5가지 모듈들을 분류해서, 그렇게 MAS의 모듈을 5가지를 제안했다.
LLM-based MAS
3.1 Agent Profile
- generation strategy
- contexualized : 풀이 없이 시나리오를 가지고 그 시나리오를 가지고 하나하나에 적합하게 만들기 !
- pre-defined : 미리 풀을 만들고, 그걸 각각 시나리오에 맞게 뽑아온다 ! 이런 것 같음.
- learning-based : 몇몇 에이전트들을 넓게(포괄적으로) 만듦 + 새로운 에이전트가 생성되어 새로운 작업을 처리 ! ! !
3.2 Perception
-
message source
메세지는 전체 환경 , 상호작용 , 자기 반성 메세지 가 있따!!! -
message type
그 메세지의 타입이
시각 : VLM -> ViT를 써서 고정 크기 패치로 나눠서 고차원으로 매핑 => 계산 자원 되게 많이
(로보틱스에서는 자동 항해, 랜드마크 인식 같은 것을 한다 ! ! )
청각 : 청각으로만 전달해야하는 미묘한 메세지...
3.3 Self-Action
지각된 정보 수신(Environment) => 기억 호출 + 외부지식에서 추가지식 => 의사결정 => 행동 수행 + 기억을 자가 업데이트
- Memory
검색 / 저장 / 기억 반영
검색 :
저장 : 일반적으로 자연어로 저장 ! ! !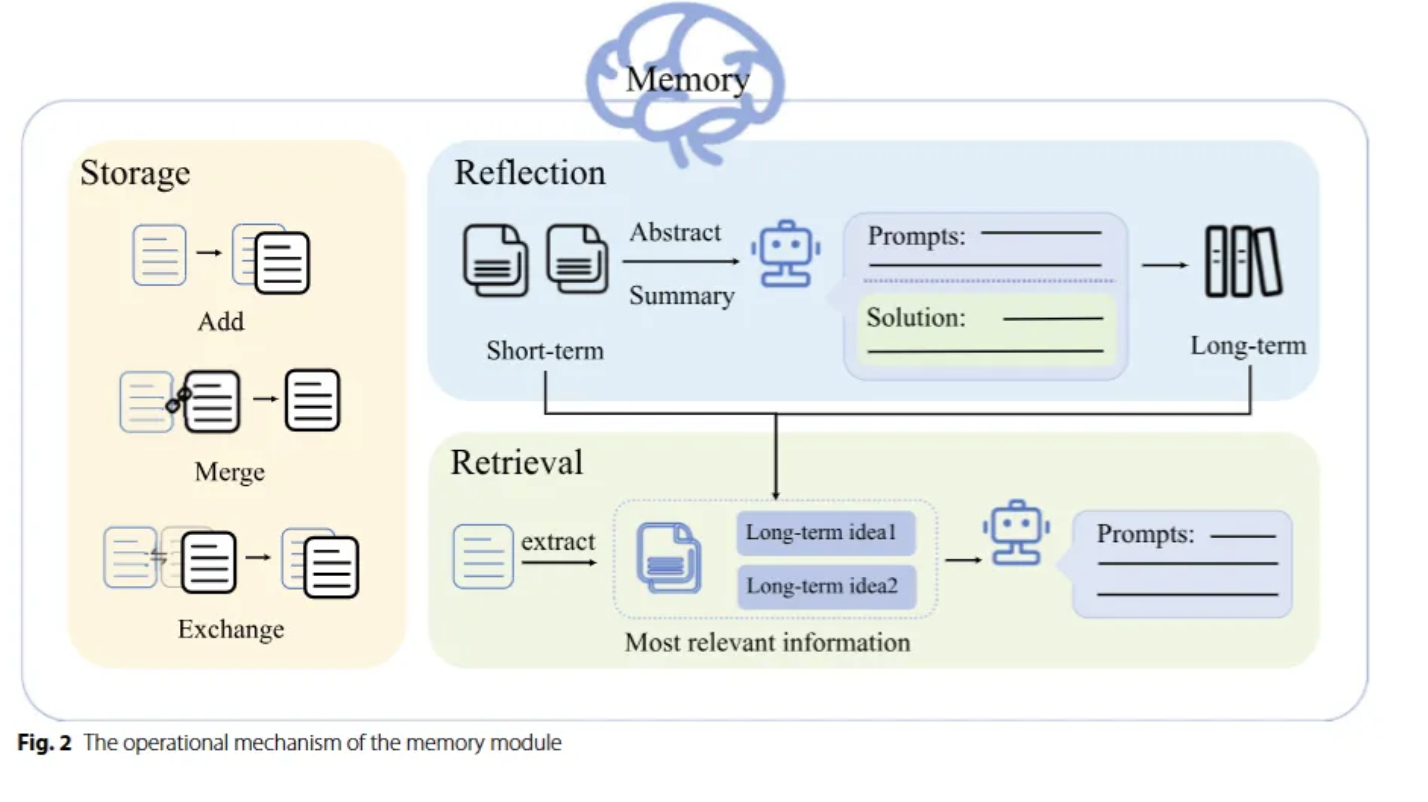
기억 반영 : 학습한 걸 가지고 어떻게 개선할지???
- knowledge utilization
외부에 있는 것을 활용하기 !
가져오는 방법 : RAG(구조화되지는 않음. 똑같이 가지고 오는거지만, RAG는 다양하게 텍스트나 이미지를 가져옴) , API webscraping(실시간 최신뉴스, 하지만 법적인 문제 발생 가능성) , database(구조화된 데이터,명확하게 정리를 해두러야한다.)
-
추출 문제
할루시네이션 / 편향
편향 : 외부지식을 가져올 때 이러한 문제점들이 나타날 수 있따. -
추론과 계획하기 !
one-step reasoning : 한번에 단일 해결책
Multi-step reasoning : 여러 하위 작업들을 제안하는 것 !
- Action
one-step decision : 바로 즉각적인 의사결정을 내리는 것
pre-defined decision : rule-base에 이미 사전 정의된 계획을 따름.
dynamic : 나에게 주어진 상황들을 맞추어 동적으로 ! ! ! ! !
3.4 Mutual-interaction
- 메세지 전달
- 상호작용 구조 : 계층 / 분산 / 중앙집중 / 공유
- 상호작용 시나리오 : 협동 / 적대 / 혼합
3.5 Evolution
- 환경 피드백
- agent interaction
- human feedback
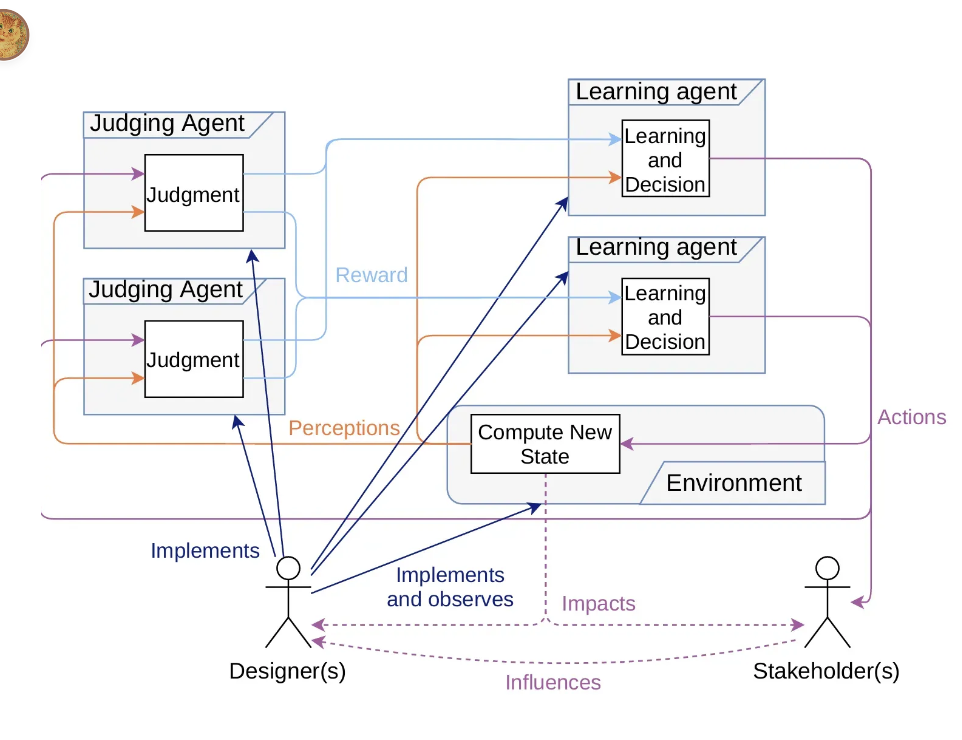
환경에 의해 피드백을 가지고 그걸 가지고 interaction을 하고 human feedback을 !
그렇다면 어떻게 발전?
prompt engineering / reinforcment learning /

한발한발 나아갑니당!