
[ 글의 목적: celery의 task 활용법에 대해 더 자세히 알아보고, 정리한 뒤 실습을 통해 고도화 & 예제 만들기 ]
Django Celery
앞 글에서는 task 자체와 실행에 초점이 좀 더 맞춰져 있었다. 이제 task의 선&후행 실행(chaining)과 grouping하여 chord와 같이 task를 묶고
for-loop없이 한 꺼번에 비동기 작업을 수행하는 것에 대해 체크해 보자.
우선 등장하게 될 예제는 https://github.com/Nuung/django-all-about 레포 기준으로 진행한다.
Chain
1. 선, 후행 task
-
task를 단일로 비동기 실행을 하면, 선-후행을 위해 결과를 기다릴 수 밖에 없는 (
.get활용) 형태로 이뤄졌다. 사실 이렇게 접근하면 blocking이나 다름이 없다. 그리고 또, 결과값을 참조해 후행 배치를 돌려야 한다면, 역시 단일 task끼리apply_async만 하는 것은 한계가 있었다. -
앞 글에서 예시와 같이 연속적인 덧셈이 있는
res = chain(add.s(2, 2), add.s(4), add.s(8))()코드를 잠깐 떠올려보자. 수행 형태는2 + 2&+ 4&+ 8=16으로 연산이 되었다. -
subtask(
s,si,signature)를 사용하여Taskobject instance를 리스트나 튜플에 담거나 비트연산자로(파이프) 연결 하여 사용할 수 있다.- 처음 실행되는 Task에만 전달할 수 있는 인자값을 (사용자 정의 인자값 중) 넣는다.
- 이후 실행되는 후행 Task에는 받아야 할 첫 인자값은, 선행에서 return되는 것으로 사용된다. 첫 인자 값 외에 다른 인자값을 사용해야 한다.
get() 사용을 피하자

-
위에서 말한대로 어짜피 첫 인자값은 선행 함수의 return값으로 받아진다.
-
위 사진 예시와 같이 chaning없이 get -> next function (result) get -> ... 과 같이 진행하면 그냥 동기식으로 함수배치한 것과 행위가 다르지 않고
update_page_info를 호출한 부분에서는 chaning된 모든 함수가wait만 하고 있는 기적을 볼 수 있다. 그리고 race-condtion(교착상태) 의 위험도 같이 안게된다.
2. subtask chaning 실습
@app.task
def add(num1: int, num2: int):
return num1 + num2
>>> res = chain(add.s(2, 2), add.s(4), add.s(8))()
>>> res.get()
16
>>> (add.s(2, 2) | add.s(4) | add.s(8))().get()
16-
앞 선 시리즈에서도 위와 같이 간단한 예시를 보았다. 좋은 example은 아니지만 실제 chain을 사용할 만한 시나리오로 case test를 해보자. (코드는 상단에 깃허브 레포를 참고해 주세요.)
-
(1)고객이 장바구니에 물건을 담았다. 결제하지 않고 담기만 한게 1개 이상인 것들을 cart_id / user_id 형태로 lsit를 만들어 return 한다. (2) 해당 list 를 받은 함수는 고객에게 마케팅 성격의 어떤 action 을 취한다. (예를 들자면 push noti, sms noti 로 장바구니 세일 등과 같은)
# models.py
class CartStatus(models.TextChoices):
DEFAULT = "DE", _("Default value")
DONE = "DN", _("End of purchase value")
CANCEL = "CN", _("Cancel or delete value")
class Cart(models.Model):
uesr = models.ForeignKey(User, on_delete=models.CASCADE, blank=False, null=False)
product = models.ForeignKey(
Product, on_delete=models.CASCADE, blank=False, null=False
)
status = models.CharField(
max_length=2,
choices=CartStatus.choices,
default=CartStatus.DEFAULT,
)
# tasks.py
@app.task
def get_carted_items():
target_cart_items = list(
Cart.objects.filter(
Q(user__isnull=False),
status=CartStatus.DEFAULT,
)
.select_related("user")
.values_list("id", "user")
)
return target_cart_items
@app.task
def fetch_noti(target_id_list: List[Tuple]):
for cart_id, user_id in target_id_list:
logger.info(f"{cart_id}, {user_id}")
def cart_and_noti():
res = chain(get_carted_items.s(), fetch_noti.s())()
logger.info(f"res >> {res}")
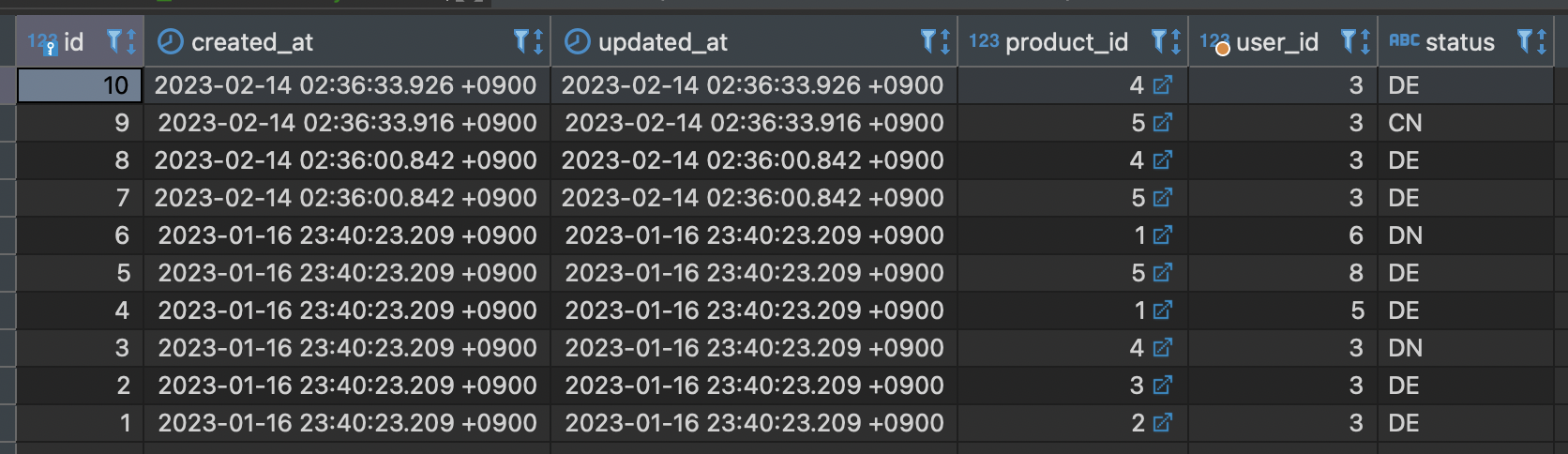
get_carted_items()를 통해 총 7개의 cart item이 return 된다. 그리고 chain에서 comma(,) 를 통해 chaining된 task -fetch_noti는 어떤 args 전달도 할 필요없이 선행 task가 return한 args를 물고 작업에 들어간다.


- 생각보다 chain이 "완전 동시성" 을 목표로 하는 task에는 어울리지 않으며, 초점 자체가 좀 더 method 선후행에 맞춰져 있는 것을 알수 있다. 특히, 오히려, official docs에서는 Network I/O 에서 [ request & data parsing - 데이터 전,후 처리 & data save to db ] 의 하나의 세트 성격의 분리된 작업을 chain으로 묶어서 만들고, 그 덩어리를 모아서 동시성 작업으로 돌리는 것을 볼 수 있다.
- 외에 단순히 생각해보면, task를 signature 로 만들어서 줄줄이 이은 다음에
chain(tasks)()할수 있다. 하지만 굳이 서로 선행 후행과 관련 없는 작업을 이렇게 실행하는 것은 동시성과 비동기의 특수성을 전혀 이용하지 않는 것이다. 그러면 줄줄이 이은 작업을 어떻게 "동시성"을 가지고 실행할 수 있을까
Group
- 그래서 필요한게
group이다. 사실 앞서 본 chain에서 비트연산자 (|) 를 통해 task를 엮는 것, 그리고listortuple에 담아서 만드는 것 자체가 "group" 성격의 task를 만드는 것과 동일하다.
1. task group으로 묶기
-
단순한 작업부터 group으로 묶어보자. 위에서 살펴본 덧셈을 그대로 가져와서 사용해보자.
-
tasks = [ add.s( i, i+1 ) for i in range(1, 5) ]이렇게list로 만들어서grouping = group(tasks)으로 묶어준다.group_task = grouping() # 또는 grouping.apply_async()로 바로 실행이 가능하다. group을 만들자 마자 실행하고 싶으면group(tasks)()또한 가능하다.
2. 상태 및 실행 결과 확인 실습
- 여기서 사용하는 함수
check_registration_number_from_hometax는 바로 앞 글에서 사용한 "홈텍스에서 사업자 번호로 폐업 여부 확인하는 API"를 활용한 Network I/O 작업이다.
import random
from celery import group
from celery.result import GroupResult
from apis.test.tasks import check_registration_number_from_hometax
def generates_number() -> str:
return "".join(str(random.randint(0, 9)) for _ in range(10))
tasks = [
check_registration_number_from_hometax.si(generates_number()) for _ in range(20)
]
grouped = group(tasks)
grouped_task: GroupResult = grouped()
print("# 1. Check Tasks")
print(f"tasks is {tasks}")
print("# 2. Check Grouped Tasks and Id")
print(f"grouped_task is {grouped_task}")
print(f"grouped_tasks's id is {grouped_task.id}")
print("# 3. Check Grouped Tasks's Status")
print(f"grouped_task status is {grouped_task.ready()}")
print("# 4. Check result of Grouped Task")
print(f"How many tasks are compeleted >> {grouped_task.completed_count()}")
print(f"Get the result of grouped_task >> {grouped_task.get()}")
print(f"Get grouped_task.join() >> {grouped_task.join()}")
print(f"How many tasks are compeleted again >> {grouped_task.completed_count()}")
print("# 5. Check Grouped Tasks's Status again")
print(f"grouped_task status is {grouped_task.ready()}")
print(f"Success status >> {grouped_task.successful()}")
print(f"Faile status >> {grouped_task.failed()}")- 10자리의 랜덤한 사업자 번호를 만들어주는 function을 만들고, 20개의 task를 group으로 만들었다. 우선 결과부터 바로 확인하자. (바로 실행하는 팁은
python manage.py shell < celery_test3.py > output.txt와 같은 커멘드!)
# 1. Check Tasks
tasks is [apis.test.tasks.check_registration_number_from_hometax('5887768495'),... 생략 ..., apis.test.tasks.check_registration_number_from_hometax('1973258064')]
# 2. Check Grouped Tasks and Id
grouped_task is 938a9767-b386-4580-a204-8dd032ca5684
grouped_tasks's id is 938a9767-b386-4580-a204-8dd032ca5684
# 3. Check Grouped Tasks's Status
grouped_task status is False
# 4. Check result of Grouped Task
How many tasks are compeleted >> 0
Get the result of grouped_task >> ['5887768495: closed ', ...생략..., '1973258064: closed ']
Get grouped_task.join() >> ['5887768495: closed ', ...생략..., '1973258064: closed ']
How many tasks are compeleted again >> 20
# 5. Check Grouped Tasks's Status again
grouped_task status is True
Success status >> True
Faile status >> False- 그룹이 될 taks list를 출력하니 바로 list에 담긴 task가 정확히 뭔지 보인다.
grouped_task을 출력한 값과grouped_task.id값이 같다. 즉GroupResult의__str__()은 id를 return하게 되어있다. 그리고 group 역시 uuid 값을 가지고 있다.- 바로
compeleted를 확인하면 0개이지만get이후에는 모두 값이 제대로 박혀있다. 그리고 실제 실행하면 get에서 멈추는 것을 확인할 수 있다. - 참고로 rootid는 flower에서 확인할 수 없다.
- log를 살펴보면 pre-fetch로 task를 먼저 Receive를 한다. -> Received 상태에서 바로 pool에 맞게 비동시 실행을 하고 -> Done, 본인의 컴퓨터 경우에는 6개씩 끊어서 병렬 처리를 했다.
3. 주의해야 할 점
-
그룹에서 하나의 실패는 전체 실패로 취급한다!
-
heavy한 작업을 group으로 묶어서 러닝할 때는 memory usage를 확인해야 한다!
-
grouping한 작업은, group내 모든 작업이 완료되어야 group 작업이 완전하게 완료된다. 즉 task가 long-time 작업이라면, group 전체의 작업 시간도 올라간다. 이 경우 역시 pre-fetch & pre-fork 에 대한 개념도 중요하다. 그렇기 때문에 grouping 되는 task들은 "만료 시간" 이 중요하다. 무한정 기다리게하면 절대안된다.
- 여기서
from multiprocessing import Pool을 사용해본 사람이라면group()실행은 내부적으로 같은 것을 알 수 있을 것이다! 그렇기 때문에 하나의 Pending때문에 pre-fetched된 task가 다 같이 느려져 버리는 불상사를 꼭 막아야 한다!
-
순서를 보장하지 않는다! (3)이기 때문에 당연한 얘기일 수 있지만, 순서가 보장되어야 한다면 당연하게
chain을 쓰자! -
에러 핸들링에 주의 해야한다. 그리고 쉽지 않다.
4. group task error 처리하기
- 사실 이 내용은 group 만 해당하는게 아니라 celery task error handling의 아주 기본 내용이다.
- Ignore errors, 특정 group 또는 task 들을 실행할때 apply_async를 통해
propagate값을 줄 수 있는데, 이러면 호출한 부분에서 error를 발생시키지 않도록, 즉 어떤 예외처리도 없게 exception ignore 해버린다. 실행되던 말던하는 작업에만 쓰자,,
result = group(task1.s(), task2.s(), task3.s()).apply_async(propagate=False)- 가장 기본적으로 우리가 해야할 작업이다. exception을 어떻게 처리할지 async task 자체에서 처리하자. 그리고 return 값을 일단은 넣는게 좋다. (최적화 관점에서는 return 자체가 없는게 좋긴하다.)
@app.task
def task1():
try:
# task logic here
return 'success'
except Exception as e:
return {'error': str(e)}- 그리고 exception이 발생했을 때 rasing을 할지, 자체 retry할지, 아니면 return string으로 error를 처리해버릴지 선택하자.
- task를 실행하는 부분에서 자체 처리하기. 즉 grouped된 task를 call하고 바로 caller function을 끝내지말고, get으로 결과를 바로 받아와버린다. -> 당연하게 caller function은 모든 group 작업이 끝날때까지 pending, waiting 한다. 전체 group 자체의 task가 무조건 짧을 때는 시도해볼만 한 방법이다.
result = group(task1.s(), task2.s(), task3.s()).apply_async()
group_results = result.get()
for task_result in group_results:
if task_result.failed():
# handle error here- group_results를 다 받아와서
task_result.failed()여부를 체크하고 해당 task 자체를 어떻게 할지, 추가작업을 할지, "사람의 가시적으로" 처리가 가능하다. 하지만get자체를 쓰는게 그렇게 추천되지 않는다.
Chord
-
사실 group 형태로 묶인 task들은 chord를 만날때 빛을 발한다.
chord()는 하위 작업을 동시에 수행하고, 각 작업자가 반환하는 값을 callback 실행 객체로 전달 해준다. -
그렇기 때문에 "그룹의 모든 작업이 완료된 후에만 실행되는 작업" 이 된다. 당연히 설명은 잘 와닿지 않는다. 단순한 example먼저 살펴보자
1. group task와 chord
-
group에 다른task를 연결하면chord로 바뀐다. 즉group에 특정task를chain하면chord가 된다. -> chord <=>group( tasks ) | task -
그리고 chord
header와body라는 keyward args를 가지는데, header는 callback이 호출되기전까지 모두 완료되어야 하는 task group 이 들어오고, body는 header의 모든 작업 결과값을 list로 가져가서 excute된다. 그리고, 언급한 대로, 무조건 그 결과값을 받을 callback이 있어야한다. 그렇기에 당연히,ignore_result=False인 attribute를 물고가는 것이다.
@app.task
def add(x, y):
return x + y
@app.task
def tsum(numbers):
return sum(numbers)
# signature task list 를 만든다
tasks = [add.s(i, i) for i in range(100)]
# 그리고 callback function으로 사용할 signature task 를 만든다
callback = tsum.s()
# 마지막으로 chord 를 만든다. 여기서는 header와 body를 활용
chord_groups = chord(header=group(tasks), body=callback)
# excute 한다.
chord_groups()-
이게 가장 official한 방법이며, 완전 short cut으로
chord(add.s(i, i) for i in range(100))(tsum.s()).get()one line으로도 가능하다. 하지만 full line을 먼저 알아야 one line에 대해 정확한 파악을 할 수 있다 :) -
실무에서는 s대신 immputable한 (이전 게시글 참조)
si를 사용해 아래와 같은 구성을 많이 사용한다.
header = [add.si(i, i) for i in range(100)]
callback = tsum.si()
result = chord(header)(callback)
result()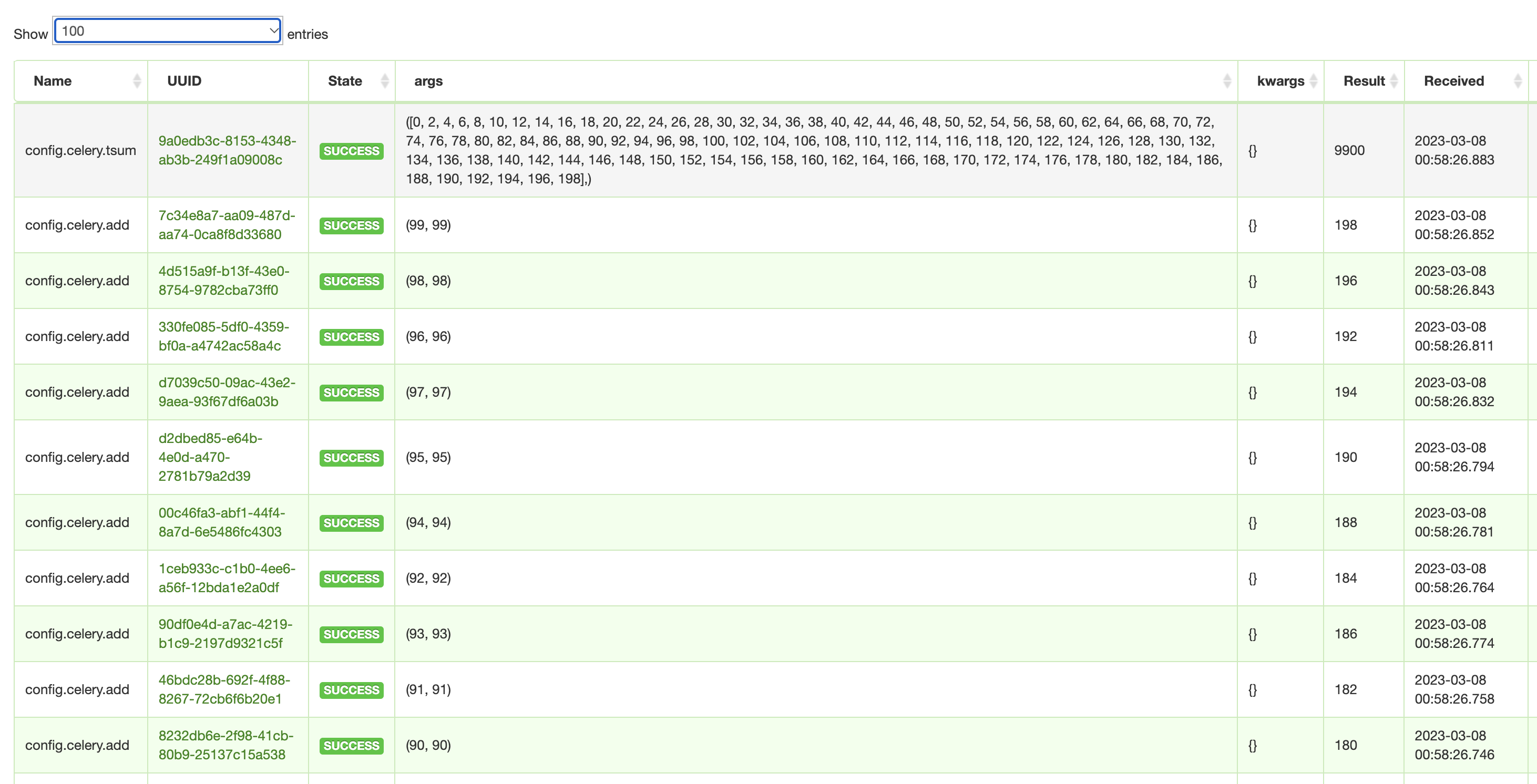
- 실행결과는 위 사진과 같다. grouping 된 add task들이 각 (1, 1), (2, 2) ... 으로 (99, 99) 까지 실행되다가 다 끝나면, callback function인 tsum 을 호출하면서 바로 모든 결과값의 list 가 args로 넘어간다. 사진의 가장 상단을 보면 된다.
그럼 에러가 생기면 어떻게 해야하나? callback은?
-
official docs 에 handling에 대해 잘 작혀져 있다.
-
일단 chord를 excute하고 error가 발생하면
ChordErrorraise를 한다. 그리고 chord안의 모든 group task가 fail 처리되는 것이 아니라, 그 외 작업은 다 돌아간다. 그리고 동시에 돌아가는 task 중 처음 fail된 task만ChordErrorraise를 한다. -
그래서 어떻게 하냐?
@app.task로 error가 발생했을 때 excute할 수 있는 task를 만들 수 있다. 그리고 task의 id를 알 수 있다면, 디버깅 & 추적에 용이하다.
@app.task
def on_chord_error(request, exc, traceback):
print('Task {0!r} raised error: {1!r}'.format(request.id, exc))- 그리고 아래와 같이 활용한다.
c = (group(add.s(i, i) for i in range(10)) | tsum.s().on_error(on_chord_error.s())).delay()
# 더 길게쓰면 아래와 같다.
tasks = [add.s(i, i) for i in range(10)]
callback = tsum.s().on_error(on_chord_error.s())
c = (group(tasks) | callback).delay()callback and errback signatures를 가지고 있는 것이다. 그리고 명심할 점은 callback과 errback은 사실 "딱 한번" 실행된다는 점이다.
2. chord 사용 주의 사항
- official docs 에서도 chord를 사용할때 핵심적으로 주의해야할 사항을 기록해 두었다.
-
언급한 대로
ignore_result=False를 task 자체에서 명시하는게 좋은 점. 혼선을 피할 수 있다! -
result backend로
Redis and Memcached만 지원하는 점, redis 사용의 경우 redis-server 2.2 이상 버전을 사용하는 것을 추천하는 점 -
result backend redis 사용시,
@app.task에서 after_return을 override할 때 super를 꼭 명시해야 제대로 callback이 실행 되는 점 (아래 참조),근데 이건 당연한거 아닌가..?
def after_return(self, *args, **kwargs):
do_something()
super().after_return(*args, **kwargs)- 외에도 존재하지만, redis stack이라면 엄청나게 유의해야할 단점은 없다. 자세한 사항은 꼭 공식문서를 참조하길 바란다.
3. backend result ?!
-
비동기적으로 작동하는 celery task의 결과값은 우리가 code level에서 get 등으로 받아주던가 하지 않으면 code level의 메모리상에서 활용할 수 없다. 당연히 지금까지 살펴본 다양한 방법으로 (chain / group / chord 등) result를 예상해서 task를 진행할 수 는있다.
-
하지만 우리가 저장하지 않는 celery task의 결과값은 어디로가는가? 바로 "result backend" 라고 계속 부르는, 우리가 celery task의 queue 활용한 redis / RabbitMQ 과 같은 메시징시스템에 저장이 된다!, 즉 borker & cache에 result가 저장된다는 의미다.
-
그러면 이 result를 계속 쌓고, 저장하기만 하면 쓸모없는 메모리 낭비가 심해질것이다. 그래서 그 낭비를 없애주기위해 운영타임에서 cleanup 하는 것이, celery & celery beat에서 자동등록된 task인 celery.backend_cleanup 이다.
-
이 cron 성격의 task는 old results from the result backend를 모두 정리해준다. 즉, 설정한 특정 life time이 지난 result들은 모두 제거된다. default 값으로는 1 day 이다.
-
CELERY_RESULT_EXPIRES라는 conf 값으로 이 생명주기를 바꿀 수 있다. 사실 이 backend_cleanup 작업은 default로 1시간마다(3600s) 돌게되어 있다. 이 역시CELERYD_TASK_TIME_LIMITconf 값으로 control 가능하다.
app.conf.CELERY_RESULT_EXPIRES = 7 * 24 * 60 * 60 # 7 days in seconds
app.conf.CELERYD_TASK_TIME_LIMIT = 1800 # 30 minutes in seconds마무리 & 출처
- 기본적인 celery의 사용법에 대해서는 전체적으로 알아봤다. 이제 "celery"를 조금 더 잘사용하기 위한 전체적인 "커스텀 접근" 과 "최적화" 에 더 알아보려고 한다. 그러기 위해 celery core (source code)에 좀 더 접근하려고 한다.
- https://snyk.io/advisor/python/celery/functions/celery.group
- https://heodolf.tistory.com/65 & https://heodolf.tistory.com/66
- https://lucky516.tistory.com/3
- 그리고 의외로 chatGPT
