Django + Celery + MQ
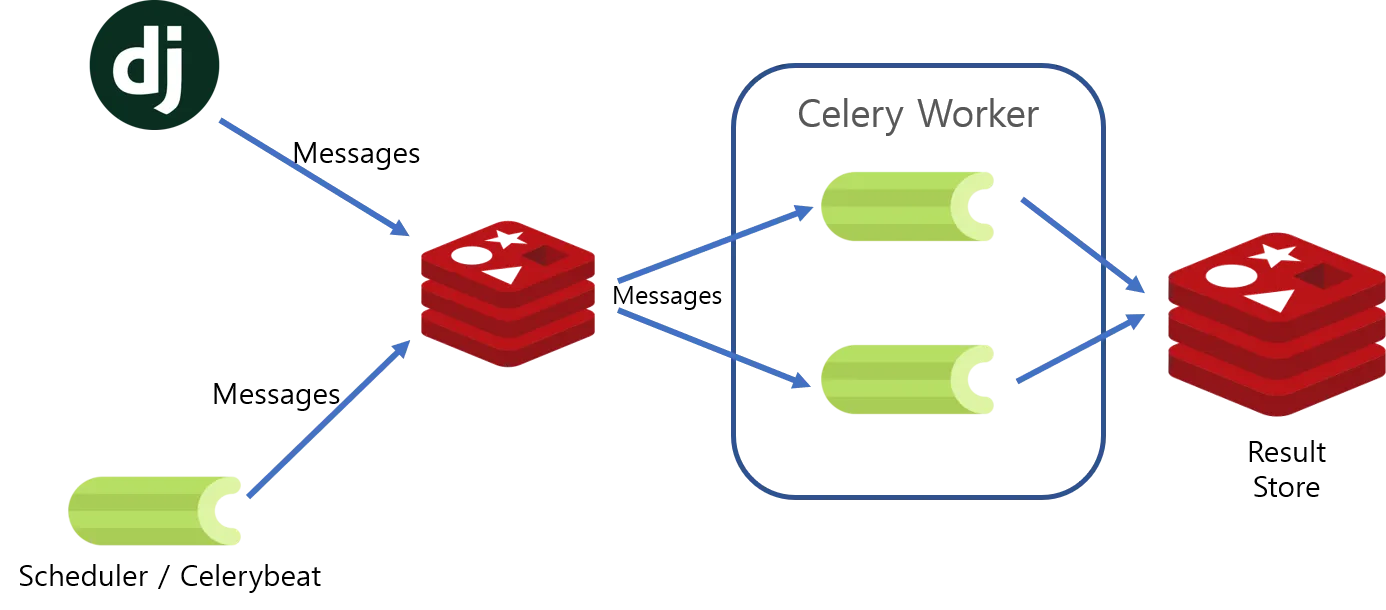
API Server <==> Redis <==> Celery stack 을 클래식한 example과 전체적인 그림 및 기본만 이해를 먼저 해보자. (추가로 redis 등을 꼭 brew 등을 통해 설치를 할 필요는 없다. 이 뒤로 이어지는 시리즈에서는 https://github.com/Nuung/django-all-about 레포 기준으로 진행한다. - 도커환경)
why?
-
핵심은 "한정 된 자원"을 잘 활용하기 위해, 여러가지 요청을 "비동기 적으로" 모두 처리하기 위해서다. 메시지큐 에 대해 우선 파악하고 오자.
-
web Back-end(이하 서버) service에 비유하여 생각해보자. http reqeust <-> response는 서로 tcp/ip 기반 protocol위에서 handsake를 통하여 소통한다.
-
일련의 요청은 서버단 에서 query들을 executing하거나 특정 데이터들을 다루게 되어 있다. django를 예로 들자면, 일반적으로 유저의 요청은 장고가 응답을 줄 때까지 기다려야 한다. 만약 처리하는 것이 Big data, video, file 등이라고 생각해보자. "처리가 완료되어야 오는 응답"은
뒤지게느릴 수 있다. 다시 원점으로 돌아가 우린 이런 상황에서 한정된 자원을 적절하게 모두 처리하기 위해서 celery를 사용한다. 그리고 그러기 위해 MQ가 필요하다.
Celery

introduction
-
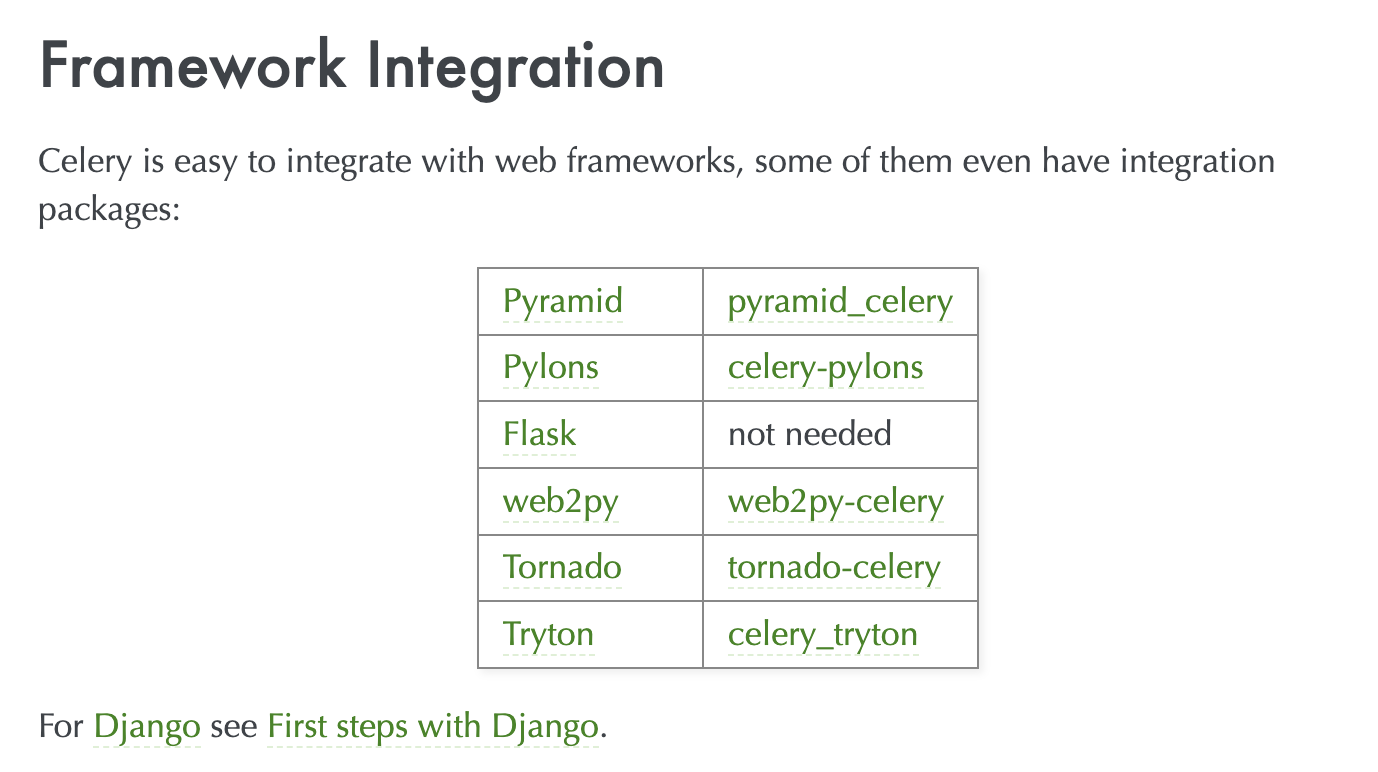
celery는 python 생태계의 다양한 stack (framework)을 지원한다. 그리고 django의 경우 docs도 잘 되어있고, 뿐만 아니라 "설정을 포함하여 아주 시작하기 간단하고 편하다."
(이게 나중에 독이 될 수 있다.) -
그리고 당연히, celery 는 django 없이 stand-alone 으로 러닝할 수 있다. 하지만 예시를 위해 django + celery stack 으로 계속 가져간다.
task queue
-
Task Queue가 있고 이런 큐에서 Task/Process를 매니징하는 것이다. 위 why에서 보듯이, "비동기로 작업을 처리하게 넘기고 바로 응답을 하는 작업"을 할 수 있게 도와주는 python 프레임워크이며 흔히 worker라고 부른다.
-
Celery는 process(taks)들을 execute만 하고, 다른 "thread(on demand / periodically)"에서 해당 작업을 실질적으로 처리한다. 그러기 위해 Task Queue는 Workload를 Distribute해줘야 한다. => 그러기 위해 MQ가 필요하다. 여기서는 "REDIS"를 사용할 것이다.
-
task queus는 다음과 같은 역할을 한다. 출처
- 작업 대기열
- 스레드 또는 머신에 작업을 분산시키기 위한 메커니즘.
- task라는 하나의 작업단위를 입력으로 받는다.
- 전담 워커 프로세스는 새로운 작업을 수행하기 위해 task queue를 지속적으로 모니터링한다.
redis 설치하기
- 철저하기 mac기반인 점 양해 바란다. 설치는 검색만 하면 너무 잘 나온다.
brew install redis
brew services start redis
brew services list
# redis started user /Users/user/Library/LaunchAgents/homebrew.mxcl.redis.plist
# 위와 같이 redis가 돌아가는 것을 확인하자 -
설정파일은 /usr/local/etc 하위에 redis.conf 파일을 통해 할 수 있다.
- port / requirepass password / timeout 시간 / bind ip 등을 설정한다.
- MQ에 관련된 설정파일은 민감하게 다뤄져야 한다. 참조 문서 확인 또는 설정 디테일 알아보기
-
redis-server를 통해 redis에 server output (log)를 실시간으로 확인 가능하다. -
redis-cli를 통해 redis server shell에 접근가능하다.redis-cli ping명령어를 쳐보고 PONG 이라는 응답을 받으면 설치 성공 및 서버 러닝 중이다! 간단한 명령어들 -
그리고 redis 서버의 log와 메시지 주고 받는 것을 실시간으로 보기 위해 redis-cli에서
monitor명령을 쳐주자!
django 세팅하기
-
사전 세팅은 이 글로 모두 대체한다.
-
우선
pip install 'celery[redis]'으로 설치를 해주자! 그리고 proj라는 프로젝트를 생성하고, proj/proj 경로에 celery.py 파일을 만들어 준다. '프로젝트 세팅'이 있는 곳에 추가해야한다. 그리고 아래와 같이 작성하자.
from __future__ import absolute_import, unicode_literals
import os
from celery import Celery
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'proj.settings')
app = Celery('proj')
# 문자열로 등록은 Celery Worker가 자식 프로세스에게 피클링하지 하지 않아도 되다고 알림
# namespace = 'CELERY'는 Celery관련 세팅 파일에서 변수 Prefix가 CELERY_ 라고 알림
app.config_from_object('django.conf:settings', namespace='CELERY')
# celery가 task로 데코레이팅된 일들을 다 알아서 찾는다.
# 실질적으로 celery 인스턴스가 만들어지는 code 이다!
app.autodiscover_tasks()
# debug 용 출력으로 하단 부분을 넣어준다!
@app.task(bind=True)
def debug_task(self):
print('Request: {0!r}'.format(self.request))python manage.py startapp app1으로 프로젝트에, "task"가 있을 app을 추가해주자. 그리고 proj/app1 경로에 tasks.py 파일을 추가해주자. 아래와 같이 내용을 채워주자.
from __future__ import absolute_import, unicode_literals
# 어노테이션과 데코레이터는 다르다! python의 '데이코레이터' 사용을 위해 import
from celery import shared_task
#shared_task 데코레이팅 되어진 실질적 작업!
@shared_task
def add(x, y):
return x + y- 이제 '프로젝트' proj/proj/settings.py 에 위에서 만든 APP을 추가하여 celery를 간단하게 테스트해보자. settings의 INSTALLED_APPS에 'app1'을 추가해준다. 그리고 redis에 대한 설정들도 추가해주자.
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
# for shared task test
'app1', ... # 생략
# 아래 내용 settings에 추가해주기.
# celery setting
CELERY_ALWAYS_EAGER = True
CELERY_BROKER_URL = 'redis://127.0.0.1:6379'
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379'
CELERY_ACCEPT_CONTENT = ['application/json']
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
CELERY_TIMEZONE = 'Asia/Seoul'- 그리고 이제
python manage.py runserver # 당연히 가상환경 키고로 장고 프로젝트를 러닝해주자.
celery test
- celery instance 세팅도 했고, 기본적인 설정과 shared_task를 만들었다. 이제 "worker"를 turn on 해야 한다.
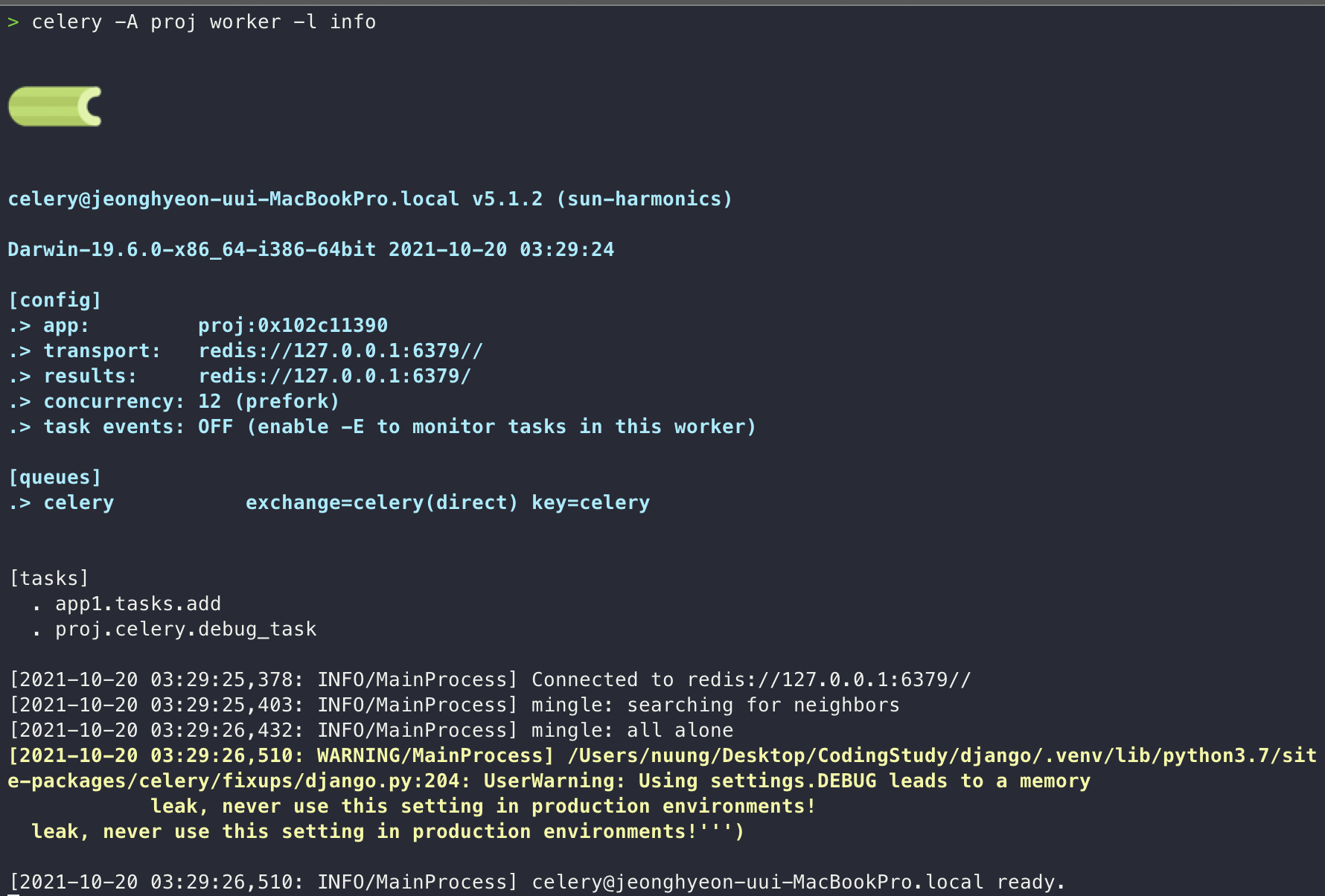
celery -A proj worker -l info # proj/ 경로에서를 쳐보자.celery -A 앱이름 worker -l 로그레벨와 같은 명령어 구조를 가진다.
-
만약 Cannot connect 에러가 뜬다면 MQ(여기선 redis) server가 켜져 있는지 확인하자! celery를 구동시키면
[tasks]에서 나오는 리스트들이 비동기로 작업할 수 있는 리스트들이다! -
redis-server도 켜두고, celery worker도 러닝 한 상태에서 우리가 실시간으로 task를 줘보자. 그러기 위해 python 쉘에 들어가서 작성한 tasks.py에서 shared_task를
- delay : Shortcut to send a task message, but doesn’t support execution options, task 메시지를 redis que에 보내고 result나 error, 실행 등에 대한 option이 없는 것이다.
- apply_async : 위 delay에 반해
apply_async는 execution option이 있다. - 사실 조금 더 고도화 된 완전 비동기 함수의 경우,
@app.task에서 가져온 task를 활용해task.s(arg1, arg2, kwarg1='x', kwargs2='y').apply_async()와 같은 형태를 많이 사용한다. s는signature의 short-cut 인데, 자세한 사항은 공식 홈페이지를 꼭 살펴보자.
>>> from app1.tasks import add
>>> add.delay(4,4)
<AsyncResult: 7bb03f9a-5702-4661-b737-2bc54ed9f558>
>>> add.apply_async(3,3)
<AsyncResult: 0bd6bdea-7cda-11ec-9f5d-51a692ab4461>- django server (사실상 celery만 테스트할꺼면 크게 필요X) / celery setting / redis server running + monitor 를 해뒀으면, 아래 사진과 같이 실시간으로 celery가 redis에 작업을 하는 것을 볼 수 있다.
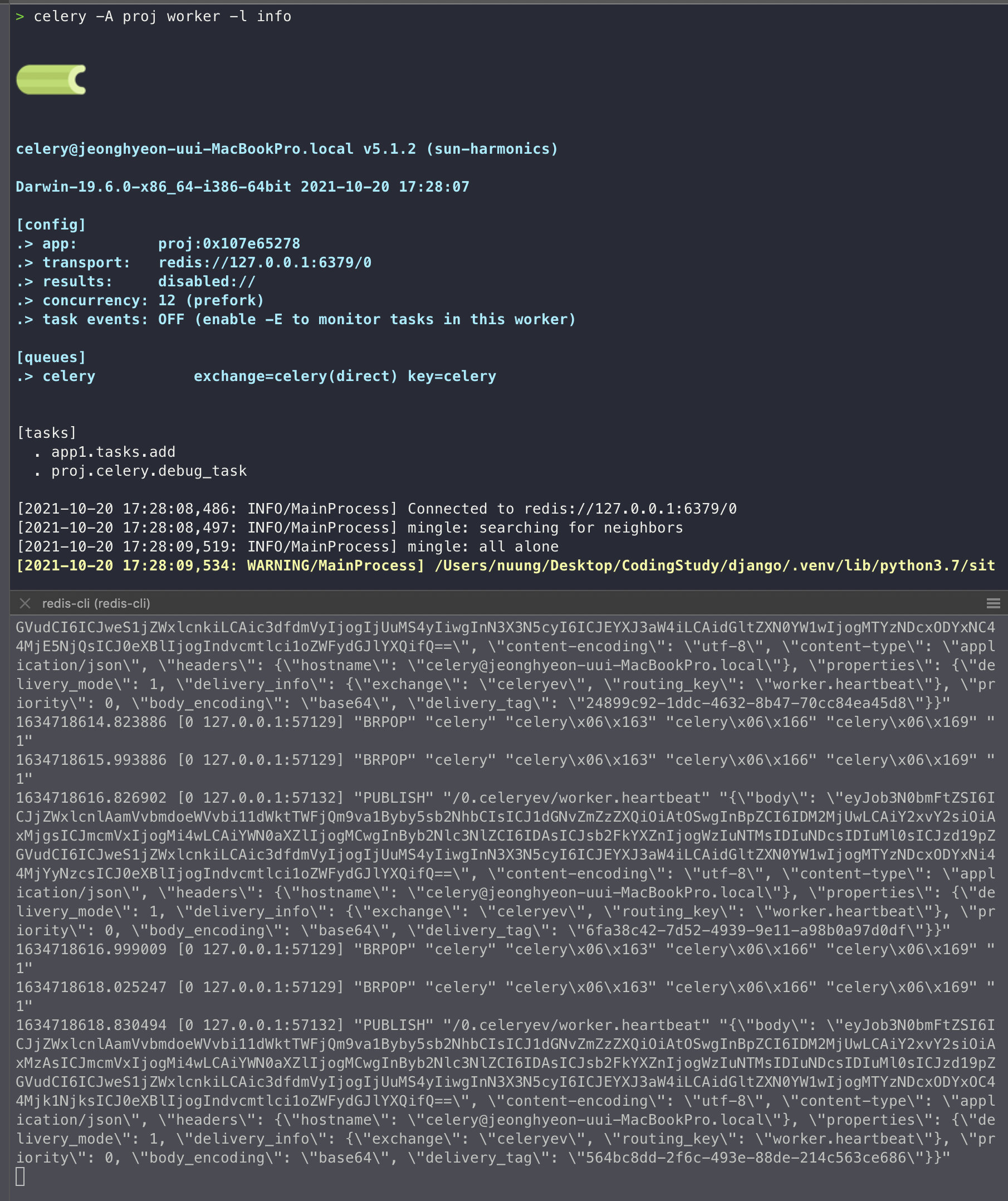
celery
-
celery(worker)를 Back-ground에서 돌아가게 하기 위해서는 "multi start" 명령어가 필요하다!
celery multi start w1 -A proj -l INFO자세한 공식문서도 확인해보자! -
보통 BG에서 돌아가게 하기 위해 사용하는 multi 커멘드는 아래와 같다
celery multi start w1 -A proj -l INFO
celery multi restart w1 -A proj -l INFO
celery multi stop w1 -A proj -l INFO # async하게 stop하는 방법이라 worker가 작업중인 상태이면 작업하는걸 그대로 shutdown 해버린다.
celery multi stopwait w1 -A proj -l INFO # worker가 작업이 끝날 때 까지 기다리다가 stop하려면 stopwait를 이용하자!- 셀러리에 대한 세부 내용은 다시 다룰것이다.
결론
- django 프로젝트에서 message que를 준비하고 celery setting을 해준다.
- 그리고 비동기적 처리가 필요한 로직을 tasks.py 등과 같은 파일을 따로 만든다.
- 해당 파일에서
from celery import shared_task을 통해 데코레이팅을 가져온다. 비동기적 처리가 필요한 로직에 @shared_task 붙여준다. - 브로커는 MQ로 일을 던지고 MQ에서 celery worker들에게 일을 할당하며 비동기적으로 일을 처리한다.
task에 대한 더 자세한 내용과 단점에 대한 내용은 다음글에서!!
