
[ 글의 목적: 250615 기준, 현재 Diffusion LLM 의 상태와 최대한 쉽게 매커니즘 정리, 기존(Autoregressive) 과 비교 ]
Diffusion LLM
GPT 3.5 의 전율이 엊그제 같은데 벌써 2년이 넘었다니.. 올해 3월 인셉션(Inception Labs) Mercury 이 공개되면서 더 많은 대중의 관심을 끌게된 "dLLM". 기존 autoregressive 방식과 어디가 어떻게 얼마나 차이가 나는 걸까? 이제 "차세대 언어모델" 로 주목받으며 (또는 과장이라 비난 받기도 하고) 커져가는 diffusion llm 의 거시적인 흐름을 살펴보자!
1. 기존 LLM의 한계와 Diffusion의 등장 배경, 현 상태
기존 autoregressive LLM(ARM)들은 왼쪽에서 오른쪽으로 순차적으로 토큰을 생성하는 방식으로 작동한다. GPT 시리즈가 대표적인 예로, 각 토큰은 이전에 생성된 모든 토큰들을 조건으로 하여 다음 토큰의 확률 분포를 계산한다. (LLM - Intro to Large Language Models 참조)
# Autoregressive 생성 방식 (순차적)
P(x) = ∏ᵢ P(xᵢ | x₁, x₂, ..., xᵢ₋₁)
# 실제 생성 과정
x₁ = predict_next_token(prompt)
x₂ = predict_next_token(prompt + x₁)
x₃ = predict_next_token(prompt + x₁ + x₂)
# ... 순차적으로 계속1) autoregressive 단점?!
하지만 이 방식은 태생적인 순차 병목현상을 가지고 있다. 각 토큰은 앞선 토큰들이 '모두 생성된 후' 에야 만들어질 수 있어서, (일반적인) 병렬화가 불가능하고 긴 시퀀스 생성 시 속도가 크게 저하 된다. ('추론모델' 도 사실 스스로 만들어낸 토큰을 스스로 참조하면서 다시 depth 있게 접근하는 방식이다.)
그래서 아래와 같은 한계가 있다.
1. 속도 제약: 각 토큰은 앞선 토큰들이 모두 생성된 후에야 만들어질 수 있어 병렬화가 불가능(어려움)
2. 누적 오류: 앞서 잘못 생성된 토큰이 뒤의 모든 토큰에 영향을 미침
3. 유연성 부족: 중간 부분을 수정하거나 특정 부분만 재생성하기 어려움
prompt = "파이썬은"
x₁ = "어려운" # 잘못된 생성
x₂ = "프로그래밍" # x₁에 영향받아 계속 잘못된 방향
x₃ = "언어다" # 전체적으로 부정확한 결과
# 중간 수정이 불가능 → 처음부터 다시 생성해야 함이런 한계를 극복하고, ARM 자체의 통념을 깨기 위해 처음부터 Diffusion 형태로 학습한 LLaDA 와 같은 모델이 나왔다. 아래 "2. Diffusion LLM의 간단 메커니즘" 에서 다시 자세하게 살펴보자. 우선 당장의 "Diffusion LLM 의 성능은 어떤가?" 부터 살펴보자.
2) diffusion llm 의 요즘 성능 벤치마크
최근 재미있는 포인트는 Diffusion과 autoregressive 언어 모델 간의 성능 격차가 극적으로 줄어들었다고 한다. LLaDA 8B는 15개 벤치마크에서 LLaMA3 8B와 경쟁력 있는 성능을 달성하면서도 LLaMA3의 15T 토큰 대비 단 2.3T 훈련 토큰만 사용했다.
ARC-C 추론 작업에서 LLaMA3 8B의 82.4, LLaDA 8B의 88.5 로 우수한 성능을 보였으며, Mercury Coder는 HumanEval에서 88.0%를 달성하면서 초당 1,109 토큰을 생성했다. 이는 GPT-4o Mini의 59 토큰/초에 비해 압도적이다. (아래 사진)
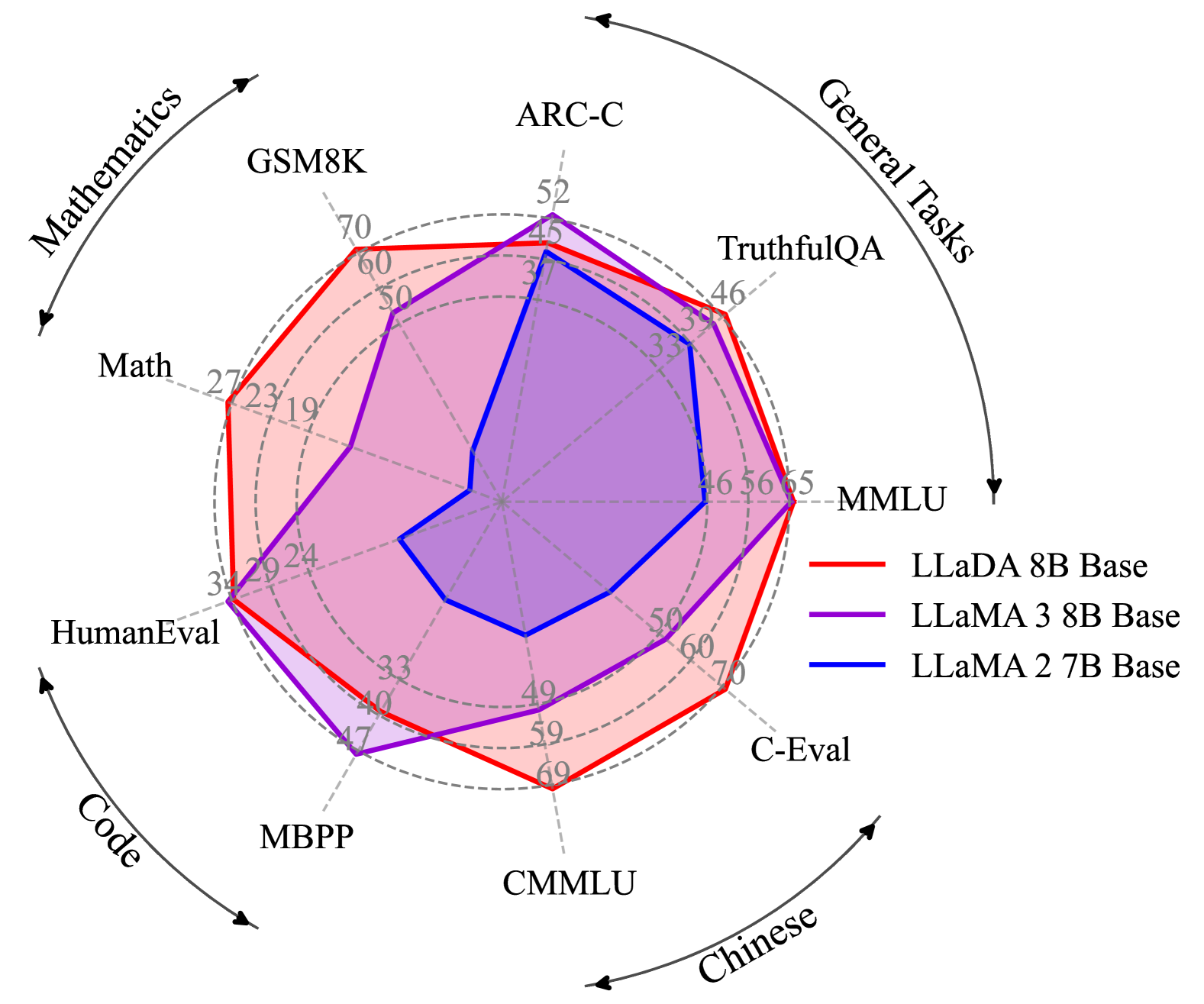
PS) LLaDA의 88.5 점과 LLaMA3 82.4 얘기는 Supervised Fine‑Tuning(SFT) 이후를 말한다.
SEDD(Score Entropy Discrete Diffusion)는 기존 diffusion 모델보다 25-75% 개선된 perplexity를 제공하며, BD3-LMs는 LM1B 데이터셋에서 28.23 perplexity로 기존 방법 대비 13% 향상을 달성했다.
Mercury 시리즈는 NVIDIA H100 GPU에서 초당 1000토큰 이상을 생성 했다고 한다. - 이게 사실이라면 GPT-4o Mini보다 약 19배 빠르면서도 비교 가능한 코딩 성능을 유지한다. (아직 100% fact 인지는 판단 안 된 듯)
속도 우위는 단순한 처리량을 넘어선다. Diffusion 모델은 병렬 토큰 생성, 양방향 추론, 환각을 줄이는 반복적 개선을 지원한다. 특히 autoregressive 모델이 어려워하는 역순 작업에서 뛰어나며, 중국어 시 완성 벤치마크에서 LLaDA가 GPT-4o를 데모에서는 앞섰다고도 한다. 속도, 품질, 제어 가능성의 조합은 지연에 민감하고 높은 처리량이 필요한 애플리케이션에서 diffusion LLM을 최적의 선택으로 만든다.
PS) 논외지만, 최근 중국 논문의 피인용수가 폭발적으로 증가하고 있다고 한다 ㅎㅎ..
요약
- LLaDA 8B: 단 2.3T 토큰으로 훈련했음에도, LLaMA3 8B (15T) 와 유사하거나 더 나은 성능(예: ARC-C에서 88.5 vs 82.4)을 보여줬다고 한다.
- Mercury Coder 는 HumanEval 정확도 88.0%, 초당 1,109 토큰 생성을 한다고 "주장" 하고 있고, 이게 fact 라면 GPT-4o Mini (59 tokens/s) 대비 19배 이상 빠른 추론 속도가 된다.
- 병렬 토큰 생성, 양방향 추론, 반복적 개선 가능이 가능하고, 역순 생성 등 autoregressive 모델이 어려워하는 작업에서 유리하다.
- 빠른 속도와 낮은 지연 시간 덕분에 고성능·실시간 처리 요구 앱에서 diffusion LLM이 유리할 수 있다.
2. Diffusion LLM의 간단 메커니즘
사실 "Diffusion" 이라는 개념 자체가 이제와서 엄청 핫해진건 아니다. 15년대 부터 논문에 등장했다고 하는데, 진짜 "대중적으로 유명"해진건 "Stable Diffusion, DALL-E 2" 라고 생각된다. (근데 사실 학문적 논문은 20년이 전환점이라고 보인다.)
같은 맥락에서 Diffusion LLM은 이미지 생성에서 검증된 점진적 디노이징(denoising) 프로세스를 텍스트에 적용한 접근법이다. 완전히 마스크된 텍스트에서 시작하여 여러 단계에 걸쳐 동시에 여러 토큰을 정제해나가는 방식으로 작동한다.
1) 핵심 동작 원리
일단 기존의 diffusion model 을 조금 알아야 한다. Diffusion model 은 데이터를 만들어내는 deep generative model 중 하나로, data로부터 noise를 조금씩 더해가면서 data를 완전한 noise로 만드는 forward process(diffusion process) 와 이와 반대로 noise로부터 조금씩 복원해가면서 data를 만들어내는 reverse process 를 활용한다. (What are Diffusion Models?)
그림에서 예시로, "대략적인 윤곽(스케치) → 스케치 채우기 → 세부사항 → 마무리" 비유를 많이 한다. 이를 자연어에서 비유해 보자면 아래와 같은 흐름이다.
# 예시: "AI가 미래를 바꿀 것이다" 문장 생성하기
# 1단계: 모든 곳이 빈칸인 상태로 시작
"[____] [____] [____] [____] [____]"
# 2단계: 가장 확실한 단어들부터 채우기
"[____] [미래를] [____] [것이다] [____]"
# 3단계: 남은 빈칸들 채우기
"[AI가] [미래를] [____] [것이다] [____]"
# 4단계: 마지막 빈칸 완성
"[AI가] [미래를] [바꿀] [것이다] [____]"
# 최종: 완성된 문장
"AI가 미래를 바꿀 것이다"
PS) 예시를 클로드한테 만들어 달라고 했다. 이제 클로드한테 선생님라고 해야할 듯...이렇게 접근하면 아래와 같은 이점이 생긴다.
1. 병렬 처리 가능: 기존 방식(첫 번째→두 번째→세 번째)과 달리 모든 위치를 동시에 처리 가능 하다.
2. 전체 맥락 고려: 문장 전체의 흐름과 의미를 처음부터 고려할 수 있다.
3. 오류 수정 기회: 여러 단계를 거치면서 잘못된 예측을 바로잡을 수 있다.
# Diffusion 생성 방식: 모든 위치를 동시에 고려
def generate_text_diffusion():
# 1. 완전히 빈 상태로 시작
text = ["[MASK]"] * 문장길이
# 2. 여러 단계에 걸쳐 점진적으로 완성
for 단계 in range(총_단계수, 0, -1):
# 현재 상태에서 각 위치의 단어 예측
예측결과 = model.predict(text, 현재_단계=단계)
# 가장 확실한 예측부터 빈칸 채우기
text = 확실한_예측만_반영(text, 예측결과)
return text2) 텍스트의 이산적 특성
텍스트의 이산적 특성 때문에 연속적인 이미지 확산과는 다른 접근이 필요하다. 텍스트는 다음과 같은 개별 단위들로 구성된다.
- 문자 단위: 'ㄱ', 'ㄴ', 'ㄷ' 또는 'a', 'b', 'c'
- 단어 단위: "사과", "바나나", "오렌지"
- 토큰 단위: "안녕", "하세요", "!"
각 단위는 명확히 구분되고, 그 사이에 "중간 상태"가 없다. 예를 들어 "사과"와 "바나나" 사이에 "사바나나" 같은 중간 단어는 의미가 없듯이 말이다. 이 특성 때문에 텍스트 처리에서 "특별한 접근이" 필요하다. 왜냐면 아래와 같인 이유때문이다!!
- "딥러닝에서" 연속적인 숫자로 변환(임베딩)해야 한다.
- "확률 모델링에서" 각 토큰별로 확률을 계산해야 한다.
- "생성 모델에서" 한 번에 하나씩 토큰을 선택해야 한다.
3) Absorbing State
그래서 "Absorbing State" 와 같은 특별한 접근법이 등장했다.
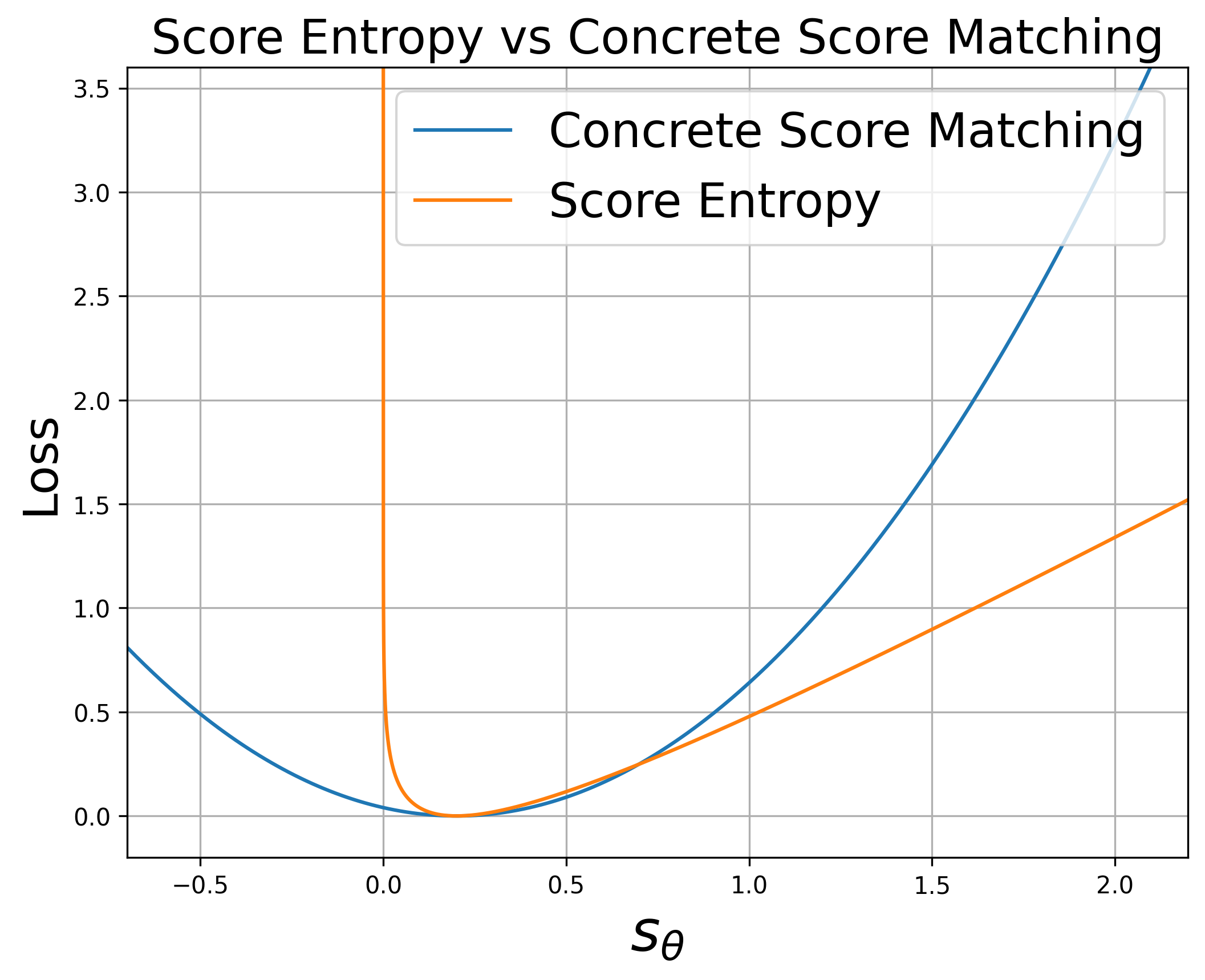
사실 더 정확하게는 D3PM(2021)에서 absorbing state를 포함한 이산 확산 모델이 제안되었고, 여전히 성능 문제가 있었다. 하지만 SEDD(2023)에서 score entropy라는 새로운 손실 함수로 이를 크게 개선했다.
Google Research 등에서 발표한 D3PM, D3PM(Discrete Denoising Diffusion Probabilistic Models) 논문에서 Absorbing State는 "모든 토큰이 최종적으로 [MASK]라는 특별한 상태로 흡수되는 과정" 으로 정의한다. (Structured Denoising Diffusion Models in Discrete State-Spaces) 이 과정이 아래와 같다.
# 원본 문장
"파이썬은 배우기 쉬운 언어다"
# Forward Process: 점진적으로 단어들이 [MASK]로 변함
# t=1: "파이썬은 배우기 쉬운 [MASK]"
# t=2: "파이썬은 [MASK] 쉬운 [MASK]"
# t=3: "[MASK] [MASK] [MASK] [MASK]" ← 모든 단어가 흡수됨
# Reverse Process: 거꾸로 [MASK]에서 원래 단어 복원
# t=3→2: "[MASK] [MASK] [MASK] 언어다"
# t=2→1: "파이썬은 [MASK] 쉬운 언어다"
# t=1→0: "파이썬은 배우기 쉬운 언어다" ← 완전 복원
# https://pmc.ncbi.nlm.nih.gov/articles/PMC10909201/
# 공식 논문의 수학적 표현을 쉽게 번역하면!
# Forward Process (원본 → 마스크)
# αt = 시간 t에서의 원본 토큰 유지 확률
q(z_t | x) = αt * 원본토큰 + (1-αt) * [MASK]
# 예시: α₃ = 0.7이면
# 70% 확률로 원본 유지, 30% 확률로 [MASK]로 변환
# Reverse Process (마스크 → 원본)
# 신경망이 마스크된 토큰의 원본을 예측
p_θ(z_{t-1} | z_t) = 모델이_예측한_토큰_분포(z_t, t)더 자세한 정보는 Simple and Effective Masked Diffusion Language Models 를 추천한다.
하지만, D3PM 에서는 Mean Prediction 방식의 한계, Concrete Score Matching 의 문제 등이 있었고, 이후 Stanford 와 Pika Labs 가 공동 개발한 Score Entropy Discrete Diffusion (SEDD) 은 이산 공간에서의 score matching 이론적 기반을 마련했다. 특히 음수값 문제, 확장성 문제, 연속시간 근사 문제를 해결하는 새로운 score entropy 손실 함수를 도입하여, 이산 데이터(특히 자연어)에 대한 Diffusion 모델의 이론적 토대를 확립했다.
이후 현재 LLaDA 까지 발전되어 왔다.
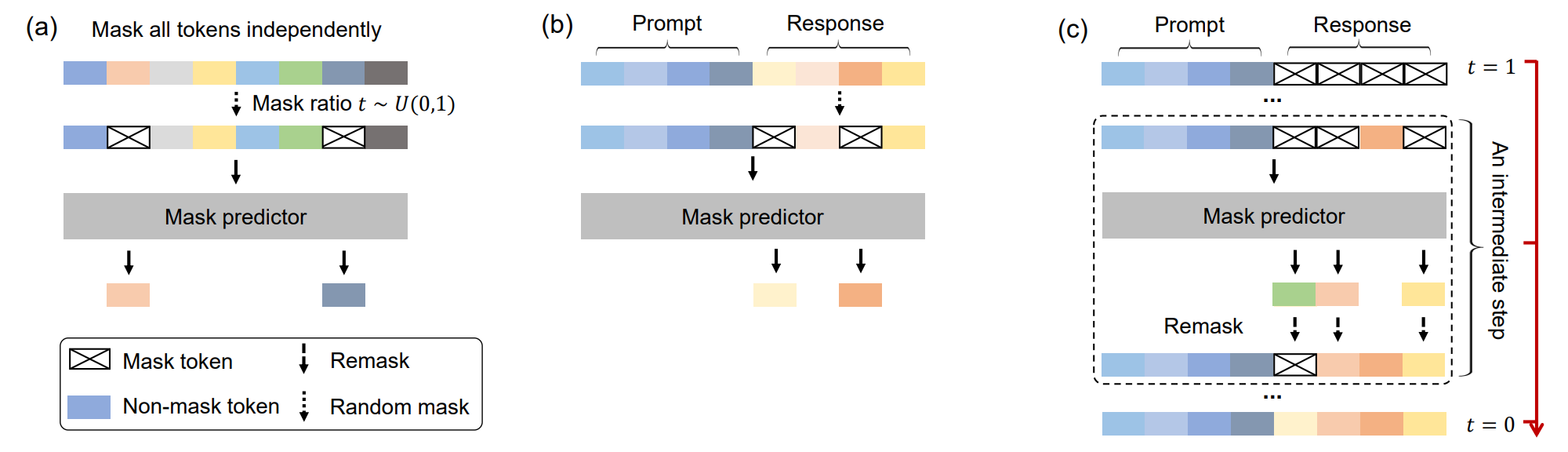
LLaDA의 학습 및 추론 방식을 도식화 하면 위와 같다. 학습 과정에서는 입력에 점진적으로 잡음(Noise)을 추가하여 마스킹 토큰을 생성고 입력 전체가 마스킹 되면, 다시 원본 문장을 점진적으로 복원한다. 추론 과정에서는 프롬프트가 아닌 응답 부분만 마스킹 처리한 후, 이 부분을 예측하는 방식을 통해 응답을 생성한다.

색이 어두울수록 나중에 예측된 토큰이며, 밝을수록 일찍 예측된 토큰이다.
Google DeepMind의 실제 구현
Google DeepMind의 Gemini Diffusion 모델은 이 매커니즘을 바탕으로 구현됐다. "전통적인 autoregressive 모델이 한 번에 하나씩 토큰을 생성하는 반면, diffusion 모델은 노이즈를 단계적으로 정제하여 출력을 생성한다"고 설명한다. - https://deepmind.google/models/gemini-diffusion/
4) Diffusion 이 만능인가여?!
- 결론 부터 보자면 아직은 시기 상조라고 보여진다. 하지만 핵심은 "특정 섹터에서는 기존 방식의 가격대비 성능을 뛰어넘고" 있다.
Autoregressive의 여전한 강점
-
생태계 성숙도
- HuggingFace Transformers, vLLM, TensorRT-LLM 등 완성된 최적화 도구들
수천 개의 사전훈련된 모델과 광범위한 커뮤니티 지원 - 프로덕션 검증된 배포 인프라 (Kubernetes operators, monitoring tools)
- HuggingFace Transformers, vLLM, TensorRT-LLM 등 완성된 최적화 도구들
-
확장성과 품질
- GPT-4, Claude, Gemini 등 100B+ 매개변수의 (엄청 라지스케일의) 대규모 모델들
- 복잡한 추론, 긴 맥락 이해에서 여전히 우수한 성능
- Chain-of-thought, few-shot learning 등에서 자연스러운 강점.
-
예측 가능성
- 토큰별 순차 생성으로 디버깅과 해석이 용이
- 확률 분포가 명확해서 불확실성 정량화가 쉬움 (물론 이게 어떻게 black box 확률을 계산했냐를 알 수 있다는 뜻은 아님)
- 길이 제어가 자연스러움 (EOS 토큰까지 생성)
-
특정 작업에서의 우위
- 대화형 AI에서 자연스러운 turn-taking
- 코드 생성에서 논리적 흐름 유지
- 창작 글쓰기에서 일관된 스타일 유지
Diffusion의 현실적 한계
-
훈련 복잡성
- 노이즈 스케줄 튜닝, 마스킹 전략 등 하이퍼파라미터 민감도 높음
- Autoregressive 대비 수렴 안정성 낮음
- 디버깅이 어려운 확률적 과정
-
제한된 규모
- 현재 대부분 8B 이하, 100B+ 규모 모델 부재
- 스케일링 법칙이 아직 완전히 검증되지 않음
-
특정 작업에서의 약점
- 매우 긴 시퀀스 생성에서는 여전히 느림
- 순차적 추론이 중요한 수학 문제 해결에서 한계
- 실시간 대화에서 응답 품질 vs 속도 트레이드오프
요약
- 고속 대량 처리: Diffusion 이 유리할 수 있음
- 복잡한 추론: 아직 Autoregressive 여전히 강세로 보임
- 안정적 프로덕션: (시장 성숙도를 포함하면) Autoregressive가 더 안전
- 비용 효율성: Diffusion이 유리 (동일 성능 대비를 의미)
3. 모델 중심 요약 및 정리
주관을 100% 담은 Diffusion LLM 을 위한 논문/모델 주의 시계열 정리
[2021.07]Google Research + MIT = D3PM: Discrete Denoising Diffusion Probabilistic Models 발표[2023.10]SEDD (Score Entropy Discrete Diffusion)[2023.12]Apple, PLANNER, Latent Language Diffusion Model 발표 (NeurIPS 2023)[2024.06]Cornell Tech의 Volodymyr Kuleshov 그룹,MDLM- Masked discrete Diffusion Language Model[2025.02]LLaDA 8B 공개, 단 2.3T 토큰으로 학습했음에도 LLaMA3 8B (15T) 에 밴치마크 비교 우위[2025.02]Inception Labs: Mercury Coder 시리즈[2025.03]BD3-LMs: Block Discrete Diffusion 기반의 language model[2025.05]Google DeepMind: Gemini Diffusion 모델 구조 공개 (Google I/O)
출처
- Lilian Weng의 “What are Diffusion Models?”
- LLaDA: Language Models as Diffusion Agents. 2024. arXiv
- LLaDA 데모 페이지
- [논문리뷰] Large Language Diffusion Models (by 김준영)
- 인셉션랩 Mercury 공개 뉴스 (AI Matters)
- Mercury Coder 소개 페이지 (Inception Labs)
- Mercury 기반 상업용 diffusion 모델 소개 (Maginative)
- Supervised Fine-Tuning 이후 성능 비교 (arXiv HTML 버전)
- BD3-LMs 공식 블로그 (by Manuel Arriola)
- SEDD 논문: Score Entropy Discrete Diffusion
- Structured Denoising Diffusion Models in Discrete State-Spaces (D3PM)
- Simple and Effective Masked Diffusion Language Models (MDLM)
- Google DeepMind Gemini Diffusion 모델 소개
- Apple Machine Learning Research: PLANNER 논문
