


































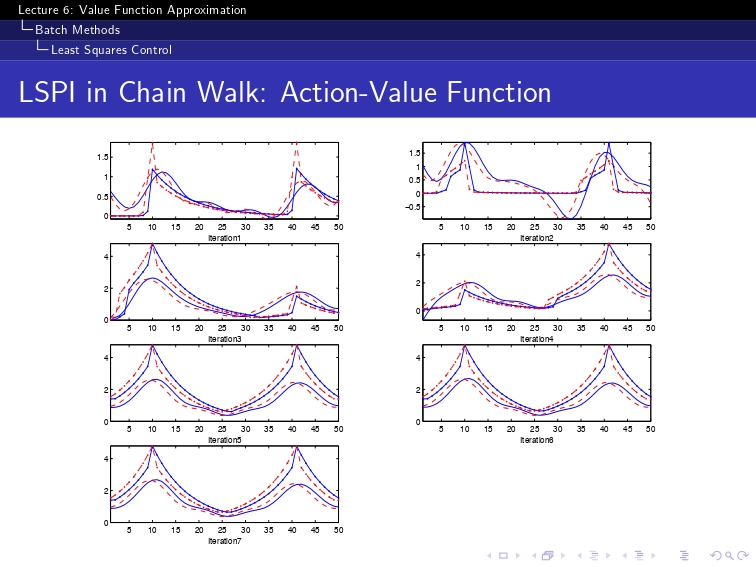

"""
THis is a code for Model Free Control in RL.
"""
# ###1. Monte Carlo Value Function Approximation ###
# #==============================================================================
import numpy as np
num_states = 5 # 상태 개수
num_actions = 2 # 행동 개수
num_episodes = 5000
# 가중치 초기화 (VFA용)
w = np.zeros(num_states) # feature vector의 크기만큼 가중치 생성
# ε-greedy policy [만약, 저 epsilon이 고정이라면 그냥 exploration만 계속하게 됨]
def epsilon_greedy_policy(w, state, epsilon):
# 행동에 대한 VFA 값 계산
action_values = [VFA(state, w) for _ in range(num_actions)] #수정
# 가장 높은 VFA 값을 가지는 행동 선택
best_action = np.argmax(action_values)
# ε-greedy 정책
policy = np.full(num_actions, epsilon / num_actions) # 모든 행동에 대해 ε/m 확률 부여
policy[best_action] += 1 - epsilon # 가장 좋은 행동에는 1 - ε 추가 확률
return np.random.choice(np.arange(num_actions), p=policy)
# 한 번의 에피소드를 실행하면서 데이터를 모으는 코드 (Monte Carlo)
def run_episode(epsilon, max_steps=10):
episode = []
state = np.random.randint(0, num_states) # 랜덤한 초기 상태
while True:
action = epsilon_greedy_policy(w, state, epsilon) #epsilon_greedy_policy로 탐색과정!
next_state = np.random.randint(0, num_states) #
reward = np.random.randn()
episode.append((state, action, reward))
state = next_state
if len(episode) >= max_steps: # 최대 10번 이동 후 종료
break
return episode
def feature_vector(state, num_states):
vec = np.zeros(num_states)
vec[state] = 1
return vec
def VFA(state, w):
return np.dot(w, feature_vector(state, num_states)) # 상태에 대한 가중치 적용
# GLIE Monte Carlo Control 학습
for episode_num in range(1, num_episodes+1):
epsilon = 1 / episode_num # episode를 점점 늘려갈 때마다 epsilon값이 줄어든다.
episode = run_episode(epsilon) #매번 epsilon greedy policy로 탐색을 해서 episode를 만들어낸다.
G = 0 # 매번 그냥 0에서부터 시작. 그 에피소드에서는 G=0인 것임.
visited = set() # 첫 방문 판별용
for state, action, reward in reversed(episode):
G = reward + 0.9 * G # 감가율 = 0.9
if (state, action) not in visited: # 첫 방문인지 확인
visited.add((state, action))
state_vec = feature_vector(state,num_states) # 상태 벡터 생성
alpha = 1 / (episode_num + 1)
w += alpha * (G - VFA(state, w)) * state_vec # w 업데이트
#Q[state, action] += alpha * (G - Q[state, action])여기서는 이걸 할 필요가 없음. 단순히 w만 업데이트 하면 됨.
print("W:")
print(w)
#==============================================================================
#### 2.SARSA ####
w = np.zeros(num_states * num_actions) # feature vector의 크기만큼 가중치 생성
def epsilon_greedy_policy(w, state, epsilon):
# 행동에 대한 VFA 값 계산
action_values = [VFA(state, w) for _ in range(num_actions)]
# 가장 높은 VFA 값을 가지는 행동 선택
best_action = np.argmax(action_values)
# ε-greedy 정책
policy = np.full(num_actions, epsilon / num_actions) # 모든 행동에 대해 ε/m 확률 부여
policy[best_action] += 1 - epsilon # 가장 좋은 행동에는 1 - ε 추가 확률
return np.random.choice(np.arange(num_actions), p=policy)
def run_episode_next(epsilon, max_steps=10):
episode = []
state = np.random.randint(0, num_states) # 랜덤한 초기 상태
action = epsilon_greedy_policy(w, state, epsilon) # 초기 행동 선택
while True:
next_state = np.random.randint(0, num_states) # 임의의 환경 이동
reward = np.random.randn()
next_action = epsilon_greedy_policy(w, next_state, epsilon) # 다음 행동 선택
episode.append((state, action, reward, next_state, next_action))
state, action = next_state, next_action # SARSA는 (s, a, r, s', a') 방식으로 진행!
if len(episode) >= max_steps: # 최대 10번 이동 후 종료
break
return episode
def feature_vector(state,action,num_states,num_actions):
vec = np.zeros(num_states * num_actions)
vec[state * num_actions + action] = 1
return vec
def VFA(state, action, w):
return np.dot(w, feature_vector(state, action, num_states, num_actions)) # state-action에 대한 가중치 적용
for episode_num in range(1, num_episodes+1):
epsilon = 1 / episode_num # episode를 점점 늘려갈 때마다 epsilon값이 줄어든다.
episode = run_episode_next(epsilon)
visited = set() # 첫 방문 판별용
for state, action, reward, next_state, next_action in reversed(episode):
if (state, action) not in visited:
visited.add((state, action))
state_action_vec = feature_vector(state, action, num_states,num_actions) # 상태 벡터 생성
alpha = 1 / (episode_num + 1)
w += alpha * (reward + 0.9 * VFA(next_state, next_action, w) - VFA(state, action, w)) * state_action_vec
print("학습된 가중치 벡터 w:")
print(w)
#### 3.n-step SARSA ####
n_step = 3
alpha = 0.1
for episode_num in range(1, num_episodes + 1):
epsilon = 1 / episode_num # Exploration 감소
episode = run_episode_next(epsilon) # 에피소드 진행
for t in range(len(episode)): # 각 time step에 대해 반복
G = 0 # n-step return 초기화
# 1. n-step 동안 보상 계산
for i in range(n_step): # n-step동안 보상 계산
if t + i < len(episode):
G += (0.9 ** i) * episode[t + i][2] # 보상 추가 n-step 동안 보상 계산 : 이거는 건들 수 없고, 건들 필요가 없음.
# 2. n-step 후의 Q 값 추가 여기서 건든다.
if t + n_step < len(episode):
G += (0.9 ** n_step) * VFA(episode[t + n_step][3], episode[t + n_step][4], w)
# 3. Q 업데이트
state, action = episode[t][:2] # 현재 상태, 행동
state_action_vec = feature_vector(state, action, num_states, num_actions) # 상태-행동 벡터 생성
w += alpha * (G - VFA(state, action, w)) * state_action_vec # 가중치 업데이트
print("학습된 가중치 벡터 w:")
print(w)
#### 4.backward SARSA ####
alpha = 0.1 # 학습률
gamma = 0.9 # 할인율
lmbda = 0.8 # Eligibility Trace 감쇠율
for episode_num in range(1, num_episodes + 1):
#원래는
E = np.zeros((num_states, num_actions))
#Q = np.zeros((num_states, num_actions))
w = np.zeros(num_states * num_actions)
epsilon = 1 / episode_num # Exploration 감소
episode = run_episode_next(epsilon)
for state, action, reward, next_state, next_action in reversed(episode):
d = reward + gamma * VFA(next_state, next_action, w) - VFA(state, action, w)#d = reward + 0.9 * Q[next_state,next_action] - Q[state,action]
E[state,action] = E[state,action] + 1 #일단 방문했으니까 +1 증가시킴
#흠 여기까지는 그래도 어느정도 이해가 가는데,밑에는 잘 몰라서
for s in range(num_states):
for a in range(num_actions):
w += alpha * d * E[s, a] # Q 업데이트
E[s, a] *= gamma * lmbda #(시간이 지나면서 감소)
"""
1. 기본 SARSA와의 비교
Q[state, action] += alpha * (reward + 0.9 * Q[next_state, next_action] - Q[state,action])
=> 이게 기본 SARSA알고리즘
=> Q[state, action] += alpha * (d) 인 것임.
따라서, E[s,a]를 단순히 곱하면
Q[state, action] += alpha * (d) * E[s,a]임
2. 왜 여기서 num_states와 num_actions에 대해 다 계산하니?
Q 값을 업데이트할 때는 현재 상태뿐만 아니라 과거에 방문했던 상태들도 보상의 영향을 받음
이걸 처리하기 위해 모든 상태-행동 쌍에 대해 Eligibility Trace를 곱해서 업데이트
"""
print(w)
#### 5. Q-Learning ####
def greedy_policy_val_weight(Q,state,action): #state가 주어질 때 best action을 선택해서 값을 찾는 greedy
#return np.max(VFA(state,action,w)) #현실적으로 greedy가 안될 거 같다? 이부분이?
return np.max([VFA(state, action, w) for action in range(num_actions)])
#ver2. 정리 버전 - 37p : Q(S,A) ←Q(S,A) + α R + γ maxa′Q(S′,a′)−Q(S,A)
for episode_num in range(1, num_episodes+1):
epsilon = 1 / episode_num # episode를 점점 늘려갈 때마다 epsilon값이 줄어든다.
#behaviro policy ( 내가 관찰한 policy )
episode = run_episode_next(epsilon)
visited = set() # 첫 방문 판별용
for state, action, reward, next_state, next_action in reversed(episode):
if (state, action) not in visited:
visited.add((state, action))
N[state, action] += 1 # 방문 횟수 증가
alpha = 1 / N[state, action] # 학습률 감소 (GLIE 조건)
# target policy에서의 action 추출?
# 어떻게 target policy를 특정하지? 일단 greedy라고 나와있으니, greedy하게 episode를 뽑아보자.
#next_val = greedy_policy_val(Q, next_state)
next_val =greedy_policy_val_weight(state,action,w) #이게 맞는건가?
w += alpha * (reward + 0.9 * next_val - VFA(state, action, w)) * feature_vector(state, action, num_states, num_actions)
#여기서 매우 중요한 건, 똑같이 저렇게 reversed(episode)를 했다고 하더라도, 저 위에서는 G를 썼지만, 여기서는 그때의 그 reward만을 써서 update를 한다는 것
print("w")
print(w)
'''
Q-learning에서는, 그 다음에 최적의 행동을 선택할 때,
가장 그 이후의 최적의 행동이어야 하는데 과연 이걸 어떻게 weight로 표현할 수 있을까?
(이전에는 단순히 Q[state]의 max를 뽑았는데?)
=> 일단 state가 고정되어 있으니까, 너무 걱정하지 말고 그 state에 해당하는 action을 뽑아서 그 action에 대한 가중치를 뽑아보자.
'''
### 6. DQN ###
w = np.zeros(num_states * num_actions) # 가중치 벡터
w_minus = np.copy(w)
def get_mini_batch(episode, batch_size):
""" 주어진 episode에서 미니 배치를 샘플링하는 함수 """
# 무작위로 미니 배치 샘플링 (배치 사이즈 만큼)
mini_batch = random.sample(episode, batch_size)
return mini_batch
for episode_num in range(1, num_episodes+1):
epsilon = 1 / episode_num # episode를 점점 늘려갈 때마다 epsilon값이 줄어든다.
#behavior policy ( 내가 관찰한 policy )
episode = run_episode_next(epsilon) #e-greedy로 episode를 뽑아낸다.
visited = set() # 첫 방문 판별용
#매번 뽑는 게 아니라, random mini-batch를 뽑는다
batch_size = 4
mini_batch = get_mini_batch(episode, batch_size)
for state, action, reward, next_state, next_action in mini_batch:
if (state, action) not in visited:
visited.add((state, action))
N[state, action] += 1 # 방문 횟수 증가
alpha = 1 / N[state, action] # 학습률 감소 (GLIE 조건)
# target policy에서의 action 추출?
# 어떻게 target policy를 특정하지? 일단 greedy라고 나와있으니, greedy하게 episode를 뽑아보자.
#next_val = greedy_policy_val(Q, next_state)
next_val = VFA(next_state, next_action, w_minus) #왜냐면, 저기 식에서 w_minus를 쓰니까
w += alpha * (reward + 0.9 * next_val - VFA(state, action, w)) * feature_vector(state, action, num_states, num_actions)
if episode_num % 10 == 0: # 예: 10 에피소드마다 동기화
w_minus = np.copy(w)
print("w")
print(w)밑에꺼는, GPT한테 argparse써서 좀 예쁘게 보일 수 있도록 맡겨보았습니당
import numpy as np
import random
import torch
import torch.nn as nn
import torch.optim as optim
from collections import deque
# 하이퍼파라미터 설정
num_episodes = 1000
epsilon_start = 1.0
epsilon_end = 0.1
epsilon_decay = 0.995
gamma = 0.99 # 할인율
batch_size = 32
learning_rate = 0.0001
update_target_every = 10 # 타겟 네트워크 업데이트 주기
# 환경 설정 (예시로 OpenAI Gym 환경을 사용)
import gym
env = gym.make('CartPole-v1')
# Q 네트워크 정의
class QNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# Q 네트워크와 타겟 네트워크 초기화
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
q_network = QNetwork(state_dim, action_dim)
target_network = QNetwork(state_dim, action_dim)
target_network.load_state_dict(q_network.state_dict()) # 타겟 네트워크 초기화
target_network.eval() # 타겟 네트워크는 평가 모드
# 옵티마이저
optimizer = optim.Adam(q_network.parameters(), lr=learning_rate)
# 경험 리플레이 버퍼
memory = deque(maxlen=10000)
# epsilon-greedy 정책
def epsilon_greedy(state, epsilon):
if random.random() < epsilon:
return env.action_space.sample() # 랜덤 행동
else:
state_tensor = torch.FloatTensor(state).unsqueeze(0)
q_values = q_network(state_tensor) # Q값 예측
return torch.argmax(q_values).item() # 가장 큰 Q값을 가지는 행동 선택
# 경험 리플레이에서 미니 배치 샘플링
def get_mini_batch(batch_size):
batch = random.sample(memory, batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
return torch.FloatTensor(states), torch.LongTensor(actions), torch.FloatTensor(rewards), torch.FloatTensor(next_states), torch.BoolTensor(dones)
# 학습 루프
epsilon = epsilon_start
for episode in range(num_episodes):
state = env.reset()
total_reward = 0
done = False
while not done:
action = epsilon_greedy(state, epsilon)
next_state, reward, done, _ = env.step(action)
memory.append((state, action, reward, next_state, done)) # 경험 리플레이 버퍼에 저장
state = next_state
total_reward += reward
# 미니 배치로 학습
if len(memory) > batch_size:
states, actions, rewards, next_states, dones = get_mini_batch(batch_size)
# 현재 Q 네트워크에서 Q값 계산
q_values = q_network(states) #feature vector뽑기 + w내적이 다 여기에 포함된 과정임.
q_value = q_values.gather(1, actions.unsqueeze(1)) # 현재 행동에 대한 Q값
# 타겟 네트워크에서 Q값 계산
next_q_values = target_network(next_states)
next_q_value = next_q_values.max(1)[0] # 가장 큰 Q값
# 타겟 Q값 계산
target = rewards + gamma * next_q_value * (~dones)
# 손실 함수 계산
loss = nn.MSELoss()(q_value.squeeze(), target)
# 역전파
optimizer.zero_grad()
loss.backward()
optimizer.step()
# epsilon 값 감소
epsilon = max(epsilon_end, epsilon * epsilon_decay)
# 주기적으로 타겟 네트워크 업데이트
if episode % update_target_every == 0:
target_network.load_state_dict(q_network.state_dict())
print(f"Episode {episode+1}/{num_episodes}, Total Reward: {total_reward}")
print("학습 완료!")하나하나 다 저 David RL보고 구현한거라서! 오류가 있을 수도 있으니(?) 주의해주세요ㅎㅎ

한발한발 나아갑니당!