
📚 서론
데이터베이스에 대해 간단한 내용을 배우고 바로 ORM 중 sequelize 에 대해 수업이 진행되었다. 데이터베이스중 CRUD 만 배우고 ORM 으로 넘어가니 CRUD 정도만 실습해봤는데 그정도로 끝낼수는 없다. 좀더 깊이 알아보자.
📘 ORM
우선 sequelize 가 ORM 이라고 했는데 대체 ORM 이란 뭘까?
ORM: Object Relational Mapping, 객체 관계 매핑
음.. 객체 - 관계 매핑? 아직은 이해가 되지 않는다.
자료조사를 해보니 ORM 은 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결)해주는 것을 말한다고 한다.
구체적으로는 OOP (Object Oriented Programming 객체 지향 프로그래밍) 에서는 클래스를 사용하고 RDMS 에서는 테이블을 사용한다. OOP 에서 데이터를 클래스를 통해 저장하려는데 이를 테이블로 전환해줘야 하는 상황이 발생한 것이다.
이렇게 객체를 데이터베이스의 필드로 매핑시켜주는 역할을 ORM 이 하는 것이다.
장점
- Persistent Layer 를 추상화하여 애플리케이션 레벨에서 DBMS 종속성을 제거할 수 있다.
단점
- 복잡한 쿼리를 작성하는데 적합하지 않다.
- 생각했던 대로 쿼리가 나가지 않을 때가 있다.(n+1문제)
- ORM, DBMS 둘다 높은 러닝 커브가 있다.
n+1 문제
연관 관계에서 발생하는 이슈로 연관 관계가 설정된 엔티티를 조회할 경우에 조회된 데이터 갯수만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오게 되는 문제를 N+1 문제라고 한다. 데이터가 굉장히 많이 쌓인 상태를 생각해보자. 이때 데이터 갯수만큼 연관관계의 조회 쿼리가 추가로 발생한다면 쿼리가 실행되는 시간이 점점 길어질 것이다.
정작 원하는 데이터는 많지 않은데 데이터 수만큼 쿼리문이 발생하는 상황이라고 보면 될 것 같다. 이걸 개선한다면 마치 insert into 쿼리중 value 에 여러 값을 넣는 경우 여러 쿼리를 줄여서 한번의 쿼리로 실행하는 것처럼 쿼리 실행 수를 확 줄일 수 있지 않을까?
📘 Sequelize
npm i sequelize sequelize-cli mysql2
npx sequelize initORM 중 하나인 Sequelize 에 대해서 알아보자.
Sequelize 는 제 3자 외부 패키지로 Object Relational Mapping Library 이다. Sequelize 는 백그라운드에서 실제로 SQL 코드를 처리하며 JavaScript 객체로 맵핑하여 SQL 코드를 실행하는 편리한 메서드를 제공하기 때문에 SQL 코드를 직접 작성하지 않아도 된다.
User 라는 객체에 이름, 나이, 이메일, 비밀번호 정보가 있다고 가정하자. 객체가 Sequelize 에 의해 데이터베이스에 맵핑되면 테이블과 관계까지 자동으로 생성한다. 이때 새로운 사용자를 만들기 위해 User 라는 JavaScript 객체에 메서드를 호출하면 Sequelize 가 필요한 SQL 쿼리 및 명령을 실행한다.
이는 SQL 을 직접 짤 필요없이 생성한 JavaScript 객체만 다루면 된다는 것을 의미한다.
class User {
constructor(name, age, email, password) {
this.name = name;
this.age = age;
this.email = email;
this.password = password;
}
}
// 클래스 인스턴스 생성 예시
const newUser = new 사용자('홍길동', 30, 'hong@example.com', 'mysecretpassword');위와 같은 User 라는 객체를 MySQL 의 user 테이블에 매핑을 시켜줘서 SQL 상에서 직접 SQL 문을 작성하지 않아도
create table user(
id int primary key auto_increment not null,
name varchar(255) not null,
age int not null,
email varchar(255) not null,
password varchar(255) not null
);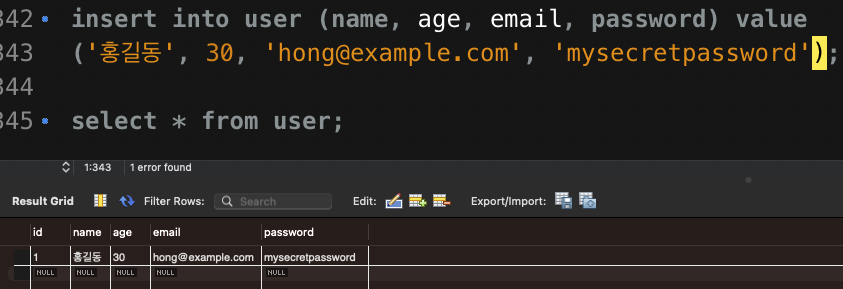
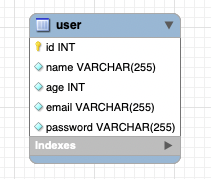
sequelize 의 메서드가 위와 같은 user 테이블에 매핑을 시켜준다.
const user = User.create({
name: '홍길동',
age: 30,
email: 'hong@example.com',
password: 'mysecretpassword'
});Sequelize 는 데이터베이스를 다루는 모델을 제공하고 모델을 정의할 수 있게 한다. 모델을 구성하는 데이터 (데이터베이스에 저장될 데이터) 를 정의한다. 그 후 사용자, 제품같은 클래스를 실체화하려면 생성자 함수를 실행하거나 utility 메서드를 이용해 모델에 기반한 새로운 사용자 객체를 생성한다. 또한 쿼리를 실행할 수 있다. 새로운 사용자를 저장하는 경우도 있으나 검색하는 경우도 있기 마련이다.
이러한 과정은 모두 Sequelize 로 정의한 모델과 관련이 있다.
그리고 모델들을 연관시킬 수 있다. 예를 들어 User 모델을 Product 모델과 연관시킬 수 있다.
예시
Model->User,Product
Instance->const user = User.build()
Queries->User.findAll()
Associations->User.hasMany(Product)
📗 모델 기초
📕 Model Definition
모델은 Sequelize 의 핵심이며 데이터베이스에서의 테이블을 추상화한 것이다.
모델은 Sequelize 에게 데이터베이스의 테이블 이름, 테이블에 포함된 column 과 데이터 타입들과 같이 모델이 나타내는 엔티티에 대한 여러 정보를 알려준다.
모델은 이름이 있는데 이 이름은 데이터베이스의 테이블명과 같을 필요가 없다. 이 둘이 전적으로 동일할지라도 일반적으로 모델은 단수의 이름을 갖는데 비해 테이블은 복수의 이름을 갖는다. ( User / Users )
모델은 다음 두가지 방법으로 정의할 수 있다.
sequelize.define(modelName, attributes, options)
init(attributes, options)실제 사용 예시
sequelize.define 사용시
const { Sequelize, DataTypes } = require('sequelize');
const sequelize = new Sequelize('database', 'username', 'password', {
host: 'localhost',
dialect: 'mysql'
});
const User = sequelize.define('user', {
name: {
type: DataTypes.STRING,
allowNull: false // allNull default 는 true 이다.
},
age: {
type: DataTypes.INTEGER,
allowNull: false
},
email: {
type: DataTypes.STRING,
allowNull: false,
unique: true
},
password: {
type: DataTypes.STRING,
allowNull: false
}
});
// 모델을 기반으로 테이블이 생성됨
sequelize.sync();
// `sequelize.define` 은 model 을 반환한다.
console.log(User === sequelize.models.User) // trueModel 상속시
const { Sequelize, DataTypes, Model } = require('sequelize');
const sequelize = new Sequelize('database', 'username', 'password', {
host: 'localhost',
dialect: 'mysql'
});
class User extends Model {}
User.init({
name: {
type: DataTypes.STRING,
allowNull: false
},
age: {
type: DataTypes.INTEGER,
allowNull: false
},
email: {
type: DataTypes.STRING,
allowNull: false,
unique: true
},
password: {
type: DataTypes.STRING,
allowNull: false
}
}, {
sequelize, // static init 메서드의 매개변수와 연결되는 옵션으로 db.sequelize 객체를 넣어야 한다.
modelName: 'User', // 모델 이름 설정
timestamps: false // createdAt 및 updatedAt 열을 사용하지 않음
// timestamps: true, // createdAt 및 updatedAt 필드 자동 생성
freezeTableName: true, // 테이블 이름을 모델 이름과 동일하게 고정
underscored: true, // 카멜 케이스가 아닌 스네이크 케이스를 사용하여 열 이름 생성 (기본적으로는 카멜 케이스로 테이블명과 칼럼명을 만든다.)
tableName: 'Employees', // 테이블명 지정, 기본적으로 모델 이름의 소문자 및 복수형으로 만든다.
paranoid: true, // true 로 설정시 deletedAt 이라는 칼럼이 생기는데 로우를 삭제시 완전히 지우지 않고 지운 시간이 기록된다. 로우 조회시 deletedAt 의 값이 null 인 로우를 조회한다. 만약 로우를 복원해야 할 것 같다면 true 로 설정하자.
charset: 'utf8',
collate: 'utf8_general_ci' // 각각을 설정해야 한글이 입력된다. 이모티콘까지 입력하고 싶다면 utf8mb4 와 utf8mb4_general_ci 를 입력한다.
});
// 모델을 기반으로 테이블이 생성됨
sequelize.sync();
freezeTableName: true 설정시 테이블 이름을 모델 이름과 동일하게 고정해서 기본적으로 모델은 단수형, 테이블은 자동으로 복수형으로 생성되는데 이 옵션을 설정하면 Users 가 아닌 User 테이블도 생성할 수 있다.
혹은 Sequelize 인스턴스가 생성될때 전역적으로 정의할 수도 있다.
const sequelize = new Sequelize('database', 'username', 'password', {
host: 'localhost',
dialect: 'mysql',
define: {
freezeTableName: true
}
});📕 Model synchronization
모델을 정의할때 만약 테이블이 데이터베이스에 존재하지 않는다면? 혹은 존재하나 column 이나 다른 요소중 다른점이 있다면?
이러한 부분에서 모델 동기화가 등장했다. 모델은 model.sync(options) 을 통해 동기화시킬 수 있다. 이 호출을 통해 데이터베이스에 SQL 쿼리를 자동으로 실행한다. 단, 이 변화는 JavaScript 에서의 모델이 아닌 데이터베이스의 테이블에만 발생하는 것이다.
User.sync() : 테이블이 존재시 아무것도 하지 않고 존재하지 않았다면 생성한다.
User.sync( { force: true } ) : 테이블을 생성하고 이미 존재하는 경우 먼저 삭제후 생성한다.
User.sync( { alter: true } ) : 데이터베이스에 있는 테이블의 상태를 확인후 데이터베이스의 테이블이 모델과 동일하게끔 바꾼다.
// 이미 존재하는 테이블의 구조를 모델에 맞게 변경
User.sync({ alter: true })
.then(() => {
console.log('테이블 구조가 모델에 맞게 변경되었습니다.');
})
.catch((error) => {
console.error('테이블 구조 변경 실패:', error);
});await User.sync({ force: true }); // 특정 모델에 대해 동기화 설정
console.log("The table for the User model was just (re)created!");
await sequelize.sync({ force: true }); // 모든 모델을 한번에 동기화 설정
console.log("All models were synchronized successfully.");📕 테이블 삭제
await User.drop(); // 특정 테이블 삭제
console.log("User table dropped!");
await sequelize.drop(); // 모든 테이블 삭제
console.log("All tables dropped!");📕 Database safety check
sync, drop 옵션이 큰 영향을 끼치니 정규 표현식처럼 match 옵션을 통해 조건에 맞을때만 실행할 수 있도록 설정할 수 있다. 위의 force: true, alter: true 의 경우 이런 saftey check 와 함께 사용하는 것이 권장된다.
// This will run .sync() only if database name ends with '_test'
sequelize.sync({ force: true, match: /_test$/ });📕 sequelize cli
sequelize cli 도 같이 설치했었는데 어떤 명령어들이 있었는지 궁금해서 찾아봤다.
Sequelize CLI [Node: 10.21.0, CLI: 6.0.0, ORM: 6.1.0]
sequelize <command>
Commands:
sequelize db:migrate Run pending migrations
sequelize db:migrate:schema:timestamps:add Update migration table to have timestamps
sequelize db:migrate:status List the status of all migrations
sequelize db:migrate:undo Reverts a migration
sequelize db:migrate:undo:all Revert all migrations ran
sequelize db:seed Run specified seeder
sequelize db:seed:undo Deletes data from the database
sequelize db:seed:all Run every seeder
sequelize db:seed:undo:all Deletes data from the database
sequelize db:create Create database specified by configuration
sequelize db:drop Drop database specified by configuration
sequelize init Initializes project
sequelize init:config Initializes configuration
sequelize init:migrations Initializes migrations
sequelize init:models Initializes models
sequelize init:seeders Initializes seeders
sequelize migration:generate Generates a new migration file [aliases: migration:create]
sequelize model:generate Generates a model and its migration [aliases: model:create]
sequelize seed:generate Generates a new seed file [aliases: seed:create]
Options:
--version Show version number [boolean]
--help Show help [boolean]
Please specify a command추후 github sequelize-cli 문서를 참고하자.
📕 Timestamps
기본적으로 Sequelize 는 createdAt 과 updatedAt 필드를 DatTypes.DATE 타입으로 모든 모델에 생성한다.
Sequelize 를 이용해서 생성하거나 수정하는 순간을 자동으로 기록해준다.
이러한 동작은 option 에 timestamps: false 옵션을 주면 정지할 수 있다.
sequelize.define('User', {
// ... (attributes)
}, {
timestamps: false
});또한 createdAt, updatedAt 을 비활성화하거나 커스텀 이름을 붙여줄 수 있다.
class Foo extends Model {}
Foo.init({ /* attributes */ }, {
sequelize,
// don't forget to enable timestamps!
timestamps: true,
// I don't want createdAt
createdAt: false,
// I want updatedAt to actually be called updateTimestamp
updatedAt: 'updateTimestamp'
});실제 사용 사례
// Student.js
const { Sequelize, DataTypes } = require("sequelize");
const StudentModel = (sequelize) => {
const Student = sequelize.define("student", {
id: {
type: DataTypes.INTEGER,
allowNull: false,
primaryKey: true,
autoIncrement: true,
},
name: {
type: DataTypes.STRING(20),
allowNull: false,
},
major: {
type: DataTypes.STRING(30),
allowNull: false,
},
enroll: {
type: DataTypes.INTEGER,
allowNull: false,
},
createdAt: {
allowNull: false,
type: DataTypes.DATE,
defaultValue: Sequelize.literal("CURRENT_TIMESTAMP"),
},
updatedAt: {
allowNull: false,
type: DataTypes.DATE,
defaultValue: Sequelize.literal("CURRENT_TIMESTAMP"),
},
});
return Student;
};
module.exports = StudentModel;-- students 테이블에 데이터 삽입
INSERT INTO students (name, major, enroll)
VALUES
('학생1', '전공1', 2020),
('학생2', '전공2', 2019),
('학생3', '전공1', 2021),
('학생4', '전공3', 2018),
('학생5', '전공2', 2019),
('학생6', '전공1', 2020),
('학생7', '전공3', 2021),
('학생8', '전공2', 2018),
('학생9', '전공1', 2019),
('학생10', '전공3', 2020);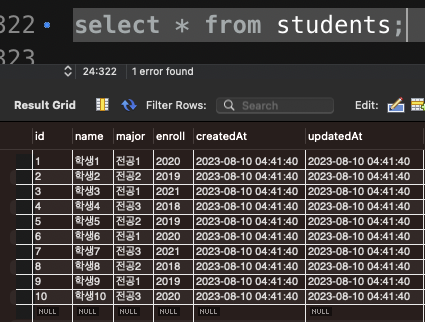
이런 특징은 사용자가 생성된 시점, 마지막으로 로그인한 시점, 수정한 시점등을 기록하여 다른 기능을 제공하고자 할때 활용할 수 있다.
📕 단축
만약 데이터 타입만 명시하면 단축하여 사용할 수 있다.
// This:
sequelize.define('User', {
name: {
type: DataTypes.STRING
}
});
// Can be simplified to:
sequelize.define('User', { name: DataTypes.STRING });📕 기본값
Sequelize 의 기본값은 대체로 NULL 이나 다른 기본값을 명시하기 위해서 defaultValue 속성을 사용할 수 있다. 혹은 DataTypes.NOW 같은 특수한 값들을 사용할수도 있다.
sequelize.define('User', {
name: {
type: DataTypes.STRING,
defaultValue: "John Doe"
}
});
sequelize.define('Foo', {
bar: {
type: DataTypes.DATETIME,
defaultValue: DataTypes.NOW
// This way, the current date/time will be used to populate this column (at the moment of insertion)
}
});📕 데이터 타입
데이터타입은 sequelize 에서 built-in 으로 생성되어 있는것을 import 해서 사용한다.
const { DataTypes } = require("sequelize"); // Import the built-in data types📖 String
DataTypes.STRING // VARCHAR(255)
DataTypes.STRING(1234) // VARCHAR(1234)
DataTypes.STRING.BINARY // VARCHAR BINARY
DataTypes.TEXT // TEXT
DataTypes.TEXT('tiny') // TINYTEXT
DataTypes.CITEXT // CITEXT PostgreSQL and SQLite only.
DataTypes.TSVECTOR // TSVECTOR PostgreSQL only.TEXT: 긴 문자열을 저장할 때 사용되는 열 타입이다. STRING과는 달리 고정된 최대 길이가 없으며, 매우 긴 문자열을 저장할 수 있다.
TINYTEXT: 상대적으로 작은 용량을 가지며, 더 짧은 길이의 문자열을 저장할 수 있는 열 타입이다. TEXT보다 작은 크기의 문자열을 저장할 때 사용된다.
📖 Boolean
DataTypes.BOOLEAN // TINYINT(1)📖 Numbers
DataTypes.INTEGER // INTEGER
DataTypes.BIGINT // BIGINT
DataTypes.BIGINT(11) // BIGINT(11)
DataTypes.FLOAT // FLOAT
DataTypes.FLOAT(11) // FLOAT(11)
DataTypes.FLOAT(11, 10) // FLOAT(11,10)
DataTypes.REAL // REAL PostgreSQL only.
DataTypes.REAL(11) // REAL(11) PostgreSQL only.
DataTypes.REAL(11, 12) // REAL(11,12) PostgreSQL only.
DataTypes.DOUBLE // DOUBLE
DataTypes.DOUBLE(11) // DOUBLE(11)
DataTypes.DOUBLE(11, 10) // DOUBLE(11,10)
DataTypes.DECIMAL // DECIMAL
DataTypes.DECIMAL(10, 2) // DECIMAL(10,2)double 과 float 는 부동 소수점 숫자, 즉 실수값을 표현하는 데이터타입이며 double 이 더 큰 범위의 실수를 표현할 수 있다.
DECIMAL: 고정 소수점 숫자를 나타내는 열 타입으로, 특정한 소수 자릿수까지의 숫자를 저장할 수 있다. DECIMAL(10, 2)와 같이 사용하면 전체 자릿수가 10이고 소수점 이하 2자리의 숫자를 저장하는 열을 생성한다.- float, double 에서 첫 번째 인수는 전체 자릿수, 두 번째 인수는 소수점 이하 자릿수를 나타낸다.
MySQL, MariaDB 에서 DataType 중
INTEGER,BIGINT,FLOAT,DOUBLE은 부호가 없거나 0 으로 채울 수 있다.
DataTypes.INTEGER.UNSIGNED
DataTypes.INTEGER.ZEROFILL
DataTypes.INTEGER.UNSIGNED.ZEROFILL
// You can also specify the size i.e. INTEGER(10) instead of simply INTEGER
// Same for BIGINT, FLOAT and DOUBLE📖 Dates
DataTypes.DATE // DATETIME for mysql / sqlite, TIMESTAMP WITH TIME ZONE for postgres
DataTypes.DATE(6) // DATETIME(6) for mysql 5.6.4+. Fractional seconds support with up to 6 digits of precision
DataTypes.DATEONLY // DATE without time📖 UUIDs
UUID 의 타입은 DataTypes.UUID 이다. 이는 데이터 타입이 PostrgreSQL, SQLite 에서는 UUID 이고 MySQL 에서는 CHAR(36) 이다.
{
type: DataTypes.UUID,
defaultValue: DataTypes.UUIDV4 // Or DataTypes.UUIDV1
}기왕 데이터타입에 UUID 가 나온김에 id 로 UUID 와 ULID 가 사용되는 경우가 많으니 이에 대해 정리해봤다.
UUID: University Unique Identifiers 범용 고유 식별자
id 의 타입을 UUID 로 하면 다음과 같은 32개의 16진수 값이 생성된다. 지금까지 랜덤값으로 생각했었는데 자료를 조사하다보니 각 영역별 의미가 있었다.
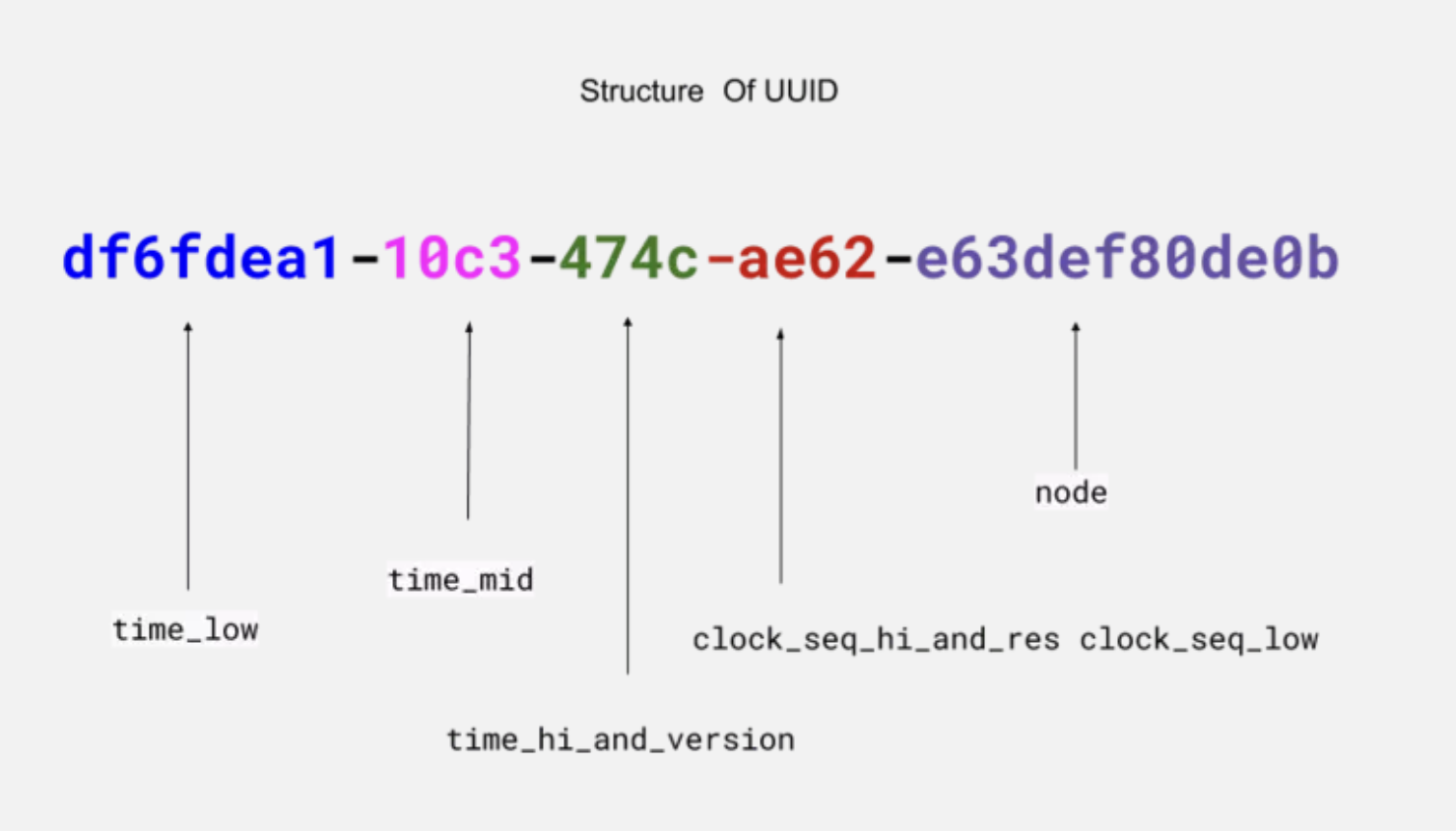
이미지 출처 : Your Guide To UUID In Java
123e4567-e89b-12d3-a456-426614174000const { v4: uuidv4 } = require('uuid');
class User {
constructor(이름, 나이) {
this.id = uuidv4(); // 랜덤한 UUID 생성
this.name = name;
this.age = age;
}
}
// 클래스 인스턴스 생성 예시
const newUser = new 사용자('홍길동', 30);sequelize 에서의 사용 예시
const { DataTypes } = require("Sequelize");
Foo.hasOne(Bar, {
foreignKey: {
// name: 'myFooId'
type: DataTypes.UUID
}
});
Bar.belongsTo(Foo);글을 다 작성하고 재밌는 부분이 있어서 내용을 추가했다.
벨로그에서 개발자모드를 켜고 애플리케이션에서 쿠키에 들어가 https://velog.io 로 들어가보면 acceess_token, refresh_token 을 볼 수 있는데 이거 어디서 많이 본 형태다.
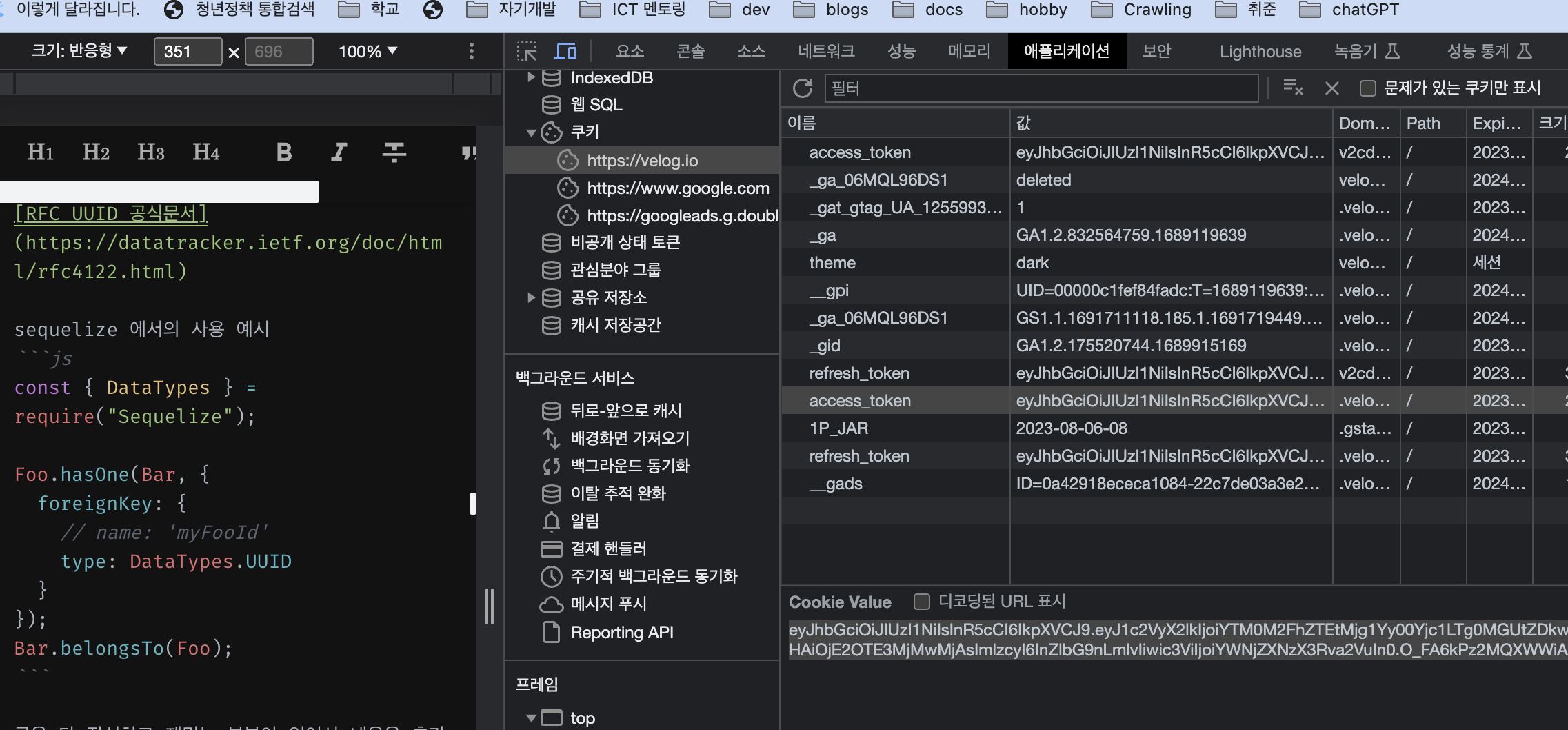
이거 혹시 velog 에서 토큰 발급할때 jwt 토큰쓰고 있나..?
바로 jwt.io 사이트에 가서 확인해봤다.
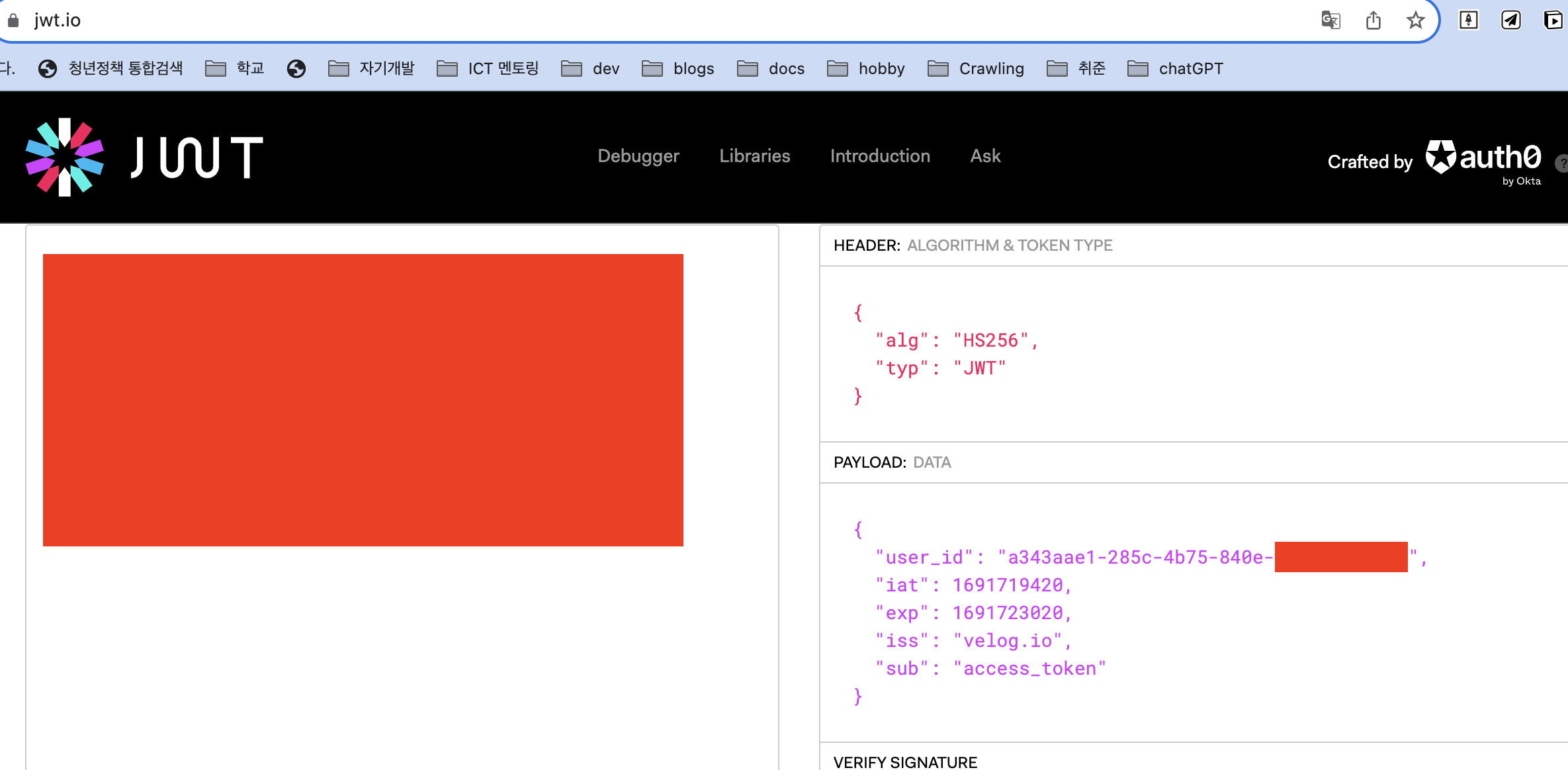
wow.. payload 를 보면 velog 에선 쿠키에 토큰 정보를 넣고 있으며 토큰은 jwt 토큰으로 생성했고 user_id 는 UUID 로 생성했음을 알 수 있다.
이런게 일상의 소소한 행복같은게 아닐까?
잠깐의 딴짓의 결과 벨로그는 유저 아이디를 UUID 형식으로 만들어 사용중이란 사실을 알게 되었다.
ULID: Universally Unique Lexicographically Sortable Identifier
대소문자를 구별하지 않는 시간을 나타내는 26자 글자와 16자 글자의 임의의 값으로 구성되어 있다.
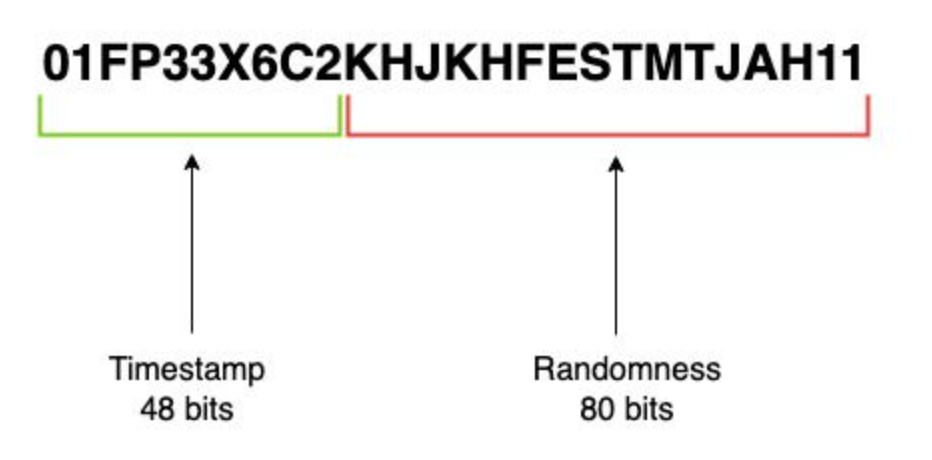
이미지 출처 : Discover ULID: the sortable version of UUID
사용법
script tag 사용시
<script src="https://unpkg.com/ulid@{{VERSION_NUMBER}}/dist/index.umd.js"></script>
<script>
ULID.ulid()
</script>npm 설치시
npm install --save ulid사용
// TS, ES6+, Babel, Webpack, Rollup ...
import { ulid } from 'ulid'
ulid() // 01ARZ3NDEKTSV4RRFFQ69G5FAV
// CommonJS
const ULID = require('ulid')
ULID.ulid()
// AMD (RequireJS)
define(['ULID'] , function (ULID) {
ULID.ulid()
});충돌 가능성에 대비하여 단조롭게 증가하는 ULID 를 생성할수도 있다.
import { monotonicFactory } from 'ulid'
const ulid = monotonicFactory()
// Assume that these calls occur within the same millisecond
ulid() // 01BX5ZZKBKACTAV9WEVGEMMVRZ
ulid() // 01BX5ZZKBKACTAV9WEVGEMMVS0이걸 왜 조사했을까?
보통 UUID 를 많이 쓰던데 ULID 의 장점이 있어서 이걸 정리하고 싶었다.
ULID 의 앞에는 timestamp 가 저장된다. 이건 primary key 타입을 ULID 로 하여 생성했을때 id 값으로 시간순으로 정렬시킬 수 있다는 것을 의미한다. 일반적으로 id 는 auto_increment 로 만들어왔을텐데 실제로는 그렇게 사용하는 경우가 거의 없다. 어떤 유저든 id 값을 그냥 integer 로 숫자를 넣다보면 정말 중요한 primary key 인데 그냥 맞출수도 있는 것이다. 또한 고유한 키를 간단하게 생성해서 사용할 수 있기 때문에 UUID 를 id 로 많이 사용하는데 이걸 대신하여 ULID 를 사용한다면?
ulid 장점
- ID 를 정렬할 수 있다.
- 고유한 값이라 중복 가능성이 거의 없다
- UUID 의 36자보다 26자로 구성되어 더 짧은 메모리를 차지한다.
중간에 갑자기 재밌는 내용이 나와서 좀 깊게 파봤다.. 다시 본론으로
📕 Column Options
나머지 option 들에 대해 확인해보자
const { Model, DataTypes, Deferrable } = require("sequelize");
class Foo extends Model {}
Foo.init({
// DATE 데이터 타입으로, defaultValue: DataTypes.NOW로 현재 시간이 기본 값으로 설정
myDate: { type: DataTypes.DATE, defaultValue: DataTypes.NOW },
// STRING 데이터 타입으로, allowNull: false로 설정되어 있어 NULL 값 허용하지 않는다.
title: { type: DataTypes.STRING, allowNull: false },
// 각각 STRING와 INTEGER 데이터 타입으로, unique: 'compositeIndex'로 같은 문자열을 사용해 유일 제약 조건 생성. 이 경우 두 열이 합쳐진 유일한 키를 형성
uniqueOne: { type: DataTypes.STRING, unique: 'compositeIndex' },
uniqueTwo: { type: DataTypes.INTEGER, unique: 'compositeIndex' },
// STRING 데이터 타입으로, unique: true로 유일 제약 조건 생성
someUnique: { type: DataTypes.STRING, unique: true },
// STRING 데이터 타입으로, primaryKey: true로 기본 키로 설정
identifier: { type: DataTypes.STRING, primaryKey: true },
// INTEGER 데이터 타입으로, autoIncrement: true로 자동 증가하는 열로 설정
incrementMe: { type: DataTypes.INTEGER, autoIncrement: true },
// STRING 데이터 타입으로, field: 'field_with_underscores'로 데이터베이스 테이블의 열 이름을 사용자 정의로 설정
fieldWithUnderscores: { type: DataTypes.STRING, field: 'field_with_underscores' },
// foreign keys 를 생성할 수 있다.:
bar_id: {
type: DataTypes.INTEGER,
references: {
// 참조하는 다른 모델
model: Bar,
// 참조된 모델의 칼럼명
key: 'id',
// PostgreSQL 에서 사용할 수 있는 옵션으로 외래키 제약조건을 확인할 수 있다.
deferrable: Deferrable.INITIALLY_IMMEDIATE
// Options:
// - `Deferrable.INITIALLY_IMMEDIATE` - Immediately check the foreign key constraints
// - `Deferrable.INITIALLY_DEFERRED` - Defer all foreign key constraint check to the end of a transaction
// - `Deferrable.NOT` - Don't defer the checks at all (default) - This won't allow you to dynamically change the rule in a transaction
}
},
// Comments can only be added to columns in MySQL, MariaDB, PostgreSQL and MSSQL
commentMe: {
type: DataTypes.INTEGER,
comment: 'This is a column name that has a comment'
}
}, {
sequelize,
modelName: 'foo',
// Using `unique: true` in an attribute above is exactly the same as creating the index in the model's options:
indexes: [{ unique: true, fields: ['someUnique'] }]
});📕 Taking advantage of Models being classes
Sequelize 모델은 ES6 클래스이니 인스턴스나 클래스 레벨의 메서드를 쉽게 추가할 수 있다
class User extends Model {
static classLevelMethod() {
return 'foo';
}
instanceLevelMethod() {
return 'bar';
}
getFullname() {
return [this.firstname, this.lastname].join(' ');
}
}
User.init({
firstname: Sequelize.TEXT,
lastname: Sequelize.TEXT
}, { sequelize });
console.log(User.classLevelMethod()); // 'foo'
const user = User.build({ firstname: 'Jane', lastname: 'Doe' });
console.log(user.instanceLevelMethod()); // 'bar'
console.log(user.getFullname()); // 'Jane Doe'📗 모델 인스턴스
모델은 ES6 클래스이다. 클래스의 인스턴스는 해당 모델의 한 객체를 말한다. 이 경우 모델 인스턴스는 DAO 이다.
DAO : Data Access Object
DB 의 데이터에 접근하기 위한 객체로 실제 DB 에 접근하는 객체를 말한다.
모델 인스턴스는 다음의 환경을 바탕으로 설명이 진행된다.
const { Sequelize, Model, DataTypes } = require("sequelize");
const sequelize = new Sequelize("sqlite::memory:");
const User = sequelize.define("user", {
name: DataTypes.TEXT,
favoriteColor: {
type: DataTypes.TEXT,
defaultValue: 'green'
},
age: DataTypes.INTEGER,
cash: DataTypes.INTEGER
});
(async () => {
await sequelize.sync({ force: true });
// Code here
})();📕 인스턴스 생성
모델은 클래스이나 new 연산자로 바로 생성해서는 안되고 build 메서드를 사용해야 한다.
const jane = User.build({ name: "Jane" });
console.log(jane instanceof User); // true
console.log(jane.name); // "Jane"그러나 위의 경우 실제로 database 와 communicate 하지는 않는데 이는 build 메서드가 오로지 데이터베이스에 맵핑될 수 있는 데이터를 나타내는 객체를 생성만 하기 때문이다. 실제로 저장하기 위해서는 save 메서드를 사용해야 한다.
await jane.save();
console.log('Jane was saved to the database!');대체로 Sequelize 메서드는 비동기식 메서드이나 build 가 매우 적은 예외중 하나이다.
📕 Sequelize CRUD 사례
/** create */
const getSequelizeSignup = (req, res) => {
res.render("signup2"); // signup2.ejs 뷰 렌더링
};
const setSequelizeSignup = async (req, res) => {
const { userid, name, pw } = req.body;
try {
await models.User.create({
userid,
name,
pw,
});
res.render("index"); // index.ejs 뷰 렌더링
} catch (error) {
console.error("회원가입 에러:", error);
res.status(500).json({ success: false });
}
};
/** read */
const getSequelizeUser = async (req, res) => {
const userId = req.params.id;
try {
const user = await models.User.findOne({
where: { id: userId },
});
res.render("user_info", { user }); // user_info.ejs 뷰 렌더링
} catch (error) {
console.error("사용자 조회 에러:", error);
res.status(500).json({ success: false });
}
};
/** update */
const editSequelizeUser = async (req, res) => {
const userId = req.params.id;
const { newName } = req.body;
try {
await models.User.update(
{ name: newName },
{
where: { id: userId },
}
);
res.redirect(`/sequelize/user/${userId}`); // 사용자 정보 조회 페이지로 리디렉션
} catch (error) {
console.error("사용자 정보 수정 에러:", error);
res.status(500).json({ success: false });
}
};
/** delete */
const deleteSequelizeUser = async (req, res) => {
const userId = req.params.id;
try {
await models.User.destroy({
where: { id: userId },
});
res.redirect("/sequelize/signup"); // 메인 페이지로 리다이렉트
} catch (error) {
console.error("사용자 정보 삭제 에러:", error);
res.status(500).json({ success: false });
}
};📕 매우 유용한 단축 메서드: create 메서드
수업중엔 create 메서드를 사용했었는데 이는 build 과 save 메서드를 합친 단축 메서드이다.
const jane = await User.create({ name: "Jane" });
// Jane exists in the database now!
console.log(jane instanceof User); // true
console.log(jane.name); // "Jane"📕 인스턴스 로깅 팁
Sequelize 인스턴스가 매우 많은 것을 포함하고 있기 때문에 로깅을 할때 다음과 같이 .toJSON 혹은 stringify 를 사용하는 것을 권장한다.
const jane = await User.create({ name: "Jane" });
// console.log(jane); // Don't do this
console.log(jane.toJSON()); // This is good!
console.log(JSON.stringify(jane, null, 4)); // This is also good!📕 Updating an instance
save 메서드로 하나의 필드를 변경하거나 set 메서드로 여러 필드를 한번에 바꿀 수 있다.
const jane = await User.create({ name: "Jane" });
console.log(jane.name); // "Jane"
jane.name = "Ada";
// the name is still "Jane" in the database
await jane.save();
// Now the name was updated to "Ada" in the database!
const jane = await User.create({ name: "Jane" });
jane.set({
name: "Ada",
favoriteColor: "blue"
});
// As above, the database still has "Jane" and "green"
await jane.save();
// The database now has "Ada" and "blue" for name and favorite colorsave 메서드는 이전의 set 을 통한 변경뿐 아니라 다른 변경점들을 지속해서 갖고 바꾼다. 만약 특정 필드들의 집합을 바꾸고 싶다면 update 를 사용한다.
save 는 다른 변경점들도 갖고있다가 한번에 수정한다면 update 는 명시한 변경점만 데이터베이스에 반영한다.
const jane = await User.create({ name: "Jane" });
jane.favoriteColor = "blue"
await jane.update({ name: "Ada" })
// The database now has "Ada" for name, but still has the default "green" for favorite color
await jane.save()
// Now the database has "Ada" for name and "blue" for favorite color위의 예시에서 jane.favoriteColor = "blue" 와 await jane.update({ name: "Ada" }) 전자는 JavaScript 에서 jane 이라는 객체의 프로퍼티의 값을 바꾼 것이고 후자는 database 상에 name 에 변경점을 반영했다는 점에서 차이가 있다.
📕 Deleting an instance
인스턴스는 destroy 로 삭제할 수 있다.
const jane = await User.create({ name: "Jane" });
console.log(jane.name); // "Jane"
await jane.destroy();
// Now this entry was removed from the database📕 Reloading an instance
데이터베이스에서 reload 를 통해 인스턴스를 다시 로드할 수 있다.
const jane = await User.create({ name: "Jane" });
console.log(jane.name); // "Jane"
jane.name = "Ada";
// the name is still "Jane" in the database
await jane.reload();
console.log(jane.name); // "Jane"📕 몇가지 필드만 저장하기
save 메서드는 실행하기까지 발생한 모든 변경점을 데이터베이스에 반영했는데 fields 에 column 이름의 배열을 전달하여 특정 필드만 저장할 수 있다.
const jane = await User.create({ name: "Jane" });
console.log(jane.name); // "Jane"
console.log(jane.favoriteColor); // "green"
jane.name = "Jane II";
jane.favoriteColor = "blue";
await jane.save({ fields: ['name'] });
console.log(jane.name); // "Jane II"
console.log(jane.favoriteColor); // "blue"
// The above printed blue because the local object has it set to blue, but
// in the database it is still "green":
await jane.reload();
console.log(jane.name); // "Jane II"
console.log(jane.favoriteColor); // "green"📗 Model Query 기본
Sequelize - Model Querying - Basics 참고
📕 SELECT 쿼리
전체 필드 검색
// Find all users
const users = await User.findAll();
console.log(users.every(user => user instanceof User)); // true
console.log("All users:", JSON.stringify(users, null, 2));SELECT * FROM ...특정 필드 검색
Model.findAll({
attributes: ['foo', 'bar']
});SELECT foo, bar FROM ...중첩 배열로 이름을 따로 명시
Model.findAll({
attributes: ['foo', ['bar', 'baz'], 'qux']
});SELECT foo, bar AS baz, qux FROM ...sequelize.fn 으로 집계연산
Model.findAll({
attributes: [
'foo',
[sequelize.fn('COUNT', sequelize.col('hats')), 'n_hats'],
'bar'
]
});SELECT foo, COUNT(hats) AS n_hats, bar FROM ...📕 WHERE 쿼리
Op 라는 심벌을 사용한다.
Post.findAll({
where: {
authorId: 2
}
});
// SELECT * FROM post WHERE authorId = 2;혹은 Op 연산자를 사용할 수 있다.
const { Op } = require("sequelize");
Post.findAll({
where: {
authorId: {
[Op.eq]: 2
}
}
});
// SELECT * FROM post WHERE authorId = 2;연산자
const { Op } = require("sequelize");
Post.findAll({
where: {
[Op.and]: [{ a: 5 }, { b: 6 }], // (a = 5) AND (b = 6)
[Op.or]: [{ a: 5 }, { b: 6 }], // (a = 5) OR (b = 6)
someAttribute: {
// Basics
[Op.eq]: 3, // = 3
[Op.ne]: 20, // != 20
[Op.is]: null, // IS NULL
[Op.not]: true, // IS NOT TRUE
[Op.or]: [5, 6], // (someAttribute = 5) OR (someAttribute = 6)
// Using dialect specific column identifiers (PG in the following example):
[Op.col]: 'user.organization_id', // = "user"."organization_id"
// Number comparisons
[Op.gt]: 6, // > 6
[Op.gte]: 6, // >= 6
[Op.lt]: 10, // < 10
[Op.lte]: 10, // <= 10
[Op.between]: [6, 10], // BETWEEN 6 AND 10
[Op.notBetween]: [11, 15], // NOT BETWEEN 11 AND 15
// Other operators
[Op.all]: sequelize.literal('SELECT 1'), // > ALL (SELECT 1)
[Op.in]: [1, 2], // IN [1, 2]
[Op.notIn]: [1, 2], // NOT IN [1, 2]
[Op.like]: '%hat', // LIKE '%hat'
[Op.notLike]: '%hat', // NOT LIKE '%hat'
[Op.startsWith]: 'hat', // LIKE 'hat%'
[Op.endsWith]: 'hat', // LIKE '%hat'
[Op.substring]: 'hat', // LIKE '%hat%'
[Op.iLike]: '%hat', // ILIKE '%hat' (case insensitive) (PG only)
[Op.notILike]: '%hat', // NOT ILIKE '%hat' (PG only)
[Op.regexp]: '^[h|a|t]', // REGEXP/~ '^[h|a|t]' (MySQL/PG only)
[Op.notRegexp]: '^[h|a|t]', // NOT REGEXP/!~ '^[h|a|t]' (MySQL/PG only)
[Op.iRegexp]: '^[h|a|t]', // ~* '^[h|a|t]' (PG only)
[Op.notIRegexp]: '^[h|a|t]', // !~* '^[h|a|t]' (PG only)
[Op.any]: [2, 3], // ANY (ARRAY[2, 3]::INTEGER[]) (PG only)
[Op.match]: Sequelize.fn('to_tsquery', 'fat & rat') // match text search for strings 'fat' and 'rat' (PG only)
// In Postgres, Op.like/Op.iLike/Op.notLike can be combined to Op.any:
[Op.like]: { [Op.any]: ['cat', 'hat'] } // LIKE ANY (ARRAY['cat', 'hat'])
// There are more postgres-only range operators, see below
}
}
});Op.not 사용예시
Project.findAll({
where: {
name: 'Some Project',
[Op.not]: [
{ id: [1,2,3] },
{
description: {
[Op.like]: 'Hello%'
}
}
]
}
});SELECT *
FROM `Projects`
WHERE (
`Projects`.`name` = 'Some Project'
AND NOT (
`Projects`.`id` IN (1,2,3)
AND
`Projects`.`description` LIKE 'Hello%'
)
)📕 UPDATE 쿼리
// Change everyone without a last name to "Doe"
await User.update({ lastName: "Doe" }, {
where: {
lastName: null
}
});📕 DELETE 쿼리
// Delete everyone named "Jane"
await User.destroy({
where: {
firstName: "Jane"
}
});📕 정렬
Subtask.findAll({
order: [
// Will escape title and validate DESC against a list of valid direction parameters
['title', 'DESC'],
// Will order by max(age)
sequelize.fn('max', sequelize.col('age')),
// Will order by max(age) DESC
[sequelize.fn('max', sequelize.col('age')), 'DESC'],
// Will order by otherfunction(`col1`, 12, 'lalala') DESC
[sequelize.fn('otherfunction', sequelize.col('col1'), 12, 'lalala'), 'DESC'],
// Will order an associated model's createdAt using the model name as the association's name.
[Task, 'createdAt', 'DESC'],
// Will order through an associated model's createdAt using the model names as the associations' names.
[Task, Project, 'createdAt', 'DESC'],
// Will order by an associated model's createdAt using the name of the association.
['Task', 'createdAt', 'DESC'],
// Will order by a nested associated model's createdAt using the names of the associations.
['Task', 'Project', 'createdAt', 'DESC'],
// Will order by an associated model's createdAt using an association object. (preferred method)
[Subtask.associations.Task, 'createdAt', 'DESC'],
// Will order by a nested associated model's createdAt using association objects. (preferred method)
[Subtask.associations.Task, Task.associations.Project, 'createdAt', 'DESC'],
// Will order by an associated model's createdAt using a simple association object.
[{model: Task, as: 'Task'}, 'createdAt', 'DESC'],
// Will order by a nested associated model's createdAt simple association objects.
[{model: Task, as: 'Task'}, {model: Project, as: 'Project'}, 'createdAt', 'DESC']
],
// Will order by max age descending
order: sequelize.literal('max(age) DESC'),
// Will order by max age ascending assuming ascending is the default order when direction is omitted
order: sequelize.fn('max', sequelize.col('age')),
// Will order by age ascending assuming ascending is the default order when direction is omitted
order: sequelize.col('age'),
// Will order randomly based on the dialect (instead of fn('RAND') or fn('RANDOM'))
order: sequelize.random()
});
Foo.findOne({
order: [
// will return `name`
['name'],
// will return `username` DESC
['username', 'DESC'],
// will return max(`age`)
sequelize.fn('max', sequelize.col('age')),
// will return max(`age`) DESC
[sequelize.fn('max', sequelize.col('age')), 'DESC'],
// will return otherfunction(`col1`, 12, 'lalala') DESC
[sequelize.fn('otherfunction', sequelize.col('col1'), 12, 'lalala'), 'DESC'],
// will return otherfunction(awesomefunction(`col`)) DESC, This nesting is potentially infinite!
[sequelize.fn('otherfunction', sequelize.fn('awesomefunction', sequelize.col('col'))), 'DESC']
]
});📕 Grouping
Project.findAll({ group: 'name' });
// yields 'GROUP BY name'📕 Limit, Pagination
// Fetch 10 instances/rows
Project.findAll({ limit: 10 });
// Skip 8 instances/rows
Project.findAll({ offset: 8 });
// Skip 5 instances and fetch the 5 after that
Project.findAll({ offset: 5, limit: 5 });📗 Model Query 탐색
findAll
테이블에서 모든 엔트리를 가져오는 SELECT 쿼리
findByPk
primary key 를 이용해 탐색
findOne
결과에 해당하는 첫 번째 엔트리를 탐색
findOrCreate
쿼리 옵션을 만족하는 항목을 찾을 수 없다면 엔트리를 생성한다. 또한 두 경우 모두 인스턴스를 반환하고 이와 함께 생성된 것인지 이미 존재했던 것인지에 대한 불린값을 반환한다.
const [user, created] = await User.findOrCreate({
where: { username: 'sdepold' },
defaults: {
job: 'Technical Lead JavaScript'
}
});
console.log(user.username); // 'sdepold'
console.log(user.job); // This may or may not be 'Technical Lead JavaScript'
console.log(created); // The boolean indicating whether this instance was just created
if (created) {
console.log(user.job); // This will certainly be 'Technical Lead JavaScript'
}findAndCountAll
findAll 과 count 를 합친 매우 편리한 메서드이다. 페이지네이션에서 데이터를 limit, offset 으로 얻을 뿐 아니라 몇개의 데이터가 있는지를 구할때 유용하다.
- group 으로 묶여있을 경우
findAndCountAll메서드는 2개의 프로퍼티를 갖는 객체를 반환한다.
count: integer, 쿼리에 해당하는 총 레코드 수rows: 객체들의 배열, 획득한 레코드들
- group 이 제공되지 않을 경우
findAndCountAll메서드는 2개의 프로퍼티를 갖는 객체를 반환한다.
count: 객체들의 배열, 투영된 특성 포함하여 각 그룹의 카운트rows: 객체들의 배열, 획득한 레코드들
const { count, rows } = await Project.findAndCountAll({
where: {
title: {
[Op.like]: 'foo%'
}
},
offset: 10,
limit: 2
});
console.log(count);
console.log(rows);📗 Associations
마지막으로 관계에 대해 정리해보자
Sequelize 는 One-To-One, One-To-Many, Many-To-Many 관계를 지원한다.
- HasOne
- BelongsTo
- HasMany
- BelongsToMany
const A = sequelize.define('A', /* ... */);
const B = sequelize.define('B', /* ... */);
A.hasOne(B); // A HasOne B
A.belongsTo(B); // A BelongsTo B
A.hasMany(B); // A HasMany B
A.belongsToMany(B, { through: 'C' }); // A BelongsToMany B through the junction table CbelongsToMany 를 제외하곤 2번째 파라미터는 옵션이다. through 는 연결테이블을 명시한다.
A.hasOne(B, { /* options */ });
A.belongsTo(B, { /* options */ });
A.hasMany(B, { /* options */ });
A.belongsToMany(B, { through: 'C', /* options */ });위의 사례에서 A 는 source model 이고 B 는 target model 이다.
A.hasOne(B) : A, B 사이의 관계가 One-To-One 이고 foreign key 가 target model 인 B 에 정의된다.
A.belongsTo(B) : A, B 사이의 관계가 One-To-One 이고 foreign key 가 source model 인 A 에 정의된다.
A.hasMany(B) : A, B 사이의 관계가 One-To-Many 이고 foreign key 가 target model 인 B 에 정의된다.
보통 외래키가 붙은 테이블이 belongsTo 가 된다.
A.belongsToMany(B, { through: 'C' }) : A, B 사이의 관계가 Many-To-Many 이고 foreign key 로 aId, bId 를 갖는 연결테이블 C 를 갖는다. 만약 C 가 없다면 자동으로 이 모델을 생성하고 적합한 외래키를 정의한다.
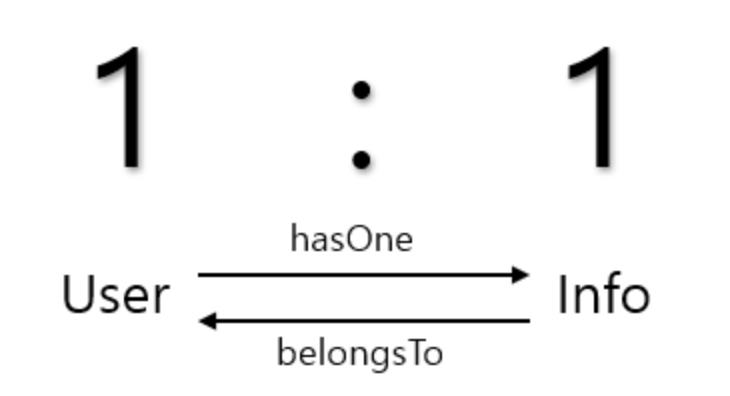
One-To-One
- hasOne, belongsTo

One-To-Many
- hasMany, belongsTo
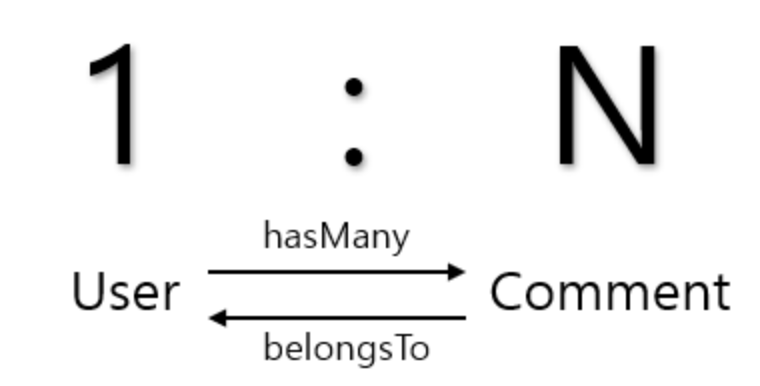

Many-To-Many
- belongsToMany
n:m 관계는 보통 중간 연결테이블을 생성하여 1:n n:1 관계로 바꿔서 사용하는데 sequelize 는 연결테이블을 생성해준다.
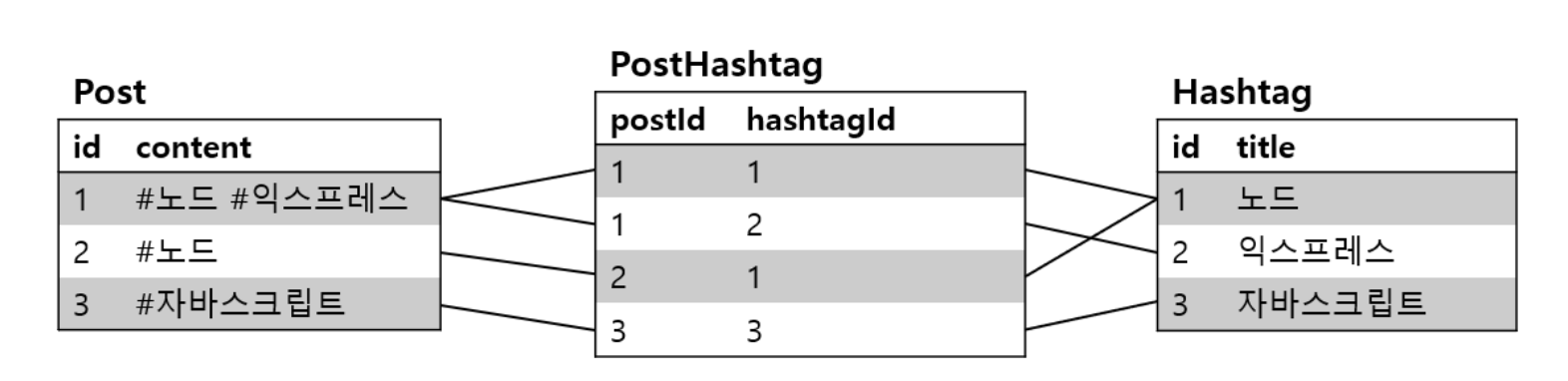

N:M 을 잘 사용하지 않고 1:N 으로 바꾸는 이유
- 위의 경우 학생과 선생이 N:M 관계라면 그 중간테이블에 속한 테이블이 동아리라고 해보자. 어떤 학생의 동아리 이름을 확인하기 위해서 학생 테이블을 봐야할까 아니면 동아리 테이블을 확인해야 할까?
- 데이터 중복
- 어떤 학생의 정보가 하나라도 바뀐다면?
- 데이터의 갱신 이상이 발생한다.
- 자동으로 생성되는 중간 연결 테이블이니 두 테이블의 PK 를 FK 로 갖는 두 필드만 갖게 되어 개발 도중에 발생하는 상황들에 대해 유연하게 대처하기 어려워 매핑 테이블을 하나의 모델로 승격시키는 편이 좋다. (하나의 N:M 관계를 2개의 1:N 관계로 쪼개는 것이다.)
- 다른 Column 들을 추가로 정의하고 싶으나 연결 관계만 묘사 가능하다
- 다른 Column 들을 기준으로 한 추가 로직이 개발되어야 할 때 (연관된 날짜 기준 정렬 등) 연결 테이블과 연관된 두 참조 테이블이 연결 테이블에 대한 cascade 설정이 필요하다.
- 이러한 이유들로 실무에선 다대다 관계를 사용하지 말것을 권장한다.
- 참고
📕 옵션들
onDelete, onUpdate
Foo.hasOne(Bar, {
onDelete: 'RESTRICT',
onUpdate: 'RESTRICT'
});
Bar.belongsTo(Foo);onDelete, onUpdate 에 대한 값으로 RESTRICT, CASCADE, NO ACTION, SET DEFAULT, SET NULL 이 올 수 있다.
RESTRICT : 외래 키 제약조건 설정, 부모 테이블의 레코드가 삭제되거나 변경시 자식 테이블에 해당 레코드를 참조하는 행이 존재시 RESTRICT 옵션을 사용하면 부모 레코드의 삭제나 변경을 막아 해당 작업을 제한한다.
CASCADE : 부모 테이블의 레코드가 삭제되거나 변경시 이에 연관된 자식 테이블의 레코드도 함께 삭제되거나 변경되도록 한다. 예를 들어 한 유저가 여러 포스트를 생성했는데 이 유저가 탈퇴하여 계정을 삭제했다면 이 유저가 생성했던 모든 포스트를 삭제해줄때 CASCADE 옵션이 사용된다.
NO ACTION : RESTRICT 옵션과 비슷하게 동작하나 부모 테이블의 레코드가 삭제되거나 변경될 때 자식 테이블에 해당 레코드를 참조하는 행이 존재할 경우 작업을 지연시키지 않고 바로 실패시킨다.
SET DEFAULT : 외래 키가 참조하는 값이 삭제되거나 변경될 때 해당 열에 기본값을 설정한다. 즉 부모 레코드가 삭제 혹은 변경시 자식 레코드에 대한 값이 기본값으로 설정된다.
SET NULL : 외래 키가 참조하는 값이 삭제되거나 변경될 때 자식 레코드의 외래 키 열을 NULL 로 설정한다.
One-To-One 관계에서 onDelete 의 기본값은 SET NULL 이고 onUpdate 의 기본값은 CASCADE 이다.
One-To-Many 관계에서 onDelete 의 기본값은 SET NULL 이고 onUpdate 의 기본값은 CASCADE 이다.
Many-To-Many 관계에서 onDelete, onUpdate 의 기본값은 CASCADE 이다.
구체적인 내용은 공식 문서 를 참고하자.
📗 raw query
SQL 쿼리문을 sequelize 를 이용해서 직접 실행하고 싶다면 raw query 를 이용한다.
const [results, metadata] = await sequelize.query("UPDATE users SET y = 42 WHERE x = 12");
// Results will be an empty array and metadata will contain the number of affected rows.results 는 결과이고 metadata 는 영향받은 rows 들의 양 등을 의미한다.
metadata 를 원하지 않는다면 sequelize 에게 결과를 어떻게 format 할 것인지 알려줘야 한다.
const { QueryTypes } = require('sequelize');
const users = await sequelize.query("SELECT * FROM `users`", { type: QueryTypes.SELECT });
// We didn't need to destructure the result here - the results were returned directly참고로 위에서 정리한 Sequelize 의 특징들은 Golang 의 ORM 인 GORM, TypeScript 의 ORM 인 TypeORM 을 사용할때도 마찬가지 개념들이 있었으니 ORM 에 대부분 비슷한 기능들이 있는 것 같다.
📗 join
수업시간때 join의 개념을 살짝 들었지만 sql 에서의 join 이었고 sequelize 에서는 어떻게 해야 join 을 할 수 있을지 생각해봤다. 무작정 떠오른 것은 raw query 만 가능하지 않는지 생각이 들었는데 실제로 raw query 뿐 아니라 include 를 사용하여 join 을 할 수 있다고 한다. 이와 관련된 eager loading 이라는 것에 대해 추가로 조사해볼 예정이다.
eager loading 즉시로딩
- 한 번에 여러 모델의 데이터를 쿼리하는 방법이다. SQL 수준에서 이것은 하나 이상의 조인이 포함된 쿼리이다. 이 작업이 완료되면 관계 모델이 Sequelize 에 의해 적절한 이름으로 추가될 것이다.
- Sequelize 에선 eager loading 은 finder query (findeOne, findAll ... ) 의 옵션중 include 를 사용하여 처리된다.
예시)
User.findAll({
include: {
model: Task,
required: true
}
});include 를 사용한 join
const { Sequelize, DataTypes } = require('sequelize');
const sequelize = new Sequelize('database', 'username', 'password', {
host: 'localhost',
dialect: 'mysql'
});
const Author = sequelize.define('Author', {
name: DataTypes.STRING
});
const Book = sequelize.define('Book', {
title: DataTypes.STRING
});
// 1:N 관계 설정
Author.hasMany(Book);
Book.belongsTo(Author);
(async () => {
await sequelize.sync({ force: true });
const author = await Author.create({ name: '작가 이름' });
await Book.create({ title: '책 제목', AuthorId: author.id });
const booksWithAuthor = await Book.findAll({
include: Author // include 옵션을 사용하여 JOIN 수행
});
console.log(booksWithAuthor);
})();
raw query 를 사용한 join
const { Sequelize, DataTypes } = require('sequelize');
const sequelize = new Sequelize('database', 'username', 'password', {
host: 'localhost',
dialect: 'mysql'
});
const Author = sequelize.define('Author', {
name: DataTypes.STRING
});
const Book = sequelize.define('Book', {
title: DataTypes.STRING
});
(async () => {
await sequelize.sync({ force: true });
const author = await Author.create({ name: '작가 이름' });
await Book.create({ title: '책 제목', AuthorId: author.id });
// raw 쿼리를 사용하여 JOIN 수행
const booksWithAuthor = await sequelize.query(`
SELECT Books.*, Authors.name AS authorName
FROM Books
INNER JOIN Authors ON Books.AuthorId = Authors.id
`, {
type: Sequelize.QueryTypes.SELECT
});
console.log(booksWithAuthor);
})();
📔 레퍼런스
course
Udemy - NodeJS 및 Deno.js 완성, Node.js를 이용한 REST API와 GraphQL 구축, 인증 추가하기, MongoDB, SQL 등 활용법! Node.js의 실전 적용과 이론을 가장 종합적으로 다루는 강의
강사 - Maximilian Schwarzmüller
docs
sequelize
sequelize guide
blog
uuid vs ulid
incodom - ORM
hanamon - ORM
koh1018 - DAO, DTO, VO 의 개념과 차이점
DevInvestor - ORM 을 프로젝트에 도입시 주의할 점
inpa dev - sequelize
kon6443 - ERD 관계 1:1 & 1:N & N:M
📒 TODO
- Sequelize 의 Eager Loading 에 대해서만 하나의 포스트에 정리
- 기왕이면 eager loading, lazy loading 을 비교 분석하여 정리
- 추가로 관련있는 N+1 Problem 에 대해서도 조사 필요
📓 결론
- 모델과 모델 인스턴스, sequelize 의 기본 개념, finder 쿼리, raw Query 와 관계에 대해 정리해봤다. 개인적으로 매우 유익한 시간이었다.
자주 사용될 것 같은 것들만 정리해봤는데도 언제나처럼 양이 엄청 많았다. 그래도 그저 CRUD 에 대해 node.js MVC pattern & MySQL 코드를 sequelize 를 이용한 코드로 전환해보는데에 그치는 것이 아니라 각 코드들이 어떻게 동작하고 어떤 옵션들이 있는지 자세히 알아 볼 수 있었다. 즉, 왜 이렇게 동작하고 어떻게 해야 이렇게 동작하는지에 대해 자세히 알아 본 것이다.
많은 부분이 그저 공식 문서의 내용을 번역한 것과 같지만 포스트 작성전 create, update, findAll, destroy 만 알고 model 이 뭔지도 몰랐던 상태와 같다고 볼 수 있을까? 적어도 sequelize 라는 ORM 을 어떻게 쓸 수 있는지에 대한 기본기가 생겼다고 생각한다.
누가 물어볼때 이 포스트에 담긴 내용만큼은 당당히 대답할 수 있도록 노력해보자.

잘 읽었습니다. 좋은 정보 감사드립니다.