
[ 글의 목적: LLM을 활용한 Vibe Coding (Preprint 상태)에 대한 세계 최초의 포괄적이고 체계적인 리서치 & 논문 리뷰잉, 단순 번역이 아니라 요약, 순서 재정리, 주관이 첨가되어 있음. 스크롤 압박 주의 ]
A Survey of Vibe Coding with Large Language Models
LLM 기반 Vibe coding의 세계 최초 서베이 논문 에 대한 정리 및 분석 글이다. 초점은 "코딩을 위한 LLM, LLM 기반 코딩 에이전트, 코딩 에이전트를 위한 개발 환경, 피드백 메커니즘" 에 맞춰져 있다. 정말 놀라운건, "바이브코딩" 이라는 단어가 등장한지 1년도 안 됐다! OpenAI의 공동 설립자이자 전 테슬라 AI 디렉터(Director of AI)인 안드레이 카페시(Andrej Karpathy)가 자신의 X(구 트위터) 에 내용을 올리면서 시작되었다. 이는 처음에 밈처럼 번지다가 지금은 문화 이상, 도구 그 이상의 가치가 되어버렸다.
이 서베이가 일단 목차부터 재미있다. 그리고 바이브코딩에 대한 전반적인 동향에 대한 리서치 뿐 아니라 진짜 진지하게 학문적으로 접근했다.
사실 나에게는 여전히 바이브코딩이라는 단어가 하나의 밈처럼 느껴진다
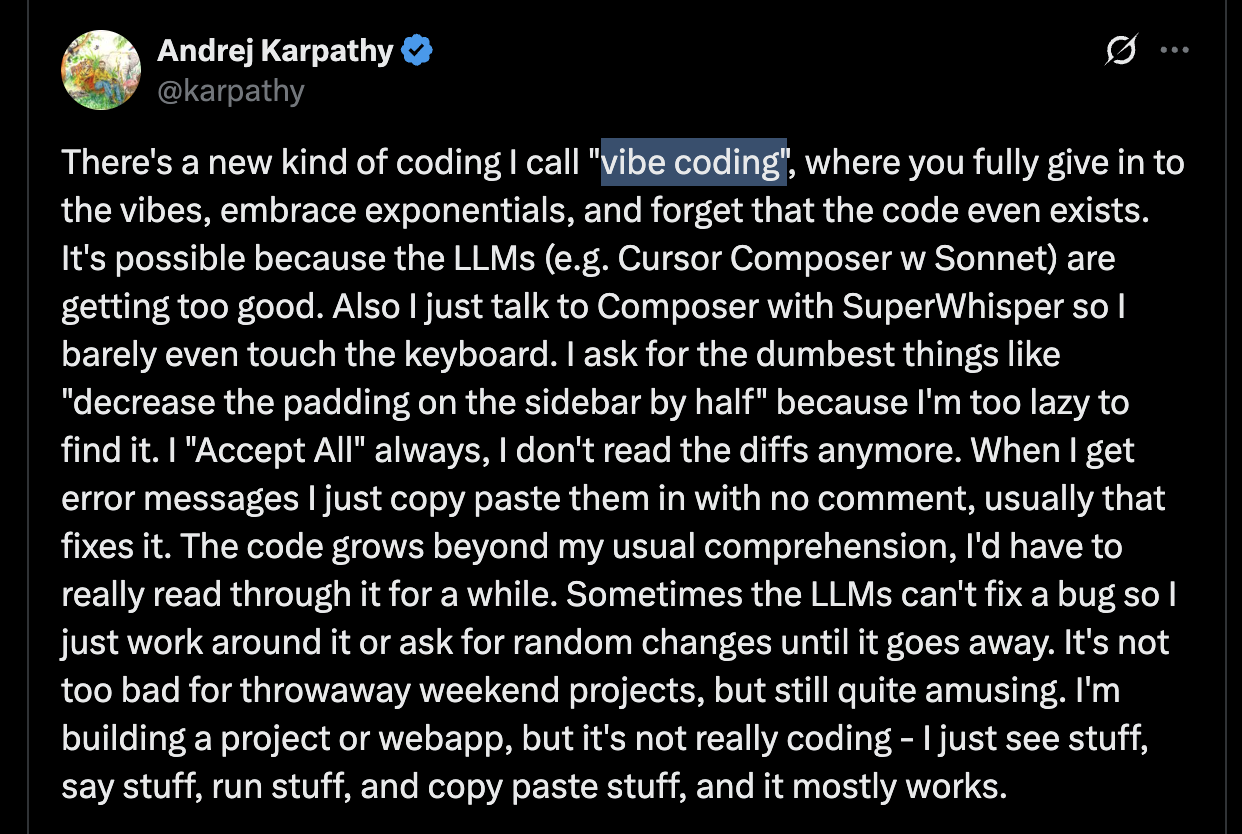
출처: https://x.com/karpathy/status/1886192184808149383
1. Vibe Coding
1) 들어가며...
해당 논문에서는 바이브코딩을 "대규모 소프트웨어 개발을 위한 엔지니어링 방법론" 으로 정의한다. (we define Vibe Coding as an engineering methodology for software development grounded in large language models)
-
새로운 개발 방법론인 “Vibe Coding” 에서는 개발자가 코드를 한 줄 한 줄 확인하기보다는 실행 결과를 관찰하여 AI가 생성한 구현을 검증한다.
-
이러한 혁신적인 패러다임은 큰 잠재력을 지니지만, 그 효과가 아직 충분히 검증되지 않았고 인간-AI 협업 측면에서 예상치 못한 생산성 저하와 근본적인 과제들이 보고되고 있다.
-
실제로, 한 연구에서는 Cursor 에디터와 Claude 모델을 활용한 숙련 개발자들의 작업 완료 시간이 기대보다 19% 증가한 것으로 나타나, Vibe Coding의 효용성에 대한 의문을 제기하기도 했다.
-
논문에서는 자연어로 이루어지는 비구조적 지시만으로는 세밀한 요구사항이나 아키텍처 제약을 전달하기 어려우며, 인간 개발자와 AI 에이전트 간의 효율적인 협업을 위해서는 체계적인 프롬프트 엔지니어링 및 컨텍스트 엔지니어링, 구조화된 지침 제공, 그리고 상호작용 유형별로 균형 잡힌 주체성 분배 등이 필수적임을 보여준다.
Vibe Coding이란 대규모 언어 모델에 기반한 새로운 소프트웨어 개발 방법론으로, 인간 개발자, 소프트웨어 프로젝트, 코딩 에이전트 간의 삼자 상호작용을 중심으로 한다.
-
Vibe Coding 패러다임에서 인간은 더 이상 직접 코드를 작성하는 주체가 아니라, 의도 전달자이자 맥락 제공자, 그리고 최종 품질 평가자의 역할이 되었다.
-
프로젝트는 단순한 정적 코드 저장소를 넘어, 코드베이스와 데이터베이스, 도메인 지식까지 아우르는 다층적 정보 공간으로 확장되었다.
2) 바이브코딩의 3자 협업 (Triadic Collaboration)
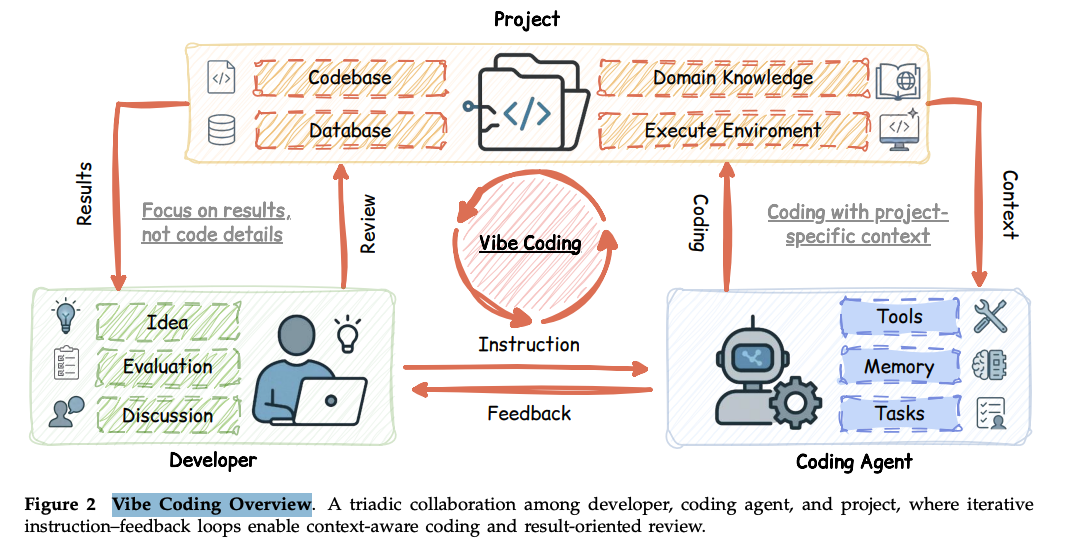
- 인간 개발자 (Human Developer, )
- 직접 코드를 짜는 작성자에서 의도 표명자(Intent Articulator) 및 품질 판정자(Quality Arbiter)로 역할
- 요구사항을 지시하고, 결과를 검토하여 수용할지 거부할지 결정한다.
- 소프트웨어 프로젝트 (Software Project, )
- 단순한 코드 저장소를 넘어, 코드베이스, 데이터베이스, 도메인 지식을 포함하는 다면적인 정보 공간(Multifaceted Information Space).
- 코딩 에이전트 (Coding Agent, )
- 인간의 의도와 프로젝트의 제약 조건 하에서 코드 생성, 수정, 디버깅을 수행하는 지능형 실행자(Intelligent Executor)
이들의 관계는 "반복적인 지시-피드백 루프(Iterative Instruction-Feedback Loop)" 를 통해 작동하며, 개발자는 코드의 세부 사항보다는 결과(Outcome) 를 중심으로 검증한다.
이 3자 관계는 수학적으로 제약된 마르코프 결정 과정(Constrained MDP) 으로 정식화 할 수 있다.
(1) 시스템 정의:
Vibe Coding 시스템 는 다음 세 요소로 구성된다.
- (인간):
- 요구사항 인지 능력 (): 도메인 요구사항()을 자연어 지시(, Instruction)로 변환한다.
- 품질 판별 능력 (): 에이전트의 산출물()을 보고 수락(1)/거부(0)를 결정하고 피드백()을 준다.
- (프로젝트): 프로젝트의 컨텍스트 공간은 로 정의된다.
- (에이전트): 매개변수 를 가진 LLM으로, 조건부 생성 함수 를 수행한다 (는 실행 환경).
(2) Constrained MDP 공식:
이 협업 과정은 다음과 같은 5개의 튜플로 정의된다.
- (상태 공간): 프로젝트의 현재 상태 (코드 및 데이터의 상태)에 의해 정의된다.
- (행동 공간): 인간의 지시가 에이전트의 행동을 촉발한다.
- (전이 함수): 에이전트가 코드를 수정하여 프로젝트 상태를 변화시키는 과정이며, 프로젝트 사양에 의해 제약된다.
- (보상 함수): 인간의 평가(수락/거부 및 피드백)에 의해 결정되는 보상이다.
- (감가율): 미래 보상의 가치를 조정하는 할인 계수다.
(3) 에이전트의 생성 과정 (Conditional Generation Process)
에이전트가 코드를 생성하는 과정은 다음 확률 분포로 표현된다.
- : 인간의 의도 (지시).
- : 프로젝트 컨텍스트의 부분집합 ().
- : 실행 환경.
- : 생성 단계 에서의 동적 컨텍스트(Dynamic Context) (). 이는 다음 세 레이어의 정보를 조합한 것:
- Human Layer: 지시사항 ().
- Project Layer: 코드, 데이터, 지식 ().
- Agent Layer: 도구 정의, 메모리, 현재 작업 ().
(4) 최적화 목표 (Optimization Objective)
Vibe Coding의 핵심 목표는 제한된 컨텍스트 윈도우() 내에서 최적의 컨텍스트 전략() 을 찾아 보상을 최대화하는 것이다!
- 즉, 프로젝트의 방대한 정보 중에서 어떤 정보()를 에이전트에게 제공해야 인간이 원하는 이상적인 결과()와 가장 유사한 결과를 낼지 결정하는 최적화 문제다!
(5) 반복적 진화 및 피드백 (Iterative Evolution)
인간의 피드백을 통해 요구사항이 점진적으로 구체화되는 과정은 다음과 같이 표현된다:
- 설명: 인간은 에이전트의 산출물()을 보고 일부만 수락()하고 수정 사항()을 지시하거나, 아예 새로운 요구사항을 추가하여 지시 집합()을 확장()한다. 이는 "점진적 요구사항 명료화(Progressive Requirement Clarification)"를 수학적으로 표현한 것이다.
3) 뭐라는거에요..?

처음에 논문의 위 설명을 보고 굉장히 당황스러웠다ㅎㅎ;; 논문에서는 바이브코딩의 이 3자 협업이 "새로운 공학" 이며 "수학적으로 계산 가능한 시스템" 이라는 걸 증명하기 위해서 정리했다.
쉽게 좀 바꿔서 이해해보자면 아래와 같다.
- 인간을 "사장님/팀장님" 으로, "무엇(What)" 을 만들지 지시하고, 결과물이 나오면 "왜 합격/불합격인지(Why)" 을 판단하며
- 에이전트를 "손이 엄청 빠른 인턴" 으로, 사장님이 시키는 대로, 그리고 회사의 규칙대로 실제로 "어떻게(How)" 일을 처리할지 고민하고 실행하며
- 프로젝트를 "회사 창고/규정집" 으로, 인턴이 일을 할 때 참고해야 하는 "어디서(Where)" 에 해당하는 정보를 의미한다.
그리고 "수학적 접근"으로 결국 논문에서 중요하다고 강조하는 것들은 아래 3가지라 이해된다.
- 말을 잘해야 한다 (Context Engineering)
- 보는 눈을 길러야 한다 (Evaluation)
- 반복해야 한다 (Iterative Loop)
그니까.. 바이브코딩은 결국 최적화 문제라는거다..!! 제한된 컨텍스트 윈도우() 내에서 최적의 컨텍스트 전략() 을 찾아 보상을 최대화하는 것을 목표로 해야 한다..! 이를 Markov decision process로 접근한 것이다.
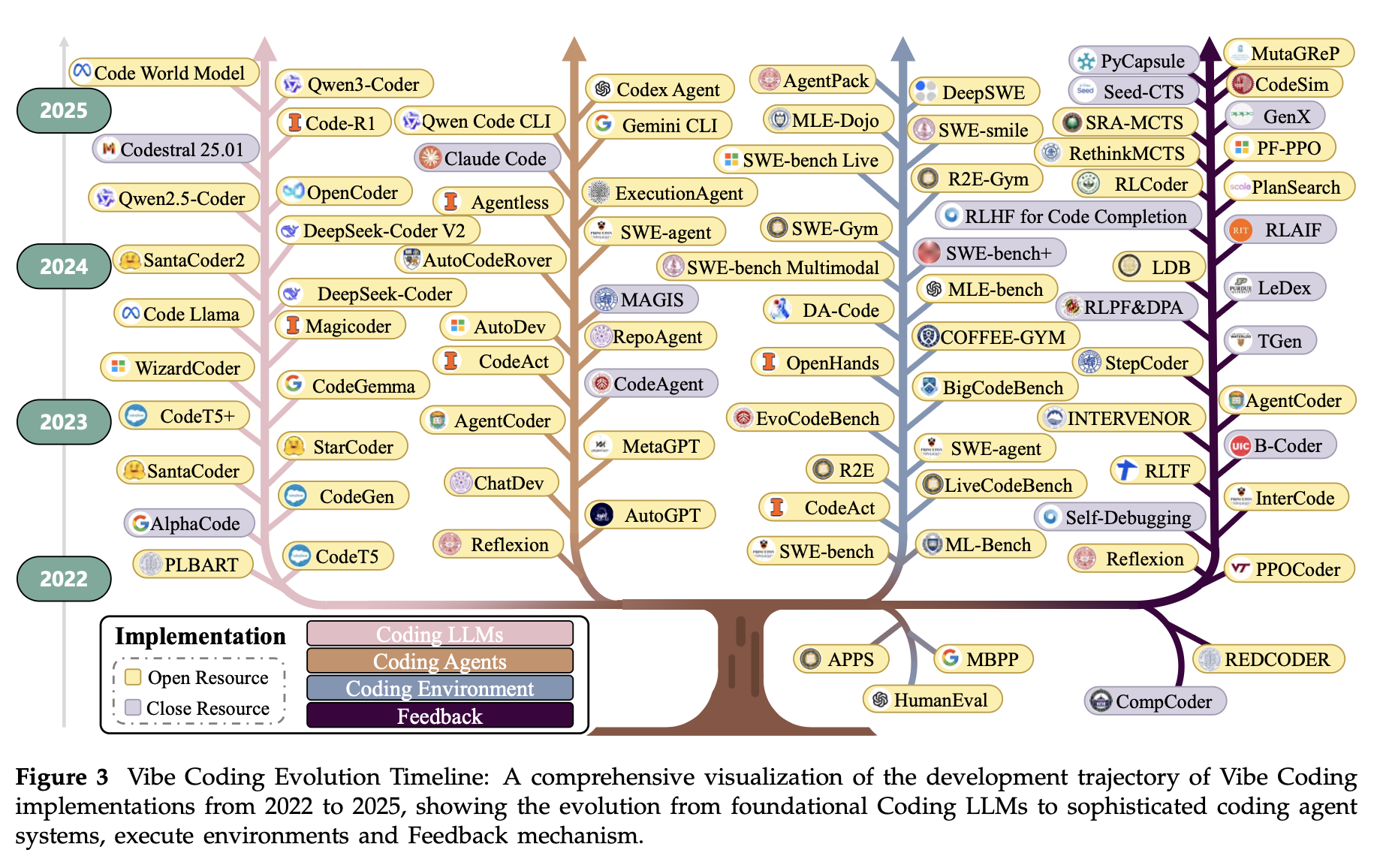
진짜 얼마나 LLM쪽 AI, model 이 대격변인지 보여주는 사진이다..
4) 코딩을 위한 대규모 언어 모델들
논문에서는 코딩을 위한 LLM(Code LLMs)을 Vibe Coding 생태계를 지탱하는 핵심 인프라로 보고 있다. 어떻게 Code 전용 LLM을 구성했는지 개괄적인 내용을 다룬다.
(1) 데이터 기초(Data Foundation)
-
코드 말뭉치 (Code Corpora): 주로 GitHub나 Stack Overflow 같은 오픈 플랫폼에서 데이터를 수집한다. 'The Stack'과 같은 데이터셋은 허가된 라이선스가 있는 코드만을 선별하여 법적 리스크를 줄였다.
-
데이터 구성 전략은 인기 있는 언어에 집중하는 '깊이 중심(depth-focused)' 전략과 다양한 언어를 포괄하는 '너비 중심(breadth-focused)' 전략으로 나뉜다.
- 깊이 중심 The Stack (v1): 라이선스 문제가 없는(permissively licensed) 소스 코드 3.1TB를 사용하며, 단 30개의 프로그래밍 언어에만 집중했다. 특히 라이선스와 데이터 출처(provenance) 관리에 엄격했다.
- 너비 중심 The Stack v2: 깊이 중심이었던 v1과 달리 커버리지를 대폭 확장했습니다. 무려 619개의 언어를 포함하며 데이터 양도 67.5TB로 폭증했다.
- GPT-Neo: "The Pile"이라는 다양한 혼합 말뭉치(mixed corpora)를 사용했고,
- CodeLlama: SlimPajama 데이터셋의 6,270억(627 billion) 토큰과 The Stack의 코드를 결합하여 광범위한 학습을 수행했다.
- Arctic-SnowCoder: 필터링된 데이터 조합을 통해 4,000억(400 billion) 토큰을 사용했다.
-
지침 및 선호도 데이터 (Instruction & Preference Datasets): 단순히 코드를 완성하는 것을 넘어 사용자의 의도를 따르게 하기 위해, 커밋 메시지나 자연어 지침이 포함된 데이터셋(CommitPack, OpenCodeInstruct 등)을 사용한다. 비용 절감을 위해 'Self-Instruct'나 'Evol-Instruct'와 같이 AI가 합성 데이터를 생성하여 학습에 활용하는 방식이 주류가 되고 있다고 한다.
생각보다 라이선스와 출처에 엄격했던 모델이 꽤 있다는 점에 놀랐다. 조금 덧붙이면, 9월에 Claude Code Meetup Seoul 가서 클로드 코드 개발 관계자가 바이브코딩엔 Typed Language(정적 타입 언어) 를 더 추천한다고 했다. Rust, TypeScript(TS) 이 2가지를 가장 먼저 말했던게 기억에 남는다 ㅎㅎ (제발 python + mypy 조합으로 다시 학습시키고 싶다..)
(2) 사전 학습 기술 (Pre-training Techniques)
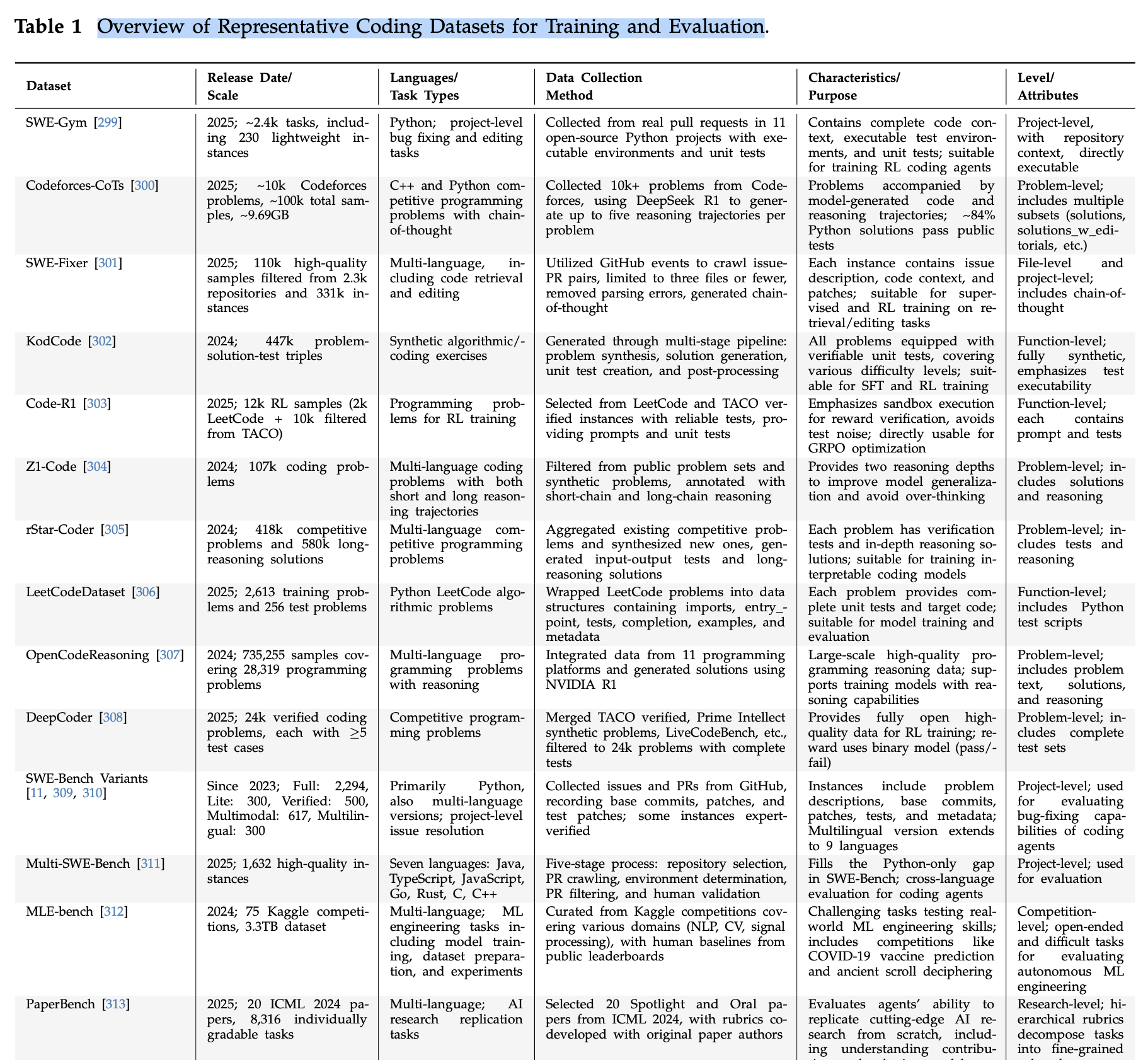
얼마나 방대한양을 사전 조사했는지 알 수 있는 "대표 코딩 데이터셋 개요" table,, (중간에 짤렸다. 논문 본문 참조.)
-
마스크 언어 모델링 (MLM): 문맥을 양방향으로 이해하는 데 유리하며 주로 코드 이해(Code Understanding) 모델(CodeBERT 등)에 사용된다.
-
자동 회귀 모델링 (Autoregressive): 이전 문맥을 바탕으로 다음 토큰을 예측하는 방식으로, 코드 생성(Code Generation) 모델(CodeGPT, CodeLlama 등)의 기초가 된다.
-
중간 채우기 (Fill-in-the-Middle): 코드의 앞부분(
prefix)과 뒷부분(suffix)을 보고 중간을 채우는 능력으로, 코드 완성 기능에 필수적이다! -
지속적 사전 학습 (Continual Pre-training): Llama 2와 같은 일반 목적의 LLM을 가져와서 코드 데이터로 추가 학습시켜 코딩 능력을 강화하는 전략이다.(예: CodeLlama, DeepSeek-Coder-V2). 이는 기존 지식을 잊어버리는 '재앙적 망각(catastrophic forgetting)'을 방지하면서 전문성을 높이는 것이 핵심 과제이다.
이 이상은 논문에서 해당 섹션을 참고하는 것을 추천한다. "Fill-in-the-Middle" 과 같은 pre-training을 할까 했었는데 실제로 적극적으로 하는 것에 놀랐다. 근데 왜 내 코드에는 syntax 안지키는 코드만 fill in 할까?
(3) 사후 학습 기술 (Post-training Techniques)
-
지도 미세 조정 (SFT): 모델이 지침을 잘 따르도록(Instruction Following) 가르친다. 최근에는 매개변수의 일부만 업데이트하는
LoRA(Low-Rank Adaptation)같은 효율적인 튜닝 기법이 널리 쓰인다. 데이터의 양보다는 '질'이 중요하다는 것이 입증되어, 적지만 고품질의 데이터를 선별해 학습시키는 추세다.- 이게 "바이브코딩" 을 발전시키는 중추로 보인다. 인간이 작성한 문제-해결 예시를 반복적으로 변형하여 대규모의 학습 데이터를 생성하는 Instruction Evolution 기법과 같이 말이다.
- 보안 강화를 위한 특수 튜닝으로 취약점 없는 코드를 생성하도록 모델을 훈련시켜 보안 수준을 크게 향상시킨 사례도 보고되었고, 성능 최적화나 코드 수정 및 디버깅 작업에 특화된 튜닝 전략들도 연구되고 있다 한다.
-
강화 학습 (Reinforcement Learning): 모델을 인간의 선호도나 객관적인 정답에 맞게 정렬(Alignment) 한다.
RLHF/DPO: 인간의 피드백이나 선호 데이터를 이용해 모델을 최적화- 실행 피드백 활용: 코딩 도메인의 특수성을 활용하여, 컴파일러의 성공 여부나 유닛 테스트 통과 여부를 보상(Reward) 신호로 사용하여 강화 학습을 수행한다(CodeRL, PPOCoder). 이는 수학이나 코딩처럼 정답 검증이 가능한 영역에서 특히 효과적이다.
5) 코딩 에이전트
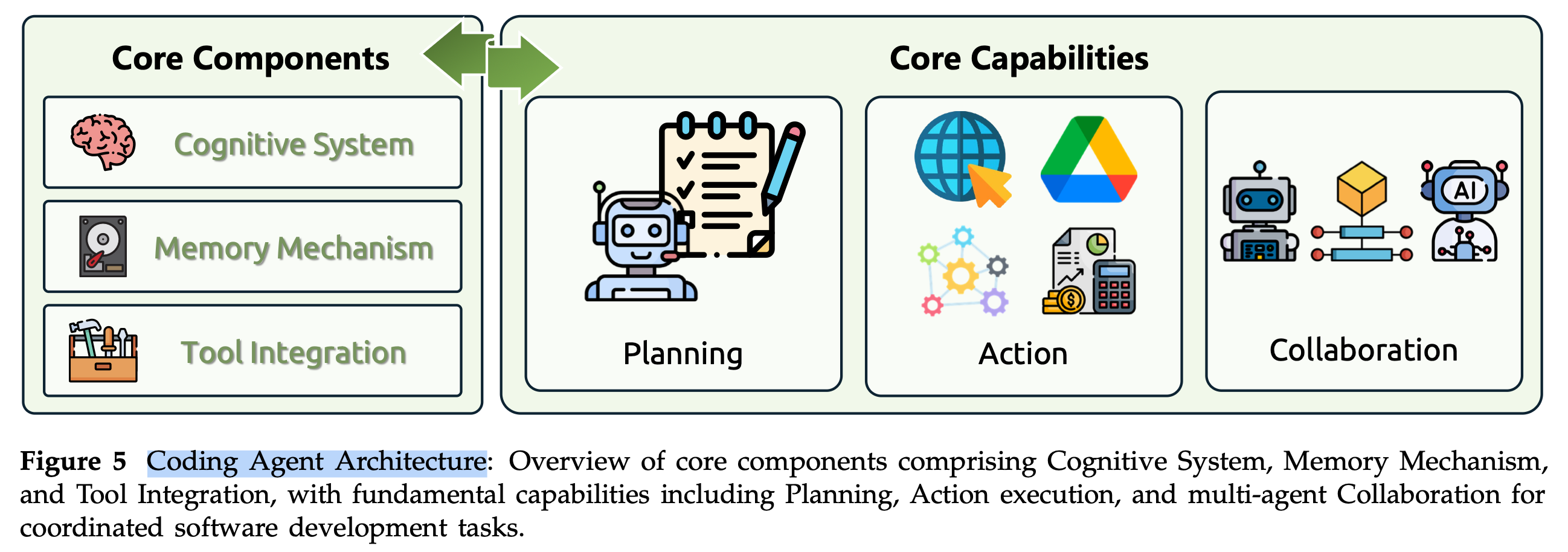
코딩 에이전트는 LLM 기반으로 동작하며, 코드 자동 완성 수준을 넘어 자율적으로 프로그래밍 작업을 수행하는 인공지능 요원을 의미한다.
이러한 에이전트들은 코드 생성 기능과 함께, 문제 해결을 위한 계획 수립 능력(planning), 현재까지의 진행 상황이나 중요한 정보를 기억하는 메모리 메커니즘(memory), 그리고 외부 도구나 환경과 상호작용할 수 있는 툴 통합 능력(tool integration) 등을 갖추고 있다.
이 챕터는 코딩 에이전트를 인지 시스템(Cognitive System) 으로 보고, 인간 개발자와 유사하게 사고하고 행동하도록 만드는 5가지 핵심 구성 요소를 소개한다.
(1) 분해 및 계획 능력 (Decomposition and Planning Capability)
-
작업 분해 (Task Decomposition): '생각의 사슬(Chain-of-Thought, CoT)'이나 '생각의 나무(Tree-of-Thoughts, ToT)'와 같은 기법을 사용하여 복잡한 요구사항을 단계별로 추론하고 분할한다.
-
계획 수립 (Plan Formulation): 에이전트는 PDDL(Planning Domain Definition Language) 같은 형식을 사용하거나, ReAct(Reasoning + Acting) 패턴을 통해 '생각-행동-관찰'의 루프를 반복하며 동적으로 계획을 수정한다. (PS. 개인적으로
ReAct 패턴이 정말 나에게 "에이전틱한 것이 뭔가" 에 대해 진지하게 고민할 수 있는 포인트를 만들어 줬다.)
(2) 메모리 메커니즘 (Memory Mechanism)
-
단기 및 장기 기억: 인간의 인지 구조를 모방하여, 현재 추론 중인 내용은 단기 기억(Short-term)에, 방대한 프로젝트 지식이나 과거 디버깅 이력은 벡터 데이터베이스(Vector DB) 등을 활용한 장기 기억(Long-term)에 저장한다.
-
메모리 관리: 정보를 단순히 저장하는 것을 넘어 통합(consolidation), 인덱싱(indexing), 망각(forgetting, 에빙하우스 망각 곡선 적용) 등의 관리 작업을 통해 효율성을 극대화한다.
(3) 행동 실행 (Action Execution)
-
도구 호출 (Tool Invocation): 터미널, 파일 시스템, 컴파일러, 웹 검색 등 외부 도구를 API 형태로 호출합니다. 최근에는 MCP (Model Context Protocol) 와 같은 표준화된 인터페이스가 등장하여 에이전트와 도구 간의 상호운용성을 높이고 있다. (PS. 최근엔 claude 가 "SKILL" 이라는 공을 던졌다.)
-
코드 기반 행동 (Code-based Action): JSON 형식의 정적인 행동 정의보다, 실행 가능한 파이썬 코드 자체를 행동(Action)으로 생성하여 실행하는 방식이 더 강력한 유연성과 수정 능력을 보여주는 추세다.
(4) 성찰: 반복, 검증 및 디버깅 (Reflection: Iteration, Validation, and Debugging): Vibe Coding의 핵심인 '결과 중심 검증'을 가능하게 하는 것.
-
반복적 개선 (Iterative Refinement): 초기 생성된 코드에 대해 스스로 비평(Self-Critique)하거나 컴파일러/테스트 결과를 반영하여 코드를 점진적으로 개선한다.
-
지능형 디버깅 (Intelligent Debugging): 실행 중 발생하는 에러나 중간 변수 상태를 분석(Self-Debugging)하여 논리적 오류를 찾아낸다. 예를 들어, Reflexion 프레임워크는 실패 기록을 장기 기억에 저장하여 다음 시도 때 같은 실수를 반복하지 않도록 한다.
-
자가 개선(self-improving) 에이전트는 17~53% 의 추가 성능 향상을 입증했다. 과거 단순한 코드 생성 보조 도구(Assistant) 수준이었던 AI가 이제는 스스로 환경을 설정하고, 코드를 실행하며, 오류를 수정하는 자율적 에이전트(Autonomous Agent) 단계로 진화했음을 보여주고 있다.
(5) 에이전트 협업 (Agent Collaboration)
-
역할 분담 (Role-Based Collaboration): 기획자, 프로그래머, 테스터, 리뷰어 등 에이전트에게 특정 페르소나와 역할을 부여한다.
-
협업 프레임워크: MetaGPT나 ChatDev와 같이 가상의 소프트웨어 회사를 모델링하여, 에이전트들이 표준 운영 절차(SOP)에 따라 대화하며 소프트웨어를 개발하는 방식이 대표적이다.
사견으로 이 "에이전트 협업" 관점이 요즘 개발자들이 가장 활발하게 시도하는 섹터라고 보인다. 다양한 mcp 또는 병렬 호출, 최근의 skills 에 이르기까지, "동시 다발적으로 다양한 형태로 에이전트에게 일을 던지고 A to Z 를 하게 하는 행위" 에 다들 뭔가 하나씩 시도하는게 보인다.
6) 코딩 에이전트 개발 환경
(1) 에이전트가 생성한 코드를 실제로 실행하기 위해서는 격리된 실행 환경(isolated execution environment) 이 필요하다.
Claude CLI가 홈 디렉터리를 삭제해 Mac이 초기화되었어요. 긱뉴스와 레딧에서 아주 인상깊었던 일이다.
-
컨테이너화 기술 (Containerization): Docker와 같은 기술을 사용하여 운영체제 수준에서 가상화를 수행한다. 이는 에이전트에게 일관된 실행 환경을 제공하고, 호스트 시스템과 분리된 독립적인 파일 시스템 및 네트워크 공간을 보장한다.
-
보안 격리 메커니즘 (Security Isolation): 샌드박스(Sandbox)는 1차 방어선 역할을 합니다.
gVisor와 같은 도구나WebAssembly기반 엔진, 그리고Intel SGX/PKU와 같은 하드웨어 기반 격리 기술을 사용하여 에이전트가 시스템의 민감한 자원에 접근하지 못하도록 권한을 엄격히 제한한다. -
클라우드 기반 실행 플랫폼:
Kubernetes와 같은 오케스트레이션 도구를 통해 에이전트의 작업을 격리된 포드(pod)에 할당하고, 수천 개의 CPU 코어에서 대규모로 코드를 실행하고 평가할 수 있는 확장성을 제공한다.
(2) 대화형 개발 인터페이스 환경 (Interactive Development Interface Environment)
개발자가 에이전트와 협업하는 접점(IDE)이 어떻게 진화하고 있는지 설명 하는 섹션이다.
-
AI 네이티브 개발 인터페이스: 기존의 코드 편집기를 넘어, 개발자가 자연어로 의도를 말하면 에이전트가 코드를 생성하고 수정하는 대화형 방식이 주류가 되고 있다. 커서(
Cursor)와 같은 도구는 인라인 제안(Inline Suggestion)과 대화형 상호작용(Conversational Interaction)을 결합하여 문맥을 이해하는 지원을 제공한다. -
원격 개발 (
Remote Development): GitHub Codespaces와 같이 클라우드 상에 미리 구성된 표준화된 개발 환경을 제공하여, 에이전트가 로컬 환경 설정 문제없이 즉시 작업을 수행할 수 있도록 한다. 비슷하게 클로드가 또 https://claude.ai/code 를 통해 웹에서 바이브코딩이 가능하게 만들어버렸다. -
도구 통합 프로토콜 표준: 에이전트가 다양한 도구와 원활하게 소통하기 위한 표준이 만들어졌다. (PS. 클로드가 MCP 공을 던진 뒤로 약간 멱살끌고 가는 느낌)
MCP (Model Context Protocol): 소스 코드나 문서 같은 문맥 정보를 교환하는 범용 인터페이스.LSP (Language Server Protocol): 코드 자동 완성이나 진단 기능을 언어에 상관없이 제공.DAP (Debug Adapter Protocol): 디버깅 상호작용을 표준화.
(3) 분산 오케스트레이션 플랫폼 환경 (Distributed Orchestration Platform Environment)
-
CI/CD 파이프라인 통합: 에이전트가 생성한 코드가 실제 소프트웨어 제품에 통합되기 전에 자동으로 빌드, 테스트, 배포되는 파이프라인(Jenkins, GitHub Actions 등)과 연동된다. ('Vibe Coding'에서도 품질 보증을 위한 필수적인 관문으로 판단된다. 최후의 보루 느낌)
-
클라우드 컴퓨팅 오케스트레이션: TOSCA와 같은 명세나 Kubernetes를 사용하여 컴퓨팅 리소스를 동적으로 할당하고 관리한다. 이를 통해 에이전트의 워크로드를 효율적으로 처리한다.
-
다중 에이전트 협업 프레임워크: 복잡한 개발 작업을 수행하기 위해 AutoGen, CrewAI, MetaGPT와 같은 프레임워크를 사용한다. 이들은 기획자, 개발자, 테스터 등 서로 다른 역할을 가진 에이전트들이 협력하여 문제를 해결하도록 조직화하며, 단일 에이전트보다 높은 신뢰성과 확장성을 제공한다. 나아가 LLMOps라 불리는 기법을 통해 에이전트 자체의 성능 모니터링과 로그 피드백을 자동화하려는 시도를 하고 있다.

- 그리고 이를 발판으로 더 이상 "Single Agent" 로만 접근하지 않는다. 위 논문에서와 같이,
AutoGen,CrewAI,MetaGPT,LangGraph와 같은 프레임워크는 이러한 패러다임을 잘 보여주고 있다.
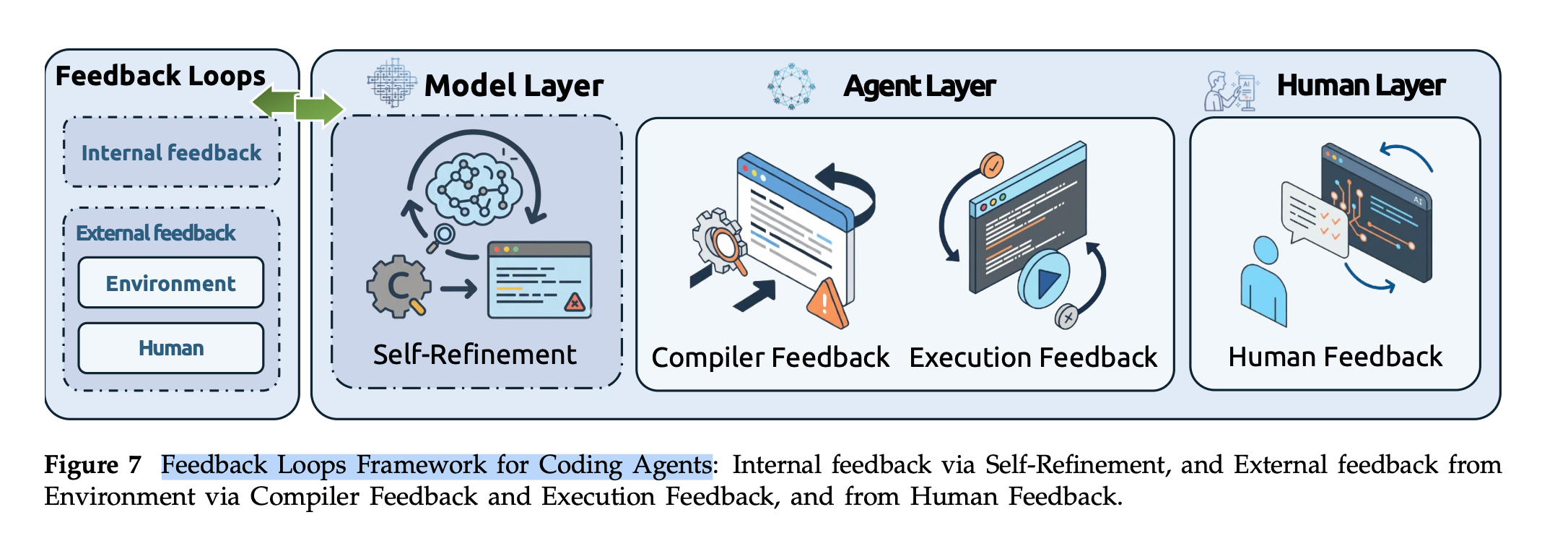
7) 피드백 메커니즘
(1) 컴파일러 피드백(Compiler Feedback)
- 에이전트가 작성한 코드를 컴파일하거나 정적 분석함으로써 얻는 피드백
- 컴파일 에러, 타입 체크 오류, 린트 경고 등이 이에 해당하며, 이러한 피드백을 통해 명백한 문법 오류나 타입 불일치 등을 에이전트가 즉각 수정할 수 있다.
- 예를 들어 "세미콜론 누락"과 같은 컴파일 오류 메시지를 에이전트에게 전달하면, 에이전트는 해당 문제를 해결하도록 코드를 변경한다.
(2) 실행 피드백(Execution Feedback)
- 생성된 코드를 실행하여 얻는 런타임 결과나 테스트 결과를 말한다.
- 프로그램을 실제로 돌려봄으로써 발생하는 예외(exception) 메시지, 실행 로그, 또는 미리 작성된 테스트케이스의 통과/실패 여부 등이 이에 포함된다.
- 에이전트는 예를 들어 "테스트 X 실패: 입력 5에 대해 8이 아닌 10을 반환함"과 같은 피드백을 받아, 논리 오류를 찾아내고 수정하는 과정을 거친다.
(3) 인간 피드백(Human Feedback)
- 개발자 또는 도메인 전문가가 에이전트의 출력에 대해 주는 직접적인 피드백이다.
- 예컨대, 에이전트가 생성한 코드에 대해 개발자가 "이 부분의 알고리즘 복잡도가 높습니다. 더 효율적으로 개선하세요."와 같이 조언하거나, "보안상 이 함수에서는 사용자 입력을 검증해야 합니다."와 같은 지침을 추가로 제공할 수 있다.
- 인간 피드백은 일반적으로 자연어 형태로 제공되며, 에이전트는 이를 해석하여 코드를 개선한다. 이때
RLHF(Reinforcement Learning from Human Feedback)등 학습 기법을 통해 향후 더 나은 출력을 내도록 에이전트를 조정하는 경우도 있지만, Vibe Coding 맥락에서는 실시간 협업 측면의 피드백 제공이 주를 이룬다.
(4) 자체 개선 피드백(Self-refinement)
- 에이전트 스스로가 자신의 출력을 검토 및 개선하는 메커니즘이다.
- 예를 들면, 에이전트가 코드를 생성한 후 곧바로 그 코드를 다시 한번 검토하여 잠재적 버그나 개선점을 찾아내는 것이다.
- 최근 제안된
Reflexion기법 등은 에이전트에게 비판적 리뷰어의 프롬프트를 추가로 주어, 에이전트가 자기 코드의 결함을 찾아내고 수정하도록 유도한다. - 이러한 자기 피드백 루프를 통해 추가 학습 없이도 출력 품질을 향상시키는 효과가 보고되었다.
Self-refinement는 내부 피드백으로 분류되지만, 충분히 체계화된다면 강력한 자동 디버깅 수단으로 활용될 수 있다.
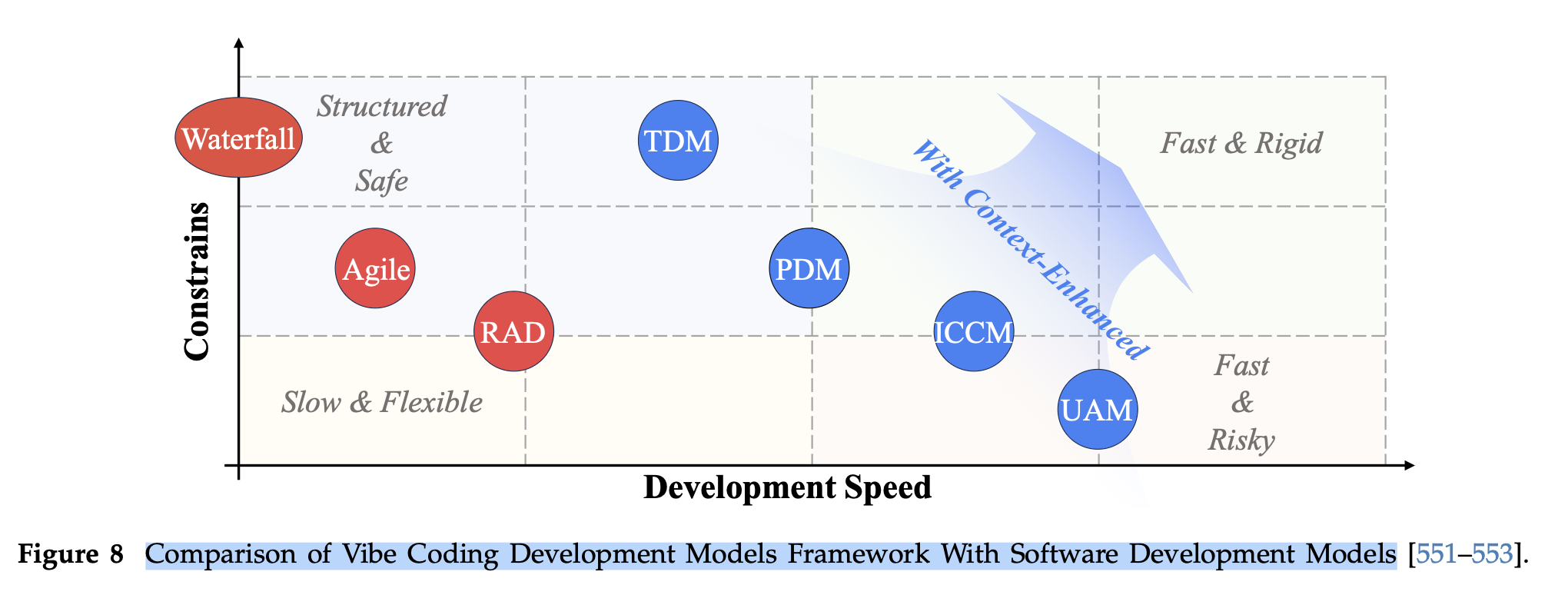
바이브 코딩 개발 모델 프레임워크와 소프트웨어 개발 모델 비교 그래프
CodeCoR: An LLM-Based Self-Reflective Multi-Agent Framework for Code Generation 논문을 보면 CodeCoR 는 Prompt Agent, Coding Agent, Test Agent, Repair Agent 가 밀접하게 협력하는 "자기 성찰(Self-Reflective)" 기반 멀티 에이전트 프레임워크이다.
2. Vibe Coding Development Models
논문은 다음 세 가지 축을 기준으로 모델을 나눈다.
1. 인간의 품질 통제 (Human Quality Control): 개발자가 코드를 얼마나 꼼꼼히 리뷰하고 이해하는가?
2. 구조적 제약 메커니즘 (Structured Constraint Mechanisms): 사전 기획이나 자동화된 테스트가 포함되는가?
3. 문맥 관리 능력 (Context Management Capability): 프로젝트의 기존 코드나 문서를 얼마나 잘 참조하는가?
논문은 이 부분을 "현상, 리서치" 정도로 접근한 것 같다. 오히려 논문의 이 분류와 현 상태덕분에 프로젝트 성격에 따른 '트레이드오프(Trade-off)' 와 '다른 사람은 어떻게 하는지?' 에 대해 더 자세하게 알 수 있었다.
1) 다섯 가지 개발 모델
(1) 무제약 자동화 모델 (UAM, Unconstrained Automation Model)
-
핵심: AI를 전적으로 신뢰하고, 코드를 줄 단위로 검사하지 않으며 기능 동작 여부만 확인한다. ("Vibe Coding"의 원래 정의에 가장 가까움)
-
특징: 에이전트에게 광범위한 자율성이 부여되며, 개발 속도가 매우 빠르고 진입 장벽이 낮아 비전문가도 프로토타입을 빠르게 만들 수 있다. 전통적인 RAD(Rapid Application Development) 와 유사하다.
-
단점: 인간의 면밀한 감독 없이 진행되므로 코드 품질이나 아키텍처 일관성이 떨어질 위험이 있다. 동시에 보안 취약점이나 기술 부채가 쌓이기 쉽고, 유지보수가 어렵다. (이로 인한 사건 사고 이슈가 아주 쏟아지고 있다..)
-
추천: UAM은 일회용 프로토타입이나 개인용 도구처럼 실패 위험이 낮은 시나리오에 적합, 일회성 프로토타입, 개인용 도구 개발.
(2) 반복적 대화 협업 모델 (ICCM, Iterative Conversational Collaboration Model)
-
핵심: AI는 '드라이버(Driver)', 인간은 '내비게이터(Navigator)'가 되어 짝 프로그래밍(Pair Programming) 하듯 지속적인 대화로 개발한다.
AI가 코드 생성 → 사람이 검토 및 이해 → 테스트로 검증 → 결과에 따라 수정 or 확정의 반복. -
특징: 인간이 AI가 짠 코드를 이해하고 검토한 뒤 수락한다. 속도와 품질의 균형을 맞출 수 있으며, 팀 단위 프로젝트에 적합하다.
- 애자일 개발의 페어 프로그래밍(pair programming) 관행과 유사하다고 평가된다.
- IDE에 붙은(내재된) agent 를 활용할때, cursor 에서 자동완성을 수동적으로 사용할때 가장 흔하게 볼 수 있지 않을까 한다.
-
단점: 개발자의 높은 역량이 요구되며, 잦은 리뷰로 피로도가 높을 수 있다.
(3) 계획 주도 모델 (PDM, Planning-Driven Model)
-
핵심: 전통 소프트웨어 공학의 아키텍처 우선 원칙을 Vibe Coding에 적용한 모델이다. 코딩 전에 인간이 기술 사양서, 코딩 규칙 등 '청사진(blueprint)' 을 완벽히 설계한 뒤 AI에게 구현을 맡긴다.
-
특징: 전통적인 워터폴(Waterfall) 방식의 현대적 적용으로 보인다. 구조가 탄탄하고 모듈화가 잘 된 코드를 얻을 수 있다.
-
단점: 초기 기획 문서 작성에 시간이 많이 걸린다. 하지만 이러한 선투자는 이후 유지보수 비용과 재작업 부담을 줄여주며, 팀 협업 시 프로젝트의 이해도를 높이는 효과가 있다.
-
추천: 복잡한 풀스택 애플리케이션, 아키텍처가 중요한 프로젝트에 추천된다.
(4) 테스트 주도 모델 (TDM, Test-Driven Model)
-
핵심: TDD(테스트 주도 개발) 를 적용하여, 인간이 테스트 케이스를 먼저 작성하고 AI가 이를 통과하는 코드를 작성하게 한다. 여기서 조금 더 AI의 손을 빌리면 "켄트 벡(Kent Beck) 형님과 함께하는 Augmented Coding, "증강 코딩" 잘해보기" 형태가 되는 것 같다.
-
특징: 테스트 케이스 자체를 명세(specification) 로 사용한다는 점이 특징이다. 인간의 주관적 리뷰 대신 기계적인 검증(테스트 통과 여부)으로 품질을 보증한다. 리팩토링 안정성이 매우 높다.
-
단점: 테스트 코드를 짜는 초기 비용이 든다.
-
추천: 핵심 알고리즘, 프로덕션 레벨의 애플리케이션에 추천된다.
(5) 컨텍스트 강화 모델 (CEM, Context-Enhanced Model)
-
핵심: 이는 독립적인 워크플로우라기보다는, 위의 4가지 모델에 결합할 수 있는 '수평적 강화 능력'(보강 기법) 이라고 명시한다.
-
특징:
RAG(검색 증강 생성) 기술 등을 활용해 AI에게 프로젝트 전체의 코드, 문서, 스타일 가이드를 주입한다. 그 결과, 에이전트는 코드를 생성할 때 기존 프로젝트 코드와 일관된 명명법과 스타일을 따르고, 기존 함수나 API를 정확히 호출하며, 프로젝트의 아키텍처적 제약을 준수하는 코드를 만들어낼 수 있다.- CEM은 앞서 언급한 네 모델과 자유롭게 조합될 수 있는데, 예를 들어
UAM + CEM조합은 신속하면서도 일정 수준 통제가 가미된 프로토타이핑을 가능하게 하고,ICCM + CEM은 방대한 코드베이스 협업에,PDM + CEM은설계 명세 준수에,TDM + CEM은 최고 수준의 코드 품질 확보에 각각 적합한 접근을 제공한다. - 구현 측면에서, CEM은 프로젝트 초기화 시 벡터 DB 인덱스를 생성하고 대화 흐름마다 관련 정보를 검색하여 맥락으로 주입하는 자동 검색 전략이나, 개발자가 참조할 파일을 직접 지정하는 수동 참조 전략 등으로 실현된다.
- CEM은 앞서 언급한 네 모델과 자유롭게 조합될 수 있는데, 예를 들어
-
효과: AI가 기존 프로젝트의 스타일을 따르고 API를 정확히 호출하도록 하여 환각을 줄이고 일관성을 높인다. 대규모 레거시 코드 유지보수에 필수적이다. (컨텍스트 윈도우를 생각해보자)
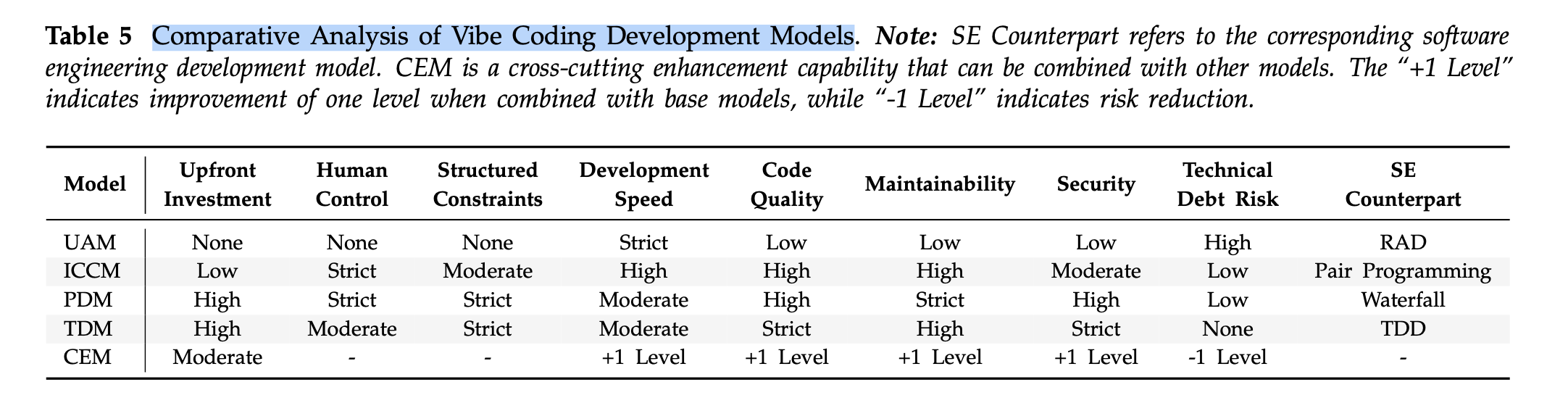
위 5가지 분류에 따르면 나는 PDM + CEM 으로 셋업하고 -> TDM 으로 확장하는 형태에 가장 가깝다. 켄트 벡(Kent Beck) 형님과 함께하는 Augmented Coding, "증강 코딩" 잘해보기 에서도 언급했듯, AI 를 위한 markdown 이 정말 중요해졌고, 이는 RAG와 매우 유사하게 작동된다.
2) 미래 전망 및 과제 (Future Impact and Open Challenges)
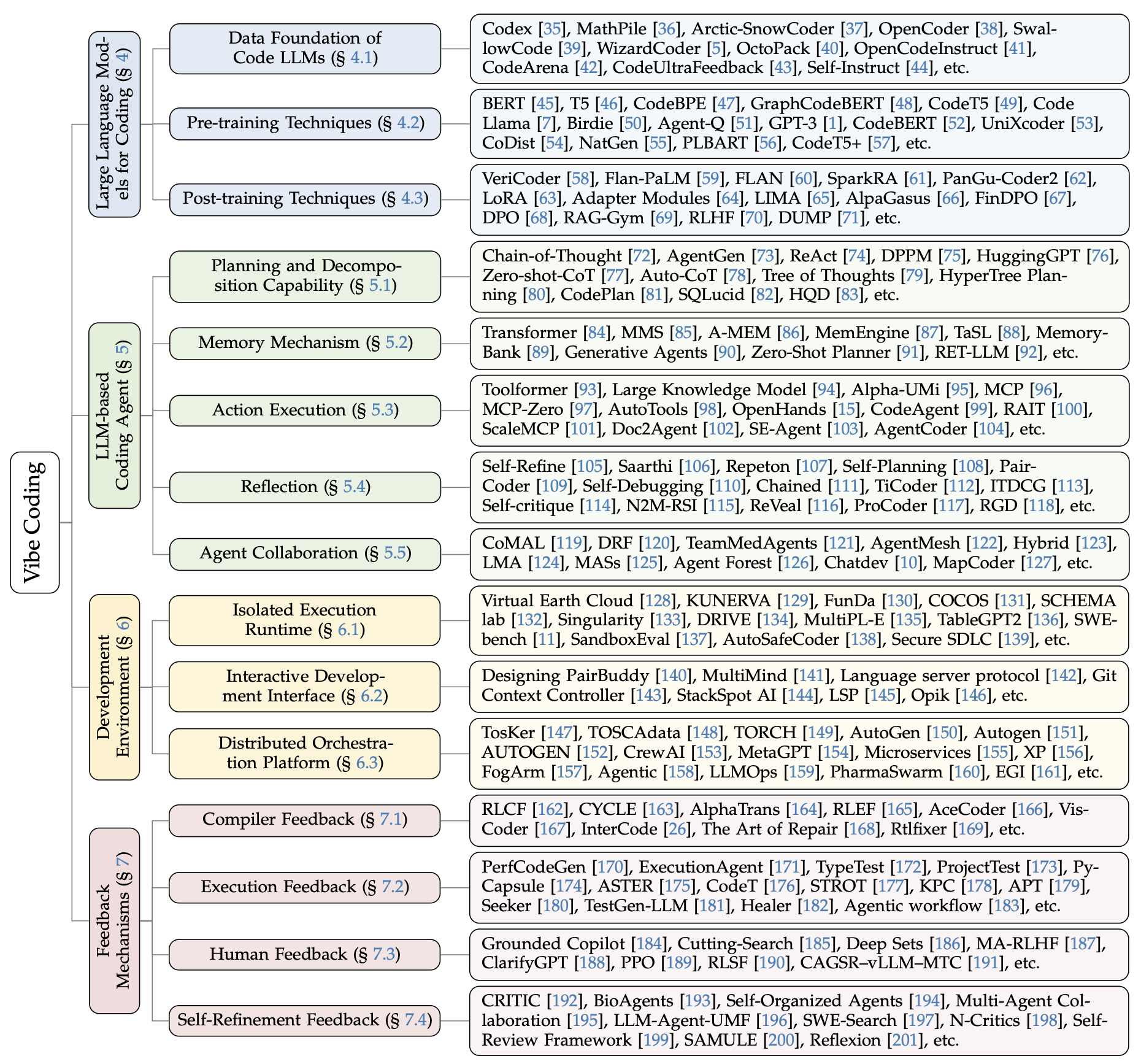
위 사진은 원래 논문에서 가장 먼저 등장하는 "Figure 1" 이다. 다 보고 다시 이 그림을 볼때 더 개괄적으로 거시적인 분류에 대해 좀 더 와닿았다.
The taxonomy of Vibe Coding is categorized into large language model foundations, coding agent architectures, development environments, and feedback mechanisms. Each area encompasses specific techniques and frameworks that collectively advance the systematic integration of LLMs and agents into intelligent and collaborative software development workflows.
(1) 개발 프로세스의 재설계 (Reengineering of Development Process)
-
단계적 주기에서 연속적 마이크로 반복으로: 전통적인 '기획-구현-테스트(SDLC)'의 긴 주기가 "프롬프트-생성-검증(Prompt-Generate-Validate)" 이라는 초고속 반복 주기(수 분~수 초)로 대체된다. 설계와 구현의 경계가 흐려지며, 개발자는 실행 결과(Vibe)를 보며 실시간으로 요구사항을 수정한다. (끊임없이 대화하며 점진적으로 목표를 만족시켜가는
iterative goal satisfaction방식) -
개발자 역할의 재정의: 개발자는 코드를 직접 짜는 '저자(Author)'에서, AI에게 맥락을 제공하고 결과를 조율하는 '문맥 엔지니어(Context Engineer)' 이자 '아키텍트(Architect)' 로 역할이 바뀌고 있다.
-
프로젝트 관리의 난관: 코드 생성 속도가 예측 불가능(어떤 기능은 1분, 어떤 건 수 시간)해져 공수 산정이 어려워지며, 기존의 코드 리뷰 방식(라인 단위 검토)이 작동하지 않게 된다.
(2) 코드 신뢰성과 보안 (Code Reliability and Security)
-
수동 리뷰의 한계: AI가 짠 코드를 인간이 일일이 검토하는 것은 Vibe Coding의 장점(속도)을 깎아먹는 모순이다. 또한, 개발자가 AI가 생성한 복잡한 로직을 완전히 이해하지 못할 수도 있다. (개발 속도와 확실성 사이의 트레이드오프 딜레마)
-
통합된 보안 피드백 루프: 따라서 인간의 개입 없이도 AI가 코드를 생성하는 즉시 보안 취약점을 잡는 자동화된 가드레일이 필수적이다. 전통적인 정적/동적 분석 도구(SAST/DAST)를 프롬프트-생성-검증 사이클에 내장하여, 에이전트가 코드를 내놓을 때마다 자동으로 보안 스캐닝과 품질 분석을 수행하고 그 피드백을 즉각 에이전트에게 제공하는 통합 피드백 루프가 이상적
- 생성 전(Pre-Generation): 프롬프트 단계에서 보안 요구사항 주입.
- 생성 중(In-flight): 코드가 생성되는 즉시 정적 분석(SAST) 수행
- 샌드박스 동적 분석: 실행 시점에 동적 분석(DAST) 및 퍼징(Fuzzing)을 통해 런타임 취약점 탐지
-
AWS의 AI 보조 코드 생성기인
Amazon CodeWhisperer(현 Amazon Q Developer)는 코드 완성 시 보안 취약점 스캔 결과를 함께 제시하는 초기 기능을 선보였는데, 향후에는 이보다 더욱 지능적이고 상황 인지적인 보안 검사 에이전트가 개발되어, Vibe Coding 과정 전반에 걸쳐 인간을 대신해 지속적인 경계 역할을 수행해야 할 것이다. -
마지막 방어선으로서 인간 개발자가 최종 감수를 하는 방안도 고려된다. 예컨대 Vibe Coding을 적용하더라도, 안전이 중요한 코드나 윤리적으로 민감한 영역에서는 최종 배포 전에 보안 전문가 또는 개발 리드가 결과물을 점검하여 승인하는 절차를 유지함으로써, 속도와 안전성 사이의 균형을 찾는 것이다. Vibe Coding의 보편화를 위해서는 이러한 다층적인 보안/신뢰성 확보 체계에 대한 연구 개발이 시급하다.
(3) 에이전트 감독의 확장성 (Scalable Oversight)
-
새로운 위험 요소: 자율 에이전트는 연쇄 오류(Cascading Errors) 를 일으키거나, 불필요한 라이브러리를 마구 설치하는 의존성 증식(Dependency Proliferation) 문제를 야기할 수 있다.
-
확장 가능한 감독 아키텍처: 인간이 모든 걸 감시할 수 없으므로, "약한 감독자가 강한 에이전트를 통제(Weak-to-Strong Generalization)" 하는 기술이 필요합니다.
- 계층적 감독: 작은 AI 모델이 큰 AI 모델을 1차로 감시.
- 다중 에이전트 토론(Multi-Agent Debate): 여러 에이전트가 서로의 코드를 비평하며 오류를 찾아내는 기술 필요.
- 자동화된 감시견(Watchdog): 에이전트가 권한을 넘어서는지 감시하는 별도의 AI 도입.
(4) 인간적 요소 (Human Factors)
-
새로운 협업 방식에 대한 거부감이나 신뢰 부족은 Vibe Coding 채택의 큰 장애가 될 수 있다. 따라서 에이전트의 의사결정 근거를 설명하는 설명가능성(XAI) 제공, 개발자가 에이전트의 진행 상황을 쉽게 이해하고 개입할 수 있는 UI/UX 디자인, 그리고 개발자의 심리적 안정감을 높일 수 있는 컨트롤 옵션 등이 중요하다.
-
멘탈 모델의 전환: 개발자는 '알고리즘 구현'보다는 '의도 표현(Intent Articulation)' 과 '문맥 구성(Context Engineering)' 에 집중해야 한다.
-
새로운 필요 역량: 프롬프트 엔지니어링, 작업 분해 능력(Task Decomposition), 그리고 AI가 만든 결과물을 검증하는 품질 감독 능력이 코딩 능력보다 중요해진다.
-
책임과 신뢰의 문제: AI가 버그를 만들었을 때 누구의 책임인가? 개발자가 AI를 맹신(Over-reliance)하거나 지나치게 불신하는 문제를 어떻게 해결할 것인가에 대한 조직적 논의가 필요하다.
-
주니어들에게 더 이상 간단한 코드 작성 작업보다는 요구사항 명세 작성이나 테스트 시나리오 설계에 집중하게 될 수 있다. 이때 숙련된 개발자와 초급 개발자 간의 업무 분담을 어떻게 새롭게 정의할지, 조직 내 평가 체계나 커리어 패스를 어떻게 조정할지도 인적 측면의 과제다.
-
인간이 최종 결정권자로 남아있는 구조를 어떻게 구현할지도 고민해야 합니다. 자동화된 에이전트에게 과업을 위임하더라도, 중요한 제품이나 시스템에 대해서는 인간이 결과를 최종 승인하도록 하는
Human-In-The-Loop메커니즘을 설계함으로써 예측하지 못한 실수를 방지해야 한다.
출처
