
LLM agent 연구에 언젠간 활용하고 싶어서 열심히, 강화학습 공부를 노력하고 있지만 쉽지는 않다.
저번거는 다 그냥 노트필기에 해버려서ㅠ올릴 게 못된다...
저번주 스터디에 스터디원분이 구현을 하셔서 오신걸 보고! 깜짝~놀라버려성
나도 한번 구현을 해봐야겠다고 생각했다! ! ! ! ! ! !
그분이 공부하신 방법대로 한번 따라해봤다.
(1) PPT를 곱씹어 보기
(2) 코드를 구현해보기
근데 너무 재밌어서 깜짝 놀랐다
나도 근데 그런 타입(?)인 거 같다!!!




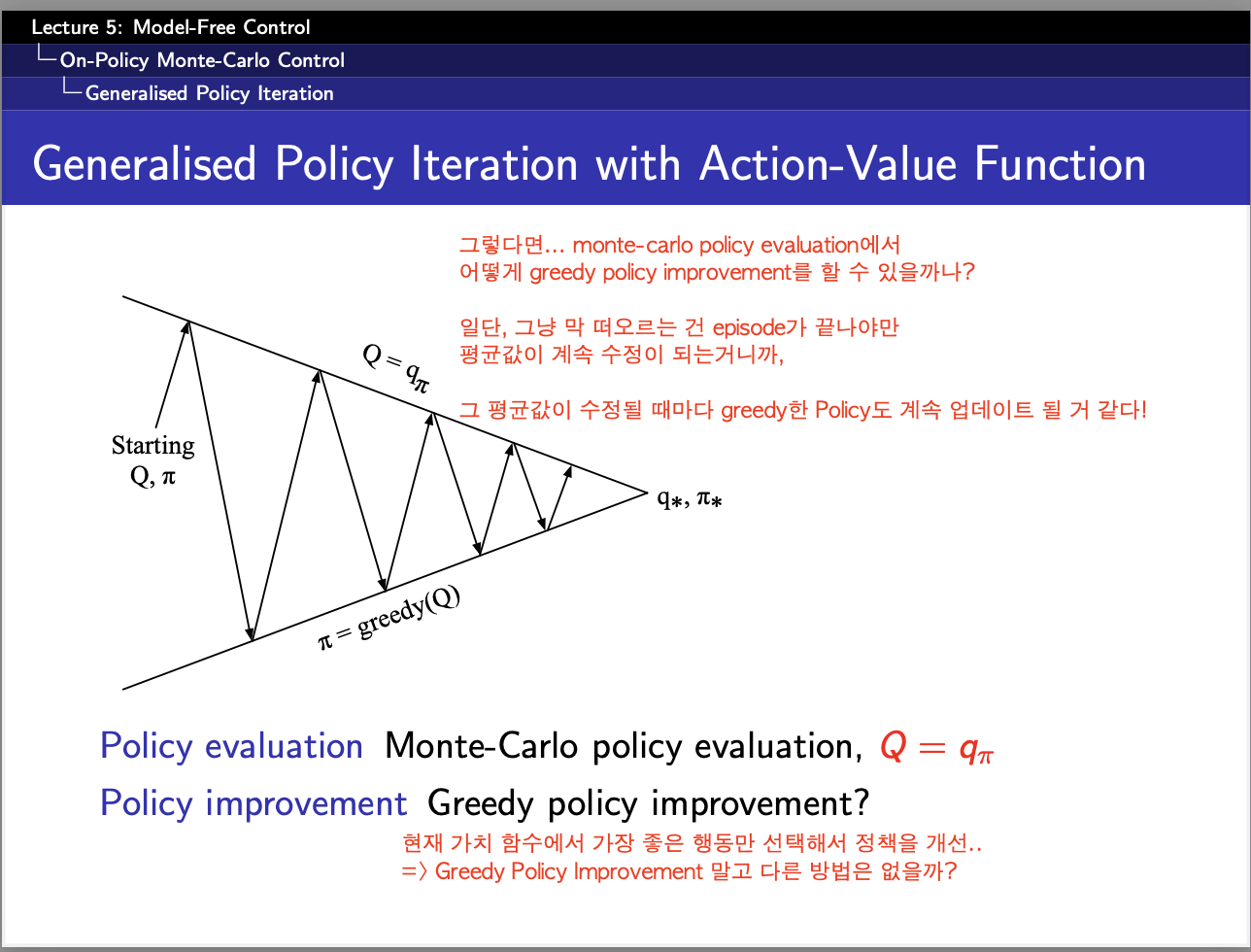
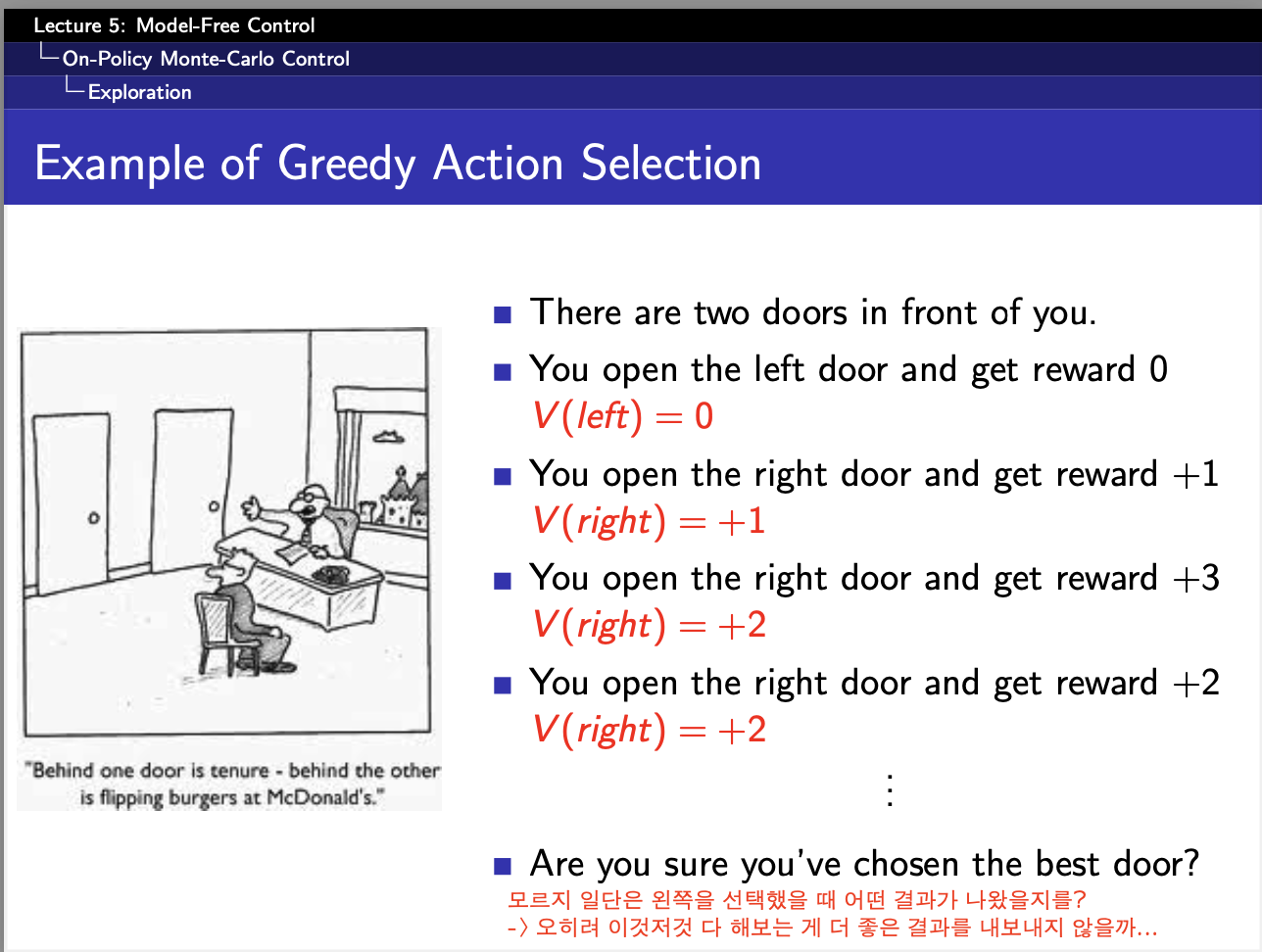


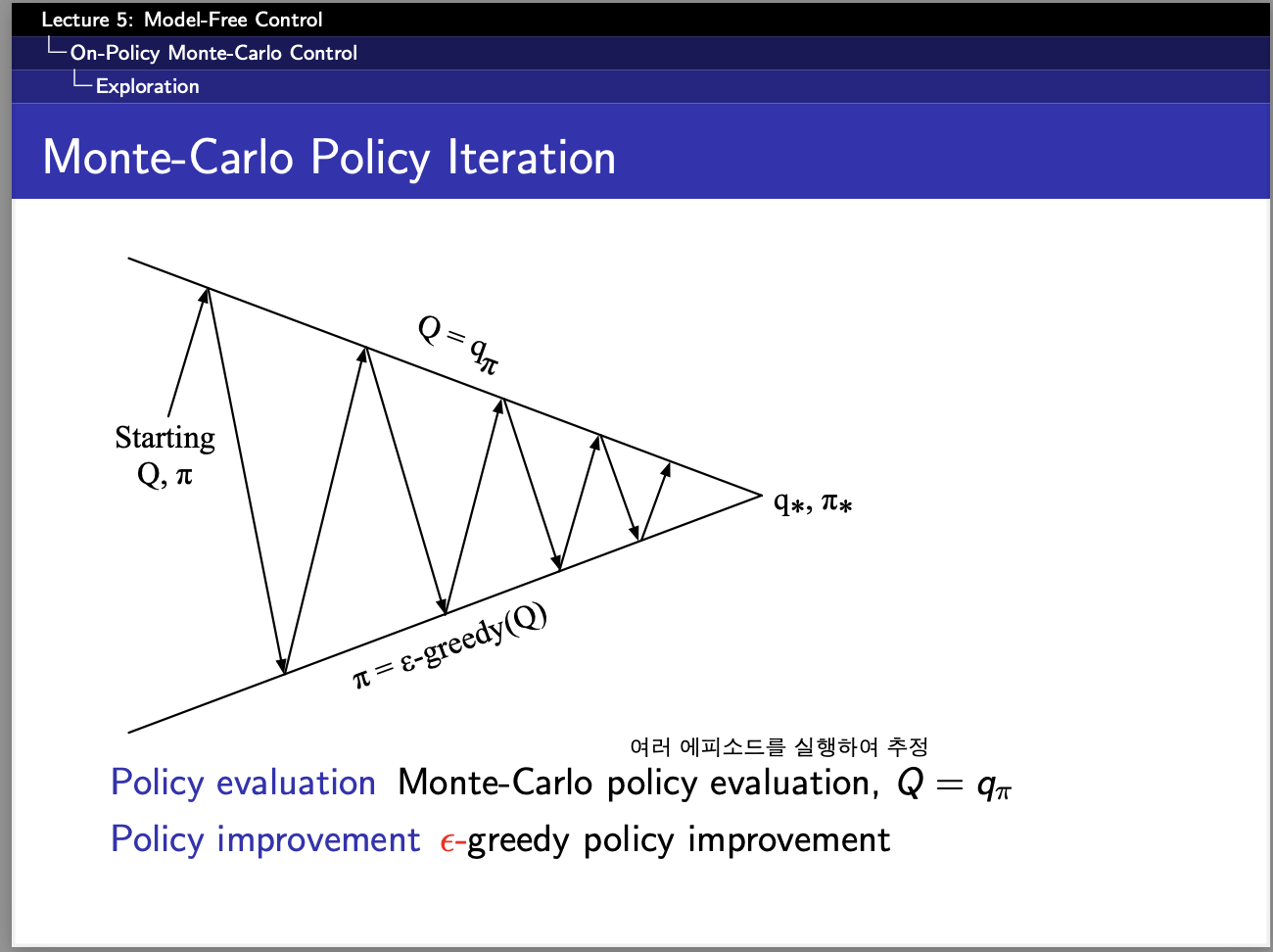
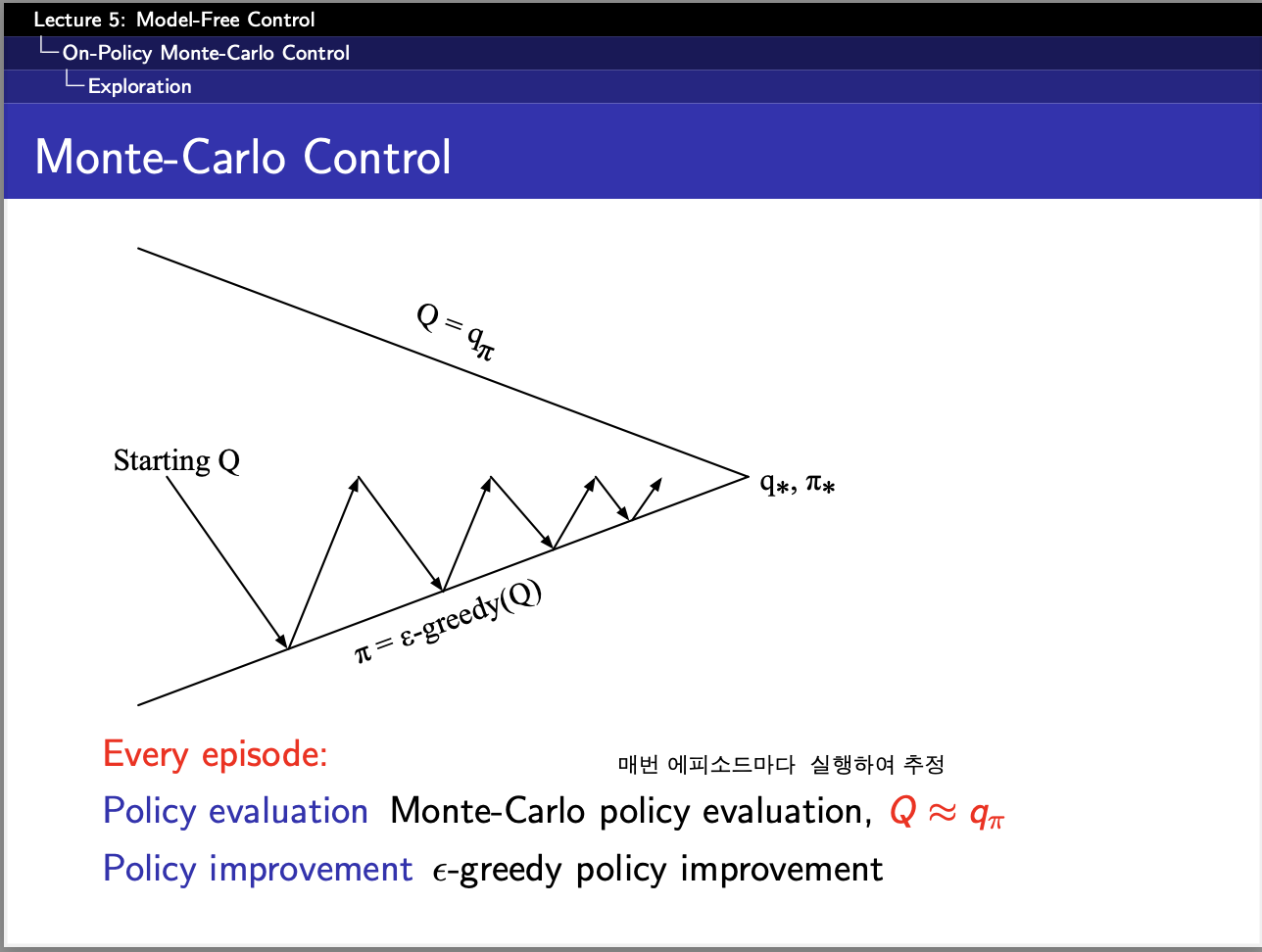





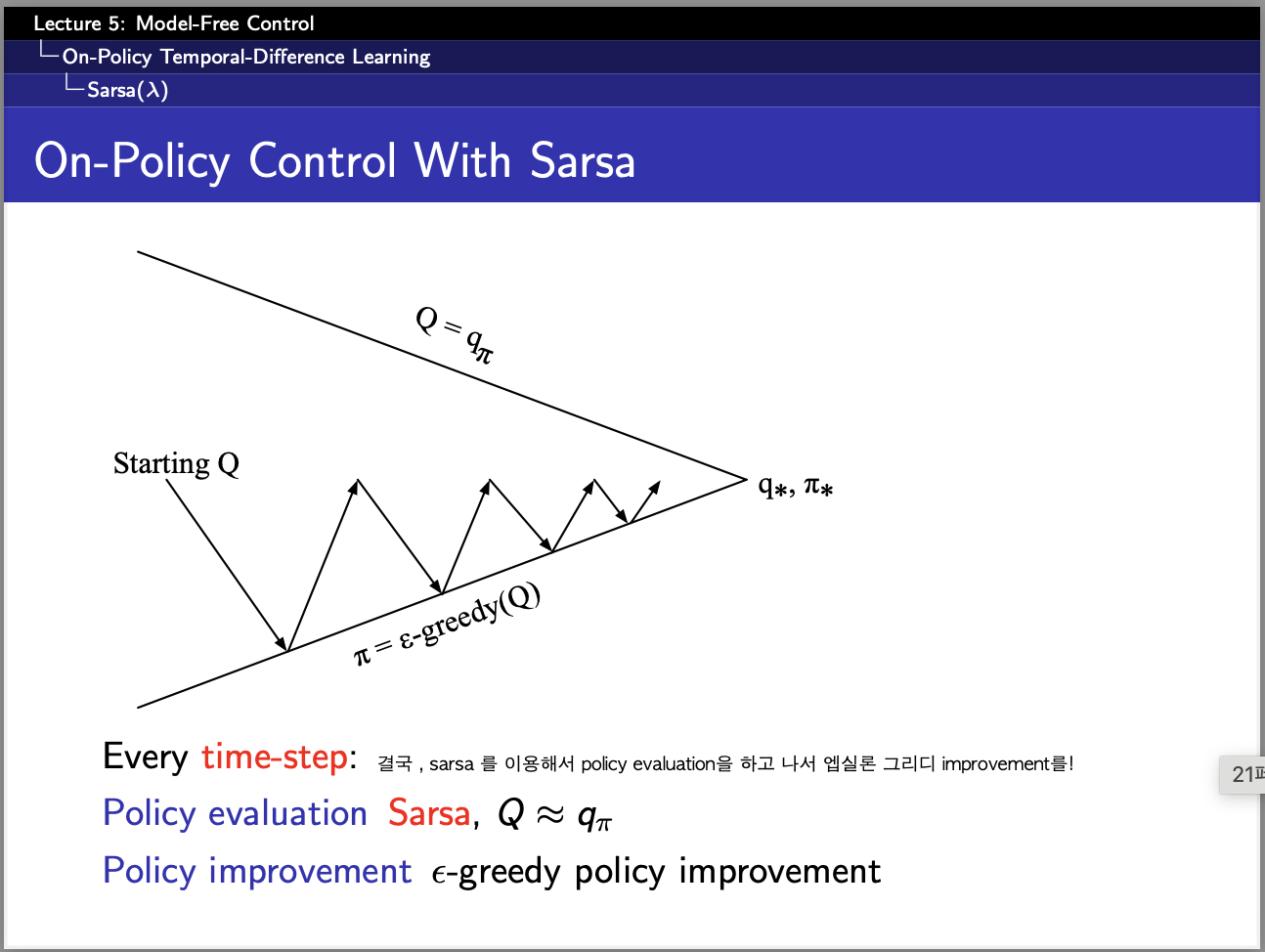


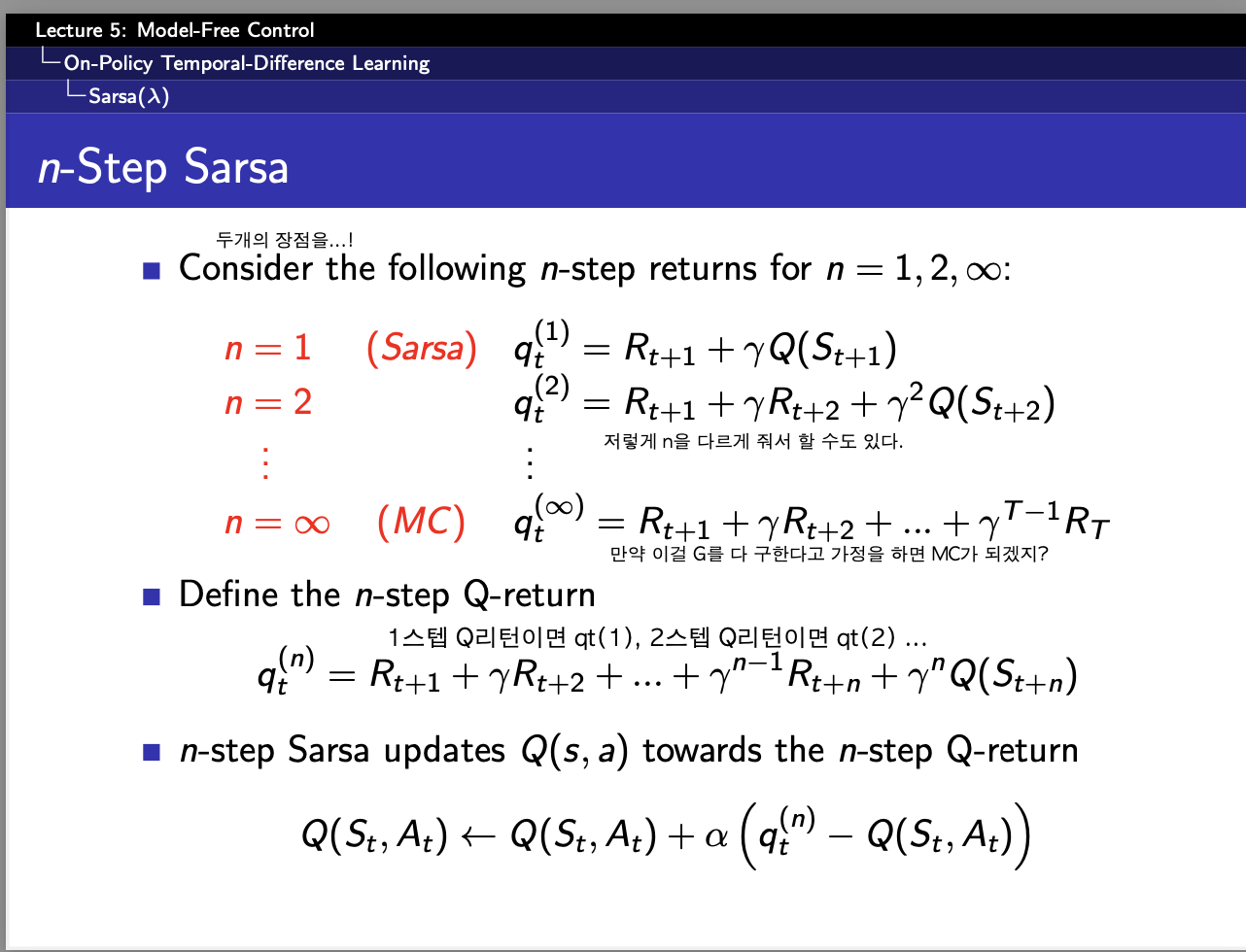

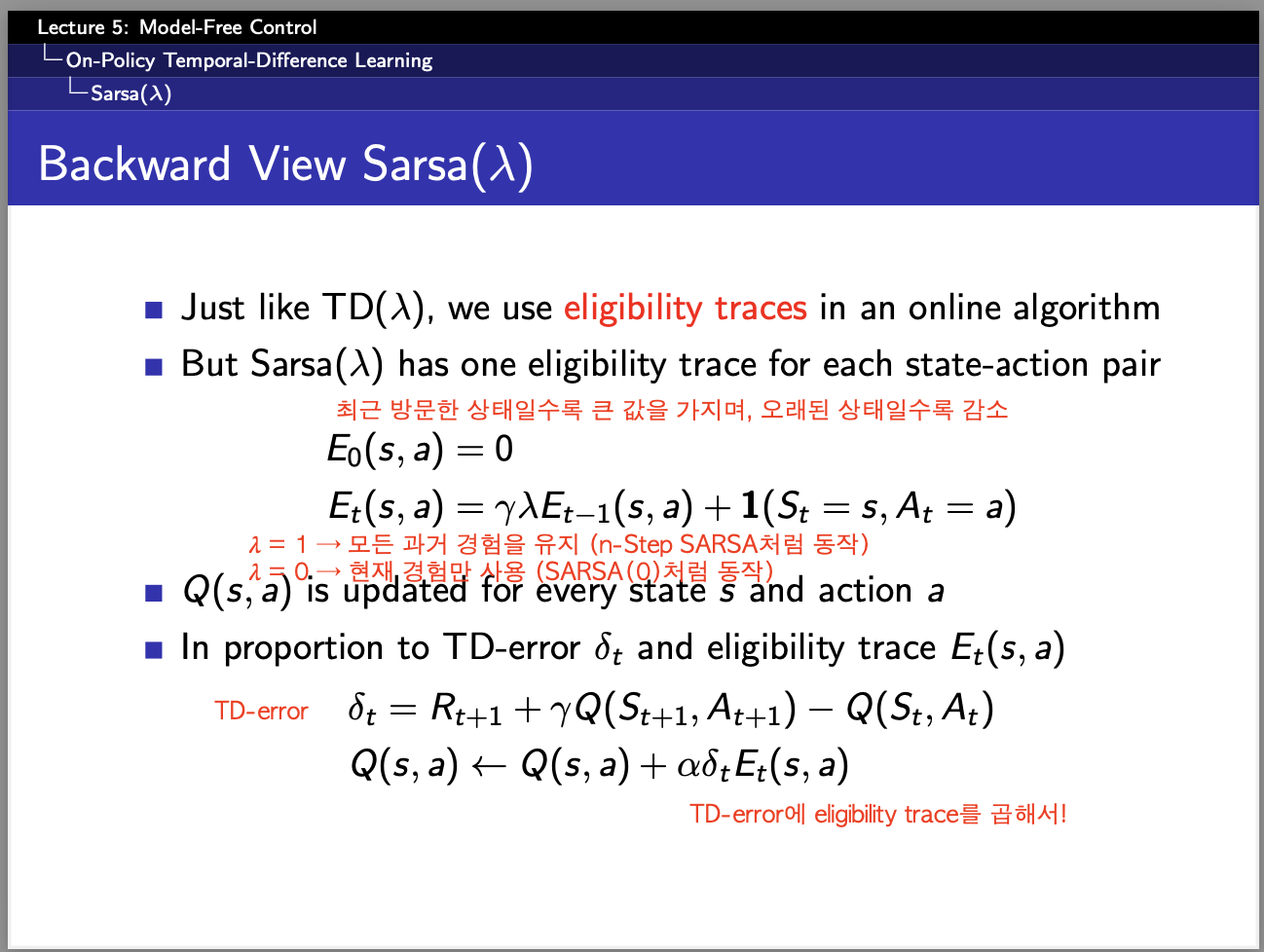

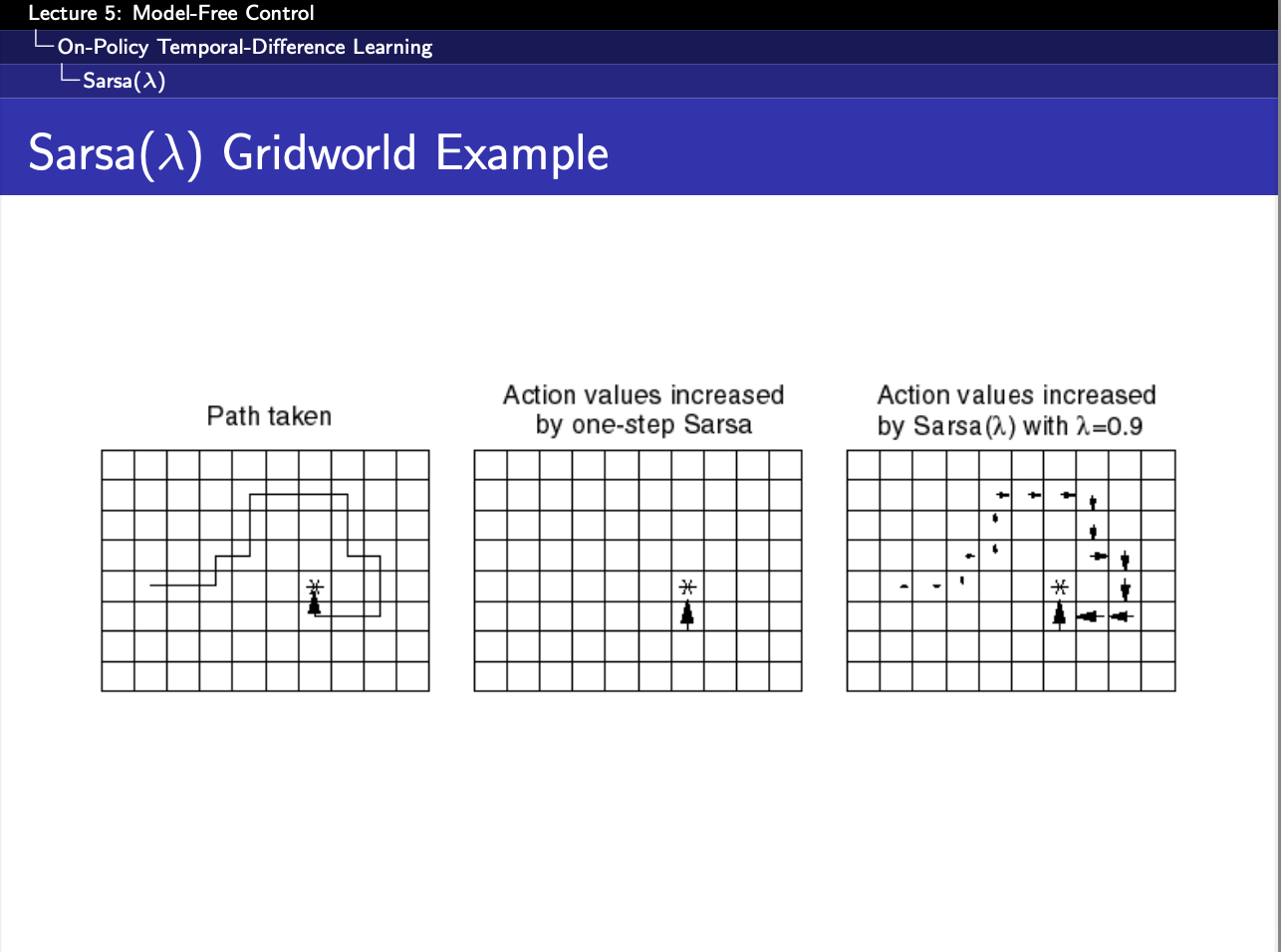






원래 Q-learning도 구현하려고 했으나,,, 시간관계상
일단
"""
THis is a code for Model Free Control in RL.
"""
#### 1. GLIE Monte Carlo Control ####
#==============================================================================
import numpy as np
num_states = 5 # 상태 개수
num_actions = 2 # 행동 개수
num_episodes = 5000
# Q-테이블 초기화 (모든 Q(s,a)를 0으로 시작)
# Q(s,a) == E[ Gt | St= s , At = a]
Q = np.zeros((num_states, num_actions))
# 각 상태에서 방문 횟수 저장
N = np.zeros((num_states, num_actions))
# ε-greedy policy [만약, 저 epsilon이 고정이라면 그냥 exploration만 계속하게 됨]
def epsilon_greedy_policy(Q, state, epsilon):
m = len(Q[state])
best_action = np.argmax(Q[state]) # Q 값이 가장 높은 행동 선택
policy = np.full(m, epsilon / m) # 모든 행동에 대해 ε/m 확률 부여
policy[best_action] += 1 - epsilon # 가장 좋은 행동에는 1 - ε 추가 확률
return np.random.choice(np.arange(m), p=policy)
# 한 번의 에피소드를 실행하면서 데이터를 모으는 코드 (Monte Carlo)
def run_episode(epsilon, max_steps=10):
episode = []
state = np.random.randint(0, num_states) # 랜덤한 초기 상태
while True:
action = epsilon_greedy_policy(Q, state, epsilon) #epsilon_greedy_policy로 탐색과정!
next_state = np.random.randint(0, num_states) #
reward = np.random.randn()
episode.append((state, action, reward))
state = next_state
if len(episode) >= max_steps: # 최대 10번 이동 후 종료
break
return episode
# GLIE Monte Carlo Control 학습
for episode_num in range(1, num_episodes+1):
epsilon = 1 / episode_num # episode를 점점 늘려갈 때마다 epsilon값이 줄어든다.
episode = run_episode(epsilon) #매번 epsilon greedy policy로 탐색을 해서 episode를 만들어낸다.
G = 0 # 매번 그냥 0에서부터 시작. 그 에피소드에서는 G=0인 것임.
visited = set() # 첫 방문 판별용
for state, action, reward in reversed(episode):
G = reward + 0.9 * G # 감가율 = 0.9
if (state, action) not in visited: # 첫 방문인지 확인
visited.add((state, action))
N[state, action] += 1 # 특정 state, 특정 action에 대해 방문 횟수 증가
alpha = 1 / N[state, action] # GLIE 조건: α → 0 (학습율 감소)
Q[state, action] += alpha * (G - Q[state, action]) # Q(s,a) 업데이트
print("학습된 Q 테이블:")
print(Q)
#==============================================================================
#### 2.SARSA ####
def run_episode_next(epsilon, max_steps=10):
episode = []
state = np.random.randint(0, num_states) # 랜덤한 초기 상태
action = epsilon_greedy_policy(Q, state, epsilon) # 초기 행동 선택
while True:
next_state = np.random.randint(0, num_states) # 임의의 환경 이동
reward = np.random.randn()
next_action = epsilon_greedy_policy(Q, next_state, epsilon) # 다음 행동 선택
episode.append((state, action, reward, next_state, next_action))
state, action = next_state, next_action # SARSA는 (s, a, r, s', a') 방식으로 진행!
if len(episode) >= max_steps: # 최대 10번 이동 후 종료
break
return episode
for episode_num in range(1, num_episodes+1):
epsilon = 1 / episode_num # episode를 점점 늘려갈 때마다 epsilon값이 줄어든다.
episode = run_episode_next(epsilon)
visited = set() # 첫 방문 판별용
for state, action, reward, next_state, next_action in reversed(episode):
if (state, action) not in visited:
visited.add((state, action))
N[state, action] += 1 # 방문 횟수 증가
alpha = 1 / N[state, action] # 학습률 감소 (GLIE 조건)
Q[state, action] += alpha * (reward + 0.9 * Q[next_state, next_action] - Q[state, action])
#여기서 매우 중요한 건, 똑같이 저렇게 reversed(episode)를 했다고 하더라도, 저 위에서는 G를 썼지만, 여기서는 그때의 그 reward만을 써서 update를 한다는 것
print("학습된 Q 테이블:")
print(Q)
#### 3.n-step SARSA ####
n_step = 3
alpha = 0.1
for episode_num in range(1, num_episodes + 1):
epsilon = 1 / episode_num # Exploration 감소
episode = run_episode_next(epsilon)
for t in range(len(episode)): # 각 time step에 대해 반복
G = 0 # n-step return 초기화
# 1. n-step 동안 보상 계산
for i in range(n_step): #3번 step이라고 하면 3번 반복해야함.
if t + i < len(episode):
G += (0.9 ** i) * episode[t + i][2] # 이건 보상!!!!
# 2. n-step 후의 Q 값 추가
if t + n_step < len(episode):
G += (0.9 ** n_step) * Q[episode[t + n_step][3], episode[t + n_step][4]]
# 3. Q 업데이트
state, action = episode[t][:2] # 현재 상태, 행동
Q[state, action] += alpha * (G - Q[state, action])
print("학습된 Q 테이블:")
print(Q)
#### 4.backward SARSA ####
alpha = 0.1 # 학습률
gamma = 0.9 # 할인율
lmbda = 0.8 # Eligibility Trace 감쇠율
for episode_num in range(1, num_episodes + 1):
E = np.zeros((num_states, num_actions))
Q = np.zeros((num_states, num_actions))
epsilon = 1 / episode_num # Exploration 감소
episode = run_episode_next(epsilon)
for state, action, reward, next_state, next_action in reversed(episode):
d = reward + 0.9 * Q[next_state,next_action] - Q[state,action]
E[state,action] = E[state,action] + 1 #일단 방문했으니까 +1 증가시킴
#흠 여기까지는 그래도 괜찮은데, 밑의 걸 떠올리는 게 힘들었음.
for s in range(num_states):
for a in range(num_actions):
Q[s, a] += alpha * d * E[s, a] # Q 업데이트
E[s, a] *= gamma * lmbda #(시간이 지나면서 감소)
"""
1. 기본 SARSA와의 비교
Q[state, action] += alpha * (reward + 0.9 * Q[next_state, next_action] - Q[state,action])
=> 이게 기본 SARSA알고리즘
=> Q[state, action] += alpha * (d) 인 것임.
따라서, E[s,a]를 단순히 곱하면
Q[state, action] += alpha * (d) * E[s,a]임
2. 왜 여기서 num_states와 num_actions에 대해 다 계산하니?
Q 값을 업데이트할 때는 현재 상태뿐만 아니라 과거에 방문했던 상태들도 보상의 영향을 받음
이걸 처리하기 위해 모든 상태-행동 쌍에 대해 Eligibility Trace를 곱해서 업데이트!!!!!
"""시간은 많이 걸렸긴한데, 근데 구현해보니까 뭐가 뭔지 알것같긴하다.
그래서 너무 즐겁다~

한발한발 나아갑니당!