1. Abstract
SISR분야에서 정확도와 속도에서 큰 진전이 있었음에도 한가지 풀리지 않은 중요한 문제가 있다.
어떻게하면 large upscaling factors를 사용한 작업에서 더 정교한 질감을 복원할수 있을까?
optimization based super resolution 방법의 behavior(행동, 특징)은 원칙적으로 목적함수에 의해 결정된다. 최근의 연구는 MSE기반의 로스를 줄이는 것에 목적을 두고있고, 이는 높은 PSNR을 얻어내는 것이 목적이다. 하지만 이런 MSE기반의 연구들은 주로 섬세한 질감의 부족하고 시각적으로 만족스럽지 않다.
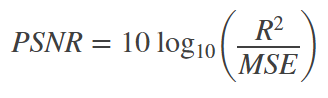
이번 논문을 통해 SRGAN을 제시한다.
SRGAN을 통해 기존의 MSE기반의 로스가 아닌 perceptual loss를 제안한다. 이는 adversarial loss와 content loss로 이루어져있다.
Adversarial loss는 실제 이미지와 같은 이미지를 생성하게 도와주고, content loss는 픽셀공간에서의 similarity가 아닌 perceptual similarity(feature map)에 영향을 받는다.
2. Introduction
supervised SR 알고리즘의 최적화 대상은 일반적으로 생성된 고해상도 이미지와 정답(GT, ground truth)의 MSE를 최소화 시키는 것이다. 위에서 말했듯이 MSE를 최소화 하는 것은 PSNR을 최대화 하는 것이다. 하지만 MSE를 최적화 시키는 방법은 높은 질감의(high texture) 디테일과 같은 시각적(지각적)으로 관련있는 차이를 잡아내는 부분에 있어서는 한계가 있다. 왜냐면 MSE기반의 loss function은 픽셀기반이기 때문이다. 그리고 높은 PSNR이 시각적으로 뛰어난 SR 결과를 보장하지 않는다.

우리가 제안하는 SRGAN은 residual network를 채용했고 우리는 VGG network의 high-level feature map을 이용한 perceptual loss를 정의했다.
2.1 Related work - loss function
MSE와 같은 픽셀기반의 loss function은 텍스쳐와 같은 high frequency details을 잃어버린채 복원하는 내제된 불확실성이 있다. 그리고 전반적으로 MSE기반의 SR결과물은 너무 smooth한 느낌이다, 샤픈이 부족하다. 이는 MSE를 최소화 시키는 작업이 그럴듯한 솔루션 들의 평균을 찾아내는 것이기 때문이다. 아래 사진을 통해 이해할 수 있다.
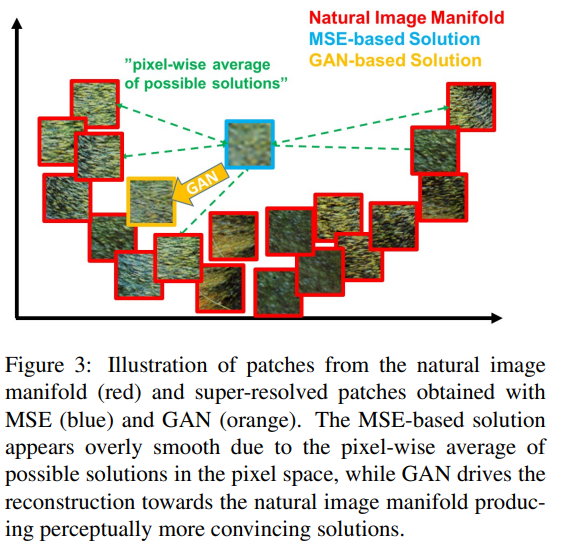
특정 이미지의 부분에 대한 매니폴드가 존재하는데 MSE를 최소화 시키면 저런 매니폴드의 결과물들에 대한 평균을 내서 뿌연 느낌의 smooth한 이미지를 결과로 얻게된다. 하지만 GAN기반의 SR방법은(본 논문) 매니폴드에 존재할법한 이미지를 얻어낸다.
2.2 Contribution
3가지 contribution을 했다.
1. 4x upscaling factor에서 PNSR과 SSIM 부분에서 16 block 의 SRResNet으로 SOTA를 달성함. (MSE 기반)
2. GAN기반의 SRGAN제안, 여기서 MSE기반의 loss를 VGG network에서 뽑은 feature map기반의 perceptual loss로 대체함
3. MOS라는 새로운 평가기준에서 SRGAN이 큰 차이로 SOTA달성
3. Method
SISR(Single Image Super Resolution)은 주어진 저해상도 이미지의 고해상도 이미지를 예측하는데 목적을 두고있다.
: High Resolution Image(Ground truth)
: Low Resolution Image 에 가우시안 필터를 적용하고 다운샘플링을해서 얻어진다.
: Super Resolution Image, 를 입력으로 받은 네트워크에 의해 만들어지는 결과물
연구의 목표는 (생성자 네트워크 에 의해 parameterized)가 실제 과 정말 비슷한 를 만드는 것 입니다.
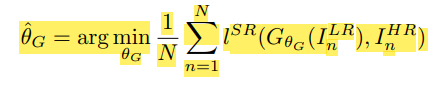
크게본다면 이렇게됨.
3.1 Adversarial network architecture
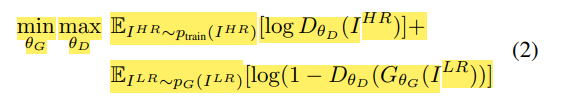
이때 는 판별자이고 는 파라미터
GAN의 min-max problem을 그대로 이용. G는 D를 속이는 것이 목적이고, D는 판별하는 것이 목적.
가 를 입력받아 과 최대한 동일한 이미지인 이미지를 생성하려하고, 는 과 를 구별함을 통해 G에게 더 스러운 이미지를 만들게함.
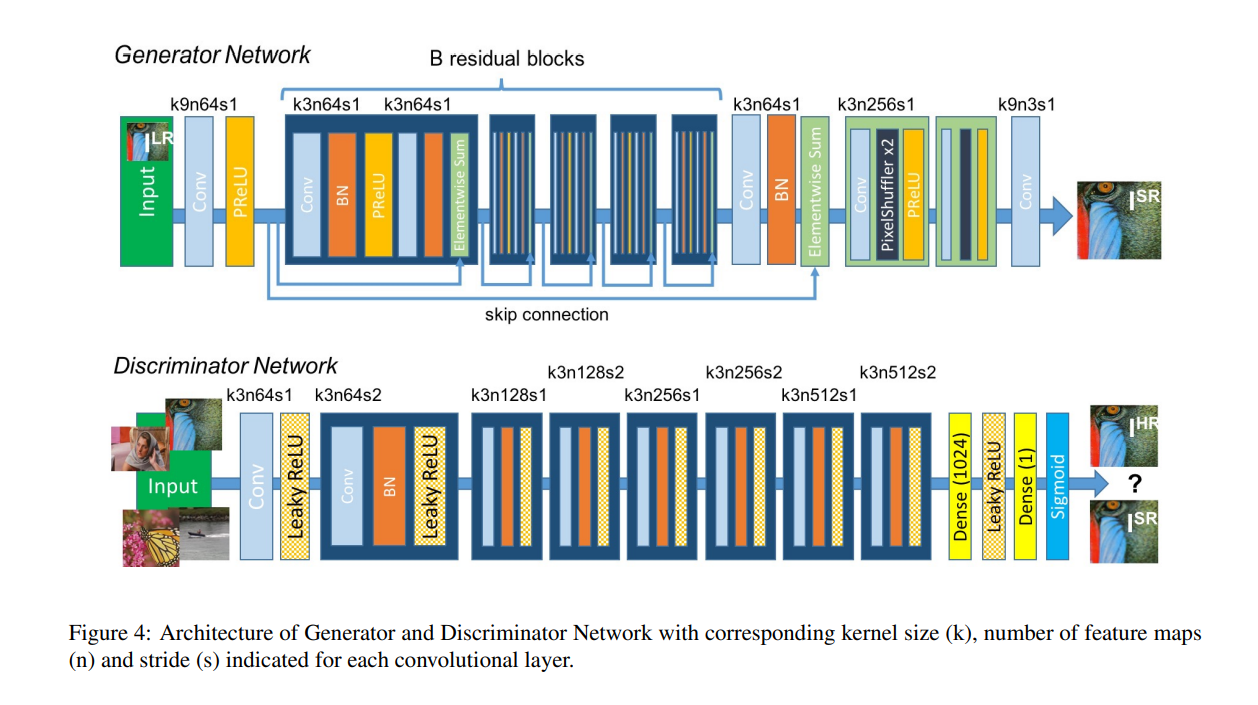
네트워크 구조는 위와같다. 실험에서 B는 16임. skip connection을 통해 resdiual network를 구현했다.
3.2 Perceptual loss function
논문에서 contribution으로 말한 perceptual loss function은 다음과 같다.
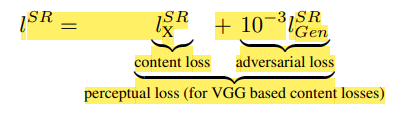
3.3 Content loss
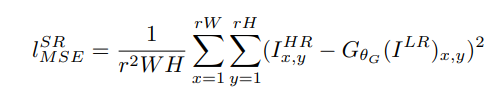
MSE기반의 pixel-wise loss function이고 기존 방법은 위의 loss를 사용했다 하지만 본 논문에서는 위의 loss를 사용하지 않고 아래의 VGG loss를 사용한다.
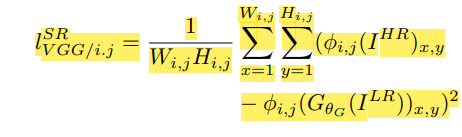
는 i번째 max pooling layer전의 j번째(activation 다음)레이어를 의미한다.
Pretrained된 VGG19네트워크의 활성화 된 feature map을 이용해서 euclidean distance를 구함. 다른 논문에서도 VGG loss를 사용하는데 이를 사용해야지만 디테일한 부분들을 잡아낼수 있는것 같다...?
3.4 Adversarial loss
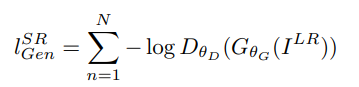
GAN에서 학습을 원활하게 하기 위해 사용되는 trick이다. 를 사용하면 초반에 gradient가 0에 가까워서 학습이 잘 진행되지 않는다. 따라서 위와같이 얻고자 하는 의미는 같고, gradient의 크기를 크게해서 학습을 용이하게 한다.
4. Experiment (간략히)
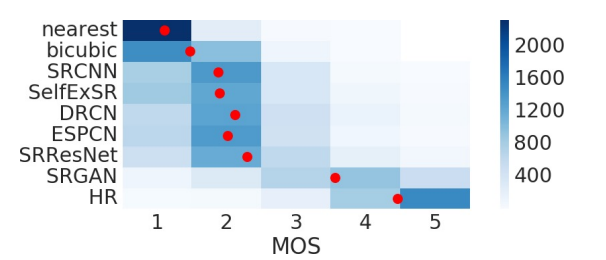
요약하면 다음과 같다. MOS기준으로 좋은 결과를 얻었다.더 자세한 내용은 논문을 참고하자..
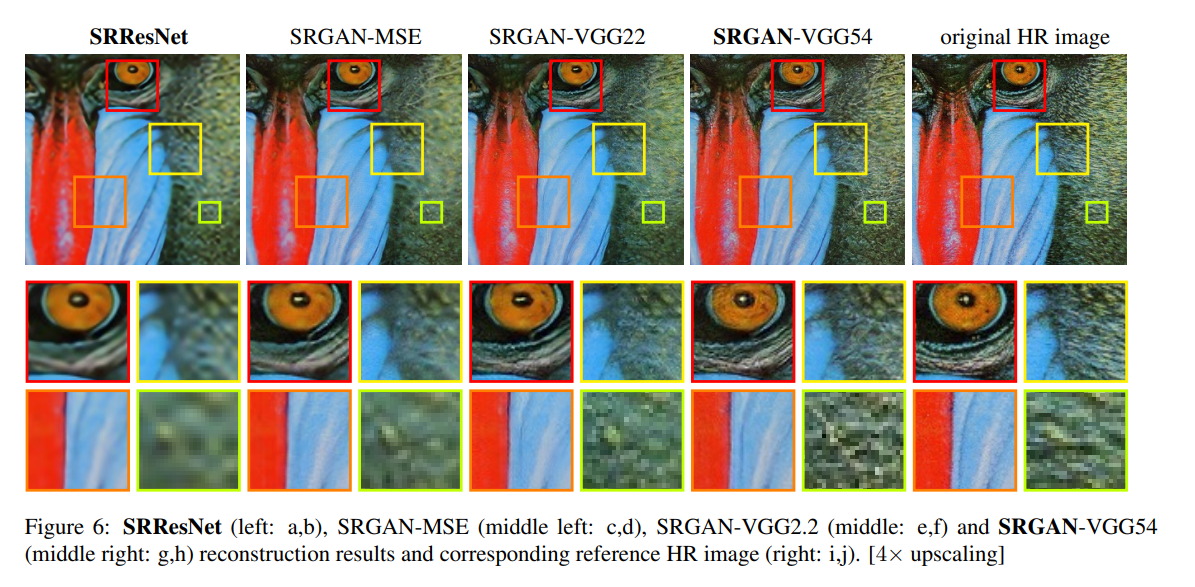
VGG 가 깊어질수록 텍스처의 질감이 점점 우너본과 같아진다. content loss를 구할 때 더 깊은 네트워크를 사용할수록 좋은 결과를 얻을수도 있다. 하지만 연산량이 증가할 것...
5. 내 결론
기존의 MSE기반의 loss function을 사용하지 않고 perceptual loss를 제안했고. 이는 adversarial loss와 vgg loss의 가중합이였다.
또한 실제와 같은 질감을 확보하기 위해 GAN을 사용하여 SISR를 진행한 첫 논문인 것이 의미가 있다.
현재 논문에서는 바닐라 GAN을 썼지만 WGAN과 같은 기존 GAN의 문제점을 개선한 GAN들이 제시되었다, 다른 GAN을 쓰면 더 좋은 결과가 나올수도 있다. 최소한 학습이 더 쉬워질수도 있다.
이 논문 이후에 ESRGAN, Real-ESRGAN이라는 논문이 나왔다. 빠르게 두 논문도 읽어봐야겠다.
