GPT2
1.GPT 2 from scratch - (1) RNN, LSTM
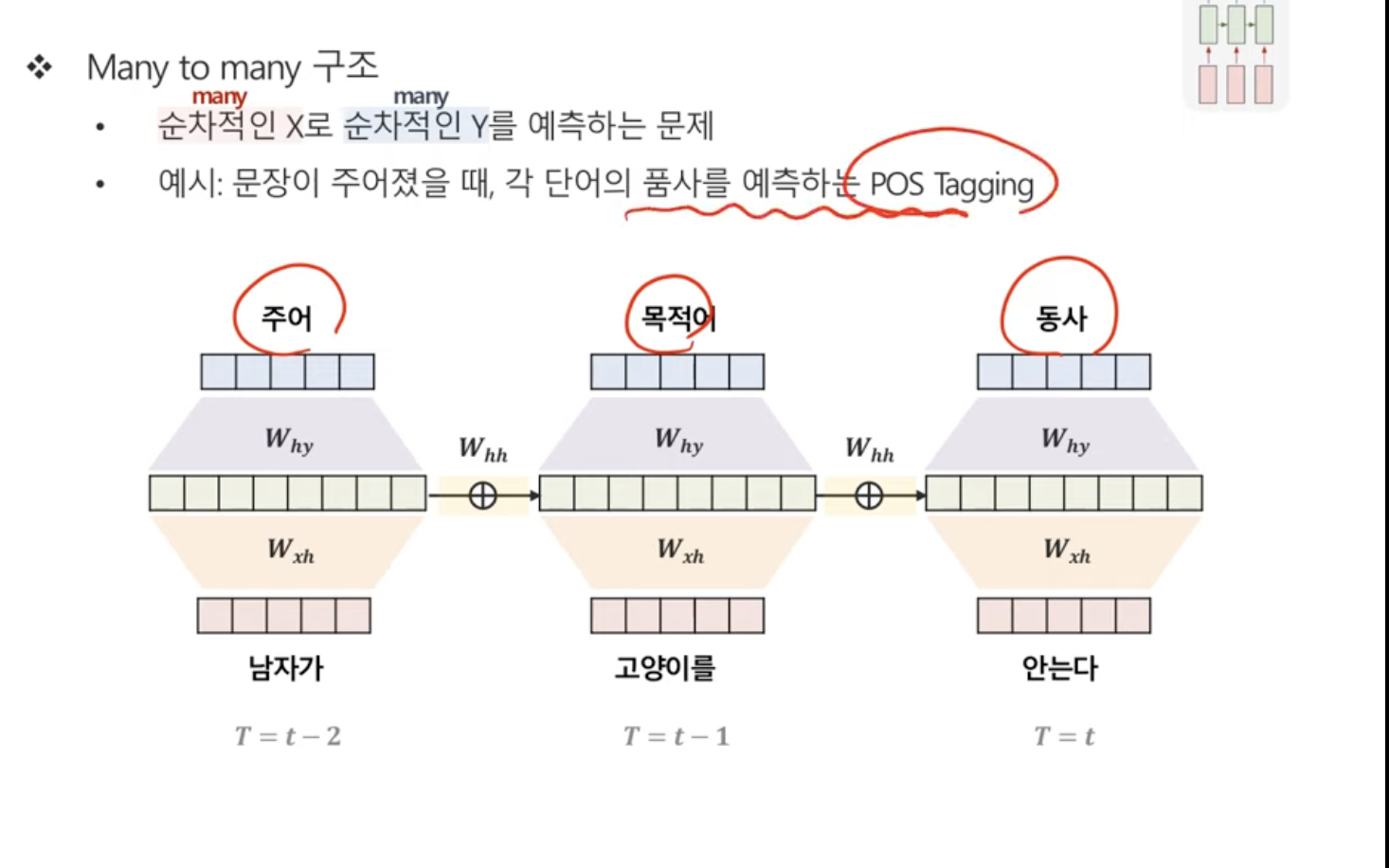
원래 공부해야하는 영상은 사실 GPT2 from scratch인데, 예전에 공부한 것을 까먹어서...다시 작성을 해본다. 아주
2.GPT 2 from scratch - (2) Transformer

Transformer의 경우, 예전에 혁펜하임 강의를 구매해서 들었는데... 지금은 시간이 없는 관계로 !! 압축된 강의를...ㅎㅎ 듣고자 한다. Preparation Weight 통과 쉽게 말하면 특정 벡터에 가중치를 곱하는 것이라고 할 수 있다. linear c
3.GPT from Scratch - (3) Layer Normalization 과 Skip Connection
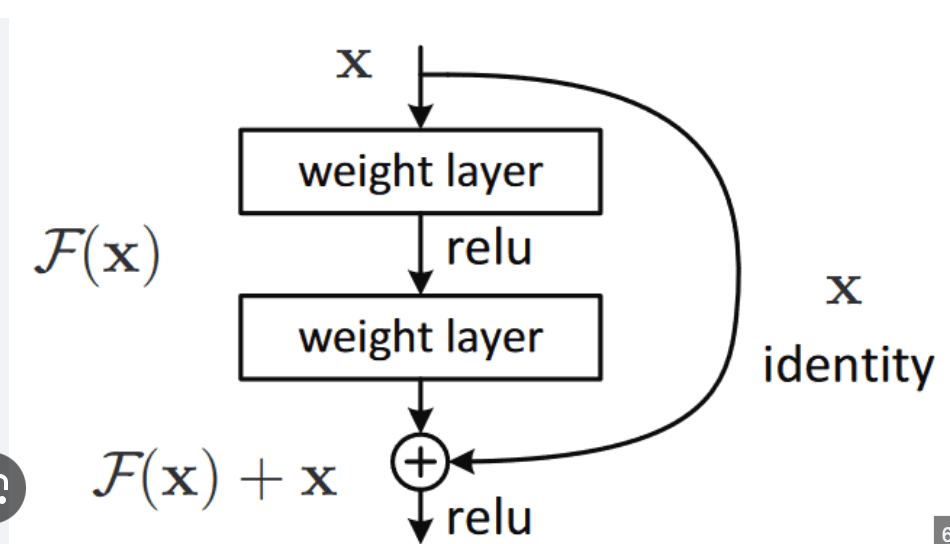
그냥 간단하게 넘길라 했는데 GPT에 이 내용이 나와서 어쩔 수 없이 적는다. Skip Connection은, 출처 : 위키독스기존에는, 그냥 input이 들어가면 function은 아웃풋을 예측하도록 만들어졌는데,Skip Connection은 input이 들어가면 f
4.GPT from Scratch - (4) Transformer 특징
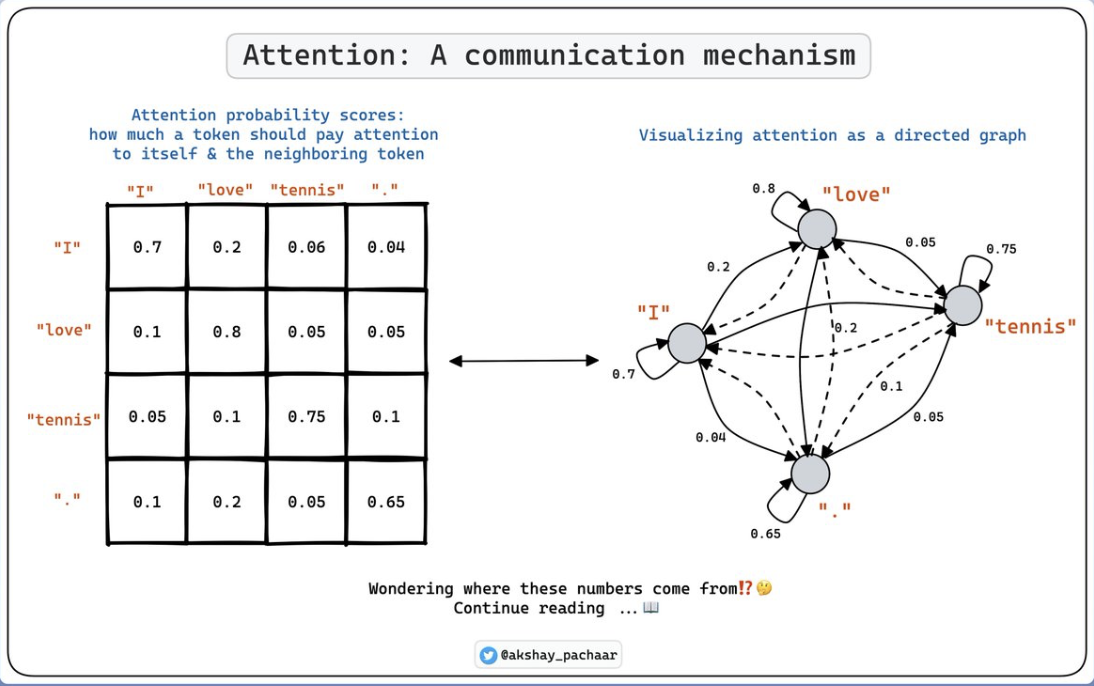
Transformer에 대해 (2)번째 포스트에서 다뤘었는데!! 아무래도 Transformer의 특징에 대해서는 깊게 다루지 못한 것 같아 포스팅을 작성하게 되었다.출처 : https://www.youtube.com/watch?v=kCc8FmEb1nY&t=43
5.GPT from scratch - (5) FFN (Feed Forward Network)
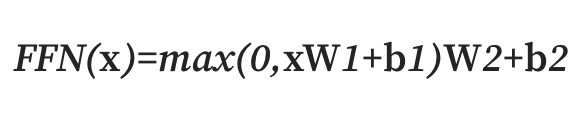
입력층 - 은닉층 - 출력층 Fully Connected Layer : 512차원에서 2048차원으로 만들어주기 Activation Function : ReLU(x) = max(0,x) Fully Connected Layer : 2048차원에서 512차원으로 만들어주기
6.GPT 2 from scratch - (6) GPT
여기서도 역시 Attention 얘기부터 시작한다. 'Attention is All You Need' Attention에 관한 나의 설명을 보고 싶다면, GPT시리즈에 있는 두번째 게시물을 참고하면 된다! 여기에서는, Transformer based languag