[NHN FORWARD] Redis 야무지게 사용하기, Redis 운영팁
Redis 야무지게 사용하기
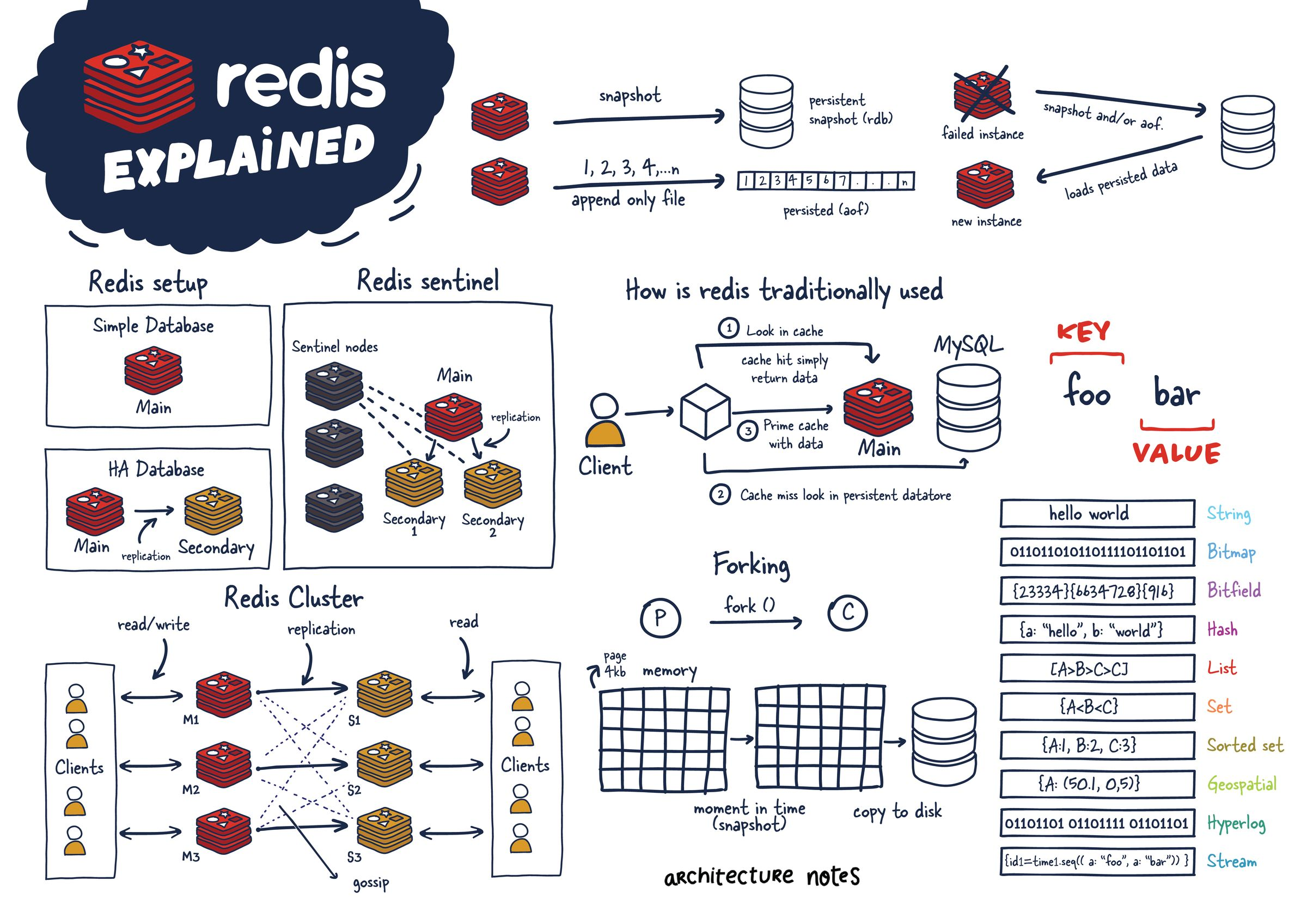
NHN FORWARD에서 소개하는 redis에 대한 정리를 한 글입니다. 해당 새션은 다음 링크에서 확인 가능합니다! >> https://forward.nhn.com/2021/sessions/16 [김가림 / NHN data 운영팀 DBA], 이미지는 새션 내용에서 캡쳐한 사진입니다.
캐시로 사용하기
캐싱 솔루션에서 유명하다
- Caching: 데이터 원래 소스보다 더 빠르고 효율적으로 액세스 할 수 있는 임시 데이터 저장소. 원본 보다 훨씬 쉽고 빠른 속도
- 같은 데이터 반복적 엑세스에 (재사용 횟수) 의미 있다.
- 잘 변하지 않는 데이터 이다.
- 단순한 key value 구조로 사용이 간단하며 어떤 데이터도 쉽게 저장 가능
- 모든 데이터를 메모리에 -> in-memory 데이터 저장소(RAM) : 굉장히 빠르다
- 평균 작업 속도가 < 1ms : 초당 수백만 건 작업 가능
캐싱 전략
Look-Aside (Lazy Loading), 읽기전략
- 캐시에 데이터가 있으면, 캐시에 있는 데이터 먼저 가져오기! -> 캐시에 없을때만 DB에서 데이터 가져온다. 그래서 lazy loading이라고도 한다.
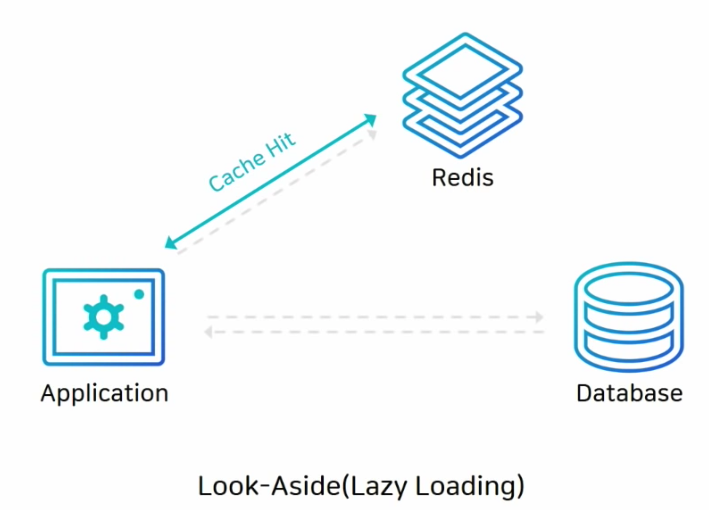
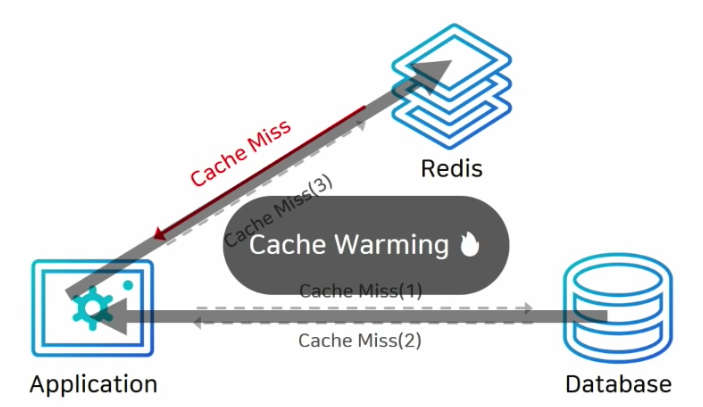
- 캐시 미스가 많으면 DB커넥션이 많이 생성되며 한 번에 부하가 많이 올 수 있다.
- 그리고 초기에 데이터를 DB에만 저장했다면 처음엔 캐시 미스가 많기 때문에 성능 저하의 가능성
- 그래서 미리 DB에서 캐시로 data넣어주는 작업 -> "Cache Warming" 이라고 한다.
Write-Around, 쓰기 전략
- 일단 DB에만 다 저장 -> 캐시 미스일땐 캐스 내 데이터 끌어온다 -> 캐시 내 데이터와 DB데이터가 다를 가능성이 있다.
Write-Through, 쓰기 전략
- DB에 데이터 저장할때, 캐시에도 같이 저장! -> 항상 최신정보를 가지고 있지만, 저장할때마다 2단계 과정을 거쳐 상대적으로 느리다.
- 캐시에 넣은 데이터를 저장만 하고 사용하지 않을 가능성이 있어서 리소스 낭비 가능성이 있다.
- 데이터를 "몇분, 몇시간" 등을 세팅하는 expire date를 정하는게 좋다
- 여기서 장애 포인트가 있을 수 있다
상황 별로 데이터 적절하게 사용하기
- redis는 자체적으로 다양한 자료구조를 제공한다.
key 자료구조
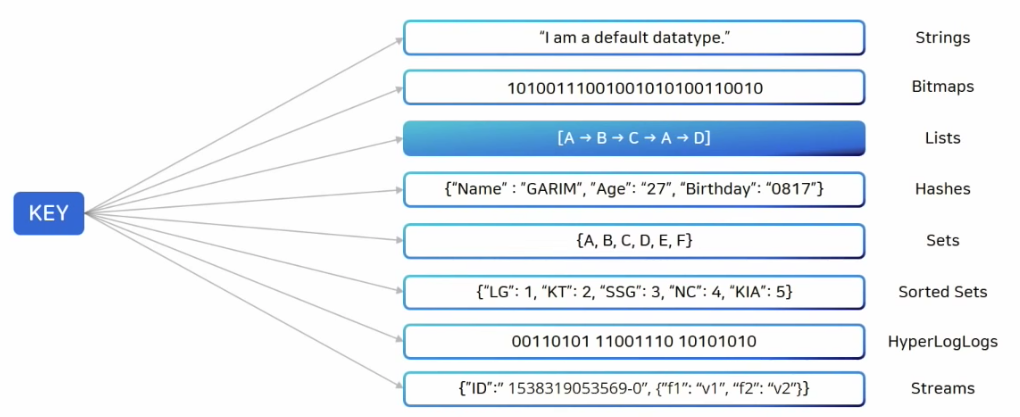
- strings은 set command이용해 저장되는 데이터는 모두 string형태
- bitmaps은 string의 변형 -> bit 단위 연산 가능하게
- lists는 데이터를 순서대로 저장 -> queue로 사용하기 적절하다.
- hashes는 하나의 key안에 다시 key-value (dict)
- sets은 중복X, 유니크한 key값
- sorted sets은 sets과 기본적으로 동일하지만 score 와 같이 정렬 기준이 있어 값 기반으로 정렬이 되면서 들어감 -> java TreeSet
- HyperLogLogs 굉장히 많은양의 데이터를 dump할때 사용, 중복되지 않는 데이터를 count할때 주로 많이 사용한다.
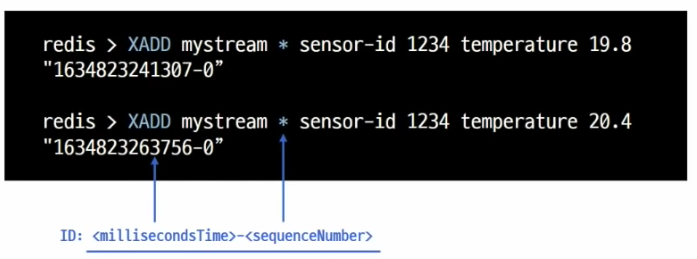
- Streams는 log를 저장하기 가장 좋은 자료 구조
counting에 적절한 경우
증감 연산
- INCR(해당 키가 integer일때 값을 하나 증가 시킨다), INCRBY(더할 값 세팅)
- INCRBYFLOAT: 해당 키를 float으로 다룰 수 있다면 increment만큼 증가시킨다.
- HINCRBY key field increment: 해당 해쉬의 필드가 integer 타입이라면 해당 값을 1증가시키고 반환한다.
- HINCRBYFLOAT key field increment: 해당 해쉬의 필드를 increment만큼 증가시킨다. INCRBYFLOAT를 참고.
- ZINCRBY key increment member: 멤버의 값을 증가 시킨다. 역 증감도 될 수 있다.
- ZINTERSTORE destination numkeys key [key …]WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX]: 정렬된 집합들의 교집합을 구한다. 교집합은 가중치가 부여된 합, 최소 값, 최대 값이 될 수 있다. 결과는 정해진 키로 정렬된 교집합을 만들어 저장된다.
Bits
- 데이터 저장공간 절약 가능하며 정수로 된 데이터만 카운팅 가능하다.
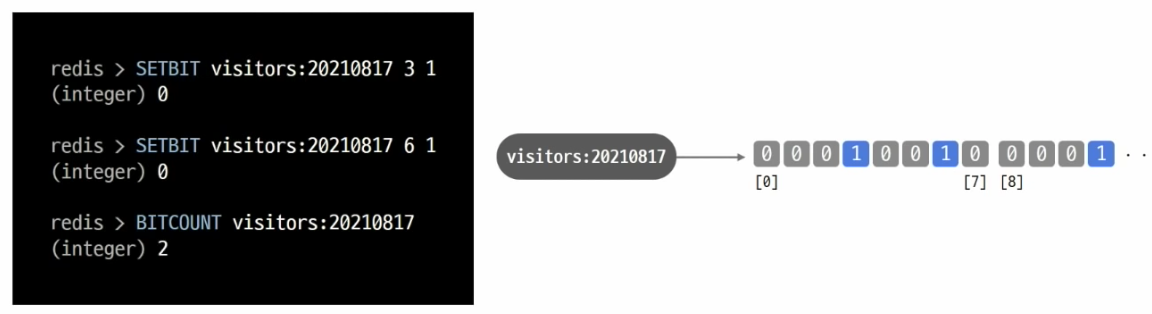
- 예를 들어 SETBIT 활용 오늘 서비스 접속 유저수 세고 싶을때 날짜 키 하나 만들어 놓고 유저 아이디에 해당하는 비트를 1로 올려주는 것
- 1비트가 한 명 -> 천 만명 -> 천 만개 비트 -> 1.2mb 밖에 차지를 안한다!!
- 모든 데이터를 정수로 표현 할 수 있어야 한다 -> user id가 정수여야!
HyperLogLogs
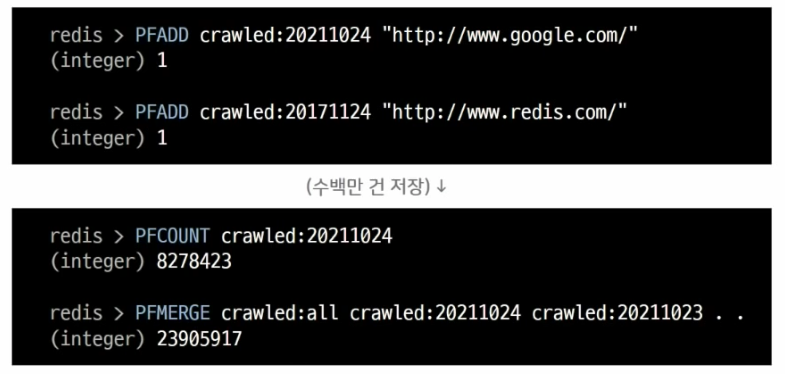
- 대용량 데이터를 카운팅 할 때 적절 (오차 범위 0.81%)
- set과 비슷하지만 저장되는 용량은 매우 작다 -> 12kb 고정! -> 하지만 저장된 데이터는 다시 확인할 수 없다!
- 웹 사이트 방문 ip 개수 카운팅, 하루 종일 크롤링 한 url 개수 몇개 인지, 검색 엔진에서 검색 한 단어 몇개 인지 -> 엄청 크고 유니크 한 값 카운팅 할 때
Messaging에 사용 적절한 경우
celery, celery beat 생각해보자!
Lists
- 메시지 큐에 사용하는 것이 아주 적절하다. blocking 기능을 이용해 event queue로 사용 가능한 것!
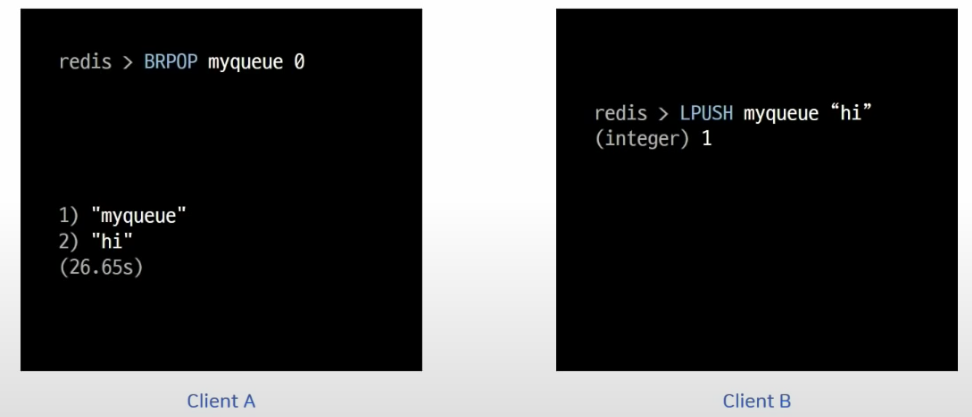
- 키가 있을 때만 데이터 저장 가능 -> 즉 사용 했던 que만 사용 한다!
- LPUSHX / RPUSHX
- SNS에서 ~ 이미 캐싱 되어 있는 "피드"에만 신규 트윗을 저장
- 즉 아래 사진 2개 중 전자가 비효율적인 사전에 미리 다 정의를 해놓고 피드 세팅하는 것 보다 redis를 활용해 후자와 같이 유동적인 세팅이 가능하다! => 트위터 자주 사용하는 유저만 캐싱
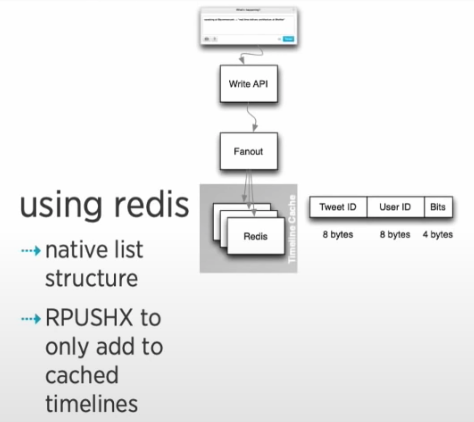
Streams
- 로그를 저장하기 가장 적절한 자료 구조다 -> append-only 이며 중간에 데이터가 바뀌지 않는다.
- 읽어 올때 id값 기반으로 시간 범위로 검색
- tail -f 사용 하는 것 처럼 신규 추가 데이터 수신
- 소비자별 다른 데이터 수신(소비자 그룹) 등 활용 가능하다.
- Streams을 kafka와 같은 MQ가 필요 할 때 대체 용으로 가볍게, 간단하게 사용 가능하다고 docs에서 설명을 하고 있다.
데이터 영구 저장, RDB vs AOF
Redis Persistence
- in-memory 데이터 스토어 -> 서버 재시작 시 모든 데이터 유실
- 복제 기능을 사용해도 사람의 실수 발생 시 데이터 복원 불가능 하다 -> 캐시 이외의 용도로 사용한다면 적절한 데이터 백업이 필요하다!
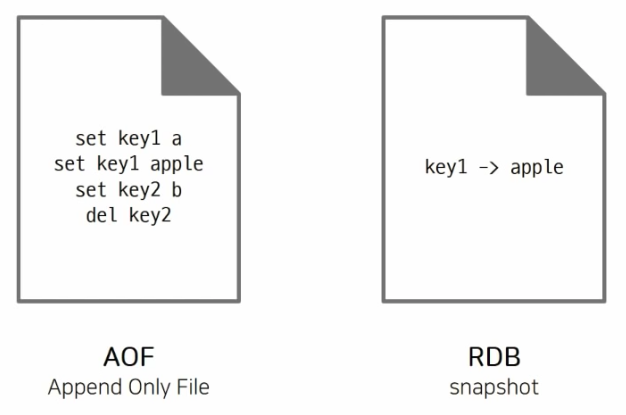
AOF
- 데이터 변경하는 커멘드가 들어오면, 모든 커멘드를 그대로 저장한다
- RDB파일보다 규모가 크며, 주기적으로 압축 + 재작성 과정이 필요하다.
- 실제 AOF 파일은 프로토콜 형태로 저장
- 자동 세팅시 : redis.conf 파일에서 auto-aof-rewrite-percentage 옵션 크기 기준
- 수동 세팅시 : 커멘드 이용해서 직접 만들 경우
BGREWRITEAOF커멘드를 이용해 CLI 창에서 수동으로 AOF 파일 재작성
RDB
- 스냅샷 처럼 동작하기 때문에 저장 당시 메모리에 있는 데이터 그대로를 사진 찍듯이 파일로 저장한다.
- 바이너리 파일 형태로 저장 -> 직접 읽을 순 없다.
- 자동 세팅시: redis.conf 파일에서 SAVE 옵션 (시간 기준)
- 수동 세팅시 : 커멘드 이용해서 직접 만들 경우
BGSAVE커멘드를 이용해 CLI 창에서 수동으로 RDB 파일 재작성SAVE커멘드는 절대 사용 X
선택 기준
- 우선 캐시로만 사용한다면 "굳이" 백업 기능은 필요 없다. 저장 공간 낭비가 될 수 있다.
- 백업은 필요하지만 어느 정도의 데이터 손실이 발생해도 괜찮은 경우
- RDB 단독 사용
- redis.conf 파일에서 SAVE 옵션을 적절하게 변경해서 사용하면 된다
- ex)
SAVE 900 1-> 900초 동안 1개 이상 키가 변경되었을 때 RDB 파일 재작성 하라는 의미이다.
- 장애 상황 직전까지 모든 데이터가 보장되어야 할 경우
- AOF 사용 (appendonly yes)
APPENDFSYNC 옵션이 everysec인 경우최대 1초 사이의 데이터 유실 가능성이 있다. (default 세팅 값임)
- 제일 강력한 내구성(무손실을) 이 필요한 경우 둘 다 동시에 사용하면 된다.
Redis 아키텍처 선택 노하우

Replication
- 단순한 복제 연결
replicaof커맨드를 이용해 간단하게 복제 연결- 비동기식 복제 (이 구조 뿐 아니라 redis의 모든 복제 기능은 async로 동작)
- 즉 master에서 복제본이 잘 만들어 졌는지 기다리질 않는다
- 이 구조는 HA 기능이 없어 장애 상황 시 수동 복구 해야 할 작업이 많다
replicaof no one으로 복제를 일단 끊어야 하고- 어플리케이션에서도 연결 설정을 변경하고 복구하는 작업이 필요하다.
Sentinel
- Auto Fail-Over 가능한 HA(High Availability) 구성
- sentinel 노드가 다른 노드를 감시한다.
- 마스터 노드가 죽으면 자동으로 페일오버를 가동 시켜 기존 master대신 Replica 노드가 master자리를 대체한다.
- 이때 어플리케이션에서는 연결 정보를 변경 할 필요가 없다. 즉 어플리케이션은 sentinel 만 연결 되어 있으면 되고, sentinel 노드가 알아서 바로 연결 시켜 준다.
- 이 구조를 사용하려면 sentinel 프로세스를 추가로 띄워야 한다.
- 항상 3대 이상의 홀수로 존재 해야 한다.
- 과반수 이상의 센티널이 동의해야 Fail-Over를 진행한다.

- nhn에서는 위 그림과 같이 센티널을 사용한다. 2대의 서버에는 일반 redis와 센티널을 함께 띄우고, 최저 사양의 서버에서는 센티널 노드만 올려 사용한다.
Cluster
- 스케일 아웃과 HA(High Availability) 구성
- 데이터가 여러 마스터 노드에 자동으로 분할되어 저장되는 샤딩 기능 제공
- 키를 여러 노드에서 자동으로 분할해서 저장한다는 의미
- 모든 노드가 "서로를 감시", 마스터 비정상 상태일 때 자동으로 Fail-Over
- 최소 3대의 마스터 노드가 필요하다. 각 마스터 노드에 레플리카 노드를 하나 씩 추가하는게 일반적인 형태이다.
선택 기준
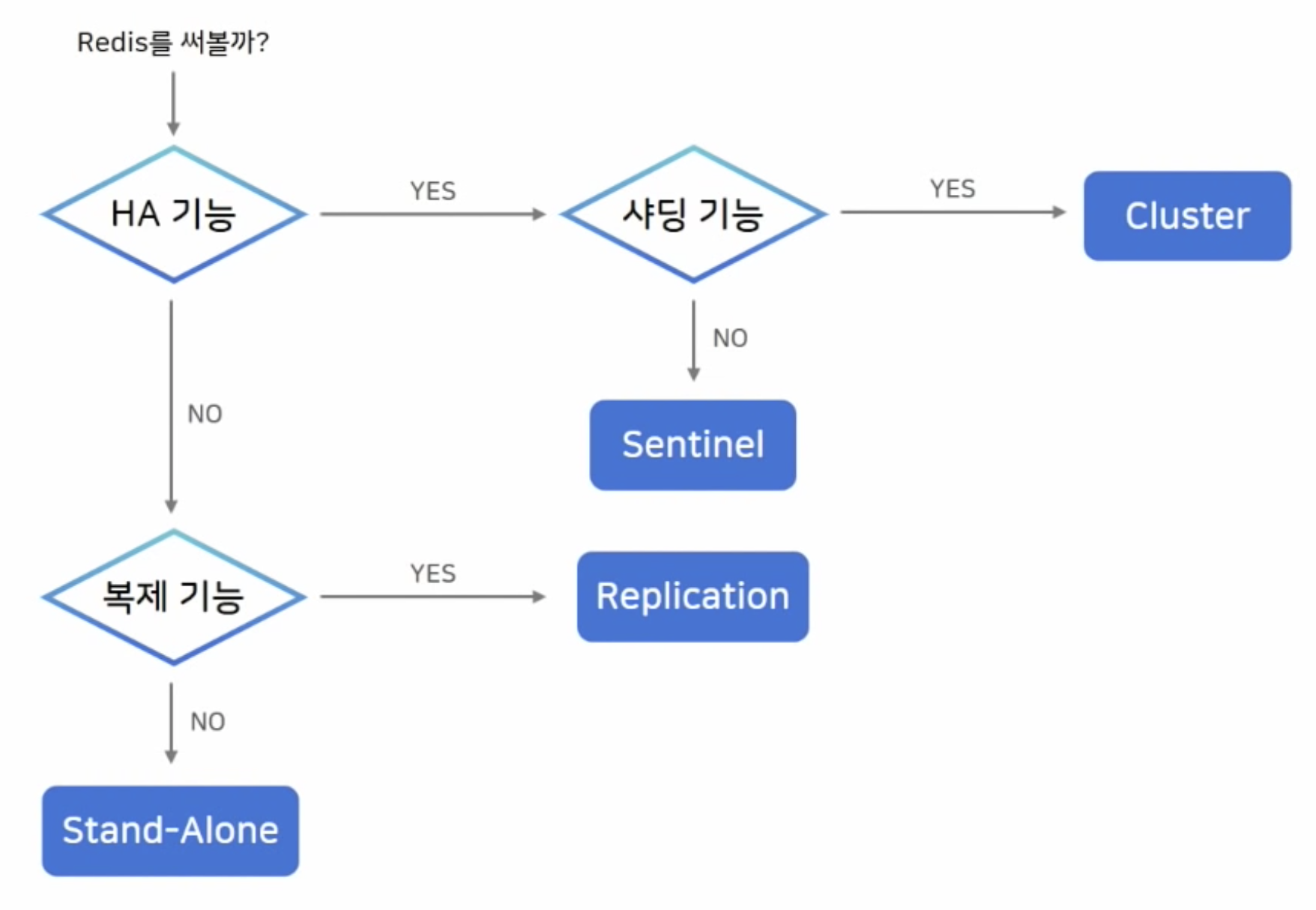
- 위와 같이 질문의 분기점에 따라 어떤 아키텍처를 선택할지 고민 해 보자.
기타 운영 꿀팁 및 장애 포인트
사용하면 안되는 커맨드
-
REDIS는 Single Thread로 동작한다. -> 즉 한 사용자가 오래걸리는 커맨드 요청할 경우 다른 로직은 기다릴 수 밖에 없음 -> O(N) 의 수행을 경계해라!
-
개발계에서는 상관 없는데 운영 환경에서 실수로 치는 경우가 있다. 그래서 그냥 오래 걸리는 커맨드를 운영계에서는 사용안하는게 낫다!
-
keys *같은 모든 key 보는 커멘드 대신scan 0으로 대체 -> "재귀적"으로 key를 순차 호출 가능함 -
Hash나 Sorted Set 등 자료 구조 내부 여러개 아이템 저장 가능
- 즉, 내부 아이템 저장 많이 되면 될 수록 성능 저하
- 퍼포먼스 상승을 위해 하나의 키에 최대 100만개 선으로 생각하고 저장하며, 키 분할을 고려하자.
hgetall->hscan: keys와 같은 이유- 키에 데이터가 많을때
del커멘트 치면 수행 오래걸린다, 키 지우는 동안 아무것도 못함 ->unlink의 경우에는 back ground 작업으로 키를 없애주기 때문에 이 명령어로 대체 추천
-
삭제에 대해 조금 더 알아보자면, Redis는 4.0.0 버전부터
UNLINK라는 커맨드가 있는데DEL과 동일하게 특정 key를 삭제하는 기능을 수행한다. 더 정확하게는UNLINK의 경우 실제로 key를 바로 삭제하진 않으며, 해당 key를 keyspace에서 제거(unlink)할 뿐이다. 실제 메모리 상의 삭제는 다른 쓰레드에서 비동기로 이뤄진다.
변경하면 장애를 막을 수 있는 기본 설정 값
STOP-WRITES-ON-BGSAVE-ERROR = NO
- RDB 파일이 정상적으로 저장되지 않았을 때, redis로 들어오는 모든 write를 차단한다는 의미.
- 디폴트값이 yes임
- redis 모니터를 알아서 잘 하고 있다면, 굳이 이 기능을 키지말자!
MAXMEMORY-POLICY = ALLKEYS-LRU
- redis를 캐시로 사용할 때 키에 대한 Expire Time 설정 하는 게 좋다 -> 메모리 한정 되어 있기 때문에 리소스 절약
- 메모리가 가득 찼을 때 MAXMEMORY-POLICY 정책에 의해 키 관리가 된다.
- noeviction(default) : 삭제 안함 -> 더 이상 레디스에 새로운 키 저장 안한다! -> 데이터 입력 불가능에 따른 장애 가능성
- volatile-lru : LRU 정책, 즉 가장 최근에 사용하지 않았던 키부터 삭제한다. -> expire 설정이 있는 key값만 삭제한다는 것을 의미한다. 만약 해당 설정이 없는 키만 남아 있다면? noeviction과 똑같은 장애 케이스가 날 수 있다.
- allkeys-lru : 위와 기본적으로 같지만, expire 설정 유무에 상관없이 최근에 사용 안한 키부터 무조건 삭제 -> 위 두 케이스 와 같은 장애 상황은 피해갈 수 있다.
TTL 값을 너무 작게 설정한 경우

- 대규모 트래픽 환경에서 ttl 값이 너무 작게 설정하면 cache stampede 현상이 발생할 가능성이 있다.
- Look-aside 패턴에서 redis에 데이터가 없다는 응답을 받은 서버 (캐시 미스)가 직접 DB로 데이터 요청한 뒤, 다시 redis에 저장하는 과정을 거친다.
- 위 상황에서 key가 만료되는 순간 많은 서버에서 이 key를 같이 보고 있었다면 모든 어플리케이션 서버에서 DB로 가서 찾게 되는 duplicate read 가 발생한다. 또 읽어온 값을 각 각 redis에 쓰는 duplicate write 도 발생
- 한 번 발생하면 처리량도 다 같이 느려질 뿐 아니라 불필요한 작업이 굉장히 늘어나 요청양 폭주로 장애로 이어질 가능성 도 있다.
- 운영 중 가능성 있음! ex) 티켓링크 -> 인기 있는 공연 -> 하나의 데이터 읽기 위해 몇 십개의 app-server에서 connection -> 위 케이스로 부하 발생 -> TTL 시간 늘려 해결
MaxMemory 값 설정
- 레디스 데이터를 파일로 저장할 때(RDB, AOF rewrite시) 포크(Fork)를 통해 자식 프로세스를 생성한다.
- 자식 프로세스에서 Background에서는 데이터를 파일로 저장 -> 원래 프로세스는 계속해서 일반적 요청을 받아 데이터 처리하고 있음
- copy on write 기능으로 메모리 복사해서 사용하기 때문에 가능하다.
- 이로 인해 서버 메모리 사용량 2배로 증가하는 상황이 발생할 수 있다!
- 영구 저장이 아니라 "복제 기능"에도 해당되는 내용이다.
- Persistence / 복제 사용시 MaxMemory 값을 실제 메모리 절반으로 설정하는 것이 좋다!
- ex) 4GB -> 2048MB
- 메모리 풀 가득 차서 장애 발생 가능성 사전 차단
Memory 관리
- in-memory db에서는 사실 "메모리 관리"가 핵심적인 관리 포인트이다.
- 물리적으로 사용되고 있는 메모리를 모니터링하는 것이 좋다.
- 즉 used_memory (논리적으로 redis가 사용하는 메모리) 값이 아닌
- used_memory_rss (OS가 redis에 할당하기 위해 사용한 물리적인 메모리 양)을 보는 것이 좋다 (더 중요하다).
- used_memory는 적은데 rss값은 큰 상황이 발생 할 수 있다. -> 이 차이가 클때 fragmentation(단편화) 이 크다 라고 한다.
- 주로 삭제되는 키가 많을 때 fragmentation이 증가한다.
- 예를 들어 특정 시점에 key가 피크를 치고 다시 삭제되는 경우
- 혹은 TTL로 인해 삭제가 과도하게 많을 경우(eviction이 많이 발생)에 발생한다.
- 이때 activefrag 기능을 잠시 켜두면 도움이 된다.
CONFIG SET activedefrag yes- 공식 문서에서도 fragmentation(단편화)가 많이 발생했을 때 켜두는 것을 권장하고 있다.
마지막 nhn 홍보
- nhn cloud의 EasyCache,, 위 설정값이 잘 구조화 되어 있다는 매력 포인트가 있음
- 링크 : https://meetup.toast.com/posts/235
추신
- 생각보다 진짜 실무에 도움 되는 내용이 가득해서 좋았다.
- redis tech자체에 대한 depth있는 것 보다 지금 당장 redis 서버에 적용해 볼 수 있는 내용 들이고 꼭 운영 환경에서는 지켜야 할 것 들을, 나도 놓쳤던 부분들도 가져갈 수 있어서 좋았다.
- 시간이 짧은 새션 특성상 레디스(또는 in-memory db 등)에 대한 코어 로직에 대해 깊이 있게 알 수 없는 부분이 아쉬웠다.

🔥 도메인 중심의 개발, 깊이의 가치를 이해하고 “문제 해결의 본질” 에 몰두하는 software/product 개발자, 정현우 입니다.