여기서도 역시 Attention 얘기부터 시작한다.
'Attention is All You Need'
Attention에 관한 나의 설명을 보고 싶다면,
GPT시리즈에 있는 두번째 게시물을 참고하면 된다!
여기에서는, Transformer based language model을 train한다고 한다.
이름은 NanoGPT이고, 데이터셋은
!wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt데이터 준비
먼저 input text를 받는다.
# here are all the unique characters that occur in this text
chars = sorted(list(set(text))) #
vocab_size = len(chars)
print(''.join(chars))
print(vocab_size)일단, text에 있는 모든 글자들을 불러와야하기에 겹치지않도록 set을 해주고, chars를 만들어준다.
chars의 length가 vocab_size!!
# create a mapping from characters to integers
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers
decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
print(encode("hii there"))
print(decode(encode("hii there")))결과는,
[46, 47, 47, 1, 58, 46, 43, 56, 43]
hii there
첫번째 코드는,
chars가 아까 !$&',-.3:;ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
이런식이었으니까
stoi = {0:!,1:$,2:&,3:',...}
두번째 코드는,
chars가 아까 !$&',-.3:;ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
이런식이었으니까
stoi = {!:0,$:1,&:2,':3,...}
세번째 코드는,
encode라는 얘가 하나의 함수인 것임.!!!
s라는 애가 필요한데, 그 s에 있는 c를 활용해서 stoi[c]를 output으로 해!
네번째 코드는,
decode라는 애가 하나의 함수.
l이라는 애가 필요한데, 그 l에 있는 i를 활용해서 itos[i]를 output으로 해!
이걸 왜 character 단위로 할까?
구글에서는 sentencepiece, openai에선 tiktoken...
결국 여기서는, 당연히 character를 기준으로 하니까 서로 다른 65개의 알파벳을 대상으로 한건데,
만약 단어를 기준으로 한다고 하면 (정확하게 단어는 아니지만) tiktoken에선 서로 다른 50257개의 단어들을 대상으로 함.
하지만 똑같은 hii there라는 문장을
tiktoken으로 표현 : [71,4178,612]
상단의 코드로 표현 : [46,47,47,1,58,46,43,56,43]으로 표현
Transformer의 embedding vector와 연관짓기
Transformer의 embedding vector는 문장개수 x 단어 개수 x 차원 수 이거다.
문장개수가 하나라고 하면,
tiktoken으로 표현 : 1 x 4 x 50257
상단의 코드로 표현 : 1 x 9 x 64
이렇게 되는 듯 하다...!!! 왜냐면 어쨌든 one-hot-encoding으로 표시하는 거니깐...
그래서 뭐가 되었든,,,천국은 없다ㅎㅎ
위 내용은 내가 개인적으로 생각한 거!
# let's now encode the entire text dataset and store it into a torch.Tensor
import torch # we use PyTorch: https://pytorch.org
data = torch.tensor(encode(text), dtype=torch.long)
print(data.shape, data.dtype)
print(data[:1000]) # the 1000 characters we looked at earier will to the GPT look like this파이토치 사용해서,
모든 텍스트를 아까의 lambda 함수를 활용하여 인코딩을 진행한다. 그리고 나서 텐서로 바꿔준다.
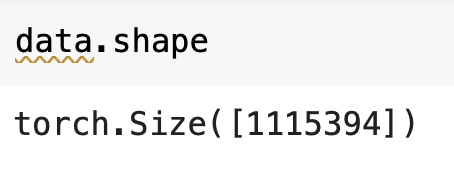
이걸로 봐서는, 총 1115394개의 character들이 있나보다!!!
# Let's now split up the data into train and validation sets
n = int(0.9*len(data)) # first 90% will be train, rest val
train_data = data[:n]
val_data = data[n:]train/val 나눠주고
block_size = 8
train_data[:block_size+1]왜 갑자기 뜬금없이 block_size가 등장하나??
왜냐면, 한번에 다 트레이닝을 할 수가 없어서 그래.
저렇게 train_data[:block_size+1]을 해버리면, 
요렇게 등장을 한다.
즉, 여러개의 문장을 합쳐서 1 x 1115394 x 64 이렇게 하는 경우도 있고
여러개의 문장들을 block_size + 1로 잘라서 139425 x 8 x 64 이렇게 하는 경우도 있는 거다!!!
(1115394를 8로 나누면 결과는 139424.25니까...)
x = train_data[:block_size]
y = train_data[1:block_size+1]
for t in range(block_size):
context = x[:t+1]
target = y[t]
print(f"when input is {context} the target: {target}")x는 transformer의 인풋이다.
y는 trasnformer의 target!
block_size가 0,1,2,3,4,5,6,7로 늘어나며 반복을 하게 되는데,
block_size가 0일 때 : context는 x[:1] , target은 y[0] => [18] , [47]
block_size가 1일 때 : context는 x[:2] , target은 y[1] => [18,47] , [56]
...
내가 몰랐던 것 : x[:1]과 x[1]의 차이
난 당연히 x[:1]이 x[0]과 x[1]을 담은 리스트라고 생각했는데 1은 제외하고 x[0]만 담긴 리스트ㅎㅎ

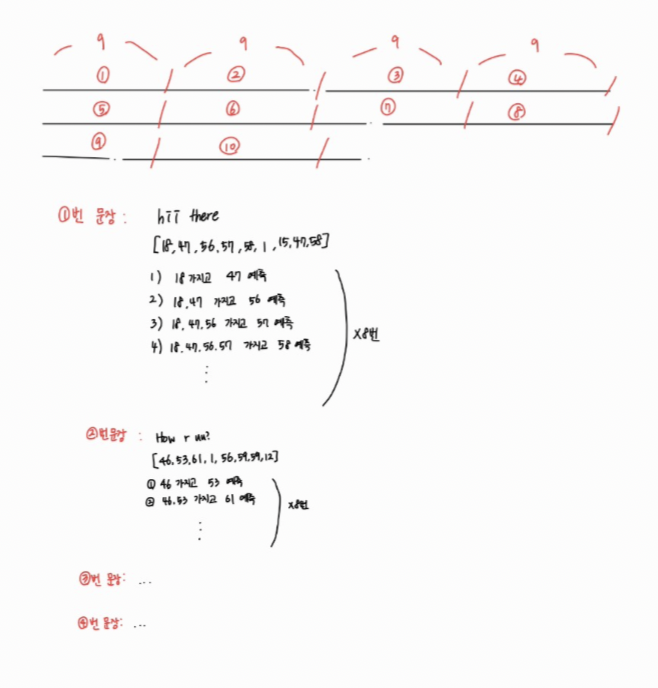
손수 그린 그림...양해해주어요...
유의해야할 점 :
전체 text에서 문장을 끊는 단위는 block_size + 1이다.
하지만 실제 transformer에서 embedding vector의 차원은 (block_size로 나눠진 문장 개수 x block_size x 차원 수그렇다면 왜?
일단, 인풋으로 들어가는 텐서의 최대 개수가 위의 사진에서 알 수 있듯이 8개다.
애초에 '예측'을 위해 사용되는 인풋 텐서는 8개가 최대일 거다.
왜냐? 타겟을 맞추는 것이 목적이기 때문에, 타겟은 18이 아니라 47부터 시작한다.
그래서 47부터 맨 마지막에 있는 47까지 해서 총 8개의 타겟이 있는 것이다~
Baseline모델
get_batch
torch.manual_seed(1337)
batch_size = 4 # how many independent sequences will we process in parallel?
block_size = 8 # what is the maximum context length for predictions?
def get_batch(split):
# generate a small batch of data of inputs x and targets y
data = train_data if split == 'train' else val_data
ix = torch.randint(len(data) - block_size, (batch_size,))
x = torch.stack([data[i:i+block_size] for i in ix])
y = torch.stack([data[i+1:i+block_size+1] for i in ix])
return x, y
xb, yb = get_batch('train')
print('inputs:')
print(xb.shape)
print(xb)
print('targets:')
print(yb.shape)
print(yb)
print('----')
for b in range(batch_size): # batch dimension
for t in range(block_size): # time dimension
context = xb[b, :t+1]
target = yb[b,t]
print(f"when input is {context.tolist()} the target: {target}")이건 generalize한거다.
일단 random seed를 고정하고
block_size는 8,batch_size는 4
ix는 0과 len(data) - block_size 범위 내에서 batch_size만큼의 random int를 뽑음.
: torch.randint(low, high, size)
예를들어 ix = [100,200,300,400] 이면 block_size가 8이니까
x = [100,101,102,,,107]에 [200,201,202,,,207]에 [300,301,302,,,307]...[400,401,402,,,407]을 stack!!!
y = [101,102,,,,108]에 [201,202,,,,208]에 [301,302,,,307]...[401,402,403,,,408]을 stack!!!
batch_size
여기서는 batch_size를 이용해서 전체 text에서 4개의 문장(부분)을 뽑아서, 각각 8번씩 트레이닝 시킨 거임!
원래 전통적인 훈련방법으로는 전체 text를 싹 다 나누고 그 문장들을 각각 8번씩 트레이닝 시켰겠지만...!
그리고 나서 for문은,
b=0,t=0일때 :
xb[0,:1] = x의 0번째 행의 0번째!
yb[0,0] = y의 0번째 행의 0번째!
== when input is [24] the target: 43
b=0,t=1일때 :
xb[0,:2] = x의 0번째 행의 0번째,0번째 행의 1번째!
yb[0,1] = y의 0번째 행의 1번째
== when input is [24,43] the target: 58
...
이런식으로!!
젤 중요한건 [0,:1]이랑 [0,1]이랑 헷갈리지 않는 것...ㅋㅋ
BigramLanguageModel
import torch
import torch.nn as nn
from torch.nn import functional as F
torch.manual_seed(1337)
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
# each token directly reads off the logits for the next token from a lookup table
self.token_embedding_table = nn.Embedding(vocab_size, vocab_size)
def forward(self, idx, targets=None):
# idx and targets are both (B,T) tensor of integers
logits = self.token_embedding_table(idx) # (B,T,C)
if targets is None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
# idx is (B, T) array of indices in the current context
for _ in range(max_new_tokens):
# get the predictions
logits, loss = self(idx)
# focus only on the last time step
logits = logits[:, -1, :] # becomes (B, C)
# apply softmax to get probabilities
probs = F.softmax(logits, dim=-1) # (B, C)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idx
m = BigramLanguageModel(vocab_size)
logits, loss = m(xb, yb)
print(logits.shape)
print(loss)
print(decode(m.generate(idx = torch.zeros((1, 1), dtype=torch.long), max_new_tokens=100)[0].tolist()))- 초기화가 되면,
token_embedding_table에 대해서는 vocab_size x vocab_size의 embedding table을 만들어 놓는다.
즉, vocab_size x vocab_size 의 matrix를 만들어둔다고 할 수 있다.
왜 그럼 Matrix 사이즈를 그렇게 하는 건데요?
1. 일단, 전체 단어의 숫자가 이정도가 있으면, 알아서 nn.Embedding 모듈로 적절하게 임베딩을 해준다.
2. 즉, 중복 빼고 순수한 단어가 이정도 있으면 최적의 embedding은 이겁니다~ 이렇게 말해주는거지!
그럼 어떤 값이 들어가 있는 건가?
= nn.Embedding은 임베딩 벡터를 작은 난수 값으로 초기화
= 기본적으로 평균이 0이고 분산이 1인 정규 분포를 사용하여 임베딩 벡터를 초기화
- forward함수
인풋 : idx (batch_size x token_size)
인풋에 해당하는 embedding vector : (vocab_size)
아웃풋 : logits
하지만 불상사가 생긴다.
이건 정말. 단순히. 내 인풋을 그냥 embedding vector로 바꾼 것에 불과하다.
- forward함수
loss : logits와 targets사이의 loss...
(embedding해서 만든 input변형) 과 (예측해야하는 값들) 사이의 loss...
또 불상사가 생긴다.
그 불상사가 뭐냐하면, pytorch가 multi-dim이면 channel이 두번째이길 바람.
- forward함수
logits = (B x T,C)
targets = (B x T)
궁금했던 점...
원래 자바에서 하는 것처럼 하면 m.forward(xb,yb)여야 할 것 같지만
신기하게도 m(xb,yb)를 하면 자동으로 forward 함수가 호출이 된다고 한다.
여기에서는, vocab_size가 65니까, 65x65!
예시 )
vocab_size = 10
batch_size= 2
token_size = 4
channel_size = 10
이면,
인풋이 (2x4) , 아웃풋이 (2x4),logits가 (4*2,10)
요런 느낌이라고 이해하면 된다!
- generate 함수
이건, 그 batch마다 반복되는 것...!
(얘랑 완벽하게 똑같은 건 아님. 왜냐면 예전것까지 다 참조하는 형식이 아니라서.)
준비물 : forward에서 나온 logits,loss (물론,loss는 필요 없음)
가장 최근 글의 다음글자 선택 : logits = logits[:, -1, :]
왜냐면, 아까 logits,loss가 (B*T,C)가 되었기 때문에,,,
다음 글자가 될 확률 계산 : softmax
다음 글자 무작위로 선택 : torch.multiomial
선택된 글자를 현재 글자에 추가 : torch.cat((idx,idx_next),dim=1)
Baseline모델에서는, 참조를 할 때 그 이전만! 참고했다!
그래서 아무래도,,,안좋은 성능이 나올 수밖에...
학습시키기
Adam Optimizer
# create a PyTorch optimizer
optimizer = torch.optim.AdamW(m.parameters(), lr=1e-3)
batch_size = 32
for steps in range(100): # increase number of steps for good results...
# sample a batch of data
xb, yb = get_batch('train')
# evaluate the loss
logits, loss = m(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
print(loss.item())일단, AdamOptimizer를 사용.
loss,logits를 output으로 해서
backward랑 optimizer씀.
print(decode(m.generate(idx = torch.zeros((1, 1), dtype=torch.long), max_new_tokens=500)[0].tolist()))처참한 결과가...나온다. 어쨌든 그럼 baseline만으로는 안된다는 것이 밝혀졌으므로 추가추가해보자.
Self-Attention
기본 뼈대
# consider the following toy example:
torch.manual_seed(1337)
B,T,C = 4,8,2 # batch, time, channels
x = torch.randn(B,T,C)
x.shape 일단, 토큰들이 communicate해야한다.
그러기 위해서 communicate하게 만들어줄까?
# We want x[b,t] = mean_{i<=t} x[b,i]
xbow = torch.zeros((B,T,C))
for b in range(B):
for t in range(T):
xprev = x[b,:t+1] # (t,C)
xbow[b,t] = torch.mean(xprev, 0)- initialize한다.
Batch dimension마다 반복하고, Token dimension마다 반복하는데, - xprev = x[b,:t+1]
: 얘는 결국, 해당 토큰의 이전 토큰들을 모아서 xprev로 만드는 것이다.
그러면 차원은 (t,C)가 되겠지!
예시 )
x[2,:3]인 경우에는, x의 두번째 batch에서 0번째부터 3번째 이전까지의 토큰들을 불러오는거다!
그러면 거기에는 (0번째부터 2번째까지의 토큰) x (채널) 이렇게 되겠지. - xprev를 평균내기
첫번째 차원을 기준으로 평균을 내는 거니까,
1번째토큰의 채널 + 2번째 토큰의 채널 + 3번째 토큰의 채널 을 3으로 나누자.
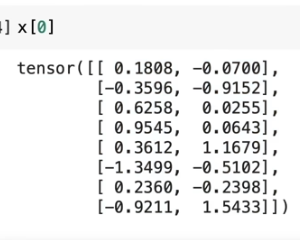
얘는 데이터의 0번째 배치의 token x channel
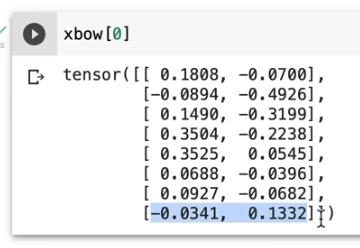
얘는 xbow의 0번째 배치의 token x channel
둘은 차원이 같더라도, 값이 달라진 것을 확인할 수 있다.
확인해봐야할점 1) x[0]의 첫번째 행은 그대로 xbow[0]의 첫번째 행이다.
확인해봐야할점 2) x[0]의 첫번째 행과 두번째 행의 평균이 xbow[0]의 첫번쨰 행이다.
확인해봐야할점 3) x[0]의 첫번째 행부터 t번째 행까지의 평균이 xbow[0]의 t번째 행이다. !!
일반화를 시켜보면, 그냥 평균이 들어간단 소리다ㅎㅎ
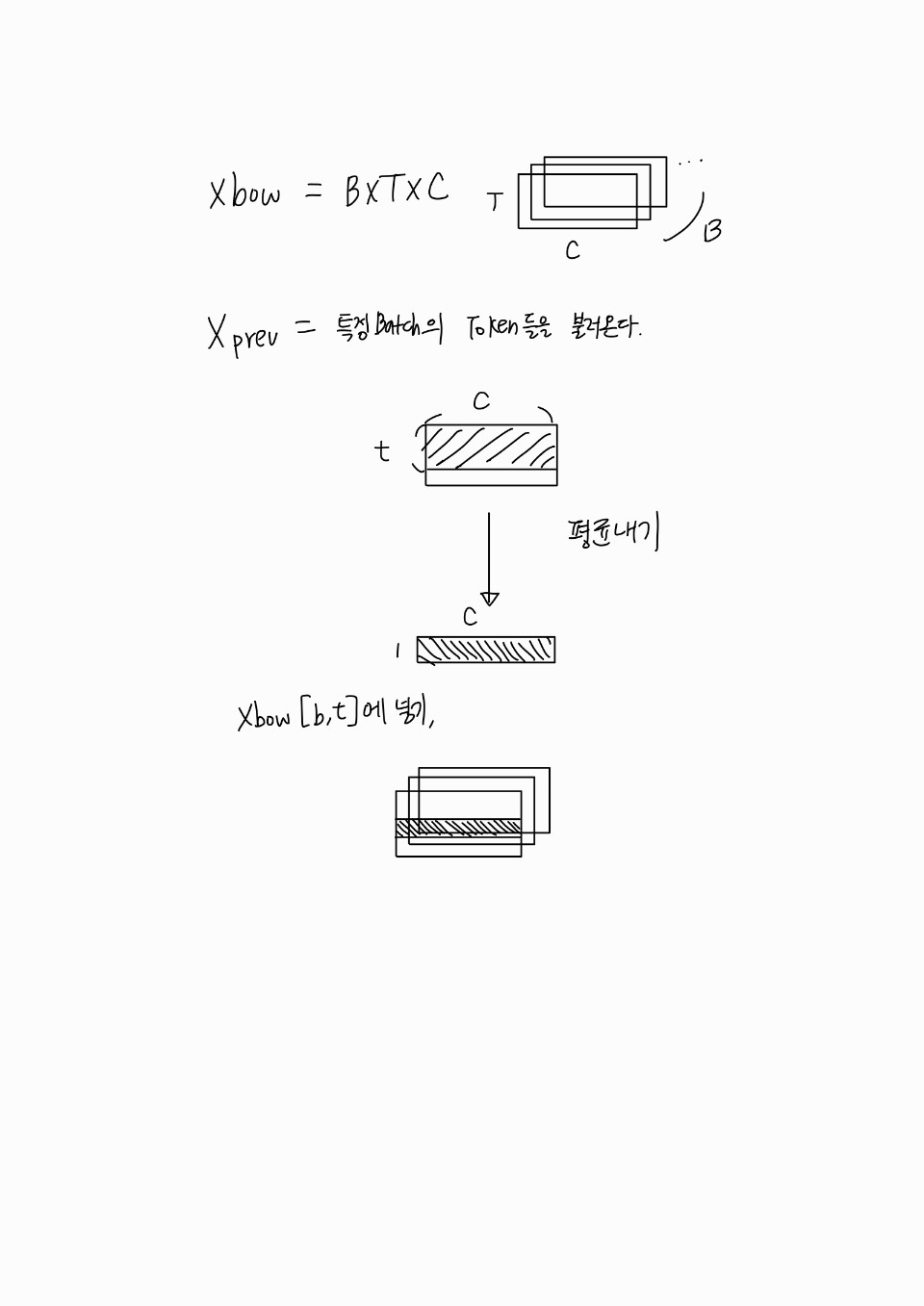
쉽게 그림으로 설명해보았다.
이제는 구체적으로 어떻게 해야하는지 살펴보도록 하겠다.
How?
Toy Example
Version 1
# toy example illustrating how matrix multiplication can be used for a "weighted aggregation"
torch.manual_seed(42)
a = torch.tril(torch.ones(3, 3))
a= a / torch.sum(a, 1, keepdim=True)
b = torch.randint(0,10,(3,2)).float()
c = a @ b
print('a=')
print(a)
print('--')
print('b=')
print(b)
print('--')
print('c=')
print(c) 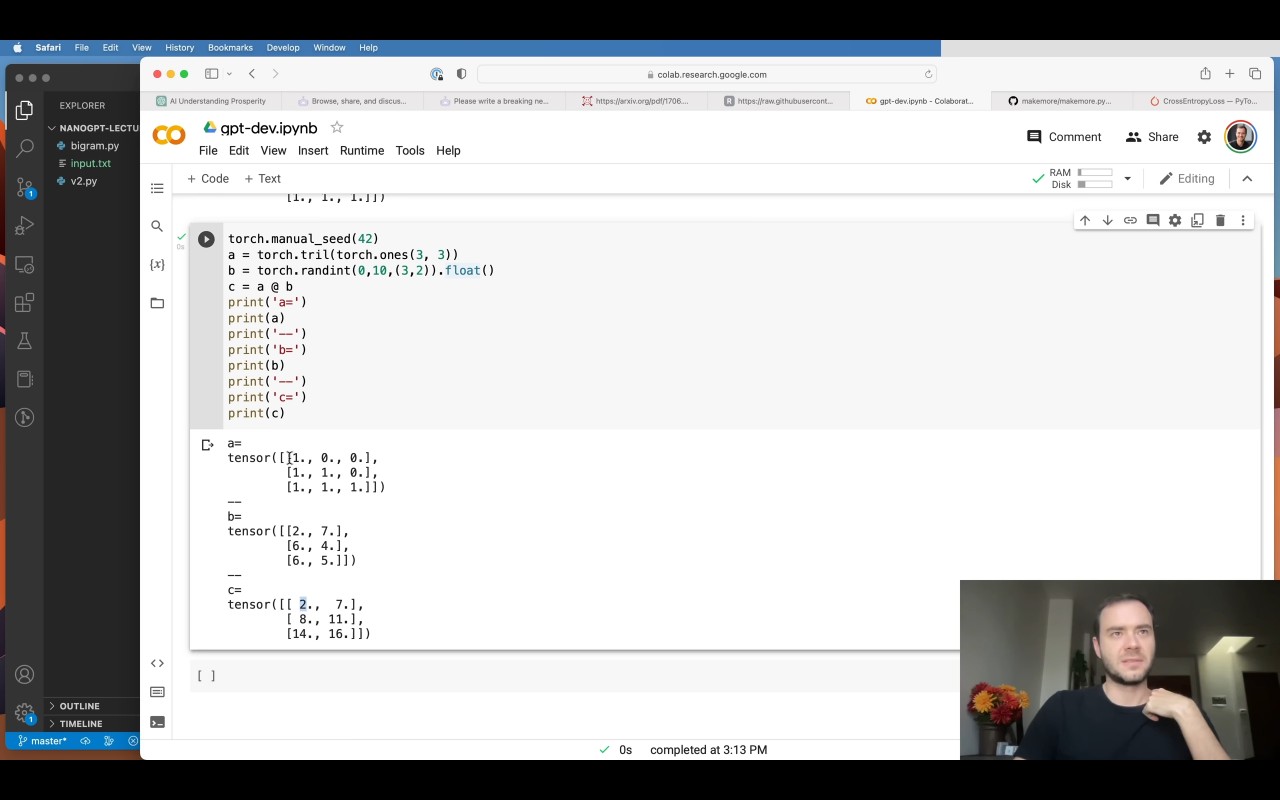
(아직 sum으로 나누지 않은 결과는 이렇게 된다.)
나누게 되면,

이렇게 하면, average를 구할 수 있다!
Version 2
# version 2: using matrix multiply for a weighted aggregation
wei = torch.tril(torch.ones(T, T))
wei = wei / wei.sum(1, keepdim=True)
xbow2 = wei @ x # (B, T, T) @ (B, T, C) ----> (B, T, C)
torch.allclose(xbow, xbow2) 똑같이 tril로 대각선 아랫부분만 1채워주고
그리고 나서 sum으로 나눠주고
그리고 나서 x랑 내적한다. 그러면 (B x T x C)가 나오겠지. 그래서 결국 xbow2를 만든 것이다!
Version 3
#version 3 :
tril = torch.tril(torch.ones(T, T))
wei = torch.zeros((T,T))
wei = wei.masked_fill(tril == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
xbow3 = wei @ x
torch.allclose(xbow, xbow3)이렇게 되면, -inf로 마스킹하고
그리고 softmax를 적용하니 확률값이 나타나고 -inf로 마스킹한건 0으로 될거다.
이게 의미하는 이유?
그러면, inf로 하게 됨으로써, 그 뒤의 것들과 communicate할 수 없다는 것을 나타낸다.
Baseline 모델
일단,
import torch
import torch.nn as nn
from torch.nn import functional as F
torch.manual_seed(1337)
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
# each token directly reads off the logits for the next token from a lookup table
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
self.position_embedding_table = nn.Embedding(block_size,n_embd)
self.lm_head = nn.Linear(n_embd,vocab_size)
def forward(self, idx, targets=None):
# idx and targets are both (B,T) tensor of integers
tok_emb = self.token_embedding_table(idx) # (B,T,n_embd)
pos_emb = self.position_embededing_table(torch.arrange(T,device=device))#(T,C)
x = tok_emb + pos_emb
logits = self.lm_head(tok_emb) #(B,T,vocab_size)
if targets is None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
# idx is (B, T) array of indices in the current context
for _ in range(max_new_tokens):
# get the predictions
logits, loss = self(idx)
# focus only on the last time step
logits = logits[:, -1, :] # becomes (B, C)
# apply softmax to get probabilities
probs = F.softmax(logits, dim=-1) # (B, C)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idx
m = BigramLanguageModel(vocab_size)
logits, loss = m(xb, yb)
print(logits.shape)
print(loss)
print(decode(m.generate(idx = torch.zeros((1, 1), dtype=torch.long), max_new_tokens=100)[0].tolist()))다시 얘를 살펴볼 필요가 있다.
1.n_embd의 등장
vocab_size가 예를들어 10000이라고 쳐보자.
왜냐면 총 10000개의 단어가 있으면 당연히 channel도 10000개일것아닌가?
-> 그러면, B x T x 10000하면 computational 용량 증가
-> 따라서, embedding으로 차원을 좀 줄여주자.
그러면 toekn_embedding_table은 (vocab_size x n_embd)가 될 것.
- token_embedding_table
foward에서, 그냥 self.token_embedding_table(idx)하면 그 idx에 해당하는 channel의 고정된 크기의 벡터를 매핑한다.
nn.Embedding?
입력이 이렇게 4 x 8 이라고 가정을 하면, 이에 해당하는 값들이 24,43이렇게 나온다.
그 값을 가지고서 token_embedding_table을 탐색을 하는 거다.
24라고 하면, 24번째 행은 어디지...?
24번째 행 찾았다!
걔를 끌고온 게 tok_emb인 거다. 그래서 B x T x C 인 것.

nn.Linear와 nn.Embedding의 차이?
입력 데이터 유형:
nn.Linear: 연속적인 수치 데이터(실수 벡터).
nn.Embedding: 이산형 데이터(정수 인덱스).
출력 데이터 유형:
nn.Linear: 선형 변환된 연속적인 수치 데이터.
nn.Embedding: 인덱스에 해당하는 임베딩 벡터.
사용 용도:
nn.Linear: 일반적인 피처 변환, 피처 추출, 예측 등.
nn.Embedding: 단어 임베딩, 이산형 데이터 임베딩 등.
nn.Embedding(vocab_size,vocab_size) 와 nn.Embedding(vocab_size,n_embd)의 차이는 무엇일까?
=> 굳이, embedding을 n_embd차원으로 하고, linear를 적용시켜서 logits을 만들 바에는 그냥 vocab_size,vocab_size로 하면 되는 거 아닌가?
그 이유는 단순하다.
1. 만약 nn.Embedding(vocab_size, vocab_size)로 설정하면, 임베딩 레이어는 사실상 one-hot 인코딩과 유사한 역할만 하게 된다.
2. 임베딩 차원을 단어 사전 크기와 동일하게 설정하면, 모델의 계산 비용이 크게 증가
3. 임베딩 벡터가 단어 사전 크기와 동일할 경우, 학습 과정에서 모델이 일반화하기 어려워질 수 있다.
- position_embedding_table
(block_size)x(n_embd)만큼 차원이 설정된 테이블!
-> 이걸 가지고 pos_emb를 만들고 tok_emb랑 합쳐서 x를 만든다.
Self-Attention
다시 self-Attention으로 돌아가서...
1. Query,Key,Value의 등장
# version 4: self-attention!
torch.manual_seed(1337)
B,T,C = 4,8,32 # batch, time, channels
x = torch.randn(B,T,C)
# let's see a single Head perform self-attention
head_size = 16
key = nn.Linear(C, head_size, bias=False)
query = nn.Linear(C, head_size, bias=False)
value = nn.Linear(C, head_size, bias=False)
k = key(x) # (B, T, 16)
q = query(x) # (B, T, 16)여기서, nn.Linear(C,head_size)만큼을 통과한다.
이 이유는 multi-head-attention을 적용할 것이기 때문!!!
head_size는 각 어텐션 헤드의 차원
C는 입력 텐서의 전체 차원(채널 수)
예를 들어, C가 32이고, 2개의 어텐션 헤드를 사용하면, 각 헤드는 16차원의 벡터(head_size = 16)를 가진다.
2. Self- Attention
wei = q @ k.transpose(-2, -1) # (B, T, 16) @ (B, 16, T) ---> (B, T, T)
tril = torch.tril(torch.ones(T, T))
#wei = torch.zeros((T,T))
wei = wei.masked_fill(tril == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
v = value(x)
out = wei @v
#out = wei @ x
out.shape1) 내적해주기.
2) k.transpose(-2,-1) : k가 (B,T,16)이었기 때문에 (B,16,T)로 바뀜! 그래서 결과는, (B,T,T)가 된다.
k.transpose(-2,-1)
따라서 k.transpose(-2, -1)은 텐서 k의 마지막 두 차원을 교환합니다.
예를 들어,
텐서 k가 3차원 (batch, height, width) 모양을 가지고 있다면, k.transpose(-2, -1)은 k를 (batch, width, height) 모양으로 변환된다.
3) torch.tril & wei.masked_fill : 삼각행렬 만들어주고 위에는 0으로 만들어주기 , 0이면 -inf 넣기
4) wei와 value를 곱해서 out을 만들어주기
디코더와 인코더의 차이점은 masking을 해주냐 안해주느냐의 차이.
class Head(nn.Module):
""" one head of self-attention """
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embd, head_size, bias=False)
self.query = nn.Linear(n_embd, head_size, bias=False)
self.value = nn.Linear(n_embd, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
B,T,C = x.shape
k = self.key(x) # (B,T,C)
q = self.query(x) # (B,T,C)
# compute attention scores ("affinities")
wei = q @ k.transpose(-2,-1) * C**-0.5 # (B, T, C) @ (B, C, T) -> (B, T, T)
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)
wei = F.softmax(wei, dim=-1) # (B, T, T)
wei = self.dropout(wei)
# perform the weighted aggregation of the values
v = self.value(x) # (B,T,C)
out = wei @ v # (B, T, T) @ (B, T, C) -> (B, T, C)
return out여기에서는 head별로, multihead로 한 것임.
Multi-Head-Attention
정의
Multiple Head Attention을 parallel하게 만들고 concate하기 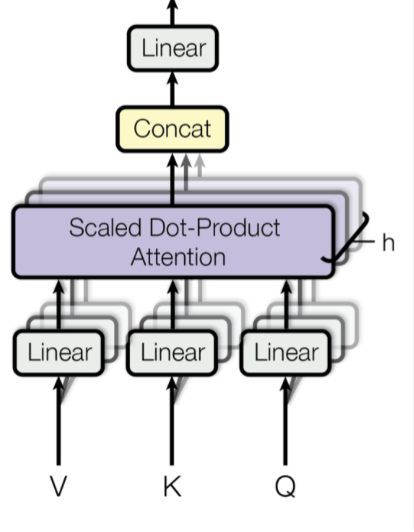
구현
class MultiHeadAttention(nn.Module):
""" multiple heads of self-attention in parallel """
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(n_embd, n_embd)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out- 여러개의 head를 만들기
이렇게 Module 여러개를 합치는 게 MHA다.
h(x) for h in self.heads
self.heads : 모듈의 리스트. 각각의 h는 self.heads에 있는 개별 함수 또는 모듈입니다.
h(x) : 입력 x에 대해 각 h 함수 또는 모듈을 적용한 결과입니다.
[h(x) for h in self.heads] : 입력 x를 각 함수 또는 모듈 h에 통과시켜 나온 결과들을 리스트로 반환
torch.cat(..., dim=-1)
torch.cat : 주어진 텐서 리스트를 특정 차원(dim)으로 연결
dim=-1: 마지막 차원으로 연결
- Baseline 코드 수정
하지만 유의해야할 것이,
MHA 클래스를 만들었으면, Baseline모델에도 그것을 추가해줘야 한다는 것이다!
Class BigramLanguageModel(nn.Module):
def _init_(self):
super()._init_()
self.token_embedding_table = nn.Embedding(vocab_size,n_embd)
self.position_embedding_table = nn.Embedding(block_size,n_embd)
self.sa_heads = MultiHeadAttention(4,n_embd//4)
self.lm_head = nn.Linear(n_embd,vocab_size)
def forward(self,idx,targets = None)
B,T = idx.shape
tok_emb = self.token_embedding_table(idx)
pos_emb = self.poistion_embedding_table(torch.arange(T,device=device))
x = tok_emb + pos_emb
x = self.sa_heads(x)
logits = self.lm_head(x) num_heads = 4 : 총 4개의 head를 만들었다.
head_size = n_embd//4 : num_heads x head_size = n_embd여야 하니까...
Feed Forward
class FeedFoward(nn.Module):
""" a simple linear layer followed by a non-linearity """
def __init__(self, n_embd):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd),
nn.ReLU(),
nn.Linear(4 * n_embd, n_embd),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)Linear Layer랑 ReLU 사용해서...
그리고 나서 BigramLanguageModel에
sa_heads 추가 ! ! !
Block
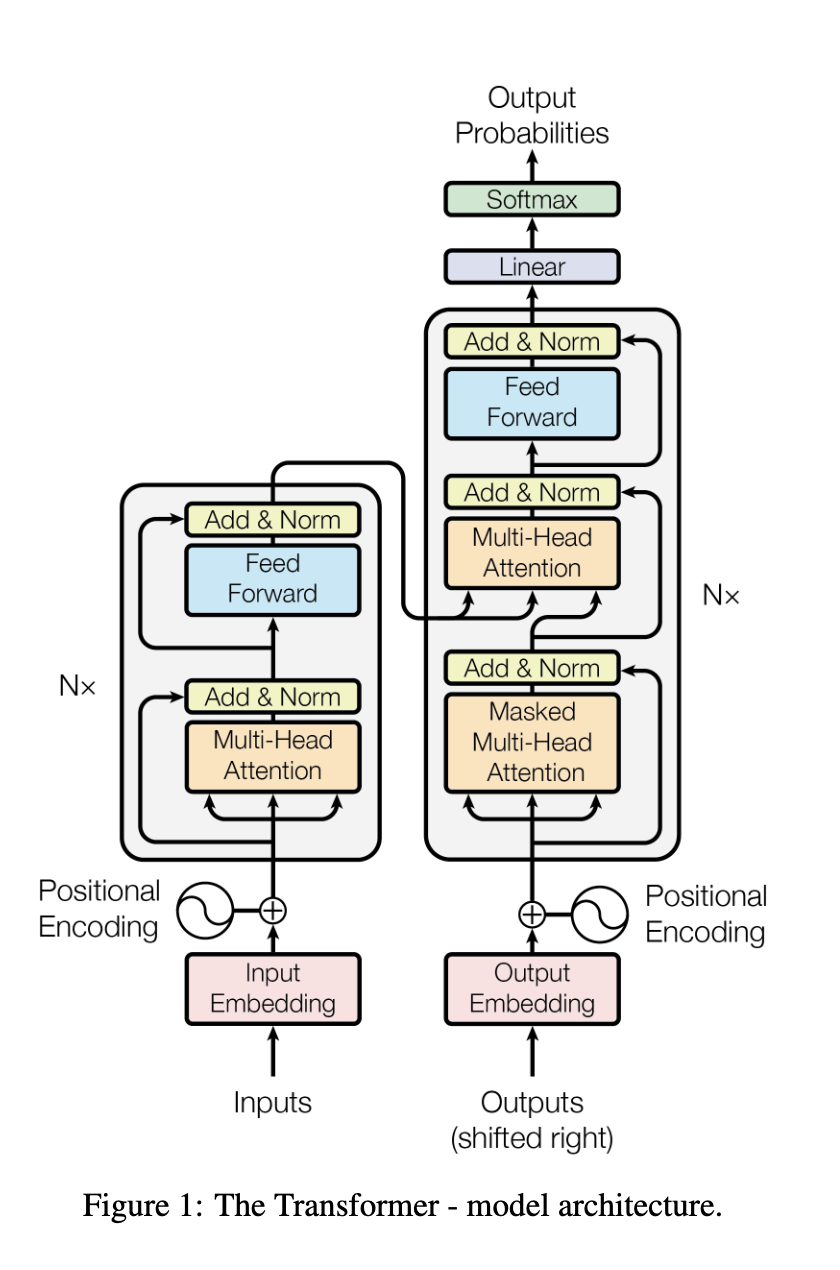
여기 보면, 사실 실제로 구동하는 방식은 Attention 단위가 아니라 Block 단위이다.
class Block(nn.Module):
""" Transformer block: communication followed by computation """
def __init__(self, n_embd, n_head):
# n_embd: embedding dimension, n_head: the number of heads we'd like
super().__init__()
head_size = n_embd // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedFoward(n_embd)
self.ln1 = nn.LayerNorm(n_embd)
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
x = self.sa(x)
x = self.ffwd(x)
return x
Feed Forward
자세한 설명을 보고싶다면, 시리즈중하나로!
class FeedFoward(nn.Module):
""" a simple linear layer followed by a non-linearity """
def __init__(self, n_embd):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd),
nn.ReLU(),
nn.Linear(4 * n_embd, n_embd),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)- Linear Layer : (n_embd,4*n_embd)
- ReLU
- Linear Layer : (4*n_embd,n_embd)
Layer Normalization
Batch Norm에서는, 0 mean과 1 variance.
Batch Norm vs Layer Norm?
Batch Norm에서는 column을 각각 normalize하는 게 아니라
Layer Norm에서는 row를 normalize한다.
최종코드
import torch
import torch.nn as nn
from torch.nn import functional as F
# hyperparameters
batch_size = 16 # how many independent sequences will we process in parallel?
block_size = 32 # what is the maximum context length for predictions?
max_iters = 5000
eval_interval = 100
learning_rate = 1e-3
device = 'cuda' if torch.cuda.is_available() else 'cpu'
eval_iters = 200
n_embd = 64
n_head = 4
n_layer = 4
dropout = 0.0
# ------------
torch.manual_seed(1337)
# wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt
with open('input.txt', 'r', encoding='utf-8') as f:
text = f.read()
# here are all the unique characters that occur in this text
chars = sorted(list(set(text)))
vocab_size = len(chars)
# create a mapping from characters to integers
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers
decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
# Train and test splits
data = torch.tensor(encode(text), dtype=torch.long)
n = int(0.9*len(data)) # first 90% will be train, rest val
train_data = data[:n]
val_data = data[n:]
# data loading
def get_batch(split):
# generate a small batch of data of inputs x and targets y
data = train_data if split == 'train' else val_data
ix = torch.randint(len(data) - block_size, (batch_size,))
x = torch.stack([data[i:i+block_size] for i in ix])
y = torch.stack([data[i+1:i+block_size+1] for i in ix])
x, y = x.to(device), y.to(device)
return x, y
@torch.no_grad()
def estimate_loss():
out = {}
model.eval()
for split in ['train', 'val']:
losses = torch.zeros(eval_iters)
for k in range(eval_iters):
X, Y = get_batch(split)
logits, loss = model(X, Y)
losses[k] = loss.item()
out[split] = losses.mean()
model.train()
return out
class Head(nn.Module):
""" one head of self-attention """
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embd, head_size, bias=False)
self.query = nn.Linear(n_embd, head_size, bias=False)
self.value = nn.Linear(n_embd, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
B,T,C = x.shape
k = self.key(x) # (B,T,C)
q = self.query(x) # (B,T,C)
# compute attention scores ("affinities")
wei = q @ k.transpose(-2,-1) * C**-0.5 # (B, T, C) @ (B, C, T) -> (B, T, T)
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)
wei = F.softmax(wei, dim=-1) # (B, T, T)
wei = self.dropout(wei)
# perform the weighted aggregation of the values
v = self.value(x) # (B,T,C)
out = wei @ v # (B, T, T) @ (B, T, C) -> (B, T, C)
return out
class MultiHeadAttention(nn.Module):
""" multiple heads of self-attention in parallel """
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(n_embd, n_embd)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out
class FeedFoward(nn.Module):
""" a simple linear layer followed by a non-linearity """
def __init__(self, n_embd):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd),
nn.ReLU(),
nn.Linear(4 * n_embd, n_embd),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
class Block(nn.Module):
""" Transformer block: communication followed by computation """
def __init__(self, n_embd, n_head):
# n_embd: embedding dimension, n_head: the number of heads we'd like
super().__init__()
head_size = n_embd // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedFoward(n_embd)
self.ln1 = nn.LayerNorm(n_embd)
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
return x
# super simple bigram model
class BigramLanguageModel(nn.Module):
def __init__(self):
super().__init__()
# each token directly reads off the logits for the next token from a lookup table
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
self.position_embedding_table = nn.Embedding(block_size, n_embd)
self.blocks = nn.Sequential(*[Block(n_embd, n_head=n_head) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embd) # final layer norm
self.lm_head = nn.Linear(n_embd, vocab_size)
def forward(self, idx, targets=None):
B, T = idx.shape
# idx and targets are both (B,T) tensor of integers
tok_emb = self.token_embedding_table(idx) # (B,T,C)
pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)
x = tok_emb + pos_emb # (B,T,C)
x = self.blocks(x) # (B,T,C)
x = self.ln_f(x) # (B,T,C)
logits = self.lm_head(x) # (B,T,vocab_size)
if targets is None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
# idx is (B, T) array of indices in the current context
for _ in range(max_new_tokens):
# crop idx to the last block_size tokens
idx_cond = idx[:, -block_size:]
# get the predictions
logits, loss = self(idx_cond)
# focus only on the last time step
logits = logits[:, -1, :] # becomes (B, C)
# apply softmax to get probabilities
probs = F.softmax(logits, dim=-1) # (B, C)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idx
model = BigramLanguageModel()
m = model.to(device)
# print the number of parameters in the model
print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')
# create a PyTorch optimizer
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
for iter in range(max_iters):
# every once in a while evaluate the loss on train and val sets
if iter % eval_interval == 0 or iter == max_iters - 1:
losses = estimate_loss()
print(f"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
# sample a batch of data
xb, yb = get_batch('train')
# evaluate the loss
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# generate from the model
context = torch.zeros((1, 1), dtype=torch.long, device=device)
print(decode(m.generate(context, max_new_tokens=2000)[0].tolist()))