
[ "한빛미디어 서평단 <나는리뷰어다> 활동을 위해서 책을 협찬 받아 작성된 서평입니다." ]
LLM 엔지니어링
Paul Iusztin(폴 이우수틴): 7년 이상 생성형 AI, 컴퓨터 비전 및 MLOps 설루션을 구축한 시니어 ML/MLOps 엔지니어. 최근에는 Metaphysic에서 대규모 신경망을 프로덕션에 적용하는 핵심 엔지니어로 근무했다. 또한 프로덕션급 ML 교육 채널인 Decoding ML을 설립해 사람들이 ML 시스템을 구축할 수 있도록 IT 기사와 오픈 소스 강좌를 제공하고 있다. - 링크드인 / PS) 실제 폴 이우스틴의 미디엄 에서 해당 책의 원본, 원문 내용을 많이 찾아볼 수 있다.
Maxime Labonne(막심 라본): Liquid AI의 모델 최적화 총괄 책임자. 파리 폴리테크닉 연구소에서 ML 박사 학위를 취득했으며, AI/ML 분야의 구글 개발자로 일하고 있다. LLM 과정과 LLM AutoEval 등의 도구, NeuralDaredevil과 같은 SOTA 모델을 포함해 오픈 소스 커뮤니티에 활발히 기여하고 있으며, 기술 블로그도 꾸준히 운영하고 있다. 저서로는 『핸즈온 그래프 인공신경망 with Python』(홍릉, 2024)이 있다. - 링크드인
🔥 한빛 책 링크 - https://www.hanbit.co.kr/store/books/look.php?p_code=B8130648672
🔥 코드 참조 깃허브 레포 - http://github.com/inrap8206/LLM-Engineers-Handbook
리뷰
실제 MVP의 핵심 기능을 직접 정하고, ML & MLOps 관점에서 아키텍처 설계부터 실습까지 점진적으로 나아가는 구성은 이 책의 가장 큰 미덕이다. 각 장을 넘길수록 기능이 하나씩 추가되고, 아키텍처가 세밀하게 확장되어 가는 방식은 단순한 튜토리얼을 넘어선다. 프로젝트가 완성되는 시점에서 "이 책은 처음부터 꽤나 치밀하게 설계되었다는 것"을 깨달았고, 그 흐름 속에 독자를 몰입하게 만든다는 점에서 확실히 '밀도' 있는 구성이다.
무엇보다도 토이 프로젝트의 완성도가 기대 이상으로 재밌다. 단순히 ‘구현했다’ 수준을 넘어 실제 운영 가능한 수준의 기획과 구조, 그리고 실험 기반 접근이 더해져 있어서 진짜 ‘프로젝트 하나 만든다’는 느낌이 강하다. 단순한 예제 코드가 아닌, 실전 감각이 묻어난 프로젝트라는 점에서 분명 큰 만족감을 준다. 입문자용이 아니라서 아주아주 마음에 들었던 책.. FTI 아키텍쳐 하나 제대로 배운 것 만으로도 만족!
[아쉬웠던 포인트 들]
책의 설명은 굉장히 상세하지만, 그만큼 진입장벽도 있다. 실습 환경을 세팅하거나 파이프라인 흐름을 따라가는 과정에서, 시각적으로 빠르게 이해하는 데 한계가 있다. 영상이나 인터랙티브한 문서가 병행되었다면 더 많은 독자들이 이 책의 가치를 누릴 수 있었을 것이다. (근데 나중에 발견한 링크, https://decodingml.substack.com/p/build-your-second-brain-ai-assistant 참조하면 도움이 꽤 될 듯 하다.)
그리고 한국 독자 기준으로는 데이터셋이 꽤 낯설 수 있다. 필자의 경우 GitHub, Notion, LinkedIn, Velog 데이터를 기반으로 커스터마이징하여 실습을 진행했는데, 국내 데이터셋에 맞춘 튜닝 사례나 팁이 조금이라도 언급되었으면 훨씬 현실감 있는 접근이 가능했을 것이다.
매우 주관적으로 "범위와 구성이 약간 과했다" 는 생각이 든다. 특히 도메인 주도 설계(DDD) 파트는 실제로 직접 카테고리를 확장하거나 데이터 파이프라인을 커스터마이징할 때 예상보다 많은 구조 변경이 필요했다. (물론 내가 못해서...) 가벼운 레이어를 분리정도로 했어도 괜찮은 프로젝트 사이즈가 아닐까!? 했다.
"LLM 평가 파트의 아쉬움" 이 있다. 아주 개인적으로는 도메인 특화 모델의 평가에 더 깊이 들어가주기를 바랐다. 파인튜닝 이후 모델을 어떻게 평가해야 하는지, 특히 정량적 지표가 부정확하거나 불충분할 때 어떻게 QA 해야 하는지가 궁금했으나, 방법론적인 틀 정도만 제시되고 넘어간 점은 아쉬웠다. 물론, 특화 도메인의 평가가 어렵다는 점은 현실적으로 공감되지만 말이다.
이 책은 ‘한 번 읽고 덮을 책’이 아니다. 처음부터 끝까지 따라하며 실습하는 것도 좋지만, 직접 파이프라인을 추가하고, 특성을 바꾸고, 평가 방식을 고민하며 R&D하는 데 활용하면 훨씬 큰 가치를 지닌다. 단지 구현에 그치지 않고, 업계에서 자주 마주치는 안티패턴을 경계하면서 고응집 / 저결합 아키텍처를 지향한다는 점도 매우 인상 깊다.
(요즘 읽은 책 중에 가장 읽기 어려웠던 책이다. 바쁜 일상 속에서도 쉽게 놓치고 싶지 않은 내용이 너무 많았기에, 욕심내며 읽게 된 책이었다. 그런 만큼 다시 두 번, 세 번 반복해서 보는 가치가 있는 책이기도 하다.)
목차별 리뷰
CH 1. LLM Twin 개념과 아키텍처 이해
이 장에서는 LLM Twin을 만들기 위한 전략적 접근과 아키텍처 설계 개념을 다룬다. 먼저, LLM Twin을 현실화하기 위한 MVP(Minimum Viable Product) 전략으로 출발하여, 실제로 어떤 기능이 핵심인지 정의한다. 이 때 단순히 모델 개발이 아닌, 제품 관점에서의 기능 정의와 프로세스 구성에 포인트를 두고 있는게 인상 깊다.
< ML 시스템은 기본적으로 다음과 같은 전체 흐름을 가진다. >
- 새로운 데이터 수집, 정제, 검증
- 학습 환경과 추론 환경의 분리
- 비용 효율적 모델 서빙
- 데이터셋 및 모델의 버전 관리와 추적
- 인프라 및 모델 모니터링
- 확장 가능한 인프라 기반 배포
- 학습과 배포 자동화
이러한 이상적인 시스템 구성은 구글 클라우드 팀이 제시한 아래 그림에서도 확인할 수 있다.
< 이를 위한 가장 단순한 아키텍처는 모놀리식 배치 아키텍처다. >
이 구조는 학습과 서빙 사이의 왜곡(training-serving skew)을 피할 수 있다는 장점이 있지만, 다음과 같은 단점을 가진다.
- 특성 재사용성이 낮음
- 데이터 양이 증가하면 PySpark, Ray 등으로 리팩터링 필요
- 팀 간 협업 어려움
- 실시간 학습 전환의 어려움
< 단점을 극복하기 위한 대안으로 무상태 실시간 아키텍처 >
하지만 실시간으로 대용량 데이터를 처리하며 지속 학습을 수행하는 것은 여전히 도전적이다. 예컨대 영화 추천 시스템처럼, 사용자 상태와 맥락에 따라 전혀 다른 예측이 필요한 경우, 이러한 시스템 설계는 복잡해진다.
< 이러한 문제의 해결을 위해, 구글은 다음과 같은 아키텍처를 제시했다. >
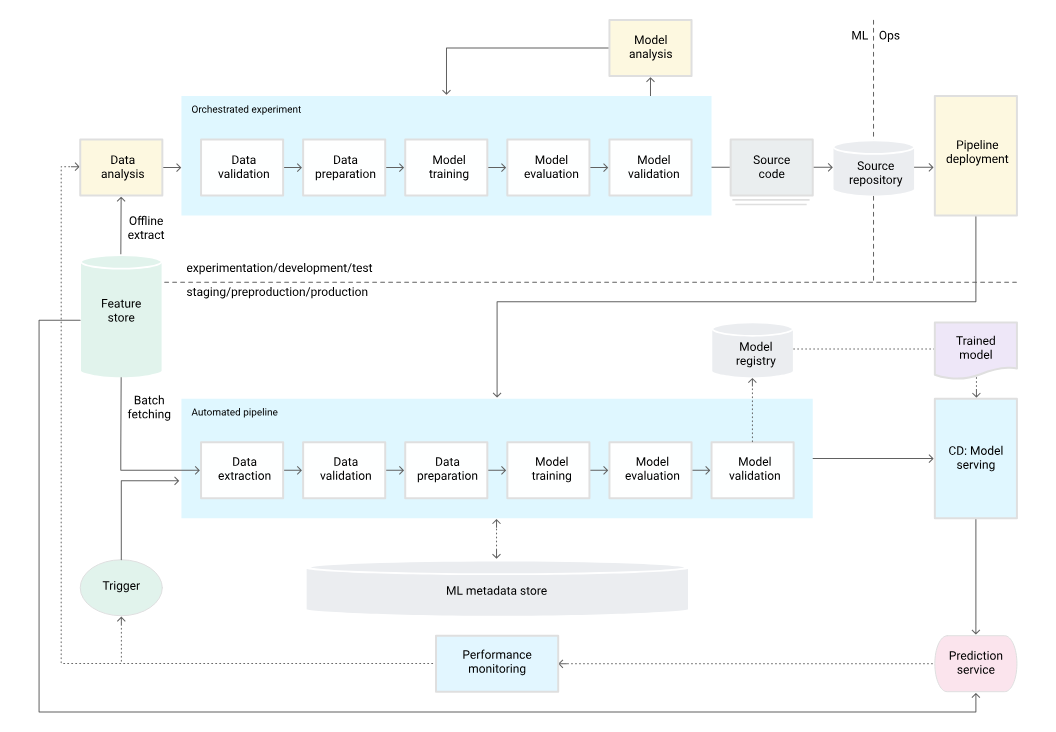
(실제 MLOps: 머신러닝의 지속적 배포 및 자동화 파이프라인 의 구글 문서에서도 따온 이미지로 설명함)
< FTI 아키텍처 - ML 시스템의 본질 >
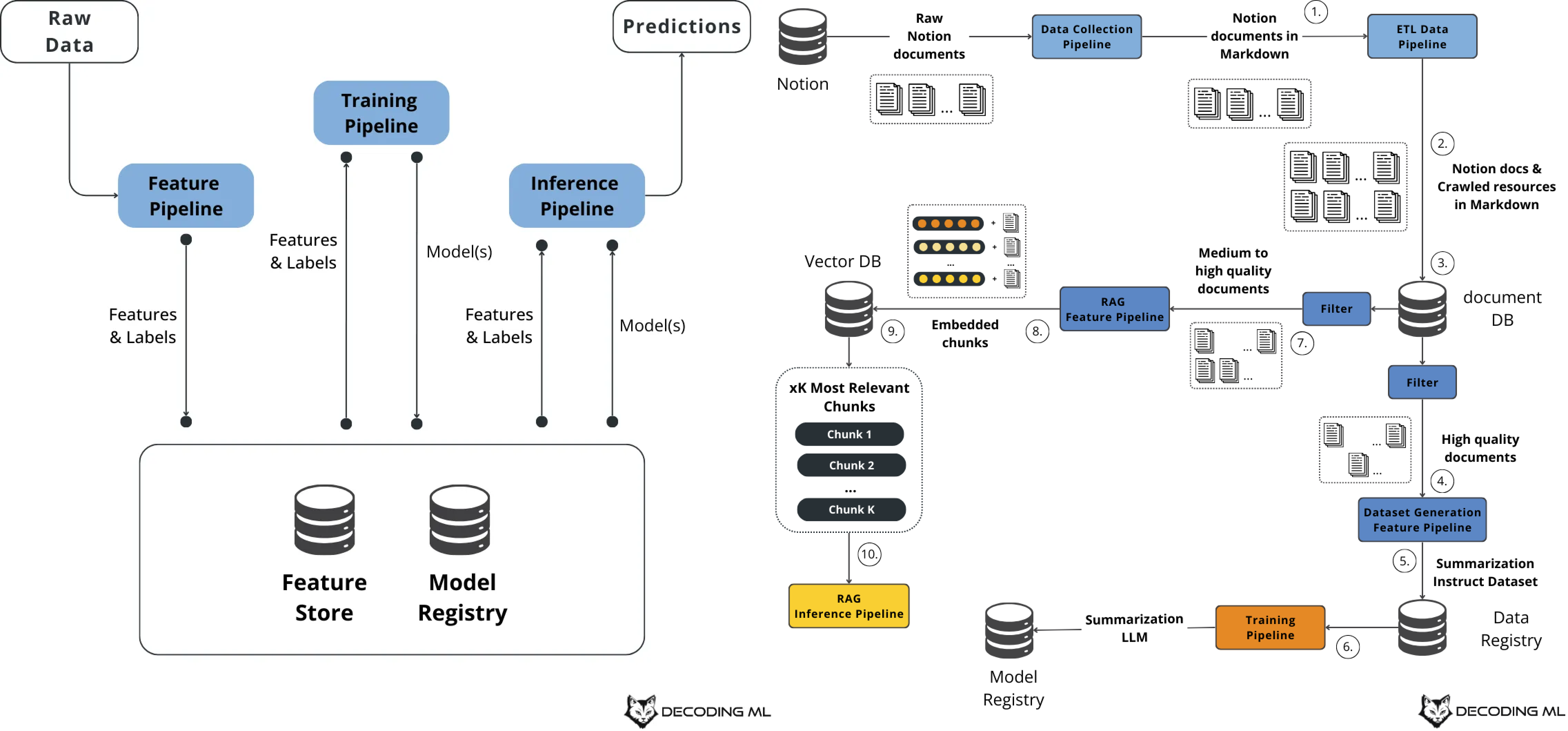
Feature - Training - Inference 로 구성된 FTI 아키텍쳐가 논리적인 ML 구조에 가장 부합하고, 구글 그림을 3개로 단순화 할 수 있다고 한다.
전통적인 웹 시스템에서의 DB - Business Logic - UI 계층처럼, 각각의 독립성과 연결성을 모두 갖춘 구조로 설명된다. 그렇기 때문에 "다양한 팀에서 관리하고, 재사용할 수 있는 형태" 라고 한다.
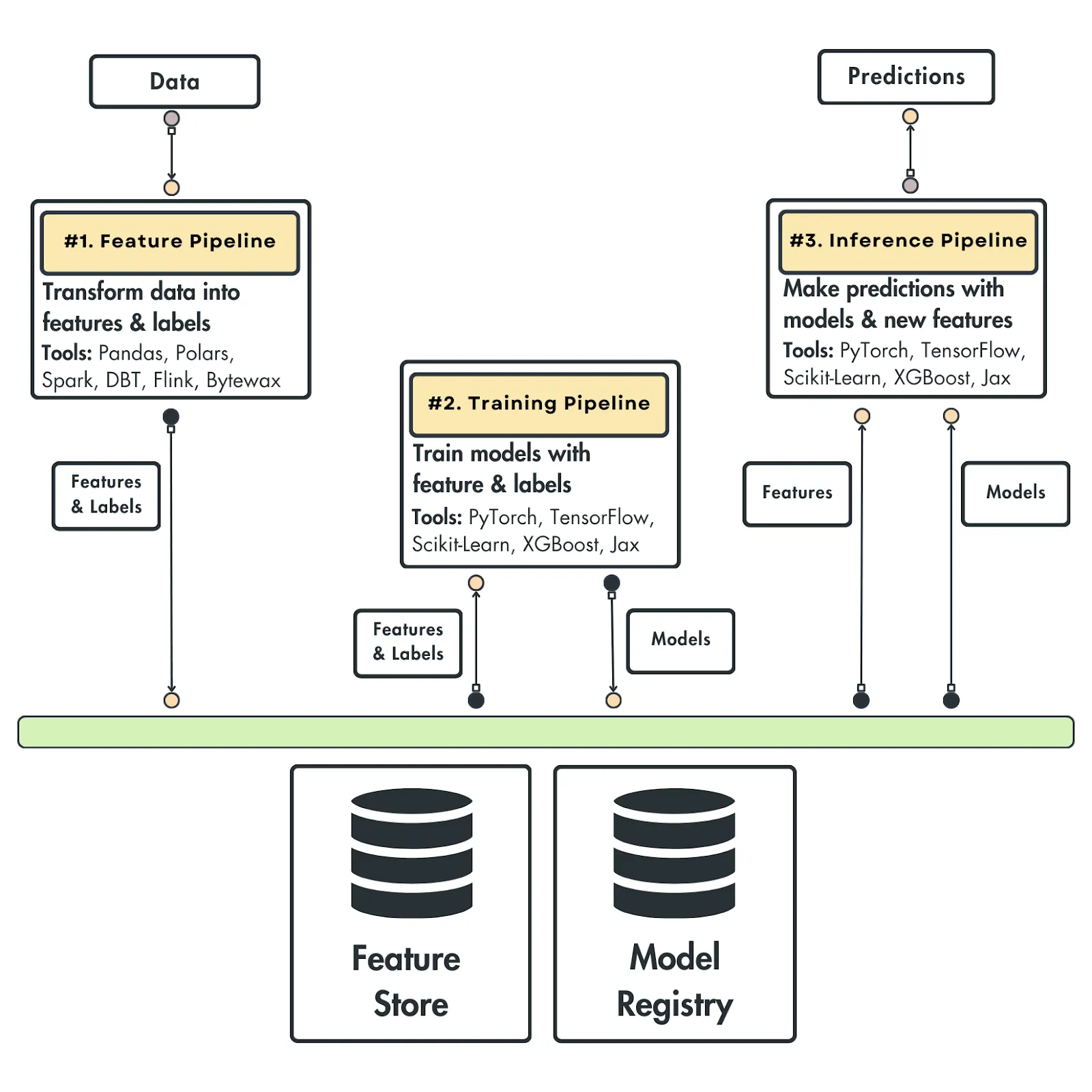
< 1. 특성 파이프라인 (Feature Pipeline) >
- 원시 데이터를 수집하고 필요한 특성과 레이블로 가공
- 이 결과는 특성 저장소(Feature Store)에 저장됨
- 다양한 팀에서 재사용할 수 있는 형태로 구성됨
< 2. 학습 파이프라인 (Training Pipeline) >
- Feature Store에서 특성과 레이블을 불러와 모델 학습을 진행
- 하나 이상의 모델을 생성하고, 이를 모델 레지스트리(Model Registry)에 저장
< 3. 추론 파이프라인 (Inference Pipeline) >
- 입력: 특성, 레이블, 학습된 모델
- 출력: 예측값
- 사용 방식: 배치 또는 실시간 형태
각 파이프라인은 독립적으로 실행 가능한 모듈이며, 각각 다른 팀이 운영하거나 독립적으로 확장/교체할 수 있다.
그리고 저자는 ML 시스템이 아무리 복잡해져도 이 기본 구조는 변하지 않을 것이라고 한다. (저자는 각 파이프라인이 현업에서 보통 어떤 팀이 담당할지도 언급을 한다.)
CH 2. 도구 및 설치
이 장은 개념적 설명보다는 LLM Twin 구축에 필요한 도구 소개와 사전 환경 세팅 가이드에 초점이 맞춰져 있다. 개발 환경을 제대로 구축하는 것은 이 책의 실습을 따라가기에 필수이며, 특히 Python에 익숙하지 않은 독자라면 진입장벽이 다소 높을 수 있다. (사실 이 책 자체가 익숙하지 않는 독자 대상이 아닌 듯 하다.)
참고로 https://github.com/inrap8206/LLM-Engineers-Handbook 에 레포 세팅을 따라가려면 대부분의 API 키 세팅이 필요하니, 해당 장에서 미리 clone 하고 .env.sample 에 맞춰 키세팅을 하는 것을 추천한다.
< Python 환경 세팅 >
pyenv: 다양한 버전의 Python을 손쉽게 설치하고 관리할 수 있는 도구.poetry: 패키지와 의존성 관리를 위한 현대적인 도구.pyproject.toml중심의 구성 파일을 사용하여 환경을 선언적으로 관리한다. python - poetry 설치부터 project initializing, 활용하기 참조poe the poet: poetry의 스크립트 실행 기능을 더 직관적으로 만들어주는 도구. CLI 명령어를 간편하게 정의할 수 있으며, 공식 사이트는 poethepoet.natn.io.- 참고로 프로젝트 세팅할때
poetry self add 'poethepoet[poetry_plugin]'해야 함!
- 참고로 프로젝트 세팅할때
< HuggingFace >
- 모델과 토크나이저를 쉽게 불러올 수 있는 모델 레지스트리 기능을 제공.
- 여러 프로젝트에서 동일한 모델을 재사용하거나 커스터마이징할 때 유용.
< ZenML >
- 오케스트레이터, 아티팩트, 메타데이터 관리 기능을 갖춘 프레임워크.
- ML 워크플로우를 재현 가능하고 구조적으로 설계할 수 있도록 도와준다.
- 핵심은
DAG(Directed Acyclic Graph)기반의 처리. - 비슷한 도구로는 Airflow, Prefect, Metaflow, Dagster 등이 있다.
- ZenML은 특히 실습과 실전 프로젝트 모두에 적합하도록 구성된 모던한 워크플로우 엔진이라는 점에서 강점이 있다.
poetry run poe local-zenml-server-up로 local-server zenml 을 바로 띄울 수 있다.
❯ poetry run poe local-zenml-server-up
Poe <= sys.platform
Poe => poetry run zenml up --blocking
The local ZenML dashboard is about to deploy in a blocking process. You can connect to it using the
'default' username and an empty password.
Deploying a local ZenML server with name 'local'.
Initializing the ZenML global configuration version to 0.67.0
Starting ZenML Server as blocking process... press CTRL+C once to stop it.
INFO: Started server process [97367]
INFO: Waiting for application startup.
Not writing the global configuration to disk in a ZenML server environment.
Not writing the global configuration to disk in a ZenML server environment.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8237 (Press CTRL+C to quit)
INFO: 127.0.0.1:65079 - "GET / HTTP/1.1" 200 OK
< Comet ML >
- 실험 추적을 위한 대표적 SaaS 도구.
- 반복적인 모델 실험을 효율적으로 추적 가능.
- 다음과 같은 지표를 시각화 및 기록:
- 학습 및 평가 손실
- gradient norm (손실 함수에 대한 기울기의 크기)
- 모델 예측 결과 등
< Opik >
- 프롬프트 모니터링 도구로 소개됨.
- 생성형 AI의 성능을 추적하고 품질을 정량화하기 위한 도구로 보임 (자세한 내용은 다소 제한적이지만, 프롬프트 기반 실험을 추적하는 데 활용 가능).
< 데이터 저장 및 처리 도구 >
- MongoDB: 문서 기반의 대표적인 NoSQL 데이터베이스. 비정형 데이터를 유연하게 다룰 수 있음.
- Qdrant: 고성능 벡터 검색 DB. 대규모 임베딩 데이터를 저장하고 빠르게 검색할 수 있는 백터 DB로, RAG 시스템과 궁합이 좋음. (PS. 저자의 말을 빌리자면 요즘 대부분의 성능에서 모난 곳 없이 가장 안정적이라고 한다.)
< AWS 세팅 및 SageMaker 소개 >
- SageMaker는 학습과 추론을 위한 클라우드 기반 ML 플랫폼.
- GPU 클러스터에서 모델을 학습하거나 파인튜닝할 수 있으며, REST API 형태로 배포 가능.
- LLM Twin을 배포할 때, 전 세계 사용자들이 실시간으로 접근 가능하도록 만드는 핵심 인프라 역할을 수행.
PS. 이 장은 진짜 재미있는게 저자의 짬바가 느껴지는 SaaS & PaaS 를 소개해줘서 오히려 좋았다. 그 목적과 이유도 명백해서 더 와닿았고 ㅎㅎ.
CH 3. 데이터 엔지니어링
이 장에서는 LLM Twin 프로젝트의 데이터 수집과 저장 구조, 즉 ETL 파이프라인을 어떻게 설계하고 구현하는지에 대한 전체 그림을 다룬다. MongoDB를 데이터 웨어하우스로 상정하고, 크롤러 → 파이프라인 → 저장의 흐름으로 진행되며, 핵심은 '카테고리 중심 수집 체계'와 'ZenML 기반 자동화'에 있다.
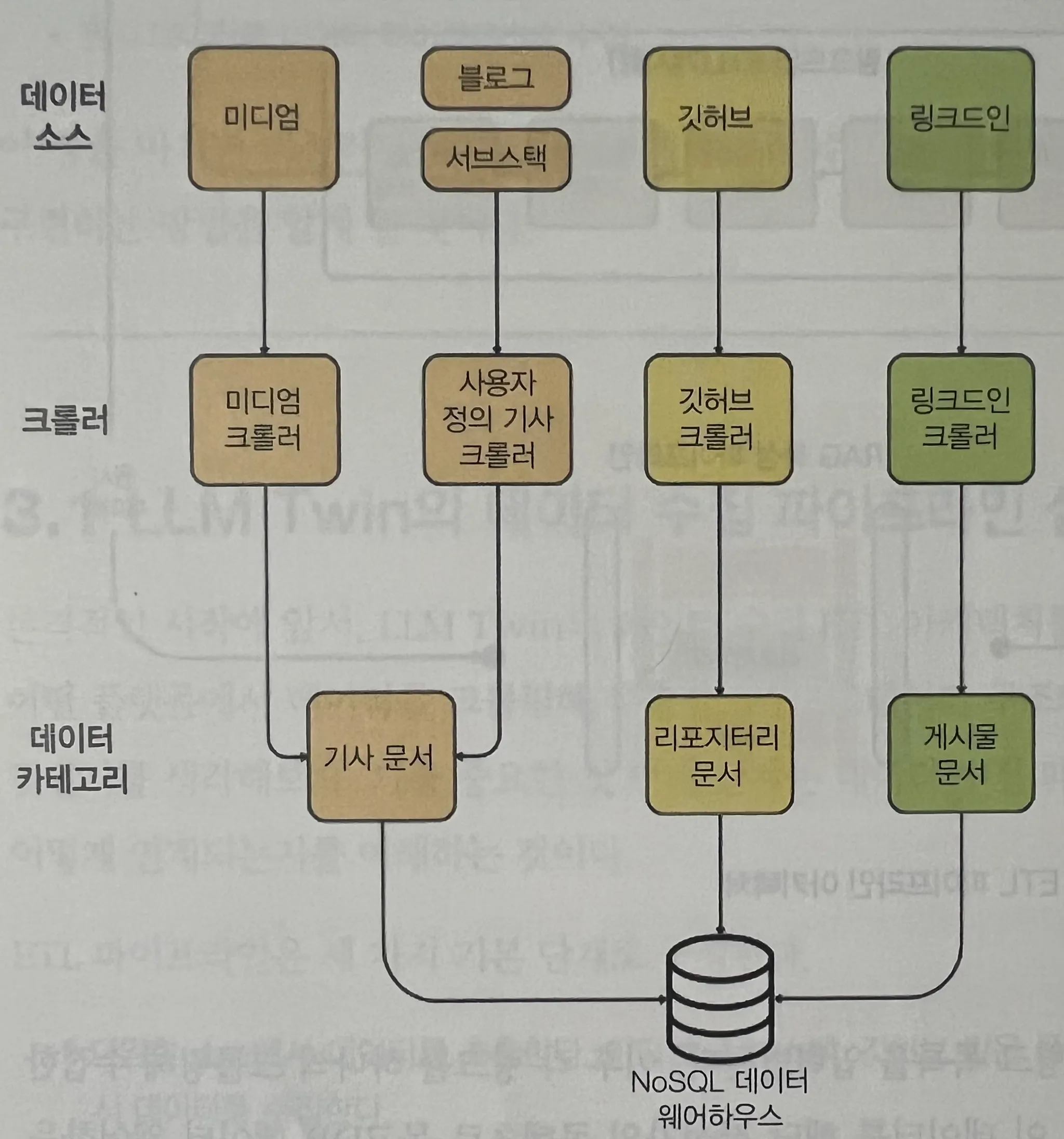
"카테고리" 기반 수집 구조
수집 데이터는 플랫폼 단위로 나누지 않고, 데이터 카테고리에 귀속 시켜 구성한다.
예를 들어 Medium은 ‘아티클’, GitHub은 ‘레포지토리’, LinkedIn 포스트는 ‘게시물’처럼 정의하여 확장성 있는 구조를 만든다.
- PoC에서는 수백 개 단위로 충분할 수 있지만
- 실 운영환경에서는 수천 개 이상의 데이터가 필요하다
- 따라서 '완성도 높은 설계'보다는 '점진적 진화'를 강조한다
이게 특성 파이프라인과 어떻게 연결되는가? -> MongoDB 에 저장된 원시 데이터를 가져와 "특성으로 변환" 하는 후속작업을 통해 Qdrant Vector DB 에 저장할 것이다.
참고로 여기서부턴 http://github.com/inrap8206/LLM-Engineers-Handbook 레포를 보면서 따라오는게 좋다. (clone 을 먼저 하는 것을 추천)
전체적인 구조
ZenML 기반 Pipeline 구조
ZenML 파이프라인 digital_data_etl은 다음과 같은 구조다.
get_or_create_user- 사용자 정보를 생성하거나 조회
- user_full_name, UUID 기준으로 처리
crawl_links- 전달받은 링크들을 기준으로 크롤링 수행
- 링크 리스트는 ZenML step에 입력으로 들어감
이 파이프라인은 완전히 모듈화되어 있고, 입력/출력에 따라 자동으로 MongoDB 에 저장된다. poetry poe run-digital-data-etl 로 실행하면 된다.
poetry run python -m tools.run --run-etl --no-cache --etl-config-filename digital_data_etl_maxime_labonne.yaml
poetry run python -m tools.run --run-etl --no-cache --etl-config-filename digital_data_etl_paul_iusztin.yamldigital_data_etl_maxime_labonne.yaml 과 digital_data_etl_paul_iusztin.yaml 에 설정에 따라 실행되며 아래와 같이 zenml 이 추적된다.
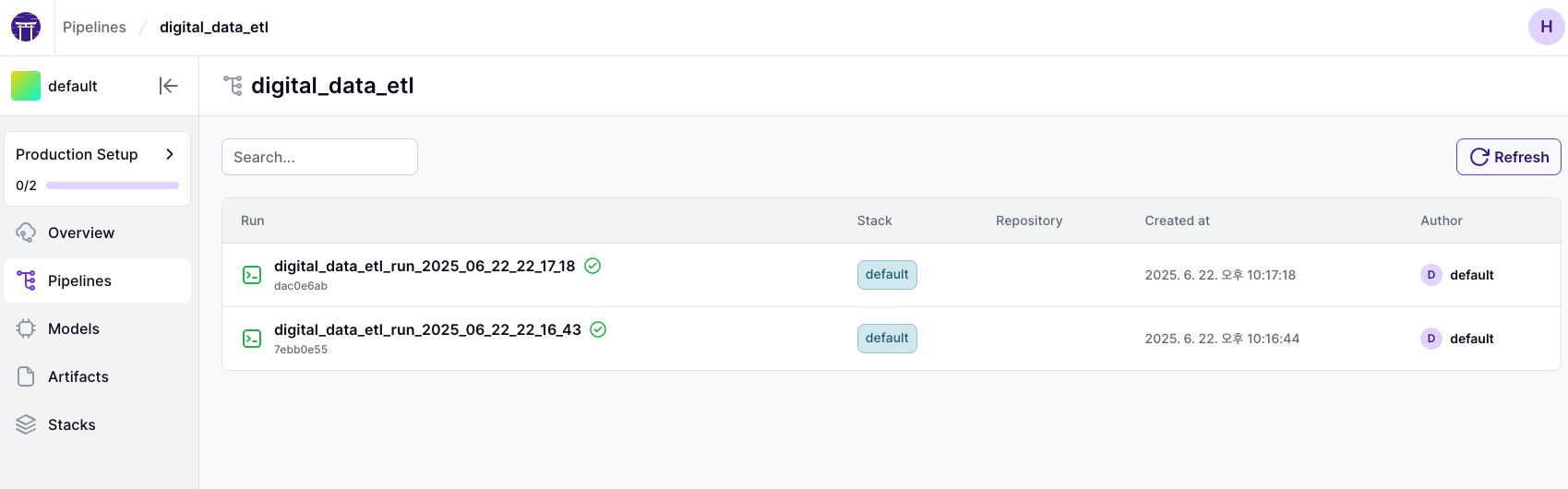
Dispatcher & Registry 패턴
크롤러 로직은 Dispatcher로 관리되며, URL 패턴에 따라 자동으로 적절한 크롤러가 선택된다.
- 예를 들어 아래와 같다.
- https://medium.com/* → MediumCrawler
- https://github.com/* → GithubCrawler
- 기타 → CustomArticleCrawler
이는 내부적으로 _crawlers = {regex_pattern: CrawlerClass} 형태의 Registry를 유지하며, 각 Crawler는 템플릿 메서드 패턴으로 공통 구조를 따르면서도 플랫폼에 특화된 로직을 담는다.
개인적으로 해당 파이프라인은 독자마다 철저하게 커스텀해서 세팅하는 것을 강력 추천한다. 솔직히 "카테고리" 와 "MongoDB" 적재 세팅만 맞추면 파이프라인은 알아서 구성하는 것이 나을 것 같다. 나의 경우
github,velog, 그리고notion을 사용했다. (참고로 처음 읽을땐 그냥 한 번 처음부터 끝까지 따라가보고 난 뒤에 바꿨다.)
(PS. 다른 원천 데이터 셋을 구성하려면, 스크래핑과 크롤링에 익숙하지 않은 사람이라면 해당 장에서 꾀나 애먹을 수 도 있다.)
MongoDB 저장 구조 및 Document 구성
데이터 저장은 twin 이라는 데이터베이스 내 아래 컬렉션들로 구성된다.
users- UserDocument (full_name, id 등)
articles- ArticleDocument (content, link, platform, author_id 등)
posts- PostDocument (content, image, platform 등)
repositories- RepositoryDocument (file tree, name, link 등)
저장 방식은 다음과 같다.
instance.save()→ 단일 문서 저장Model.bulk_insert(docs)→ 다수 문서 저장Model.get_or_create(**kwargs)→ 중복 방지 저장
PS. 깃허브 레포 기준 llm_engineering/domain/base/nosql.py 에 기본 ODM class 를 구현했다. 사실 이 부분에서 이 책은 확실히 진입장벽이 높다고 많이 느겼다. (근데 코드와 다르게 설명은 이제 막 NoSQL 이 뭔지 배운 사람에게 설명하는 듯하다 ㅋㅋㅋ)
이후 poe the poet 로 사전에 세팅된 poe command 로 바로 시작할 수 있다.
CH 4. RAG 특성 파이프라인
개인적으로 이 책의 정수는 4장부터라고 생각된다. 본격적으로 Retrieval-Augmented Generation(RAG)에 대한 구조와 개념이 실제 시스템에 어떻게 구현되는지를 보여주는 장이며, 단순 이론에 그치지 않고 LLM Twin 프로젝트의 구체적인 사례로 연결되는 부분이 핵심이다.
RAG의 개요와 목적
RAG는 이름 그대로 Retrieval(검색), Augmented(증강), Generation(생성)의 세 단계를 조합한 구조다. 모든 LLM은 기본적으로 매개변수화된 지식(parameterized knowledge)에 의존한다. 즉, 사전 학습된 데이터에 기반한 지식을 제공하므로 최신 정보가 반영되지 않거나 사전에 포함되지 않은 정보를 요청하면 할루시네이션(환각) 문제가 발생할 수 있다.
이를 해결하기 위해 외부 정보에 접근할 수 있는 구조가 필요하며, 대표적인 해결책이 RAG다. 특히 금융 비서, 실시간 뉴스 기반 어시스턴트처럼 외부 정보의 실시간 접근이 필수적인 도메인에서는 RAG 구조가 매우 효과적이다.
1. 수집 파이프라이닝
- 데이터 추출 모듈: 다양한 소스(Crawling, DW 등)에서 원시 데이터 수집
- 정제 모듈: 수집된 데이터를 표준화, 정규화, 정제
- 청킹 모듈: 모델 처리 효율성을 위해 작은 단위로 문서 분할
- 임베딩 모듈: 청킹된 문서를 벡터화
- 로딩 모듈: 임베딩 결과와 메타데이터를 함께 Vector DB에 저장
2. 검색 파이프라이닝
- 사용자 입력(텍스트, 이미지 등)을 임베딩
- Vector DB에서 유사한 벡터를 K개 검색 (코사인 거리 등 활용)
- 검색 결과를 LLM 프롬프트에 보강 정보로 삽입
여기서 사용하는 거리 계산법 중 가장 일반적인 것은 코사인 거리이며, 수식은 다음과 같다:
두 벡터 사이 각도의 코사인 값을 1에서 뺀 값이며, -1 에서 1 사이 값을 가진다.(벡터 서로 반대일 때 -1, 수직일 때 0, 같은 방향 1)
3. 생성 파이프라이닝
- 검색된 문서 + 사용자 입력 → 프롬프트로 구성
- LLM에 전달하여 최종 답변 생성
- 프롬프트도 버전 관리가 필요하면
LangFuse같은 도구로 모니터링 및 관리 가능
임베딩
임베딩은 단어, 이미지, 추천 시스템의 항목 등 객체를 연속적인 벡터 공간에 벡터로 인코딩한 밀집된 숫자 표현이다. 의미론적 의미(semantic meaning) 와 의미론적 관계(semantic relationship)를 포착하는데 도움 준다. (ML은 오직 숫자만 처리 가능하다. 왜? 임베딩 필요? 는 skip)
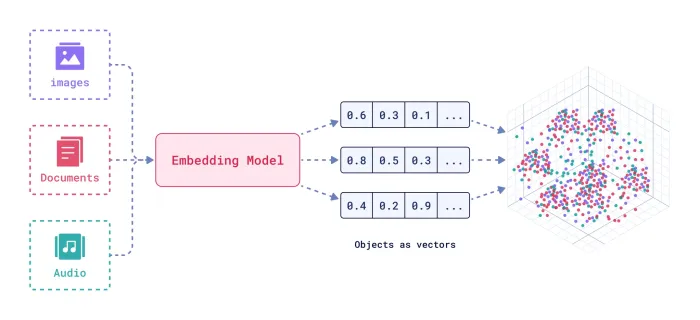
(출처: https://uracle.blog/2025/03/14/embedding/)
- 일반적인 차원: 64 ~ 2048차원
- 시각화 도구: UMAP (사람이 인지하는 2-3차원 보다 훨씬 높기 때문에 시각화 못함. 근데 강제로 3차원으로 축소해서 시각화)
- 초기 기법: Word2Vec, GloVe
- 현대 기법: BERT, RoBERTa,
sentence-transformers(Python) - 벤치마크: HuggingFace의 MTEB
이미지 임베딩은 CNN, 특히 ResNet을 주로 활용하며, 이런 임베딩된 값들을 저장하기 위해 기존 스칼라 기반 DB는 이를 다루기 어려워 Vector DB가 부상하게 됐다. vecotr dbms 대신 FAISS 같은 독립형 벡터 인덱스도 유사도 검색에 효과적이긴 하지만 포괄적인 관리 기능 부족하다.
원-핫 인코딩과 같은 간단한 방법은 왜 안하는가? -> "차원의 저주 문제"가 있다.
텍스트 임베딩 기법으로 Word2Vec, GloVe 등이 초기에 등장했고, 오늘날엔 BERT, RoBERTa 트랜스포머 모델이 유명하다. 더욱이 요즘에 쉽게 임베딩 모델 바로 사용가며, python Sentence Transformers 패키지 같은거 사용해보면 좋다!
PS) 허깅 페이스 MTEB(Massive Text Embedding Benchmark) 통해 임베딩 모델 성능 비교 가능.
Vector DB의 작동 방식 요약
- 임베딩된 입력 쿼리 → Vector DB로 전달
- ANN(Approximate Nearest Neighbor) 방식으로 근접 벡터 검색
- 후처리로 정렬, 필터링 등의 단계 존재
RAG 최적화의 세 단계
- 검색 전처리 (Pre-retrieval)
- 데이터 인섹싱과 쿼리 최적화
- 인덱싱 개선, 쿼리 전처리, 슬라이딩 윈도우, 데이터 세분화 개선 (enhancing data granularity), 메타데이터 구조화, small-to-big, 쿼리 라우팅, 쿼리 재작성, 쿼리 확장 기법 등
- 검색 최적화
- 임베딩 모델 개선 혹은 instructor 모델 활용
- 하이브리드 검색 (필터링 + 벡터 검색)
- 검색 후처리
- 리랭킹, 프롬프트 압축, 필터링 등
정리하자면 RAG는 검색 전처리, 검색, 검색 후처리 세 가지 핵심 단계 개선하는게 중요
LLM Twin에서의 특성 파이프라인 구현
LLM Twin은 DDD(Domain-Driven Design) 원칙을 기반으로, 데이터 흐름과 상태를 명확히 나눈다.
- 데이터 범주: 게시물, 기사, 레포지터리
- 데이터 상태: 정제됨 / 청킹됨 / 임베딩됨
- Pydantic 도메인 엔티티, OVM (VecotrBaseDocument class 참조), 디스패처 계층(핸들러 적용) 와 같이 잘 짜여진 구조얘기도 같이 나온다! 이 부분은 정말 직접 구축할 때 많은 도움이 될 것 같다.
텍스트는 단순히 문자열로 저장됐다고 해서 특성(feature)이 아니며, 모델 입력을 위한 구조화, 즉 토큰화 과정이 반드시 필요하다.
LLM Twin은 배치 기반 파이프라인을 선택하며, 스트리밍 기반은 복잡도 및 실시간성을 요구하는 도메인에 한정해 사용한다. 대표적으로 아래와 같은 구조로 구성된다.
LLM Twin RAG 특성 파이프라인 5단계
- 데이터 추출
- 데이터 정제
- 문서 청킹
- 임베딩
- Vector DB 적재 (Qdrant 활용)
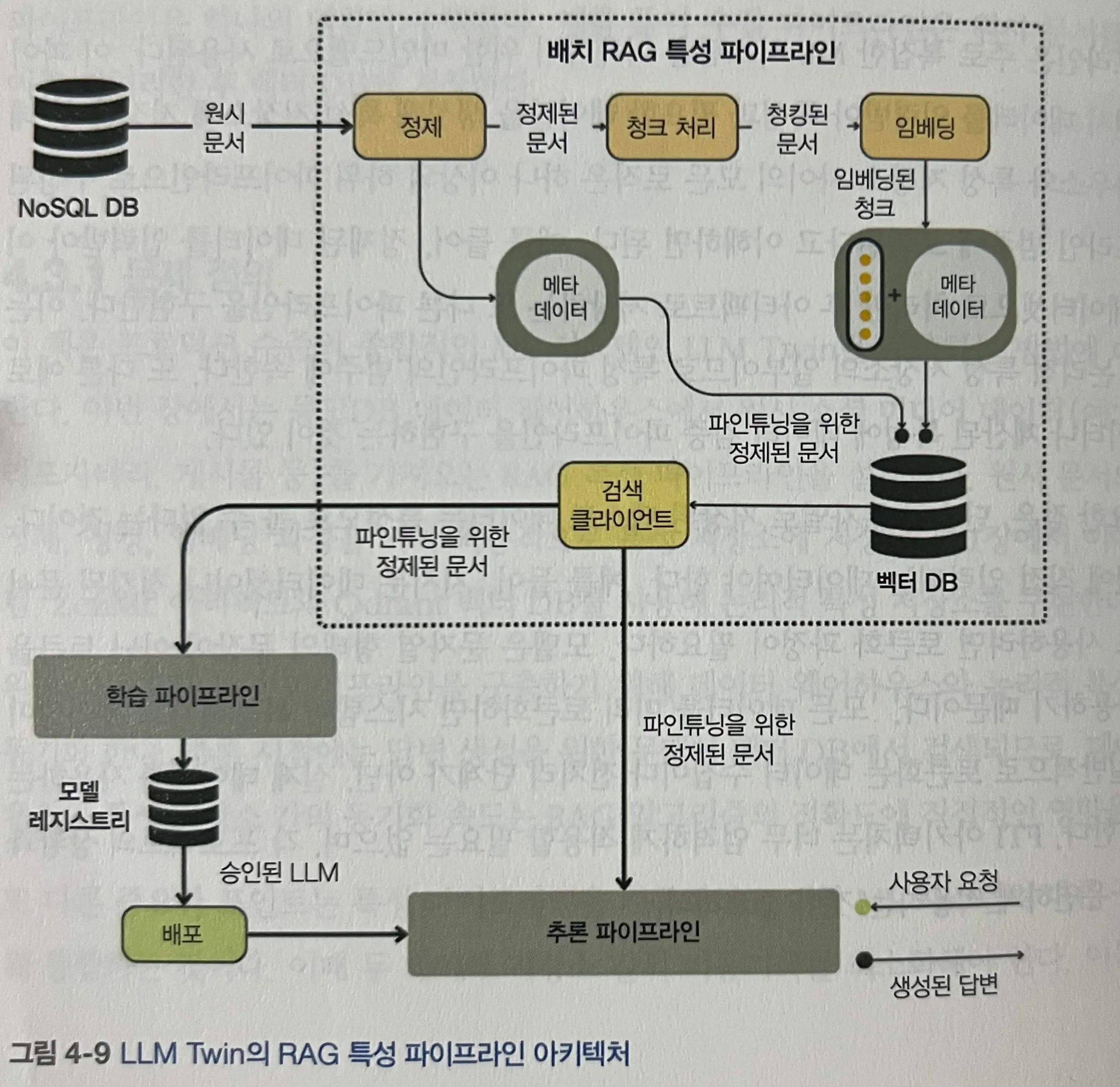
배치 vs 스트리밍 파이프라인
- 배치(Batch) 방식은 데이터를 일정 단위로 모아서 처리하는 형태로, 상대적으로 구현이 단순하고 안정적임.
- 스트리밍(Streaming) 방식은 실시간으로 데이터를 처리해야 하므로 구현 복잡성이 높음.
- 메시징 큐(MQ), 이벤트 기반 아키텍처, 낮은 지연 시간 설계 필요
- 실시간 업데이트가 중요한 틱톡, 소셜 미디어 추천 시스템, 사기 탐지 시스템 등에서 필수적
- LLM Twin에서는 시스템 복잡도를 고려해 배치 방식을 채택함. 즉 배치 방식으로 Qdrant Vecotr DB Upsert 되는 형태.
CDC(Change Data Capture) 활용
- 배치 기반 데이터 처리 후, Qdrant Vector DB에 Upsert 방식으로 적재함.
- 데이터 동기화를 위해 CDC(Change Data Capture) 방식 활용
- CDC 활용 (Elasticsearch - ELK stack & Postgresql & Logstash, query based CDC 만들기 by docker compose / 카프카 클러스터와 파이썬 (2) - Debezium & Postgresql & Django, log based CDC 만들기 (source & sink connector) 참조!)
- 업계에서는 로그 기반 CDC를 더 선호하는 추세 (더 안정적이고 누락 없이 데이터 반영 가능)
두 번의 스냅샷 저장 이유
- 데이터 정제 후 저장 → LLM 파인튜닝에 사용
- 문서 청킹 + 임베딩 후 저장 → RAG 검색용으로 활용
실제 특성 파이프라인 메인 코드
@pipeline
def feature_engineering(author_full_names: list[str], wait_for: str | list[str] | None = None) -> list[str]:
raw_documents = fe_steps.query_data_warehouse(author_full_names, after=wait_for)
cleaned_documents = fe_steps.clean_documents(raw_documents)
last_step_1 = fe_steps.load_to_vector_db(cleaned_documents)
embedded_documents = fe_steps.chunk_and_embed(cleaned_documents)
last_step_2 = fe_steps.load_to_vector_db(embedded_documents)
return [last_step_1.invocation_id, last_step_2.invocation_id]위 코드에서는 청크 전/후 데이터를 구분하여 각각 Vector DB에 적재한다. 병렬성 확보를 위해 GIL 제약을 피하고, 각 fetch 함수는 ThreadPoolExecutor 기반으로 실한다.
전체 파이프라인은 poetry poe run-feature-engineering-pipeline 명령어로 실행 가능 하다.
CH 5. 지도 학습 파인튜닝
LLM을 실제 응용 프로그램에 효과적으로 적용하기 위한 핵심 과정이 바로 지도 학습 기반 파인튜닝(SFT) 이다. 사전학습된 모델이 언어 일반 능력을 갖추고 있다면, SFT는 여기에 실전 적합성을 더해주는 역할을 한다. 즉, "일반적인 언어 이해"와 "실전 문제 해결 능력"의 간극을 메우는 것이 SFT의 목적이다.
이 장은 크게 세 부분으로 나뉜다. 1) 지시문 데이터셋 생성, 2) SFT 기법, 3) 파인튜닝 구현이다.
지시문 데이터셋: 파인튜닝에서 가장 어려운 부분
지도 학습 파인튜닝은 기본적으로 자연스러운 지시문-응답(instruction-response) 쌍이 필요하다. 하지만 원시 텍스트를 이러한 구조로 전환하는 것은 쉽지 않다.
이 과정은 거의 노가다 수준의 수작업이 필요하고, 무엇보다 데이터 품질이 매우 중요하다.
- Open-Orca/SlimOrca (https://huggingface.co/datasets/Open-Orca/SlimOrca) 와 같은 오픈 데이터셋은 좋은 참고 예시이다.
- LIMA (Less Is More for Alignment) 논문에 따르면, 700억 파라미터 모델도 고품질 데이터 샘플 1,000개만으로도 효과적으로 튜닝 가능하다.
SFT 목적에 따른 모델 유형
파인튜닝 주요 목적은 "작업 특화 모델" 과 "도메인 특화 모델" 을 개발하는 것이다.
-
작업 특화 모델(Task-specialized Model)
번역, 요약, 감정 분석 등 특정 작업에 최적화
→ 작은 모델(8B 이하)도 효율적 -
도메인 특화 모델(Domain-specialized Model)
의료, 법률, 금융, 엔지니어링 등 특정 분야 용어와 언어 패턴 학습
→ 도메인 복잡성에 따라 난이도 매우 상이
규칙 기반 필터링 기법
데이터 품질 관리를 위한 체계적인 방식
- 길이 필터링: 너무 짧거나 긴 응답 제외
- 키워드 필터링: 저품질 키워드 포함 여부로 제거
- 형식 검사: JSON, 코드 예제 등 구조 일관성 유지
- 중복 제거:
- 정확 중복
- 퍼지(Fuzzy) 중복 (MinHash 등)
- 의미론적 유사도 기반 중복 제거 (밀집 벡터 - Dense Vector 기반 등)
과적합을 방지하기 위해 유사 샘플 제거는 반드시 필요하다.
데이터 품질 평가와 자동화 방안
수작업은 시간과 비용이 많이 들기 때문에, 최근에는 LLM을 평가자로 삼거나, 보상 모델, 분류기 기반 예측 모델 등을 사용하는 방식이 시도되고 있다.
- 참고: ArmoRM-Llama3-8B-v0.1의 보상 모델 기반 아키텍처
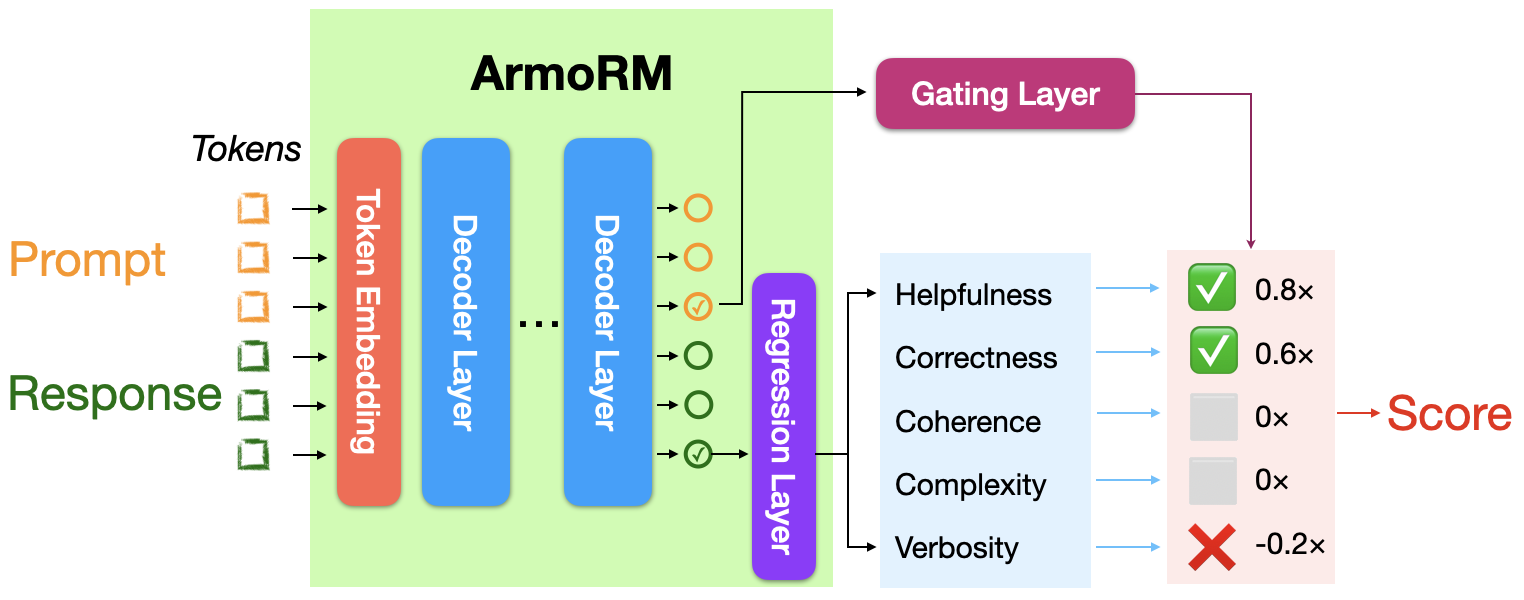
LM Twin에서의 실제 적용
3장에서는 크롤링한 데이터를 기반으로 지시문 데이터셋을 자체 생성한다. → 여기엔 두 가지 큰 난제가 존재
- 크롤링 데이터의 비정형성
- 크롤링 가능한 기사 수의 한계
이를 해결하기 위해 합성 데이터 생성 파이프라인을 구성한다.
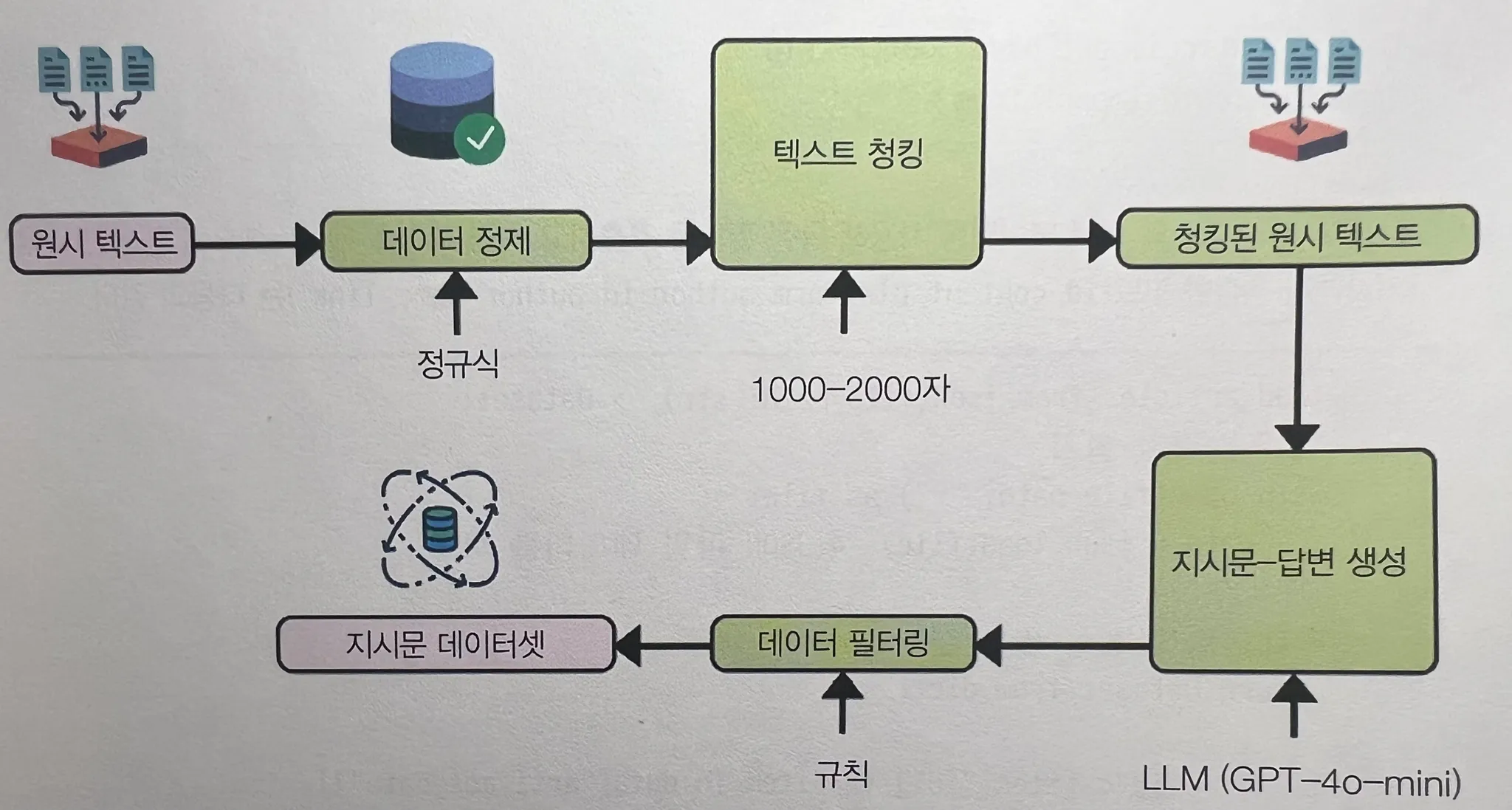
위 그림과 같이 원시 텍스트에서 지시문 데이터셋으로 합성 데이터 생성 파이프라인을 만들 수 있다. (실제 python 코드 예시가 이어진다.)
지시문 템플릿 구조화
지시문-응답 쌍은 모델별로 템플릿이 조금씩 다르다. 예를 들어 OpenAI GPT 계열과 HuggingFace 기반 모델은 프롬프트 구조가 다를 수 있다.
<|im_start|>system
당신은 유용한 AI 도우미입니다.
<|im_end|>
<|im_start|>user
토끼와 거북이 이야기를 요약해줘.
<|im_end|>
<|im_start|>assistant
거북이가 느리지만 꾸준히 가서 결국 토끼를 이깁니다.
<|im_end|>SFT 기법 세 가지
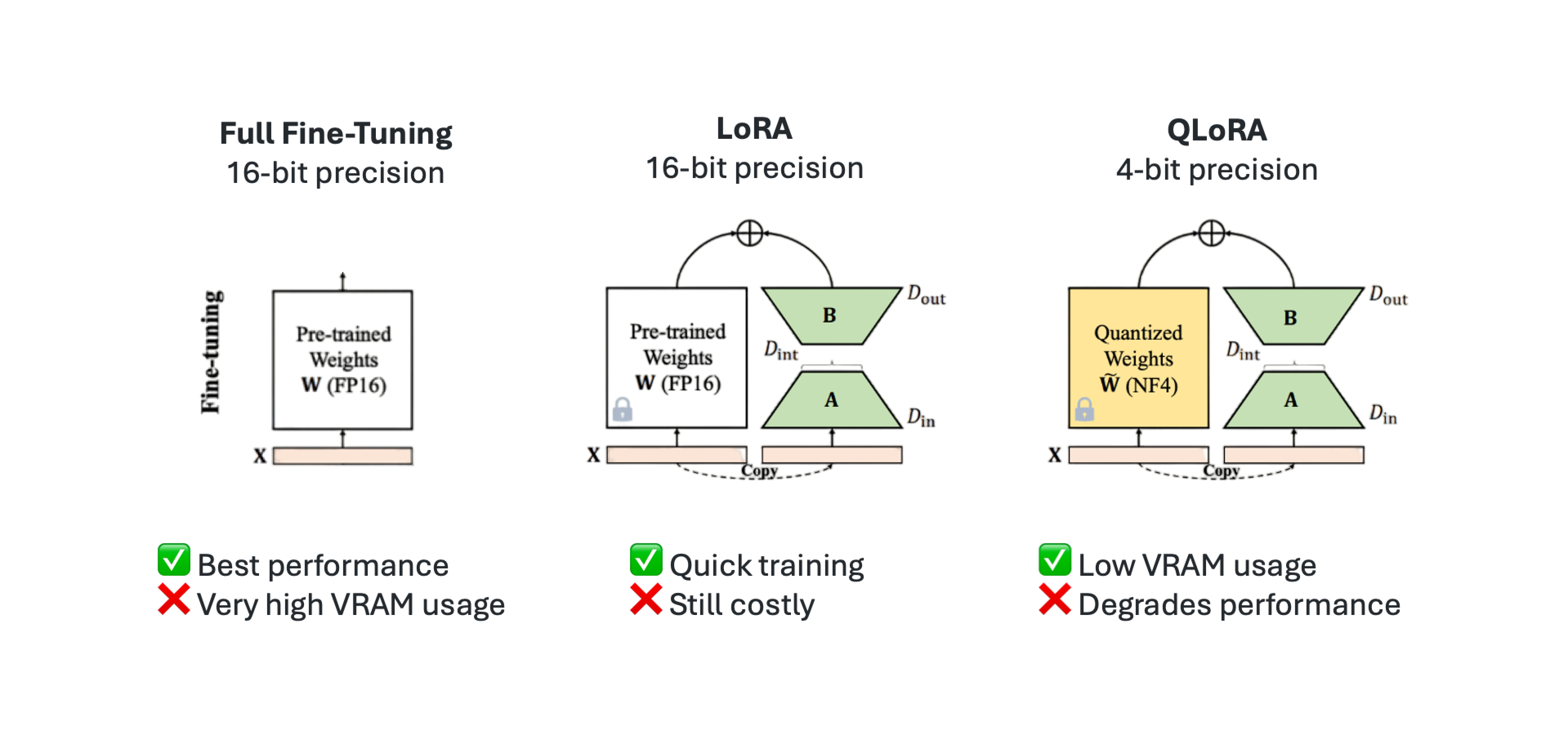
(출처: https://huggingface.co/blog/mlabonne/sft-llama3)
- 전체 파인튜닝: 모든 파라미터를 다시 학습
- LoRA (Low-Rank Adaptation):
- 학습 가능한 저랭크 행렬 도입
- 메모리 사용량 감소 / 빠른 학습 / 파괴 없는 튜닝
- 작업 간 빠른 전환 가능
- QLoRA:
- LoRA + 양자화(quantization) 기법
- NF4 (4비트 커스텀 데이터 타입) 활용 → 소형 GPU에서도 학습 가능
학습 하이퍼파라미터 구성
학습 품질을 좌우하는 핵심 요소들
- 학습률 & 스케줄러
- 배치 크기 (Batch Size)
- 최대 시퀀스 길이 & 패킹 전략
- 에포크 수 (Epochs)
- 옵티마이저 선택 (AdamW 등)
- 가중치 감소(Weight Decay)
- 그레디언트 체크포인팅 (Gradient Checkpointing)
이후 장에서는 실제로 SFT 학습 코드 예시와 함께 실습이 이어진다. 이 장은 실제 SFT의 이론부터 실전 구현까지를 아우르는, 모델을 현실의 문제 해결 도구로 전환하는 과정의 핵심이다.
이후 CH 6 ~ 11 ...
책이 양이 엄청 방대하기에 이후 장은 핵심 주제에 대해서만 요약하고자 한다. 총 평에서 언급했듯 LLM 에 관심이 있다면, 해당 책 정도는 꼭 한 번 찍먹이라도 하면 도움이 많이 될 것 같다.
CH 6 선호도 정렬을 활용한 파인튜닝
- 단순한 SFT(Supervised Fine-Tuning)를 넘어서, DPO(Direct Preference Optimization) 같은 선호도 기반 학습 기법에 대한 얘기.
CH 7 LLM 평가, 모델 평가, RAG 평가, TwinLlama-3.1-8B 평가
- 모델의 성능은 정량 지표만으로는 절대 충분하지 않다는 것을 강조한다. 특히 RAG 시스템이나 커스텀 모델에서는, 단순 BLEU, ROUGE와 같은 전통적 자연어 지표보다 '실제 문제 해결 능력'이 훨씬 중요해진다.
- 이 챕터에서는 모델 평가, RAG 평가, TwinLlama-3.1-8B 모델 평가까지 다루며, 성능 지표와 주관적 평가의 균형을 어떻게 잡을 것인지에 대해 말한다. 개인적으로 기대했던 도메인 특화 파인튜닝에 대한 구체적 평가 방안은 부족했지만, 지표 설계 자체를 실험적으로 풀어내는 의도가 담겨 있었다.
CH 8 추론 최적화, 모델 최적화 전략, 병렬 처리, 양자화
- 모델 최적화 전략: 레이턴시 감소, 메모리 효율성 증대 / key value 캐싱
- 병렬 처리: multi-GPU 환경과 tensor 병렬, pipeline 병렬 등 다양한 방법론 소개
- 양자화: 특히 최근 논의가 활발한 int4, int8 양자화를 활용한 경량화 접근이 구체적으로 설명된다.
CH 9 RAG 추론 파이프라인, LLM Twin의 RAG 추론 파이프라인과 RAG 기법, 구현
CH 10 추론 파이프라인 배포, 모놀리식 & MSA, 오토스케일링
CHAPTER 11 DevOps, MLOps, LLMOps, LLM Twin 파이프라인을 클라우드에 배포와 LLMOps 적용기
- DevOps: CI/CD 기반 배포 자동화
- MLOps: 실험 추적, 모델 버전 관리, 재현성 보장
- LLMOps: 프롬프트 버전 관리, 벡터 인덱스 동기화, 쿼리 추적 등 LLM 기반 시스템에 특화된 운영 전략
- "운영 가능한 시스템"을 만들기 위한 최소한의 규칙을 지켜야 한다. 특히 클라우드에 올릴 때 발생하는 문제들, 실험 결과를 롤백하거나 재현해야 할 때의 장애 포인트들을 미리 체크해볼 수 있다.
