
-
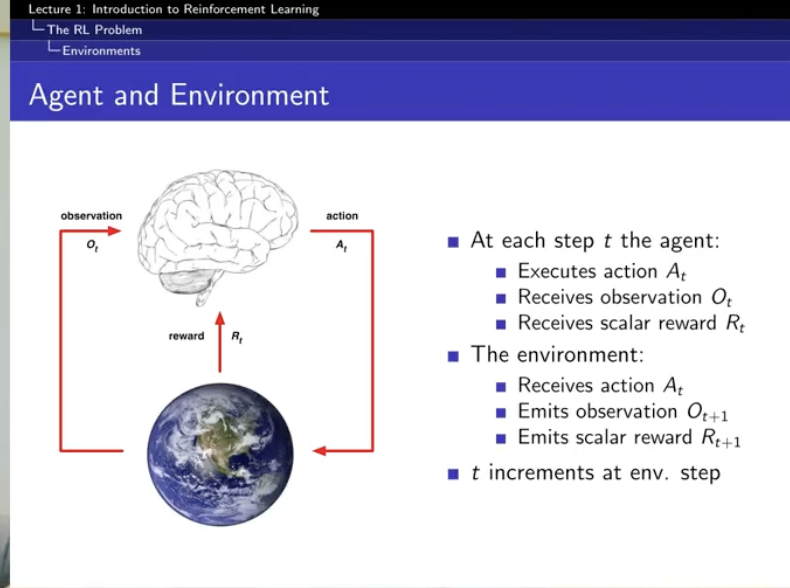
reward signal
정답이 알려주는 사람 없이, 에이전트가 리워드 신호만 받으면서 좋은 방법론을 찾아가는 것 ! ! ! !
supervisor가 없이 ! ! !
== 자기주도학습 잘 하는 학생
reward : 니가 알아서 해! -
feedback is delayed
supervised learning에서는 지연 학습 이런 게 없지만... -
time really matters
supervised learning 에서는 independent & identically distributed.
하지만, 강화학습은 sequential ... 오. -
agent's action affect the subsequent data it receives
아 순간적으로 학습하는 건가?


reward는 숫자 scalar 하나 !! !
하지만, 여기서는 cumulative reward...라는 것!
(현재말고 전체를 봐서)
그러면, 굳이 스칼라로 치환해서 안되는 그런 문제들은??...(ex.벡터)
=> 뭔가 조작을 해야하겠군.

(예시)

하 한번 결정 잘 하면 안되고, 지속적으로 결정을 잘해야함.
greedy하게 하면 안되고 long-term을 언제나 생각해야함. 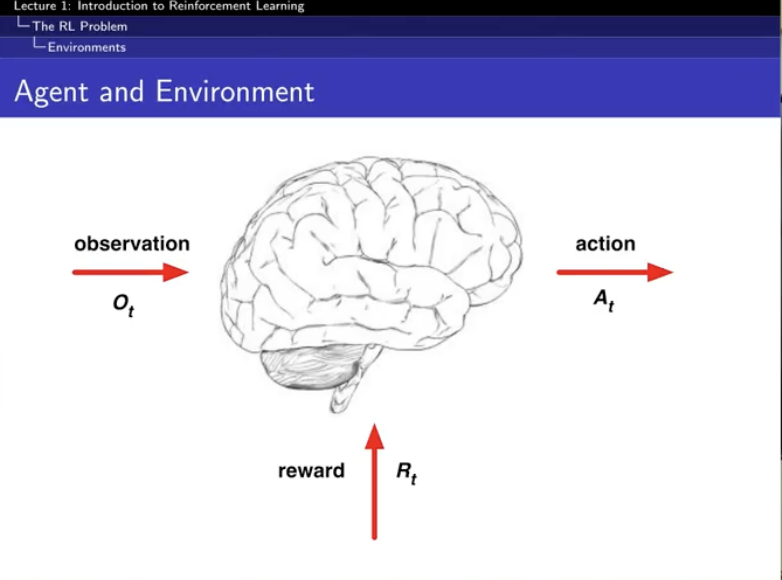
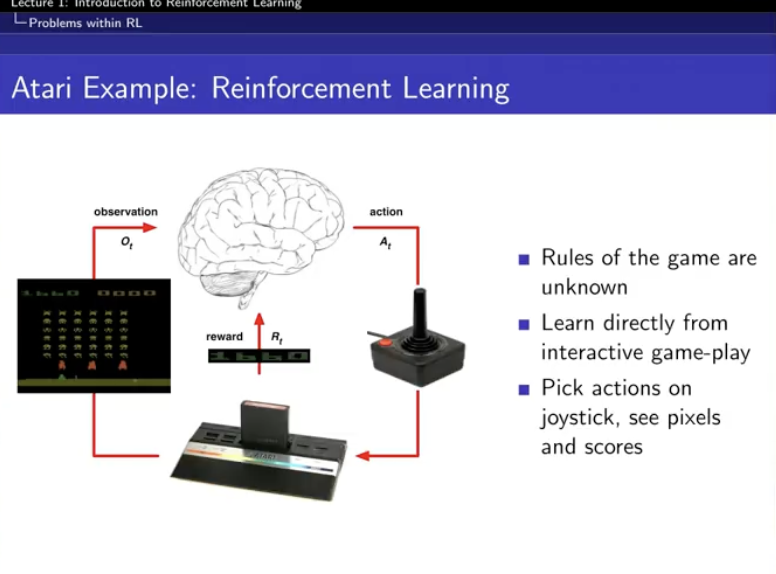
llm agent, 주식 포트폴리오 알고리즘이 저 뇌

state : history에 함수를 씌운 것
= f : 과거 자체를 다 볼 수는 함수
= f : 과거 중 하나만 보는 함수
= 즉, history의 어떤 부분에 가중치를 둘 지 생각할 수 있는 것임.
얘는 그럼 실시간으로 학습하는 거네?
llm한테 프롬프트를 그냥 주입하는 것은 inference였고, 전혀 llm의 internal state에 영향이 없었는데
얘는 inference + learing을 동시에 하다보니 internal state를 바꿀 수 있음.
llm chat history vs RL에서의 history
1 시점에서의 Agent A의 message+ 1 시점에서의 Agent B의 message + 2 시점에서의 Agent A의 message = chat history : 단순히 inference 때의 prompt의 일부로 들어감
O,R,A = H = RL history : learning에 사용
- environment state

environment의 state는 뭔데?
== obv + reward + action 을 관찰한 후 , 다음 obv값은?
== f (Ht) == f (obv + reward + action )
[근데 여기 f가 history를 가지고 environment의 state를 알아내는 함수인거지]
-> 다음 enviornment를 예측하기 위해 필요한 feature들 + 그 feature의 값들!
-> 내부에서 돌아가고 있는 것들@!!! !! ! !
- agent state

agnet의 state는 뭔데?
== obv + reward + action 을 관찰한 후 , 다음 obv값은?
== f (Ht) == f (obv + reward + action )
[근데 여기 f가 history를 가지고 agent에게 필요한 정보들을 알아내는 함수인거지]
ex) 삼성전자에서 주식할 때 필요한 것들(ex. 블룸버그 뉴스, 어제 매도량, 어제 매수량 등등)
-> 학습할 때 중요하게 생각하는 feature를 추출 + 그 feature의 값들!
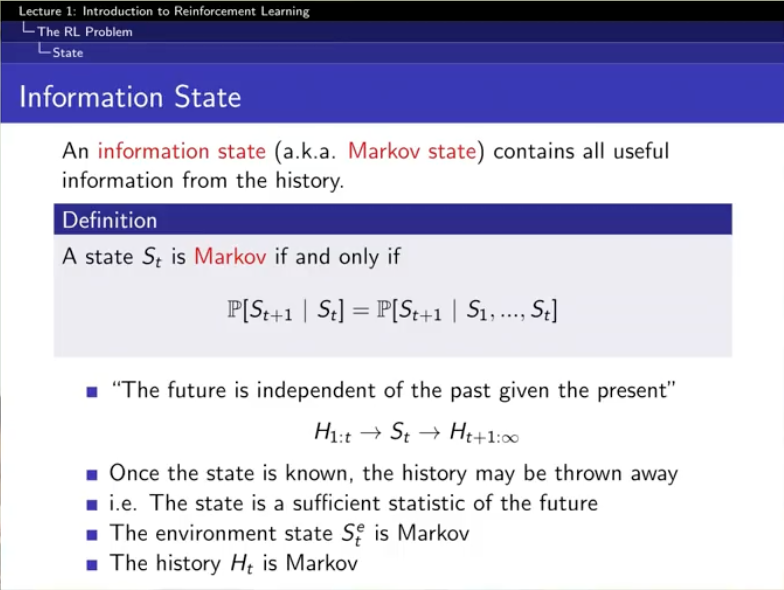
여기서 information state가 등장.
저거라면 markov인거
우리는 이제 쥐...
agent의 state를 어떻게 정하느냐에 따라서 달라지는 것.

MDP

agent state != environment state
agent state : public한 정보들로만 구성됨
environment state : public + private들로 구성 ( 모든 애들 다 ! )
RL agent의 구성 요소

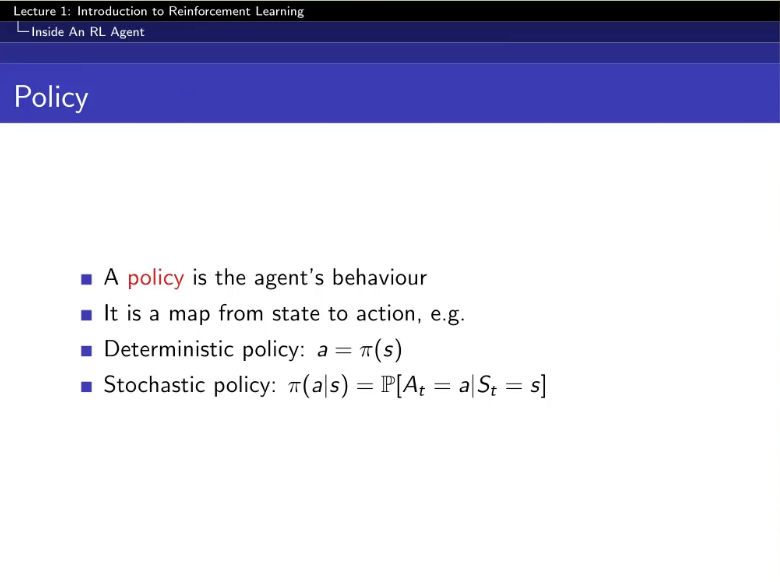
state를 넣으면 action을 뽑아내는!
오 신기
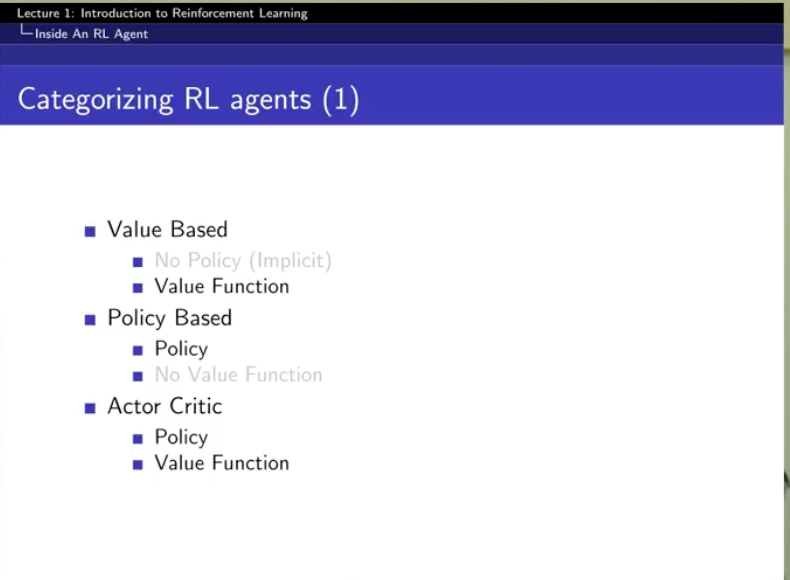
- deterministic policy : 하나의 액션만 !
- stochastic policy : 각 action별 확률을 뱉음

state를 넣으면 value을 뽑아내는!
어떤 Poclicy 파이를 따라갔을 때 예상되는 기댓값인 것임.
감마 : 2000년대의 돈 != 2010년대의 돈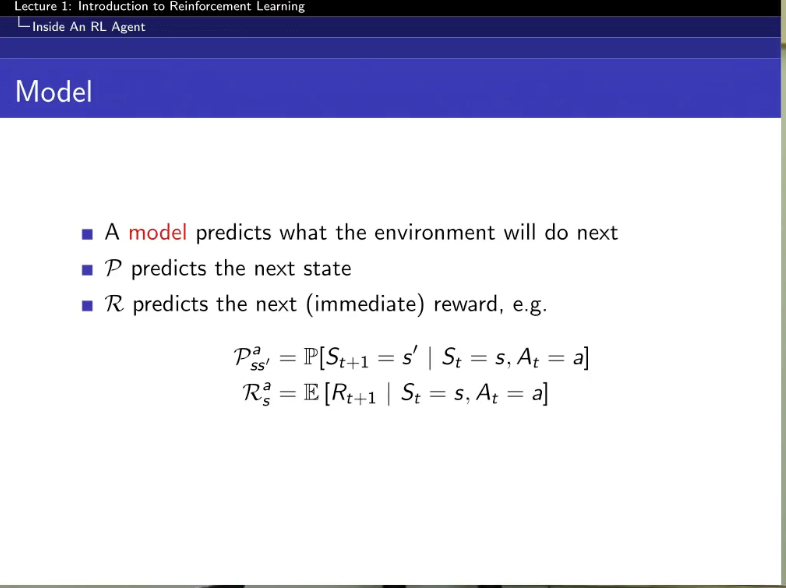
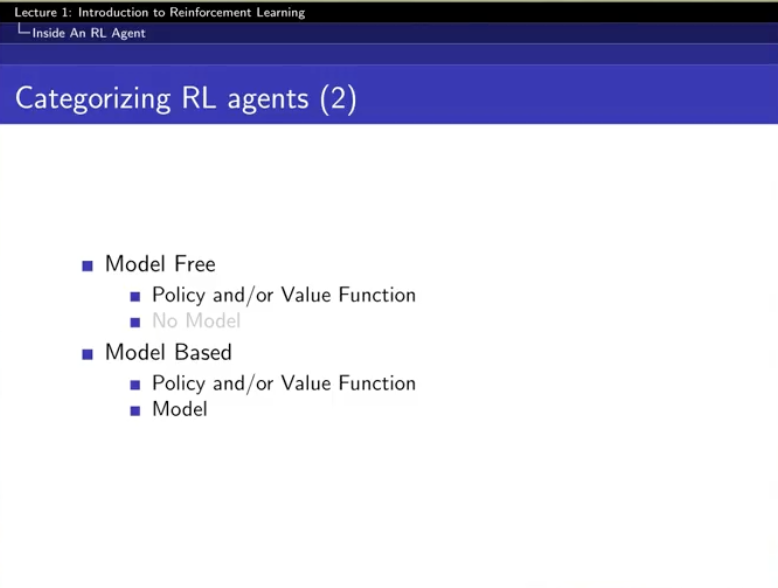
state를 넣으면 환경에 대한 예측값을 뽑아내는 !
1. reward 예측
2. 그다음 state 예측
(모델이 이걸 예측을 한 것이다)
예시
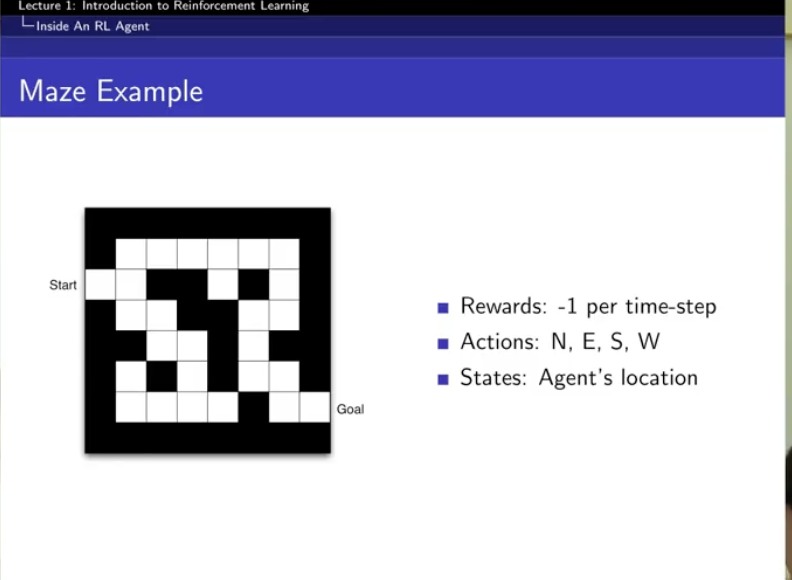
policy : 선택 화살표 
처음에는 아예 검은색 맵인 것임.
Categorizing RL agents
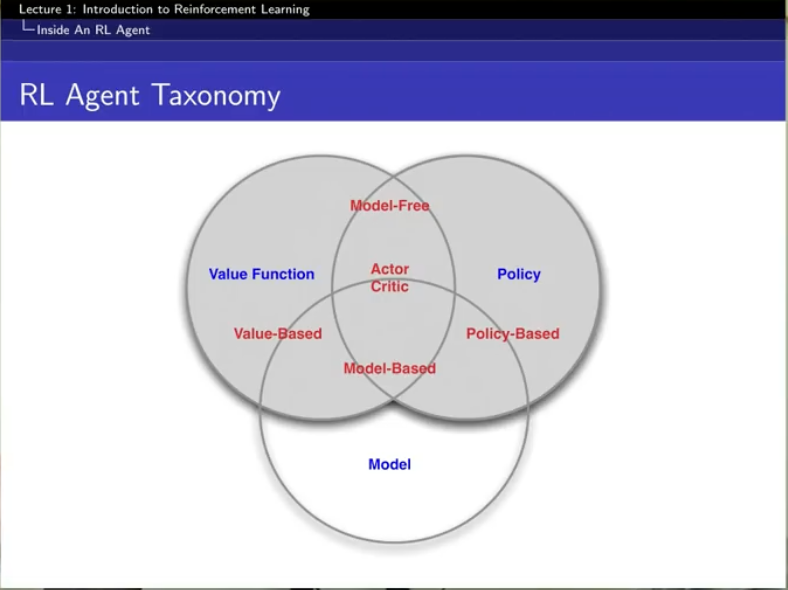
LEARNING AND PLANNING

강화학습은 두개를 합친 것
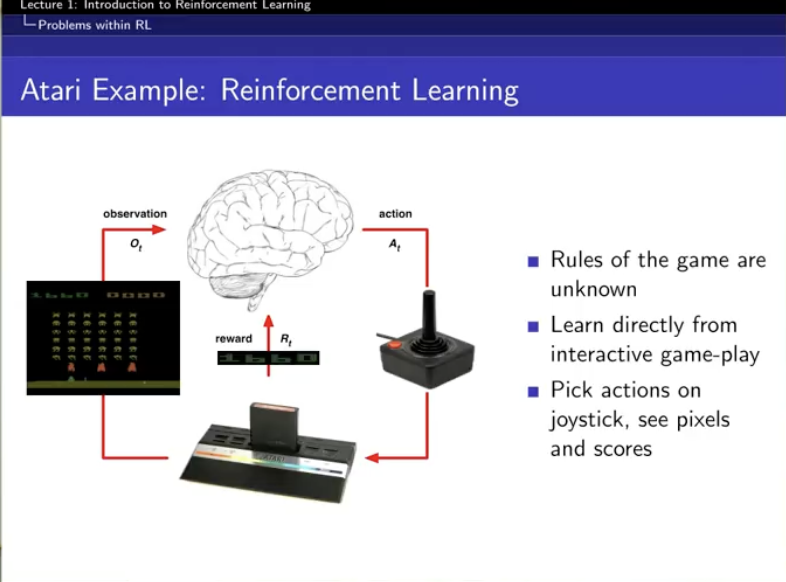
learning : env를 모르는 것. 환경에 그냥 던져진 것. 걔의 policy를 개선시켜가는 게 learning
planning : env를 앎. reward가 어떻게 되는지 알고 transistion이 어떻게 되는지 앎 . (이게 몬테카를로...)


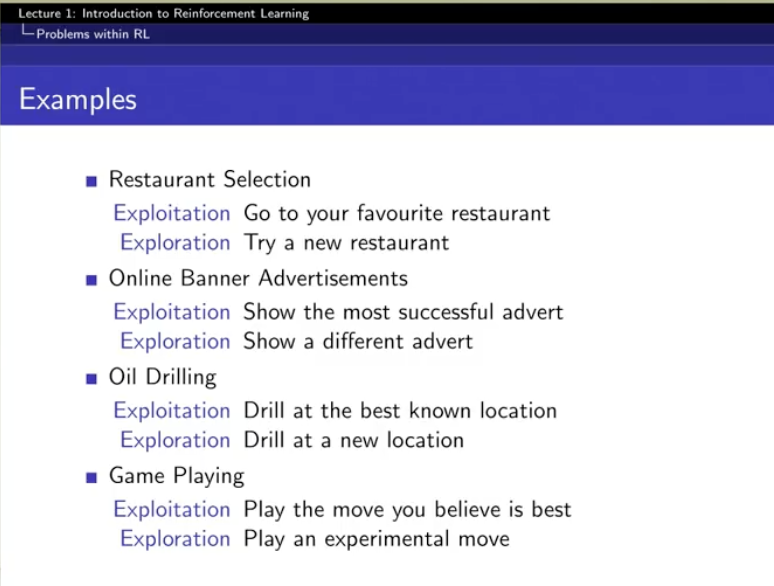
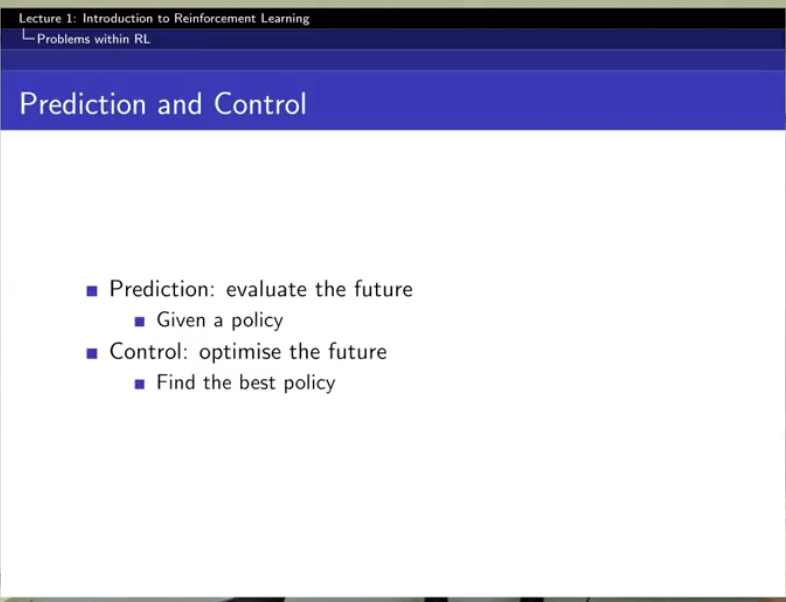
prediction은 value function을 잘 만드는 것
control은 best policy를 찾는 것! 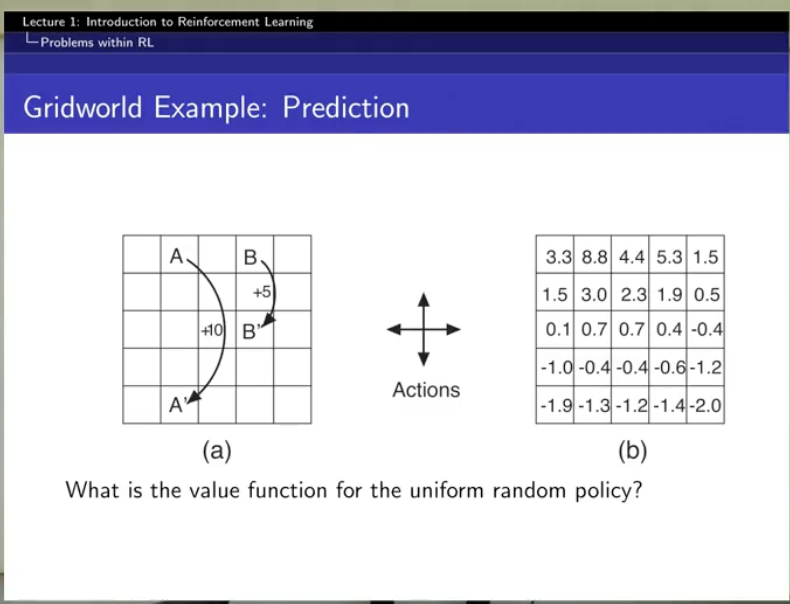
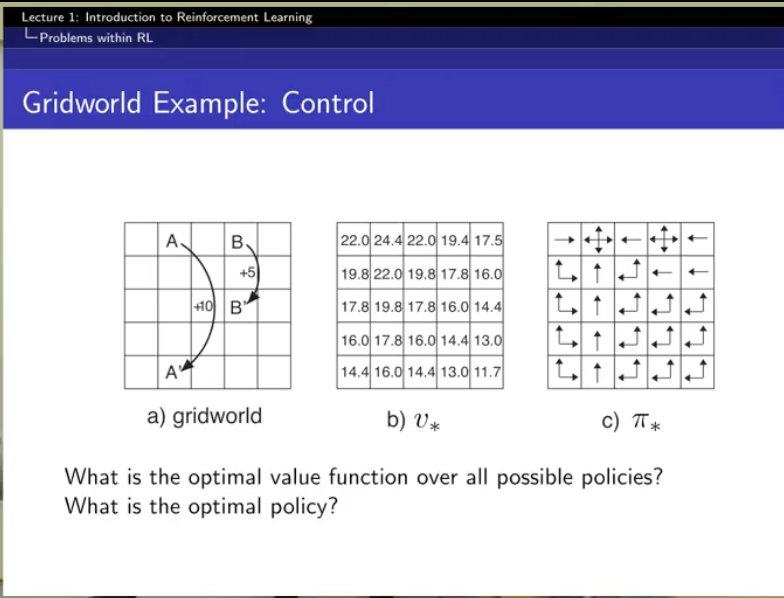
아우 재밌다!
