논문 링크 :
https://dl.acm.org/doi/pdf/10.1145/3613904.3642349
참 Problem Solution 구조에 따라 아주 잘 쓴 논문같다.
Abstract
LBT + teachable agent 의 장점 ⇒LBT + teachable agent의 단점 ⇒ LBT + teachable agent 해결방법 제시!
여기서 중요한 건, teachable agent 가 우리가 늘상 봐오던 여러개의 agent가 아니라,
single-agent라는 점이다!
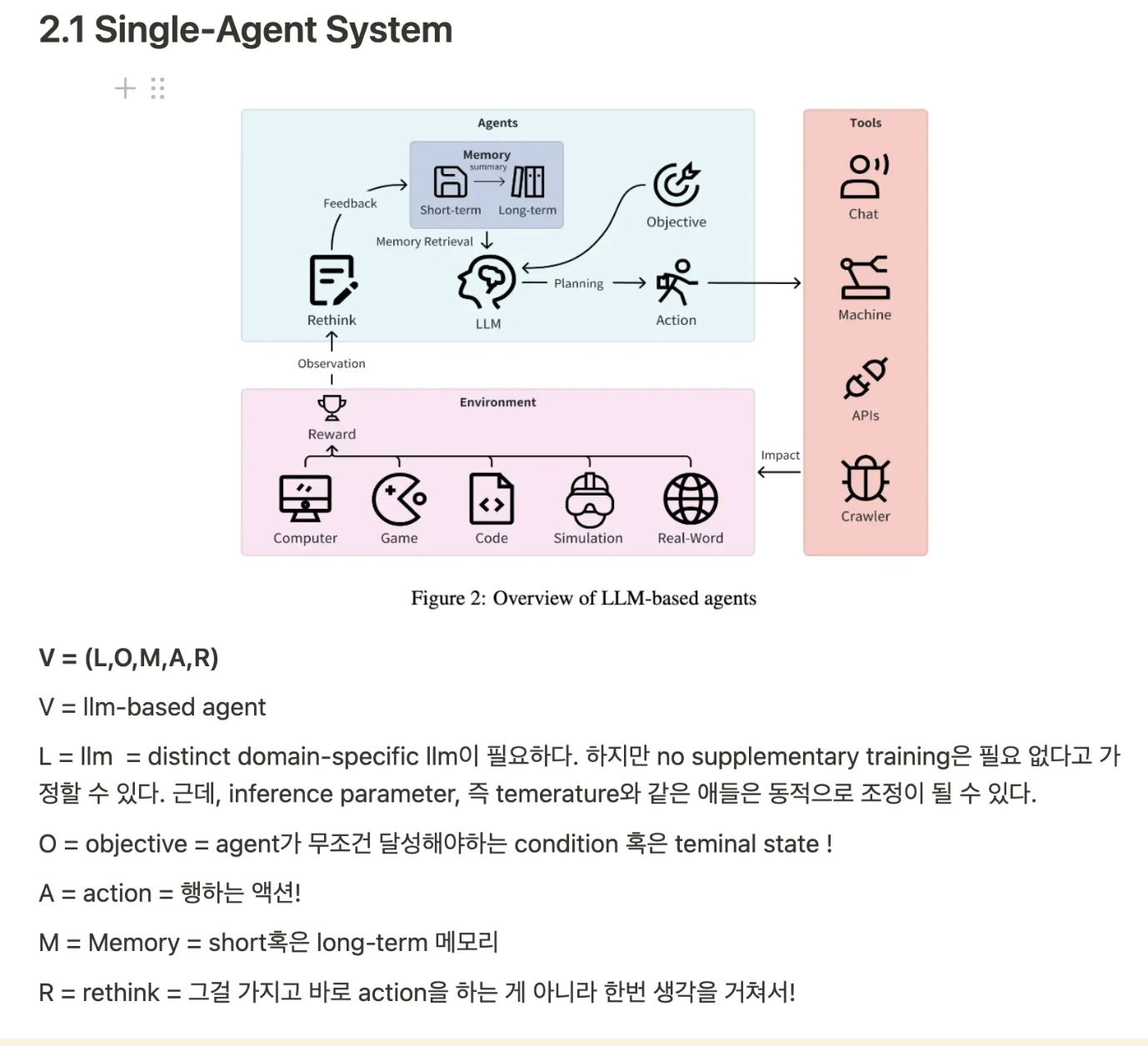
그 single-agent를 위해 예전에 했던 reflection, memory 등을 어떻게 짜는 지에 관한 방법론 !
-
LBT + teachable agent의 장점 : knowledge gap을 줄여줄 수 있고, new knowledge를 발견할 수 있다.- LBT란 Learning By Teaching으로, 교육에서의 일정 기법이라고 생각하면 될 것 같다. 공부를 할 때 가장 좋은 것은, 남에게 가르치는 것!이잖슴!
- LBT란 Learning By Teaching으로, 교육에서의 일정 기법이라고 생각하면 될 것 같다. 공부를 할 때 가장 좋은 것은, 남에게 가르치는 것!이잖슴!
-
LBT + teachable agent의 단점 : 주제에 한정된 지식이 필요 & llm이 너무 tutee로써 능력이 뛰어나다. -
LBT + teachable agent해결방법 : llm의 지식 수준을 낮추기 + “Why” & “How”의 질문을 던지게 하기 !환경 : TeachYou
챗봇 : AlgoBo

( 결국 , 내가 누군가에게 가르침으로써 나의 실력 향상을 도모하는 거다 ! ! ! )
( 근데, 친구가 너무 공부를 잘해버리면 내가 의욕도 사라지지…마치 교수님께 가르쳐드린다고 생각하면 될듯…내가 교수님에게 가르쳐봤자 교수님은 이미 다 아는데?!…)
Introduction
-
LBT + teachable agent의 장점: 배우는 사람이 ! 친구한테 가르칠 수 있음 so good
-
LBT + teachable agent의 단점단점 1 : 다양X - 다양한 주제에 해당하는
teachable agent를 어떻게 만들것인가?(왜냐면, teachable agent는 우리가 원하는 대로 결과를 내지 않을 것이 뻔하기 때문에 ! )
단점 2 : 어려움 - 기존의 방법들은 선생님과 연구자들이 쉽게
teachable agent를 만들 수 있는 상황 X -
LBT + teachable agent의 해결방법-
첫번째 방법 ( 기본적인 chatGPT를 tutee로 만듦) 사용 후
→ 공통적으로 원하는 사항!
요구 1 . llm agent의 지식 수준을 조절 할 수 있게 !
요구 2 . agent-initiated “why” and “how” question ?
요구 3. user의 가르치는 방법에 대한 피드백 !
:
teachable agent가 code를 짜는 데에 굉장히 능했기 때문에, 자세하게 말해줄래? 와 같은 그런 질문들을 던지지 않았다…ㅠ -
새로운 방법 ( TeachYou , AlgoBo)
- AlgoBo
:
teachable agent- TeachYou
:
web-based algorithm learning systemTeachYou에서 programming 문제를 풂 → AlgoBo를 풀면서 reflect를 한다. → 점점 AlgoBo가 misconception을 줄이고 가르침 받은 대로 코딩을 한다. → 종종 AlgoBo는 questioner mode로 변한다. → Teaching Helper를 통해 그들의 teaching 방법에 대해 제안을 받는다.
-
- 결과
- 대상 : 40명의 알고리즘 novice !
- 많은 호응을 얻었다.
Related work
2.1 LBT
: 과연 learning by teaching에서 어떤 요소가 중요하니 ?
- knowledge-building이 중요하다.
- Knowledge-building 제공된 자원들을 넘어서 ! 지식을 확장하는 것! ! !
- Knowledge-building 제공된 자원들을 넘어서 ! 지식을 확장하는 것! ! !
- However , knowledg-building 이 LBT로 자연스럽게 되는 것은 아님.
- 중요한 것은 ,
- tutee’s role
- tutee’s follow-up questions
2.2 Teachable Agent for LBT
: teachable agent
- peer learner의 존재가 중요하다.
- However, 매번 인간이 존재할 수는 없는 마당.
- Thus ,
teachable agent가 등장했다. - However,
teachable agentnatural 하게 만드는 게 되게 어렵다. - Thus , we will make it with LLMs
2.3 LLM-powered simulation of tutoring
3. Formative study
: 이진탐색을 그냥 llm chatbot한테 한다고 했을 때 어떤 효과가 있었는지…?
→ 그때 나타난 패턴들을 살펴 보았다.

3.1 Participants and Procedure
- 대상 : 15명의 사람들을 대상으로 !
- algobo-basic : GPT-4가 backbone !
- 자료 : 실험 참가자로부터의 피드백 + 대화 내용 분석 → 그림에 등장
3.2 dialogue analysis
분류 기준을 일단 instruction / prompting / statement 로 잡았따!
instruction = tutee에게 하라고 시켰던 message !
prompting =
statement =
3.3 Participants’ commment와 dialouge analysis
문제점 1 . agent가 너무 유능 : 너무나도 algobo-basic 은 유능하다.
: 오히려, 학생보다는 , 거의 뭐 보조 느낌이었다…!
문제점 2 . learner는 아는 것만 말하기 : 그냥 knowledge-telling 에 가까웠다.
: 아까 , knowledge-building 이 중요하다고 했는데,
단순히 그냥 아는 것 말하기 + 그냥 대충 넘어가도 응응 ⇒ knowledge-building이 불가한 것이다.
- 예시 참가자들 왈 )
I didn’t discover anything new because I explained what I had already learned
Sorted arrays reduce the number of calculations and maximize the effectiveness of binary search 이렇게 말했는데, 그냥 바로 넘어감. 구체적으로 “why”와 “how”가 없어도 넘어감…
문제점 3 . learner에게 피드백 X : 내가 정확하게 맞게 가르치고 있는 것에 대한 피드백이 부족ㅠ
: 과연 내가 맞게 가르치고 있는 건감…?
- 예시
I was able to see that my teaching skill improved, but the reflection on my tutoring session left a lot to be desired due to the lack of feedback on my tutroing session
4. Design goals
그렇다면, 디자인을 한번 해보자!
디자인 목표 1 . agent의 수준 : agent가 너무 유능 → misconception과 점진적인 학습을 모방할 수 있는 agent !
디자인 목표 2 . agent의 질문 : 아는 것만 말하기 → 좀 더 깊게 질문을 해야함. (why + how )
디자인 목표 3 . learner에게의 피드백 : learner에게 피드백이 없다. → 내가 맞게 잘 가르치고 있는 건지 피드백이 필요하다 !
5. System
agent는 algobo , 그 환경은 teachYou !
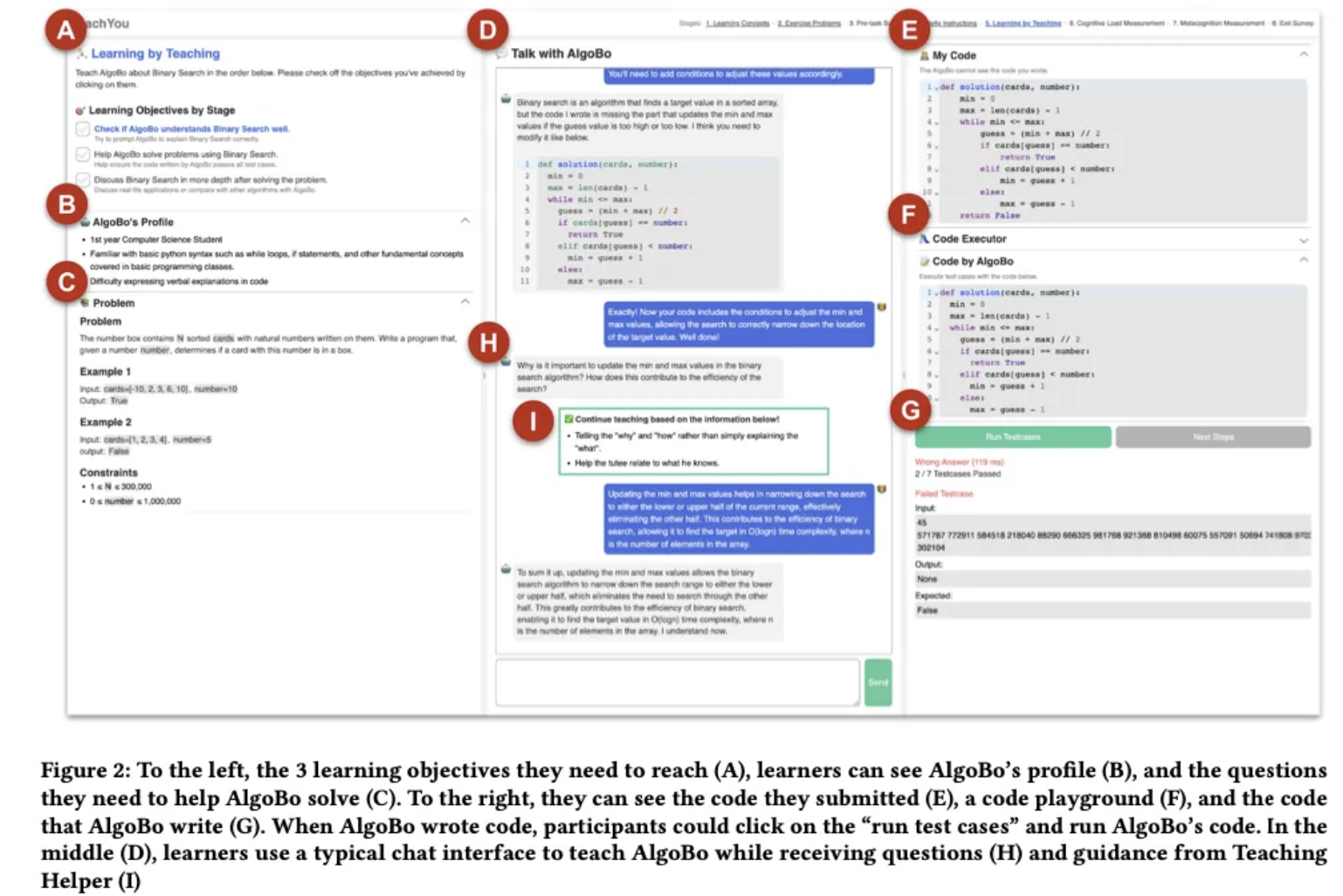
- persona 설정
: 2nd highschool
- 페르소나 설정 예시

아까, 문제점 3개에 해당하는 디자인 골 3개가 있었지?
그 3개를 바탕으로 설명을 해보겠다.
대단한게 5.1, 5.2, 5.3에서 앞의 문제점 1 , 문제점 2 , 문제점 3 을 개선하기 위한 각각의 방법을 나열한다!
5.1 Reflect-Respond Prompting pipeline to simulate knowledge learning
agent가 너무 유능하다는 문제점 1 을 해결하기 위해서는, 점진적으로 학습하는 게 매우 중요하다. 과연 그러면 필요한 요소는 무엇인걸까?
-
조건 1 reconfigurability : 에이전트의 지식 수준을 조절할 수 있어야 함 !
예시 ) “중학교 2학년 아이처럼 “ , “ 초등학교 1학년 아이처럼 “ 등등
-
조건 2 persistence : 처음에 설정했던 그대로의 수준이어야 함 !
예시 ) 처음에는 되게 못하는 것처럼 하다가 , 시간이 조금만 지나도 그냥 자기가 자문자답해서 “어? 답은 이거네요?” 이렇게 하지말아야 함.
-
조건 3 adaptability : 점점 대화를 해나가면서 , 알게되는 그 지식들을 업데이트를 해야한다 !
예시 ) 점점 대화를 해나가면서 알아가는 것들을 업데이트 !
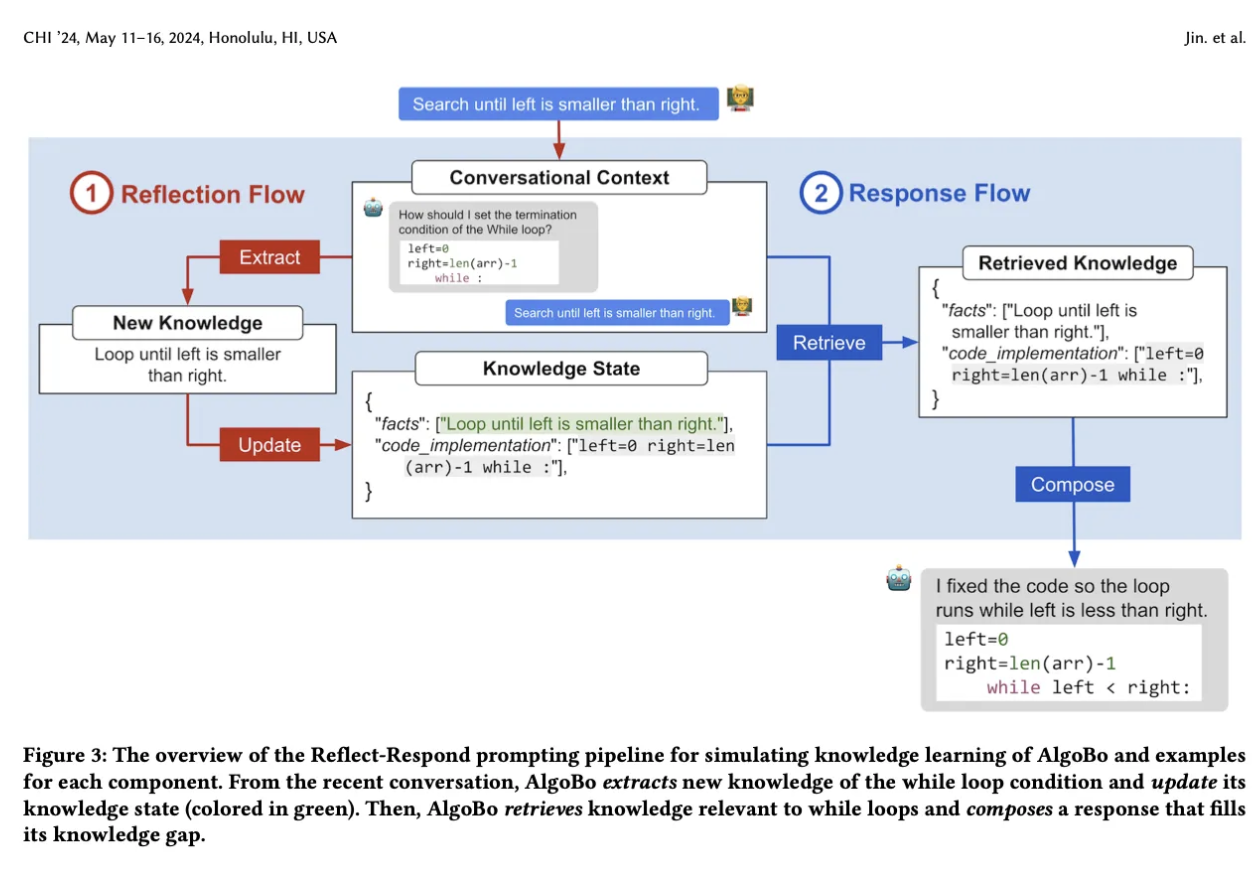
그래서, reconfigurability와 persistence, adaptability를 구현하기 위해서 이렇게 설계를 했다.
그렇다면 , 설계의 요소들을 하나하나 살펴봐야지.
Knowledge state 가 있다. 이건 뭐지?
knowledge state : AlgoBo가 현재 알고 있는 지식 저장소 ! **JSON** 형식으로 저장 !
ex ) 만약에 knowledge state가 없다면 agent는 zero-knowledge 행동을 보일 것.
facts 는 자연어 설명
code implementation 은 코드로 된 거 ! 과정 1. reflection : reconfigurability 와 연관 !
llm을 가지고 대화에서 extract함 → ** knowledge state를 update**함.
과정 2. response : persistence, adaptability 와 연관!
conversational text와 연관된 정보를 knowledge state에서 retrieve한다 → 그 retrieved된 knowledge를 바탕으로 compose를 한다
🤗
구현방법
knowledge state : json으로 구현!
( facts 는 자연어 설명 , code implementation 은 코드 )
extract, update, retrieve, compose : 다 gpt-4 로 구현 !


( retrieve, compose도 똑같이 프롬프트 존재)
5.2 AlgoBo’s Mode-shifting to develop constructive LBT dialogues
agent가 그냥 단순히 배운 거 말하기만 한다(knowlege-telling)는 문제점 2 을 해결하기 위해서는 지식을 구축하는 것(knowledge-building)을 “why”와 “how”의 질문을 통해 하는 게 매우 중요하다.
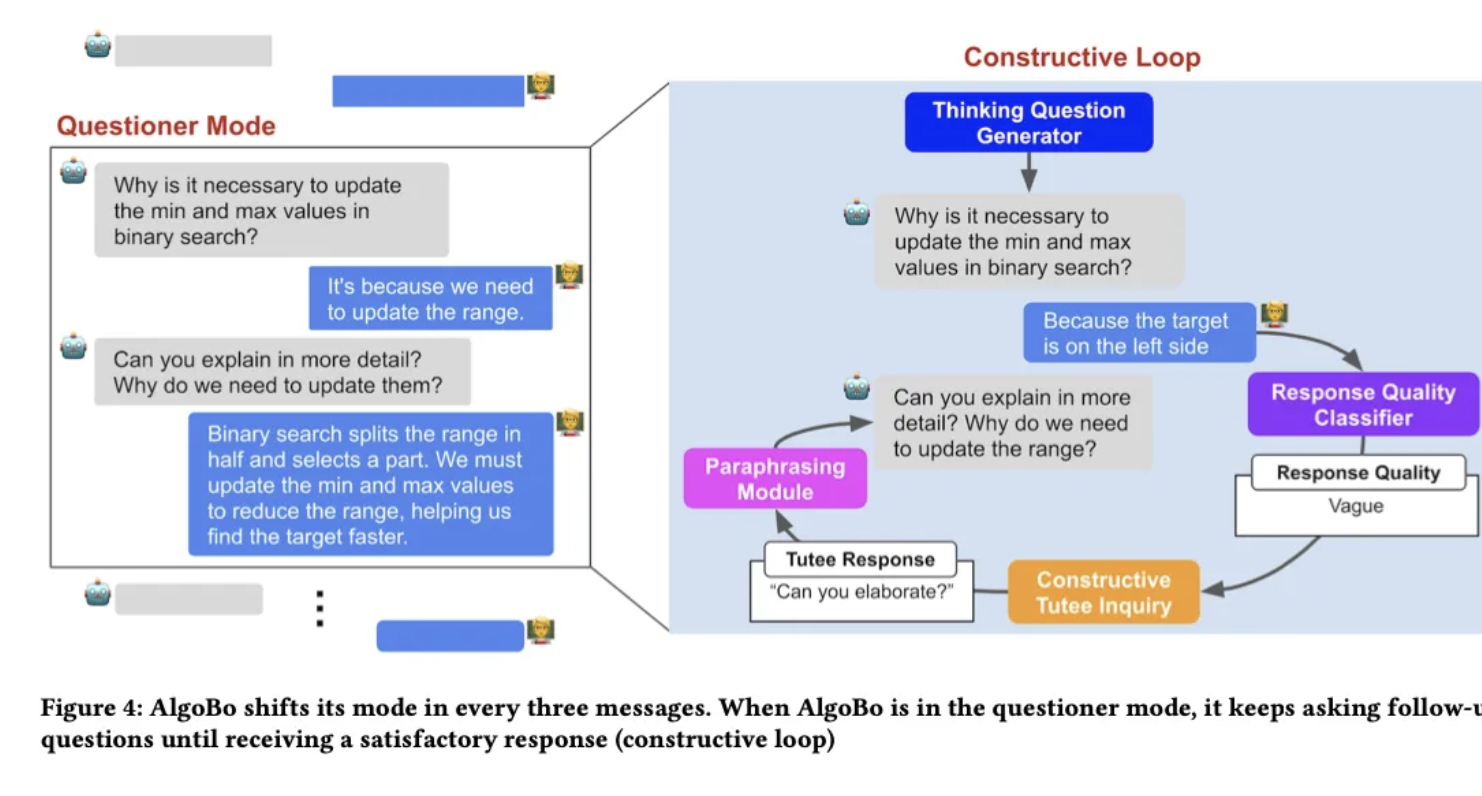
그래서 mode-shifting을 도입했다!
: 두가지 모드가 있음.
-
첫번째 모드 : help-receiver 모드 !
-
두번째 모드 : questioner 모드 ! 로 바꿔서 thinking question을 물어본다.
thinking question이란?
“why” question(learner의 코드에 맞추어서) “how” question(설명하고, 배운 것을 연결지으려는) -
반복
(3n)
번마다 questioner 모드로 바뀌게 됨
🤗
🤗
구현방법
1. Thinking Question Generator
: GPT-4를 써서 현재 대화에 맞는 thinking question 만들어내기!
2. Response Quality Classifier
: 만약 tutee(learner)가 잘못 대답했다면, 다시 질문을 해야하니까! learner의 답변을 classify하는 거다!
3. Constructive Tutee Inquiry protocol
: 만약 vauge하다고 나오면 무조건 “can you elaborate?”
: 만약 good이라고 나오면 무조건 “well done”
: 만약 unrelated하다고 나오면 무조건 “That is not the question I’ve asked”
4. Paraphrasing module
: 맨날 저 “can you elaborate?,well doone,that is not the question I’ve asked” 만 하면 질릴 것아님? 그래서 이 모듈을 추가했음
(3n번마다 questioner 모드로 바뀌게 됨)
Thinking Question Generator의 예시는,

5.3 Teaching HElper for metacognitive guidance
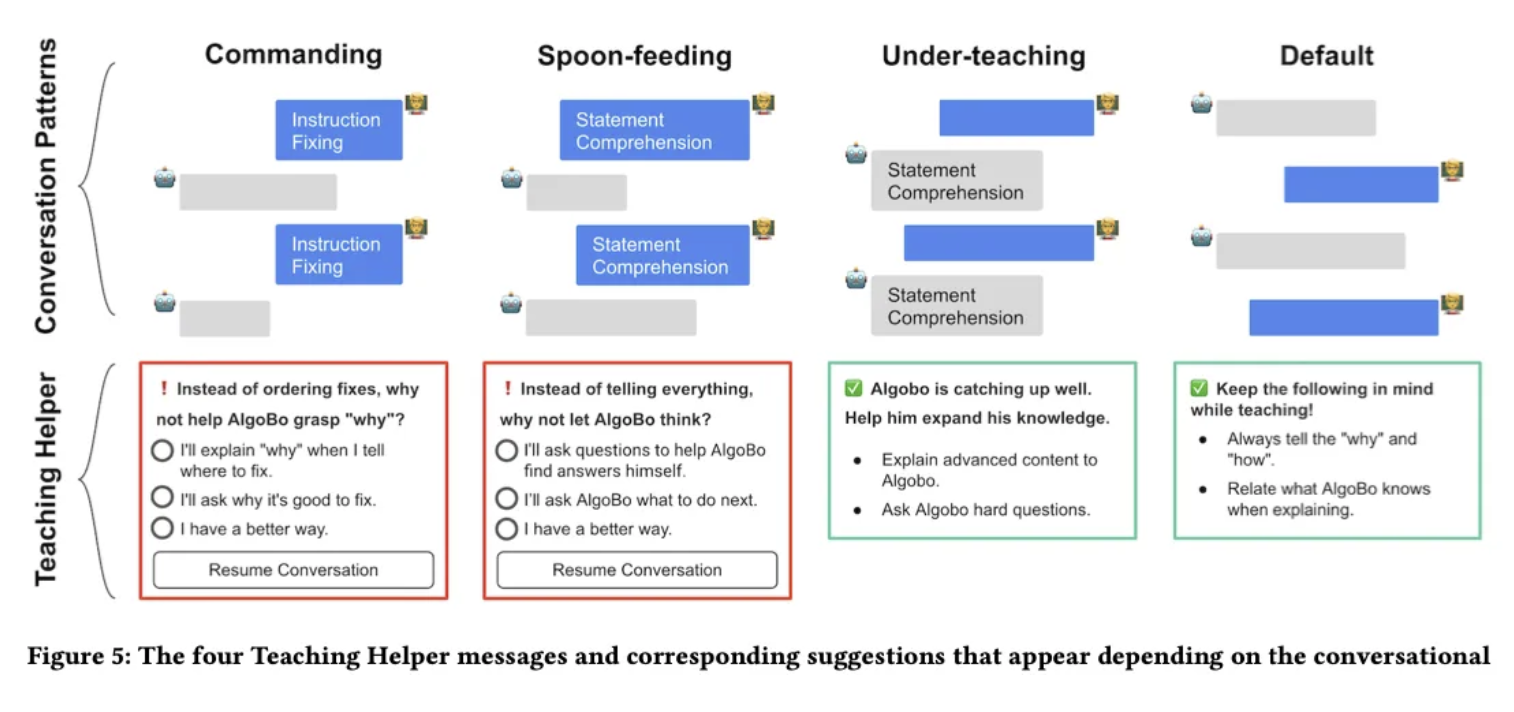
learner가 가르치는 것에 대한 피드백을 제공하지 않는다는 문제점 3 을 해결하기 위해서는 metacognitive pattern을 파악하여 feedback을 주는 것이 중요하다 ( 빨간색 or 초록색 ! )
패턴 1. commanding
: learner가 teaching style을 바꿔야 함.
⇒ 그래서 저 3가지 선택지 중에 하나를 선택하게 함!
패턴 2. spoon-feeding
: learner가 teaching style을 바꿔야 함.
패턴 3. under-teaching
: 팁을 준다!
패턴 4. default
: 팁을 준다!
🤗
구현 방법
message-type classfier를 만들어서 4개의 패턴으로 구분했다.
트레이닝 : dialogue dataset 438개!
정확도 : validation dataset 108개에 71%의 accuracy
6. Evaluation
7. Discussion
8. Limitation and Future work
(추가하여 작성했음!)
-
일단 이 pipeline은 프로그래밍에서의 ‘알고리즘을 배우는 것’ 에만 한정이 되어 있음.
→ 수학,물리와 같은 다른 과목들에 있어서는 한계가 있다.
-
TeachYou를 써서 좀더 교실 환경에 사이즈를 키워서, 하는 것이 future work가 될 수 있을 것 같다.
-> 왜냐면 학습자들간에 variance도 크고, 기존의 지식에도 한계가 있으니까.
결론 :
-
single-agent에 대한 흥미 !
At first, 나는 단순히 무조건 multi-agent system이 많으니까 좋은 건 줄 알았다.
(왜냐? 매우 흥미롭기 때문.ㅎㅎㅎ)
However, agent 안에 들어 있는 다양한 reflection, memory 이런 요소들이 있기 때문에 그걸 어떻게 design할지 구상해보는 것도 매우 흥미로울 듯 하다. -
잘짜여진 논문 구조
문제점 → 그 문제점들을 해결하기 위한 design goal → design goal을 실현시키기 위해 구상한 방법론들
매우 잘 짜여진 논문구조인 것 같다.
