출처 | https://www.youtube.com/watch?v=IWpJsoX_UmU
https://github.com/jewerlykim/HashtableImplementationByC
해시테이블에 대한 간단한 설명
해시테이블은 데이터의 양이 많을 경우 생기는 데이터 검색에 대한 연산과정을 줄일 수 있는 자료구조이다.
key가 주어졌을 때 value를 찾기 위한 방법으로 해시 함수를 사용한다. input 으로 key가 들어오면 해쉬 함수를 통한 해쉬 인덱스가 나오고 해당 인덱스를 통해 빠르게 데이터를 찾아 들어가는 구조이다. 그림을 보자.
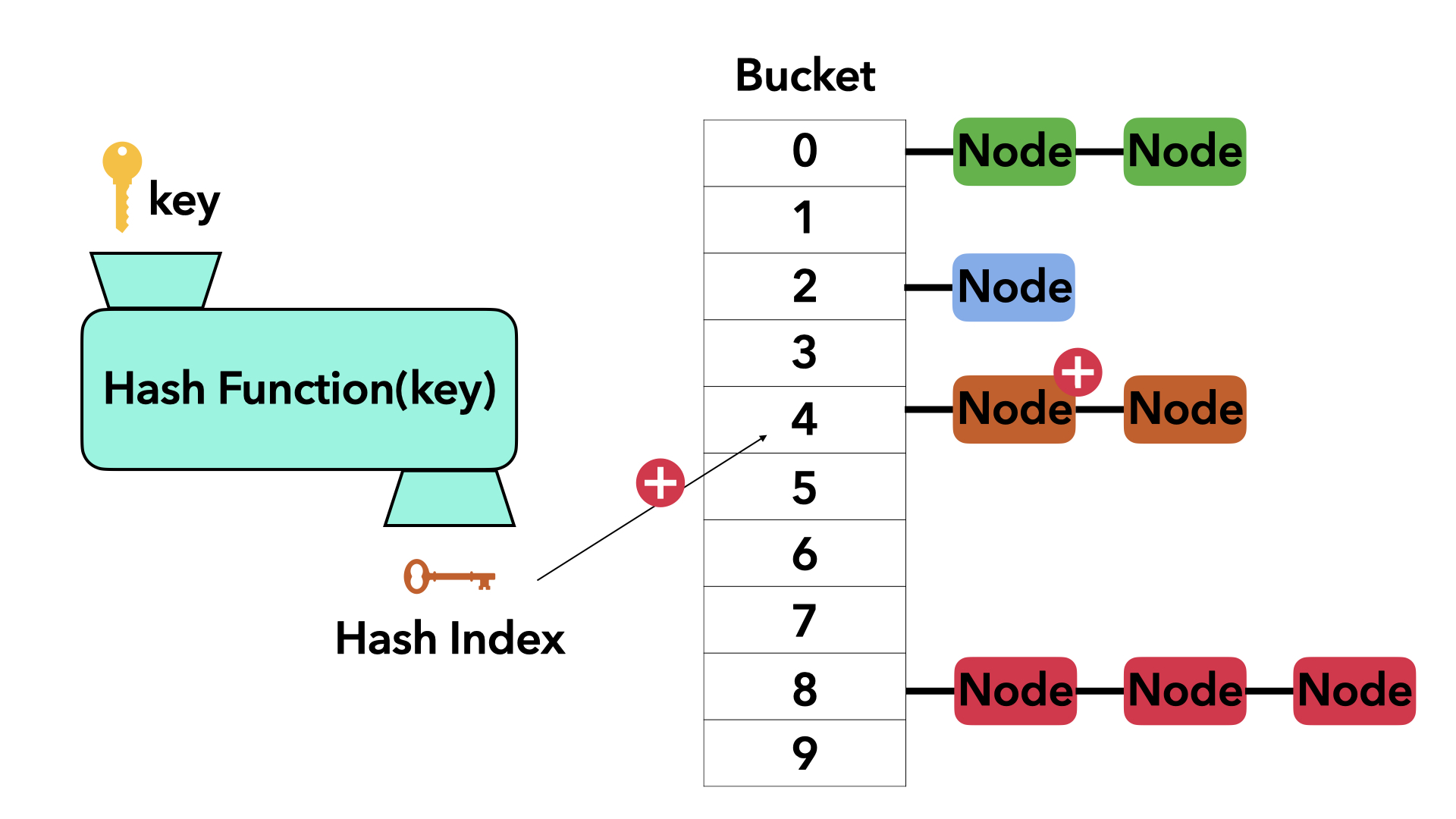
키와 해시함수를 통해 얻은 해시 인덱스로 Bucket의 인덱스를 찾는다. 그 뒤에 키와 데이터가 저장된 노드를 버켓 뒤에 붙이는 형식이다.
단순 링크드 리스트 자료구조를 사용했을 때 값을 찾기위해 모든 노드를 순회해야하는 반면 해쉬 테이블은 키를 통해 바로 해시 인덱스로 접근할 수 있으므로 시간 복잡도가 줄어듦을 알 수 있다.
다만, 위 그림에서 유추할 수 있듯이 한 인덱스로 노드가 모두 몰리는 경우가 생길 수도 있다. 그렇게 될 경우 링크드 리스트와 다른 점이 없으므로 해쉬테이블의 검색의 시간복잡도는 최악의 경우 O(n)이 될 수 있다.(n은 node의 개수)
그래서 인덱스를 만드는 해시 함수가 무엇보다 중요한 자료구조라고 할 수 있다.
충돌(Hash Table Collisions)
가장 이상적인 해시테이블은 한 버켓에 딱 한개의 노드가 있는 경우이다. 그럴 경우에 데이터 검색의 경우 인덱스만 계산하면 바로 값을 찾을 수 있으므로 O(1)의 시간복잡도를 보장할 수 있다. 하지만 그렇지 않은 경우, 즉, 한 버켓에 여러개의 노드가 있는 경우를 충돌이라고 한다.
충돌을 해결하는데에는 크게 두가지 방법이 있다. 체이닝과 개방주소방법이 있다. 체이닝은 해당 인덱스를 링크드 리스트로 묶어서 계속 뒤에 덧붙이는 식으로 해결하는 방법이고 위의 그림과 같은 형태가 된다. 두번째 개방주소방법은 인덱스에 이미 다른 노드가 있다면 다른 인덱스를 탐색해서 빈 인덱스에 삽입하는 방식이다.(더 숨겨진 내용이 많다. 나중에 알아보자)
웬만한 low단이 아닌 언어들은 해시 함수를 기본적으로 제공하는데 여기서는 파이썬에서 문자열을 해쉬하는 함수만 예시로 보자.
static long string_hash(PyStringObject *a)
{
register Py_ssize_t len;
register unsigned char *p;
register long x;
if (a->ob_shash != -1)
return a->ob_shash;
len = Py_SIZE(a);
p = (unsigned char *) a->ob_sval;
x = *p << 7;
while (--len >= 0)
x = (1000003*x) ^ *p++;
x ^= Py_SIZE(a);
if (x == -1)
x = -2;
a->ob_shash = x;
return x;
}매우 복잡한 과정을 통해 인덱스의 중복을 없애려고 함을 알 수 있다. 따라서 파이썬에서 해시테이블을 사용한 set, dict를 사용할 때 웬만한 데이터 크기라면 시간복잡도 걱정을 크게 하지 않고 사용할 수 있다.
이번 포스팅에서는 체이닝을 통해 해시 테이블을 구현해보고자 한다.
추가로 체이닝할 때 링크드 리스트를 singly linked list로 만들거나 혹은 doubly linked list로 만들수 있는데 둘을 모두 만들어보고 그 차이점을 알아보려고 한다.
해시 구현
1 . singly linked list로 구현
선언부
// 체이닝을 singly linked list 로 한 해시 테이블 구현
#include <stdio.h>
#include <stdlib.h> // 메모리 할당을 위함
struct bucket* hashTable = NULL;
int BUCKET_SIZE = 10; // 버켓의 총 길이해시테이블은 버켓을 통해 접근하기 때문에 hashTable이라는 이름으로 bucket 배열 주소값을 선언해둔다. 버켓의 총 길이는 10이 된다.
구조체 선언
// 노드 구조체 선언
struct node {
int key; // 해시 함수에 사용될 키
int value; // key 가 가지고 있는 데이터
struct node* next; // 다음 노드를 가르키는 포인터
};
// 버켓 구조체 선언
struct bucket{
struct node* head; // 버켓 가장 앞에 있는 노드의 포인터
int count; // 버켓에 들어있는 노드의 개수
};노드와 버켓의 구조체를 선언한다. 노드 - 노드에는 key, value가 있고 체이닝이 되었을 때 다음 노드를 가르키는 next 포인터를 멤버로 갖는다. 버켓 - 버켓에는 버켓에 있는 첫번째 노드의 포인터와 해당 버켓에 있는 노드의 개수인 count를 멤버로 갖는다.
이제부터 해시테이블에서 필요한 함수를 구현해보려고 한다. 필요한 함수는 다음과 같다.
-
createNode
-
hashFunction
-
add
-
remove_key
-
search
-
display
-
main
createNode
// 해쉬테이블 삽입될 때 새로 노드를 생성해주는 함수(초기화)
struct node* createNode(int key, int value){
struct node* newNode;
// 메모리 할당
newNode = (struct node *)malloc(sizeof(struct node));
// 사용자가 전해준 값을 대입
newNode->key = key;
newNode->value = value;
newNode->next = NULL; // 생성할 때는 next를 NULL로 초기화
return newNode;
}사용자가 넘겨준 key, value로 해쉬테이블에 추가하기 전에 노드 구조체를 만들어 주는 함수이다.
hashFunction
// 해쉬함수 만들기. 여기서는 단순히 key를 버켓 길이로 나눈 나머지로 함수를 만듦.
int hashFunction(int key){
return key%BUCKET_SIZE;
}충돌을 피한 해쉬함수를 만드는게 중요하지만 본 글에서는 설명을 위해 간단히 key값을 bucket 길이인 10으로 나눈 나머지를 인덱스로 반환하는 해시 함수를 만들어보았다.
add
// 새로 키 추가하는 함수
void add(int key, int value){
// 어느 버켓에 추가할지 인덱스를 계산
int hashIndex = hashFunction(key);
// 새로 노드 생성
struct node* newNode = createNode(key, value);
// 계산한 인덱스의 버켓에 아무 노드도 없을 경우
if (hashTable[hashIndex].count == 0){
hashTable[hashIndex].count = 1;
hashTable[hashIndex].head = newNode; // head를 교체
}
// 버켓에 다른 노드가 있을 경우 한칸씩 밀고 내가 헤드가 된다(실제로는 포인터만 바꿔줌)
else{
newNode->next = hashTable[hashIndex].head;
hashTable[hashIndex].head = newNode;
hashTable[hashIndex].count++;
}
}2.
void insert(int key, int value)
{
int hashIndex = hashFunction(key);
// 유저로부터 전달 된 key 값의 인덱스를 알기 위해서 해시함수를 호출한다.
// 그러면 해시함수에 의해 정의된 매핑 방법에 따른 index를 리턴 받아서
// hashIndex 변수에 저장한다.
struct node* newNode = createNode(key, value);
// 전달된 key, Value 값을 가진 노드를 생성한다.
// hashTable의 해시함수에 의해 전달받은
//Index의 Bucket에 접근하여 비어 있다면
if (hashTable[hashIndex].count == 0)
{
hashTable[hashIndex].head = newNode;
// 새로운 head 노드를 새로운 노드로 지정하고
hashTable[hashIndex].count = 1;
// 해당 Bucket의 노드 카운트를 1로 설정한다.
}
else
//내가 넣고자 하는 인덱스에 이미 값이 있는 경우
{
newNode->next = hashTable[hashIndex].head;
// 버켓이 비어있지 않다면, 새로운 노드의 new 포인터를 예전 head로 바꾼 다음
hashTable[hashIndex].head = newNode;
// 버켓의 head를 새로운 노드로 바꾼다.
hashTable[hashIndex].count++;
// 그 다음 해당 버켓의 노드 카운트를 증가시킨다.
}
}
키가 추가될 때 체이닝의 어느 부분에 삽입되어도 상관없지만 본 글에서는 추가된 키가 항상 버켓의 head가 되도록 하였다.
remove_key
// 키를 삭제해주는 함수
void remove_key(int key){
int hashIndex = hashFunction(key);
// 삭제가 되었는지 확인하는 flag 선언
int flag = 0;
// 키를 찾아줄 iterator 선언
struct node* node;
struct node* before; // 노드가 지나간 바로 전 노드
// 버켓의 head부터 시작
node = hashTable[hashIndex].head;
// 버켓을 순회하면서 key를 찾는다.
while (node != NULL) // NULL 이 나올때까지 순회
{
if (node->key == key){
// 포인터 바꿔주기 노드가 1 . 헤드인 경우 2 . 헤드가 아닌경우
if (node == hashTable[hashIndex].head){
hashTable[hashIndex].head = node->next; // 다음 노드가 이제 헤드
}
else{
before->next = node->next; // 전노드가 이제 내 다음 노드를 가르킴
}
// 나머지 작업 수행
hashTable[hashIndex].count--;
free(node);
flag = 1;
}
before = node; // 노드 바꿔주기 전에 저장
node = node->next;
}
// flag의 값에 따라 출력 다르게 해줌
if (flag == 1){ // 삭제가 되었다면
printf("\n [ %d ] 이/가 삭제되었습니다. \n", key);
}
else{ // 키가 없어서 삭제가 안된 경우
printf("\n [ %d ] 이/가 존재하지 않아 삭제하지 못했습니다.\n", key);
}
}2.
void remove(int key)
{
int hashIndex = hashFunction(key);
//해시 값 받아오기
struct node* node;
//Bucket안에 chianing 된 노드들을 하나하나 비교 하면서 찾아야 해서 임시 노드 포인터인 node 생성
struct node* trace;
//중간에 있는 노드를 없애는 경우 이전노드의 추적하여 next 포인터를 연결해줘야 하기 때문에 이전노드 추적
node = hashTable[hashIndex].head;
//임시 노드는 해당 버켓의 head 노드를 가르키게 된다.
if (node == NULL)
{
printf("\nno key found");
return;
}
while (node != NULL)
{
if (node->key == key) //만약 key값이 동일한 노드를 찾았을 경우
{
if (node == hashTable[hashIndex].head)
//만약 그 노드가 Bucket의 Head일 경우
{
hashTable[hashIndex].head = node->next;
//head 포인터를 다음칸으로 이동
}
else
{
trace->next = node->next;
//Head가 아닐 경우 이전 노드의 포인터를 현재 노드의 next가 가르키고 있는 노드로 바꾼다.
}
hashTable[hashIndex].count--;
//해당 버켓의 정보 업데이트 후 노드 삭제
free(node);
return;
}
trace = node;
//해당 노드가 찾고 있는 노드가 아니라면
//다음 노드로 가기전에 이전노드를 현재노드로 바꾸고
//다음 노드로 이동
node = node->next;
}
printf("\nnot key found");
return;
}remove 함수가 doubly linked list로 체이닝을 구현한 방식과 가장 큰 차이가 있는 부분이다.
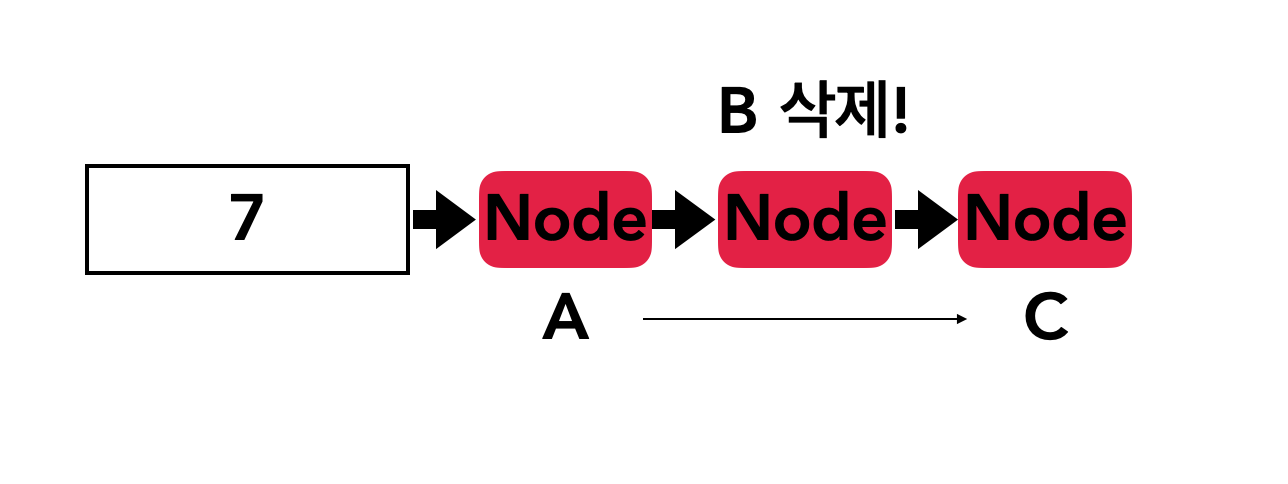
그림과 같이 A, B, C 노드가 체이닝되어있을 때 B를 삭제한다고 가정해보자. 그렇게 되면 A의 next 포인터를 C로 바꿔주는 과정이 필요한데 이때 B에서는 A로 doubly linked list와 달리 바로 접근할 수가 없으므로 한번 더 search를 해줘야하는 불상사가 생기므로 연산과정이 더 들게 된다.
search 함수
// 키를 주면 value를 알려주는 함수
void search(int key){
int hashIndex = hashFunction(key);
struct node* node = hashTable[hashIndex].head;
int flag = 0;
while (node != NULL)
{
if (node->key == key){
flag = 1;
break;
}
node = node->next;
}
if (flag == 1){ // 키를 찾았다면
printf("\n 키는 [ %d ], 값은 [ %d ] 입니다. \n", node->key, node->value);
}
else{
printf("\n 존재하지 않은 키는 찾을 수 없습니다. \n");
}
}해당 value를 반환하지않고 출력하는 식으로 간단하게 구현해보았다.
display 함수
// 해시테이블 전체를 출력해주는 함수
void display(){
// 반복자 선언
struct node* iterator;
printf("\n========= display start ========= \n");
for (int i = 0; i<BUCKET_SIZE; i++){
iterator = hashTable[i].head;
printf("Bucket[%d] : ", i);
while (iterator != NULL)
{
printf("(key : %d, val : %d) -> ", iterator->key, iterator->value);
iterator = iterator->next;
}
printf("\n");
}
printf("\n========= display complete ========= \n");
}해시테이블 버킷 전체를 순회하면서 출력해주는 함수이다.
main 함수
int main(){
// 해시테이블 메모리 할당
hashTable = (struct bucket *)malloc(BUCKET_SIZE * sizeof(struct bucket));
}먼저 값 여러개를 넣고 출력해보자
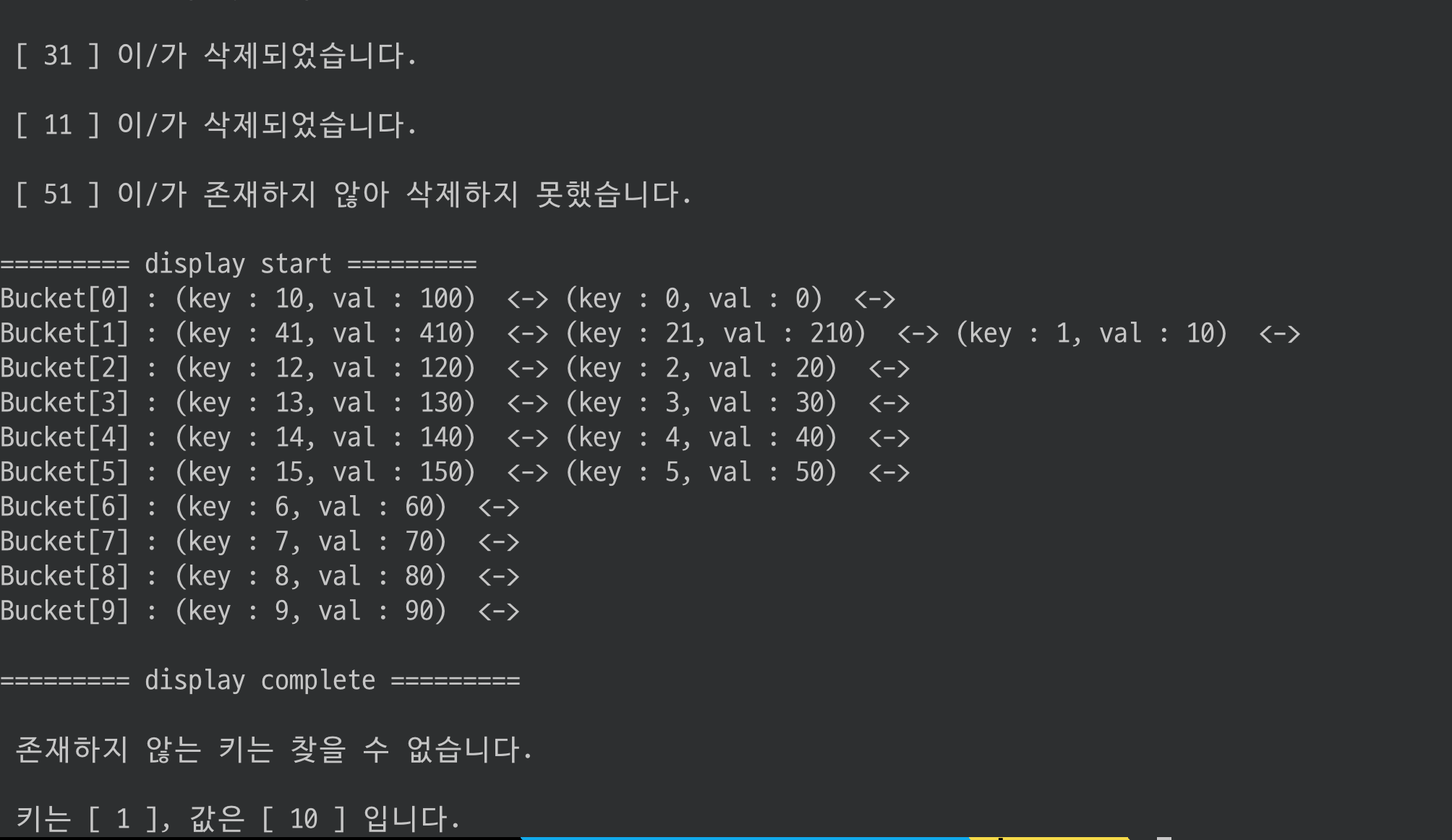
// 15 까지 값 추가
for (int i=0; i < 16; i++){
add(i, 10*i);
}
// 몇개 더 추가
add(21, 210);
add(31, 310);
add(41, 410);
display();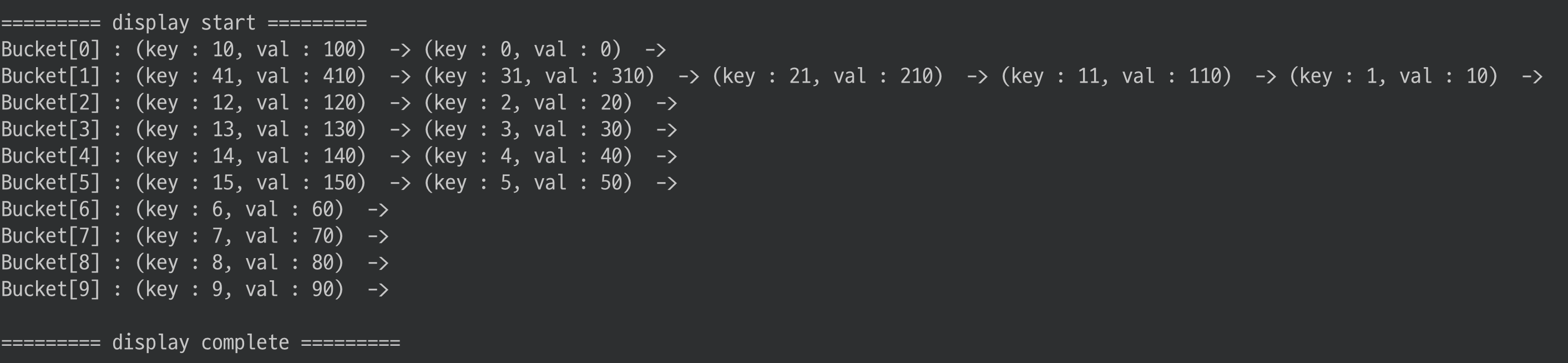
값 여러개를 삭제해보고 출력해보자
remove_key(31);
remove_key(11);
remove_key(51);
display();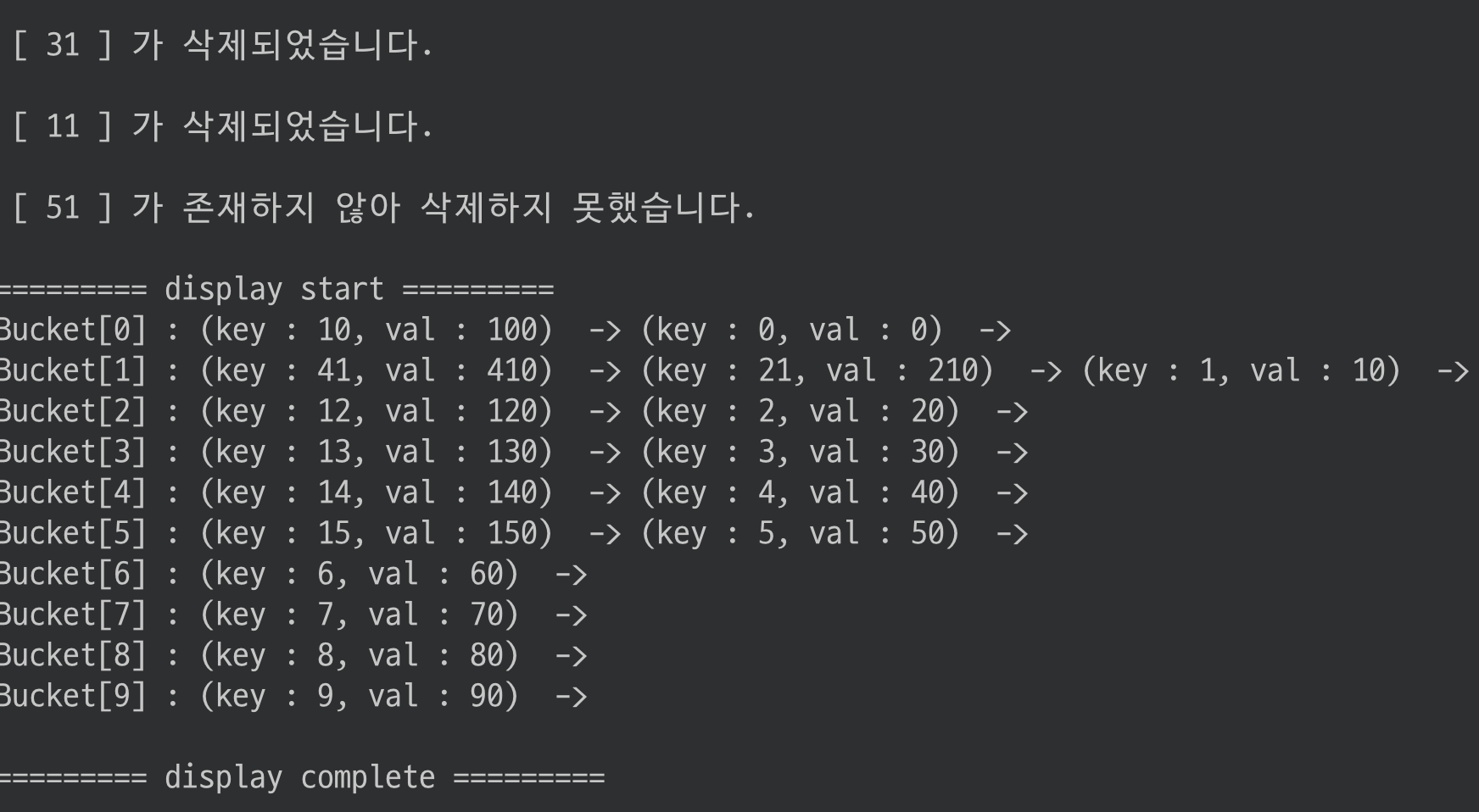
search 함수도 사용해보자
search(11);
search(1);
2 . doubly linked list로 구현
노드 구조체
**doubly linked list**
struct node {
int key; // 해시 함수에 사용될 키
int value; // key 가 가지고 있는 데이터
struct node* next; // 다음 노드를 가르키는 포인터
struct node* previous; // 이전 노드를 가르키는 포인터
};
**single linked list**
// 노드 구조체 선언
struct node {
int key; // 해시 함수에 사용될 키
int value; // key 가 가지고 있는 데이터
struct node* next; // 다음 노드를 가르키는 포인터
};
// 버켓 구조체 선언
struct bucket{
struct node* head; // 버켓 가장 앞에 있는 노드의 포인터
int count; // 버켓에 들어있는 노드의 개수
};
새롭게 previous라는 포인터가 생겼다. 당연히 createNode에서 previous 포인터도 NULL로 초기화 해준다. 이 함수 부분은 생략한다
add 함수
// 버켓에 다른 노드가 있을 경우 한칸씩 밀고 내가 헤드가 된다(실제로는 포인터만 바꿔줌)
else{
hashTable[hashIndex].head->previous = newNode; // 추가
newNode->next = hashTable[hashIndex].head;
hashTable[hashIndex].head = newNode;
hashTable[hashIndex].count++;
}add 함수에서 else부분에 한줄이 추가되었다. 한칸 뒤로 밀려나기 때문에 새롭게 들어온 node가 원래 있던 head의 previous가 된다.
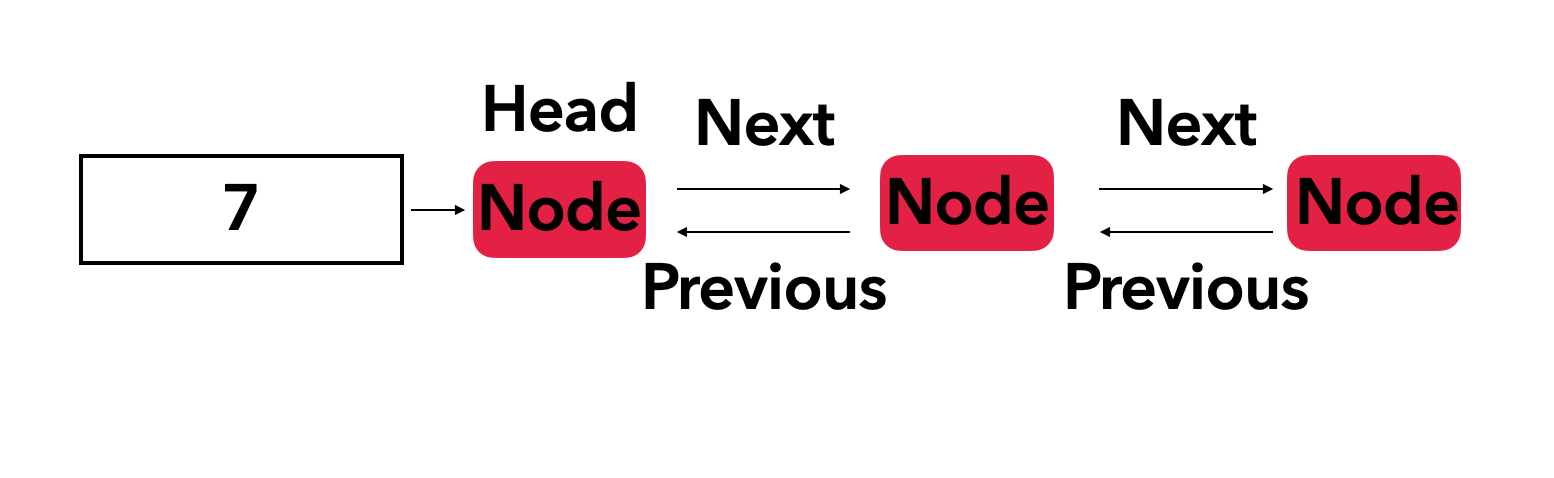
remove_key함수
// 키를 삭제해주는 함수
void remove_key(int key){
int hashIndex = hashFunction(key);
// 삭제가 되었는지 확인하는 flag 선언
int flag = 0;
// 키를 찾아줄 iterator 선언
struct node* node;
// struct node* before; // 필요 없음!
// 버켓의 head부터 시작
node = hashTable[hashIndex].head;
// 버켓을 순회하면서 key를 찾는다.
while (node != NULL) // NULL 이 나올때까지 순회
{
if (node->key == key){
// 포인터 바꿔주기 노드가 1 . 헤드인 경우 2 . 헤드가 아닌경우
if (node == hashTable[hashIndex].head){
node->next->previous = NULL; // 추가 이제 다음께 헤드가 되었으므로 previous가 없음
hashTable[hashIndex].head = node->next; // 다음 노드가 이제 헤드
}
else{
node->previous->next = node->next; // 내 전 노드의 앞이 이제 내 앞 노드
node->next->previous = node->previous; // 내 앞 노드의 전이 이제 내 전 노드
}
// 나머지 작업 수행
hashTable[hashIndex].count--;
free(node);
flag = 1;
}
node = node->next;
}
// flag의 값에 따라 출력 다르게 해줌
if (flag == 1){ // 삭제가 되었다면
printf("\n [ %d ] 이/가 삭제되었습니다. \n", key);
}
else{ // 키가 없어서 삭제가 안된 경우
printf("\n [ %d ] 이/가 존재하지 않아 삭제하지 못했습니다.\n", key);
}
}일단 지나온 노드를 저장하던 before는 필요가 없게되었다. 그리고 포인터를 바꿔줄 때 previous로 바로 접근하여 포인터를 바꿔주는 방식으로 수정되었다.