
[ 글의 목적: python 에서 context manager 가 필요한 상황과 원리, with 에 대한 deep dive, python 3.13 기준!! ]
Python context manager
python 에는 with 구문이 있다. (사실 2005년 PEP 343 부터 있었던 고인물). 동시성 얘기와 context manager 얘기하는데 왜 with 냐? 사실 이 질문은.. 고민이 역전된 질문이다. 정확히 말하면 with는 context manager를 사용하기 위한 문법이기때문!
사실 batch 중심 서비스에서 celery 쓰긴 과해서, 기존 운영 DBMS 에 추상화된 task model 로 단일 python runtime process 띄워서 처리하는데, 이 "task" 객체 모델링하다가 삘받아서 쓰는 정리글인건 비밀이다.
1. 동시성 처리
이제는 멀티코어 프로세서가 일반화되고 I/O 집약적인 작업을 효율적으로 처리하기 위해 동시성 프로그래밍이 거의 기본 개념이 되어버렸다. (왜 동시성 처리가 필요한지는 이제 너무 식상한 얘기가 되어버린 것 같은..)
이제 멀티스레딩, 멀티프로세싱뿐만 아니라, 단일 스레드 내에서도 이벤트 루프와 코루틴을 활용해 동시성을 극대화할 수 있다. (python 코루틴(coroutine) - 동시성과 병렬성, 동기와 비동기 작업, blocking과 non-blocking 그리고 코루틴 / javascript - 기본 동작 원리와 v8 js 엔진 참조)
근데 with 랑 context manager 얘기하면서 왜 동시성 얘기 부터 하느냐? 사실 동시성 프로그래밍에서 가장 까다로운 문제는 바로 "공유 리소스 관리(Shared Resource Management)" 이기 때문이다.
즉 여러 스레드나 코루틴이 파일, 데이터베이스 커넥션, 네트워크 소켓과 같은 공유 리소스에 동시에 접근할 때, 접근 순서를 제어하고 사용 후 리소스를 안정적으로 해제하지 않으면 경쟁 상태(Race Condition), 데드락(Deadlock), 리소스 누수(Resource Leak) 등 심각한 문제로 이어질 수 있기 때문이다.
import threading
lock = threading.Lock()
shared_resource = 0
def worker():
global shared_resource
# with 구문이 lock의 획득(acquire)과 해제(release)를 보장합니다.
with lock:
# 이 블록은 한 번에 하나의 스레드만 실행할 수 있는 임계 영역(Critical Section)입니다.
data = shared_resource
data += 1
# 다른 스레드가 끼어들 수 있는 잠재적 위험 구간
time.sleep(0.1)
shared_resource = data
# ... 스레드 생성 및 실행 ...
# 또는 장고에서
from django.db import transaction
def my_view():
with transaction.atomic():
# 이 블록 안의 작업이 하나의 트랜잭션으로 묶임
do_something()
do_something_else()python 하면 위 코드는 식상할 정도로 뭔가 많이 본 형태다. 누군가 "왜 with 를 쓰나요?" 라고 한다면, "lock 을 저 block 에서만 사용하고 빠빠이 하려고요!" 라고만 답하게 된다면, 조금 더 아래를 내려보자!
1) 동시성 처리에서 Context Manager가 필수적인 이유
- 결론부터 말하면, 안전한 리소스의 '획득'과 '해제'를 보장하기 때문 이다.
동시성 환경에서는 여러 실행 흐름이 언제든지 CPU를 점유하고 리소스에 접근할 수 있다. 이때 리소스 접근을 제어하는 '락(Lock)'을 획득하고 사용 후 반드시 '해제'해야 한다.
만약 락을 해제하는 코드가 실행되기 전에 예외가 발생한다면? 해당 락은 영원히 해제되지 않아 다른 스레드들은 무한정 대기하는 데드락 상태에 빠지게 된다.
Context Manager 는 with 블록에 진입할 때 리소스를 획득하고, 블록을 빠져나올 때 예외 발생 여부와 관계없이 반드시 리소스를 해제하는 작업을 수행하도록 보장한다. 이것이 동시성 프로그래밍에서 Context Manager가 필수적인 이유다.
with 없는 lock 획득 예시
import threading
lock = threading.Lock()
def unsafe_operation():
lock.acquire() # 락 획득
# ... 공유 리소스 작업 ...
if some_error_condition:
raise ValueError("오류 발생!")
lock.release() # 예외 발생 시 이 코드는 절대 실행되지 않음!위 문제는 try ... finally 로 해결 가능
# 조금 나아진 예시: try...finally 사용
def slightly_better_operation():
lock.acquire()
try:
# ... 공유 리소스 작업 ...
if some_error_condition:
raise ValueError("오류 발생!")
finally:
lock.release() # finally 블록으로 해제를 보장- 이 code 형태는 java 에서도 매우 유사하다.
- 하지만 위 예시는 lock 이 필요한 부분에서 코드 자체가 겁나 지저분해진다는 한계가 있다. 그렇다고 매번
try ... finally구문을 추상화 해서 사용할 수 도 없는 것.. (자주 바뀌게 되어있음...)
이걸 with 로 해결한 파이써닉한 처음 예제!
import threading
lock = threading.Lock()
def safe_operation():
with lock: # 진입 시 lock.acquire(), 탈출 시 lock.release() 자동 호출
# ... 공유 리소스 작업 ...
if some_error_condition:
raise ValueError("오류 발생!")
# with 블록이 끝나면 예외가 발생해도 락은 안전하게 해제됨- with 를 쓰는게 확실하게 깔끔하다. (물론 depth 가 깊어진다는 trade-off도 있다.)
- 그러면 이
with가 이걸 어떻게 해결한다는 건가? 어떻게 진입 시lock.acquire(), 탈출 시lock.release()자동 호출을 한다는 것이가!?!?
2) 아니 그래서 with 가 뭔 상관인데유
with, 걍 resource leak 방지 하려고 한거 아녀유?
- 매우 맞다. 근데 이는 "with" 의 특성때문에 이 목적이 가능한거다!
# 리소스 누수 예시
def leak_file_descriptors():
# 이 함수를 반복 호출하면 결국 에러 발생
f = open('temp.txt', 'w')
f.write('leak')
# f.close()를 의도적으로 누락- (위 코드) 파일을 열고
close()를 호출하지 않는 코드가 반복 실행되면 운영체제가 프로세스에 할당한 파일 디스크립터(File Descriptor) 개수 제한에 도달 해 "Too many open files" 오류가 발생한다.with는 이걸 원천적으로 막아준다.
# 리소스 누수 방지
def no_leak_example():
with open('temp.txt', 'w') as f:
f.write('safe')
# with 블록이 끝나면 f.close()가 자동으로 호출됨with 는 컨텍스트 관리 프로토콜(Context Management Protocol) 을 따르는 객체와 함께 동작한다.
-
with는 "Context Manager"를 위한 "Syntactic Sugar" 이다. contextlib — with 문 컨텍스트를 위한 유틸리티 -
쉽게 말하면
__enter__()와__exit__()메소드를 구현한 객체로with문 사용 시 자동으로 호출되는 메서드들이다.(만약 던더메서드, 매직메서드를 모른다면 이 글은 도움이 못된다.)
-
__enter__(self):with블록에 진입할 때 호출된다. 리소스를 획득하고 설정하는 역할을 하며,as키워드로 변수에 할당할 값을 반환한다. -
__exit__(self, exc_type, exc_value, traceback):with블록을 "빠져나올 때" 반드시 호출된다. 리소스를 해제하는 역할을 한다. 만약 블록이 예외 없이 정상 종료되었다면 세 인자(exc_type, exc_value, traceback)는 모두 None이 된다. 예외가 발생했다면 해당 예외 정보가 전달된다.__exit__메서드가True를 반환하면 예외가 전파되지 않고 억제된다.
with 의 바이트 코드
import dis
def my_func():
with open('file.txt', 'w') as f:
f.write('hello')
dis.dis(my_func) 3 RESUME 0
4 LOAD_GLOBAL 1 (open + NULL)
LOAD_CONST 1 ('file.txt')
LOAD_CONST 2 ('w')
CALL 2
BEFORE_WITH
L1: STORE_FAST 0 (f)
...생략...
4 L2: LOAD_CONST 0 (None)
LOAD_CONST 0 (None)
LOAD_CONST 0 (None)
CALL 2
POP_TOP
RETURN_CONST 0 (None)
L3: PUSH_EXC_INFO
WITH_EXCEPT_START
...생략...-
왜 갑자기 바이트코드냐면,, 지금 cpython 3.14 이상인 main인 깃헙 레포에는
with에 대한 코드를 찾기 어렵다.. "Remove the BEFORE_WITH and BEFORE_ASYNC_WITH instructions. Add the new :opcode:LOAD_SPECIALinstruction" 때문 ㅠ -
덧붙이자면
with문은Python 3.11부터 도입된 특화 적응형 인터프리터(Specializing Adaptive Interpreter) 덕분에 고도로 최적화된 바이트코드를 사용한다. - https://peps.python.org/pep-0659/ & https://www.youtube.com/watch?v=shQtrn1v7sQ (아니 그니까 좀 python 최소한 3.11 이상은 써라 제발 좀) -
여튼
BEFORE_WITH가__enter__이며WITH_EXCEPT_START가with에서 예외 발생 시__exit__(...)호출 하기 위한 세팅이다.파이썬이 이렇게나 상위 문법을 지원해줘서 감사할따름
2. contextlib 모듈과 제너레이터
-
사실
__enter__와__exit__를 가진 클래스를 매번 작성하는 것은 "귀찮다". 이럴때마다 파이써닉이 와닿는데,contextlib내장 라이브러리가 이 과정을 훨씬 쉽게 만들어주는@contextmanager데코레이터를 제공한다. -
https://github.com/python/cpython/blob/main/Lib/contextlib.py 에서 실제 해당 내장 라이브러리의 코드 참조!
1) @contextmanager 데코레이터의 내부 구현
@contextmanager 데코레이터는 제너레이터(Generator) 함수를 손쉽게 Context Manager로 변환해 준다. 이 데코레이터는 내부적으로 _GeneratorContextManager 라는 헬퍼 클래스를 사용하여 제너레이터를 컨텍스트 관리 프로토콜에 맞게 래핑한다.
def contextmanager(func):
"""@contextmanager decorator.
Typical usage:
@contextmanager
def some_generator(<arguments>):
<setup>
try:
yield <value>
finally:
<cleanup>
This makes this:
with some_generator(<arguments>) as <variable>:
<body>
equivalent to this:
<setup>
try:
<variable> = <value>
<body>
finally:
<cleanup>
"""
@wraps(func)
def helper(*args, **kwds):
return _GeneratorContextManager(func, args, kwds)
return helper_GeneratorContextManager
class _GeneratorContextManager(
_GeneratorContextManagerBase,
AbstractContextManager,
ContextDecorator,
):
"""Helper for @contextmanager decorator."""
def __enter__(self):
# do not keep args and kwds alive unnecessarily
# they are only needed for recreation, which is not possible anymore
del self.args, self.kwds, self.func
try:
return next(self.gen)
except StopIteration:
raise RuntimeError("generator didn't yield") from None
def __exit__(self, typ, value, traceback):
if typ is None:
try:
next(self.gen)
except StopIteration:
return False
else:
try:
raise RuntimeError("generator didn't stop")
finally:
self.gen.close()
else:
if value is None:
# Need to force instantiation so we can reliably
# tell if we get the same exception back
value = typ()
try:
self.gen.throw(value)
except StopIteration as exc:
# Suppress StopIteration *unless* it's the same exception that
# was passed to throw(). This prevents a StopIteration
# raised inside the "with" statement from being suppressed.
return exc is not value
except RuntimeError as exc:
# Don't re-raise the passed in exception. (issue27122)
if exc is value:
exc.__traceback__ = traceback
return False
# Avoid suppressing if a StopIteration exception
# was passed to throw() and later wrapped into a RuntimeError
# (see PEP 479 for sync generators; async generators also
# have this behavior). But do this only if the exception wrapped
# by the RuntimeError is actually Stop(Async)Iteration (see
# issue29692).
if (
isinstance(value, StopIteration)
and exc.__cause__ is value
):
value.__traceback__ = traceback
return False
raise
except BaseException as exc:
# only re-raise if it's *not* the exception that was
# passed to throw(), because __exit__() must not raise
# an exception unless __exit__() itself failed. But throw()
# has to raise the exception to signal propagation, so this
# fixes the impedance mismatch between the throw() protocol
# and the __exit__() protocol.
if exc is not value:
raise
exc.__traceback__ = traceback
return False
try:
raise RuntimeError("generator didn't stop after throw()")
finally:
self.gen.close()_GeneratorContextManager 가 이미 매우, 충분히 잘 만들어져 있기때문에, (제발 다시 처음부터 만들지 말고) @contextmanager 이거 부터 사용할지 고민해봐야 한다.
__enter__메서드
- context manager에 진입할 때 호출
- 제너레이터의 첫 번째 yield까지 실행
- yield된 값을 반환 (보통 with 문의 as 변수에 할당)
__exit__메서드
- context manager에서 나갈 때 호출
- 예외가 없으면: 제너레이터가 정상 종료되는지 확인
- 예외가 있으면: 제너레이터에 예외를 전달하여 처리 기회 제공
- 예외 억제 여부를 결정하여 반환
간단한 해당 class 의 flow chart 는 아래와 같다.
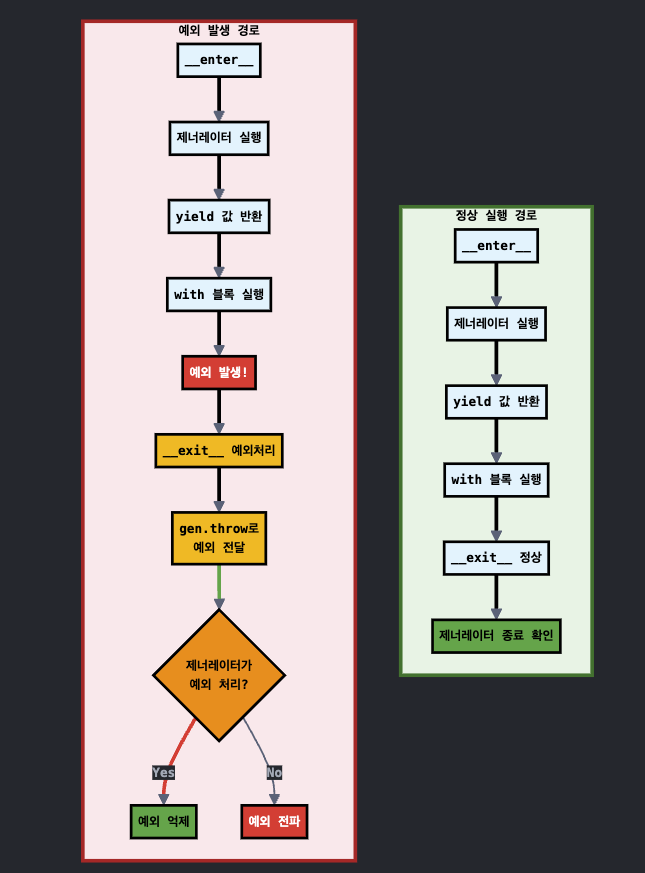
예외 발생시의 gen.throw(value) 조금만 더 보자!
-
예외가 있으면,
__exit__메서드는 전달받은 예외 정보(typ, value, traceback)를 사용하여 제너레이터의throw()메서드를 호출한다. -
즉,
gen.throw(value)를 통해 제너레이터가yield에서 멈춰있던 지점으로 예외를 '주입' 한다. 그러면 제너레이터 함수 안의try...except블록에 의해 잡히게 된다. -
그러니까
@contextmanager를 사용한 함수에서try...except에서 잡히게 된다는 거고,try...except를 써야 좀 더 depth 있는 디버깅을 할 수 있다는 것!
수동 클래스 구현 vs. @contextmanager 데코레이터
# 방법 1: 클래스로 직접 구현
class Timer:
def __enter__(self):
self.start = time.time()
print("타이머 시작")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
end = time.time()
print(f"소요 시간: {end - self.start:.2f}초")
return False # 예외를 억제하지 않음
# 방법 2: @contextmanager 데코레이터 사용
from contextlib import contextmanager
import time
@contextmanager
def timer():
start = time.time()
print("타이머 시작")
try:
yield # __enter__의 반환값 (여기선 None), 이 지점에서 with 블록 코드가 실행됨
finally:
# with 블록을 빠져나오면 이 코드가 실행됨
end = time.time()
print(f"소요 시간: {end - start:.2f}초")
# 사용법은 동일
with timer():
time.sleep(1)@contextmanager 를 사용하면 try...yield...finally 패턴으로 __enter__ 와 __exit__ 의 로직을 훨씬 직관적으로 표현할 수 있다.
- yield 이전까지의 코드:
__enter__에 해당 - yield 이후 finally 블록 안의 코드:
__exit__에 해당
_GeneratorContextManager는 __enter__가 호출되면 제너레이터를 yield 지점까지 실행하고, __exit__ 가 호출되면 예외 정보를 제너레이터의 throw() 메서드로 주입하거나 next() 를 호출하여 finally 블록이 실행되도록 한다.
더욱이 이제 "바이트코드" 로 구현되어 있어서 최소한의 오버헤드를 추가 한다고 한다.
2) 얘랑 제네레이터랑 무슨 연관이 있음?
사실 제네레이터를 모르면 위 예제들이나 설명이 와닿지가 않는다. (python 코루틴(coroutine) - iterator, generator, asyncio, async, await 그리고 코루틴 (2) 참조) 단순한 정의를 보면 python 에서 제네레이터는 "이터레이터를 생성하는 함수" 이다. yield 표현식을 사용하고 다음 호출 시 마지막으로 실행된 yield 표현식 이후부터 실행을 재개한다.
-
실행 흐름의 일시 중단 및 재개: yield 키워드는 함수의 실행을 잠시 멈추고 제어권을 호출자에게 넘겨준다.
with블록의 코드가 실행되는 동안 제너레이터는yield지점에서 대기하게 된다. -
상태 유지: 제너레이터 함수 내의 "지역 변수"는
yield를 통해 중단되었다가 다시 재개될 때까지 그 상태를 그대로 유지한다. (start 변수처럼) -
예외 주입: 제너레이터의
throw()메서드를 사용하면 제너레이터가 멈춰있는yield지점 외부에서 예외를 발생시킬 수 있다.@contextmanager는 이 기능을 활용해with블록의 예외를 제너레이터 내부로 전달한다. 이 얘기가 바로 위에서 본 "예외 발생시의 gen.throw(value)" 얘기다.
그리고 사실 대용량 처리일 수 록, "메모리 관점의 이점이 상당하다." 이건 당연히 제네레이터의 특성이자 이를 기반으로 할 수 있는 with 의 결과론적인 이점이다.
- 리소스 누수 방지 & 리소스 자동 정리 & 제네레이터 & 캐시 지역성
3) 실제 사용하면 좋은 케이스
데이터베이스 연결 관리
- 데이터베이스 연결은 열고 닫는 것뿐만 아니라, 작업 성공 시
commit, 실패 시rollback을 수행해야한다.
from contextlib import contextmanager
import sqlite3
@contextmanager
def db_transaction(db_path):
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
print("DB 커넥션 및 트랜잭션 시작")
try:
yield cursor # with 블록에서 사용할 커서 객체를 반환
print("트랜잭션 커밋")
conn.commit()
except Exception as e:
print(f"예외 발생: {e}, 트랜잭션 롤백")
conn.rollback()
raise # 예외를 다시 발생시켜 호출자에게 알림
finally:
print("DB 커넥션 종료")
conn.close()
# 사용 예시
with db_transaction('app.db') as cursor:
cursor.execute("INSERT INTO users (name) VALUES ('Alice')")
# 만약 여기서 예외가 발생하면 자동으로 롤백됩니다.근데 사실 SQLAlchemy 같은 대부분의 최신 DB 라이브러리는 이미 자체적으로 뛰어난 Context Manager를 내장하고 있어 직접 만들 필요는 거의 없다.
# SQLAlchemy의 내장 Context Manager 예시
from sqlalchemy.orm import Session
with Session(engine) as session:
session.add(User(name="Bob"))
# 예외 발생 시 자동으로 롤백, 정상 종료 시 커밋 (설정에 따라 다름)
session.commit()
# 세션은 자동으로 닫힘- 그리고 본문 가장 초기에 언급한 django transaction 예제도 내부적으로 context manager protocol 에 따른 형태로 class가 구현된 것을 볼 수 있다. ㅎㅎ
분산 락과 동기화
여러 서버에 걸쳐 리소스 접근을 동기화해야 할 때 Redis 같은 외부 저장소를 이용해 분산 락을 구현할 수 있다. 이때도 Context Manager는 매우 유용하다.
(나쁜예)
import redis
# 락을 획득했지만, 프로세스가 갑자기 죽으면 락이 해제되지 않을 수 있음
def bad_distributed_lock(r, lock_key):
is_acquired = r.set(lock_key, "locked", nx=True, ex=30)
if is_acquired:
# ... 임계 영역 작업 ...
r.delete(lock_key) # 작업 중 오류가 나면 실행되지 않음
else:
print("락 획득 실패")(context manager 예시)
from contextlib import contextmanager
import redis
import uuid
@contextmanager
def distributed_lock(r: redis.Redis, lock_key: str, timeout: int = 30):
lock_id = str(uuid.uuid4())
# 락 획득 시도 (nx=True는 키가 없을 때만 set)
if not r.set(lock_key, lock_id, nx=True, ex=timeout):
raise TimeoutError("분산 락을 획득할 수 없습니다.")
try:
yield lock_id # 락을 획득했음을 알림
finally:
# 내가 획득한 락이 맞는지 확인하고 안전하게 삭제 (Lua 스크립트 사용)
release_script = """
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
"""
r.eval(release_script, 1, lock_key, lock_id)
# 사용 예시
r = redis.Redis()
try:
with distributed_lock(r, "my-distributed-lock") as lock_id:
print(f"락 획득 성공 (ID: {lock_id})")
# 여러 서버에서 공유하는 중요한 작업 수행
except TimeoutError as e:
print(e)API 비율 제한과 리소스 조절
외부 API 호출 시 "비율 제한(Rate Limiting)" 이 필요하거나, 스레드 풀 같은 리소스를 사용하고 안전하게 종료(shutdown)하는 데도 Context Manager가 이상적이다.
(나쁜예)
import time
import requests
from concurrent.futures import ThreadPoolExecutor
# 스레드에 안전하지 않은(non-thread-safe) API 클라이언트
class UnsafeAPIClient:
def __init__(self, requests_per_second=1):
self.interval = 1.0 / requests_per_second
self.last_request_time = 0
def make_request(self, url):
# 여러 스레드가 이 부분을 동시에 통과할 수 있어 비율 제한이 깨짐 (Race Condition)
time_since_last = time.time() - self.last_request_time
if time_since_last < self.interval:
time.sleep(self.interval - time_since_last)
self.last_request_time = time.time()
print(f"{threading.current_thread().name}: Requesting {url} at {self.last_request_time:.2f}")
return requests.get(url)
# 스레드 풀을 생성하고 제대로 종료하지 않음
def bad_api_usage():
client = UnsafeAPIClient(requests_per_second=2) # 초당 2회 제한
executor = ThreadPoolExecutor(max_workers=5)
urls = ['https://api.example.com/data'] * 5
# 여러 스레드에서 안전하지 않은 클라이언트를 공유하며 작업 제출
for url in urls:
executor.submit(client.make_request, url)
# executor.shutdown(wait=True) 호출을 잊어버림!
# 프로그램이 즉시 종료되지 않거나, 스레드 리소스가 누수될 수 있음.
print("모든 작업을 제출했지만, 스레드 풀을 종료하지 않았습니다.")위와 같이 스레드 풀을 수동으로 관리하고, 비율 제한이 스레드에 안전하지 않은 경우는
-
경쟁 상태 (Race Condition):
UnsafeAPIClient의 비율 제한 로직은 여러 스레드가 동시에 접근하면 바로 꺠진다. 여러 스레드가 거의 동시에time_since_last를 확인하고sleep없이 바로 요청을 보내기 때문에 의도한 비율 제한을 바아로 초과하게 된다. -
리소스 누수 (Resource Leak):
ThreadPoolExecutor를 생성한 후shutdown()메서드가 호출되지 않았다! -> 백그라운드 스레드가 정리되지 않아 프로그램이 비정상적으로 대기하거나 리소스가 계속 점유되는 문제가 발생한다. (이거 생각보다 그냥 놓치면 나중에 디버깅하기 어렵다. 평소 습관이 중요...)
(context manager 예시)
from concurrent.futures import ThreadPoolExecutor
from contextlib import contextmanager
import threading
# 스레드 풀을 안전하게 관리하는 Context Manager
@contextmanager
def thread_pool(max_workers):
executor = ThreadPoolExecutor(max_workers=max_workers)
try:
yield executor
finally:
# with 블록이 끝나면 반드시 shutdown이 호출됨
executor.shutdown(wait=True)
# 스레드에 안전한 비율 제한 로직을 제공하는 Context Manager
@contextmanager
def rate_limiter(client_instance):
with client_instance.lock: # 스레드 락으로 임계 영역 보호
time_since_last = time.time() - client_instance.last_request_time
if time_since_last < client_instance.interval:
time.sleep(client_instance.interval - time_since_last)
client_instance.last_request_time = time.time()
yield
class SafeAPIClient:
def __init__(self, requests_per_second=1):
self.interval = 1.0 / requests_per_second
self.last_request_time = 0
self.lock = threading.Lock() # 스레드 동기화를 위한 락
def make_request(self, url):
with rate_limiter(self): # 컨텍스트 매니저로 비율 제한
print(f"{threading.current_thread().name}: Requesting {url} at {time.time():.2f}")
return requests.get(url)
# Context Manager를 활용한 안전한 병렬 API 요청
def good_api_usage():
client = SafeAPIClient(requests_per_second=2)
urls = ['https://api.example.com/data'] * 5
with thread_pool(max_workers=5) as executor:
futures = [executor.submit(client.make_request, url) for url in urls]
# 결과 처리...
print("모든 작업이 완료되고 스레드 풀이 안전하게 종료되었습니다.")- 사실, 눈치챗듯 위
thread_pool은 좀 과하다 ㅎㅎ; ThreadPoolExecutor가 이미__enter__와__exit__메서드를 구현하고 있기 때문에 불필요한 중복이다 ㅎ. 하나의 예시를 위해 가져와서 사용했다.with ThreadPoolExecutor(max_workers=5) as executor로 처리 가능하다.
# ThreadPoolExecutor를 직접 Context Manager로 활용
def good_api_usage_simplified():
client = SafeAPIClient(requests_per_second=2)
urls = ['https://api.example.com/data'] * 5
# ThreadPoolExecutor 자체가 Context Manager이므로 별도 래퍼 함수 불필요
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(client.make_request, url) for url in urls]
# 결과 처리...
# concurrent.futures.as_completed(futures) 등을 사용하여 완료된 순서대로 결과 처리 가능
print("모든 작업이 완료되고 스레드 풀이 안전하게 종료되었습니다.")핵심 요약
-
결국 Context Manager는 "리소스의 안전한 획득과 해제를 보장하는 파이썬의 핵심 메커니즘" 이다. 그리고 이걸
with구문으로 사용할 수 있다. (__enter__와__exit__자동 호출) -
결국
with문은 동시성 환경에서 발생할 수 있는 경쟁 상태(Race Condition), 데드락(Deadlock), 리소스 누수(Resource Leak) 등의 심각한 문제들을 원천적으로 방지 하는 짱편한 문법이다. -
특히
@contextmanager데코레이터와 제너레이터의 조합은 복잡한 클래스 구현 없이도 직관적인try...yield...finally패턴으로 리소스 관리 로직을 표현할 수 있게 해준다. -
특히 3.11 이상의 특화 적응형 인터프리터 덕분에 성능 오버헤드도 최소화되었으니, 파일 I/O, 데이터베이스 트랜잭션, 스레드 동기화, 분산 락 등 리소스가 관련된 모든 곳에서 Context Manager를 적극 활용해보자!
출처

글 초반부 읽으며 이거 generator 이야기가 빠질 수 없겠는데.. 하면서 읽었는데 역시 나오는군요 ㅋㅋㅋ|
3.14 부터 gil 해제가 공식 지원 되면서 여러 변경사항이 with에도 영향이 갔나보네요
재미있게 잘 읽었습니다!