Django Celery - 단점, Task & subTask & Signature 비동기 작업 다루기 with network I/O
Django Basic to Advanced

[ 글의 목적: django async worker인 celery의 task 활용법에 대해 더 자세히 알아보고, 정리한 뒤 실습을 통해 고도화 & 예제 & 실무에서 도움되는 단점 파훼법 기록하기 ]
Django Celery
앞에서 아주 기본적인 celery 세팅과 함수를 async task로 만들어서 비동기 실행을 했다. 이제 celery를 좀 더, Distributed processing worker로 활용해보고 그에 따른 celery의 단점과 파훼법을 살펴보자.
조금 많이 장문입니다..
우선 등장하게 될 예제는 https://github.com/Nuung/django-all-about 레포 기준으로 진행한다.
celery에게 비동기 작업, task를 주고 실행하기
- 일단 task 함수로 데코레이팅 할 때
@app.task와@shared_task의 차이점이 궁금할 수 있다. 결론 부터 말하자면 전자는 같은 app 내에서(같은 app - celery instance), 후자는 외부에서도, 이기종 app 에서도 호출이 가능한 비동기 작업이 된다. 자세한 설명은 이 링크로 대신하겠다.
1. apply_async & delay
-
특정 함수를
@app.task로 만들어 두고, 그 함수를function.apply_async(...)orfunction.delay(...)로 호출하면 바로 celery worker가 비동기적으로 해당 function을 처리한다. -
apply_async가 기본 형태이고delay는 해당 형태의 shortcut이다. 즉 delay는 특정 인자값 없이 편하게 즉시 default 값으로 바로 비동기 작업으로 실행이 가능하다. -
apply_async는 Arguments와
countdown,queue,ingnore_result등 다양한 옵션을 설정할 수 있다. -
apply_async(args=None, kwargs=None, task_id=None, producer=None, link=None, link_error=None, shadow=None, **options)형태 이며 소스 코드는 공식 홈페이지에서 바로 볼 수 있다. 대표적으로 함수에게 전달할 args(Positional argument) kwargs(keyword argument) 를 인자로 넘겨줄 수 있다. -
직접 uuid를 만들어서
task_id로 넘겨 줄 수 있다. 이 경우 로깅에 유리하게 작성할 수 있다. 하지만 uuid를 절대 중복되게 작성하면 안된다. -
retry: bool인자 값을 주어 실행한 task가lossorfailure로 판단 될 때 재실행에 대한 값을 줄 수 있다. -
countdown: int=10과 같이 excute를 하고 특정 시간이 지나고 실행되도록 할 수 있다. 이 경우 상대적인 시간초이기 때문에eta=now + timedelta(seconds=10)와 같이 절대 실행시간을 박을 수 도 있다. -
expires: int or Datetime인자 값을 줘서retry와 무관하게 특정 절대 시간이후에 절대적으로 expires 시킬 수 있다. 이하 더 자세한 옵션 값은 공식 홈페이지를 참고하는게 좋다.
2. apply & send_task
-
결국
apply_async로 보내진 비동기 함수들은applyorsend_task로 넘어간다. -
apply의 경우 eager 상태이다. 동기 형태로 바로 함수를 실행하고 return 값을 줄 때 까지 blocking이 된다. = Execute this task locally, by blocking until the task returns. 소스 코드를 보면 더 자세하게 확인이 가능하다. -
send_task의 경우는 비동기를 위해 메시징 큐 (message que, 계속 예시로 보고 있는 redis)에 producing 한다. 앞선 시리즈들을 본다면 확실하게 이해할 수 있다. 역시 소스 코드를 보면 더 자세하게 확인이 가능하다. -
결국 메시징 큐에 들어간 task들은
comsumer에 의해 하나의 worker가apply하는 형태로 이뤄지게 된다. 그리고 celery는 내부적으로kombu를 활용한다. kombu는 메시지 브로커를 쉽게 사용할 수 있는 python 메시징 라이브러리다. -
celery가 어떻게
comsumer역할을 하고 있는지는 직접 소스 코드 보는 것을 추천한다.celery > worker > comsumer > comsumer.py에서 확인 가능하다.
3. task 실습
-
우선 아주 단순한 예제를 통해 살펴보자. 사업자 등록 번호를 10개 정도 준비하고, restful API를 만들어 홈텍스의 사업자등록상태조회 로 사업자가 폐업한 상태인지 아닌지 체크를 해보자. (ps. Network I/O 는 비동기의 필요성을 아주 여실하게 느끼는 분야이다.)
-
python manage.py startapp test로 임시 app을 만들고,tasks.py,view.py,models.py,urls.py를 코딩하자. (디테일 한 부분은 생략하고, 전체 코드는 아래와 같다). settings.py 에 app 추가, makemigrations, migrate 는 생략한다.
# test > models.py
class CheckedCrn(models.Model):
registration_number = models.CharField(
max_length=20,
unique=True,
blank=False, null=False,
verbose_name="사업자등록번호"
)
is_closed = models.BooleanField(blank=False, null=False, verbose_name="사업자 폐업여부")
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
def __str__(self) -> str:
return f"{self.registration_number}: {'closed' if self.is_closed else 'not close'} "
######################################################
# test > view.py
# django, drf lib
from rest_framework import status
from rest_framework.request import Request
from rest_framework.response import Response
from rest_framework.decorators import api_view
from drf_yasg import openapi
from drf_yasg.utils import swagger_auto_schema
# app lib
from apis.test.tasks import check_registration_number_from_hometax
@swagger_auto_schema(
method='GET',
manual_parameters=[
openapi.Parameter('query', openapi.IN_QUERY, description='검색할 사업자 등록 번호', required=True, default="", type=openapi.TYPE_STRING),
]
)
@api_view(('GET',))
def check_registration_number(request: Request):
"""
- query에서 list로 넘어온 사업자 등록 번호들을 폐업 여부를 체크하는 API
"""
qry = request.GET.get("query")
if not qry:
return Response(status=status.HTTP_204_NO_CONTENT)
qry_list = qry.split(",")
for registration_number in qry_list:
registration_number = registration_number.strip()
check_registration_number_from_hometax.apply_async(args=[registration_number], kwargs={})
return Response(
dict(success=True, message="사업자 등록 번호를 조회합니다. 결과는 admin에서 확인해 주세요"),
status=status.HTTP_200_OK
)
######################################################
# test > tasks.py
# python lib
import logging
from requests import Session, Response
from requests.adapters import HTTPAdapter, Retry
from bs4 import BeautifulSoup
from bs4 import BeautifulSoup as bs, Tag, ResultSet
from config.celery import app
from apis.test.models import CheckedCrn
logger = logging.getLogger(__name__)
def get_retry_session() -> Session:
"""
- request 모듈에서 제공해주는 adapter pattern 활용
- retry 내장 request session object 만들기
"""
retries_number = 3
backoff_factor = 0.3
status_forcelist = (500, 400)
retry = Retry(
total=retries_number,
read=retries_number,
connect=retries_number,
backoff_factor=backoff_factor,
status_forcelist=status_forcelist,
)
session = Session()
session.mount("http://", HTTPAdapter(max_retries=retry))
return session
@app.task
def check_registration_number_from_hometax(registration_number=1208801280):
s = get_retry_session()
url = "https://teht.hometax.go.kr/wqAction.do"
querystring = {"actionId":"ATTABZAA001R08"}
payload = f"""
<map id="ATTABZAA001R08">
<pubcUserNo/>
<mobYn>N</mobYn>
<inqrTrgtClCd>1</inqrTrgtClCd>
<txprDscmNo>{registration_number}</txprDscmNo>
<dongCode>88</dongCode>
<psbSearch>Y</psbSearch>
<map id="userReqInfoVO"/>
</map>
"""
headers = { "Accept": "application/xml; charset=UTF-8" }
res: Response = s.post(url, data=payload, headers=headers, params=querystring, timeout=2)
# xml return 이라 직접 parsing or parser 필요, bs4 & lxml 활용
res: BeautifulSoup = bs(res.content, 'lxml')
result: str = res.find("map").find("smpcbmantrtcntn").get_text().strip()
logger.info(f"{res}, {registration_number}")
is_closed = True
if result == "등록되어 있는 사업자등록번호 입니다.":
is_closed = False
new_check_crn: CheckedCrn
try:
new_check_crn = CheckedCrn(
registration_number=registration_number,
is_closed=is_closed
)
new_check_crn.save()
except Exception:
return None
return new_check_crn.__str__()-
핵심 코드는
view.py에서 for loop 안에 있는check_registration_number_from_hometax.apply_async(args=[registration_number], kwargs={})이다. (명시적으로 이렇게 사용하는 것이 좋다.) -
사업자 등록 번호를 하나씩 확인하고, 동기적으로 for 돌리는 것보다 network I/O는 이렇게 다 for loop의 비동기 task로 돌려버리면, 우리가 만든 view.py 의 비즈니스 로직 time만 걸린다.
-
직접해보면 사업자 등록번호 10개, 100개를 넣어도 response time을 1초안으로 보장하는 것을 알 수 있다. (url 매핑은
http://localhost/api/test/check/?query=1208801280,213,3898602190,2143,2208162517와 같이 했다.) -
더 자세한 코드는 해당 글 최상위 깃허브 레포 링크를 참고하길 바란다.
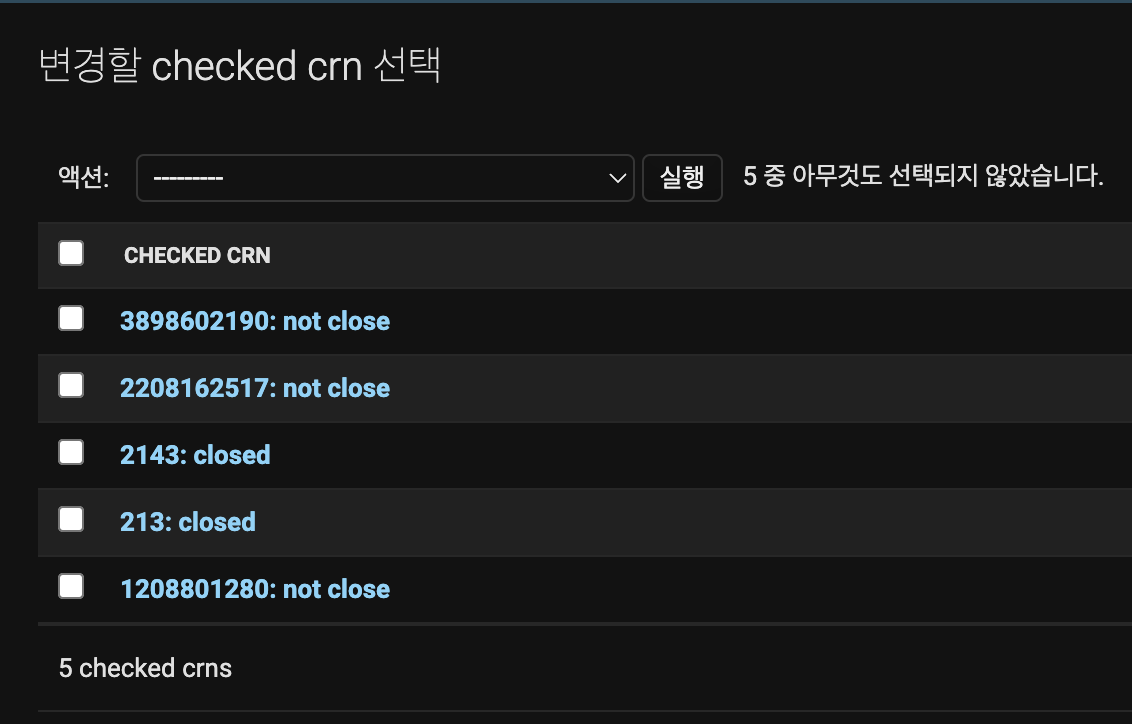
- flower를 확인해 보면 아래와 같다.
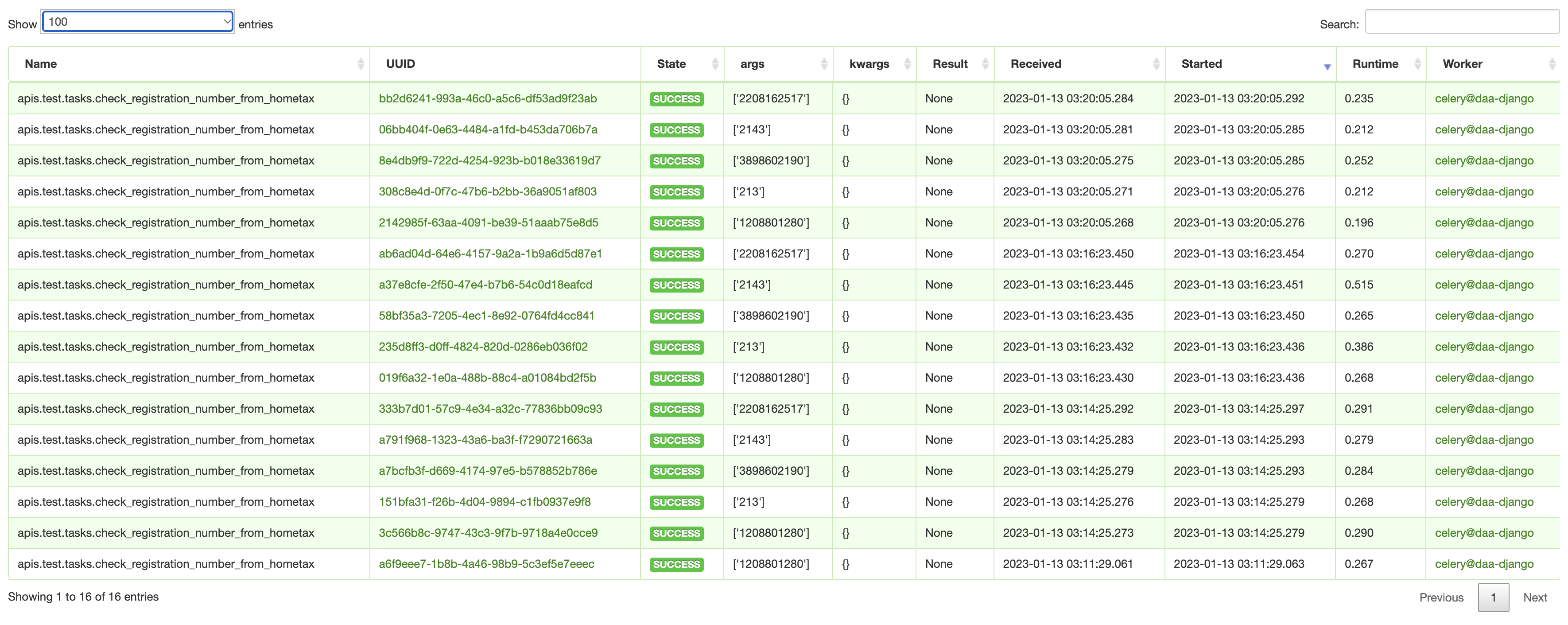
4. task 상태 및 실행 결과 확인 실습
-
해당 실습은 예시 파일을 만들고
python manage.py shell로 던져 결과를 확인 해 보자. apply_async를 delay로 어떻게 편하게 쓰는지, 그리고 result ignore는 어떻게 하는지 체크 하자. -
참고로 result(return) 값을 제대로 get 해오려면 task가 끝나는 시간보다 get 호출 시간이 빨라야 한다. 그래야 await 상태로 result(return)를 가져올 수 있다. ->
from time import sleep&sleep(1)을check_registration_number_from_hometax가장 위에 추가 해 줬다.
from celery.result import AsyncResult
from apis.test.tasks import check_registration_number_from_hometax
# delay와 apply_async
# task 변수들의 type: celery.result.AsyncResult(id, backend=None, task_name=None, app=None, parent=None)
task_1: AsyncResult = check_registration_number_from_hometax.delay("1208801280")
task_2: AsyncResult = check_registration_number_from_hometax.apply_async(args=["3898602190"], ignore_result=True)
task_3: AsyncResult = check_registration_number_from_hometax.apply_async(args=["123"], kwargs={})
print("# 1. Task UUID")
print(f"task_1 is {task_1.id}")
print(f"task_2 is {task_2.id}")
print(f"task_3 is {task_3.id}")
print("# 2. Task Status")
print(f"task_1 is ready? {task_1.ready()}")
print(f"task_2 is ready? {task_2.ready()}")
print(f"task_3 is ready? {task_3.ready()}")
print("# 3. Task Run and get return")
print(f"task_1 is {task_1.get()}")
print(f"task_2 is {task_2.get()}")
print(f"task_3 is {task_3.get()}")
print("# 4. Task Status again")
print(f"task_1 is ready? {task_1.ready()}")
print(f"task_2 is ready? {task_2.ready()}")
print(f"task_3 is ready? {task_3.ready()}")
print("# 5. When is the time task was done")
print(f"task_1 is {task_1.date_done}")
print(f"task_2 is {task_2.date_done}")
print(f"task_3 is {task_3.date_done}")- 위 파일을 만들고 (temp.py로 만듦),
python manage.py shell < temp.py로 던져주면 아래와 같은 결과를 얻을 수 있다.
# 1. Task UUID
task_1 is 01b361c2-48a9-4d6d-8749-2b7d87a3da5e
task_2 is 5a95b603-1801-4299-9b71-210a8618dea2
task_3 is 0d11d212-4738-4532-8366-86ecf86bab9d
# 2. Task Status
task_1 is ready? False
task_2 is ready? False
task_3 is ready? False
# 3. Task Run and get return
task_1 is None
task_2 is None
task_3 is None
# 4. Task Status again
task_1 is ready? True
task_2 is ready? False
task_3 is ready? True
# 5. When is the time task was done
task_1 is 2023-01-14 08:23:38.904629
task_2 is None
task_3 is 2023-01-14 08:23:38.904725
-
flower에서 알 수 있 듯, task_2 (7b6b4518-5ee9-4ff2-9114-0a2a6f56c08e) 역시 running은 아주 잘 되었지만,
ignore_result=True로 인해 status check가 안되는 것을 확인할 수 있다. -
참고로 결과는 "Celery 결과 작업을 다루는 객체",
celery.result.AsyncResultobject를 return 한다. 위 코드에서 볼 수 있듯, task 변수의 type은class celery.result.AsyncResult(id, backend=None, task_name=None, app=None, parent=None)이며 attribute는 공식 홈페이지 에서 더 확인할 수 있다.
subtask 만들고 다루기
1. s & si & signature (=subtask)

-
s 는
signature의 가장 단순한 shortcut 이다. :Shortcut for .s(*a, **k) -> .signature(a, k). -
si 는
signature의 shortcut인데, immutable signature 를 만들어 낸다. :Create immutable signature. Shortcut for .si(*a, **k) -> .signature(a, k, immutable=True). -
그래서
signature는? 핵심만 보면, 대기 상태의 Task를 생성 (다양한 파라미터를 준 채로)을 먼저하는 것이다. 그렇기 때문에 만들어진signature는 위에서의appy_async또는delay로 호출하여 실행할 수 있다. 그리고 "재사용" 이 가능해 진다.- 대기 상태이기 때문에 만들어진
signature를apply_async&delay로 실행을 해야한다는 것이다. - 그렇게 실행할 때 또 인자값을 추가하면
append가 된다.
- 대기 상태이기 때문에 만들어진
-
그리고 일반적인 task와 성격이 조금 다르다. 왜냐면 class (type) 자체가
Signature이다. task class는celery.app.task에 위치하며Signature는celery.canvas.signature이다.celery.canvas는 group화된, 즉 묶음으로 된 비동기 작업들을 다루는 것들과 관련이 있다.
@app.task
def add(num1: int, num2: int):
return num1 + num2- 위와 같이 아주 단순한 함수를 다음과 같은 형태로 활용이 가능하다.
add.signature(args=(1,), kwargs={'kw': 2}, options={})add.s(1, kw=2).s()shortcut 은 특정 실행 옵션값을 지원하지 않는다. 하지만 chaning 할 수 있는.setmethod 를 제공한다. (that returns the signature)add.s(2, 2).set(countdown=10).set(expires=30).delay()
# 2 + 2 + 4 + 8
>>> res = chain(add.s(2, 2), add.s(4), add.s(8))()
>>> res.get()
16
>>> (add.s(2, 2) | add.s(4) | add.s(8))().get()-
이렇게 사용이 가능하다. 위 예시에서 후자와 같이 파이프 로 묶어주는 것도 가능하다.
-
더 자세한 정보는 공식 홈페이지 에서 signature 를 확인하자
2. subtask 상태 및 실행 결과 확인 실습
-
위
apply_async예시에서view.py를 조금 바꿔보자. 생각해보면for - loop로 질의들어온 만큼 비동기 작업을 바로바로 하는 것은 worker 한 테 바로바로 쓸모없는 일을 너무 많이 시키는 것일 수도 있다. -
올바르지 못한 작업이 바로 호출 되어 에러를 일으킬 수도 있고, 제대로 정규화된 데이터가 들어가지 않을 수도, 잘 못된 작업 호출인데 계속 비동기 호출하여 더 크리티컬한 이슈를 일으킬 수도 있다.
-
물론 모든 경우가 그렇다는게 아니라 대응을 잘 한다면 당연히 위 내용과 상관없이
for - loop - apply_async를 해도 전혀 상관이 없지만,signature를 만들어 한 묶음으로 바로 비동기 작업을 실행해 보자!
# view.py
... 생략
def check_registration_number(request: Request):
... 생략
## as-is
# for registration_number in qry_list:
# registration_number = registration_number.strip()
# check_registration_number_from_hometax.apply_async(args=[registration_number], kwargs={})
## to-be
sub_task = [ check_registration_number_from_hometax.si(q) for q in qry_list ]
from celery import group
group(sub_task)()
... 생략sub_task = [ check_registration_number_from_hometax.si(q) for q in qry_list ]로 한 묶음으로 묶어버리고 (List[Signature]), group이라는 것을 통해 일괄적으로 비동기 실행해버렸다. (group & chain 에 대한 내용은 다음 글에서 다룰 예정이다.)
from typing import List
from celery.result import AsyncResult
from celery.canvas import Signature
from apis.test.tasks import check_registration_number_from_hometax
# Signature
stask_1: Signature = check_registration_number_from_hometax.si("1208801280")
stask_2: Signature = check_registration_number_from_hometax.signature(args=["3898602190"], ignore_result=False)
stask_3: Signature = check_registration_number_from_hometax.signature(ignore_result=True)
num_list = ["4535", "23415457463", "3424354673241", "23141", "23435329", "9992"]
task_list: List[Signature] = [ check_registration_number_from_hometax.si(num) for num in num_list ]
print("# 1. Check SubTask(Signature) UUID")
print(f"task_1 is {stask_1.id}")
print(f"task_2 is {stask_2.id}")
print(f"task_3 is {stask_3.id}")
print(f"task_4 is {task_list}")
# Excute Signature
task_1: AsyncResult = stask_1.delay()
task_2: AsyncResult = stask_2.apply_async(args=[], kwargs={}, countdown=3)
task_3: AsyncResult = stask_3.apply_async(args=["898989"], kwargs={})
print("# 2. SubTask(Signature) Status")
print(f"task_1 is ready? {task_1.ready()}")
print(f"task_2 is ready? {task_2.ready()}")
print(f"task_3 is ready? {task_3.ready()}")
print("# 3. SubTask(Signature) Run and get return")
print(f"task_1 is {task_1.get()}")
print(f"task_2 is {task_2.get()}")
print(f"task_3 is {task_3.get()}")
print("# 4. SubTask(Signature) List Run and get return")
task_list_result = list()
for task in task_list:
temp = task.delay()
print(temp.get())
task_list_result.append(temp)
print("# 5. SubTask(Signature) Status again")
print(f"task_1 is ready? {task_1.ready()}")
print(f"task_2 is ready? {task_2.ready()}")
print(f"task_3 is ready? {task_3.ready()}")
for task in task_list_result:
print(task.ready())
print("# 6. When is the time task was done")
print(f"task_1 is {task_1.date_done}")
print(f"task_2 is {task_2.date_done}")
print(f"task_3 is {task_3.date_done}")
for task in task_list_result:
print(task.date_done)- 위 파일을 만들고 (temp2.py로 만듦), python manage.py shell < temp2.py 로 던져주면 아래와 같은 결과를 얻을 수 있다.
# 1. Check SubTask(Signature) UUID
task_1 is None
task_2 is None
task_3 is None
task_4 is [apis.test.tasks.check_registration_number_from_hometax('4535'), apis.test.tasks.check_registration_number_from_hometax('23415457463'), apis.test.tasks.check_registration_number_from_hometax('3424354673241'), apis.test.tasks.check_registration_number_from_hometax('23141'), apis.test.tasks.check_registration_number_from_hometax('23435329'), apis.test.tasks.check_registration_number_from_hometax('9992')]
# 2. SubTask(Signature) Status
task_1 is ready? False
task_2 is ready? False
task_3 is ready? False
# 3. SubTask(Signature) Run and get return
task_1 is 1208801280: not close
task_2 is 3898602190: not close
task_3 is None
# 4. SubTask(Signature) List Run and get return
4535: closed
23415457463: closed
3424354673241: closed
23141: closed
23435329: closed
9992: closed
# 5. SubTask(Signature) Status again
task_1 is ready? True
task_2 is ready? True
task_3 is ready? False
True
True
True
True
True
True
# 6. When is the time task was done
task_1 is 2023-01-14 13:29:37.703932
task_2 is 2023-01-14 13:29:40.740860
task_3 is None
2023-01-14 13:29:41.885330
2023-01-14 13:29:43.030393
2023-01-14 13:29:44.184961
2023-01-14 13:29:45.398235
2023-01-14 13:29:46.548202
2023-01-14 13:29:47.744286-
subtask(signature)는 task 미리 만들어 두고 type은 Signature 이며 아직 uuid(id) 값은 없다.
-
쇼컷 사용 체크와 signature를 그냥 만들면 mutable(
immutable=False) 하기 때문에task_3: AsyncResult = stask_3.apply_async(args=["898989"], kwargs={})와 같이 만들어진 subtask(signature)를 수정할 수 있다. -
사실 만들어진 subtask(signature)에 args를 주면 해당 instance가 가진 args가 append 되어진 task가 되는 것과 같다.
-
task_2: AsyncResult = stask_2.apply_async(args=[], kwargs={}, countdown=3)에서countdown을 주었기 때문에 3초 뒤에 러닝되는 것을 확인할 수 있다. (위 파일대로 실행하면 countdown이 있는 get에서 3초 pendding되는 것을 볼 수 있다.) -
list 형태로 만들고 (Signature instance니까) 따로
apply_async할 수 있다.
3. subtask 활용 방향
-
apply_async는 Task가 독립적으로 각각 실행되는 (즉발) 경우에 적합 하며, subtask는 "연속" 된 Task나 Task를 "일괄처리" 하는데 적합하다.
-
subtask를 처리할 때 chain을 사용하여 연속된 Task를 처리하고, chord를 사용하여 일괄처리 할 수 있다. 해당 부분은 다음 글에서 다룰 예정이다.
단점
그래서 셀러리가 만능이냐?
- push notification을 execute하는 celery function이 있다고 하자. "병목" 현상 때문에 새벽 2시, 3시에 느닷없이 늦어진 push noti를 받는 고객이 생길 수 있다. "잘 알고 써야한다!"
Broker
-
첫 번째 페인포인트 이다. 이전과 이번 글을 보면 알수 있듯, Broker(Message Que) 에게 task를 가장 먼저 던진다. 그래서 이 Broker는 중추 신경계이다. 모든 message que를 broker로써 사용할 수 없다.
-
탄생 자체가 RabbitMQ랑 쓸려고 만들어졌다. 그러다보니 RabbitMQ의 AMQP protocol을 모사하는 방식으로 다른 브로커 stack을 지원한다. 여기서 버전에 따라 제공되는 기능과 제공안되는 기능이 있다.
acks_late=True
-
AMQP를 모사함에 따라 생길 수 있는 이슈는, 브로커가 worker에게 일을 나눠주고 ack를 받는게 AMQP의 기본 형태다. ack는 일을 잘 처리 했다라는 응답이고, 이 응답이 오지 않으면 다시 보낸다. celery는 다른 브로커에서 AMQP를 모사하기 위해 이 시간을 "visivility timeout" 값으로 구현했다.
-
기본 ack는 worker가 task를 excute하기 "직전"에 준다. fail case의 경우
Ack > que에서 제거 > excute > fail ~ 빠빠이~가 된다. 그래서acks_late=True로 주어서 task가 실행이 다 되고 나서 ack를 주게 만들면excute > fail ~ 빠빠이 > ...?가 될 수 있기 때문에 ack를 받지 못해 다시 일을 한다. -
즉 visivility timeout 내에 ack가 전달되지 않으면 task가 중복 실행 된다. => 여기서 중요하게 체크할 부분이 바로 위에서 살펴본 실제 일을 수행하는 function인
apply_async의eta&countdown값이다. -
즉 중복 실행을 막기 위해서는
eta&countdown시간 보다 visivility timeout 값이 커야한다. 또 AWS SQS의 경우 최대 시간제한은 12시간이라 12시간 이후에 갑자기 task가 중복실행이 될 수 있다. -
Redis의 경우 설정을 제대로 하지 않는다면 메모리가 부족한 상황에서 임의로 key가 삭제될 수 있다. [NHN FORWARD] Redis 야무지게 사용하기, Redis 운영팁 글을 체크해 보자.
-
AWS SQS는 API 요청당 과금에 Pub/Sub 형태보다는 Polling 형태이다. 그렇기때문에 polling 할 때마다 과금된다. 그리고 Monitoring을 지원하지 않아 해당 부분 예기치 못한 이슈 대응 및 디버깅에 좋지 못하다.
Prefetch
Prefetch is a term inherited from AMQP that’s often misunderstood by users. - celery optimizing 공식 홈페이지 글
-
prefetch 라 함은 worker가 자기 공간 - 버퍼에 미리 task를 땡겨오는 것 처럼 이해가 된다. 하지만 그렇지 않다!
-
prefetch limit은 broker에서 worker로 분배하는 로직이다. 이 값이 4라고 하자 & (task도 4개가 만들어졌다고 가정). 3개는 빨리 끝나고(0.1초) 1개는 상대적으로 시간이(1초) 걸린다고 하자. 그러면 4개의 워커가 3개 작업을 하고, 1개의 긴 작업을 하고 있다.
-
3개의 워커는 먼저 일을 끝낼 것이다. 그러면 M.Q에 들어가 있는 작업을 broker에게 빨리 받아와야 할 것이다. 하지만 그렇지 않다. 상대적으로 시간이 긴 1초짜리 작업까지 모두 끝내야 ack를 준다.
-
그렇기 때문에, prefetch 단위 내에서 빨리 일을 끝낸 워커는 멍때리고 1초 기다리고, 다시 작업을 가져온다.
셀러리가 일을 제대로 처리를 못하니 broker queue에 계속 쌓이기만 해요!!
위 이유들 때문에 결국 이런 문제까지 이어질 수 있다.
어떻게 최대한 핸들링하고 해결할 수 있을까?
1. 한 바구니에 다 담지 말자, task를 한 큐에 다 담지말자!
-
바로 위에서 언급 했듯, prefetch 특성때문에 수행 시간이 비슷한 것들을 같은 queue에 있는게 성능적으로 유리하다.
-
역시 task의 절대적인 수 자체도 퍼포먼스에 중요한 영향을 준다. 그렇기 때문에 처리의 중요도 & 시급도 (Priority)에 따른 분류도 중요하다.
-
위 부분에 따라 queue를 분산해서 사용하면 오히려 celery의 처리 능력이 올라간다. 이 경우
task_routes를 세팅해서 큐를 분산시킬 수 있다. (나중에 다시 다룰 예정입니다.)
2. prefetch & prefork 설정 팁
-
긴 task에 대해서는
worker_prefetch_multiplier을 1 로 설정해주고,acks_late를True로 해주면 실행 중인 task 1개를 끝낼 때 마다 queue에서 떙겨오기 떄문에 불필요 하게 다른 worker들이 쉬게 되는 일이 없다. -
위 (1)에서 언급한 분산 broker queue라면, long-time task의 경우만 다루는 queue에 이렇게 설정하면 꽤 괜찮은 퍼포먼스 향상을 노릴 수 있다.
-
위에서 언급하였듯이
prefetch limit은 broker에서 worker로 분배하는 로직이고, 해당 worker안에서 분배하는게prefork이다. -
celery worker 실행하는 커멘드에
-Ofair를 줄 수 있다. (celery worker의optimization=fair로) 이렇게 하면, 기본적으로 celery worker가 자기 버퍼가 가득 찰 때까지 받아서 하는 작업을 worker안에서 Master가 분배하는 방법으로, 일 안하고 있는 worker에서 일을 시키게 된다.
#!/bin/sh
if [ $1 = "beat" ] ; then
celery -A path.to.celery.app beat --loglevel=INFO
else
celery -A path.to.celery.app worker --concurrency=4 --loglevel=INFO --without-gossip --without-mingle --without-heartbeat -Ofair
fi3. 성능에 은근 영향을 많이 주는 요소
-
ignore_result를 위에서 언급했다. celery는 기본적으로 수행 결과(return)을 "저장" 하는 작업이 이뤄져야 끝이난다. (끝이 났다고 판단한다. 그리고 기본값이 true이다.) -
하지만 사실 우리가 celery task에서 return 값을 쓰는 시나리오 자체가 드물다. 그래서 task 체이닝, 선후행이 있을 때나 사용할 법 하다.
-
결과 자체를 저장하는 비용이 꽤 크기 때문에 이 값을
False만 줘도 성능 향상을 느낄 수 있다.
출처
- https://docs.celeryq.dev/en/stable/reference/celery.app.task.html
https://docs.celeryq.dev/en/stable/_modules/celery/app/task.html#Task.apply_async - https://www.youtube.com/watch?v=3C8gBRhtkHk
- https://www.youtube.com/watch?v=vGPyjJ1jWUs
- https://heodolf.tistory.com/63
- https://blog.hannal.com/2015/07/celery_chord_and_chain/
- 다음 subtask를 group 단위로 다루는 글도 봐주세요 :), celery의 thread & pool & concurrency에 대한 글도 작성할 예정입니다.

좋은 글 감사합니다! 새로운 프로젝트에 도움이 많이 됐어요