
[ 글의 목적: PyCon korea에서 다루는 제일 최근의 celery 세션, "셀러리 핵심과 커스터마이제이션" 정리 및 celery를 진짜 제대로 사용하기 ]
Django Celery, 핵심과 customization
celery에 대한 글만 해당 시리즈에서, 이 글을 포함해 벌써 5개다. 그만큼 celery는 django를 확실히 Enterprise 급으로 올려줄 수 있는 좋은 worker이자 비동기 작업의 수단이다. 2019 pycon에서 다룬 celery에 대한 얘기를 통해 celery에 대한 시리즈글을 마무리하려고 한다. 해당 영상은 여기서 확인 가능하다.
-
pycon에서 celery를 다룬 세션은 꽤 많고, celery가 지속적인 업데이트가 됌에 따라 pycon에서도 꽤 지속적으로 업로드가 되는 것 같다. 그 중 가장 최근의 영상을 리뷰잉 하려고 한다. (하지만 3년전 영상이라는 점 주의! 그래도 현 버전 기준으로 다른 내용은 없다!)
-
celery 자체에 대한 설명 및 내용, 코드레벨의 task 세팅 등의 내용은 모두 제외 했다. 해당 내용은 지금 시리즈의 앞 글들을 꼭 확인하길 바란다!
1. 안정적으로 완료하기
-
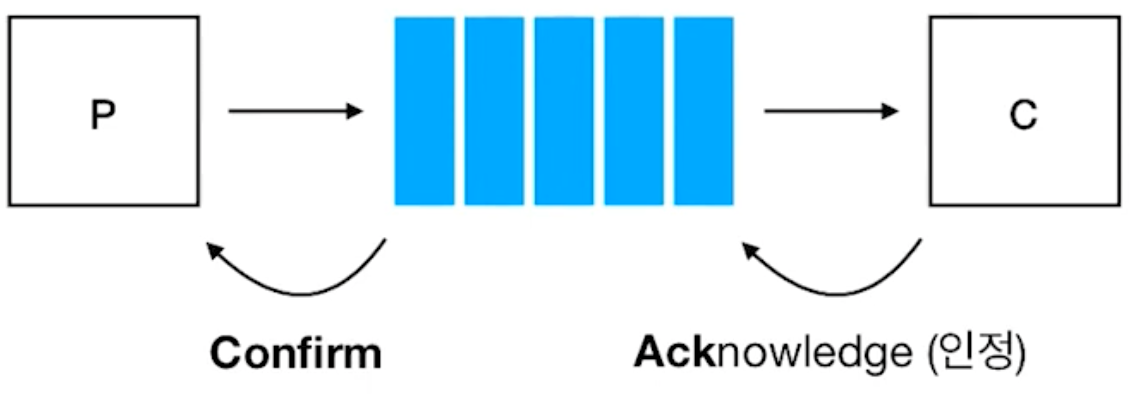
앞 글, 그리고 메시지큐 글 시리즈에서 많이 언급했고, rabbit MQ를 알고 있으면 이미 해당 프로토콜도 알것이다!
-
AMQP(Advanced Message Queueing Protocol) 기반을 염두에 두고 만들어졌다. "최소한 한번은 전달된다" 가 핵심 아이디어 이며, ack는 consumer가 broker에게 메시지를 잘 받았다고 주는 signal이며, broker는 그 signal을 받으면 queue에서 제거 한다는 의미다.
-
즉, 여러번 전달 될 수도 있다는 의미를 가진다.
-
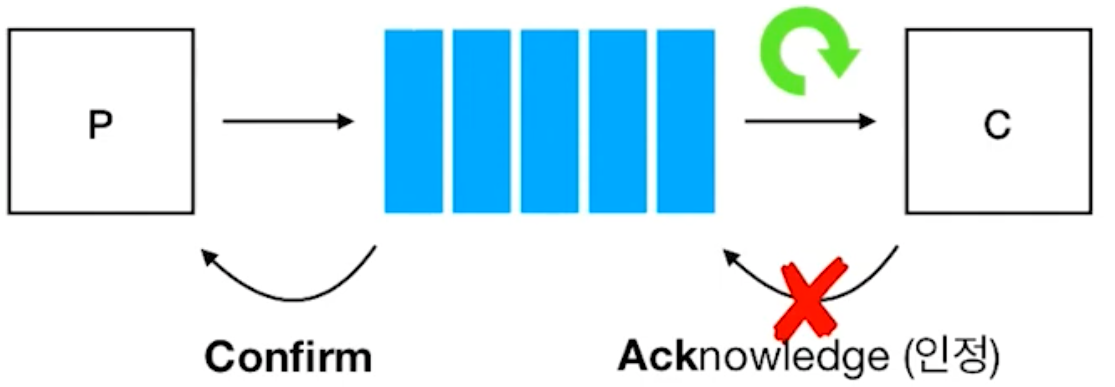
consumer가 ack를 주지않으면, queue에서 제거가 안되며, 다시 excute된다. 그래서 message에 대한 처리를 idempotent 해야 한다. "멱등성" 으로 해석이 가능하다.
-
idempotent는
f(f(x)) = f(x) = y를 만족할 때, 프로그래밍에서 위 수식을 그대로,f: operation,x: system state before excute,y: system state after excute정도로 대입이 가능하다.
1) late ack
-
task 실행 도중 worker에 문제가 생겨서 종료가 된 경우
-
ack는 기본적(default)으로 task가 "실행하기 직전" 에 ack를 준다. -> consumer가 메시지를 잘 받았다는 그 자체로만 해석하기 때문이다.
-
이 경우 queue에서는 제거가 되었지만 worker crah로 인해 work자체가 excute가 제대로 되지 못한채로 "잊혀지게 된다".
-
그래서 이런 실패케이스를 대응하기 위해
acks_late=true를 줄 수 있다. 이 경우, 위 issue에도 queue에 존재하기 때문에 재처리를 성공적으로 할 수 있다. 이 경우 중복실행의 가능성이 당연해 지고, 더욱이 위에서 언급한 task의 idempotent, 멱등성이 중요하다.
2) retry: 외부 Network I/O 간헐적 실패
- 우리쪽에서 통제할 수 없는, 특히 network I/O에서 외부 api call할 때 간헐적 실패의 경우, task가 가지고 있는
"retry"method를 활용하면 된다. 공식 페이지를 참고하려면 클릭
@app.task(bind=True)
def send_twitter_status(self, oauth, tweet):
try:
twitter = Twitter(oauth)
twitter.update_status(tweet)
except (Twitter.FailWhaleError, Twitter.LoginError) as exc:
raise self.retry(exc=exc)
-
retry를 사용할때 굉장히 중요한 점은 "Atomicity" 를 지키는 것과 exception 처리에 확실히 공을 들여야 하는 것이다. -> 즉 예상 불가능한 exception에 무지성 retry를 하다가는 참사가 있을 수 있다. 예상 가능한 exception에, 그리고 확실하게 retry가 될 때만 exception + retry를 활용하자.
-
그리고 "result backend" 가 enabled되어야 retry exception에 대한 task state를 정확하게 파악할 수 있다.
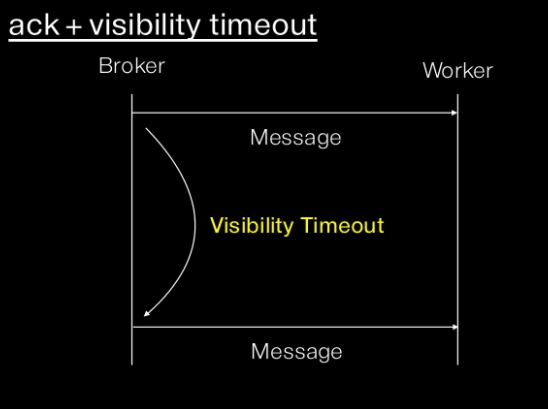
3) visibility timeout 활용하기
- visibility timeout 은 전달 후 일정시간내로
ack되지 않으면 다른 worker에게 task를 전달해 처리하게 하는 것이다. -> 즉eta (or countdown) > visibility timeout이면 다시 실행하게 된다.
-
ETA 나 countdown을 설정하면 최소한 그 시각 이후에 실행됨을 보장할 뿐 반드시 해당시각에 실행되는것은 아니다. 큐에 많은 태스크가 대기하고 있어가 네트웍 latency가 높으면 더 늦게 실행될 수도 있다.
-
사실 이런 이슈는 redis는 내부적으로 AMQP를 사용하지 않고, celery는 rabbitMQ를 기본으로 잡고 만들어졌기 때문이다. celery는 내부적으로 redis만을 위한 AMQP를 모사하는 방식으로 개발 되어 있는데 이 때문에 발생한다. 이게 싫으면 rabbitmq 사용하면 된다 :)
2. 효율적으로 처리하기
1) 처리 속도 < 쌓이는 속도
-
일시적으로는 일어날 수 있는 일이다. 하지만 지속되는 경우 브로커에 불필요한 로드가 계속 가며 그에따라 꼭 실행되어야 하는 task가 미뤄지다가 excute 안될 수 도 있다.
-
그래서 이때 task의 절대 수명을 줘버리는 것도 좋다.
soft_time_limit와hard_time_limit값으로 task의 절대 수명을 컨트롤 할 수 있다. -
soft_time_limit의 경우 해당 시간을 넘기면SoftTimeLimitExceeded를 raise 하고, forcefully terminated 되지는 않는다! -
hard_time_limit의 경우 해당 시간을 넘기면 완료 여부와 상관없이 forcibly terminated 되며,TimeLimitExceeded를 raise 한다. 이 경우 terminated 된 task 내부 code에 의해 catch 될 수 없다.
from celery.exceptions import SoftTimeLimitExceeded
@celery.task(time_limit=20)
def mytask():
try:
return do_work()
except SoftTimeLimitExceeded:
cleanup_in_a_hurry()
# or
mytask.apply_async(args=[], kwargs={}, time_limit=30, soft_time_limit=10)- 또는 global 설정으로
task_soft_time_limit값을 아래와 같이 줄 수 있다. 이 경우 위에서 언급한soft_time_limit등의 값으로 override할 수 있다.
from celery import Celery
app = Celery('myapp', broker=...)
app.conf.task_soft_time_limit = 10 # set global soft time limit to 10 seconds- 그리고 rate limit 자체를 세팅하는 것이다. 이를 통해 task가 일정 빈도 이상 실행되지 못하도록 세팅할 수 있다. 위 예시를 이어서
app.conf.task_default_rate_limit = '10/m'를 통해 10개 task를 분당 처리량으로 고정할 수 있다.
2) concurrency, worker pool
- 우리가 celery worker를 구동할 때 사용하는 스크립트 형태는 아래와 같다.
celery -A <prj> worker -P <worker_name> -c <concurrency>-
여기서 말하는
worker pool은 결국concurrency를 어떻게 구현했냐와 같다. 대표적인 형태는prefork,gevent,eventlet,solo와 같은 option을 줄 수 있다. -
prefork는 prefetch와 구분하기 위해, prefetch를 살펴본 뒤 다시 체크하자! 그리고 위 에서 언급한 option들은 모두 worker pool을 어떻게 control할 것이냐 라는 점을 잊으면 안된다!!
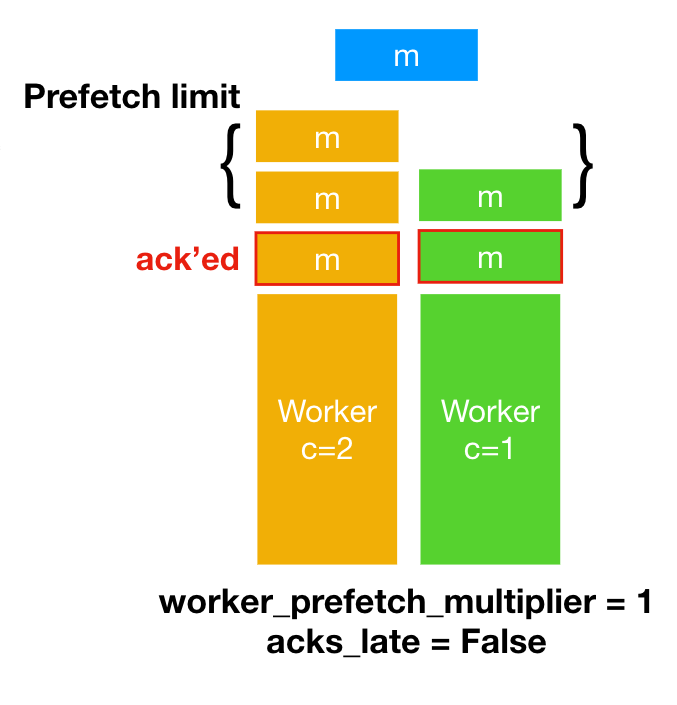
3) Prefetch Limit
-
"worker pool과 무관하다!". 개념적으로 햇갈릴 수 있지만, 해당 시리즈 celery의 앞 선글에서도 많이 언급했 듯, prefetch는 동시성 및 처리량에 대한 얘기가 아니라 ack가 안된 message(task)를 worker가 한 번에 가질 수 있는 최대 값, 즉 한 번에 얼마나 많은 양의 task를 미리 가지고 있을 수 있냐 에 대한 얘기 이다.
-
worker_prefetch_multiplierconfig 값으로 global하게 prefetch 개수를 설정할 수 있다.0으로 설정한다면, prefetch 개수를 0으로 생각하며 메모리 및 효율성을 고려하지 않고 계속해서 excute하게 된다.
-
acks_late가False이면서 (받자 마자 ack),worker_prefetch_multiplier = 1세팅을 했다면concurrency가 2인 worker는 2개의 task를 prefetch 하고(좌측), 1인 worker는 1개의 task를 prefetch 한다(우측). 이 prefetch되는 개수 제한을 prefetch limit 라고 한다. -
Long tasks인 경우,
worker_prefetch_multiplier = 1&acks_late = True라면 지금 실행중인 테스크만 prefetch 하게 된다. -> 미리 prefetch 하는 경우하고 대기하는 task가 없다!
4) Prefork - worker pool
- python에서 multi processing 처리를 하는 것과 동일하다.
celery -A <prj> worker -P <worker_name> -c N으로 worker를 구동하면 1개의 master(main) process, N개의 child(forked, sub) process 가 만들어지는 것이다. 내부적으로 python의 multiprocessing 과 동일하게 처리한다!

-
"메모리 사용량" (child process forking하는데 있어서 부모를 그대로 복-붙 하기 때문) & "초기 구동 속도" (파이썬 멀프를 사용하면 알겠지만 child process를 마냥 늘린다고 만능이 아니고 오히려 어느 구간에서는 더 적은 child를 사용할 때 보다 전체 처리량이 늦어진다) 의 측면에서 손해가 있을 수 있다. 이때 5) 에서 살펴볼
GeventandEventlet을 사용할 수 있다. -
우선 python core - multiprocessing의 example을 보고 싶으면 아래 예시를 실행해 보자
from time import sleep
import multiprocessing
def square(num):
sleep(2)
return num * num
if __name__ == '__main__':
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Create a multiprocessing pool with 4 processes
pool = multiprocessing.Pool(processes=4)
# Map the square function onto the list of numbers
results = pool.map(square, numbers)
# Print the results
print(results)-O fair
-
이 prefork에서 중요한 옵션은
-O fair이다. master 에서 child에서 task를 분배하는 작업에 있어서 prefork는 기본적으로 pipe buffer가 허용하는 만큼의 메시지만 전달 한다. 하지만-O fairoption을 통해 실행 가능할 경우만 전달 가능하다. -
긴 작업과 짧은 작업이 섞여 있다면, 긴 작업때문에 prefetched task가 실행되지 못하게 된다. 이 경우 "성능 향상" 과 "예상 가능한 동작" 을 기대하기 위해
-O fairoption을 주면, 마치 "한줄 서기의 과학" 과 같이 줄이 더 빨리 줄어는 것과 같은 원리다.
5) Gevent & Eventlet
-
위에서 언급한 것과 같이, prefork의 multiprocessing이 만능이 아니기에, Gevent & Eventlet 를 활용할 수 있다.
-
얘를 사용하는 컨셉은 "수천 개의 HTTP GET 요청과 같은 network I/O ..." 경우 CPU bound가 아니라 그저 응답이 올때까지 기다려야 하는 경우가 대부분이다. 당연히 이 병목은 CPU 퍼포먼스가 아니라 prefork 컨셉에는 맞지 않을 수 있다. 마냥 프로세스를 추가하면 오버헤드만 계속 커질 수 있다. 그래서 thread를 수천개를 만드는 컨셉으로 접근하는 것이다.
-
그래서 스레드 기반 실행 풀 (eventlet & gevent)이 있는 것이고, 실행 풀은 celery 작어 자체와 동일한 프로세스에서 실행된다. 더 정확하게는 "thread 보다는 greenlet을 사용한다" 이 얘기는 전혀 다른 쪽의 깊은 얘기가 될 것 같아 파고들지 않겠다. 일단 greenlet은 기본 운영 체제 기능에 의존하지 않고 다중 스레드 환경을 에뮬레이트 한다.
-
gevent와 eventlet의 핵심 차이는 전자가 gevent Greenlet 풀(
gevent.pool.Pool) 을 사용하고, 후자는 eventlet Greenlet 풀(eventlet.GreenPool) 을 사용하는 것이다. -
일단 CELERYD_CONCURRENCY 값 (위에서 worker 실행시 주는 -c 값) 이 1보다 커야 한다.
6) Queues, 다중 큐 사용하기
-
message를 저장하는 queue를 분리하는 것이 일단 가장 쉽고 빠르게 퍼포먼스를 올릴 수 있는 방법이라 생각한다.
-
작업의 성질에 따라 중요도, 수행시간, 실행의 빈도에 따라 queue 자체를 분리해서 작업을 분배한다면, 애시당초 위 1~5에서 고려한 것 보다 쉽게 "물리적 분리"를 꽤할 수 있다.
from celery import Celery
app = Celery('tasks', backend='...', broker='...')
app.conf.update(
CELERY_TASK_SERIALIZER='json',
...
CELERY_ROUTES={
'tasks.add': {'queue': 'queue1'},
'tasks.multiply': {'queue': 'queue2'},
}
)- 위와 같이 task를 가져와서 바로 queue를 나눌 수 있지만, 우선 queue자체를 먼저 만들고, 다음에 추가될 task를 어디에 분배할지 세팅하는게 낫다.
from kombu import Queue
from celery import Celery
app = Celery('tasks', backend='...', broker='...')
app.conf.update(
CELERY_TASK_SERIALIZER='json',
...
)
app.conf.task_default_queue = "default"
app.conf.task_queues = (
Queue("default", routing_key="task.#"),
Queue("sub", routing_key="sub.#"),
)- 위와 같이 세팅하고
celery -A config.celery_app worker -Q sub -n sub@$HOSTNAME --loglevel DEBUG와 같이 worker를 구동할 수 있다.
3. 배포와 Customization
-
celery를 사용하고, 초기엔 django와 동일 서버에 있던 worker를 이제 분리 하려고 할 것이다. 사실 django application file만 있으면 celery를 어느 서버에서든 둘 수 있고, M.Q 도 다른 서버에 두면서 3개의 덩어리 [ django app + celery worker + M.Q ] 의 분산 모놀로식 세팅은 간단하다.
-
그리고 celery worker는 데모나이징을 하는 것이 좋다. 데모나이징에 물음표가 있다면 리눅스 데몬 글을 한 번 보는 것을 추천한다.
-
AWS의 EB(elastic beanstalk을 예시로, profile을 통해 정의된 러닝 프로세스들은 알아서 데모나이징해주며 service에 등록된다. 이렇게 관리하는게 좋다. 아래는 실제 내가 느낀 celery 세팅시 아주 기본적으로 가져가면 좋은 것들이다.
- django app, worker, mq의 분산 서버 구조는 시작부터 가져가는 것을 추천한다. 그리고 result_backend는 사용하자! (그러기에 차라리 rabbitmq보다는 redis를 추천한다. 그 redis에 대한 메시지 유실율을 없애고 싶다면 클러스터링과 같이 고려!)
- "다중큐" 정도는 일단 세팅하는 것을 추천한다. depth있는 최적화를 가져가기 전에 큐 자체를 분리해서 쉽게 쉽게 다중 처리를 꽤할 수 있다.
- celery matric 정보를 활용해 monitoring을 하자. 즉, [ celery flower + prometheus + grafana ] 와 같은 stack은 고려를 하고 구성하자.
- 일단 위 3개로 celery 세팅을 시작하고 depth있는 최적화를 위해 하나하나 분석하면서 2. 효율적으로 처리하기 부분을 다시 고려하는 것을 정말로 추천한다.
rate limit는 worker 별로 관리 된다.
- 예로, rate limit을 분당 60개로 해두었는데 worker가 2개라면, 각 60개씩 가져가 실제 1분에 120개 처리되는 현상이 발생했다. 실제 celery core는 아래와 같이 처리해 뒀다.
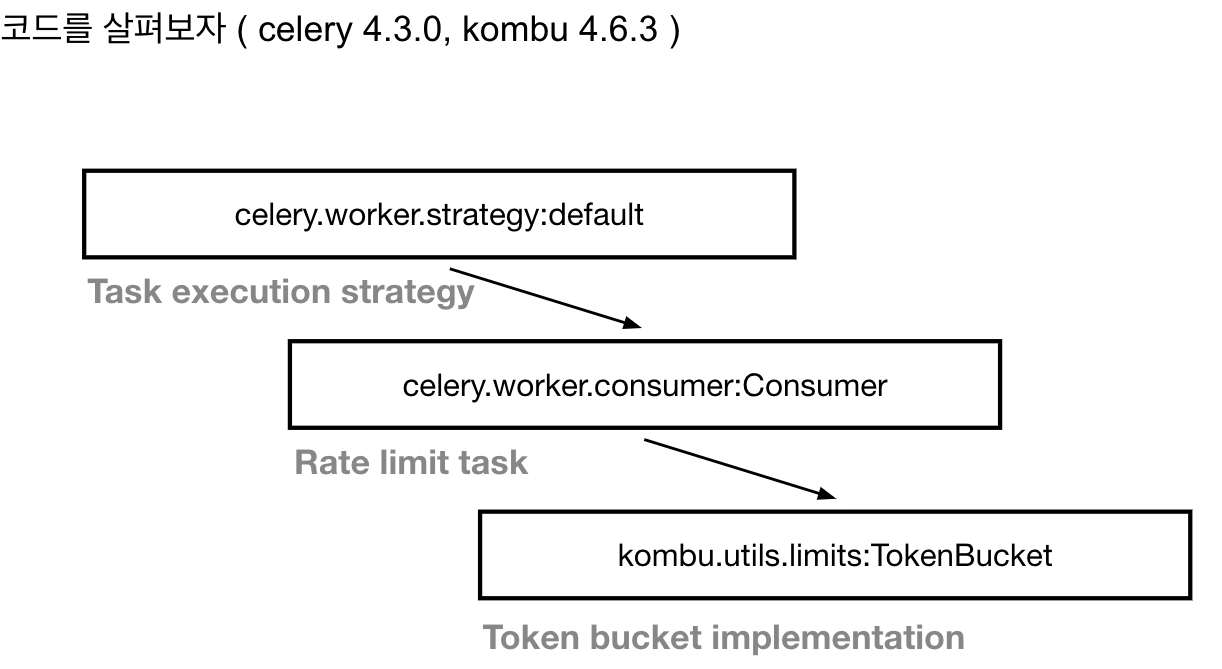
- 참고로
kombu는 celery가 사용하는 messaging library이다.TokenBucket을 이용해 rate limit를 control하고 있다.
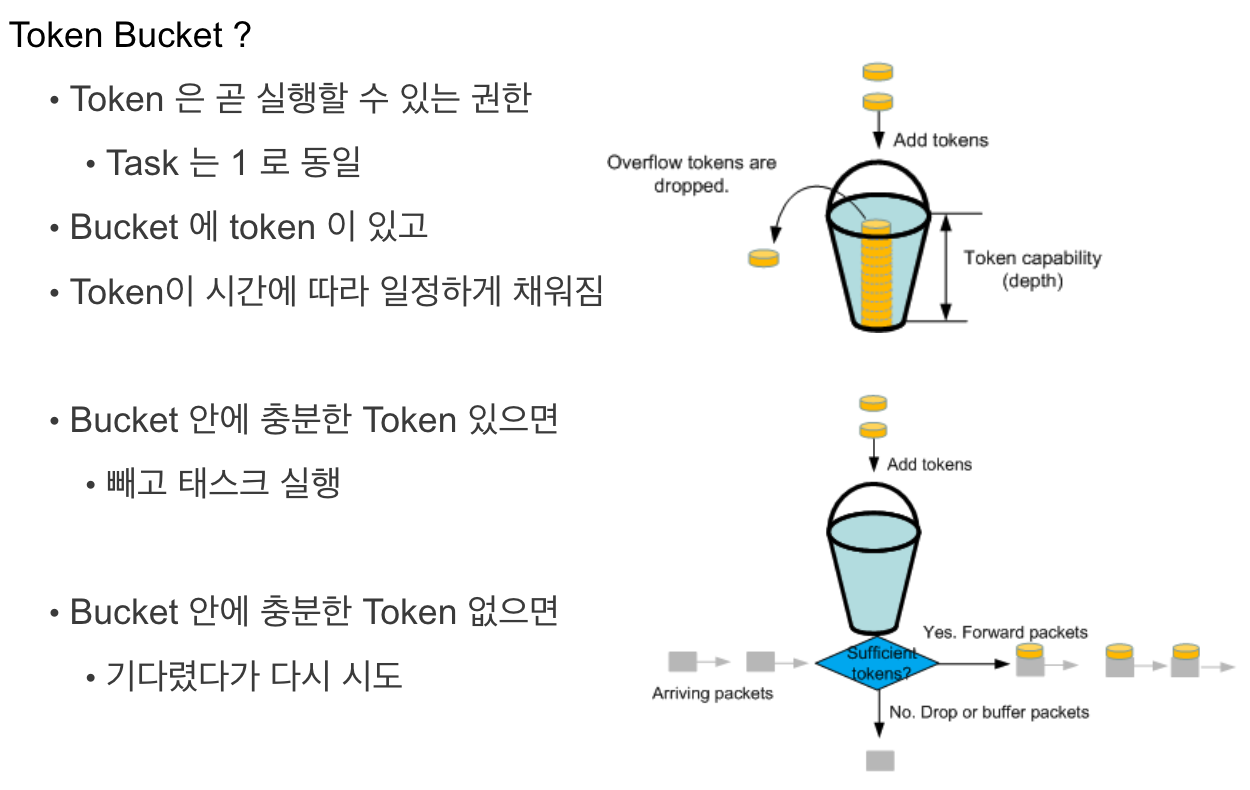
- 위 ppt 장표와 같이 세팅된 token 값 ->
_get_tokens라는 method를 override 해서 세팅하면 토큰 버켓을 조금 더 정교하게 세팅이 가능하다. 이 부분은 직접 해당 pycon 발표를 보는것을 강력추천한다.
출처
