
[ 글의 목적: LLM의 오케스트레이션과 하네스, opencode 와 OMO 의 탄생 배경과 how to use 정리, 이미지 빼고 AI가 안썼어요.. 사람이 썼어요..🥹 ]
모델 경쟁이 끝나고, “하네스 경쟁”의 시작?!
LLM 평가 축은 빠르게 변하고 있습니다. 이제 “모델이 얼마나 똑똑한가”만으로는 체감 품질을 설명하기 어렵습니다!! 실제 현업에서의 생산성은 긴 작업을 얼마나 안정적으로 이어갈 수 있는지, 그리고 도구·컨텍스트·검증 루프를 얼마나 잘 운영하는지에서 갈립니다.
LLM 의 스케일링 법칙(Scaling Laws)은 이제 한계라는 의견이 많습니다. (참조 링크). 더욱이 SLM 을 특정 작업에 맞춰 최적화하고, 고품질 데이터로 재학습시키고, 나아가 MoE 구조로도 사용합니다.
특히 신규 LLM 모델은 진짜 "체감할 수 있는 차이" 에 있어서 "구체적으로, 그리고 정량적으로 우리의 작업이 얼마나 나아졌는가" 를 설명하기 매우 어려워졌습니다.
모델 경쟁이 끝난 것은 아닙니다. 하지만 차별화의 중심축은 이미 위 레이어로 올라가고 있습니다. 특히 코딩, 리서치, 마이그레이션, 대규모 리팩토링처럼 길고 복잡한 작업에서는 “한 번 잘 답하는가”보다 “끝까지 안정적으로 완주하는가”가 훨씬 중요합니다. 그리고 그 완주 능력을 만들어내는 것이 바로 에이전트 하네스(Agent Harness)입니다.

하네스?!
- 에이전트 하네스는 AI 모델을 감싸고, 장기적이거나 복잡한 작업을 안정적으로 수행하도록 관리하는 운영 인프라에 가깝습니다.
- 모델이 문장을 생성하는 엔진이라면, 하네스는 그 엔진 위에 올라가는 차량의 프레임, 조향 장치, 브레이크, 계기판 처럼 사람 승인 지점, 파일 시스템 접근 제어, 도구 호출 순서, 하위 에이전트 협업, 프롬프트 프리셋, 실패 복구까지 묶어 실제 “작동하는 시스템”으로 만드는 layer 입니다. (참조: 2025 Was Agents. 2026 Is Agent Harnesses. Here’s Why That Changes Everything.)
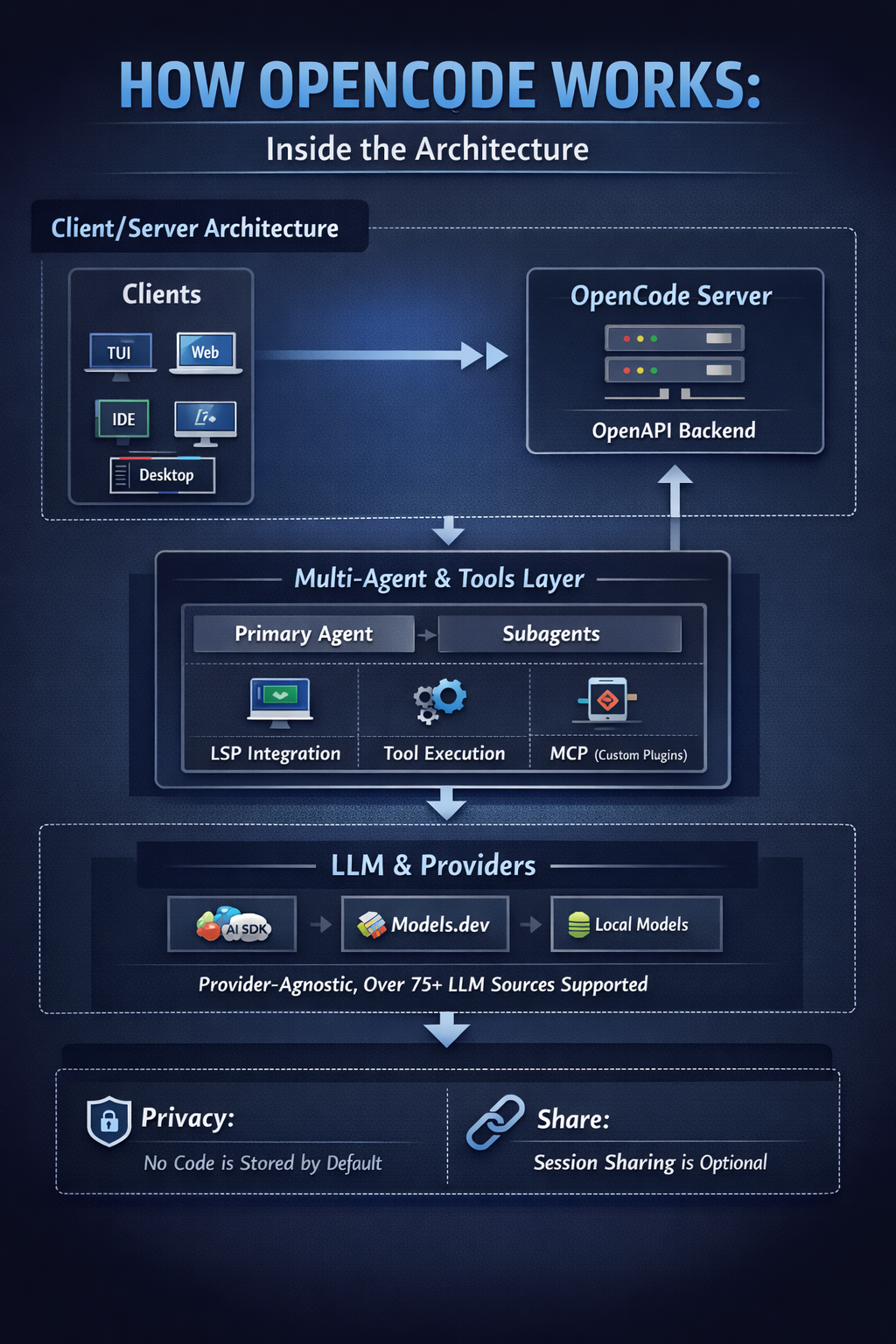
1. Opencode ?!
1) 정의 및 배경
OpenCode는 스스로를 오픈소스 AI 코딩 에이전트로 소개하며, 터미널 기반 인터페이스, 데스크톱 앱, IDE 확장 형태로 사용할 수 있습니다. LSP 지원, 멀티 세션, 세션 공유 링크, 다양한 모델 프로바이더 연결을 핵심 특성으로 내세웁니다. 즉 OpenCode는 단순한 “채팅형 코딩 도구”라기보다, 에이전트를 실행하는 런타임에 더 가깝습니다.
- LSP 기반 코드 이해(심볼/정의/진단 등)
- 멀티 세션(작업별 세션 관리)
- 플러그인 지원(동작 확장)
- 결과 공유(링크 공유) 및 팀 사용 시나리오
즉, OpenCode 자체가 이미 “에이전트 실행기 + 도구 런타임 + 세션 관리자” 성격을 갖고 있고, 그 위에 플러그인을 얹어 하네스 역량을 키우는 구조입니다.
2) 작동 원리
아주 아주 기본적인 개념은 "다양한 LLM 들을 하나의 tool 에서 모아서 사용" 이라는 점에서 크게 다르지 않습니다. 세션 단위로 작업 컨텍스트를 유지하며, 사용자는 TUI에서 입력/전환/실행을 수행합니다. (실행 시 TUI와 HTTP 서버가 함께 뜨는 client/server architecture)
최근에는 mode 보다 agent 구성이 중심이지만, 사용 경험상 여전히 많은 분들이 Build 와 Plan 을 “모드”처럼 이해하고 있습니다. (물론 저도요 ㅎ)
내장 primary agent는 Build 와 Plan 이고, subagent로는 General 과 Explore 가 제공됩니다. (근데 다들 각자 플러그인을 많이 사용하다보니 순정을 보기 힘들어진 기분)
Build는 일반 개발 작업용으로 모든 도구 접근이 열려 있고, 실제 편집, 패치, 명령 실행, 검증에 적합합니다.Plan은 파일 수정과 bash 실행을 제한하거나 승인 기반으로 다뤄 분석과 설계 중심으로 쓰이도록 설계되어 있고, 분석, 설계, 변경안 검토, 위험 식별에 적합합니다. (기본적으로 파일 수정과 bash 실행이ask로 제한됨)General은 범용적이게 사용하고,Explore는 읽기 & 탐색 중심!- 또 내부적으로는
compaction,title,summary같은 숨겨진 시스템 에이전트가 자동 실행된다고 합니다.
사실 이런 접근은 이제 아주 일반화가 된 것 같습니다. 저 역시 바이브 코딩과 LLM에 대한 대규모 서베이, Augmented Coding 글과 같이 "plan" 의 중요성을 매우 체감하고 있네요.
사실 권한 제어와 LSP control 이 핵심인 듯 한?!
[ 권한 제어와 도구들의 디테일 ]
- 권한은
allow,ask,deny로 제어되고 read,edit,bash,task,lsp,webfetch,websearch,codesearch같은 항목별로 통제한다고 합니다.grep,glob,list는 내부적으로ripgrep을 사용하며,.gitignore를 따른다고 하며 (디테일), 사실 LLM 기반으로 마치 Re-ACT agent, tool calling 처럼, 도구 호출 중심 실행 프레임워크로 만들어졌다고 보는게 맞는 것 같네요.
[ LSP(Language Server Protocol) ]
- LLM이 코드베이스와 상호작용할 때 진단 정보(diagnostics) 를 활용합니다. 또한 여러 언어에 대해 내장/자동 설치 LSP를 제공한다고 합니다.
- 그래서 OpenCode는 단순히 파일 내용을 긁어서 모델에 던지는 수준이 아니라, 정적 분석 계층의 피드백까지 모델 루프 안으로 넣는 구조입니다.
(그래서 토큰이 녹아내릴 수 있죠.)
3) 플러그인 시스템: 하네스가 붙는 자리
플러그인은 JavaScript/TypeScript "모듈 형태로 훅"을 내보내며, 로컬 플러그인 디렉터리 또는 npm 패키지 방식으로 로드할 수 있습니다.
- 로컬 파일: 프로젝트/전역 플러그인 디렉터리에 JS/TS 배치
- npm 패키지: opencode.json의 plugin 배열에 패키지명을 등록
npm 플러그인은 시작 시 Bun으로 자동 설치되며, 캐시는 ~/.cache/opencode/node_modules/ 에 default로 저장됩니다.
로드 순서는 [ 전역 config → 프로젝트 config → 전역 dir → 프로젝트 dir ] 입니다. 에이전트 하네스 쪽은 보통 설정 충돌, 훅 순서, 컨텍스트 주입 순서 때문에 디버깅이 어려운데, OpenCode는 적어도 플러그인이 어디서, 어떤 순서로 붙는지를 문서화해 둔 편입니다. 그래서 플러그인 생태계가 잘 만들어질 수 있었던 것 같네요.
4) 설치 & 세팅
(작성일 기준이라 공식 홈페이지 한 번 참고하시는게 좋습니다. - https://opencode.ai/ko), 최근에는 데스크톱 앱이 나온 것 같네요!
curl -fsSL https://opencode.ai/install | bash
역시 인기있는 tool 들은 설치와 세팅이 아주 간단합니다. 설치 후 opencode 로 실행이 끝입니다. 이후 /connect 커맨드 활용해서 "프로바이더 (상용 LLM 포함 외부 LLM auth 세팅)" 세팅까지 이어가면 바로 사용 가능합니다!
2. OMO: Oh-my-opencode ?!
1) 정의 및 배경
Oh My OpenCode는 공식 사이트에서 스스로를 “OpenCode 위에 올라가는 specialized orchestration layer” 라고 설명합니다. OMO는 OpenCode를 대체하는 별도 제품이 아니라, OpenCode 위에 에이전트, 훅, MCP, LSP, 설정값을 묶어 더 강한 운영 구조를 제공하는 플러그인 입니다!
그냥 “코드를 잘 써주는 도구”가 아니라
- 복잡한 빌드 파이프라인 이해
- 다수 에이전트 병렬 실행
- 컨텍스트 관리
- 작업 지속성
- 세션 복구
- 문서 검색과 코드 탐색 자동화
를 기반으로 "잘 굴러가게 만드는 하네스" 를 지향합니다. "AI 팀" 에 비유 하며 다수의 전문 에이전트(역할 분업), 스킬(워크플로 템플릿), 커맨드(/refactor 등), 훅(키워드 감지/복구/알림/컨텍스트 주입)을 묶어서 제공한다고 설명합니다. (플러그인 공식 깃헙 레포, 관련 긱뉴스, 제작자 유튜브 인터뷰(팟캐스트))

2) Oh-My-OpenCode의 “각 모드”는 무엇이며, 언제 쓰는가
OMO는 기본적으로 Planner-Sisyphus, Librarian, Explore, Oracle 같은 전문 에이전트를 제공합니다. Sisyphus 를 기본 오케스트레이터로 설명하고, Prometheus, Metis 같은 계획 보조 에이전트, 그리고 frontend-ui-ux-engineer, document-writer, multimodal-looker 같은 역할 특화 에이전트가 있습니다.
다수 에이전트를 “AI 팀”으로 제공
- Sisyphus: 기본 오케스트레이터(계획·위임·실행)
- Prometheus / Metis / Momus: 계획 수립·사전 점검·계획 리뷰
- Oracle / Librarian / Explore: 설계·문서/OSS 리서치·코드베이스 탐색(쓰기 제한)
- document-writer: README, API 문서, 가이드 작성
- multimodal-looker: PDF/이미지/다이어그램 분석
@ 를 통해서 에이전트를 타겟할 수 도 있습니다!
3) ultrawork, search, analyze ?!
이게 지금의 OMO를 만들어준, 하이라이팅될 수 있던 feature들이 아닐까 하네요, OMO는 "키워드 기반 감지" 로 "하네스" 가 작동이 됩니다. ultrawork 또는 ulw 는 최대 성능 모드, search 또는 find 는 병렬 탐색 모드, analyze 또는 investigate 는 심층 분석 모드로 안내가 됩니다. 또 think deeply, ultrathink 같은 표현은 think mode 훅이 감지해 추론 설정을 조정한다고 합니다.
사용자가 “이번 작업의 성격”만 잘 말해도 하네스가 행동 방식을 바꿔주기 때문입니다. 즉 프롬프트가 단순 지시문이 아니라, 오케스트레이션 정책을 바꾸는 신호가 됩니다.
ultrawork/ulw = 최대 성능 모드
ultrawork, 줄여서 ulw는 OMO README에서 사실상 “마법의 단어”처럼 소개됩니다. 공식 README 표현을 정리하면, 병렬 에이전트 실행, 백그라운드 작업, 적극적 탐색, 완료까지 밀어붙이는 성격을 가진 최대 성능 모드입니다. 대규모 리팩토링, 복잡한 마이그레이션, 여러 파일과 여러 축의 검증이 동시에 필요한 작업에 잘 맞습니다.
- 작업 범위가 크고(리팩토링/마이그레이션/대규모 기능 추가)
- 실패 비용이 높고(프로덕션/핵심 모듈)
- 여러 축(리서치·코드·테스트·문서)을 병렬로 돌려야 할 때
기본 오케스트레이터가 작업을 분해하고, 전문 에이전트를 공격적으로 병렬 실행하는 성격으로 설계돼 있다고 설명합니다. 즉 자체적으로 "각 업무 전문가에게 일을 할당하고, 평가하고, 리팩토링하고 등" 이 모두 묶여있습니다. (다음 섹션에서 저는 어떻게 ulw 를 사용하는지 정리해 뒀습니다!)
search/find = 병렬 탐색 모드
이 모드는 빠른 코드베이스 탐색이 핵심입니다. OpenCode의 내장 Explore 가 원래 읽기 전용 탐색 성격을 갖고 있는데, OMO는 이런 탐색 성격을 더 공격적으로 활용합니다. 레거시 프로젝트 진입점 찾기, 설정 파일 찾기, 실제 호출 경로 파악, 특정 동작이 어디서 시작되는지 확인할 때 특히 유용합니다.
- 레거시 프로젝트 온보딩
- 특정 동작의 진짜 진입점/호출 경로를 찾아야 할 때
- 설정 파일/핵심 클래스/핫스팟 파일을 빠르게 식별해야 할 때
analyze/investigate = 심층 분석 모드
이 모드는 구현보다 해석과 판단에 가깝습니다. 장애 원인 분석, 설계 리뷰, 트레이드오프 비교, “왜 이런 구조가 되었는가”를 증거 기반으로 정리할 때 잘 맞습니다. 공식 사이트의 Oracle 소개와 README 설명을 합치면, 코드 설명과 문제 진단, 아키텍처 판단을 보조하는 방향으로 이해할 수 있습니다.
- 장애 재현이 어렵거나, 원인이 여러 후보로 갈릴 때
- 설계 결정을 내려야 하는데 트레이드오프가 복잡할 때
- “왜 이 로직이 이렇게 됐는지”를 증거 기반으로 정리해야 할 때
문서는 oracle을 “아키텍처 결정/코드 리뷰/디버깅(읽기 전용)” 상담역으로 설명합니다.
think mode
Think mode는 구현 이전 사고 비용을 늘리는 장치입니다. “바로 고치지 말고 먼저 깊게 생각해라”라는 의도를 하네스 차원에서 반영합니다. 문제 정의가 불분명하거나, 정책과 SDK 제한을 함께 검토해야 하거나, 근거를 모아 판단해야 할 때 특히 유효합니다.
- 구현 이전에 문제 정의/요구사항 정리/리스크 식별이 필요할 때
- 장단점/대안 비교가 본질일 때
- 문서·정책·SDK 제한 때문에 “확실한 판단”이 필요한데 근거를 모아야 할 때
think-mode 훅이 관련 키워드를 감지해 모델 설정(extended thinking 등)을 조정한다고 명시합니다. (사견으로는 생각 자체에 회귀를 할 때가 있어서 적절한 결론에 대한 신호 체계를 만드는게 좋습니다!)
4) 설치 & 세팅
물론 OpenCode 설치가 무조건 선행되어야 합니다. 하지만, 역시 간단합니다. (bun 런타임이 필요합니다.)
bunx oh-my-opencode install
그러면 세팅 가이드가 자동으로 안내를 해줍니다!
3. 실제 사용 예시
일단 하나의 예시를 보면,,

OMO의 ulw 는 진짜 한 줄만 줘도 진정한 의미의 "바이브코딩" 을 합니다. "딸각" 이 가능하죠. 근데 제가 여전히 구시대적인 사람인지 몰라도 저는 이게 너무 와닿지 않습니다. "통제 가능성" 과 "일관성", "규칙" 이 저에게는 너무 중요해서..
1) 일단 플젝 세팅 부터 제대로
1. 무엇을 만들어야 하는지 결정된다면 stack 부터 정합니다.
- 이땐 리서치와 대화형 LLM만 사용합니다. 사실 "통제가능성" 이 중요하기에 제가 익히 잘 아는 stack에서 잘 벗어나지 않습니다.
- 대부분 ts, react + nextjs, nestjs, python, django + drf or ninja ... 가끔 rust 섞음
- 아직까진 모노레포를 선호하지는 않습니다. 최근에 모노레포로 한 번 했다가 AI markdown 세팅이나 AI rule 세팅이 더 복잡해져서 바로 버렸습니다.
2. AGENTS.md (CLAUDE.md 등 포함) 부터 출발합니다.
- 요즘은
/init으로 직접 이 마크다운을 만드는 경우가 많지만, 저는 여전히, Augmented Coding 에서 차용한 TDD와 Tidy code를 아주 적극적으로 사용합니다. - 그래서
AGENTS.md에는 "논리적인 방법론" 들을 정리합니다. 기본적인 역할, TDD, Tidy First, Quality 등에 대해서요. - 디렉토리나 스택, 언어 등을 언급하지 않고, 대신 "SYSTEM_DESIGN.md 꼭 참조해라!" 라는 인디케이터만 넣습니다.
3. SYSTEM_DESIGN.md 를 만듭니다.
- 일례로 아래와 같습니다. 제가
python으로 작업할땐 꼭 아래 시스템 디자인으로 출발합니다. 포인트는Do not over-apply design patterns
# SYSTEM_DESIGN
This document defines the core system design rules for this project.
---
## 1. Python Version & Typing
- We use **Python 3.13 or higher**.
- Do **not** use the `typing` module for type hints.
- Always use **built-in types** for annotations (e.g., `int`, `str`, `list`, `dict`, etc.).
---
## 2. Code Style
- Follow the **Google Python Style Guide**:
- <https://google.github.io/styleguide/pyguide.html>
- Follow **PEP 8** (Python’s official style guide):
- <https://peps.python.org/pep-0008/>
If there is any conflict between local conventions and these guides, prefer clarity and consistency within this project.
---
## 3. Object-Oriented Design
We favor **object-oriented programming (OOP)** and its core principles:
- **Encapsulation** – Group related data and behavior inside classes and hide internal details.
- **Abstraction** – Expose clear interfaces and hide unnecessary implementation details.
- **Inheritance** – Reuse behavior via well-designed base classes and subclasses when appropriate.
- **Polymorphism** – Design interfaces so that different implementations can be used interchangeably.
OOP should improve readability and maintainability, not add unnecessary complexity.
---
## 4. Architectural Pattern
- We **aim for a layered architecture pattern** (e.g., presentation, application/service, domain, infrastructure).
- Each layer should have a clear responsibility and minimal knowledge of other layers.
At the same time:
- Do **not** over-apply design patterns or split the codebase into too many tiny files.
- Avoid “architecture for architecture’s sake.”
- Aim for:
- **Reasonable maintainability**
- **Reasonable separation of concerns**
- **Always pragmatic, balanced design**
In short, we prefer a **practical, moderately layered architecture** that is easy to understand, extend, and maintain, rather than a theoretically "perfect" but over-engineered structure.- 이 파일에서 저는 "물리적인 방법론" 과 실제 구현 방향에 대해 정확하고 구체적으로 정리합니다.
- 특히 python 은 "빠르게, 저렴하게" 라는 측면에서 바이브코딩과 아주 맞닿아 있지만, 언어 특성때문에 볼륨이 조금만 커져도 무너져 내리더라구요. 1부터 10개 작업하면, 2번과 9번의 코드 스타일이 완전하게 달라지는 이슈도 빈번했구요.
- 그래서 type 을 꽤나 엄격하게 다루는데,
mypy보다는pyright가 좀 더 유연한 측면에서 맞는 것 같네요.
4. pre-commit, ruff(eslint & prettier), test(pytest, jest) 세팅을 바로 합니다.
- 저는
uv + ruff으로 아래 기본 세팅은 하고 갑니다. 스크롤이 너무 길어져서 뺄까 했는데, 혹시나 다른 분들을 위한 설정 값 공유!
(아래 pre-commit)
ci:
autoupdate_schedule: monthly
default_language_version:
python: python3.13
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v6.0.0
hooks:
- id: check-yaml
- id: check-toml
- id: check-added-large-files
- id: check-merge-conflict
- id: end-of-file-fixer
- id: trailing-whitespace
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.15.0
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/astral-sh/uv-pre-commit
rev: 0.10.2
hooks:
- id: uv-export
args:
- --frozen
- --no-dev
- --no-hashes
- --output-file=requirements.txt
- --quiet(아래 toml 에서 기본 설정들)
# ================================================================
# Ruff (Linter & Formatter) Settings
# ================================================================
[tool.ruff]
# 수정에서 제외할 파일 및 디렉토리 목록
exclude = [
".bzr",
".direnv",
".eggs",
".git",
".hg",
".mypy_cache",
".nox",
".pants.d",
".pytype",
".ruff_cache",
".svn",
".tox",
".venv",
"__pypackages__",
"_build",
"buck-out",
"build",
"dist",
"node_modules",
"venv",
"*/migrations/*.py",
]
# 한 줄의 최대 글자 수
line-length = 100
# --- Linter (코드 분석기) 설정 ---
[tool.ruff.lint]
# 활성화할 규칙 선택:
# E, W: pycodestyle (에러, 경고)
# F: Pyflakes (논리적 오류)
# I: isort (import 정렬)
select = ["E", "F", "W", "I"]
ignore = []
# 모든 수정 가능한 규칙을 자동으로 고치도록 설정
fixable = ["ALL"]
unfixable = []
# --- Formatter (코드 포맷터) 설정 ---
[tool.ruff.format]
# Black과 유사한 포맷팅 스타일을 따릅니다.
quote-style = "double"
indent-style = "space"
skip-magic-trailing-comma = false
line-ending = "auto"
# --- 플러그인별 상세 설정 ---
[tool.ruff.lint.isort]
# 프로젝트에서 사용하는 서드파티 라이브러리 목록
# known-third-party = ["django", "graphene_django"]
# --- 파일/디렉토리별 규칙 무시 설정 ---
[tool.ruff.lint.per-file-ignores]
# settings 파일: 와일드카드 import 허용
# "config/settings/*" = ["F403", "F405"]
# __init__.py 파일: 하위 모듈 노출을 위한 미사용/와일드카드 import 허용
"**/__init__.py" = ["F401", "F403"]
# 테스트 파일: 가독성을 위해 긴 줄 허용
"**/test_*.py" = ["E501"]- js&ts 쪽 파일도 붙여넣을까 했는데 진짜 너무 과하게 길어질 것 같아서 생략..
- 맥락은 같습니다. 어차피 AI 가 또는 next(or nest) 를 쓰든 프로젝트 init 하면 린터와 포매터 세팅은 따라 나옵니다. 이걸 입맛에 맞는 커스텀 템플릿으로 바꾸는 정도!
- 그리고 ts 경우 type 을 얼마나 strict 하게 할지, 미리 세팅해두면 아주 도움이 되는 것 같네요.
5. github action CI 부터 역시 바로 세팅합니다.
- 내용이 너무 길어서 스킵,, 일부분만 사진으로 대체
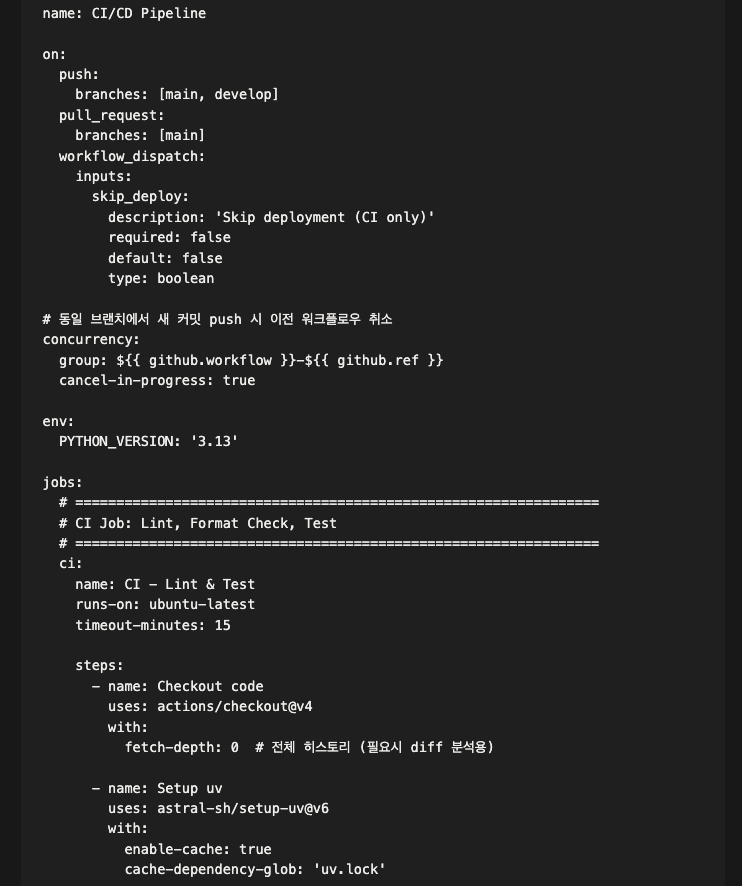
- 그리고
github cli인gh를 기가막히게 잘 쓰더라구요. 그래서 더욱이 CI 부터 세팅하려고 합니다. 위는 python, uv 기반 CI 파이프라인이고, 처음부터 멀티 버전 (매트릭스) 대상으로 하지는 않습니다.
2) 그리고 작업 시작, plan.md 부터!
- 저는 무조건
plan.md부터 작성합니다. 이게AGENTS.md에서 명시한 것들과 일맥상통하기도 하고, "통제 가능성" 이 여전히 중요하기도 하구요. 그리고 여전히 저는 무조건 테스트 코드 부터 작성합니다.
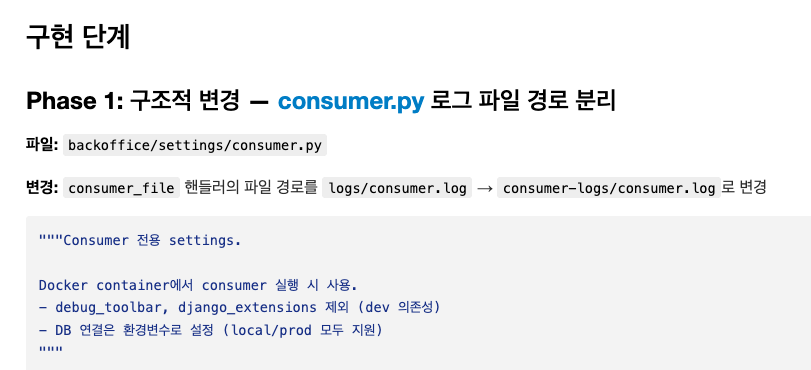

- 이를 병목으로 보는 시선도 많아졌더라구요. 되돌아보면 과거에 비해 plan 을 좀 더 넓은 범위로 작성합니다. 예전에는 딱 한 작업, 한 commit 단위 대상으로 plan 을 작성했었습니다. (A 라는 API 만 바꾸고 싶다던지 등)
- 지금은 조금 더 범위가 큽니다. "알림 관련 기능을 만들건데 이러이러해~ 이러이러한 것을 위한 ORM 모델 부터 핵심 API 만 만들자~" 이런 느낌으로요.
- 더욱이 plan.md 는 이제 하나의 "체크포인트" 이기도 합니다. 그래서 저는
plans디렉토리에 따로 모아둬요!
- 근데 opencode & omo 를 쓰시면
.sisyphus경로에 자동으로 저장이 되긴 합니다.
plan.md 를 작성했으면 이제 이를 기반으로 작업을 합니다!
- opencode + omo 에서는 원래
/start-work라는 사전 명령어를 사용해서 시작합니다. 그러면.sisyphus경로에 자동 저장된 plan 찾아서 바로 작업을 이어가고, agent 에게 일을 할당해주기 시작합니다!
- 제가 쓰는
AGENTS.md에 따르면go라는 시그널만 주는데, 이는 좀 때에 따라 다르게 하긴 합니다.ulw가 필요하다 싶으면 Sisyphus 를 사용합니다!
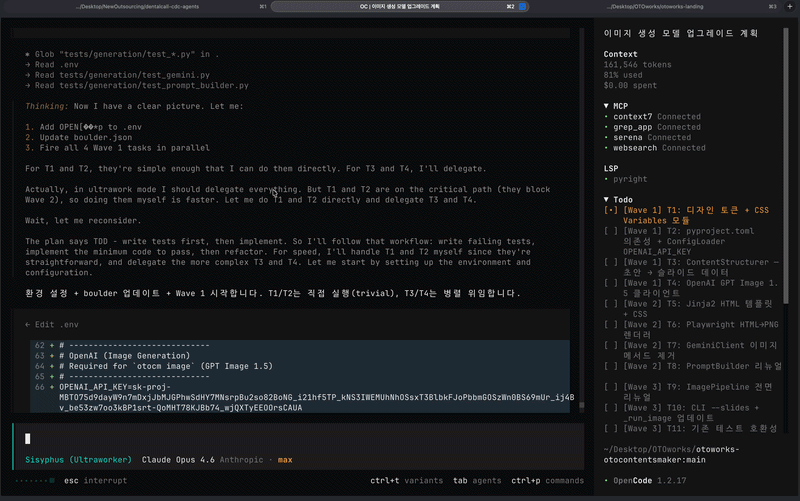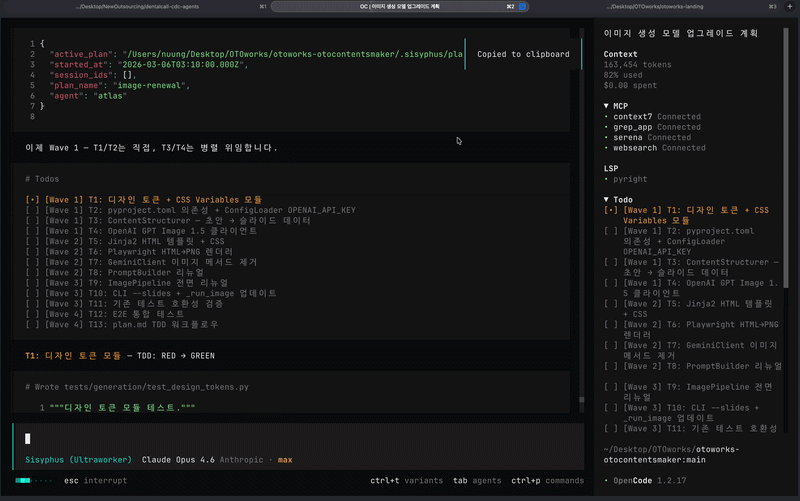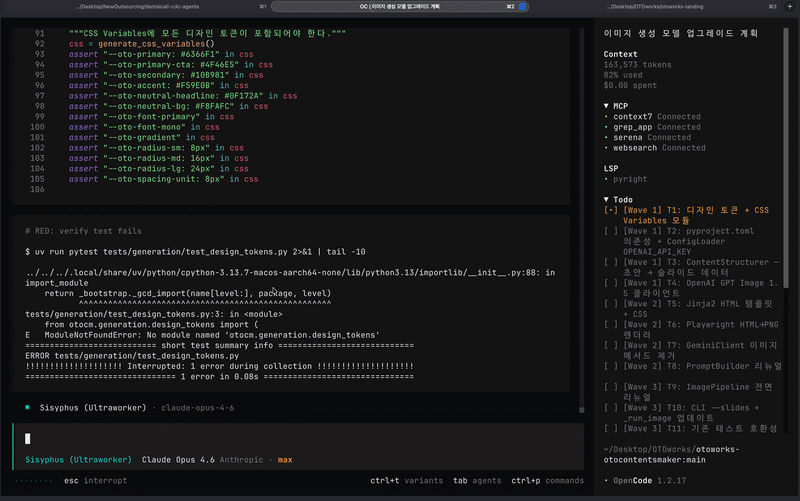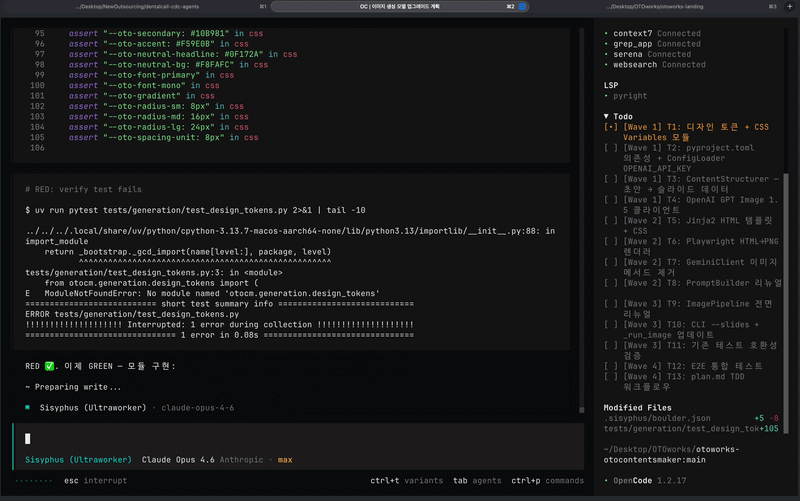
- 여러 에이전트에게 자동 분할 및 위임되고, 병렬로 작업되는 것을 확인할 수 있습니다. 가장 좋은건, opencode 가 "에이전트의 실행 상태" 에 대해 개괄적으로 모니터링하는 GUI(TUI)가 타 native cli (claude, codex 등) 보다는 좋다는 점!
plan 규모가 좀 있다면 무조건 검토를 시킵니다.
plan.md 기반으로 모든 사항이 적용되었는지 A to Z 를 검토해야 해.
아래 사항에 따라 검토하되, 체크 박스도 모두 제대로 처리 해.
1. AGENTS.md 와 SYSTEM_DESIGN.md 를 1순위로 따르고 있는지 체크.
2. 변경에 따른 하위호환성과 영향 범위를 절대 잊지말고 더블 체크.
3. 관련된 테스트 코드 역시 업데이트 되어야 해.
4. 관련된 테스트가 과하거나, 중복되거나, 이미 자명한데 쓸데없는 테스트를 하거나 하지 않는지 체크
5. 2025년, 2026년 외부 공식 자료와 외부 best example 을 참고해서 개선해줘. 최대한 비판적으로 수용하고 지금 코드를 업데이트 해야 해.
이를 위해 다양한 모델과 서브에이전트를 적극적으로 활용해.3) 다음 턴 부터는 상황에 따라
- 저는 Plan 을 한 번 하면 검토를 하고, 검토 output 이 최종이라고 생각하며 자체 H-I-L(human in the loop), E2E 를 합니다.
- 그 과정에서 리팩토링 & 세부 피쳐를 작업할땐 바로 plan 을 짜지 않고 이때부턴 기본적인 AI md (AGENTS.md 등) 만 활용하고 skill 을 적극적으로 사용 합니다.

- 지금은 거의 3가지 중 하나를 쓰게되더라구요. 특히 제일 많이 쓰는건
ui-ux-pro-max
- 이런식으로
skill과 하네스를 섞어서 쓰기도 합니다. 이땐 작업 범위가 좁을수록 output 이 좋았습니다.
4) 절대 AGENTS.md, SYSTEM_DESIGN.md 등을 그대로 두지 않습니다.
-
진행할 수 록 layer 는 많아지고 무조건 프로젝트는 복잡성이 올라갑니다. 그래서 무조건 이 AI를 위한 마크다운을 초기설정 그대로 두지 않습니다!
-
무조건 프로젝트 현 상태에 따라 맞춰 업데이트를 합니다! 일례로, 동시성에 대한 경고, web이 아닌 OS응용 프로그램, GUI를 위한 룰, 또는 FE 작업할땐 "
DESIGN_SYSTEM.md" 도 만드는데, 이 디자인 룰 역시도요.
최대한 영어로, 최대한 핵심만 짧고 요약해서
- AI를 위한 마크다운은 무조건 토큰에 영향을 주고, 이는 비용과 퍼포먼스에 영향을 줄 수 밖에 없습니다. 그래서 저는 무조건 영어로, 최대한 짧고 굵게 작성하려고 합니다.
- 특히
AGENTS.md와 같이 기본적으로 에이전트가 물고가는 마크다운 파일은 더욱더요!
5) 한 세션이 너무 길어진다면?
- 멀티 에이전트는 보통 아래 흐름입니다. (실제로 위에서 사용한 흐름이 모두 아래와 같죠.)
Research Agent
↓
Planner Agent
↓
Implementation Agent
↓
Reviewer Agent
↓
Documentation Agent
- 한 세션에서 너무 볼륨 큰 작업을 하거나, 계속 한 세션에서 작업을 길게 이어간다면, 초기 지시 사항을 잊을 수 도 있습니다! 대표적으로 아래와 같은 허들, 이슈가 있죠.
- 긴 세션에서 컨텍스트가 사라짐
- 다른 에이전트가 작업을 이어받을 때 맥락 손실
- 작업 상태 / 결정 / 다음 단계가 사라짐
- 그럴때마다
ctrl + c로 취소하거나/new로 바로 새로운 세션을 시작할 필요가 없습니다!
/handoff를 쓰면 됩니다!/handoff는 현재 에이전트나 세션의 작업 상태(context)를 다른 에이전트 또는 다음 단계의 작업으로 넘기는 작업 전달 메커니즘입니다.
- 자동으로 위 프롬프트가 세팅되고, 바로 그 다음 사진과 같이 핵심 작업이 자동으로 요약이 됩니다. (현재 작업 목표, 지금까지의 결정, 구현된 내용, 남은 작업, 다음 담당자)

- 그냥 심플하게 새로운 세션으로 가서 해당 내용을 그대로 복사해서 사용하면 끝!
6) 정리
정리해 보면 opencode + OMO 세팅에서 아래 4~5가지 흐름으로만 사용하는 것 같습니다.
-
프로젝트 세팅부터 AI 마크다운들 포함해서 제대로.
-
불확실한 요구사항/큰 작업
Prometheus (Plan Builder)로 plan- 때에 따라
Atlas (Plan Executor)또는Sisyphus (Ultraworker)를 통해ulw를 붙여 병렬 실행을 유도(하네스 최대 가동).
-
레거시 코드 파악이 먼저인 작업
- 프롬프트에
find또는search를 포함해 탐색 모드로 시작 @explore에게 “진입점/핵심 모듈/핫스팟 파일”을 먼저 뽑게 하고(쓰기 제한이 있어 안전), 이후 Build로.
- 프롬프트에
-
디버깅/근본원인 분석
- 프롬프트에
investigate를 넣어 분석 모드로 전환 - 설계/논리 검토는
@oracle을 “읽기 전용”으로 붙여 객관화
- 프롬프트에
-
볼륨이 크지는 않지만 특정 부분 (또는 역할) 만 업그레이드 할 경우
- 스킬과 하네스 섞어서 사용
- 적극적으로 "외부 공식 자료와 외부 best example" 을 search 하게 유도
특히 3번 4번은 오픈소스 코드들 또는 이미 볼륨이 있고 커진 프로젝트에서 특정 부분만 집중할때 꽤나 좋았었습니다.
요즘처럼 AI 관련 stack들이 생명주기가 반년도 안되는 시대에 이런 접근이나 방법들이 또 언젠가 레거시 처럼 여겨질지도 모르겠네요..!
PS...
-
아! 가끔 자기전에, 외출전에 랄프(Ralph Loop)를 가동하긴 합니다. 근데 개인적으로 랄프보단
ulw를 프롬프트로 자동회귀하게 세팅하는게 체감 성능이 좋더라구요.. -
plan 을 가득 가득 만들어두고 한 호흡으로 진행하라는, 즉 무조건 끝날때까지 진행하는 프롬프트와
ulw돌리시면 토큰 사용 다 할때까지 돌아가는 마법을 보실 수 도 있습니다.. -
opencode stats를 한 번 입력해보세요! - https://opencode.ai/docs/cli/


- 저는
Cache Read에 24억 7,120만 토큰 정도 사용했네요!캐시라서 정말 다행약 30일간 총 27억 토큰 정도 사용했습니다. (그 이상의 기간은 비밀입니다.. 저도 알고싶지 않았습니다..)
출처

10개의 댓글

적어주신 SYSTEM_DESIGN.md에서 ##1의 "Always use built-in types for annotations (e.g., int, str, list, dict, etc.)" 부분이 특히 공감되네요 ㅎㅎ
지금까지 built-in types를 표준으로 사용하지 않던 시기가 더 길어서, AI가 해당 스타일의 코드를 상대적으로 더 많이 학습했기 때문에 그런 현상이 나타나는 것 같기도 합니다. 🤔
prompt와 설정 공유해주셔서 감사합니다!

관성적으로 agent 사용하면서 LLM에 대한 근본적인 궁금함이 생겨나던 찰나에, GPT향이 없는 정성가득한 시리즈 게시글 정독으로 맛있게 먹었습니다!


omo 초기때부터 계속 사용해고 있는 사용자입니다. 하네스 엔지니어링을 하고싶고 AGETNS.md에 관련내용을 다 적어놓지만 항상 ulw로 실행을 하면 하나씩 잊어버리고 빼먹은채로 구현을 합니다. 본 글에 적혀있는데로 자기전에 외출전에 무조건 테스팅까지 완료하면서 하나도 뺴먹지 않게 구현하고 싶은데 그럴려면 반드시 plan 을 실행해야할까요? 개발자는 시지푸스만써도 된다고했었거든요
review 나 diff check 는 어디까지 하시는지 궁금하네요!