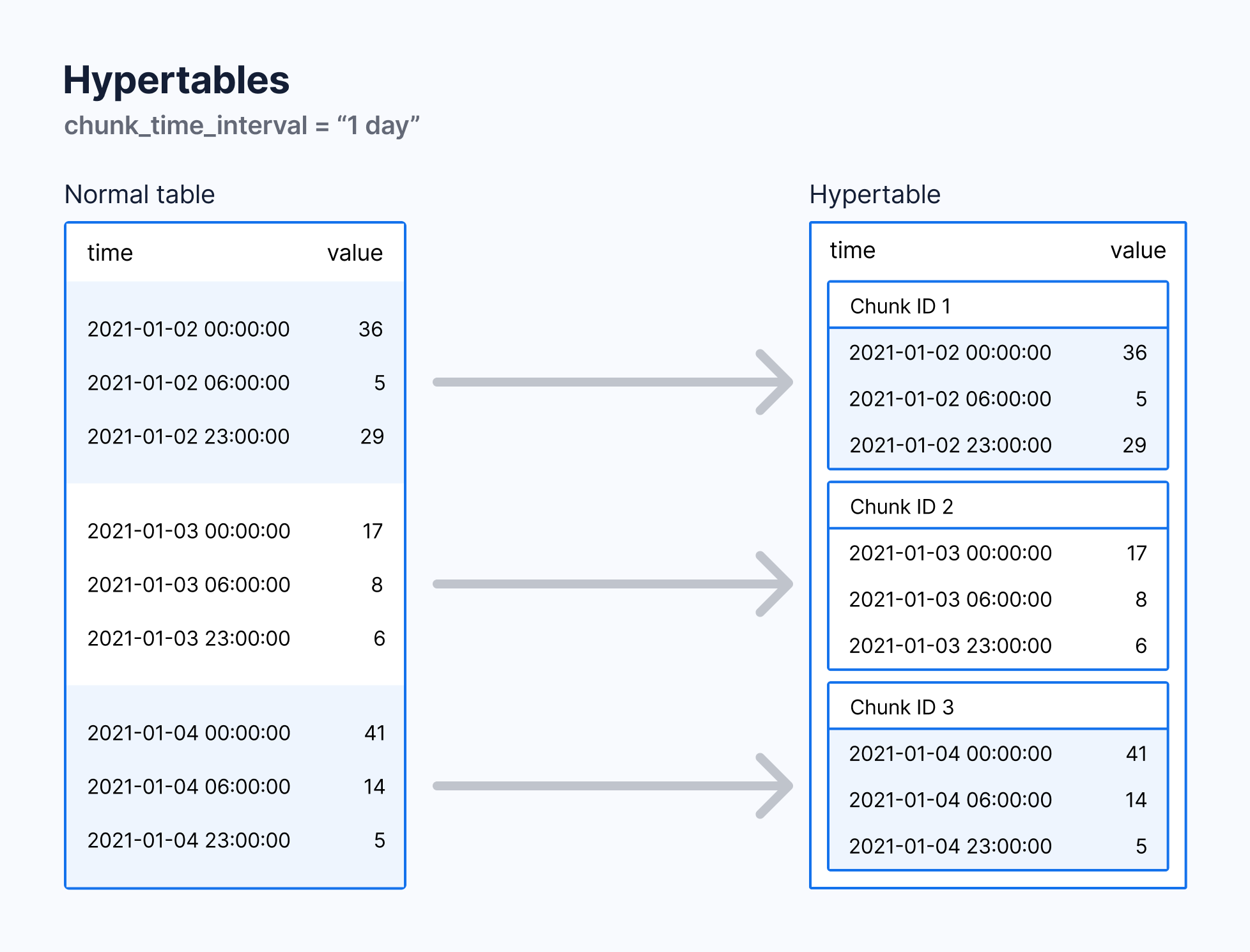
언급한 대로, 하이퍼테이블은 "청크"라는 작은 하위 테이블들로 나눈다. - "Each hypertable is made up of child tables called chunks"
-
기본적으로 각 청크는 7일을 기준으로 파티셔닝 한다. (필요에 맞게 변경할 수 있다.)
chunk_time_interval을 "1일로" 설정하면 각 청크는 같은 날의 데이터를 저장한다. (아래 공식 홈페이지 사진 출처)
-
시간 파티셔닝을 "하루 단위, 월 단위 등" 으로 잡을 수 있고, 공간 파티셔닝을 "장치 ID, 사용자 ID" 을 추가로 사용해 데이터를 나눌 수 있다. (우리의 경우 하루 + 사용자ID 복합 파티셔닝이 되지 않을까?)
-
Chunk Creation Time 과 Partition Range 는 다를 수 있다고 한다. 당연하게도
2024-01-01 ~ 2024-01-07기간 데이터를2024-01-10일에 생성할 수 도 있다. -
내부적으로는 이 차이를 혼동하지 않아야 한다는데, 청크가 처음 만들어질 때의 "시스템 시간이 TimescaleDB의 카탈로그 메타데이터에 기록되기 때문" 이라고 한다.
-
청크가 파티셔닝을 하위 테이블로 나누어서 한다면, 오히려 "데이터 보존 정책" 을 지키기 아주 용이해진다는 의미다. (ex - 3개월이 지난 데이터는 자동으로 삭제, 그에 따른 법적 규제 준수 용이, 즉 데이터 라이프사이클 자동화!)
청크의 퍼포먼스
-
이 "청크"는 쿼리 퍼포먼스에 영향을 제일 직접적으로 주는 단위라고 한다. 청크의 단위는 메모리에 적합할 정도로 작아야 하며, 그래야 최신 데이터를 디스크에서 읽지 않고도 삽입하거나 쿼리할 수 있다고 한다.
-
너무 작고 비어 있는 청크가 많아지면 쿼리 계획 수립 시간과 압축 효율성에 악영향을 준다고 한다.
-
청크당 크기가 메인 메모리의
25%를 초과하지 않도록 설정하는 것을 권장 한다. (활성 하이퍼테이블의 인덱스를 포함한 청크의 크기) -
청크 사이즈를 정하는 공식 홈페이지 예시는 아래와 같다.
- 하루 약 2GB의 데이터를 기록하고 메모리가 64GB인 경우, 청크 시간 간격을 1주로 설정
- 동일한 환경에서 하루 약 10GB의 데이터를 기록하는 경우, 청크 시간 간격을 1일로 설정
-
생각보다 대용량 데이터를 위해 추가 압축을 해야하나? 싶은 생각도 들었다. 1G 메모리 환경이 base 일 것 같은데, 250mb 를 기준으로 청크를 잡아야 하면, 잘 추산해야 되겠다 싶다 ㅎㅎ
인덱싱
-
기본적으로 인덱스를 자동 생성한다. (
create_default_indexes를false로 처리해서 자동 인덱싱을 막을 수 도 있다고 한다.) -
모든 하이퍼테이블에는 시간별 인덱스가 내림차순으로 세팅되고, 공간 매개변수와 시간에 대한 인덱스를 같이 할 수 있다고 한다.
추가로
-
해당 글의 목적은 "django 에서 얼마나 잘 적용 시키냐" 이기 때문에, 더 depth 있는 내용은 생략한다!
-
공식 홈페이지에 이 하이퍼테이블 관련 글이 굉장히 정리가 잘 되어 있다. 특히 Create unique indexes on a hypertable 까지는 꼭 읽어보는 것을 추천한다.
5) timesacleDB with (raw) SQL, 실습
- https://docs.timescale.com/self-hosted/latest/install/installation-docker/ 를 기준으로 F/U 해보자 (pg17 은 애플 실리콘도 지원!)
services:
# https://github.com/timescale/timescaledb-docker-ha?tab=readme-ov-file
db:
image: timescale/timescaledb-ha:pg17
container_name: timescaledb
environment:
POSTGRES_USER: django-timescaledb
POSTGRES_PASSWORD: django-timescaledb
POSTGRES_DB: timescaledb_demo
ports:
- "5432:5432"
volumes:
- timescale_data:/var/lib/postgresql/data
platform: linux/arm64
volumes:
timescale_data:-
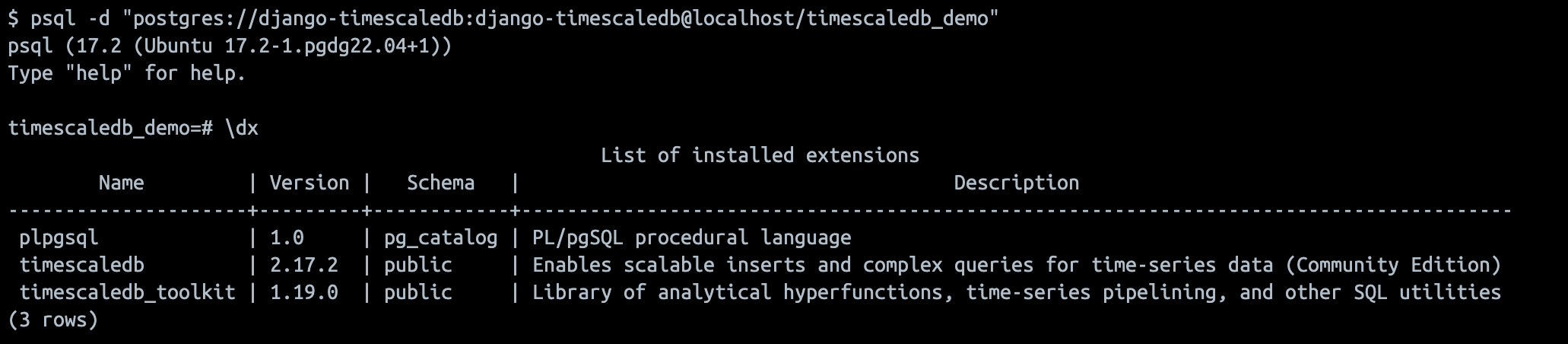
TimescaleDB 이 잘 설치되었는지 보기 위해 psql shell 에 붙어서
\dx를 입력해보자! -
docker exec&psql -d "postgres://django-timescaledb:django-timescaledb@localhost/timescaledb_demo"
예시 데이터
- 하나의 "센서" 데이터를 실시간으로 계속 받고 있다고 가정하고, 그 "센서" 데이터 기록을 다 저장하는 table 을 만들어 보자
-- 기본 PostgreSQL 테이블 생성
CREATE TABLE sensor_data (
time TIMESTAMPTZ NOT NULL,
sensor_id INT NOT NULL,
temperature DOUBLE PRECISION,
humidity DOUBLE PRECISION
);- 그리고 이를 hyper-table 로 만들고 샘플 데이터를 밀어넣어 보자!
-- TimescaleDB 하이퍼테이블로 변환
SELECT create_hypertable('sensor_data', 'time', chunk_time_interval => INTERVAL '1 day');
-- 테스트 데이터 삽입
INSERT INTO sensor_data (time, sensor_id, temperature, humidity)
VALUES
('2024-11-20 10:00:00', 1, 22.5, 60.1),
('2024-11-20 11:00:00', 1, 23.0, 58.3),
('2024-11-21 09:00:00', 2, 19.8, 65.4),
('2024-11-21 10:30:00', 3, 25.0, 55.2),
('2024-11-22 12:00:00', 1, 21.0, 59.9);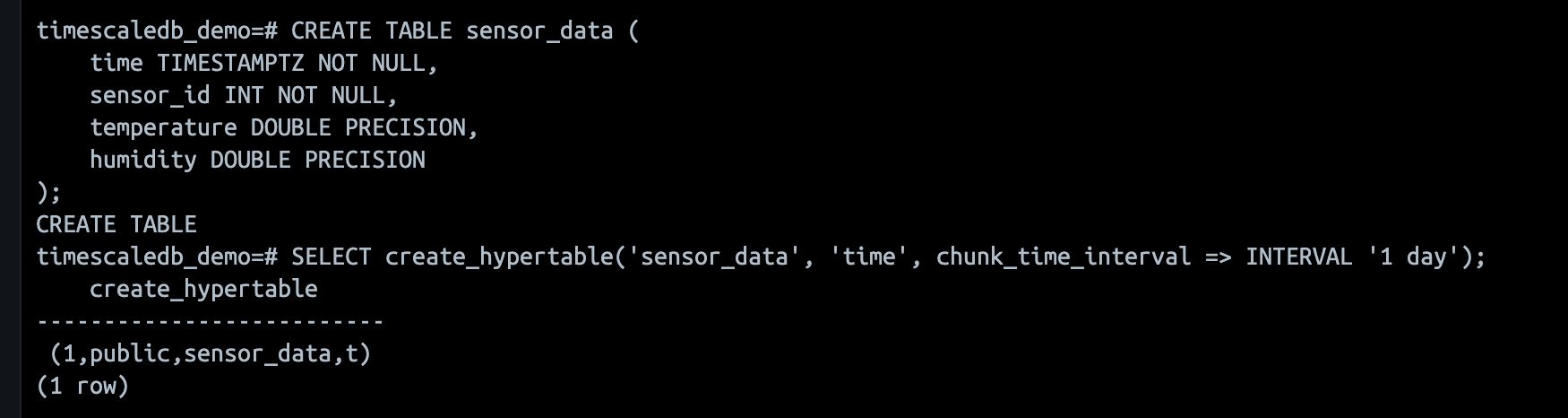
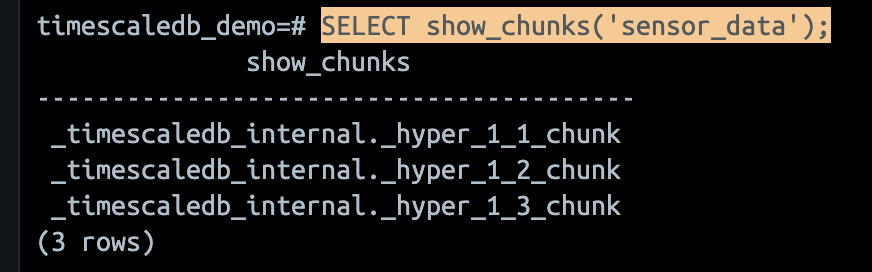
청크 확인
SELECT show_chunks('sensor_data');로 청크를 확인할 수 있다.
- 실제 청크 데이터 확인을 위해서 아래 쿼리를 활용할 수 있다.
-- 청크에 저장된 데이터 확인
SELECT chunk_name, range_start, range_end
FROM timescaledb_information.chunks
WHERE hypertable_name = 'sensor_data';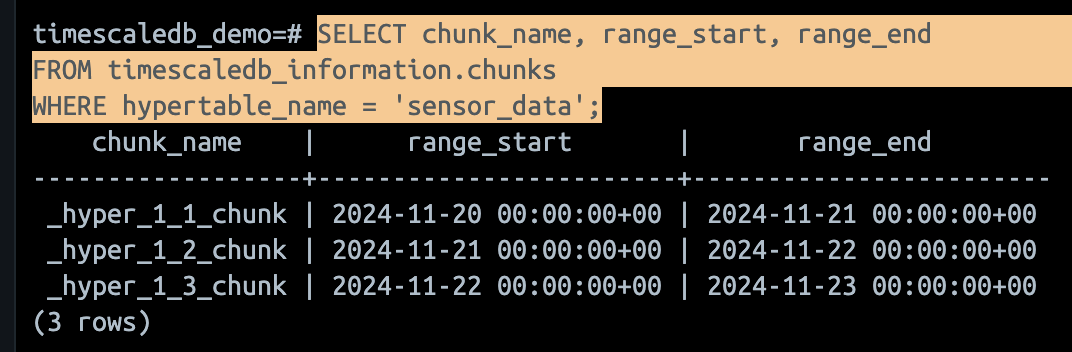
진짜 파티셔닝을 타니?!
- psql의 쿼리 분석,
EXPLAIN ANALYZE을 활용해 보자!
EXPLAIN ANALYZE SELECT * FROM sensor_data
WHERE time BETWEEN '2024-11-20 00:00:00' AND '2024-11-21 00:00:00';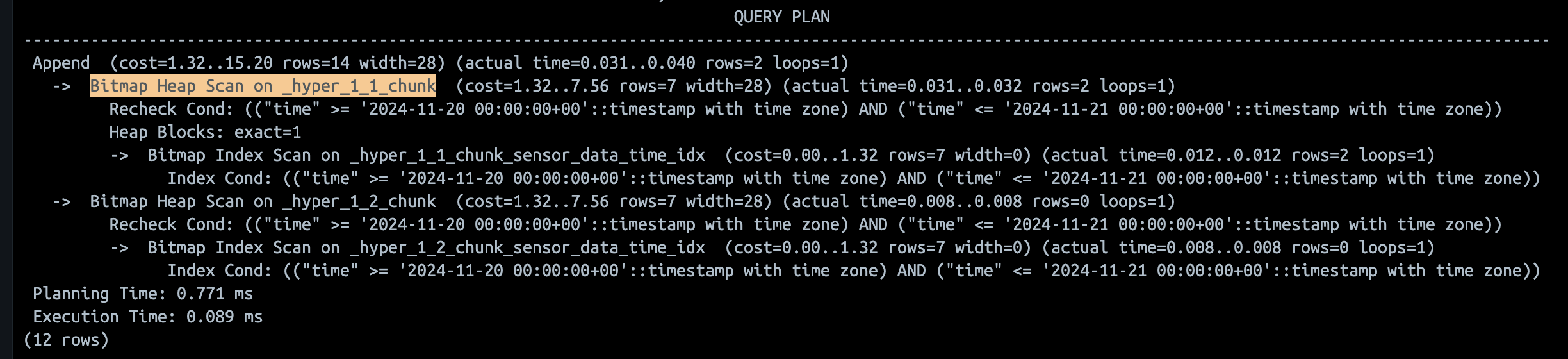
-
Bitmap Index Scan과Bitmap Heap Scan을 사용한다. 아주 간략하게 말해서 "데이터 ctid (테이블 내부 행 버전의 물리적 위치) 만 찾고" 나서 다 찾으면 "해당 물리적 위치를 타고 실제 데이터를 읽는" 다. -
그 과정에서 조건에 맞는 행이 저장된 데이터 페이지(블록)를 비트맵 구조로 저장하는
Bitmap기반 로직 (실제 psql 은 B-Tree를 사용하기도 한다고 한다.) 을 돌리는 것이다. -
그리고
_hyper_1_2_chunk에서는 조건에 맞는 데이터가 없었으므로 행 수(rows=0)가 반환되지 않았다. 이 역시 파티셔닝을 활용해 효율적으로 쿼리 범위를 제한했다는 것을 알 수 있다.
-
결론적으로 아주 잘, 파티셔닝하고, 인덱싱하고 있다!
-
이를 더 자세하게 파고 들면 다른 얘기가 될 것 같아 줄인다.
더 다양한 활용
-
하이퍼테이블 생성, 청크 인터벌, 사이즈 세팅 외에 데이터 보존 정책 세팅과 압축 정책, 연속 집계 (continuous aggregation) query 들이 있으니 더 확인하면 도움이 될 것 같다.
-
바쁜 사람들에게는 아래 부분을 먼저 보라고 추천한다!
2. Django + timesacleDB
1) 관련 라이브러리
-
django-timescaledb 라는 라이브러리가 있다.
-
꽤나 핵심 기능은 단순하다.
TimescaleModel클래스를 상속받아 모델을 정의하면, 해당 모델에 대한 하이퍼테이블이 자동으로 생성된다.
2) 기본 세팅
- 일단 위
docker-compose.yaml기반으로 timescaleDB 는 러닝하고,settings.py의DATABASES만 바꿔주자
DATABASES = {
"default": {
"ENGINE": "timescale.db.backends.postgresql",
"NAME": "timescaledb_demo",
"USER": "django-timescaledb",
"PASSWORD": "django-timescaledb",
"HOST": "localhost",
"PORT": "5432",
},
}테스트 모델은 "주식" 데이터로 잡았다.
- 참고로 app 이름은
timeseries로 만들었다.
from django.db import models
from timescale.db.models.models import TimescaleModel
from timescale.db.models.fields import TimescaleDateTimeField
class StockPrice(TimescaleModel):
"""
주식 데이터를 저장하는 모델.
"""
time = TimescaleDateTimeField(interval="1 minute") # 1분 간격
ticker = models.CharField(max_length=10) # 주식 티커 (e.g., AAPL, TSLA)
open_price = models.DecimalField(max_digits=10, decimal_places=2) # 시가
close_price = models.DecimalField(max_digits=10, decimal_places=2) # 종가
high_price = models.DecimalField(max_digits=10, decimal_places=2) # 고가
low_price = models.DecimalField(max_digits=10, decimal_places=2) # 저가
volume = models.BigIntegerField() # 거래량
def __str__(self):
return f"{self.ticker} @ {self.time}"- 하이퍼테이블이 제대로 만들어 졌을까? 아래 sql 로 확인해 보자!
SELECT *
FROM timescaledb_information.hypertables;
hypertable_schema: 하이퍼테이블이 속한 스키마 이름, 기본적으로 TimescaleDB에서 생성된 하이퍼테이블은 public 스키마hypertable_name: 하이퍼테이블 이름.owner: 하이퍼테이블의 소유자(데이터베이스 사용자) 이름, 해당 테이블을 생성한 PostgreSQL 사용자의 이름num_chunks: 해당 하이퍼테이블에 생성된 청크의 개수,chunk_time_interval설정 값에 따름compression_enabled: 하이퍼테이블에 압축이 활성화되었는지 여부. (TimescaleDB는 오래된 데이터를 압축하여 저장 공간을 절약하는 기능을 제공)f: 압축이 비활성화됨 (기본값).t: 압축이 활성화됨.
tablespaces: PostgreSQL의 테이블스페이스는 데이터를 저장할 디스크의 위치를 지정하는 기능
더미데이터 밀어넣기
["AAPL", "TSLA", "GOOGL", "AMZN", "MSFT"]종목으로 23년 1월 부터 3월 말까지의 더미데이터를 밀어넣어 보자!
# python manage.py shell
# >>> from timeseries.bulk_create import generate_stock_data
# >>> generate_stock_data()
import random
from datetime import timedelta
from django.utils import timezone
from .models import StockPrice
def generate_stock_data():
tickers = ["AAPL", "TSLA", "GOOGL", "AMZN", "MSFT"]
start_time = timezone.make_aware(timezone.datetime(2023, 1, 1))
end_time = timezone.make_aware(timezone.datetime(2023, 1, 14))
delta = timedelta(minutes=3)
data = []
current_time = start_time
batch_size = 3000 # 배치 크기 줄임
while current_time <= end_time:
for ticker in tickers:
open_price = round(random.uniform(100, 1500), 2)
close_price = round(open_price * random.uniform(0.98, 1.02), 2)
high_price = round(max(open_price, close_price) * random.uniform(1.0, 1.05), 2)
low_price = round(min(open_price, close_price) * random.uniform(0.95, 1.0), 2)
volume = random.randint(1000, 1000000)
data.append(
StockPrice(
time=current_time,
ticker=ticker,
open_price=open_price,
close_price=close_price,
high_price=high_price,
low_price=low_price,
volume=volume,
)
)
# 일정 배치마다 데이터 삽입
if len(data) >= batch_size:
StockPrice.objects.bulk_create(data, batch_size=batch_size)
data = [] # 배치 초기화
current_time += delta
# 남은 데이터 삽입
if data:
StockPrice.objects.bulk_create(data, batch_size=batch_size)
-
참고로
bulk_create할때max_locks_per_transaction가 뜰 수 있으니, 1000개씩 짤라서 bulk_create 하거나, 직접 해당 값 바꿔주기 싫다면 그냥 바로createorsave로 해도 된다! (테스트 only) -
매 3 분마다 5개의 tickers 대상으로 만드니까
6720 × 5 티커 = 33600 개가 만들어 진다. 그러면 청크는 약 6720 개 정도가 만들어 져야 한다.
SELECT chunk_name, range_start, range_end
FROM timescaledb_information.chunks timeseries_stockprice LIMIT 10;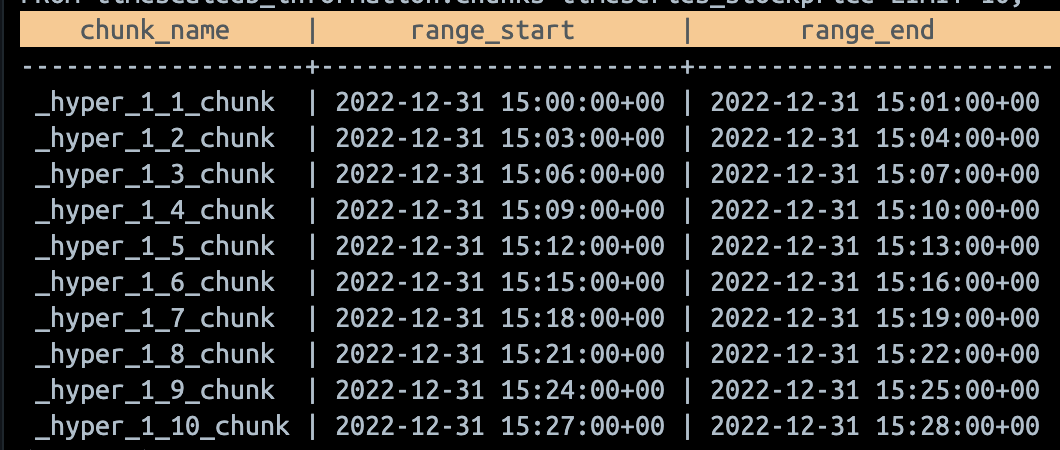
-
DBMS는 default 세팅상 UTC 기준으로 만들다보니까 1월 1일이 곧 22년 12월 31일의 15시 부터 시작이다 ㅎㅎ 우선 청크는 잘 만들어 진 것 같다!
-
참고로, 테스트로 아무 데이터 겁나 많이 만들어두고 삭제 통으로 하면 메모리 이슈가 겁나 날 것 이다 ㅎㅎ 청크들 때문에.. (위 "청크당 크기가 메인 메모리의 25% 를 초과하지 않도록 설정" 을 곱씹으며 ㅎㅎ) 그럴때를 위해 아래 스크립트를 사용하셨으면 해서,,
DO $$
DECLARE
chunk RECORD;
BEGIN
FOR chunk IN
SELECT format('%I.%I', chunk_schema, chunk_name) AS full_chunk_name
FROM timescaledb_information.chunks
WHERE hypertable_name = 'timeseries_stockprice'
LOOP
-- 청크 삭제
EXECUTE format('DROP TABLE %s CASCADE;', chunk.full_chunk_name);
RAISE NOTICE 'Deleted chunk: %', chunk.full_chunk_name;
END LOOP;
END $$;3) time_bucket
-
하이퍼테이블을 대상으로 실제 자주 query 하는 형태는 "time_bucket"
function이다. 5분, 1시간 또는 3일 등의 "구간" 으로 가져오는 것이다. (psql의 date_bin과 비슷하다고 한다.)
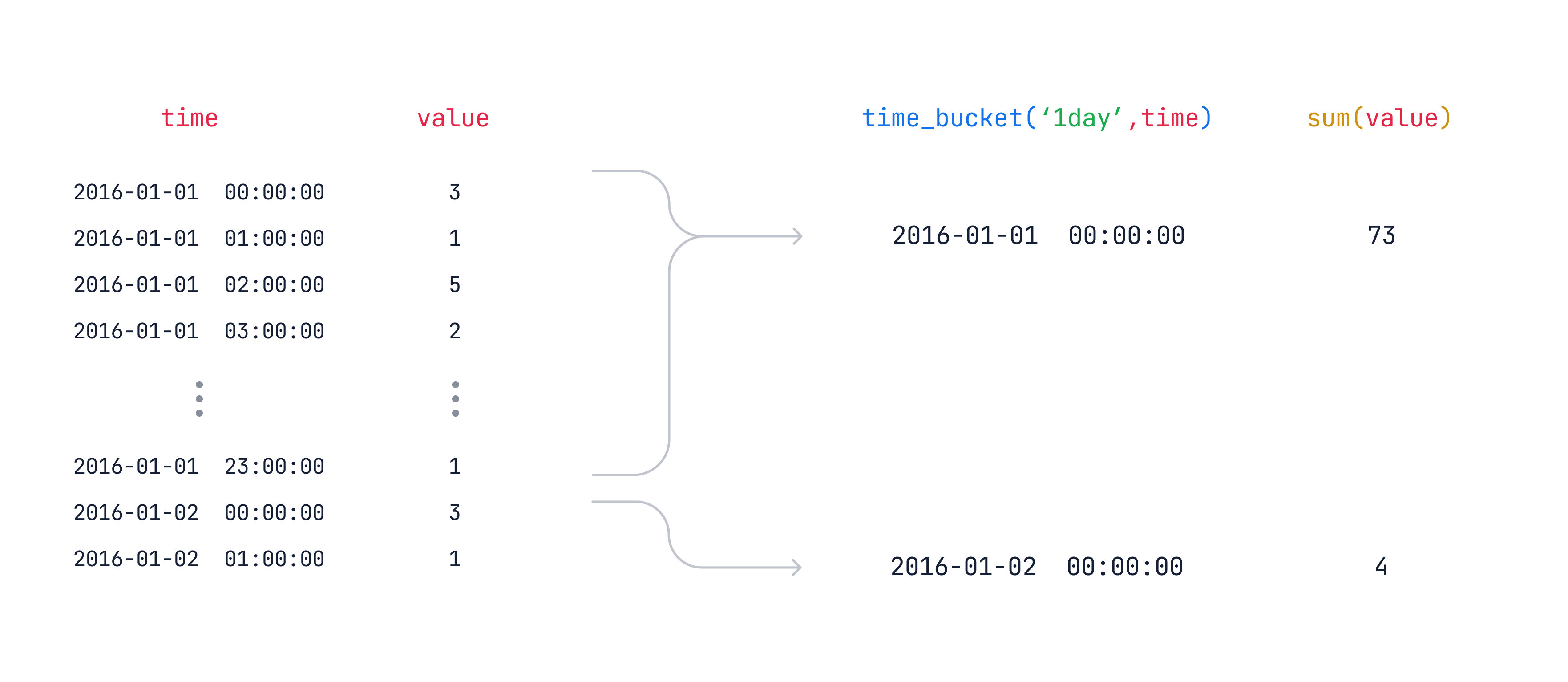
기본적은 time_bucket 활용
- 위
StockPricemodel 대상 sql query 로 구성해보면 아래와 같다.
SELECT time_bucket('1 hour', time) AS bucket
FROM timeseries_stockprice
WHERE time BETWEEN '2023-01-01 00:00:00' AND '2023-01-02 00:00:00'
GROUP BY bucket
ORDER BY bucket;- 이를 이제
django-timescaledb를 기반으로 질의할 수 있다.
from datetime import datetime
from django.utils.timezone import make_aware
from timeseries.models import StockPrice
start_time = make_aware(datetime(2023, 1, 1, 0, 0, 0))
end_time = make_aware(datetime(2023, 1, 2, 0, 0, 0))
date_range = (start_time, end_time)
bucketed_data = StockPrice.timescale.filter(time__range=date_range).time_bucket('time', '1 hour')
>>> bucketed_data
<TimescaleQuerySet [{'bucket': datetime.datetime(2023, 1, 1, 15, 0, tzinfo=datetime.timezone.utc)}, {'bucket': datetime.datetime(2023, 1, 1, 15, 0, tzinfo=datetime.timezone.utc)}, '...(remaining elements truncated)...']>-
해당 라이브러리를 timesacleDB 의 sql을 던지도록 활용하려면, 자동으로 만들어주는 manager,
timesacle이라는 attribute (manager) 로 접근해서 사용한다! -
그리고 결과값은
TimescaleQuerySetinstance 로 return 해준다. 해당 쿼리셋의 정의는 여기서 확인할 수 있다.
time_bucket 과 그룹, 통계
- 이제 위에서 지정한 시간 "버킷별" 로
open_price의 평균을 계산해보면 아래와 같다. (순서대로 sql & queryset)
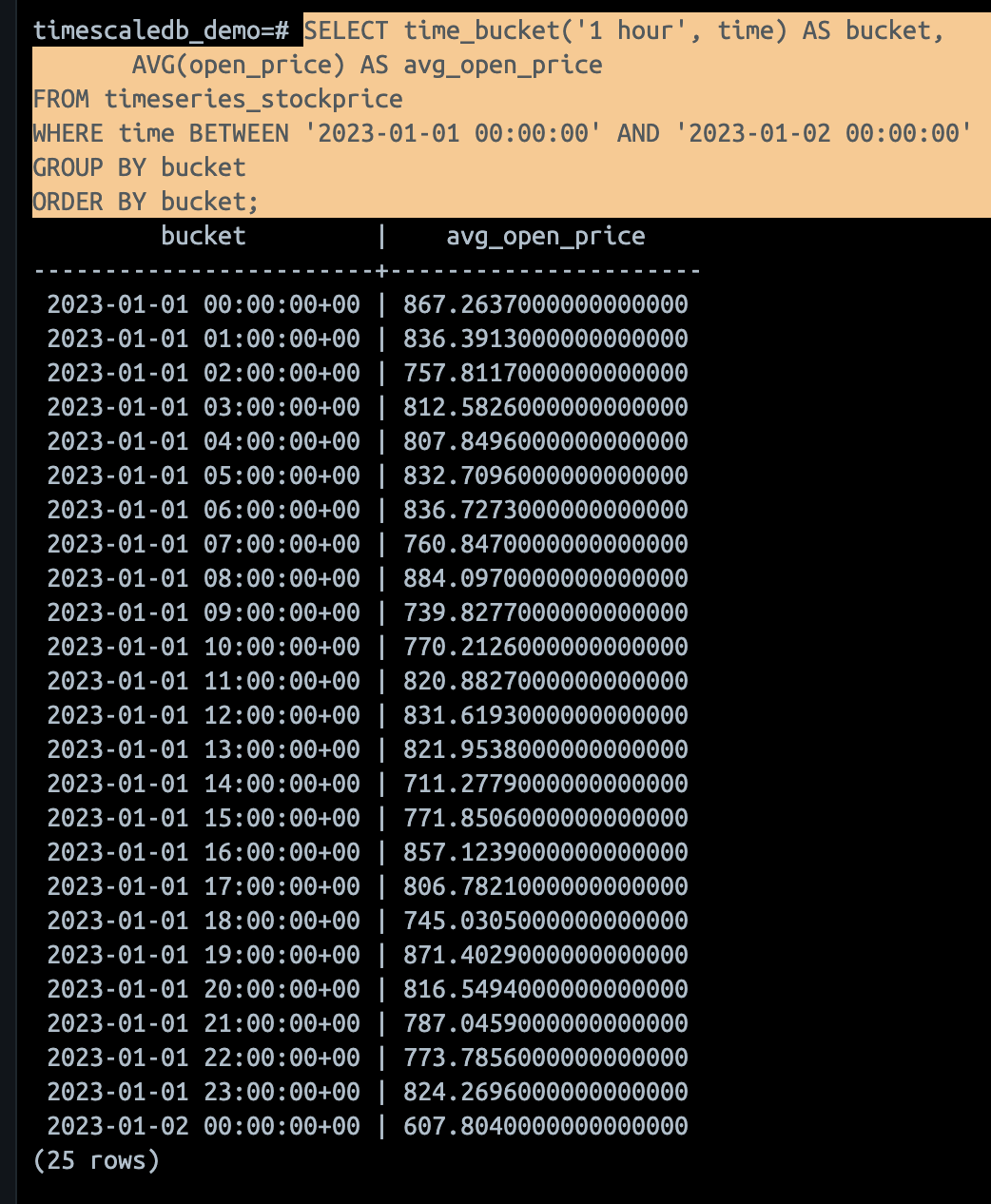
SELECT time_bucket('1 hour', time) AS bucket,
AVG(open_price) AS avg_open_price
FROM timeseries_stockprice
WHERE time BETWEEN '2023-01-01 00:00:00' AND '2023-01-02 00:00:00'
GROUP BY bucket
ORDER BY bucket;from datetime import datetime
from django.utils.timezone import make_aware
from django.db.models.aggregates import Avg
from timeseries.models import StockPrice
bucketed_avg_data = StockPrice.timescale.filter(time__range=date_range).time_bucket('time', '1 hour').annotate(avg_open_price=Avg('open_price'))
-
raw sql 쓰면 안될까? -> 물론 안될게 전혀 없다. 하지만 django ORM 특성상 raw sql 에서 예상하지 못한 issue 가 발생할 가능성이 있다. (자연스럽게 보안적인 이슈도 따라오고!)
-
해당 글에서는 아주 간단한 형태의 sql 과 queryset 을 살펴보자! 다음 글에서는 실제 최적화 관점과 그냥 psql 만 사용했을때 과연 단순 index 보다 (Index Scan) 더 나아지는 지점은 언제일까?
-
시간 자체를 indexing 했을 때 보다 유의미해지는 데이터 개수, 연산 개수 등의 지점에 대해 체크할 필요가 있을 것 같다.
출처

8개의 댓글

이번 프로젝트가 시간별로 데이터를 저장하는 프로젝트인 만큼 timescaleDB와 관련한 대화가 조금씩 있었던 것 같은데, 그 때마다 무슨 소린지 당최 이해가 안 가서 조금씩 찾아가면서 겨우 이해했던 것 같습니다.
이 글이 그 때 이미 있었으면 편하게 이해했을 것 같은데, 이제라도 올라와서 정말 다행입니다~ 😄

새로운 기술을 이렇게 순식간에 간결하고 이해하기 쉽게 정리해주시는 게 정말 대단하신 것 같슴다!
현우님 내공에 감탄하며.. 틈틈이 여러 번 정독하고 개인적으로도 추가로 공부해보겠습니다
감사합니다!!🙇🏻♂️
시계열 데이터를 다루는 데 있어 TimescaleDB의 기본 개념 핵심 개념들을 단계적으로 설명해주시고 예시코드도 포함되어 있어 이해하기 쉬웠습니다!
저희 프로젝트에서는 어느 정도 사이즈로 청크 만들면 될지 고민해봐야겠네요! 유익한 글 감사합니다👍