
[ "한빛미디어 서평단 <나는리뷰어다> 활동을 위해서 책을 협찬 받아 작성된 서평입니다." ]
GPT API를 활용한 인공지능 앱 개발(2판)
올리비에 케일린(Olivier Caelen): 결제 기술의 선도 기업인 월드라인(Worldline)에서 머신러닝 연구자, 브뤼셀 자유대학교(Universite libre de Bruxelles)에서 머신러닝 개론과 심화 딥러닝 과목을 가르치고 있음, 통계학과 컴퓨터 과학으로 석사 학위를 받고 머신러닝으로 박사 학위 - https://www.linkedin.com/in/oliviercaelen
마리 알리스 블레트(Marie-Alice Blete): 코모도 헬스(Komodo Health)에서 AI 엔지니어, LLM 관련 커뮤니티 & 강연 활발 - https://www.linkedin.com/in/mblete/
리뷰
책 이름이 "앱 개발" 보다는 "다양한 응용프로그램(application) 개발" 이 한국어 번역에 더 익숙하지 않을까? 라는 생각이 든다. "앱" 이라는 의미가 유독 국내에서는 "모바일앱" 으로 인식되는 것 같아서 오해가 될 가능성도 있을 것 같다.
난이도는 python 기본 문법과 관심만 있으면 바로 시도할 수 있을 정도로 평이하다. 만약 모델 내부의 로직의 상세한 step 이나, 대중적으로 알려진 LLM 활용 그 이상을 바란다면 이 책이 너무 얕게 느껴질 수 있을 것 같다.
거시적인 관점에서 LLM 을 살펴볼 수 있고, 특히 GPT 기반으로 다양한 application 의 정말 다양한 활용과 예제를 볼 수 있다. 실습 기반이다 보니, 책엔 코드가 절반 정도 차지한다. 그 깊이는 당연하게 얕지만 진짜 제너럴하게 대부분의 기능을 맛볼 수 있다. (심지어 OpenAI 의 웹 인터페이스(playground)에서 설명도 말이다 ㅎㅎ, 거의 OpenAI 홍보 너낌)
오히려 "프롬프트 엔지니어링" 에 많은 인사이트를 얻을 수 있었다. 그리고 function & tools 와 같이 진짜 누가 말 안해줬으면 절대 몰랐을 것 같은 꿀팁도 있었다. (물론 Official Docs 에는 있다.ㅎㅎㅎ)
400p 이지만 하루만에 완독 가능한 수준이고, 컴퓨터와 깃허브 예제와 함께 한 호흡으로 쭉 따라기 좋게 구성되어 있다. 만약 현업에서 당장 LLM 을 활용한 프로젝트를 실행하거나 R&D 가 필요한 부분이 있다면, 가장 먼저 읽어보면 그 다음 힌트를 찾을때 많은 도움이 되는 책이라고 생각이 든다.
(PS. 그 외에도 LLM 에 조금이라도 관심을 가지는게 좋다고 생각하며, 적어도 이 정도 책은 읽는게 앞으로 많은 도움이 되지 않을까 생각한다.)
책 보러가기 >> GPT API를 활용한 인공지능 앱 개발(2판)
목차별 리뷰
CHAPTER 1 GPT 모델과 챗GPT
GPT는 "옴니 모달" 부터 다양한 유형 인풋(시각, 청각 등)을 하나의 모델로 처리하고 있다. 그리고 가볍게 AI, ML, Deep Learning, Transformer, LLM (foundation model) 까지의 관계를 보여준다.

LLM의 핵심 로직은 "다음 단어가 될 가능성이 큰 단어 예측" 하는 것이다. [ 엔그램 -> RNN -> LSTM ] 순서로 발전된 자연어 처리에서 "트랜스포머" 아키텍처가 "혁명"을 가져왔다고 평가한다.
RNN의 긴 시퀀스 context 잊어버리는 치명적인 이슈가 있었다. (파괴적망각), 이를 위해 "트랜스포머"는 "어텐션 메커니즘" 을 활용한다.
모든 단어를 똑같이 중요하게 평가하지 않고, 작업 각 단계에서 관련성이 높은 부분에 "주의" 한다는 것
트랜스포머는 "교차 어텐션" 과 "셀프 어텐션" 을 활용하며, 순환하는 형태가 아니라 "동시 처리 가능" 해서 병렬 작업 가능하며 이에 GPU 와 완벽한 궁합이 맞게 되었다. 그에 따라 더 큰 데이터셋으로 훈련이 가능했고, LLM 의 기반이 되었다. (아래는 어텐션 개념에 중요한 맥락이 되는 논문)
-
Bahdanau Attnetion - Paper : Neural Machine Translation by Jointly Learning to Align and Translate
-
Luong Attention - Effective Approaches to Attention-based Neural Machine Translation
트랜스 포머는 인코더와 디코더라는 중요 두 구성 요소가 있고 모두 어텐션 매커니즘 의존한다. "인코더" 의 임무는 입력 텍스트 처리, 중요한 특징 식별 (주의), 의미 있는 표현 생성하는 것 이라고 한다(임베딩). "디코더" 는 그 임베딩을 활용해 출력을 생성하는 부분을 의미한다.
GPT 는 genrative pre-trained transformer, 디코더를 활용하는 모델이며 GPT 는 인코더가 없고, GPT 는 셀프 어텐션 메커니즘에만 의존, BERT 와 반대된다.(BERT는 인코더 전용)
짧게 GPT의 자연어 처리 흐름을 보자면 아래와 같다.
- (1) 입력 내용 -> (2) "토큰" 단위로 분해 (토크나이징), 토크나이징 도구가 따로 존재 -> (3) 어텐션 메커니즘 + 트랜스포머 아키텍쳐, 토큰 처리
- (4) 의미 해석, context 식별, 해석한 context 에 따라 필요한 "자리", "토큰" 에 확률값 계산 -> (5) 반복
가장 핵심적으로 GPT 3 이후 "인간 피드백 강화 학습 - RLHF" 를 통해 성능을 개선 했고, 인스트럭트GPT-3 가 등장했다고 한다. 그리고 이를 위한 크게 아래 2가지 방법을 소개한다.
(1) 지도형 파인 튜닝 (SFT, Supervised Fine-Tuning)
- 인간 라벨러가 프롬프트에 대한 이상적인 응답 예시를 제공하며, 이를 학습 데이터로 활용
- 모델이 이상적인 답변을 반복적으로 학습하도록 유도
- 대규모의 고품질 정제 데이터셋을 기반으로 모델을 사전 훈련
- 결과적으로, 더 자연스럽고 유용한 응답을 생성하는 능력이 향상됨
(2) RLHF (인간 피드백 강화 학습) 과정
보상 모델(RM, Reward Model)을 활용하여 학습을 진행- 우선, 라벨러가 모델이 생성한 여러 개의 답변을 평가하고 순위를 매김
- 이를 통해 보상 모델이 "좋은 답변"과 "좋지 않은 답변"을 구별하는 기준을 학습
- 이후, 강화학습(RL) 기법을 적용하여 GPT 모델이 보상 모델을 최대화하는 방향으로 최적화
그리고 RLHF 를 통해 GPT-4o 가 1년도 안되는 시기에 전작 4 에 비해 압도적 성능 강화 성공했고, 이제는 다양한 파운데이션 모델 하며 앞으로는 "최적화와 활용" 의 시대가 열렸다고 한다.
(PS. GPT-4o mini 경우 128,000 토큰 입력 컨텍스트 처리 가능, 이는 종이책 300페이지)
CHAPTER 2 오픈AI API
이 장에서는 OpenAI의 API 사용법을 중심으로, OpenAI 홈페이지 활용법, 플레이그라운드(Playground) 사용법, API 키 발급 과정, 그리고 Python 기반 API 활용 방법 등을 다룬다.
특히, OpenAI의 핵심 파라미터인 temperature 와 top_p 의 개념을 상세히 설명한다.
temperature
- 모델의 출력 변동성을 조절하는 매개변수로, 값이 클수록 더 창의적이고 다양성이 있는 응답이 생성되며, 작을수록 더 일관된 응답이 나온다.
temperature값이 높을수록(예: 1.0 이상) 더 예측 불가능한 단어 선택이 이루어지며,
낮을수록(예: 0.2 이하) 더 정해진 패턴의 답변이 생성된다.
top_p
- 확률 질량 상위 토큰을 선택하는 방식으로, 예를 들어
top_p=0.9로 설정하면 상위 90% 확률을 차지하는 후보들 중에서만 토큰을 선택한다. temperature와 달리, 확률 분포 자체를 변화시키지는 않으며, 모델이 선택할 후보군을 사전 제한하는 방식이다.
그리고 가장 간단하고 다양한 예제를 소개하는데, 특히 tools 와 function 은 재미있게 봤다. 아래는 SQL 쿼리를 실행하여 상품 목록을 찾는 기능을 함수 호출 방식으로 활용하는 예제이다.
def find_product(sql_query):
# 쿼리를 실행
results = [
{"name": "pen", "color": "blue", "price": 1.99},
{"name": "pen", "color": "red", "price": 1.78},
]
return results
function_find_product = {
"name": "find_product",
"description": "sql 쿼리에서 상품 목록을 찾습니다.",
"parameters": {
"type": "object",
"properties": {
"sql_query": {
"type": "string",
"description": "A SQL query",
}
},
"required": ["sql_query"],
},
}전반적으로 대부분의 기능들에 대해 아주 기본적인 예제들 나열해 놓은 장이다.
CHAPTER 3 LLM 기반 애플리케이션 개발
여기서 부터는 실제 깃허브 코드 예제를 보는게 빠르다. 실제 애플리케이션 개발에 적용할 수 있는 LLM 활용 사례, 아키텍쳐와 구조에 대한 설명으로 이뤄져 있다.
-
뉴스 생성 솔루션 구축
- GPT를 활용하여 기사 요약 및 재구성, 특정 주제나 키워드 기반으로 뉴스 콘텐츠 자동 생성
-
유튜브 동영상 요약
- 동영상의 자막을 LLM에 입력하여 핵심 내용 요약, 시간당 요약 비용 절감을 위해 적절한 프롬프트 및 API 사용 최적화
-
의도 분류 서비스 (Redis 및 벡터라이징 활용)
- 사용자의 입력을 벡터화하여 의도를 자동 분류, Redis와 같은 고속 캐싱 시스템을 활용하여 응답 속도 최적화
-
개인 어시스턴트
- 사용자의 일정, 이메일, 메모 등을 정리하는 AI 비서 기능, 문맥을 이해하여 보다 자연스러운 응답을 생성
-
문서 정리 및 감정 분석
logprobs매개변수를 활용하여 응답 신뢰도를 평가 - 감정 분석 예제logprobs라는 개념 자체를 아는 것이 필요할 것 같다.
그 외 "비용 관리 및 쿼리 캐싱" 으로 API 호출 비용을 절감하기 위해 쿼리 결과를 캐싱하거나 자주 반복되는 요청에 대해 Redis 또는 DB 캐싱 활용하는 예제가 있다.
가장 재미있게 본 부분은 "프롬프트 압축" 인데, https://velog.io/@mmodestaa/LLMLingua-draft 글과 같이 "LLMLingua" 같은 방법이 있다. 실제 MS 에서 제공하는 활용가능한 라이브러리도 존재한다. (LLMLingua 깃허브)
참조할 만한 논문 LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
CHAPTER 4 GPT-4o 및 챗GPT 활용 고급 기법
(개인적으로 가장 재미있게 본 챕터이다.) 이 장에서는 프롬프트 엔지니어링, 파인 튜닝, RAG(Retrieval-Augmented Generation) 기법 등을 다루며, GPT-4o와 챗GPT를 보다 효과적으로 활용하는 방법을 소개한다.
이전 장까지가 기본적인 API 활용과 애플리케이션 개발에 초점이 맞춰져 있었다면, 이 장에서는 성능 최적화, 모델 개선, 신뢰성 향상에 대한 보다 고급 기법을 중점적으로 다룬다.
프롬프트 엔지니어링은 LLM을 보다 정교하게 제어하여 원하는 결과를 얻는 기법이다. 이를 위해 역할(Role), 컨텍스트(Context), 작업(Task) 지정 방식이 중요하게 다뤄진다.
- 역할(Role): 모델이 어떤 역할을 수행하는지 명확하게 지정 (예: "당신은 데이터 분석가입니다.")
- 컨텍스트(Context): 모델이 작업을 수행하기 위해 필요한 배경 정보 제공 (예: "이전에 생성된 텍스트는 다음과 같습니다.")
- 작업(Task): 모델이 수행해야 할 작업을 명확하고 구체적으로 설명 (예: "다음 데이터를 JSON 형식으로 변환하세요.")
Few-shot Learning과 단계적 추론(Chain of Thought, CoT)
-
제로샷 러닝(Zero-shot Learning)
- 예제 없이 바로 문제를 풀도록 시도하는 방식
- 예: 곱셈 문제를 단순 계산하는 경우
- 2 x 3 = ? → 6
-
원샷 러닝(One-shot Learning)
- 예제 하나를 제공한 뒤, 유사한 문제를 해결하도록 유도하는 방식
- 예제: 3 × 4 = 12 → 그럼 2 × 5는?
-
퓨샷 러닝(Few-shot Learning)
- 여러 개의 예제를 제공한 후 패턴을 학습시켜 문제 해결을 유도하는 방식
- 대표적인 활용: 코딩 문제 해결, 문장 요약, 감정 분석 등
-
Chain of Thought(CoT) & 단계적 추론
- LLM이 단순한 응답이 아니라 사고 과정을 따라가며 답을 도출하도록 유도
- "단계별로 생각하세요." 같은 프롬프트를 삽입하여 복잡한 문제 해결 능력을 향상
- 대표 논문: "Let's think step by step"
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
아래와 같이 프롬프트를 "피드백 통한 반복적 개선, reviewer, questioner, maker 루프를 구성한 아주 간단한 예시" application 도 재미있게 봤다. (개인적으로 여기에 다른 파운데이션 모델을 피드백 루프에 끼는 것이 좀 더 상향 평준화에 도움이 된다고 생각한다. )
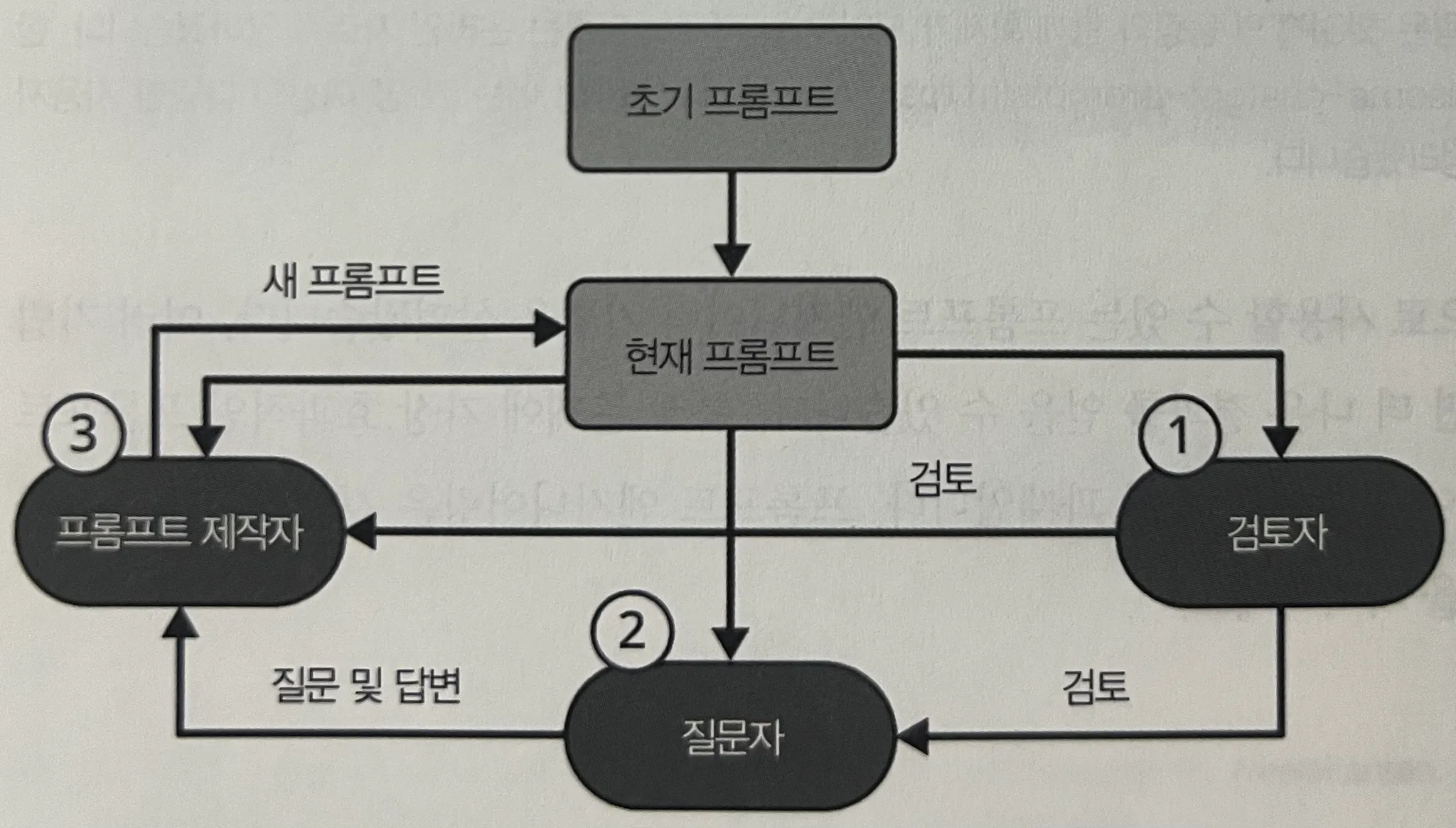
프롬프트 체이닝 & 네거티브, 섀도 프롬프팅
-
프롬프트 체이닝 (Prompt Chaining)
- 하나의 작업을 여러 단계로 나눠서 실행하도록 유도
- 예: 문서 요약을 먼저 수행한 후, 요약된 내용을 다시 구조화
-
네거티브 프롬프트 (Negative Prompting)
- 특정 출력을 억제하는 방식 (예: "아무것도 출력하지 마세요.")
- 이미지 생성 모델에서도 적용됨 (예: "노이즈 없이 선명한 이미지를 생성하세요.")
-
섀도 프롬프팅 (Shadow Prompting)
- 작업을 명시적으로 밝히지 않고도 원하는 결과를 도출하는 기법
- 창의적 작업을 유도하는 데 효과적
프롬프트 최적화 도구
- Promptfoo, https://discuss.pytorch.kr/t/promptfoo-llm/4715
- DSPy, https://devocean.sk.com/blog/techBoardDetail.do?ID=166043&boardType=techBlog
파인 튜닝
- 어조와 스타일 조정, 원하는 형태로 변경, 특정 도메인 지식에 집중하게 유도
- 신뢰성과 할루시네이션 감소, 프롬프트에서 묘사하기 어려운 복잡한 작업 수행
- 모델의 출력 형식을 정확하게 원하는 형태로 조정 (자연어 -> JSON)
OpenAI 에서 자체 파인 튜닝 가능한 기능 제공 하지만 open ai 서버에 모델 저장된다. 그리고 학습 이후 API 호출로만 활용 가능하며 비용면에서 장기적으로 후달린...다!..
데이터셋 구성은 (1) prompt 와 completion key (프롬프트와 완료쌍) 방법과 (2) role 과 conents 딕셔너리로 구성된 데이터 방법이 있다. OpenAI는 후자를 권장한다고 한다. 후자 예시 데이터셋은 아래와 같다.
{
"messages": [
{"role": "system", "content": "당신은 고객 지원 챗봇입니다."},
{"role": "user", "content": "환불을 받고 싶어요."},
{"role": "assistant", "content": "환불 절차를 안내해 드리겠습니다. 주문 번호를 알려주세요."}
]
}RAG
- 검색 증강 생성, 전반적인 RAG 구성도에 대한 설명이 있다. (사실 다들 잘 알듯 RAG 는 구현 자체가 어려운 기술이라기 보다는 이를 위한 데이터셋 구성와 "설계"가 엄청 중요한 기술이다.)
-
가상 문서 임베딩 - HyDE (Hypothetical Document Embedding)
- 가상의 문서를 생성 후, 이를 임베딩하여 검색 성능 향상
-
KNN (k-최근접 이웃) 검색
- 코사인 유사도를 활용한 벡터 기반 검색 방식, 백터 검색의 표준
-
ANN (근사 최근접 이웃) 검색
- 성능을 높이기 위해 일부 데이터만 검색하여 빠르게 유사 문서 찾기, "충분히 가까운 데이터"
-
하이브리드 검색 (퓨전 검색)
- 키워드 기반 검색 (TF-IDF or BM25 ...) + 상호 순위 융합(RRF - Reciprocal Rank Fusion) 와 합치는 것
- 그리고 실제 RAG 는 현재 진행형으로 다양한 형태의 발전을 이루고 있다. 책에서는 언급되지 않지만, 가장 기억에 남는 것은 "GraphRAG" 가 있고, 정리가 잘 된 다음 글을 추천한다.
- https://brunch.co.kr/@vsongyev/28
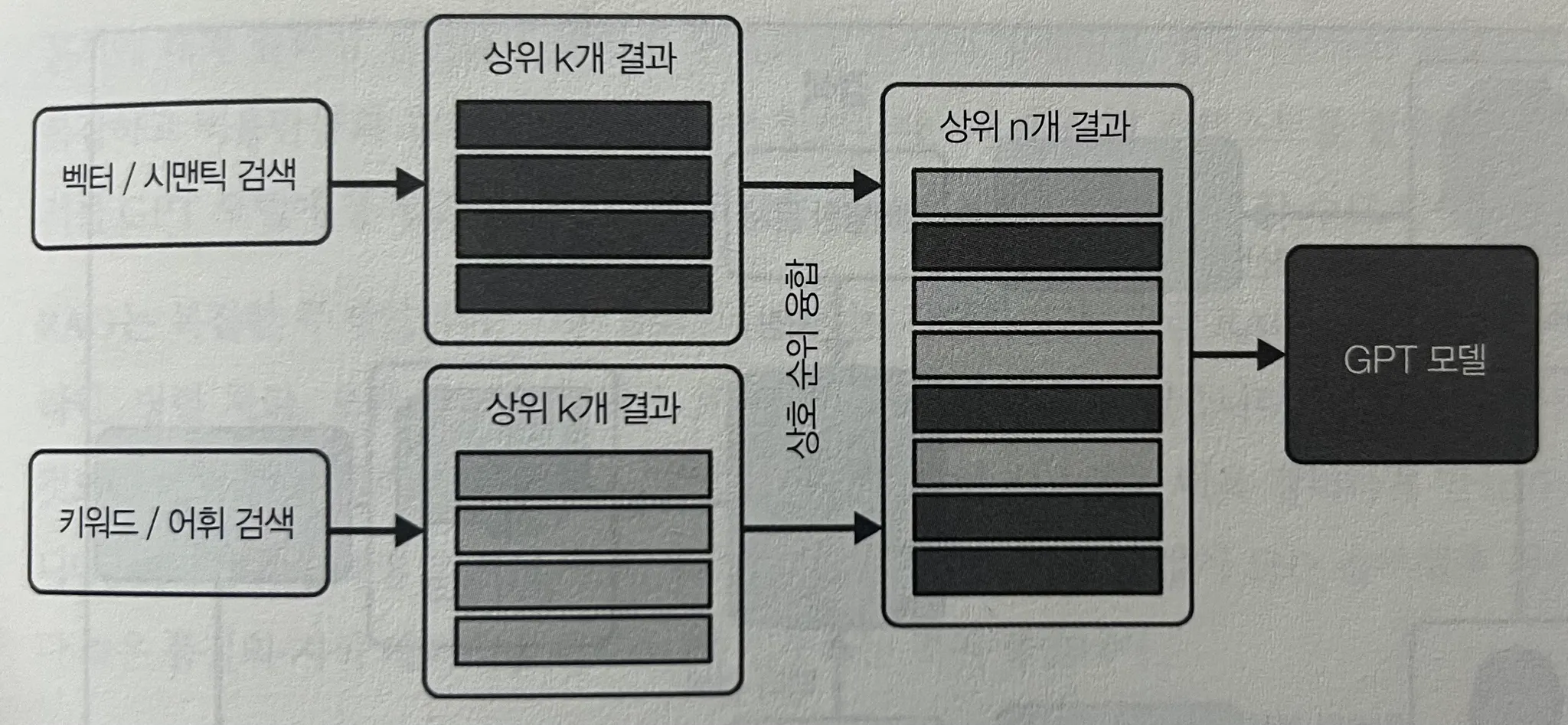
사실 최근 RAG 관련 글을 너무 많이 읽어서 그런지, 이 부분이 엄청 와닿지는 않았다. (RAG R&D 고민만 반년 내내 하고 있으니 당연히 ㅠㅠ🥹) 그래도 가장 "심플하고 이상적인 아키텍처" 그림이 좋았다.
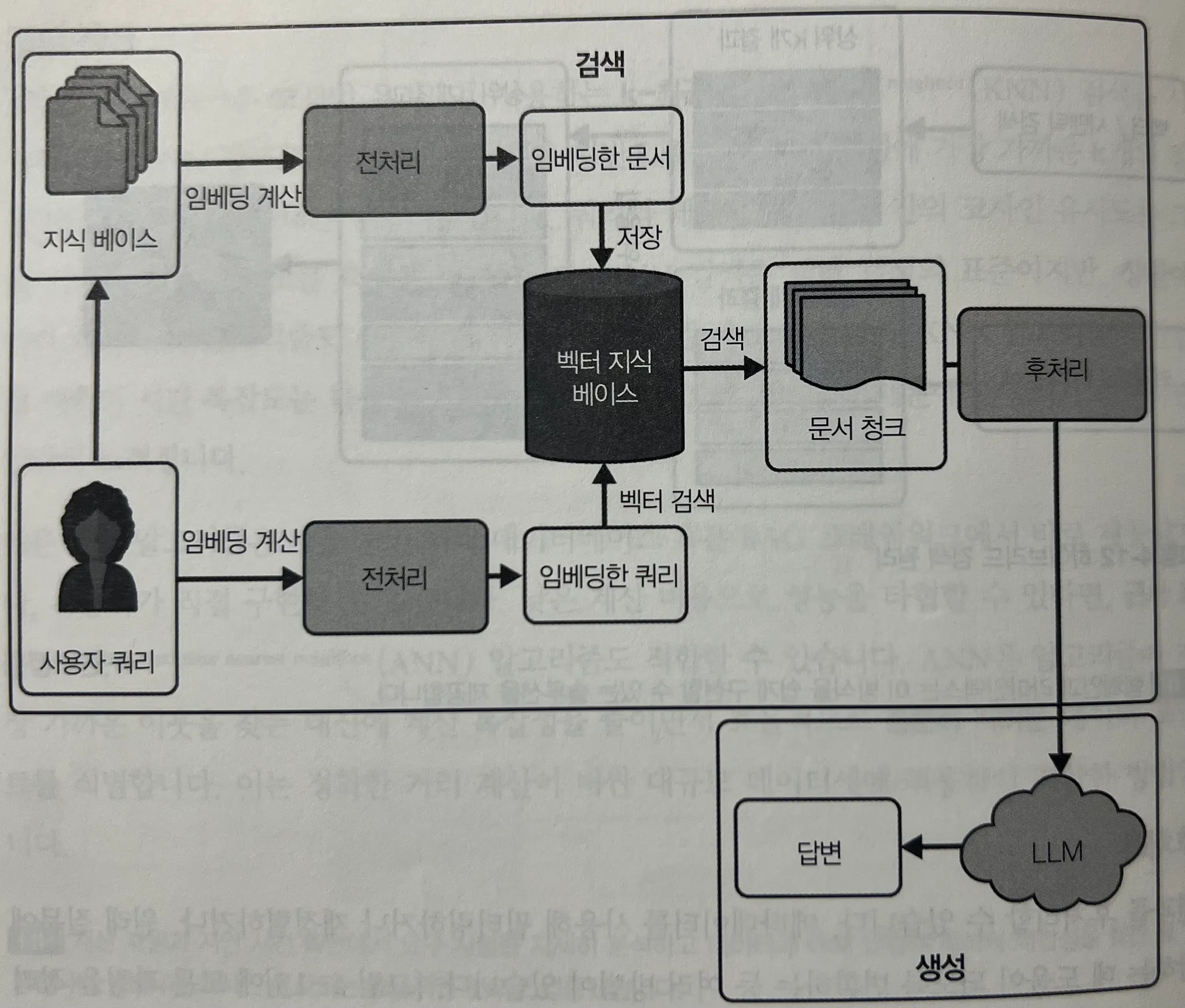
사실 이 RAG 에서는, 개인적으로, (모든 ML이 그렇겠지만) 저 vecotr 된 데이터가 9할, 후처리가 1할 하는 것 이라고 생각한다. 그리고 "평가" 방법에 대해 소개하며, 실제 OpenAI 가 사용하는 평가 방법을 참조하는 것이 좋다. Existing templates for evals
LLM 기반 솔루션 문제들
-
민감도와 비결정성 (Non-determinism)
- 같은 질문이라도 구두점이나 단어 배열에 따라 결과가 달라지는 문제
- 이를 해결하기 위해 일관된 프롬프트 작성 규칙이 필요하다.
- 그리고 같은 요청을 보내도 항상 동일한 답변을 보장할 수 없다.
- 이를 위해 seed 를 사용하지만 여전히 불완전하다.
- temperature 와 top_p 는 결국 다음 토큰 예측에 대선 선택일 뿐
-
할루시네이션 (Hallucination)
- 익히 유명한, "실제 존재하지 않는 정보를 생성하는 현상" 을 의미한다.
- 위에서 쭉 살펴본 프롬프트 엔지니어링, RAG, 파인 튜닝, RLHF 등의 기법으로 개선 가능하다.
간단한 내용일 수 있지만, 해당 장의 마지막에 아래와 같은 flow-chart 형식의 접근법이 다시 나에게 초심을 찾게 하는데 도움이 되었다. (쩨발 RAG 부터 고민하지마!! 그만~~)
CHAPTER 5 프레임워크로 LLM 기능 높이기
이 장에서는 LLM을 활용한 애플리케이션을 보다 체계적으로 개발할 수 있도록 도와주는 다양한 프레임워크를 다룬다. 특히, LangChain 과 LlamaIndex 를 중심으로 설명하며, RAG(검색 증강 생성) 파이프라인 구축 및 활용 사례를 소개한다.깊은 내용 보다는 기본적인 프레임워크 매커니즘과 실행에 대해서만 다룬다.
그리고 OpenAI GPT 앱(GPTs) 만드는 방법, GPT 의 어시스턴트 API 에 대한 간단한 소개가 포함되어 있다.
CHAPTER 6 마치며 & Appendix
이 장에서는 LLM 기반 애플리케이션 개발의 전반적인 과정을 정리하고, 앞으로의 발전 방향 및 최적화 기법에 대한 고찰을 제공한다.
스트림릿(Streamlit) 같이 심플한 UI 만을 위한 라이브러리 소개와 o1 에 대한 (퍼포먼스 중심의) 소개가 있고, 단어 정리와 함께 끝난다.
출처
- 해당 책의 깃허브 코드 예제
- Bahdanau Attnetion - Paper : Neural Machine Translation by Jointly Learning to Align and Translate
- Luong Attention - Effective Approaches to Attention-based Neural Machine Translation
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- https://brunch.co.kr/@vsongyev/28
- Promptfoo & DSPy
- Existing templates for evals

AI까지,, 현우님 정말 올라운더이시군요🫢