
사진 찍는것을 좋아하는 저에게 흥미있는 논문이 있어 읽어봤습니다. 제목처럼 어둠속을 보는 방법을 배우는데요, 극악의 저조도 환경에서 얻어진 RAW데이터를 기반으로 이를 밝게 만들어주는 방법을 제시한 논문입니다. 결과물을보면 이게 말이되나 싶을정도로 어두운 이미지였는데, 논문이 제시한 방법을 통해 개선됩니다.
1. Abstract
- 저조도 환경에서 Imaging(사진, 동영상촬영)은 적은 광자의 수와, 낮은 SNR(Signal to Noise ratio, 신호대 잡음 비)때문에 힘들다.
- 저조도 환경에서 short-exposure(셔터스피드를 빠르게한) image는 노이즈가 심하고, 반면에 long-exposure을 해도 blur를 야기할수 있습니다. 사진을 찍어보신 분들이면 아실껍니다, 손떨림을 잡기위해 셔속을 높히자니 사진이 어두워지고, 노이즈가 끼고, 셔속을 낮추면 사진은 밝아지나 손떨림, 피사체의 움직임때문에 원하는 사진이 나오지 않습니다.
- 저자들은 새로운 데이터셋을 만들고 이를통해 문제를 해결하려합니다.
- 데이터셋은 저조도의 short-exposure이미지와 그에 반대되는 같은구도, 같은 피사체의 long-exposure이미지로 구성됩니다.
- 또한 논문에서 제시하는 모델은 RAW데이터를 직접 처리하는것을 목적으로합니다.
2. Introduction
- 노이즈는 어떤 이미징 시스템에나 존재한다, 하지만 저조도에서는 더욱 심하다.
- ISO를 높히면 센서의 민감도를 올려 밝기는 올릴수 있겠지만 노이즈가 더욱 심해진다. 이외에도 다른 후보정방법, 히스토그램 스트레칭이나.. 이런걸 시도할수 있겠지만 근본적으로 낮은 SNR을 해결할수는 없다.
- 사실 물리적으로 사진의 밝기를 조절할수 있다, 카메라를 사면 가장먼저 배우는 셔터스피드, ISO, 조리개값 등을 조절해서 물리적으로 사진의 밝기를 조절할 수 있지만 이런 방법들 모두 단점이 존재한다, 위에서 말했듯이 셔터스피드를 느리게하면 밝기는 높힐수 있지만 셔터가 열렸다 다시 닫히는동안 손떨림, 피사체의 움직임 때문에 blur(흔들림)가 있는 사진이 나올 확률이 높다.
- 이와관련해서 저조도의 이미지들을 개선하는 방법들이 발표되었지만, 이는 이미지가 그래도 적당한 불빛은 받았을 때 얘기다, 본 논문은 극도로 제한된 밝기에서의 이미징을 다루고, short exposure상황에 관심을 가진다(비디오 rate에 적절한 short exposure)
아마 저자들은 동영상에 이 연구를 접목하길 원하는것 같았다.
사진을 보면 소니 7S2로, 0.1 lux 미만의 광량에서, 셔터스피드 1/30으로 찍은 사진이다.
(a)는 ISO 8000으로 찍었고 아무것도 안보인다.
(b)는 ISO 409600으로 찍었고 물체가 보이나 노이즈가 심각하다, 사실 저정도 ISO는 중급자 라인의 모델까지에서 지원되지 않는 ISO이고 7S2정도나 되야 지원하는 ISO이다. 위에서 설명했다싶이 밝기는 올라갔지만 노이즈가 심함을 알수있다.
(c)는 논문에서 제안하는 방법을 통해 raw데이터를 처리한 결과이다. 밝기도 (b)에 비해 밝고, 노이즈도 적음을 확실하게 느낄수 있다.
SOTA방법도 저렇게 노이즈를 제거하지 못하고 color-bias문제를 해결할수는 없다. - ISO를 높히고, 조리개, 셔터스피드를 조절하는 것 말고 다른 대안은 연사(burst of images)이다, 레퍼런스를 살펴봐야겠지만 내가 아는 연사는 밝기를 다르게 찍은 사진을 합성해서 저조도에서도 밝은 결과물을 얻어내는 것이지만 이또한 극심한 저조도 환경에서는 어렵고, 무엇보다 동영상 촬영에는 연사가 사용될수 없다.
3. Related Work
a. Image denoising
- 이미지 denoising은 low-level vision에서는 연구가 잘 된 토픽이다.
- 다양한 방법이 있고 그중 BM3D(?)라는 방법이 가장 효과적이였던 것 같다.
- 하지만 기존의 방법들은 모두 synthetic data에서 평가되었다, 진짜 실생활의 noise가 아닌 인위적으로 추가한 가우시안 노이즈나 salt&pepper noise를 denoising 한 것이였다.
- 저자들에 따르면 최근 연구에 따르면 BM3D가 최근의 기법을 outperform한다.
- single image denoising말고 multiple image denoising이라는 것도 있다. 결과는 여러장의 이미지를 사용하는편이 좋다.
b. Low light image enhancement
- 다양한 기법들이 저조도 이미지의 contrast(대조)를 향상시키기 위해 사용되고있다.
- 그중 가장 클래식한 방법이 histogram equalization이다.
- 또다른 유명한 방법은 gamma correction이다
- 하지만 이러한 방법들은 이미지가 이미 괜찮은 환경에서 찍혔다고 가정한다.
- 우리연구에서는 극심한 저조도의 이미징을 다룰것이다.
c. Noisy image datasets
- 대부분 현존하는 기법들은 synthetic data에 대해서 평가된다. 예를들어 멀쩡한 이미지에 가우시안 노이즈를 입히고 이를 제거시킨다.
- 저자들이 알기로는 그 당시에 raw형식의 저조도 이미지와 그에 상응하는 정답 이미지를 포함한 공개된 dataset이 없었다.
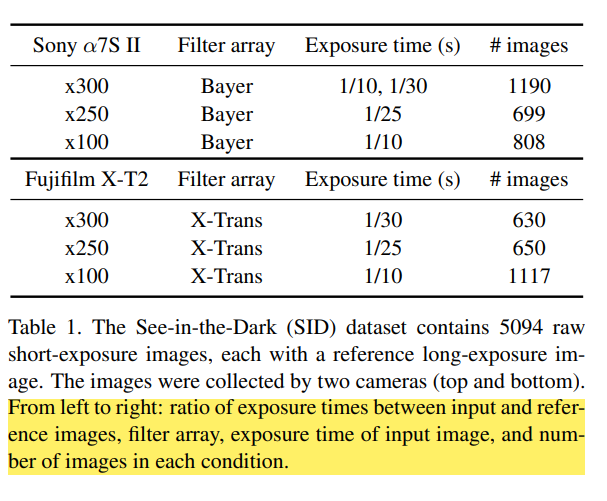
저자들이 만들어서 제공한 데이터셋이다. 일단 소니카메라와 후지필름의 카메라로 촬영했다. 두가지로 나눈 이유는 두 카메라들의 센서 구조가 다르다.
TMI로 블로그 주인장인 나는 후지필름의 X-T30을 사용하고있다...(그래서 이 논문이 더욱 흥미로웠다...)
표에 대한 설명은 하이라이트 친 부분을 읽으면된다.
4. See-in-the-Dark Dataset (SID)
이 논문이 갖는 가장 중요한 의미 같습니다. 뒷부분에 가면 모델도 U-net기반에 특별한게 없는데 기존에 없는 데이터셋을 사용해서 확실한 저조도이미지의 품질 향상을 얻어낸것 같습니다.
- 저자들은 새로운 dataset을 만들었고 이는 5094개의 raw 형식의 short-exposure image들이고 이런 각각의 이미지에 상응하는 long-exposure image가 존재한다.
- 알아둬야 할 것은 복수의 short-exposure image들이 상응하는 이미지로 동일한 long-exposure image를 갖는다. 이는 저자들이 burst denoising method를 실험하기 위해 short exposure로 연사를 했는데 이런 경우 연사될때 찍힌 이미지들의 상응하는 GT이미지는 하나다.
- 따라서 distinct한 long exposure reference image는 데이터셋에 총 424개가 있다.
- 데이터셋은 실내, 실외 이미지들을 모두 포함하고 있고, 실외 이미지의 광량은 0.2 ~ 5lux 사이고, 실내 이미지는 보통 0.03 ~ 0.3lux 사이이다.
- 20퍼센트를 test set으로 사용하고, 나머지 10퍼센트를 validation으로 사용한다.
- 위에서 말했듯이 소니, 후지필름 카메라로 찍었고 소니는 풀프레임 bayer센서이고, 후지는 APS-C X-Trans sensor다.
- 소니로 찍은 이미지의 화소는 4240 2832이고 후지는 6000 4000이다, 소니 카메라로 찍은 경우는 두개의 다른 렌즈를 이용해서 찍었다.
- 사실 long expousre 이미지도 여전히 노이즈가 있지만, Ground truth로 쓰기에 충분한 품질이다.
5. Method
a. Pipeline
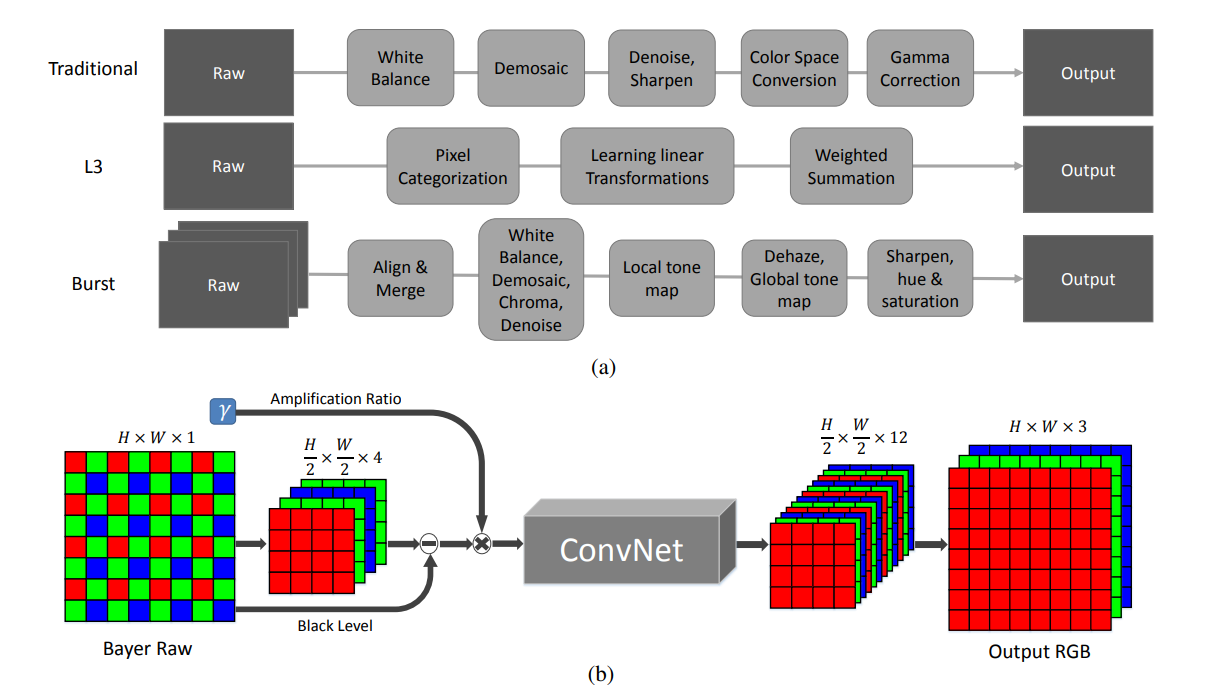
- 전통적인 파이프라인에서는 이미지 센서로부터 raw 데이터를 받고 화이트밸런스, 디노이징, 샤프닝 등의 작업을 걸쳤다. (위의 Traditional)
- 그리고 L3방식은 modern consumer imaging system에 사용되고 있다.
- 하지만 위의 두 방법 모두 저조도에서 short exposure로 찍은 이미지를 잘 처리하지 못한다.
- Burst는 스마트폰을 위한 연사 pipeline인데 복잡하긴하지만 좋은 결과물을 낼수 있다. 하지만 동영상에 쉽게 적용될수는 없다.
- 저자들은 fully-convolutional-network를 이용한 end to end learning을 제안한다.
다시한번 중요한점은 sRGB 이미지를 처리하는게 아니라 raw 데이터를 이용하여 처리한다.
파이프라인은 위 이미지의 (b)를 참고하면 된다. - 저자들은 중간의 ConvNet에 Unet을 이용했다. Unet을 이용하게 된 계기는 원 논문을 참고하면된다. 속도, 메모리 용량등을 고려한거같다.
b. Training
- 네트워크(U-net)을 처음부터 학습시켰고, L1 loss와 Adam optimizer를 이용했다.
- 네트워크의 입력은 short exposure로 얻어진 raw data과 sRGB형식의 long exposure image(ground truht)이미지이다.
- 소니카메라와 후지필름 카메라의 센서가 근본적으로 다르기 때문에 카메라마다 네트워크를 따로 학습시켰다.
- iter마다 이미지를 랜덤하게 512 by 512로 크롭하여 트레이닝했고 그리고 flipping, rotation을 사용하여 data augmentation을 진행했다.
- 초기 lr값은 이고 2000에포크 이후에는 로 하였고, 4000에포크 학습시켰다.
6. Experiments
자세한 내용은 원 논문을 참고해주세요
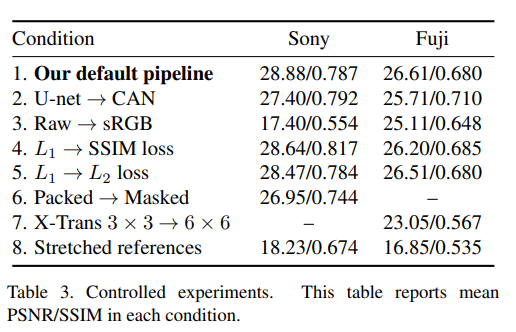
- 저자들은 네트워크의 구조, 다양한 loss로 실험했고
- 기존의 파이프라인, BM3D의 방법과 자신들의 파이프라인을 비교했습니다.




느낀점
- 사진을 찍는입장에서 마술과 가까운 파이프라인임.
- 하지만 raw파일을 처리하기 때문에 고용량 데이터를 다루는만큼 촬영기기에서 연산이 가능한지가 중요할 것
- 새로운 데이터셋을 만든 것이 큰 의미를 갖는 것 같다.
- 몇몇 이미지를 보면 너무 과하게 밝아진 느낌도 있다.
- 저자들은 이를 동영상에 적용하려 하는 것 같다. 프레임 방어가 가능하다면 군용 나이트비전, 드론의 야간정찰 등에 활용될 수 있을 것 같다.

시원한 맥주, 음악, 야구, 사진찍기를 좋아합니다.