Markov Chain
P(Xn|X1,X2 ,,,, Xn-1) = p(Xn|Xn-1)
: 처음부터 그 이전까지의 상태 = 그 이전만의
2.1 Single-agent reinforcement learning
(X,U,P,R,Y)
X : 상태들의 집합
U : 행동들의 집합
P : 전이 확률 함수
특정 상태에서 특정 행동을 취하고 다음 상태로 전이될 확률 ! ! ! !
R :
r : 0에 가까운 즉각적인 보상 ? 1에 가까울 수록 장기적인 보상
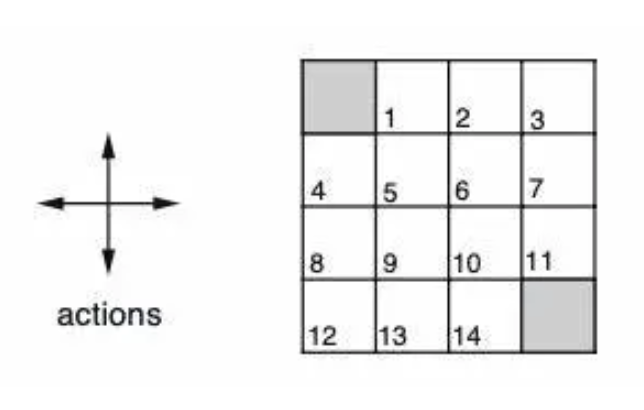
- 목표
: 누적된 보상을 최대화 ! !
정책은, 행동을 결정하는 규칙 혹은 확률 분포 ! ! !
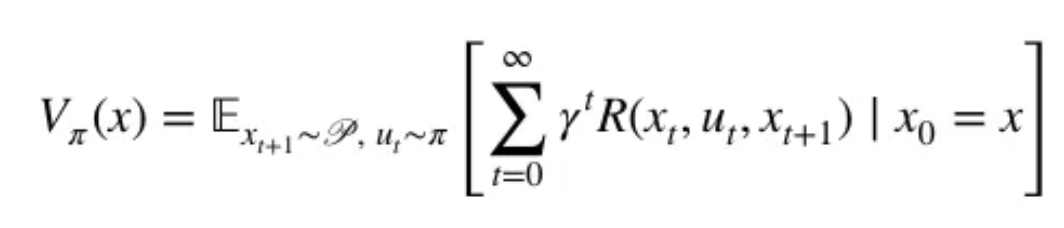
여러가지 정책을 했었을 때, 그 정책 중에 어떤 게 가장 좋은 건가?
그것은 정책가치함수로 할 수 있다 ! ! ! ! !
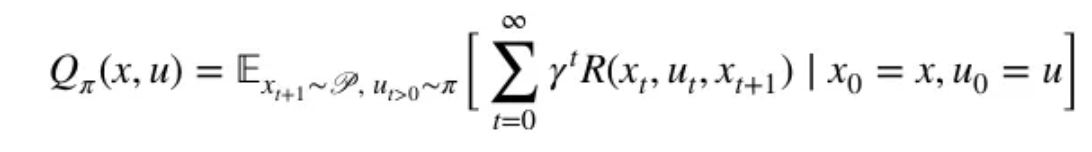
과연 어떤 행동이 유용할까??? 고정해두고, 얼만큼의 보상을 가져다줄지 구할 수 있는 식이다...! 행동하나에 대해!!!
2.2 Multi-agent reinforcement learning

N =
X =
U =
P =
R^i =
r =
목표는, 개별행위자가 장기적으로 누적 보상을 최대화하는 방식대로 행동!
각자의 정책에 따라서, 각자의 ㅠ에 따라서 행동을 실행한다
i의 정책에 대해 가치를 알고 싶은 것이다. 즉, 개별 행위자의 정책을 구하고 싶은 것이다 ! ! ! !

한발한발 나아갑니당!