multi-armed bandit

매번 동일한 돈이 나오지는 않음.
어떤 기계는 더 많은 보상금을, 어떤 머신은 평균적으로 나오는!
우리는, 도박장에서 도박에 대한 정보가 정말 아무것도 없다.
이때 어느 밴딩머신을 땡길 것인지는 우리에게 달려있다.
- 우리가 하게 될 것은?
- 랜덤하게 시도하여 탐색을 한다. exploration!
- 시도를 통한 보상값을 보고 행동 결정. 누적된 정보를 바탕으로 선택!
이것의 목적은,
주어져 있는 횟수에서 총 보상을 최대화하기 위한 슬롯머신을 선택하는 것이다.
예시
의사도, 어떤 약이 주어진 질환을 해결할지 모른다...
임상시험을 통해 피드백을 하고 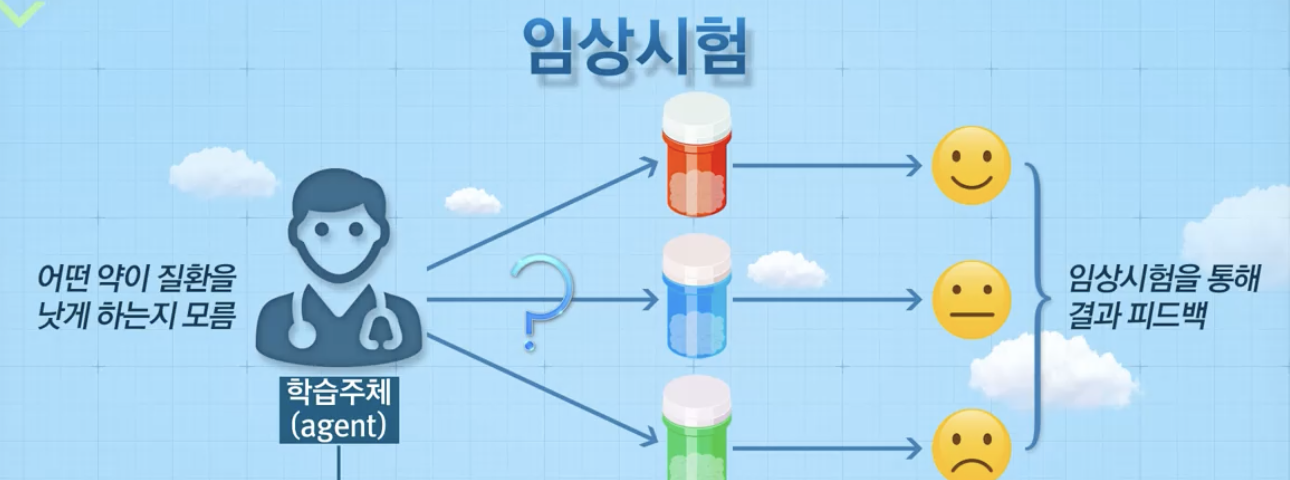
어느 약이 좋다, 나쁘다를 가지고 행동 결정!
일정 기간 동안 취득한 보상의 총합에 대한 기댓값을 최대화하도록!
그럼 어떤 action을 취했을 때, 그게 좋은지 나쁜지 어떻게 알아?
그것이 바로! action values...
: 특정 시점에서 어떤 행동을 취했을 때의 보상에 대한 기댓값
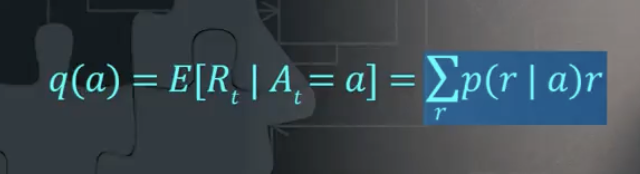
식만 보면 어려울 수 있는데 잘 살펴보면,
1) 행동가치 q(a)
2) a라는 액션이 있을때 받을 R 리워드의 expectation인 것.
3) 매번 reward와 action을 했을 때의 그 reward를 받을 확률을 곱하여 다 더한 것!
1) 2) 3) 이 다 같은 말이지...! 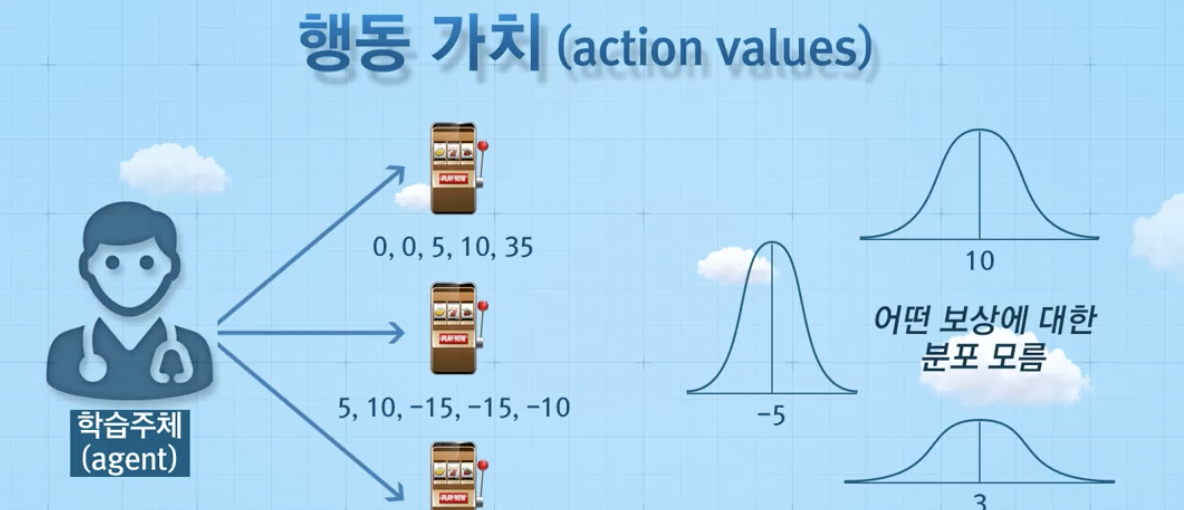
여기서 문제는, 우리가 p(r|a)를 전혀 알 수가 없음...
만약, 우리가 distribution을 완전히 안다면?

완벽하게 q(a)를 알 수 있을 것이다.
하지만 그렇지 못한 것이 현실...
=> trial을 통해서 추정을 해보자 ! ! ! ! ! !
=> 그러면 그때는 우리가 가장 좋은 슬롯머신을 찾을 수 있지 않을까? ! ! ! !
그러면 가장 그 단순한 방법은?
가장 단순한 방법


빨간 약을 먹었을 때, 2번중에 1번 성공했으면 그건 값이 0.5겠지, 하지만 아직 시도해보지 않은 것은 계속해서 0으로 유지가 될 것임.
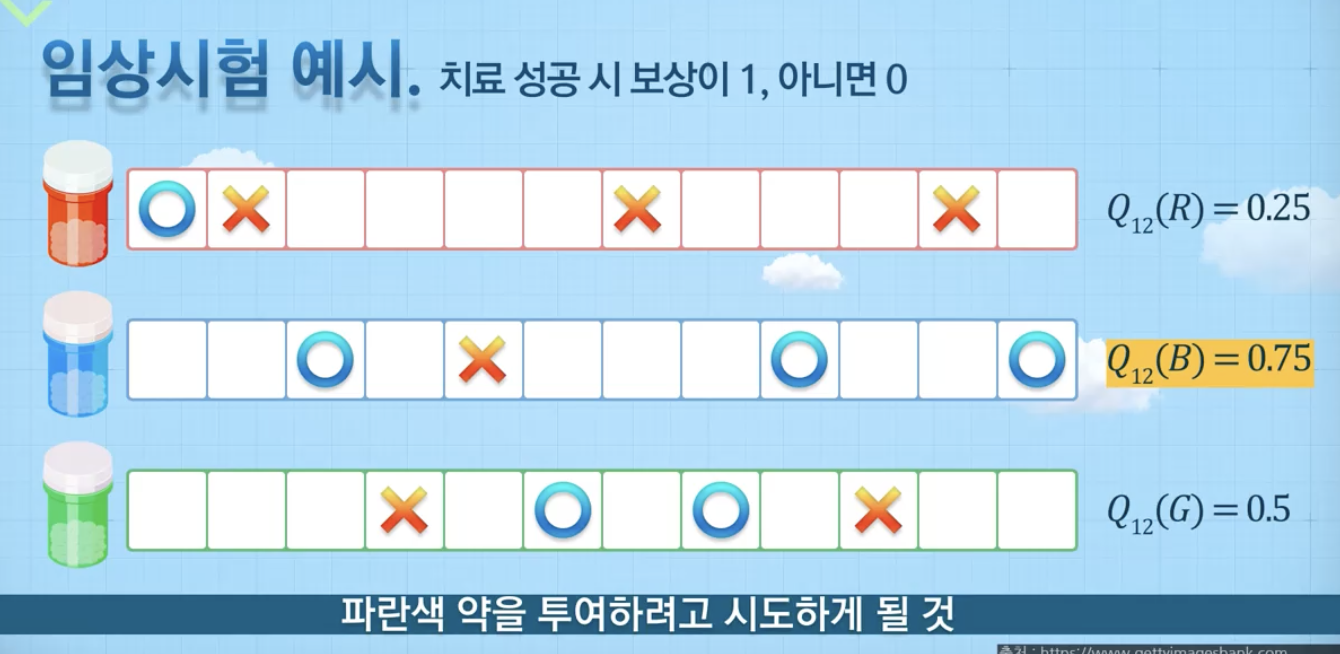
이렇게 되면 파란색 약을 투여하려고 하겠지???
=> 근데, 매번 행동 가치 추정치를 계산하게 되면 힘드니까, 효율적으로 계산을 할 수 있는 방법이 없을까!? 
매단계마다 계산하면 매우 힘들다...
개선방법

결론적으로, 새로 얻게 되는 행동 가치 추정치는, 저 마지막 수식으로 해석이 가능하다.
그때까지의 이전값 + 현재값을 더하는 그런 느낌이라고 생각하면 될듯.
