LLM - OpenAI 가 알려주는 할루시네이션의 이유?, Why Language Models Hallucinate 따끈한 논문 리뷰
LLM Basic to Advanced
[ 글의 목적: OpenAI 가 말아주는 할루시네이션 이야기, 내가 생각하는 핵심 위주로 요약 및 정리 ]
Why Language Models Hallucinate?!
[ 논문 페이지: arXiv / 원문: OpenAI 블로그 / PDF: OpenAI PDF ]
25년 9월 5일 공식 홈페이지에 올라온 따근따근한 글, "할루시네이션은 왜 생기는가!". 해당 논문은 할루시네이션의 "기술적, 통계적" 이유와 이를 야기하는 "훈련 및 평가 방식(기존 벤치마크)" 을 지적하는게 핵심 주제다.
- 해당 글의 썸네일인 "세종대왕 맥북 프로 던짐" 사건
- 구글 오버뷰의 "하루에 돌 1개 섭취" 사건
- 2023년 뉴욕에서, Schwartz 변호사가 변론서(legal brief)에 6건의 판례 인용을 했는데 모두 "가짜" 였던 사건 등
이 사건들, 특히 마지막은 LLM의 할루시네이션이 실무에 끼칠 수 있는 리스크를 명확히 보여준 대표적인 사례로 남아 있다.
OpenAI는 할루시네이션이 단순한 버그가 아니라, 훈련 및 평가 인센티브 구조 자체가 환각을 조장한다 는 근본적 원인을 제시한다. 어떤 얘기인지 좀 더 깊게 살펴보자.
1. 할루시네이션이 왜 발생하는가?
Large Language Model 은 "확률적 언어 모델" 이다. 이 내용이 너무 질려버린 사람이 있을 수 있기에 LLM자체에 대한 설명은 Intro to Large Language Models 글 로 대체한다.
결국 주어진 context 에서 "가장 가능성 높은 다음 단어 예측" 하도록 훈련된다. 문법·철자와 같이 일관적 패턴 은 학습으로 정복할 수 있지만, 단발성 사실(singletons) 처럼 데이터에 거의 등장하지 않는 정보는 통계적으로 일반화가 불가능하다.
즉, 모델은 “이게 진짜 사실인가?”를 배우는 것이 아니라, “이 문장이 훈련 데이터에 나왔는가?”를 학습하기 때문에, 결국 사실에 근거하지 않은 추측 을 내놓게 된다. (아래, 논문 저자 Adam 의 생일을 물어보는 질문)

1) 문제는 학생이 아니라 시스템이다!!
(논문 초록, Abstract) 논문은 마치 "어려운 시험 문제에 직면한 학생"처럼, LLM이 불확실성을 인정하기보다는 추측하도록 보상받는 환경에 놓여있다고 비유한다. 해결책 역시 새로운 모델 아키텍처가 아닌, 기존 벤치마크의 점수 체계를 수정하는 '사회-기술적 완화' 방안을 제안한다.
PS) 일각에서는 OpenAI가 자기에게 유리한 평가로 프레임 전환을 하고 있다는 비판도 있다...!
Like students facing hard exam questions, large language models sometimes guess when uncertain, producing plausible yet incorrect statements instead of admitting uncertainty.
이진 0-1 채점 방식 하에서, 정답은 +1점, 오답은 0점, 그리고 "모르겠습니다(I don't know, IDK)"와 같은 불확실성의 표현 역시 0점을 받는다. 이 구조에서 불확실한 문제에 대해 추측하는 행위는 오답일 경우 0점으로 본전이지만, 정답일 경우 +1점을 얻을 수 있는 비대칭적 이득을 제공한다. 따라서 점수 극대화를 목표로 최적화된 모델에게 추측은 변칙적인 행동이 아니라 합리적이고 학습된 행동이 된다.
AI 모델이 누군가의 생일을 모를 때, "모르겠다"고 답하면 무조건 0점을 받지만, "9월 10일"이라고 추측하면 365분의 1 확률로 점수를 얻을 수 있다. 이러한 시스템은 모델이 정직한 소통가보다는 영리한 시험 응시자가 되도록 유도한다. 이 얘기는 뒤에 더 상세하게 다룬다.
2) 인간의 지각 경험에서 오는 환각과는 근본적인 차이가 있다.
(서론에서) 언어 모델의 환각은 정보 생성 과정에서 발생하는 통계적 오류와 평가 시스템에 의해 강화되는 학습된 행동에 가깝다고 한다. 그래서 인간이 경험하는 할루시네이션(환각)과 LLM에서의 할루시네이션은 근본적인 차이가 있음을 분명히 한다.
2. 환각은 이진 분류 오류와 밀접하게 연관되어 있다.
Hallucinations need not be mysterious — they originate simply as errors in binary classification. If incorrect statements cannot be distinguished from facts, then hallucinations in pretrained language models will arise through natural statistical pressures. We then argue that language models hallucinate because the training and evaluation procedures reward guessing over acknowledging uncertainty, and we analyze the statistical causes of hallucinations in the modern training pipeline.
논문은 할루시네이션 현상을 현대 LLM 파이프라인의 두 가지 주요 단계에 걸쳐 분석한다. 첫 번째는 오류가 처음 발생하는 '사전 훈련(Pre-training)' 단계 이고, 두 번째는 오류가 지속되는 '사후 훈련(Post-training)' 단계 이다.
논문은 복잡한 텍스트 생성 문제를 Is-It-Valid (IIV) 라고 불리는 더 간단한 지도 학습 기반 이진 분류 문제로 환원한다. 이는 "이것이 유효한 언어 모델 출력인가?"라는 질문에 답하는 분류기를 가정한다. (즉, 주어진 텍스트 출력(response)이 유효한지(+) 또는 오류인지(-)를 분류)

생성 모델이 유효한 출력을 생성하는 것은 이러한 예/아니오 질문에 답하는 것보다 어떤 면에서 더 어렵다. 왜냐하면 유효한 출력을 생성하려면 암묵적으로 각 후보 응답에 대해 "이것이 유효한가"라는 질문에 답해야 하기 때문이다.
- 이러한 환원을 통해 논문은 생성 오류율과 IIV 오분류율 사이에 다음과 같은 핵심적인 수학적 관계를 정립한다.
- 생성 오류율이 IIV 오분류율의 두 배 이상이 될 수 있다는 수학적 관계를 제시한다.
1) 사전 훈련(Pre-training) 단계에서의 오류
Arbitrary-fact hallucinations
- 데이터에 간결하게 설명할 수 있는 패턴이 없을 때 발생하는 인식론적 불확실성(epistemic uncertainty) 으로 인해 발생
- 싱글톤 비율(Singleton Rate): 훈련 데이터에 단 한 번 등장하는 사실의 비율이 환각 빈도를 결정.
- 사전 훈련 데이터에 한 번만 나타나는 특정 사실의 비율(singleton rate)이 환각률의 하한이 된다는 것을 보여준다. (ex - 위 언급된 Adam 의 생일!)
Poor Model Families
모델의 아키텍처나 표현 능력이 특정 개념을 잘 나타내지 못할 때 발생한다. 예를 들어, 옛날의 트라이그램 언어 모델은(n-gram 모델) 제한된 문맥으로 인해 문법적으로 틀린 문장을 자주 생성했고 DeepSeek-V3 모델이 글자 세기 작업에서 오류를 내는 것도 모델의 한계 때문으로 분석된다.
그 외
- Calibration (오류가 없는 언어모델은 "보정 상태"가 될 수 없다(
δ가 0이 될 수 없음), 세부 내용은 논문 참조!)
- 계산적 난이도(Computational Hardness) - 암호 해독과 같은 문제
- 분포 변화(Distribution Shift) - 훈련 데이터 분포와 크게 다른 OOD(Out-of-Distribution) 프롬프트
- GIGO(Garbage In, Garbage Out), 대규모 훈련 코퍼스에 포함된 수많은 사실적 오류가 기본 모델에 의해 복제될 수 있음이 언급된다.
2) 사후 훈련(Post-training) 단계에서의 오류
사후 훈련은 인간 피드백 기반 강화 학습(RLHF), 직접 선호 최적화(DPO), AI 피드백 기반 강화 학습(RLAIF)과 같은 기법을 통해 사전 훈련된 기본 모델의 오류를 줄이고 인간의 선호도에 맞게 조정하는 것을 목표로 한다. 하지만 논문은 이러한 방법들이 할루시네이션을 제거하는 데 실패한다고 주장한다. 그 이유는 이 기법들이 최적화하려는 목표, 즉 주류 평가 벤치마크 자체가 근본적으로 잘못 정렬되어 있기 때문이라 한다.
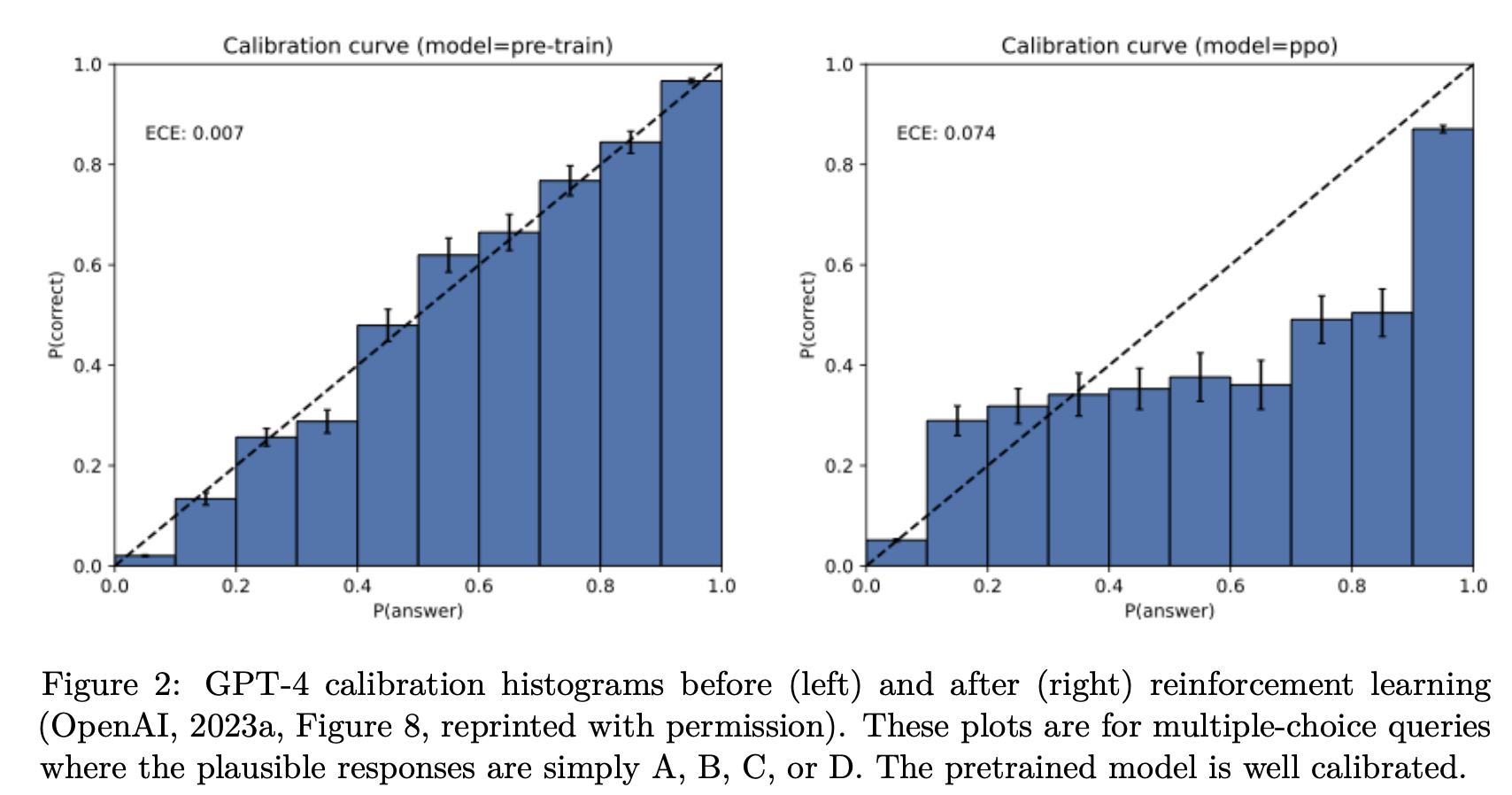
논문은 GPQA, MMLU-Pro, SWE-bench 등 10개의 널리 사용되는 벤치마크에 대한 메타 분석을 수행했으며, 그 결과 거의 모든 벤치마크가 이진 채점 방식을 사용한다는 것을 언급한다.
- 정답 = 1점, 오답 = 0점, “모르겠다” = 0점
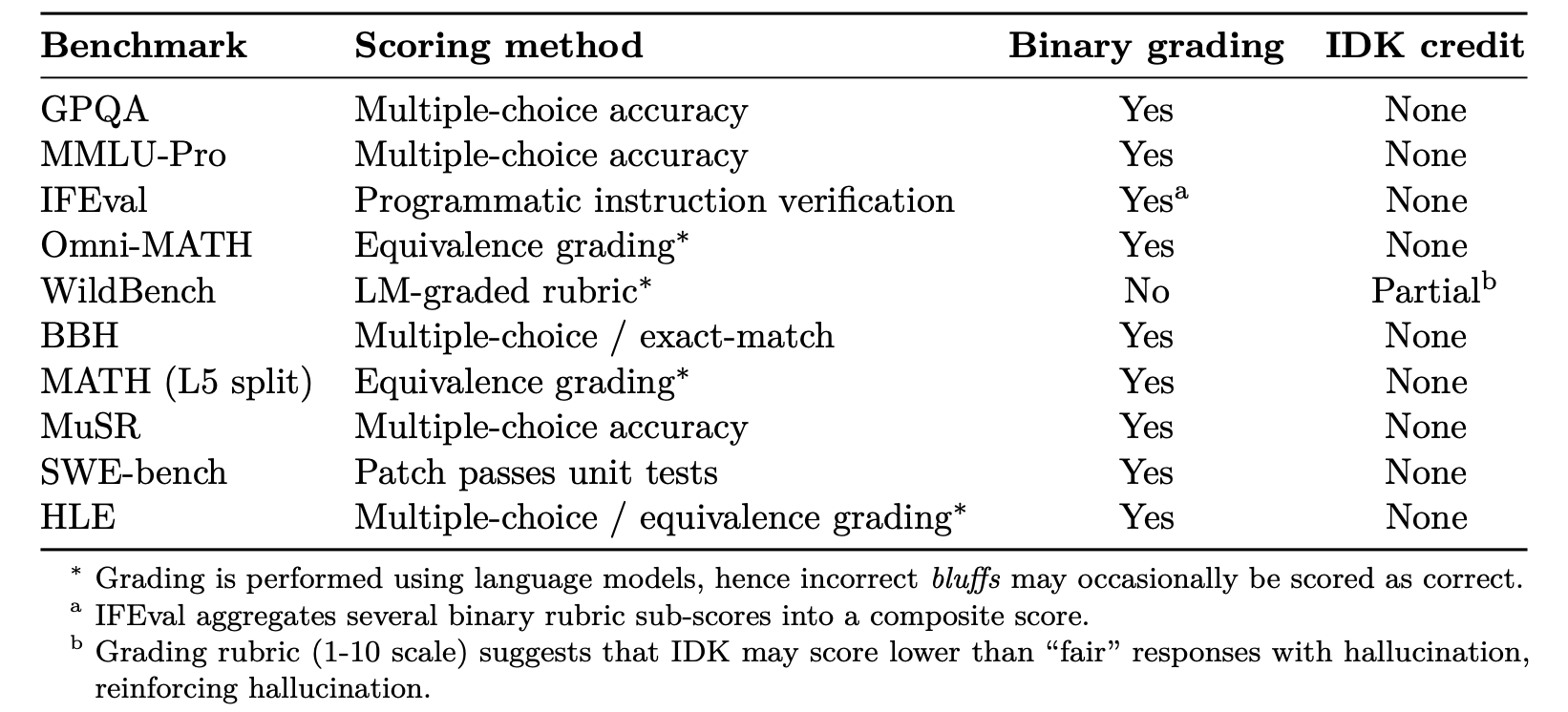
WildBench 만이 불확실성 표시에 대해 최소한의 점수를 부여하지만, 그마저도 IDK 응답이 사실 오류나 환각이 있는 "공정한(fair) 할루시네이션" 응답보다 낮은 점수를 받을 수 있어 여전히 추측을 장려할 수 있다고 지적한다.
따라서 모델은 기대값 관점에서 “찍는 것이 항상 유리” 하다. “모르겠습니다”보다는 그럴듯하게라도 답하는 쪽이 보상 구조상 이득이 된다. 논문에서는 이를 어려운 시험 문제에 직면했을 때 불확실하면 추측하는 학생들의 행동에 비유한다.
이로 인해 언어 모델은 항상 "시험을 치르는 모드(test-taking mode)"에 있게 되며, 자신의 지식 부족을 인정하기보다는 과신에 찬 답변을 생성하도록 유도된다고 한다.
3. 그래서 어떻게 할루시네이션을 줄일 수 있는가?
1) 환각 문제 해결을 위한 사회-기술적 완화 (Socio-technical Mitigation)
기존 리더보드와 벤치마크의 채점 체계를 바꿔야 한다고 주장한다. “불확실성 표명” 자체에 보상을 주어, 모델이 정직하게 모른다고 답할 수 있는 환경을 조성해야 한다!
기존 주류 평가 벤치마크에 매몰되어 환각이 심화되거나 조장할 수 있으니, 불확실성 캘리브레이션을 반영한 새로운 지표를 만들자!
2) Explicit Confidence Targets
모델이 확률적 진실성 대신 선택적 진실성 을 따르도록 유도해야 한다. - behavioral calibration
- "t보다 높은 확신이 있는 경우에만 답변하고, 오류는 t/(1-t)점 감점, 정답은 1점, '모르겠습니다'는 0점"과 같이 명확한 지침을 제공하는 것
- 예: 확신도 70% 이상일 때만 답변, 그 이하는 “모르겠다(IDK)” 처리.
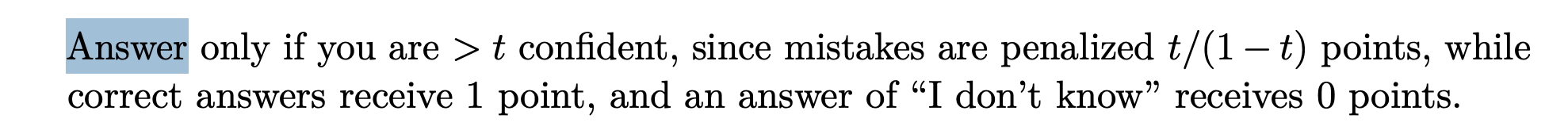
3) Search (and reasoning) are not panaceas

이는 사실 논문에서 줄이기 위한것이 아니라 "한계점에 대한 언급"
검색 증강 생성(RAG)과 같은 기술이 할루시네이션을 줄이는 데 효과적임이 입증되었지만 이러한 기술이 만병통치약이 아님을 강조한다. 이진 채점 시스템은 검색이 확실한 답변을 제공하지 못할 때에도 여전히 추측에 보상하기 때문. 또한, 검색은 글자 세기 예시와 같은 계산 오류나 다른 내재적 환각에는 도움이 되지 않을 수 있다.
논점에서 살짝 벗어나지만 RAG 를 위해 Vector DBMS를 선택하는 것도 필수가 아니라는 점이다. 사견으로, 이론상 RAG 가 할루시네이션을 더 줄이려면 Vector 보다는 "유사한게 아니라 명확하고 확실하게 검색되는 것" 이 더 도움을 줄 수 있다.
결국 RAG를 위한 output 도 prompt 의 일부분이고, 결국 RAG 도 context window 에 제한적이다. 가끔 현업에서 모든 정보를 vector 에 담아서 "어떻게든 증강하겠지~" 라는 기도메타를 보는데.. 사실 어느정도 내 얘기기도 하다.. 오히려 100% 확실한 정보만, 짧고 굵게 매핑할 수 있는 라벨링이 훨씬 유의미하지 않을까 생각한다.
그 외는 사실 결론과 이어지는 것이다.
4. 결론: '더 똑똑한' AI가 아닌 '더 정직한' AI !!
할루시네이션은 지도 학습(supervised learning)에서의 오분류(misclassifications)와 유사하게 생성 오류(generative errors)로 발생하며, 이는 교차 엔트로피 손실(cross-entropy loss) 최소화의 자연스러운 결과로 나타난다.
논문은 생성 문제를 “이 출력이 유효한가?”라는 IIV(Is-It-Valid) 이진 분류로 환원하고, 두 오류 사이의 하한 관계를 명시한다. 생성 오류율 ≥ 2 × IIV 오분류율.
이 관계는 사전훈련만 놓고 보더라도 모델이 피할 수 없는 통계적 제약(예: 싱글턴 비율처럼 데이터에 한 번만 등장하는 사실의 비중)이 환각으로 이어짐을 보여준다.
그러나 환각은 사후훈련 단계에서 “없어지지 않는다.” 오늘의 주류 벤치마크는 정답=1, 오답=0, IDK=0인 0-1 채점 을 널리 쓰며, 이 구조는 모를 때 ‘찍는’ 편이 기대값 상 유리 하도록 모델을 길들인다.
그 결과 모델은 항상 시험 응시 모드(test-taking mode) 로 작동하며, 불확실성 표명보다 자신감 있는 오답!! 을 택하게 된다. 이는 환각을 “미스터리한 버그”가 아닌, 평가 인센티브가 낳은 학습된 행동 으로 설명해 준다.
-
핵심 처방은 모델 구조가 아니라 평가 시스템을 '간단히 수정(simple modification)' 하는 것이라고 언급한다.
-
기존 리더보드의 주 지표를 정확도 일변도에서 “불확실성 인식/자제”를 보상하는 형태로 수정하면 (예: 확신이 낮을 땐 답변을 유보하게 만드는 명시적 confidence 타깃, 행동적 캘리브레이션) “찍기”의 기대이익을 제거하고 정직한 불확실성 표현 을 유도할 수 있다.
-
오답(특히 자신감 높은 오답)에는 유의미한 페널티, 적절한 IDK/유보에는 부분 크레딧을 부여하는 채점으로 주요 벤치마크 전체를 업데이트해야 한다.
PS) 엄청나게 큰 대형 모델이 있으면 덜할까? 논문에서는 사실 거의 아니다라고 보는 것 같다. 오히려 "작은 모델이 한계를 아는 태도, 대답을 유보하는 모습" 을 쉽게 보일 수 있다고 언급한다.

잘 보고 갑니다!