
DFS ( Depth First Search )
깊이우선 탐색은 특정한 경로로 탐색하다가 특정한 상황에서 최대한 깊숙이 들어가서 노드를 방문한 후, 다시 돌아가 다른 경로로 탐색하는 알고리즘이다.
동작 과정
- 탐색 시작 노드를 스택에 삽입하고 방문 처리를 한다.
- 스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면 그 인접 노드를 스택에 넣고 방문 처리를 한다. 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼낸다.
- 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
사례
출처 : 이것이 취업을 위한 코딩 테스트다 with 파이썬
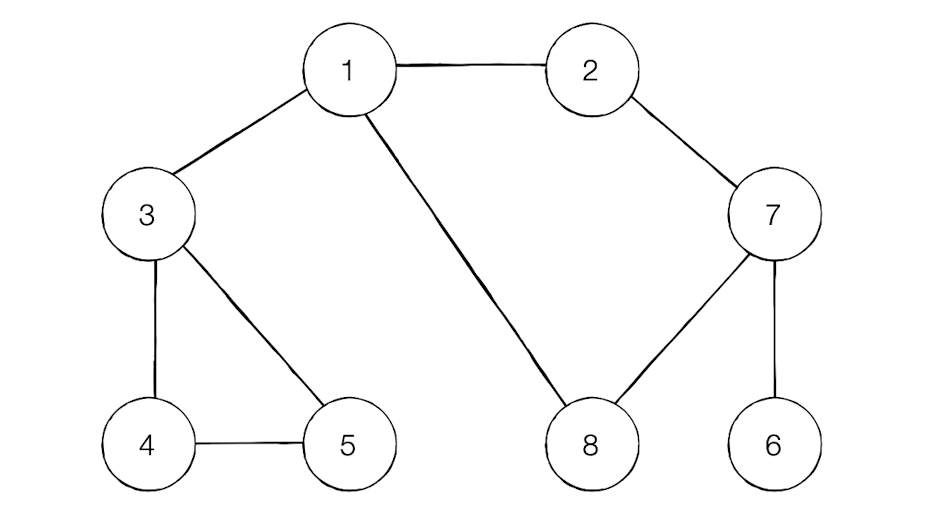
노드 1을 시작으로 DFS 탐색
탐색 시작 노드가 노드1이니 스택에 1을 삽입한다.
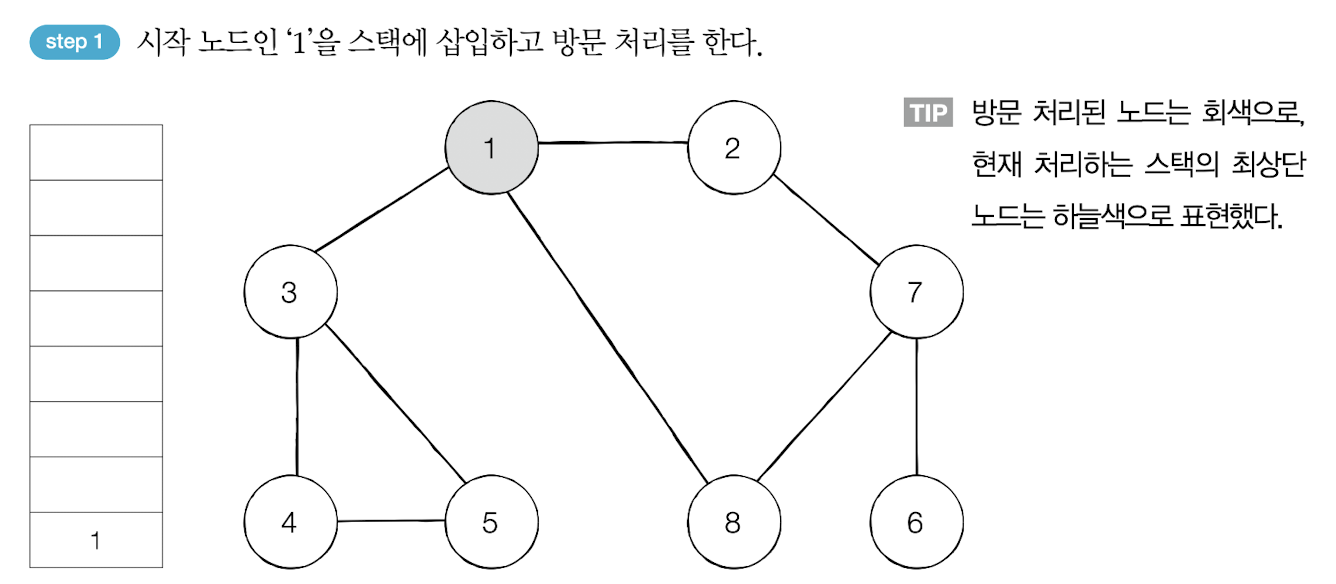
인접 노드중 숫자가 가장 작은 노드를 스택에 넣고 방문한다.
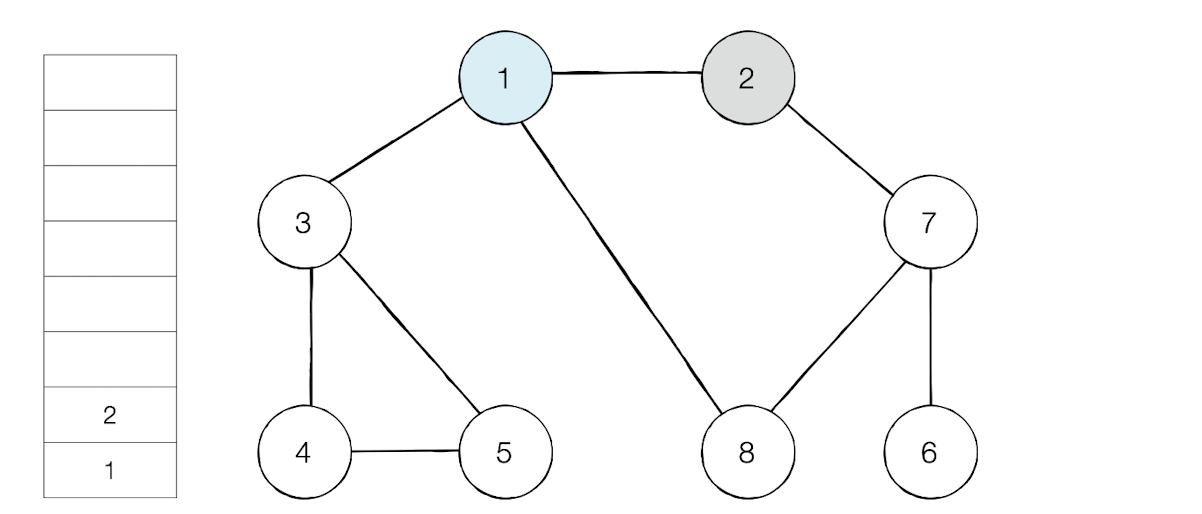
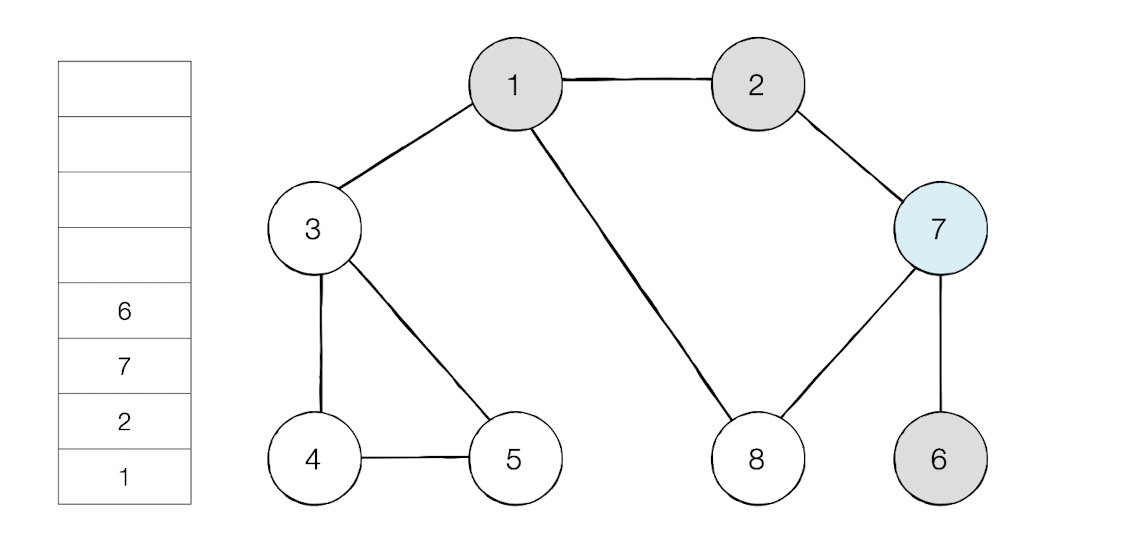
이제 스택의 최상단 노드가 된 6은 방문하지 않은 인접노드가 없다.
그러면 스택에서 6을 꺼낸다.
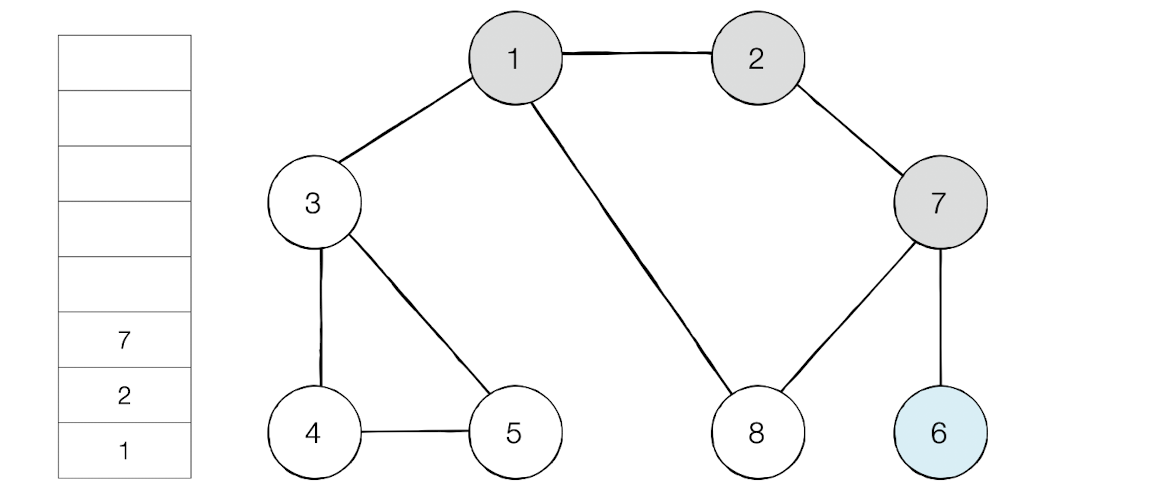
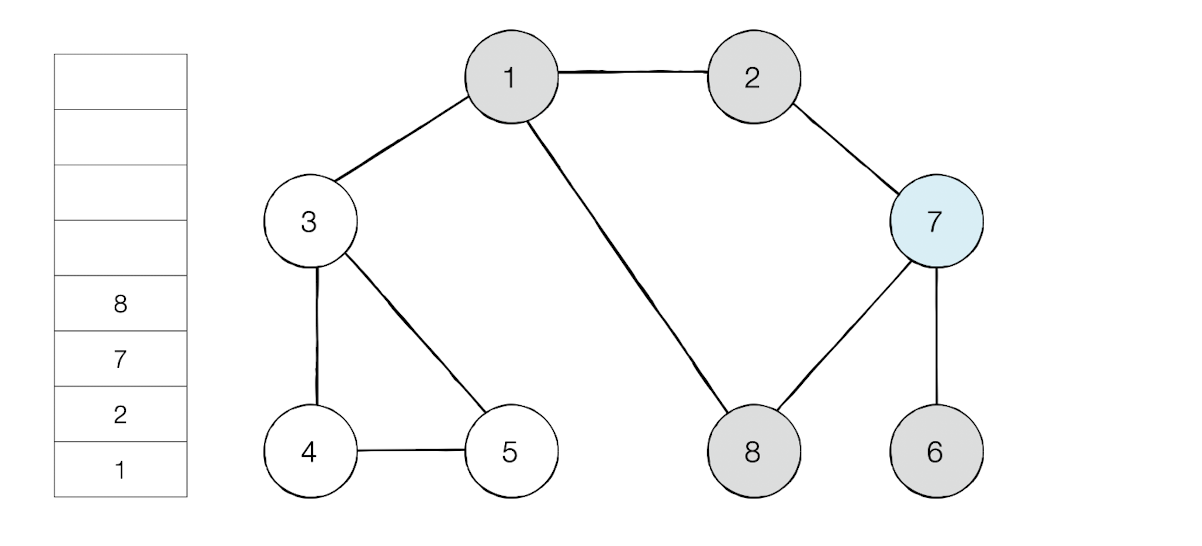
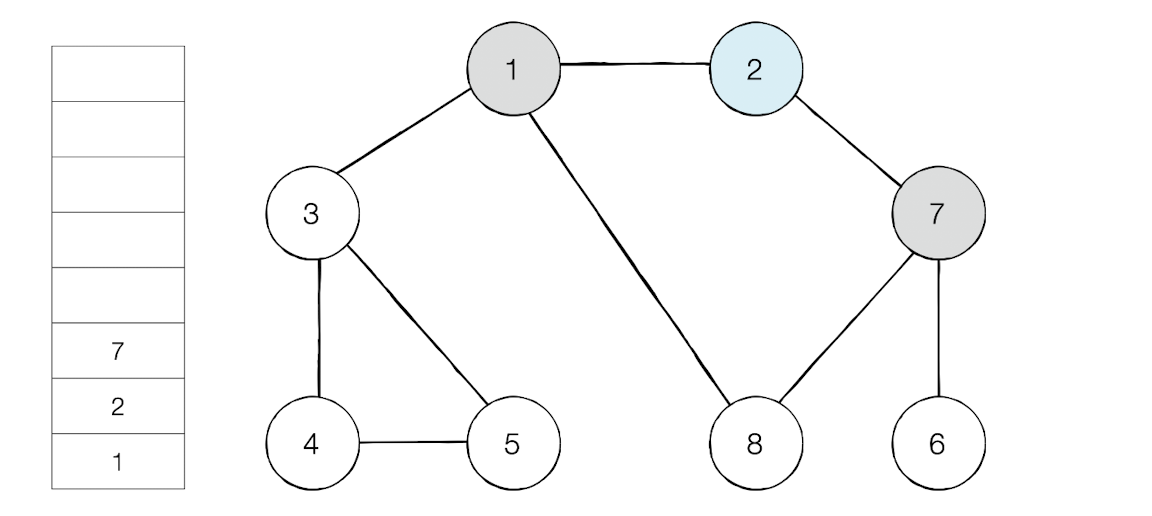
최상단 노드가 된 노드8은 이제 인접 노드중 방문하지 않은 노드가 없다. 그러면 스택에서 노드를 꺼낸다.
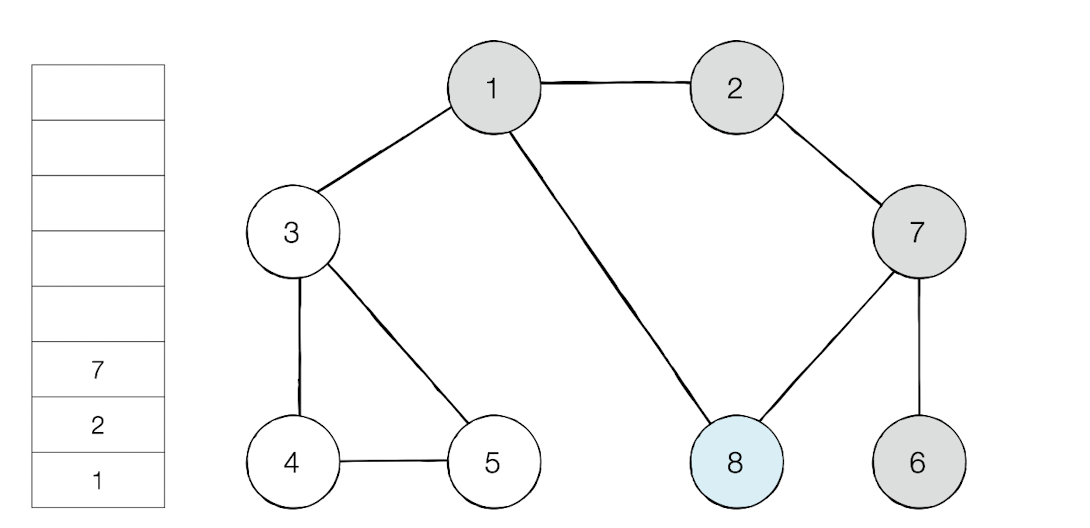
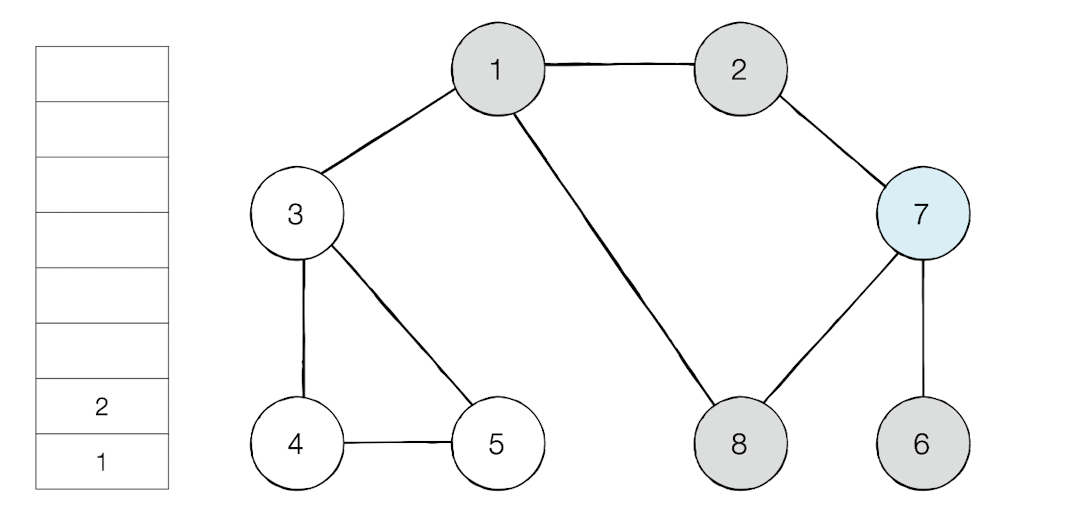
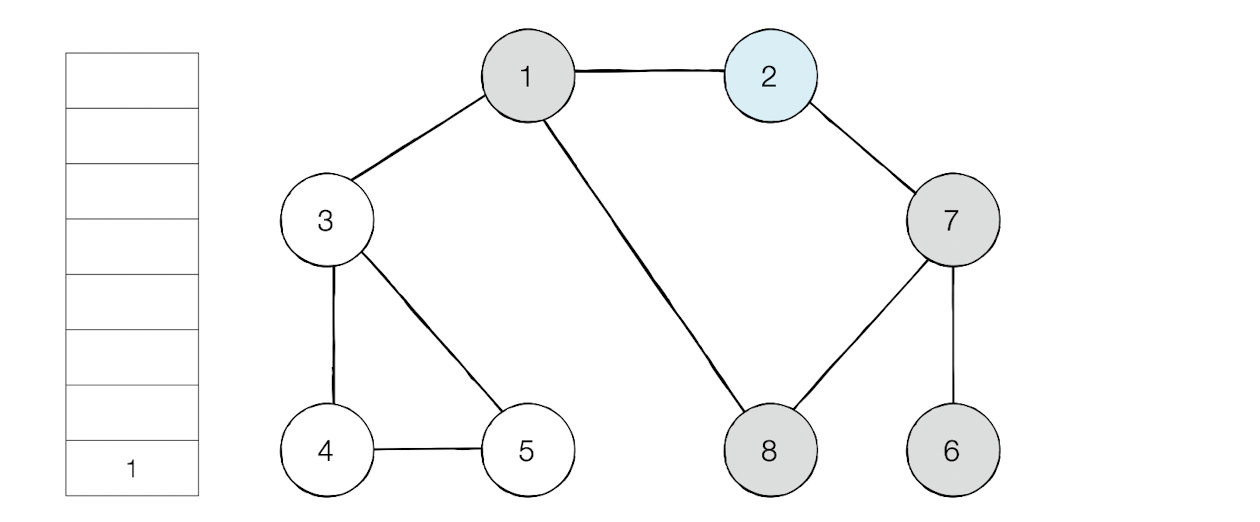
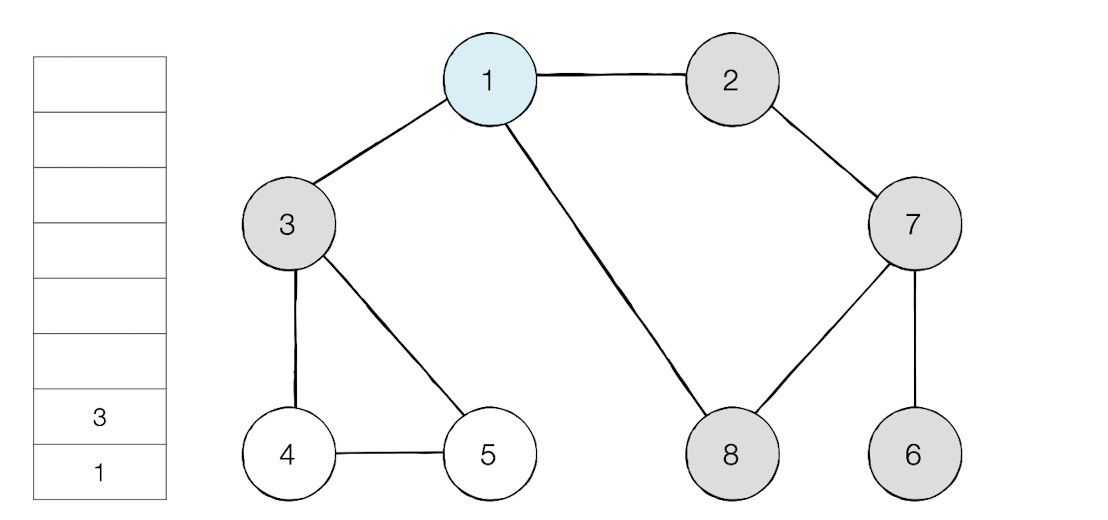
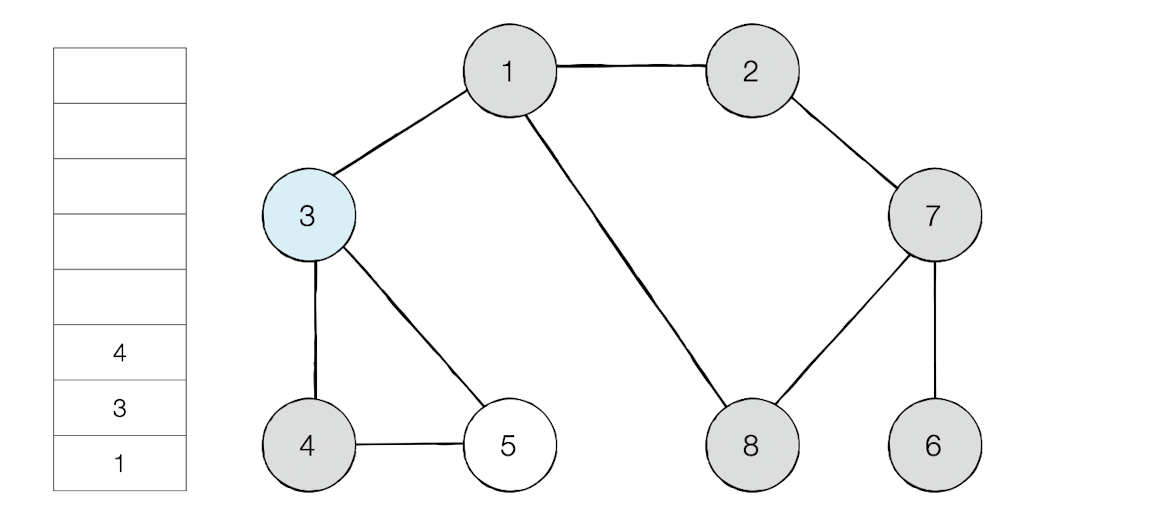
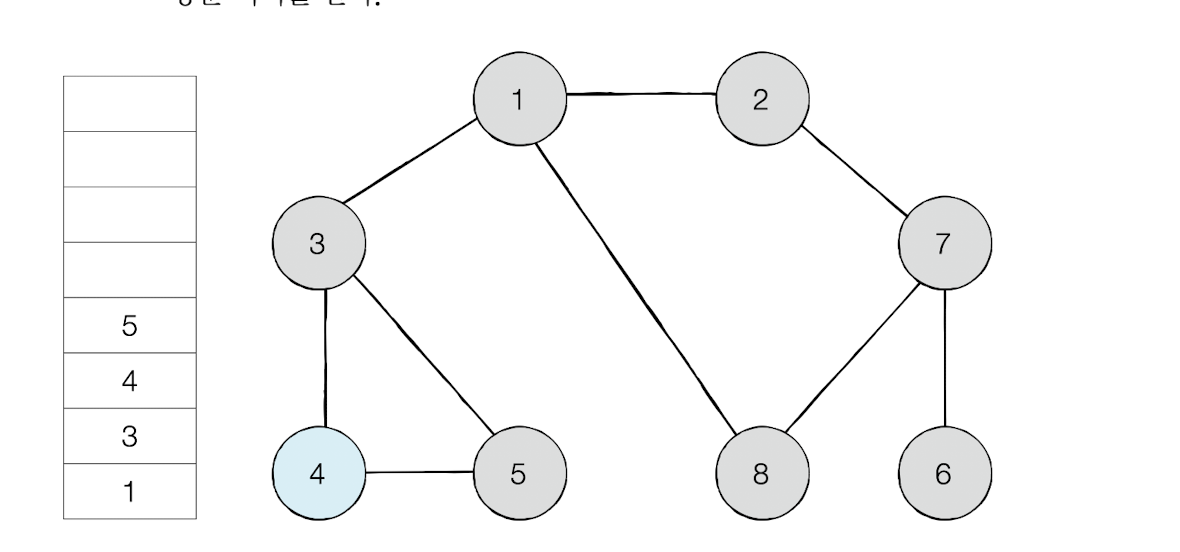
방문 순서 : 1 -> 2 - >7 -> 6 -> 8 -> 3 -> 4 -> 5
구현 코드
1) 인접 리스트
def dfs(graph, v, visited):
# 현재 노드를 방문 처리
visited[v] = True
print(v, end=' ')
# 현재 노드와 연결된 다른 노드를 재귀적으로 방문
for i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
# 각 노드가 연결된 정보를 리스트 자료형으로 표현(2차원 리스트)
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
# 각 노드가 방문된 정보를 리스트 자료형으로 표현(1차원 리스트)
visited = [False] * 9
# 정의된 DFS 함수 호출
dfs(graph, 1, visited)2) 인접 리스트
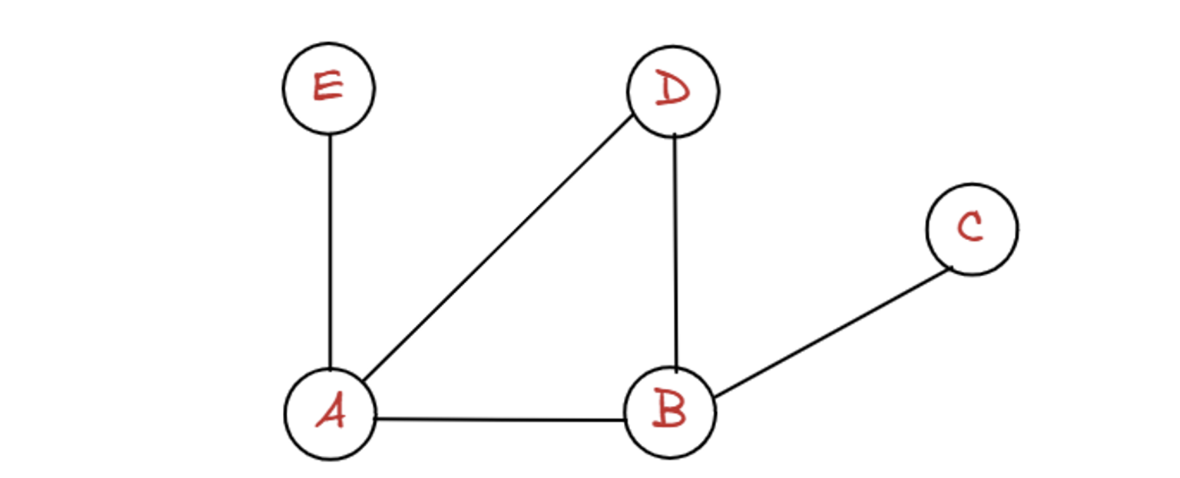
graph = {
"A": ["B", "D", "E"],
"B": ["A", "C", "D"],
"C": ["B"],
"D": ["A", "B"],
"E": ["A"]
}
visited = []
def dfs(cur_v):
visited.append(cur_v)
for v in graph[cur_v]:
if v not in visited:
dfs(v)BFS ( Breadth First Search )
너비 우선 탐색은 가까운 노드부터 탐색하는 알고리즘이다. DFS 는 BFS 와 반대로 최대한 멀리 있는 노드를 우선으로 탐색하는 방식으로 동작한다.
BFS 의 구현은 FIFO 방식인 큐 자료구조를 이용한다. 인접한 노드를 반복적으로 큐에 넣도록 알고리즘을 작성하면 먼저 들어온 것이 먼저 나가게 되어, 가까운 노드부터 탐색을 진행하게 된다.
BFS 는 deque 라이브러리를 사용하는 것이 좋고 탐색을 수행하는데 O(N) 의 시간이 소요된다. 일반적으로 실제 수행 시간은 DFS 보다 좋다.
동작 과정
- 탐색 시작 노드를 큐에 삽입하고 방문 처리를 한다.
- 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리를 한다.
- 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
사례
출처 : 이것이 취업을 위한 코딩 테스트다 with 파이썬
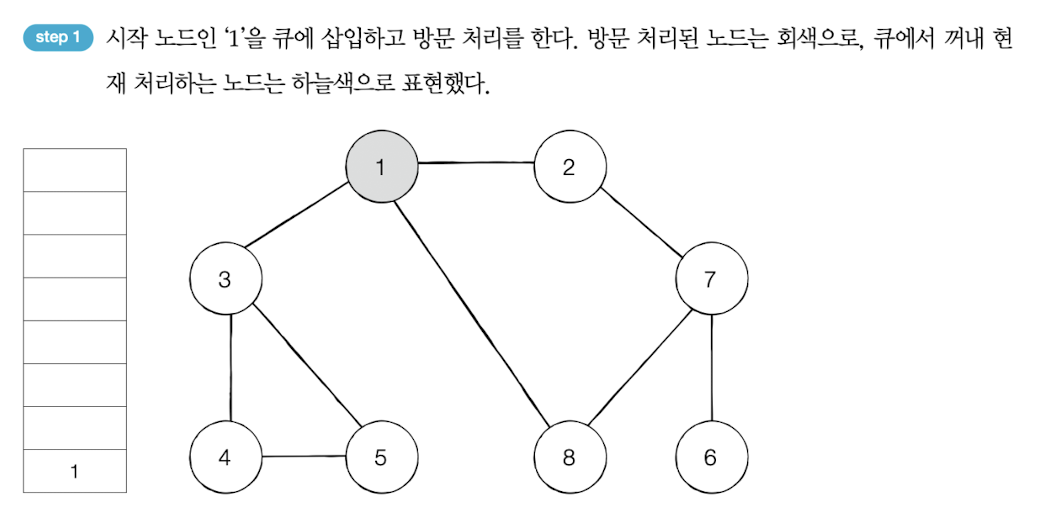
큐에서 1을 꺼내고 방문하지 않은 인접 노드 2, 3, 8을 모두 큐에 삽입하고 방문 처리를 한다.
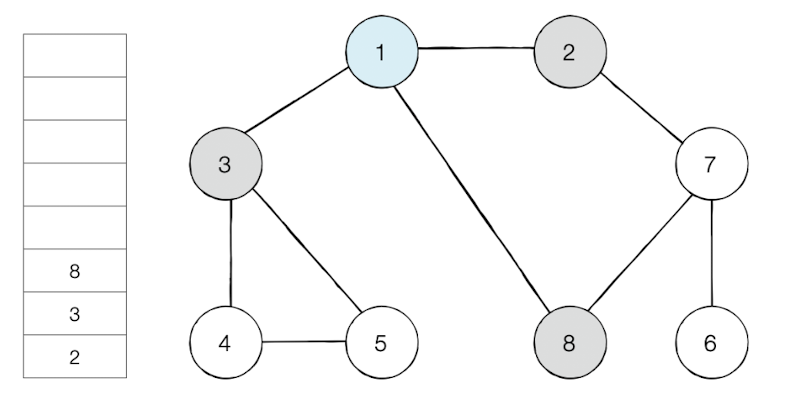
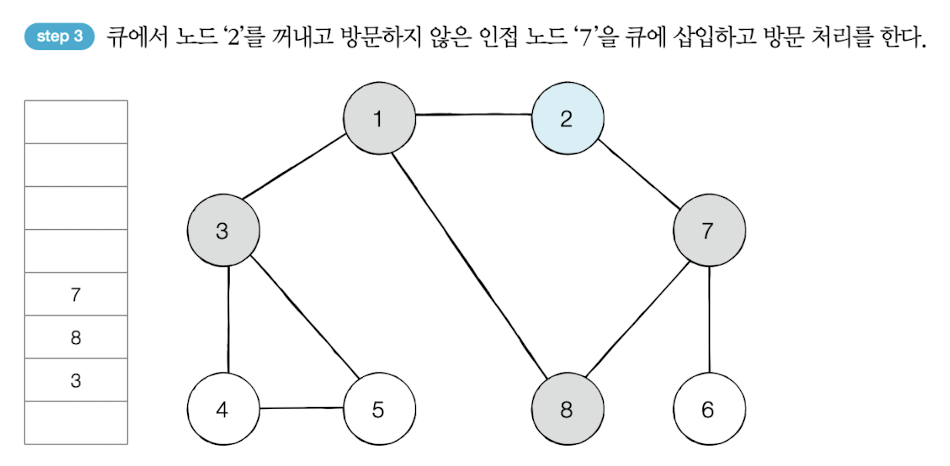
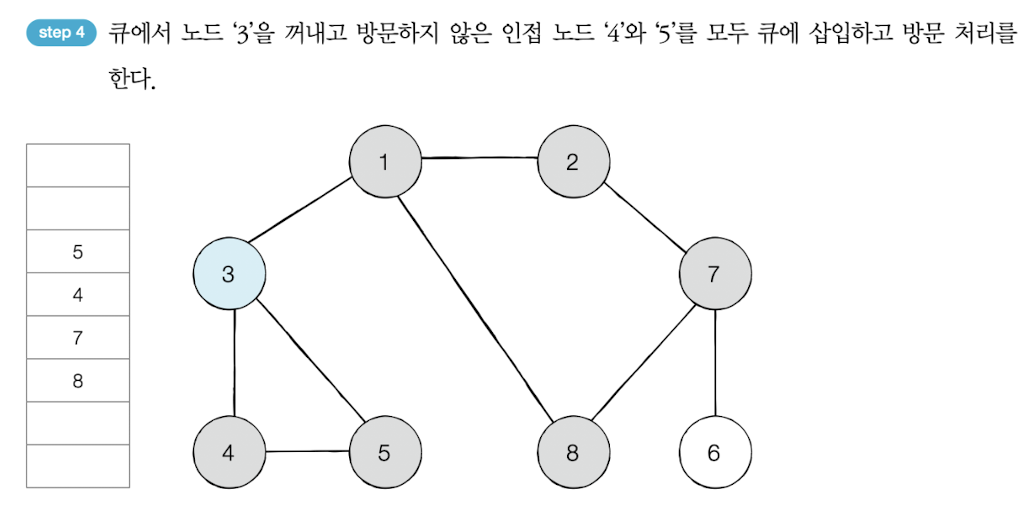
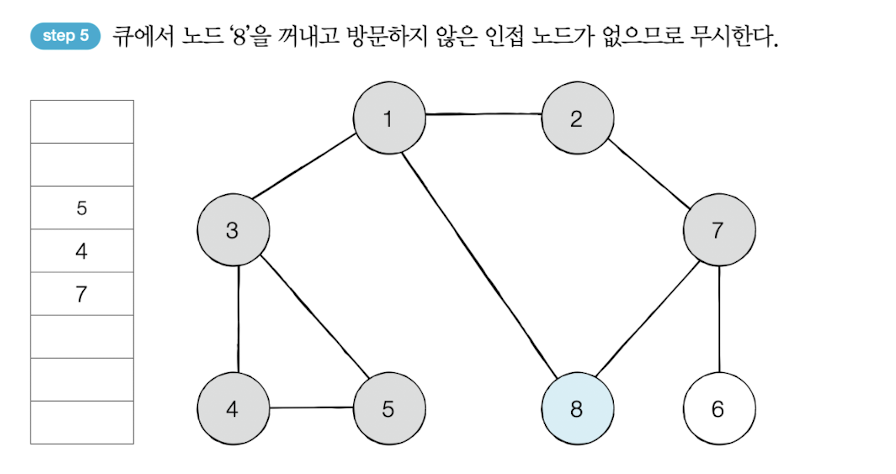
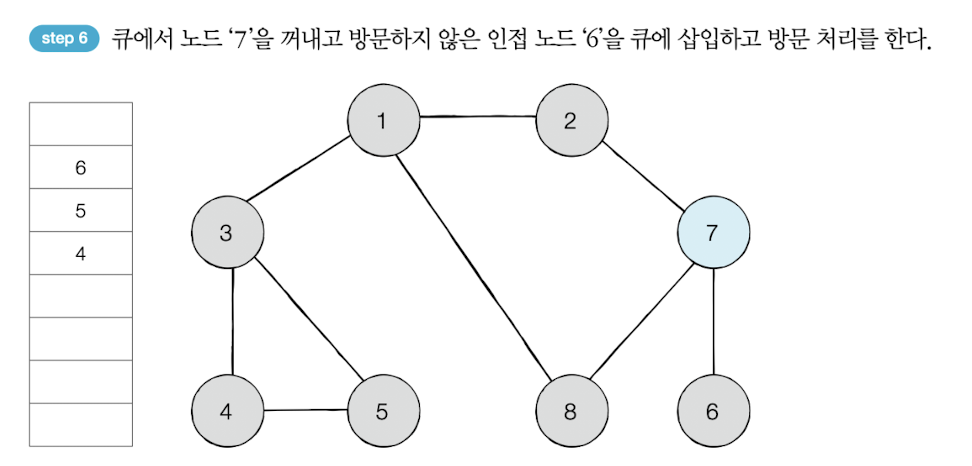
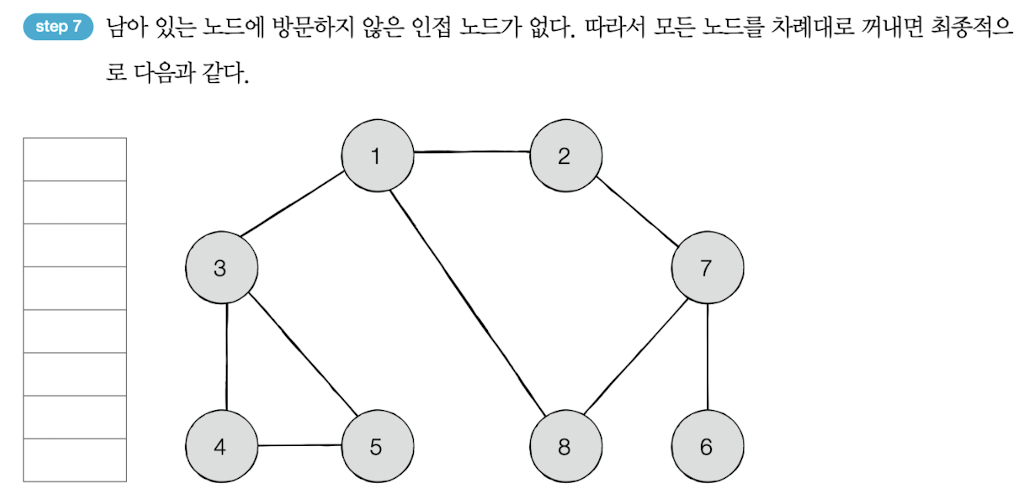
방문 순서 : 1 -> 2 -> 3 -> 8 -> 7 -> 4 -> 5 -> 6
구현 코드
1) - 인접 리스트
from collections import deque
# BFS 메서드 정의
def bfs(graph, start, visited):
# 큐(Queue) 구현을 위해 deque 라이브러리 사용
queue = deque([start])
# 현재 노드를 방문 처리
visited[start] = True
# 큐가 빌 때까지 반복
while queue:
# 큐에서 하나의 원소를 뽑아 출력
v = queue.popleft()
print(v, end=' ')
# 해당 원소와 연결된, 아직 방문하지 않은 원소들을 큐에 삽입
for i in graph[v]:
queue.append[i]:
visited[i] = True
# 각 노드가 연결된 정보를 리스트 자료형으로 표현(2차원 리스트)
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
# 각 노드가 방문된 정보를 리스트 자료형으로 표현(1차원 리스트)
visited = [False] * 9
# 정의된 BFS 함수 호출
bfs(graph, 1, visited)2) - 인접 리스트
from collections import deque
graph = {
"A": ["B"],
"B": ["A", "C", "E"],
"C": ["B", "D"],
"D": ["C", "E", "F"],
"E": ["B", "D", "F"],
"F": ["D", "E"],
}
def bfs(graph, start_v):
visited = [start_v]
queue = deque(start_v)
while queue:
cur_v = queue.popleft()
for v in graph[cur_v]:
if v not in visited:
visited.append(v)
queue.append(v)
return visited3) 인접 행렬
문제 출처 : 백준 2606 바이러스
# 그래프 이론, 그래프 탐색, 너비 우선 탐색, 깊이 우선 탐색
import sys
from collections import deque
N = int(sys.stdin.readline().rstrip()) # 컴퓨터의 수
M = int(sys.stdin.readline().rstrip()) # 네트워크 상에서 직접 연결되어 있는 컴퓨터 쌍의 수
matrix = [[0] * N for _ in range(N)]
visited = [False] * N
for _ in range(M):
i, j = map(int, input().split())
matrix[i-1][j-1] = 1
matrix[j-1][i-1] = 1
queue = deque([1])
visited[0] = True
def bfs():
count = 0
while queue:
node = queue.popleft()
for idx, val in enumerate(matrix[node - 1]):
if val == 1 and visited[idx] is False:
queue.append(idx + 1)
visited[idx] = True
count += 1
return count
print(bfs())추가로 참고 - 시간초과 팁
