Abstract
llm 기반 모델들이 rapid하게 progress를 이뤄내고 있다.
-> However, llm기반 모델들이 성장하는 가장 큰 이유는, _'인간'_ 에 있다.
(인간이 그 대화에 input을 집어넣어주기 때문에...!)
-> 그렇다면, autonomous한 cooperation이 가능해야한다!
-> 그래서 role-playing이라는 agent framework를 등장시켰다!
Introduction
-
llm이 등장했다.
-
하지만, llm의 성공은 대부분 인간의 인풋에 달려있다.
문제 -> 인간이 무조건 정확하고, 관련 있는 프롬프트 만을 제공해야할 것 같다!
ex) 트레이딩에 관한 지식이 정말 1도 없는 사람에게 chat agent한테 prompt를 써봐! -> 굉장히 어려움을 겪음...ㅠㅠ
- 여기서, 질문이 등장!
"can we replace human intervention with an autonomous
communicative agent capable of steering the conversation toward task completion with minimal human supervision?"
(인간의 개입을 최소화해도 자동적으로 communicative한 agent를 어떻게 만들 수 있을까??)
- role-playing 등장 ( by inception prompting!)
- preliminary idea 만 있으면 됨!
(+) library(에이전트 실행 + 데이터 생성 파이프라인 + 데이터 분석 + 데이터)도 제공!
Related Work
- communicative agents
: 현재, cooperative한 AI시스템을 만드는 것은 아직도 활발한 연구 분야 중에 하나이다.
- AI alignment
- AI alignment가 뭔데? AI system이 디자이너에 의해 설계된 목표,가치 등을 고수하는 것을 의미한다.
이게 중요한 이유는, 원하는 목표 는 이루면서 원하지 않는 결과 는 피하는 것이기 때문에!
→ 그래서 최근 AI alignment 연구에서는 후자에 집중을 하고 있다.
3. Methodology
3.1 Role-playing Framework
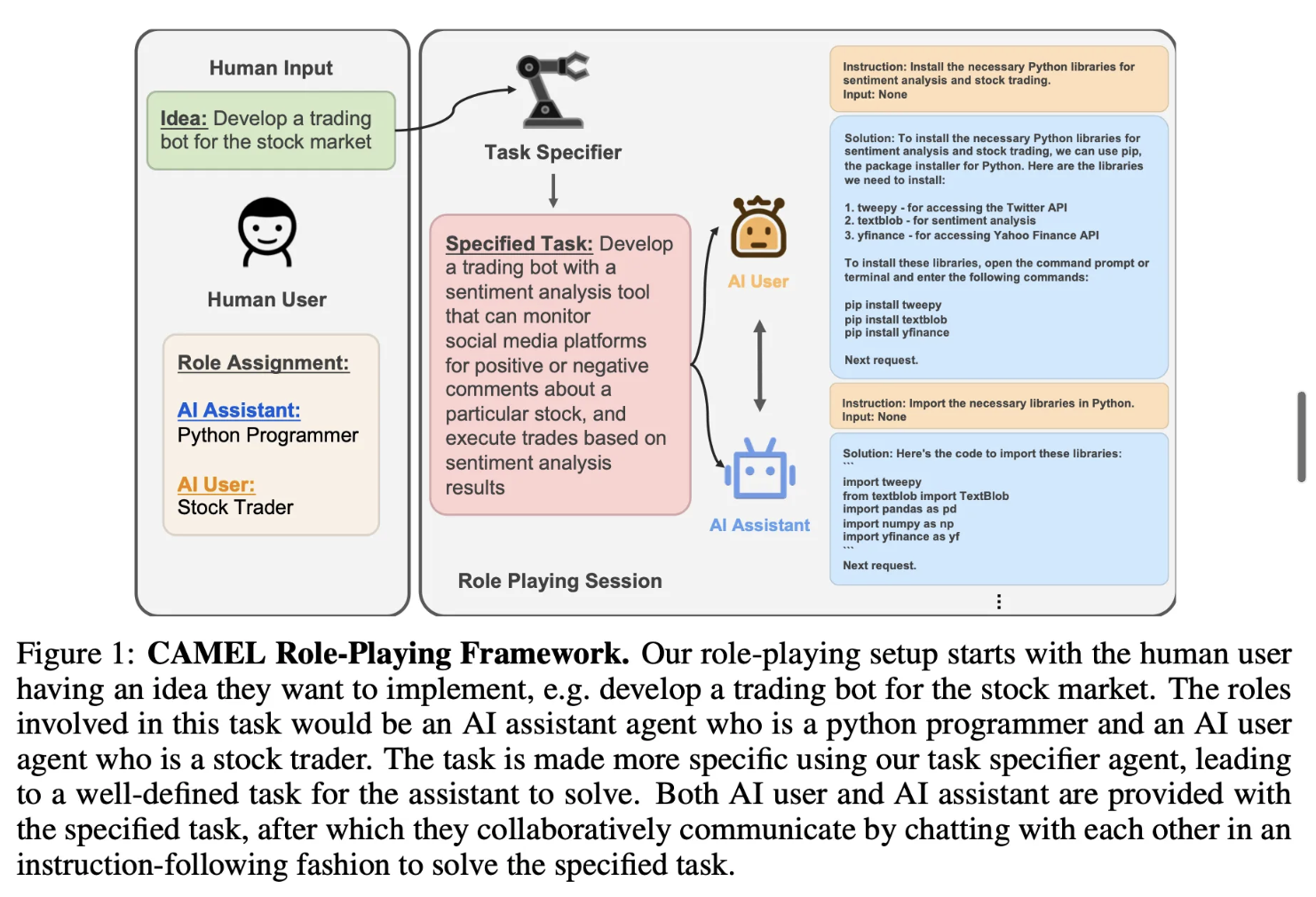
- 인간이 구현하고 싶은 것 (ex.Develop a trading bot for the stock market)
- task specifier : AI assistant agent (파이썬 프로그래머) + AI user agent(주식 트레이더)에게 일을 할당
- AI assistant agent + AI user agent : 서로 상호작용 !
- AI user : AI assistant에게 instruction 주기
- AI assistant : AI user가 하라고 하는 일들 실행
< 단계 >
- 크게 단계 나누어보기
Human Input and Task specifying →
AI assistant - User Role Assignment →
Conversation Towards Task-Solving
- 작게 단계 나눠보기
1) task specifier : 인간이 가진 input → specific한 task
2) task specifier : specific한 task → AI user와 AI assistant의 system role
3) 에이전트 생성 : llm모델에 system role → AI user Agent와 AI assistant 에이전트 생성 !
4) Instruction 0 생성 : AI user Agent → I0
5) Solution 0 생성 : AI assistant Agent + I0 → S0
6) Instruction 1 생성 : AI user Agent + M0(I0 + S0) → I1
7) Solution 1 생성 : AI assistant Agent + M0(I0 + S0) + I1 → S1
8) Instruction 2 생성 :AI user Agent + M1(I0 + S0 + I1 + S1)→ I2
9) Solution 2 생성 : AI assistant Agent +M1(I0 + S0 + I1 + S1) + I2 → S2
10) 반복…!
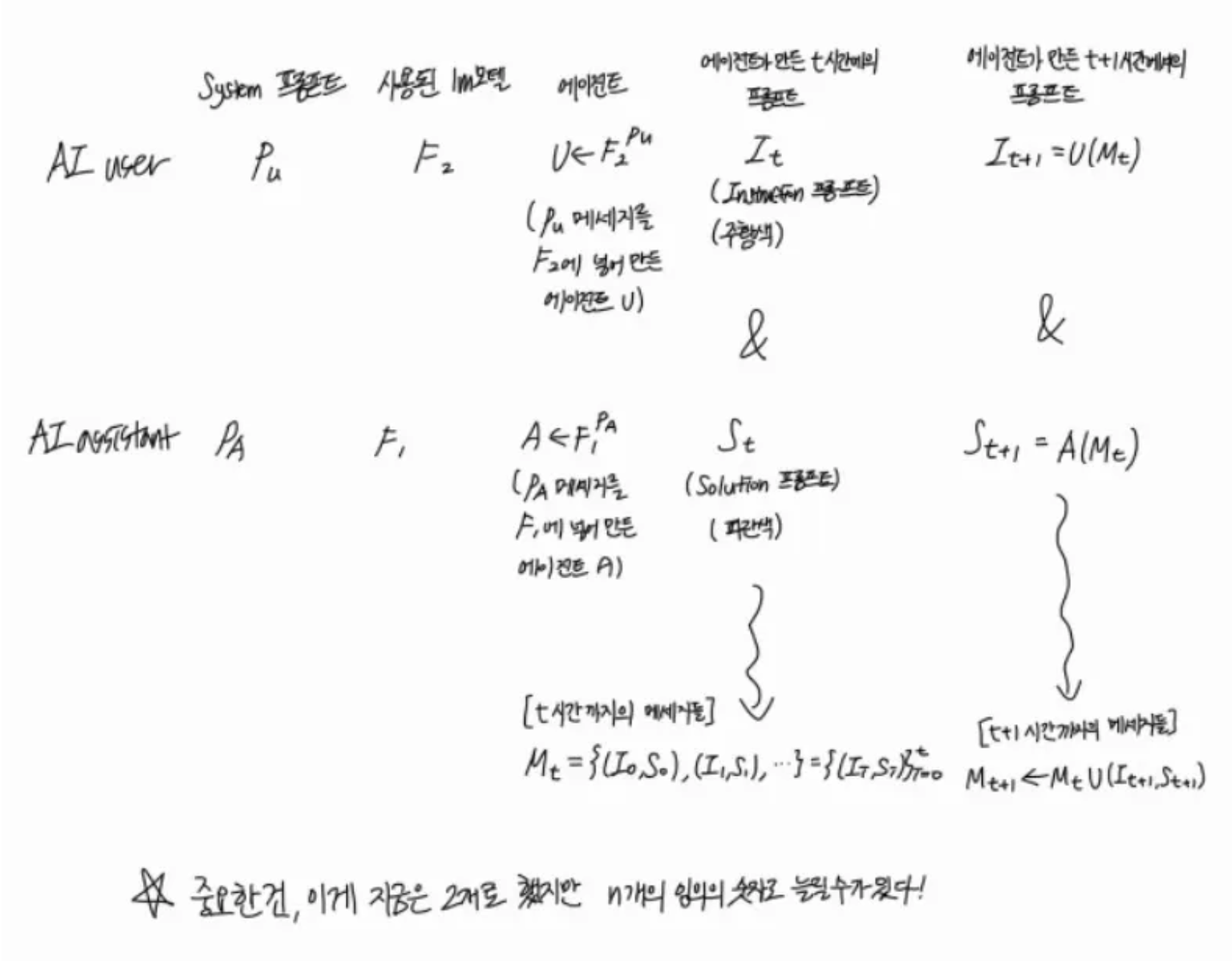
⇒ 중요한 건 이건 2개로 했지만, n개의 임의의 숫자로 늘릴 수 있다는점!
St+1 = A(Mt,It+1)
3.2 Inception Prompting
일단, 3.1에서 framework는 봤지만, prompt engineering이 가장 중요하기 때문에, 한번 프롬프트 엔지니어링 테크닉에 관해 한번 자세하게 보겠다!
prompt engineering이 필요한 구간 : 1)단계와 2)단계
prompt engineering이 필요없는 구간 : 3),4),5) … 단계
→ why? : 나머지는 알아서 자동으로 해결이 되기 때문에.
→ Therefore , Inception Prompting 이라고 부르겠다!
Inception prompt는 그럼 과연 어떻게 구성이 되어 있을까?
-
task specifier prompt (인간input → specific task)
-
assistant system prompt (specific task → user,assistant system role)
Never forget you are a <ASSISTANT_ROLE> and I am a <USER_ROLE> : user role에게 지정된 role을 던져주는 것임!
Never flip roles! Never instruct me! : role을 바꾸지 말라고 제약을 거는 것!
You must decline my instruction honestly if you cannot perform the
instruction due to physical, moral, legal reasons or your capability
and explain the reasons : 만약 moral,legal reason이 없다면 거부해야해!Unless I say the task is completed, you should always start with:
Solution: <YOUR_SOLUTION> : -
user system prompt (specific task → user,assistant system role)
Keep giving me instructions and necessary inputs until you think the
task is completed. When the task is completed, you must only reply with
a single word <CAMEL_TASK_DONE>. : End of token이 필요함. 왜냐면 이거 없으면 계속 안녕~그리고 또 안녕~ 이것만 반복해서ㅋㅋㅠ

4. Experiments
준비물
- 에이전트 : gpt3.5 turbo
- 프롬프트 : inception prompt(3.2에 있는)
⇒ 결과물 : CAMEL AI Society , CAMEL Code datasets , CAMEL Math , CAMEL Science
( 결과물은 쉽게 말하면, 두 에이전트가 소통해서 남긴 대화 기록이라고 생각하면 됨)
4.1 Role-Playing for AI Society
- 50개의 assistant - user관계로 만들어낼 수 있는 50가지의 관계를 한번 만들어달라고 함!
- 그 task == 인간의 input
- task specifier로 3.2의 과정 반복 !
For our AI society dataset, we generated 50 assistant roles, 50 user roles, and 10 tasks for each combination of roles yielding a total of 25,000 conversations.
AI society dataset을 만들기 위해, 즉 AI society 결과물(simulation)을 만들기 위해 50개의 assistant role과 50개의 user role 만듦 → 각각의 조합에 10개의 combination → 25000 conversation 생성해냈다!
( 50 x 50 ) x 10 = 25000


5. Evaluation
과연 그러면 성능을 어떻게 평가했을까? → 만들어진 데이터셋 을 가지고 평가를 하는 거겠지??
5.1 Agent Evaluation
- 데이터
- 평가 데이터
- AI society 시나리오를 통해 만들어진 25000개 데이터 중에서, 100개의 task + Code 시나리오를 통해 만들어진 25000개 데이터 중에서 100개의 task
- 그 데이터를 요약한다 ! (by GPT-4)
- 비교 데이터
- single-shot으로 만들어진 데이터(by GPT-3.5 turbo)
결국,
평가데이터 vs 비교데이터
= 여러번 대화를 통해 만들어진 데이터(gpt 3.5) + 요약(gpt 4) vs 한번에 만들어진 데이터(gpt 3.5-인간!)
- 비교 방법
저 두개의 데이터들을 가지고,
인간과 GPT-4에게 평가데이터 vs 비교데이터?
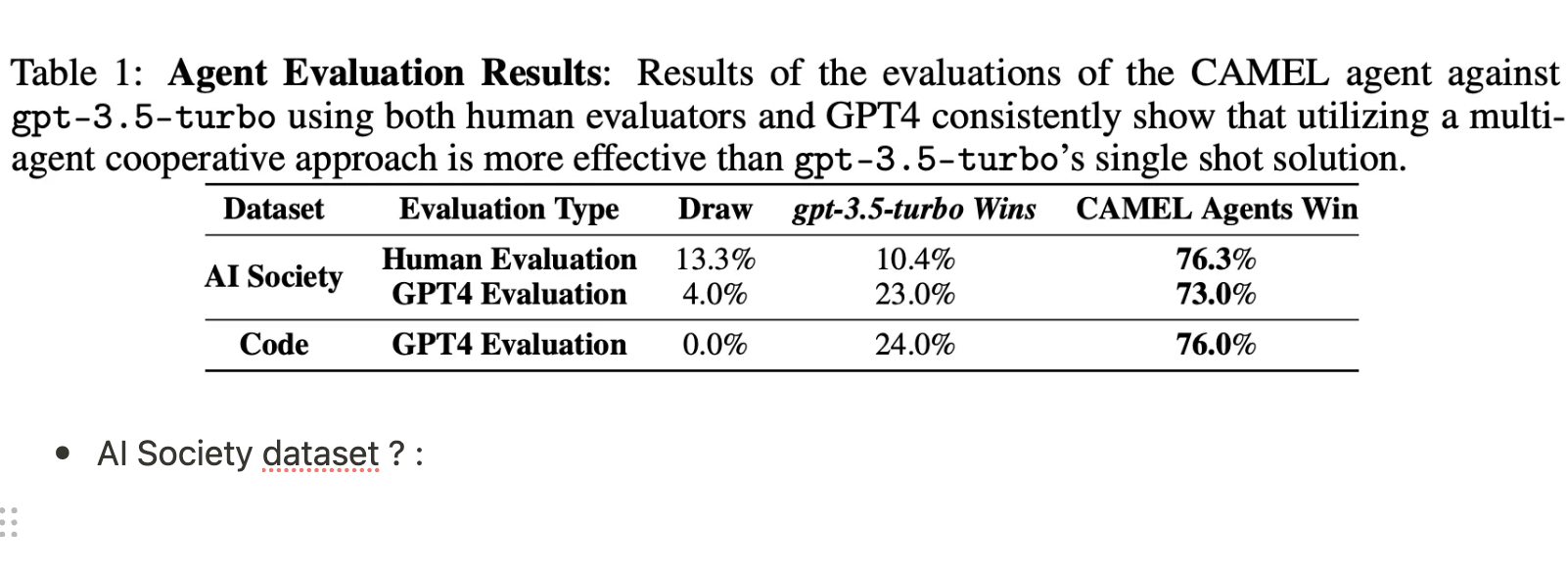
- AI Society dataset ? :
5.2 GPT4 for ChatBot Evaluation
에이전트가 만들어낸 결과물을 5.1에 평가했다면,
에이전트가 만들어낸 결과물들을 써서 다른 모델 finetuning했을때의 성능을 5.2에서는 평가!
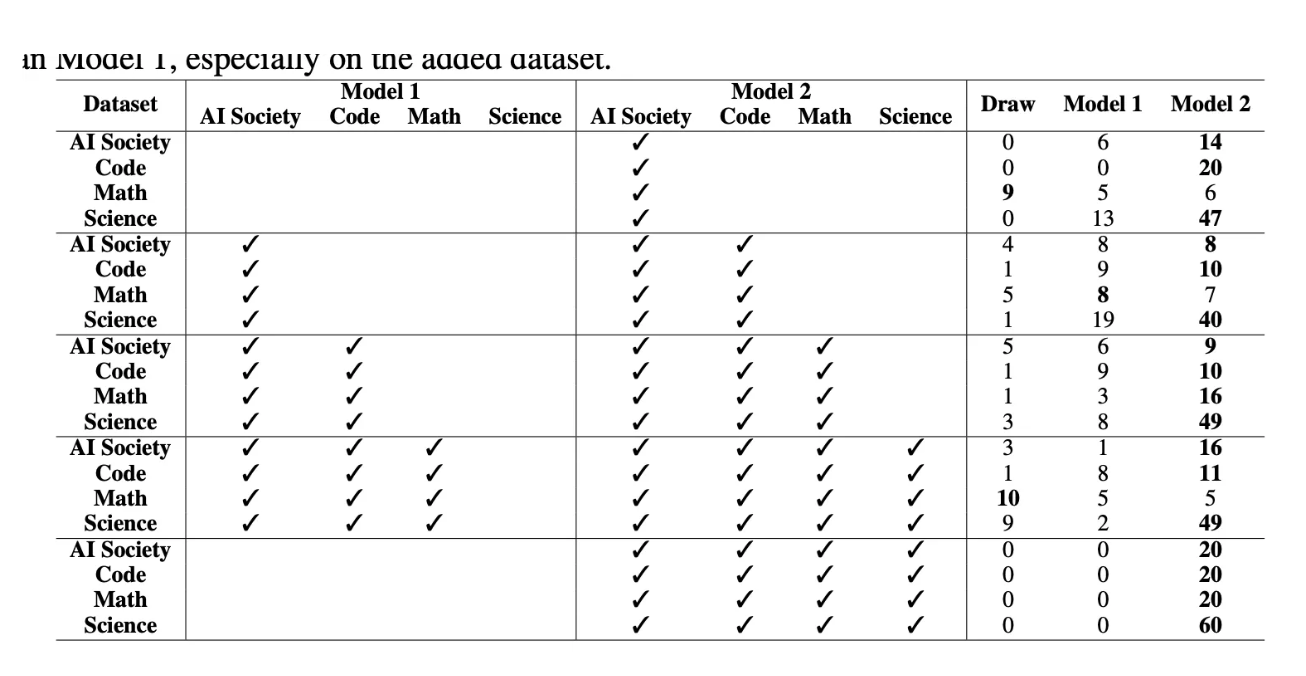
첫번째 라운드 : Model2만 AI society데이터 학습
⇒ 결과 : AI society, Code, Math, Science 데이터로 평가했을 때 Model2 대부분 win!
두번째 라운드 : Model 1은 AI society 데이터 학습 , Model2는 Code데이터도 학습
⇒ 결과 : AI society, Code, Math, Science 데이터로 평가했을 때 Model2 대부분 win!
…(4번째까지 실행!)
💡
결론
이렇게 하면 simulation을 할 수 있는 거구나!
⇒ 이렇게 해서 trust simulation이 가능했던 거 였음.
⇒ 근데 이렇게 하면 생각보다 쉽게 multi agent simulation 이런 것들이 가능하겠구나 이런 생각이 든다?
