[ 해당 글은 "velog-dashboard" 프로젝트를 만들면서 기록한 DevLog 입니다! ]
[서비스 일시 중단 🙆🙇🙆🙇] 12월 중으로 레거시 통계 보기가 안정화 된 상태로 다시 제공" 된다고 하니, 그때 다시 살려보도록 하겠습니다! [🙆🙇🙆🙇]
Velog Dashboard
2021년 6월 5일년 조회수 통계 기능 도입 안내 글을 필두로 velog에 게시글 통계 (조회수) 기능이 배포되었다. 그리고 최근에 v3 발표가 되었다. 사실 velog 자체가 퍼포먼스 마케팅이나 inbound가 중요하게 생각되는 플랫폼이 아니라 자세한 조회수 또는 통계에 그렇게까지 니즈는 없으며, 이 부분이 오히려 타 플랫폼과 "KISS(Keep it small and simple)" 라는 점에서 차별점이 있지 않을까 라는 생각도 있다. 하지만 내가 궁금하다,, 그리고 은근 나 처럼 궁금해 하는 사람이 있다!,,
사용 영상 보러가기
사용하러 가기 - https://velog-dashboard.kro.kr
1. Background
velog 의 통계를 쉽고 빠르게, 편하게 보고 싶었다. 그리고 사실 다른 사람의 통계도 익명으로 global dashboard 로 만들어 보고 싶다. 후자는 너무 희망 사항
점점 글을 기록 보다는 기술 + 컨텐츠 형식으로 만들다 보니까 자연스럽게 유입이 궁금해지고 반응 및 리액션이 궁금해졌다. 물 안들어오는데 노를 젓고 싶었다는 거다
그래서 그냥 자체적으로 velog graphQL API 호출해서 보고 있었는데 이게 점점 귀찮다.. 깃허브에도 꽤 써드파티들이 보인다. 근데 산양되거나 FE(UI/UX) 가 고려된 프로젝트는 없다..
그래서 그냥 "내가 볼 HTML 퍼블리싱만 하자" 가 판이 커져버렸다. 해당 글은 velog dashboard를 만드는 과정을 처음부터 기록한 글이다. 계속 글이 이어질 예정이다 :)
2. 요구사항과 핵심 기능
간단하게 아래 통계들을 한 눈에 볼 수 있었으면 했다.
- daily view count
- total view count
- total like count
- (list) each post view count / like count
그리고 "통계" 는 "단순 시계열 데이터" 이다. 통계 시계열 데이터는 본질적으로 그 시간이 지난 데이터는 "바뀌지 않는" 값이고 log 데이터와 동일하다. 그래서 위 기능을 위해 과거의 데이터를 기록하면 자연스럽게 "등락폭을 보고 비교" 가 가능하다.
- 해당 count 값들의 "전일자, 또는 특정일자 비교" 기능
- 데이터의 유동적인 시각화
이렇게 데이터 수집, 보관과 데이터 시각화 가 핵심인 프로젝트이며 더 나아가 만약 다른 분들이 개인정보를 제외하고 재활용 하지 않는 범위의 통계의 비교 분석을 위한 수집 동의만 해주신다면, 위 기능들을 "global" 하게 비교 할 수 있게 된다.
3. 설계
"핵심만 집중해서 먼저 만들기", 로깅 및 수집, QE(Quality Engineering) & 테스트 코드, DevOps, SPoF, 프로비저닝 등의 미래는 최소한으로 고려만 하고 세팅하기!!
1) 모델 중심 기능 설계
핵심 기능만 버티컬하게 먼저 만들고 싶었다. 설계가 코딩의 80% 임은 격하게 동감하지만 기능적인 도메인을 구분하는 등의 치밀한 설계를 하지는 않았다. "모델 중심, user flow 중심 설계" 를 사전에 러프하게 했다. 다들 사이드 할때 고질적으로 먼 미래를 보게 되는 병이 있을 것이다.. 최대한 내려놓자, 내려놓고 시작해야 에자일하게 가능하다!!
일단 데이터 수집을 위해서는 (velog의 graphQL 활용을 위해서는) velog의 auth token이 필요하다. 그래서 access token과 refresh token을 일단 저장해야 한다.
(1) token 과 velog unique url (velog host url, id) 를 매핑해서 가지고 있어야 한다.
-
token을 무단 수집하는 것은 악의적인 공격이 될 수 있고 보안적 위협이 맞다. 그래서 확실한 가이드 라인을 만들고 (수집 방법), 절대적인 오남용이 없게 (사용 목적) 명시 하고, 약관을 만들어야 한다. 당연히 공개된 정보외에 수집이 있으면 안되고 절대적으로 그 사람을 식별할 수 없어야 한다.
-
나중에 언급하겠지만 그래서 절대 DB가 털리면 안된다. 다른건 다 됐고 DB가 나의 보안이 아닌 "대중적으로 인증이 된 보안" 하위에 있어야 한다.
-
token과 velog unique url (https://velog.io/@qlgks1 와 같이) 매핑되어서 다른 데이터와 참조되어야 한다.
(2) 해당 unique velog의 post list를 가지고 있어야 한다.
-
velog의 post는 uuid를 가지고 있다. 이 uuid를 가지고 title과 통계정보를 저장해야 한다. 이렇게 post uuid값과 (1)에서의 velog unique url (FK) 둘 다 가지고 있으면서 index 되어야 한다. 그래야 통계 데이터를 빠르게 가져올 수 있다.
-
포스트 자체의 시계열 데이터를 그대로 저장해야한다.
(3) 데이터 수집은 비동기적으로 이뤄져야 한다.
-
velog의 통계 API는 통으로 전체 시계열 데이터를 던진다. 그래서 "굉장히 무겁다." 근데 어쩔 수 없고 생각한다. 개인적으로 이 통계 데이터 자체가 velog가 지향하는 점이 아니기 때문이라고 생각한다.
-
그래서 최초 유저 (신규 토큰)의 경우 데이터 스크래핑 대기열에 추가가 되고, 워커에 의해서 스크래핑 되는 형태가 되어야 한다.
-
그렇기 때문에 워커가 필요하고, 워커는 특정 데이터를 기반으로 계속해서 데이터 스크래핑을 하고 등록된 토큰은 폐기가 될 때 까지 (refresh 만료) 마지막 데이터 수집 시간을 기점으로 계속 스크래핑을 해야한다.
-
따라서 "데이터 수집의 결과 (인증 이슈, 4XX or 5XX 이슈)" 와 "마지막 스크레이핑 시도 시간" 필드가 필요하다.
빠른 개발 속도와 저장하는 데이터의 특성, 거의 insert & select only data들이고 대량 업데이트에 많은 초점이 맞춰진 모델에 맞는 DBMS는 document DB라고 생각이 들었고, mongodb 를 선택했다.
2) frontend
원래 프레임워크 없이 vanilla js, HTML, CSS 조합을 좋아해서 ES6+ js & typescript 로 webpack + babel 통해서 퍼블리싱하려고 했는데 굳이? 라는 생각에 그냥 생짜 static file 에 nginx 조합 으로 서빙하려고 결심했다. 바벨링 해서 얻는 이득이 크지가 않다고 생각했다!..
이번에 하면서 확실하게 나는 웹디자인 "창조"의 능력은 많이 부족하다는 걸 다시 깨달았다. 웹디자인의 0에서 1을 만드는게 진짜 어렵다.. 갓터레스트 덕분에 남이 만들어둔 1에 살을 붙여서 3정도 겨우 만들었다 🥹
(1) index page
-
사용자가
access token/refresh token을 넣어야 한다. 이게 여간 귀찮을 수 있기때문에 velog에 로그인한 브라우저의 경우 쿠키에서access_token&refresh_token값을 찾아 주도록 해야 한다. -
하지만 velog github repo를 보면서 깨달았는데
HttpOnly로 세팅된 쿠키라 브라우저, client side에서는 함부로 접근할 수 없다! 그래서.. 직접 찾아서.. 뽑아내야한다 사용자가.. 끄훕 ㅠ^ㅜ
- 그래도 velog는 거의 개발자 only blog라 직접 token들을 찾아서 넣을 수 있다고 생각하고, 직접 넣어야 한다..! UX를 향상시킬 수 있는 좋은 방법이 떠오르지 않는다.. 자칫하면 XSS 공격이 될 것 같다..

(2) dashboard page
-
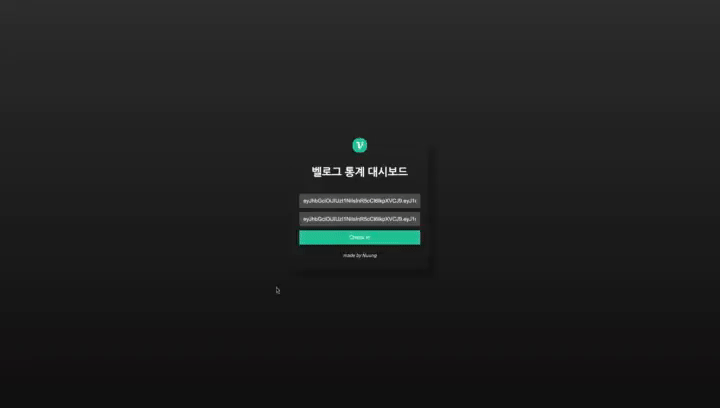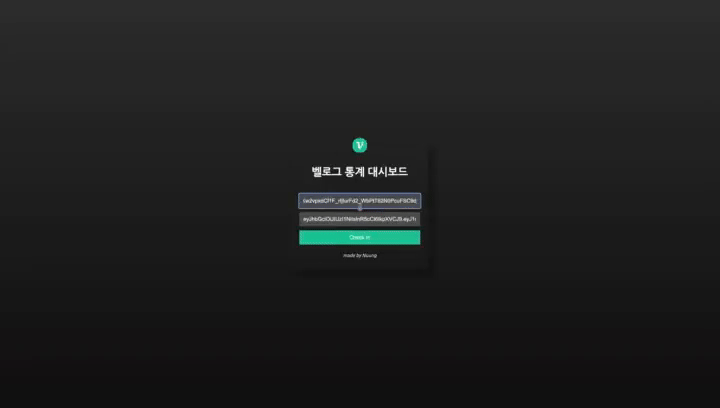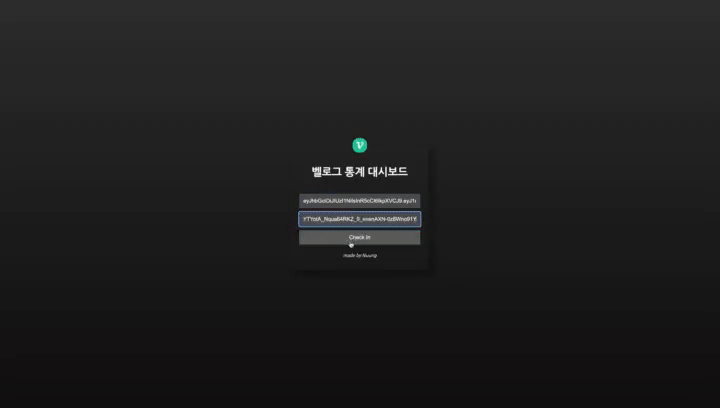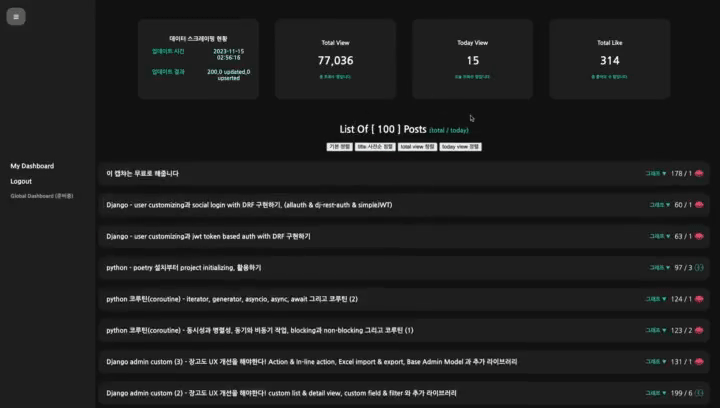
2. 요구사항과 핵심 기능에서 언급한 모든 부분이 보여져야 한다. 데이터 수집, 스크레이핑이 비동기적으로 워커가 하니 기본적으로 polling이 필요하다. 그에 따라 dynamic rendering이 가능한 구조로 세팅해야 한다. -
첫 색션에 수치화된 간단한 통계가 바로 보이고 날짜 구간을 세팅할 수 있는 등락폭 선 그래프가 바로 보이면 좋을 것 같다. 그 다음 색션에 게시글 리스트가 뜨면서 게시글 별 total view가 있으면 좋을 것 같다.
-
각 게시글을 클릭하면 게시글 별로 날짜 구간을 세팅할 수 있는 등락폭 선 그래프가 보이면 좋을 것 같다. 마치 지금 velog 통계에서 보여주듯이 말이다. 이 기능은 일단 최후순위다. 화면을 어떻게 배치하면 좋을까가 바로 떠오르지 않는다.. 🥲
(3) global dashboard page
- 완벽한 TBD다. velog 트랜딩 처럼 등록된 post의 daily traffic이 급상승하는 것을 노출할지, 그냥 간단한 전체 view를 노출할지,, 고민이다. 많은 조언 부탁드리겠습니다!! 😇🙆🙇
3) backend & data scrapping
단일 stack 유지를 위해 js를 계속 사용하고, node.js & express 로 핵심 model 들만 RESTFul 한 API로 제공하려고 한다. API 역시 1) 모델 중심 기능 설계 에서 나온 결론대로 따라갈 것 이다.
그리고 지속적인 데이터 수집은 python asyncio & aiohttp 조합으로 비동기 및 코루틴으로 세팅하려고 한다. 즉 데이터 수집, 데이터 스크레이핑은 파이썬 워커를 만들어서 작동시키는 것 이다.
앞서 언급한대로 "DB" 가 가장 중요하고 mongodb를 사용하는 것에 결론을 내렸기 때문에, 가장 좋은 선택은 atlas cluster mongodb 를 사용하는 것이다!
DB는 결정되었지만 역시 "호스팅, 서버" 가 문제다. 하꼬 개발자는 배포할 돈이 없다..! 개인적인 선호로 서버리스 대신 클라우드 서버에 온프램으로 직접 배포하고 싶다..
(1) 현실적인 방안
일단 독립적인 기능적 면모로 API server & web server & worker server 로 최소 3개의 노드(간단하게 S/W server)가 필요하다. 하나의 docker compose 로 말아도 최소 2개 코어는 써야 마음이 편안한 구조다. 이래서 욕심을 줄여야 한다..
- 솔직히 정말 현실적인 방안은
Netlify와 같은 PaaS로 static file serving 하고 - api는 serverless 로 (
AWS lambda등) 제공하고 - DB & DBMS는 web SaaS로 관리가능한 cloud 사용하고
- worker 는
github action을 사용하는 것이다.
이러면 worker를 제외하면 초기 구축만 잘하면 개발자로써 관리를 고민하는 포인트가 정말 거의 없다. "하지만 그냥 내가 하나의 docker compose로 말아서 배포하고 싶다!"
(2) free cloud server 찾기
사실 하나의 서비스를 온프램에 가깝게 직접 구축하고 관리하는 것은 항상 즐겁다. 규모가 커지면 솔직히 혼자는 답이없지만, 토이플젝 서비스를 적어도 VM 기반의 cloud server에 올리고 관리하는게 즐겁다!
- Oracle Cloud
- IBM Cloud
- 그 외 중소 Cloud
오라클은 프리티어 2개까지 가능하다. 각설하고 지금 시장에서 홍보하는 머기업 클라우드중에서는 프리티어 스팩이 굉장히 좋은 편이다. (왜냐면 2개까지 평생 무료를 밀고 있기 때문이다.) 하지만 내가 이미 다른 곳에서 너무 열심히 쓴..다..!
이번 기회에 다른 라이트한 free cloud LaaS or PaaS 를 찾아보려고 했!! 는데... 검색 실력의 한계인가,, 오라클에 준하는 평생 무료 cloud server IaaS platform은 없는 것 같다. 일단 선택권이 없다. 내 욕심을 버리고 초기 오버헤드가 있지만 현실적인 방안을 선택하던지 vs IaaS 에 docker compose 로 말아올리고 직접 모든 부분을 관리하던지 중 후자를 확실하게 밀고 가야 한다!!

(3) 단계별로 준비하기
IaaS 에 docker compose 로 바로가면 오버헤드가 크다고 판단했다.
1. 바로 사용가능하게 세팅되어 있는 (nginx와 pm2세팅 되어 있음!) 서버에 FE + BE(API) 만올리고, worker는 github action 사용하기
바로 위 단계부터 일단 하고, 베타 론칭을 한 뒤에 볼륨 & 트래픽을 보고 판단한 뒤 IaaS 에 CI/CD를 구축하기로 했다.
2. docker image 구성하고 docker compose 로 구성, 모노레포를 통해 IaaS 에 SCP & SSH 기반으로 CI/CD 구성하기
위가 베타 론칭이후 정식오픈에 활용할 구성이다.
4) infra 구상도
위에서 언급한 단계별로 인프라 구상도가 살짝 바뀌는데, 아래는 첫 단계다. 왜 이렇게 대충 그렸니..
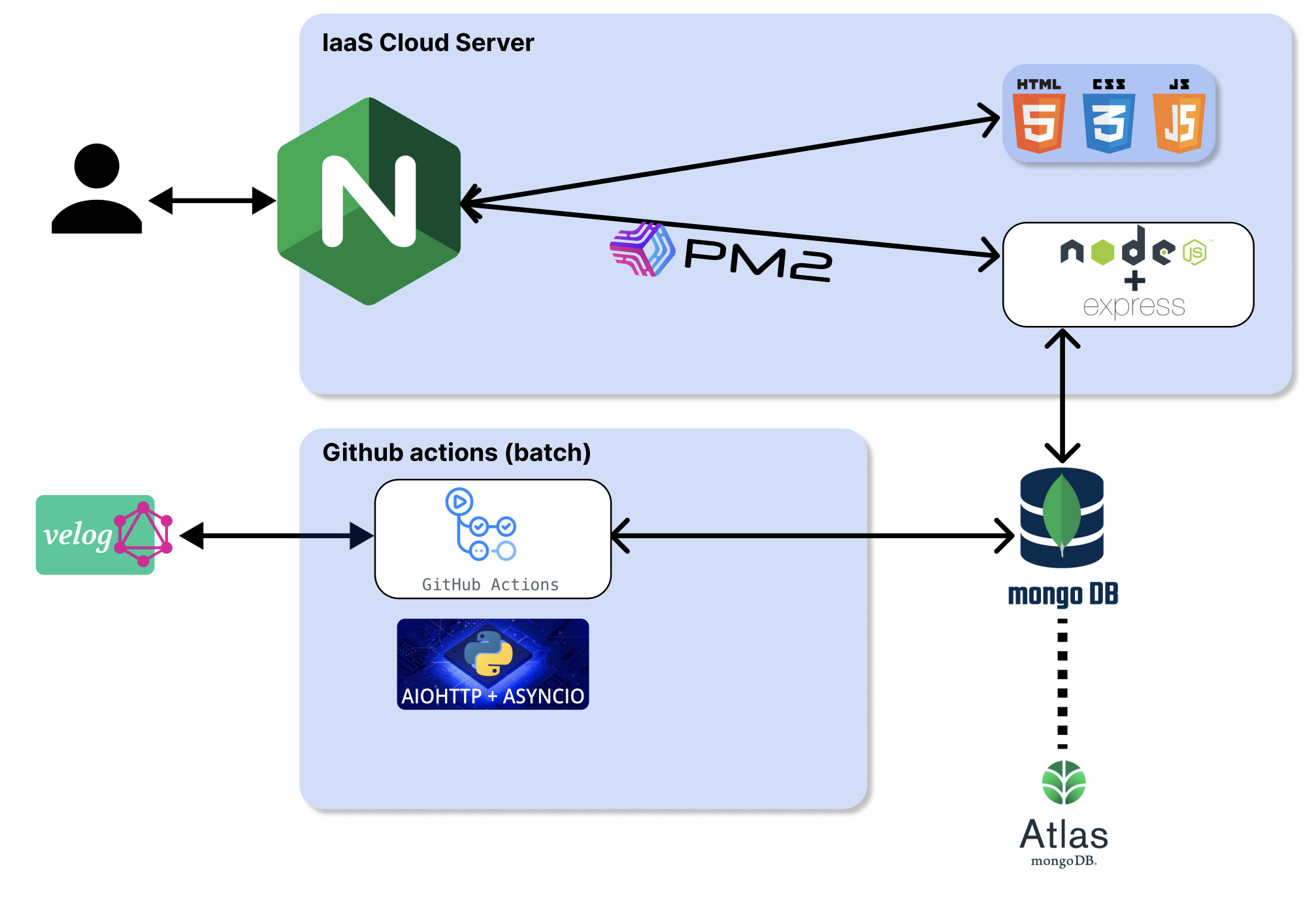
이후 클라우드 서버에 통짜로 도커라이징된 친구들을 docker compose 로 배포하는 형태다. 서버 모니터링, 프로비저닝, 로깅 시스템, SPoF, CI & CD 등이 고려안된 아주 최초의 인프라 구조다. 일단 이대로 작업하고 하나씩 살을 붙이려고 한다.
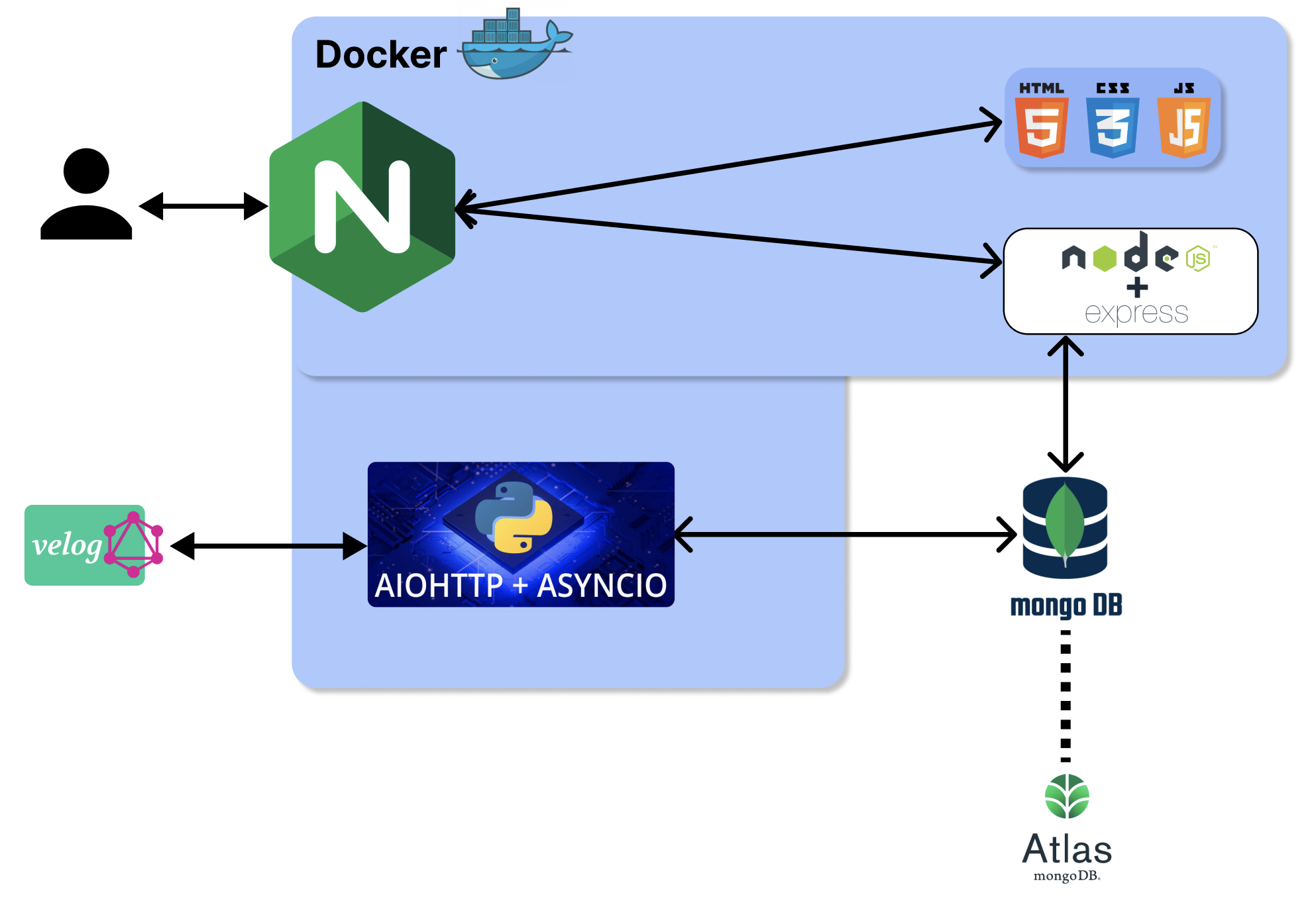
(1) 도메인과 ssl?
일단 CDN, 최적화는 잊고, "도메인" 과 그에 따른 SSL 인증 (for https)는 꽤 중요하다. 내도메인.한국 이라는 곳을 사용할 것이다. 그리고 ssl 인증서는 역시 certbot 이다!
(2) 이제 디테일로
이제 전체 간략한 그림은 다 잡았다! 앞으로 이어지는 글로 세부적인 디테일을 기록하려고 합니다! 부족함이 많은 설계이고 프로젝트라 많은 지적 부탁드리겠습니다! UI & UX에 대한 지적질도 많이 부탁드립니다.
언젠간 velog 정식 side로 dashboard를 위한, 하나의 메뉴 섹션으로 만들어지길 기도하면서 ㅎ

8개의 댓글



만드신 프로젝트와는 별개로.. 기존 벨로그 통계 시스템이 너무 비효율적이였어서 (2편에서 얘기 하셨듯이) 데이터베이스를 느리게 만드는 현상이 발생했습니다.
게시물별 일일 통계는 잠깐 비활성화하고 조만간 개선하여 다시 도입하겠습니다.
👍🏻