
서론
8/31 일에 시작한 팀프로젝트가 오늘 9/14에 모든 작업이 끝났다.
다시 처음으로 돌아가서 2주간 진행한 이번 팀프로젝트 (4인)가 어떻게 준비하고 어떤 결과물을 만들었는지 정리해보고자 한다.
첫 회의
처음에 팀원들과 회의시, 가장 먼저 무엇을 해보고 싶은지에 대해 이야기를 해봤다. 먼저 버스 탑승객의 탑승 정류장과 하차 정류장에 대한 정보를 취합하여 어떤 승객이 언제 내릴지 공유하는 플랫폼을 생각해봤다. 이때 서울시에서 버스에 관한 API 를 제공하는 부분도 있었고 재미있는 아이디어라 생각했지만 구조가 단순할 수 있다는 피드백을 받고 다음 아이디어에 대해 논의를 했다.
최근 한달간 리액트에 관한 스터디를 진행했었는데 코딩온에서의 주 2회 블로깅과 더불어 주 2회 리액트 블로깅을 하는 것이 다소 빡빡한 계획이었던 것 같다. 그래서 추가로 북스터디도 하고 싶고 팀플도 해보고 싶은데 더 적극적으로 의견을 내기 어려운 상황에 이번 프로젝트 주제로 스터디 모집 플랫폼에 대해 만들어보자는 의견을 냈다.
요구사항 명세서
개발은 기획 - 디자인 - 백 / 프론트 개발 - 배포의 순서로 볼 수 있는데 Do IT 팀에선 에자일 방법론중 스크럼과 스프린트 회고의 프로젝트 진행방식을 채택했다. 주제가 정해졌으니 가장 먼저 했던 일은 요구사항에 대한 분석을 하는 것이었다.
처음엔 아래와 같이 어떤 기능에 어떤 부분들이 필요한지를 먼저 정리했다.
회원가입
아이디, 비번, 닉네임이 필요하다.
로그인
아이디, 비번이 필요하다. 단, 소셜 로그인은 제외했다.
마이페이지
닉네임, 포인트 조회, 내가 개설한 스터디 리스트와 내가 참여중인 스터디 리스트 조회
면접 질문
CS 주제로 데이터베이스, 네트워크, 알고리즘, 자료구조, 운영체제 이렇게 5가지를 잡고 선택한 주제에 대해 OpenAI 의 API 를 활용하여 ChatGPT 를 면접관의 역할로 잡고 CS 면접을 연습할 수 있는 기능을 제공하자.
스터디 지원
지원에 제동을 걸기 위해 매 스터디에 지원할 때마다 포인트를 소모
포인트 체계
면접 질문에 따라 포인트를 습득할 수 있다.
스터디 지원 및 개설에 포인트를 소모한다.
면접 연습을 통해 포인트를 획득할 수 있다. 총 3회의 면접 질문을 받아 대답을 해야 하며 면접 연습에 참여하여 한번에 총 30점의 포인트를 습득할 수 있다.
스터디 개설엔 100 포인트를 소모하며 스터디 참여엔 30 포인트를 소모한다.
슬랙봇
Socket 과 Webhook 기능을 활용하여 스터디 모임 개설 신청시 스터디의 개설에 대한 승낙 여부를 운영진 측에서 직접 슬랙을 통해 처리할 수 있다.
이때 신청한 스터디의 계획, 정보, 개설 신청자의 깃허브 혹은 기술블로그 링크를 참고하여 승낙 여부를 결정한다.
스터디
스터디 개설여부는 운영진이 결정하고 스터디 지원자의 참여 여부는 스터디 개설자가 결정한다.
스터디 개설
스터디 개설시 포인트가 소모된다. (100)
개설될 세부사항에 개설자에 대한 정보가 필요하다. 여기엔 증빙할만한 깃허브 혹은 기술블로그 링크를 첨부해야 한다.
개설 요청시 스터디 진행상황을 조회할 수 있어야 한다.
스터디 개설 신청시 슬랙봇을 통해 운영진 측으로 알림을 가게 한다.
개설이 승낙되면 스터디가 대기 상태에서 승낙 상태로 전환된다.
스터디 참여
스터디 참여시 포인트가 소모된다. (30)
스터디 개설자가 스터디 지원자들의 참여 여부를 결정할 수 있다. 스터디 개설자는 스터디 지원자의 깃허브 혹은 기술블로그 링크를 확인할 수 있다.
스터디 리스트 조회
스터디 조회 페이지에서 공개 상태로 개설된 스터디 목록을 확인할 수 있다.
모집중인 리스트에서 스터디에 지원할 수 있고 모집이 완료된 리스트는 조회만 가능하다.
스터디 세부사항
스터디 개설자의 깃허브 혹은 기술블로그 링크를 확인할 수 있다.
스터디 진행 계획을 포함한 세부사항에 대해 확인할 수 있다.
구조 설계 논의
| 구조 | 구조 |
|---|---|
 |  |
 |  |
 |  |
 |  |
 |  |
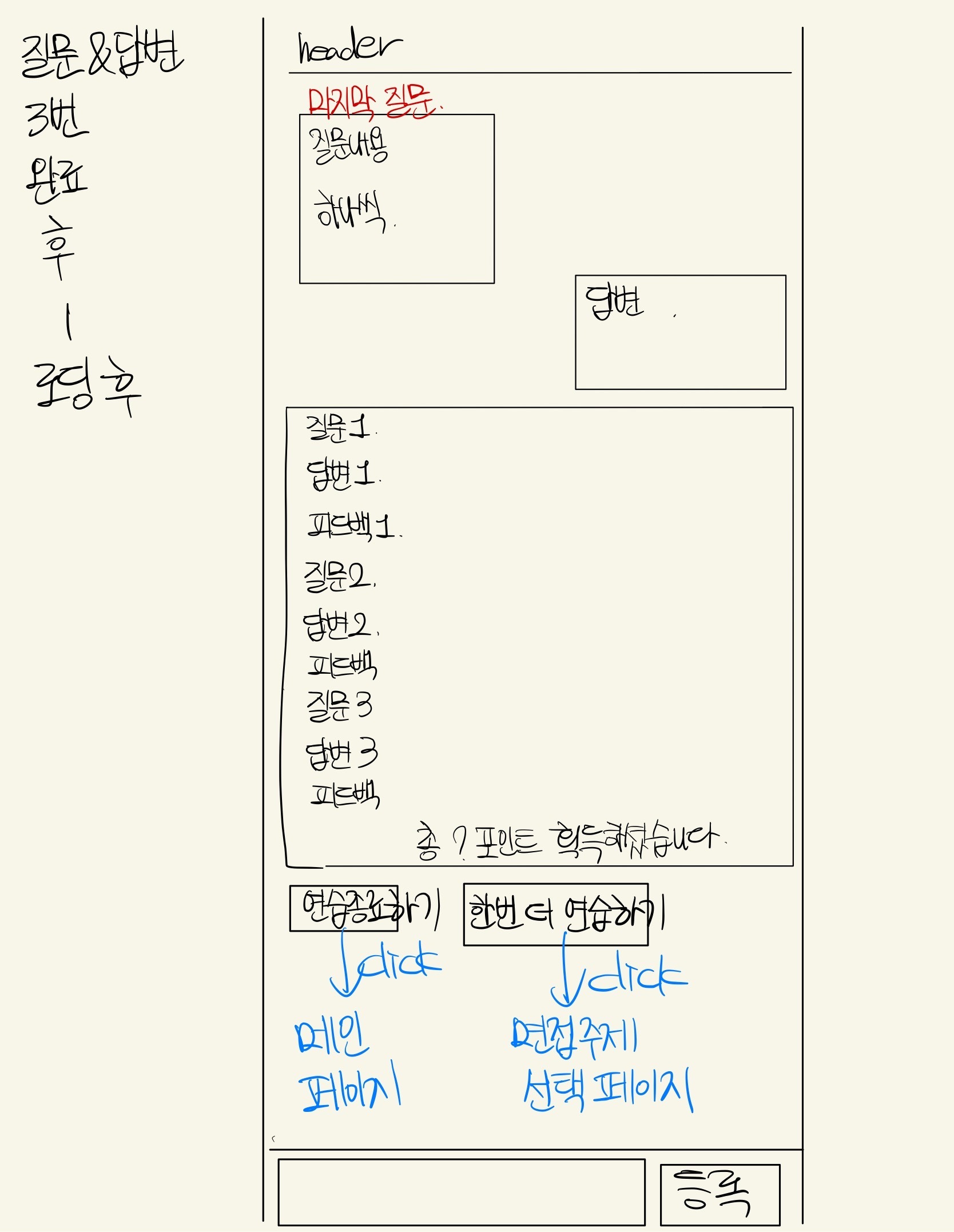 |
GROUND_RULE
요구사항 명세서와 구조를 설계한 이후 GROUND_RULE 에 대해 논의했다.
조 이름은 Do IT 으로 제안했는데 Just Do It 을 생각하다가 너무 길어서 Do It 에 개발자를 위한 스터디 모집 플랫폼이니 IT 를 강조해서 Do IT 으로 정해졌다.
이번 프로젝트에서 해보고 싶었던게 협업다운 협업이라는 것을 더 확실히 해보고 싶었다. 지난 프로젝트때 각자 브랜치를 관리하여 작업을 진행하는 것은 좋았으나 페이지 단위로 쪼개서 각자 작업한 이후 결과물을 합치는 방식이어서 협업같은 느낌이 들지 않았다.
지난 프로젝트때 모두 프론트만 했으니 이번엔 모든 멤버가 백엔드 작업을 원했다. 그래서 우선 페이지 단위가 아닌 기능별 맡아보고 싶은 기능들을 분배한 뒤, node.js, express, sequelize 를 활용하여 백엔드 작업을 먼저 하면서 필요한 페이지는 ejs 로 최소한의 필요한 태그만 붙여서 작업을 하는 것으로 논의했다.
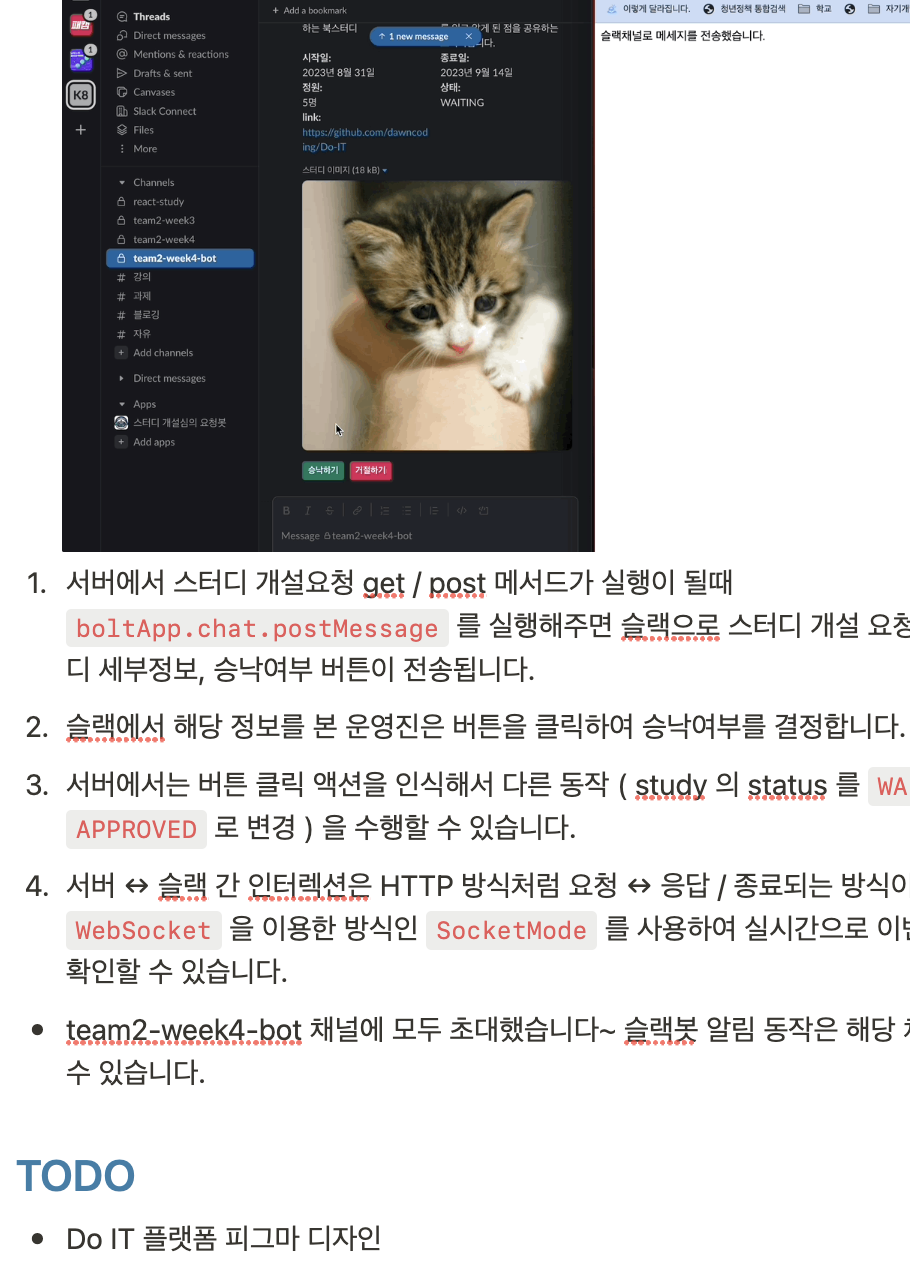
프론트 작업에 앞서 디자인 작업이 반드시 먼저 끝나야 한다. 그래서 슬랙봇을 통한 심사는 스터디 개설 요청 기능이 생성되면 그때 만들어진 슬랙봇 로직을 붙이기만 하면 되니 이전에 슬랙봇 관련 작업을 한 적이 있어서 빠르게 슬랙봇 작업을 맡아서 하고 이후에 디자인 작업을 하기로 했다.
논의중 MVP(Minimum Viable Product) 의 중요성에 대해 이야기했다.
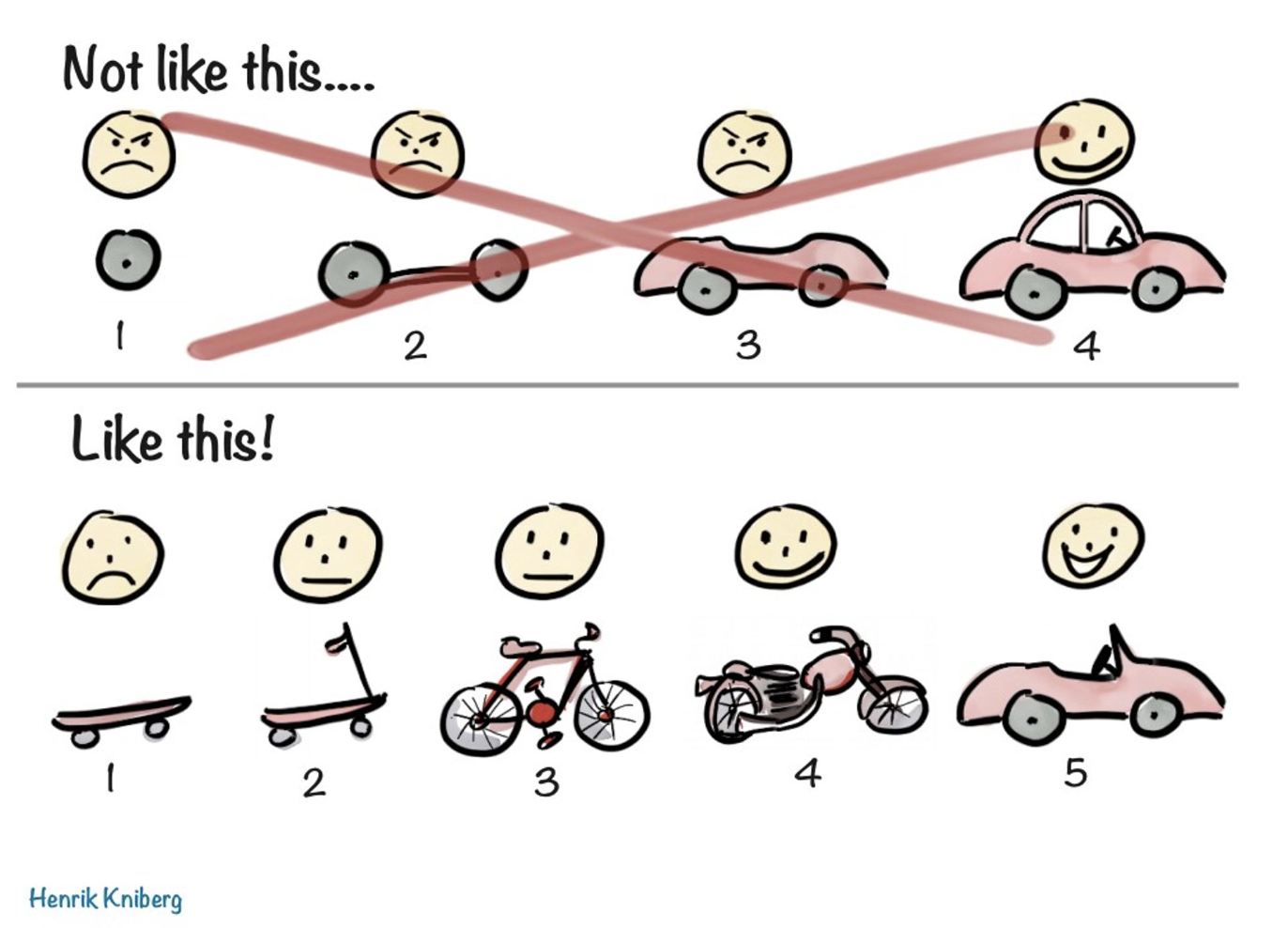
구성 요소별로 만든후 최종적인 단계에서 합치지 말고 일단 굴러가는 최소한의 기능을 만들어 이런 최소 기능 제품 단위로 작업을 하자는 것이었다.
그래야 작업 - 배포의 사이클을 줄여 최소한의 기능 단위로 쪼개 작업을 진행할 수 있고 코드 리뷰도 수월하며 다른 팀원이 이번 이슈동안 어떤 작업을 했는지 확인하기도 수월하다.
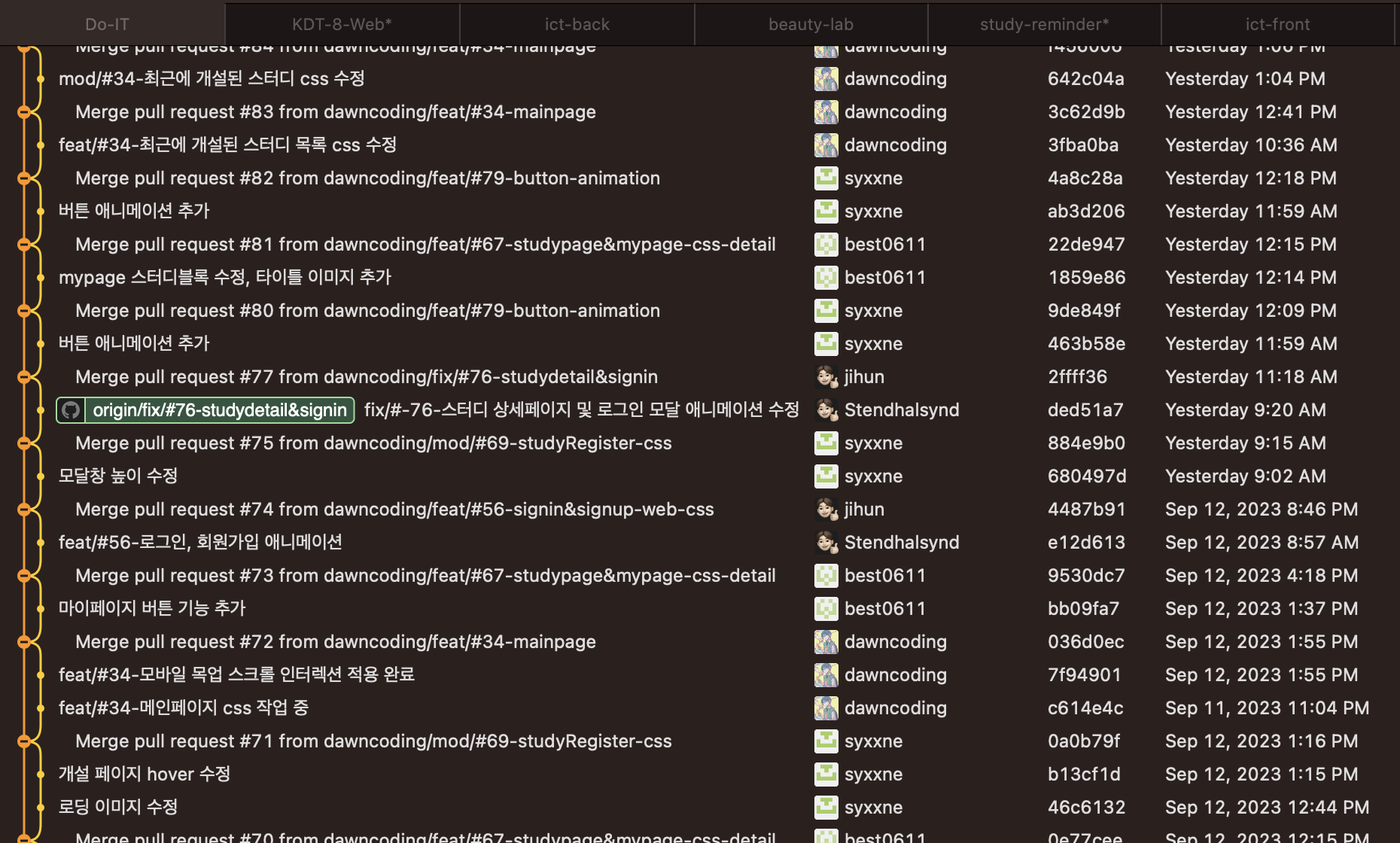
그래서 우리 조는 MVP 를 위한 이슈를 생성 -> 이슈 생성시 부여되는 넘버를 기반으로 브랜치 생성 ( 종류는 feat / mod / refactoring / 추후 bug 도 사용 ) -> 각각 해당 브랜치에서 작업후 누군가 작업이 완료되어 Pull Request 하면 시간이 여유로운 상황일때 팀원들의 PR 에 대해 코드리뷰 진행 / 바쁜 상황이라면 바로 merge 후 다른 팀원들은 새로 바뀐 base 로 rebase 하여 작업을 진행 하는 순서로 git 브랜치를 관리했다.
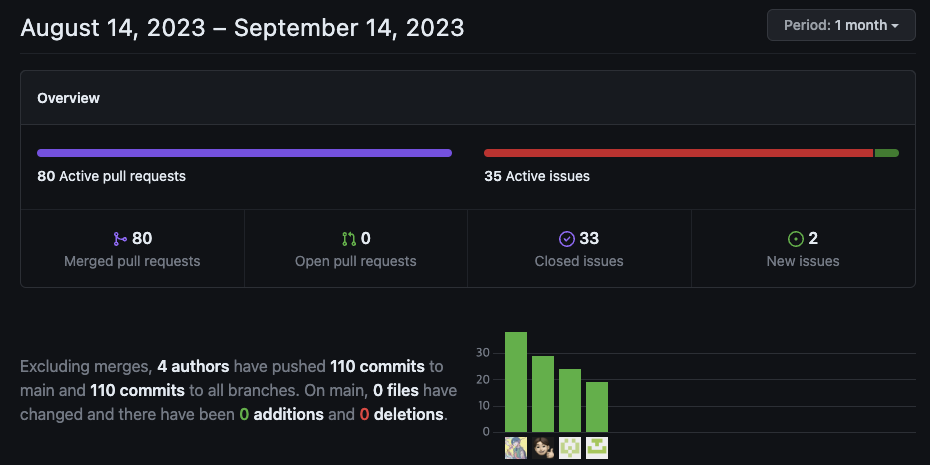
2주 동안 80번의 merge 를 했고 35 개의 issue 를 생성했다.
깔끔한 깃 관리 흔적
스크럼
앞에서 애자일의 스크럼과 스프린트 회고를 활용하고자 논의했다고 말했다.
매일 아침 각 멤버는 해당 날짜의 스크럼 회의록 페이지에 전날 한일, 오늘 해야 할일을 미리 정리해둔다. 그러면 스크럼 회의 전에 팀원들은 회의 전에 각 멤버들이 전날 한 일들과 오늘 해야 할 일들을 미리 파악이 가능하며 한 일들, 해야 할 일들에 관한 메모를 남겨둘 수 있어 스크럼 회의를 원활하게 할 수 있다.
스프린트 회고
Do IT 팀의 스프린트 주기는 1주일로 잡았다. 이번 프로젝트는 2주로 지난 프로젝트보다 기한이 길었기에 1주 단위 스프린트를 2회로 잡아 두번의 스프린트 회고를 진행하고자 했다.
각 스프린트 회고는 한 주가 지나고 해당 주간 진행했던 GROUND_RULE, 개발 방식, 진행 방식 등에 대해 느낀점, 개선점, 의견등을 공유하고 한주간 해온 일들을 공유하는 식의 회고를 말한다.
이 과정을 통해 1주일마다 팀 단위로 이번 스프린트동안의 개발 방식에 대한 끊임없는 피드백을 받아 더 나은 방식의 개발문화를 형성할 수 있다.
| 스크럼 기록 | 스크럼 회의록 일부 |
|---|---|
 |  |
디자인
디자인은 내가 피그마로 작업을 해본 적이 있어 팀원들과 구조 설계에 대한 논의를 진행한 후 해당 기록을 바탕으로 피그마로 디자인을 담당했다. 특히 회의시 UI 를 참고할만한 레퍼런스 사이트들에 대해 팀원분들이 공유를 잘 해 주셔서 디자인 작업을 하는데 이번만큼 수월했던 적이 없던 것 같다.
참고 레퍼런스 사이트 : DevFoliOh / 비사이드 / LET'S PL / HOLA / UPSTUDY
전체 디자인

원래 모바일, 태블릿, 데스크탑 순서로 반응형 디자인을 하려고 했는데 모바일 내에서도 반응형이 이루어져서 크게 모바일과 웹으로 나누어 디자인을 했다.
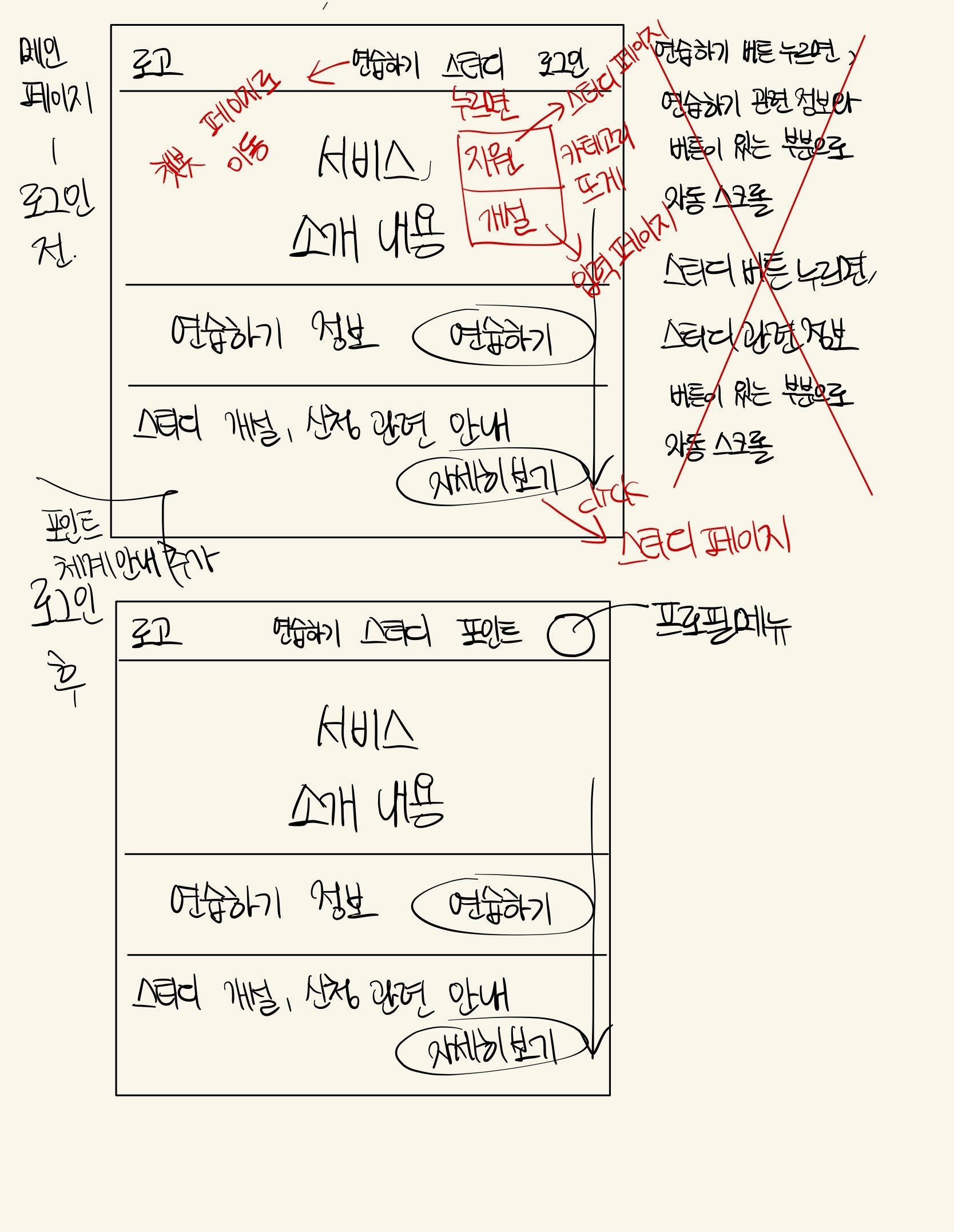
메인

메인 화면에 대한 디자인이다. 로그인 할때와 하지 않았을때, 최소 크기일때와 최대 크기일때의 디자인을 구성했다.
모바일 목업에 대해서는 피그마 커뮤니티중 Free Clay Mockups, iPhone 12 Free Mockups 를 활용했다.


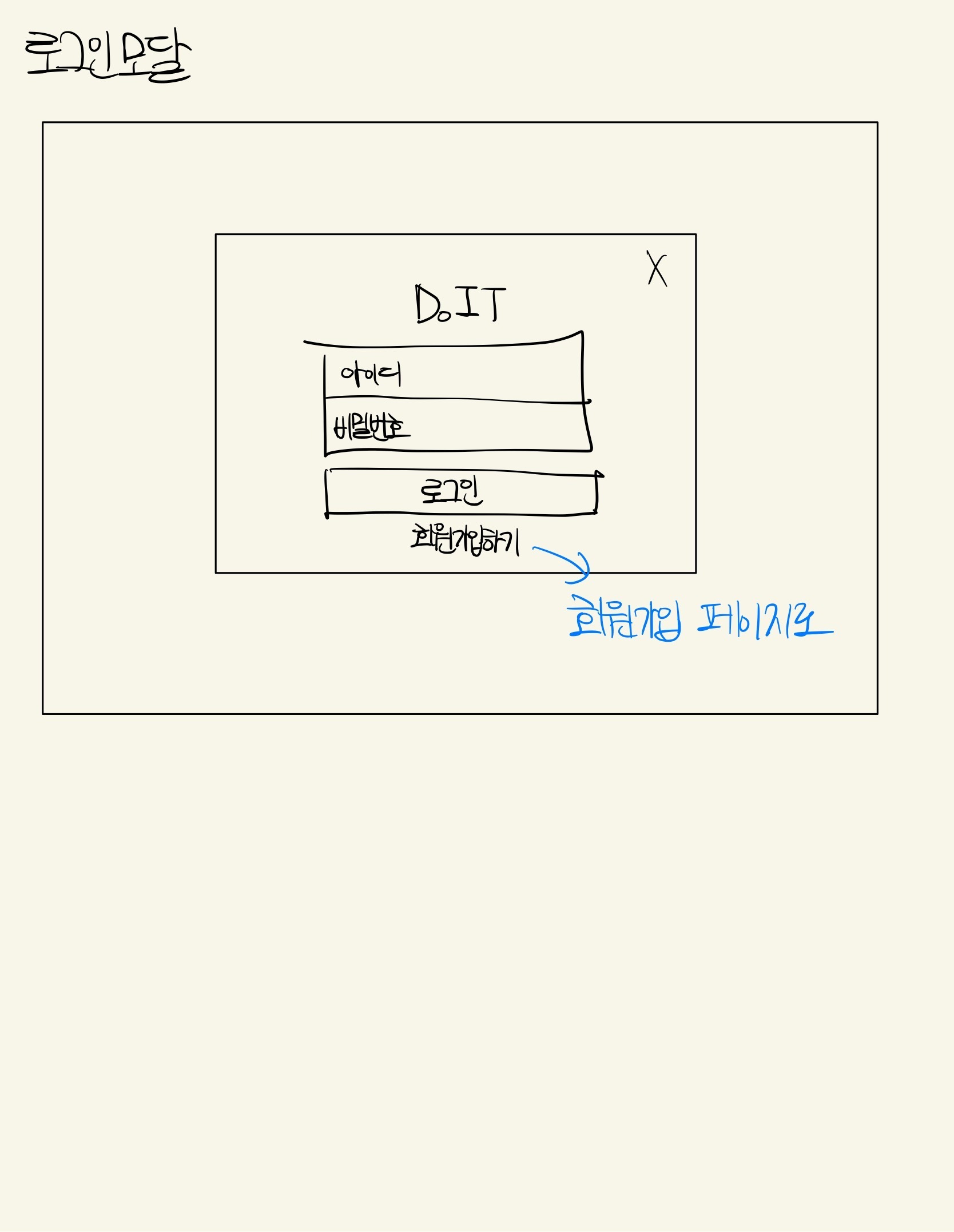
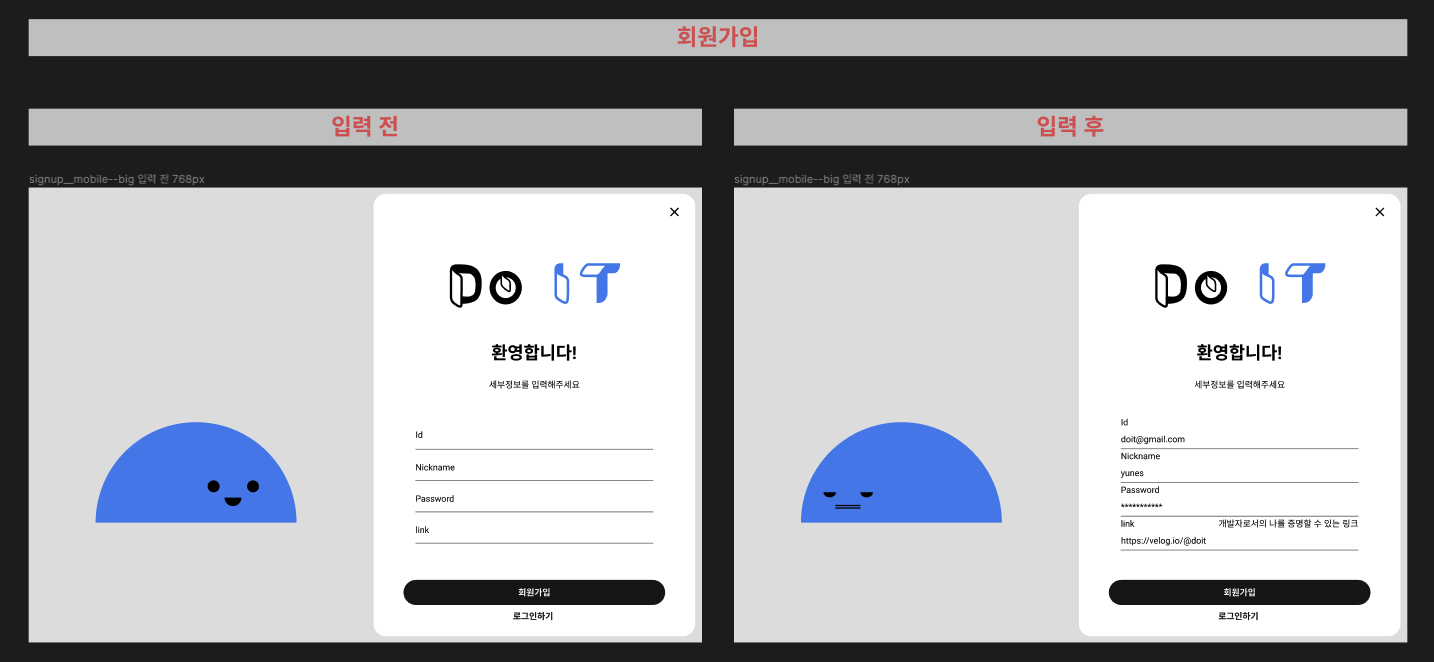
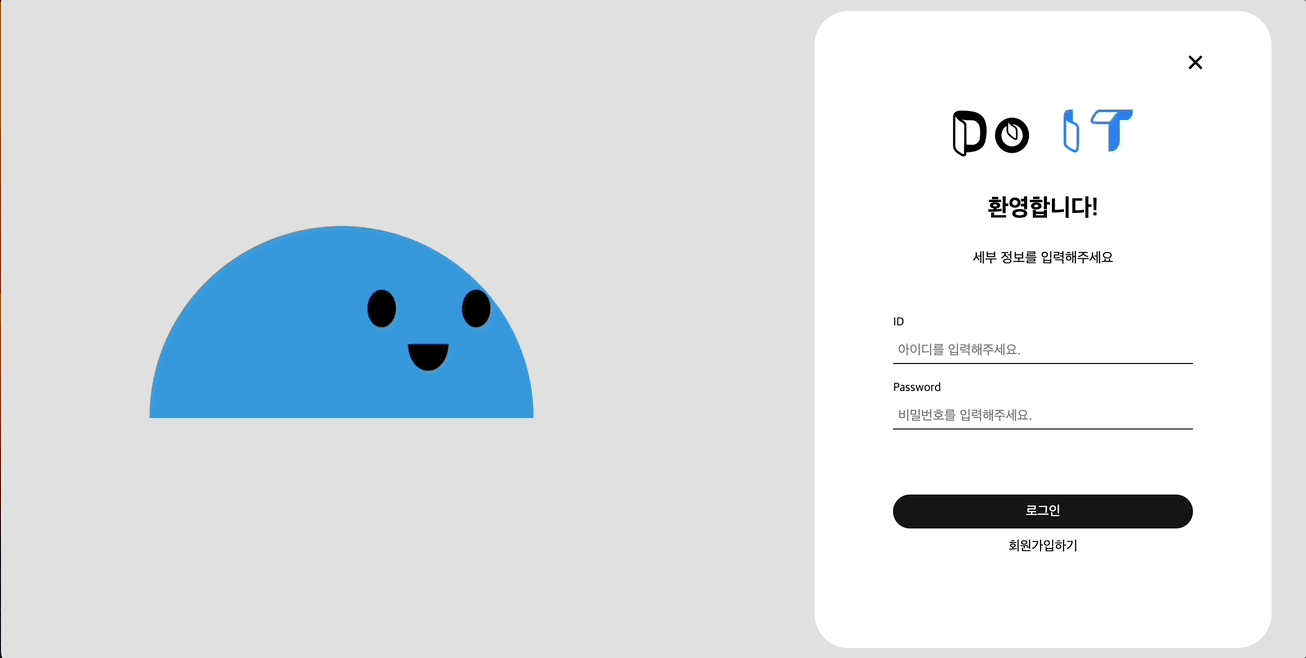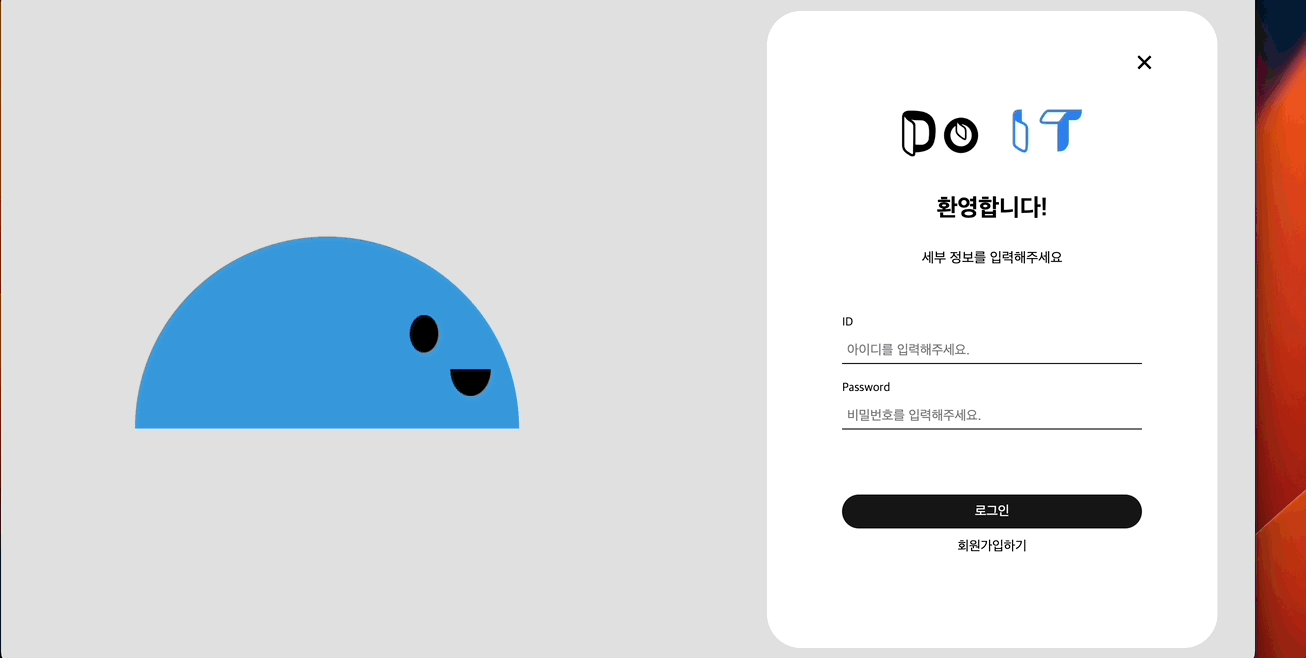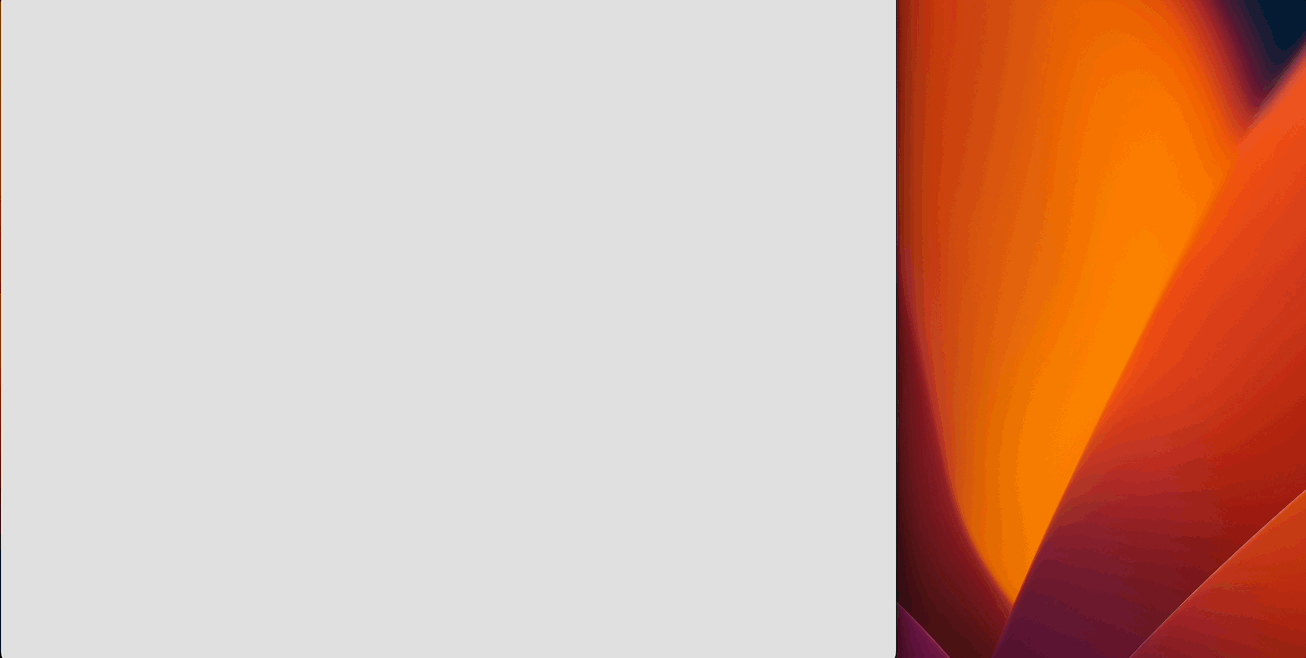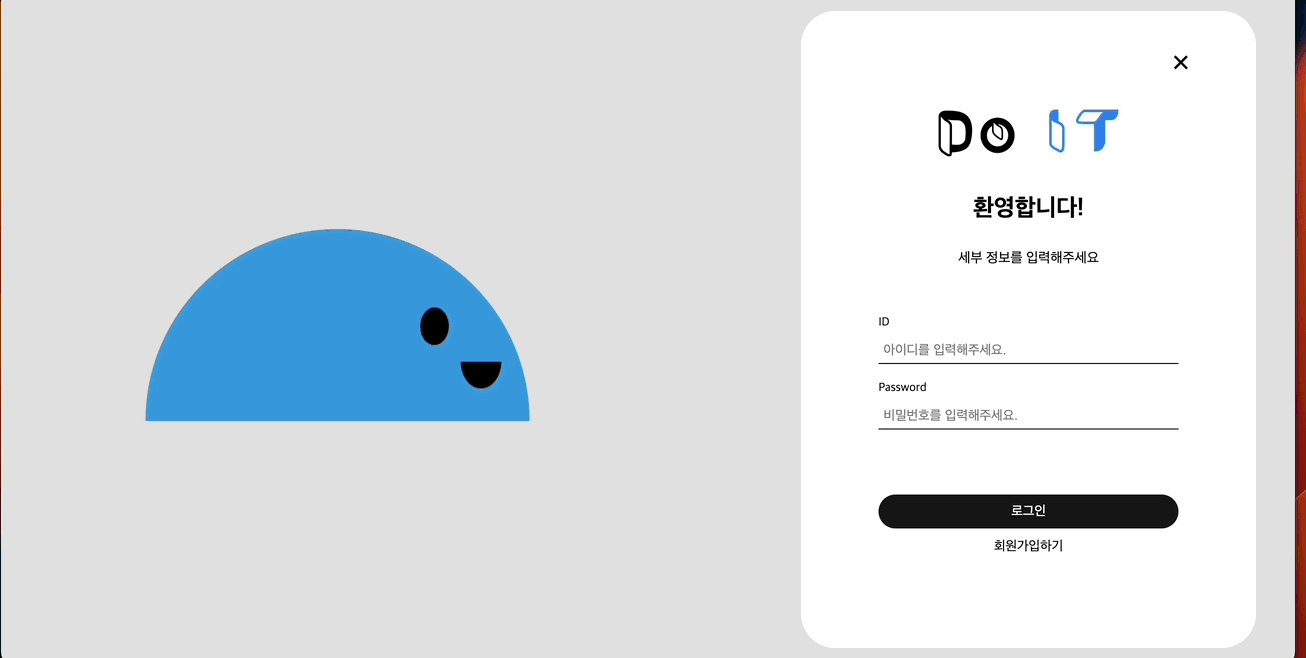
회원가입 및 로그인
모바일이니만큼 아래서 위로 올라오는 형태의 바텀시트를 생각했고 웹에서는 닫기 버튼으로 닫을 수 있는 모달을 생각했다.
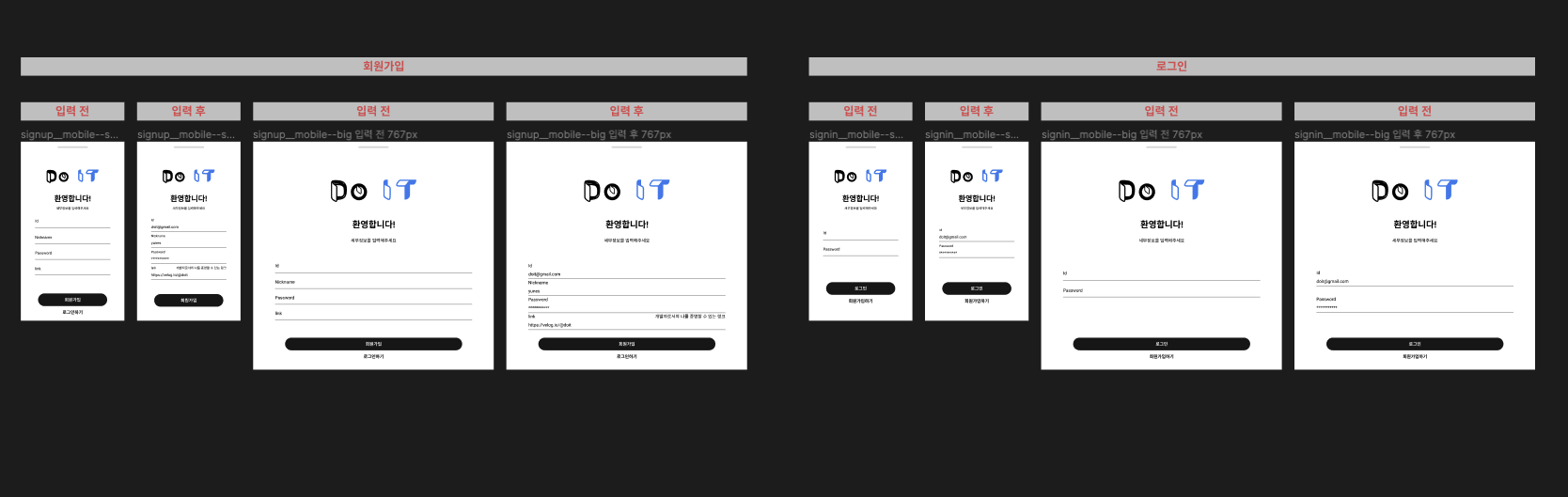
웹에서의 디자인을 모바일과 다르게 구상했다.
다음 블로그들 kozel - 그래픽 툴 없이 svg 만을 이용해 캐릭터 그리기, 코드쓰는사람 - svg, js, css 로 만드는 라이언 로그인 폼, outcrowd - creative log in for the educational platform 을 참고했다.
특히 하단의 Do IT 마스코트는 위에서 언급한 outcrowd의 동작 애니메이션과 디자인처럼 움직이게 만들어보고 싶었다.
해당 사이트에서 본 것처럼 캐릭터가 말랑말랑하게 움직이도록 하고 싶었는데 방법을 찾다못해 얼굴만 마우스를 따라 움직이고 비밀번호 입력시 보안을 위해 보지 않도록 하는 애니메이션을 넣어봤다.

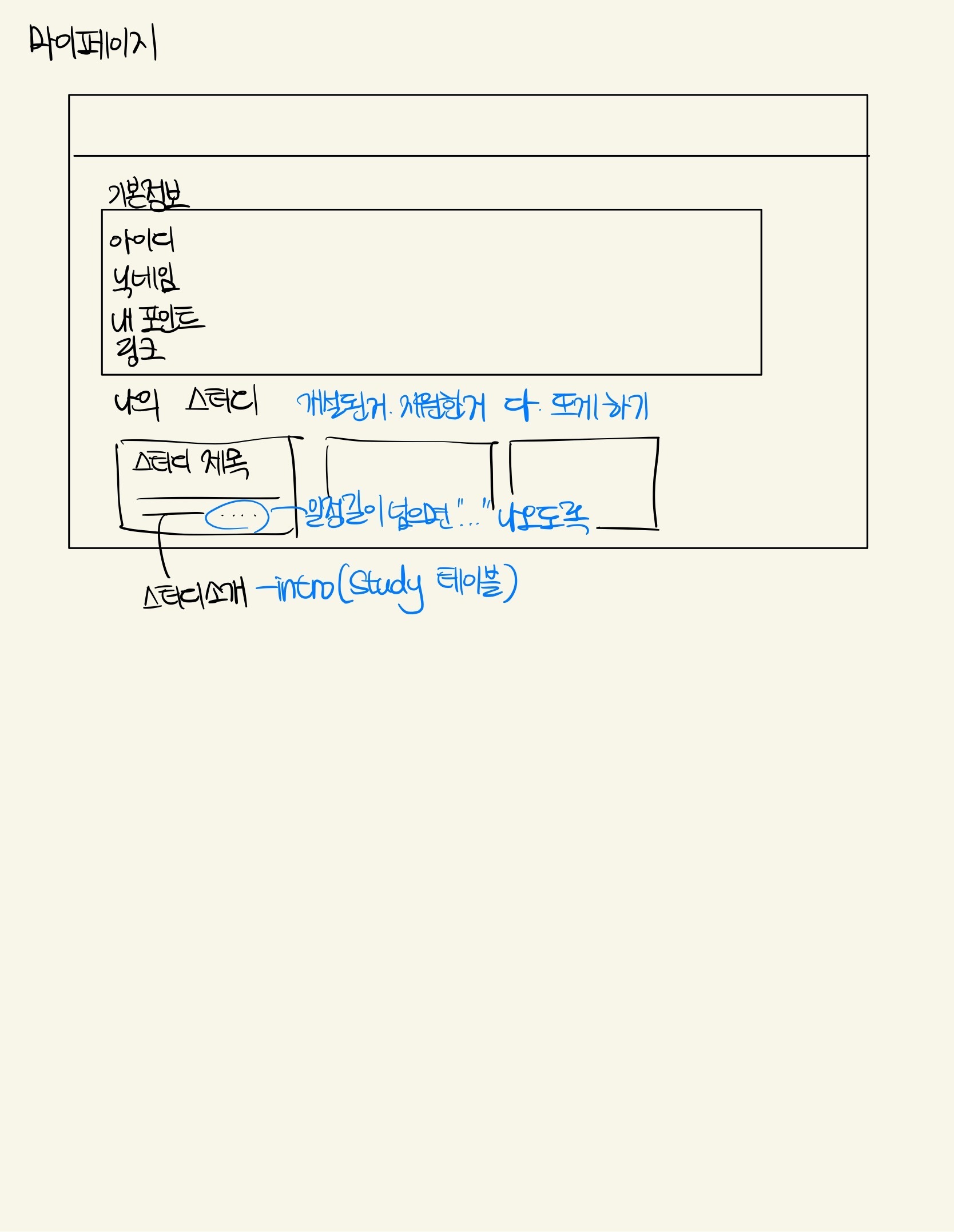
마이페이지
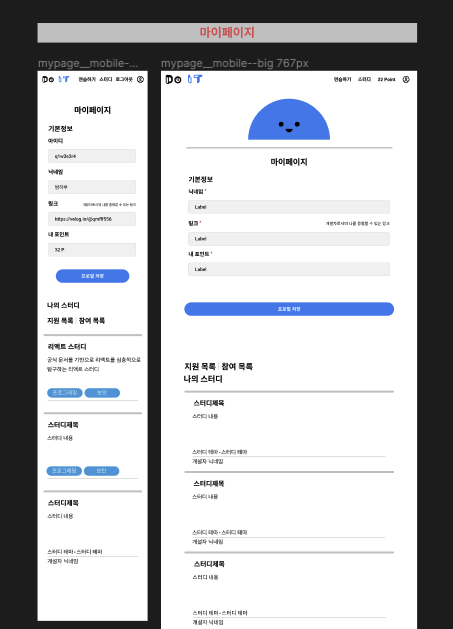
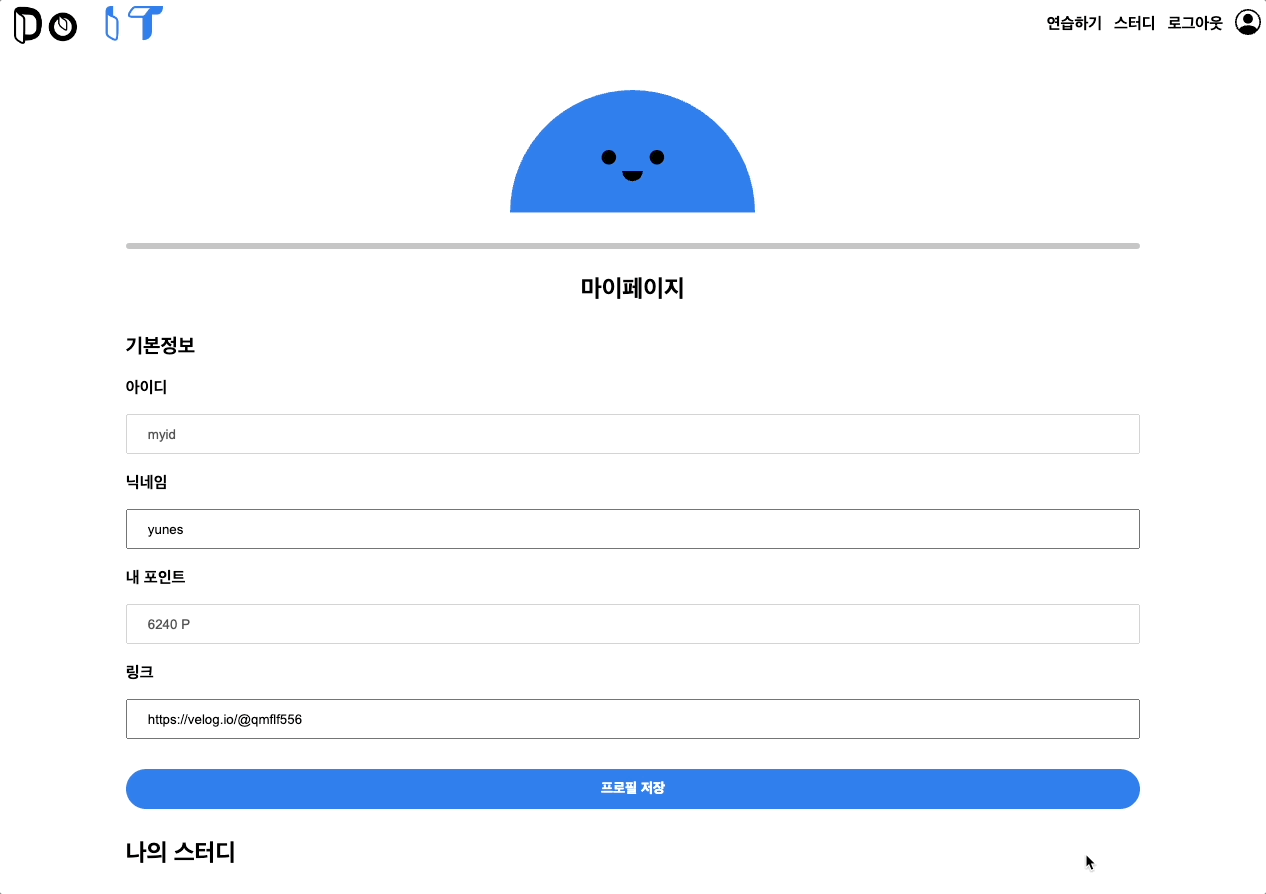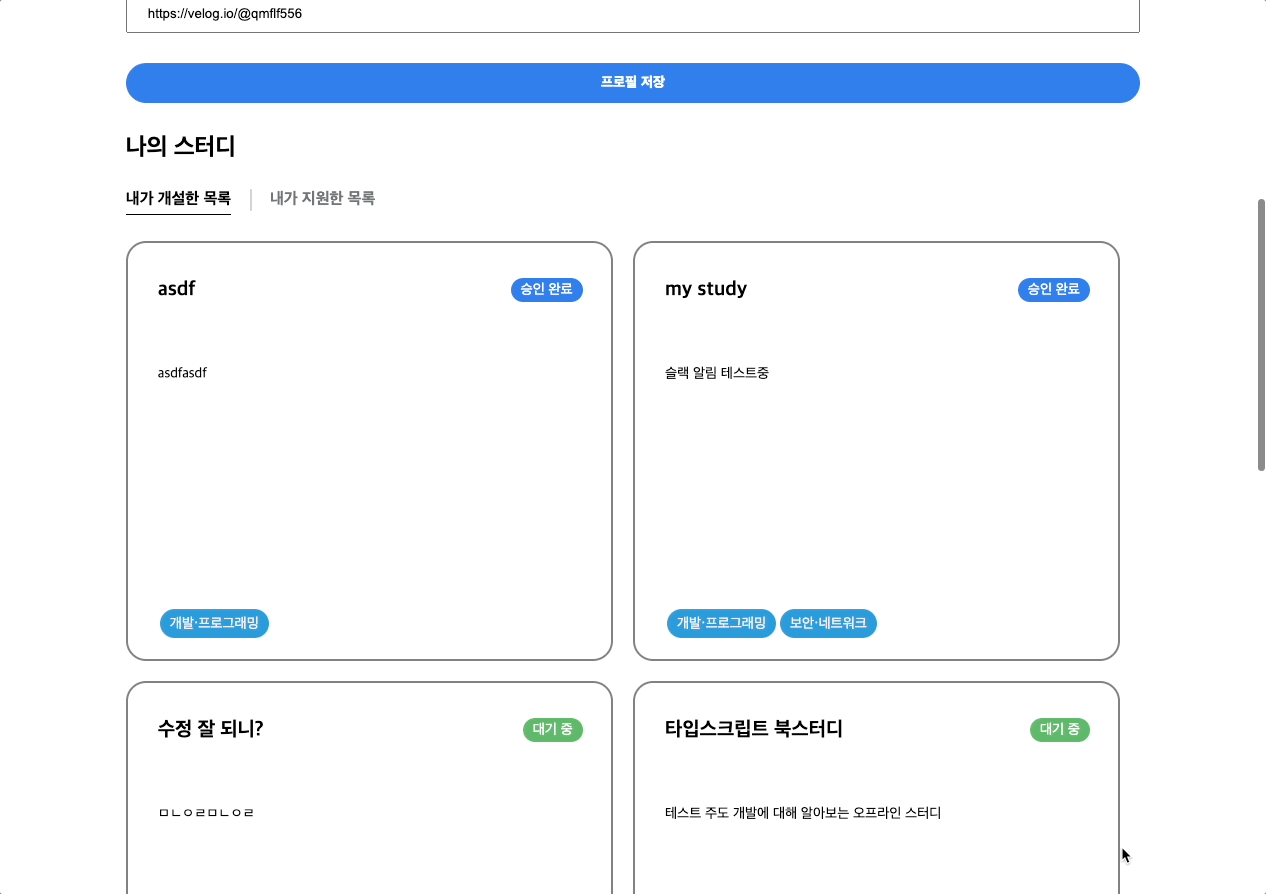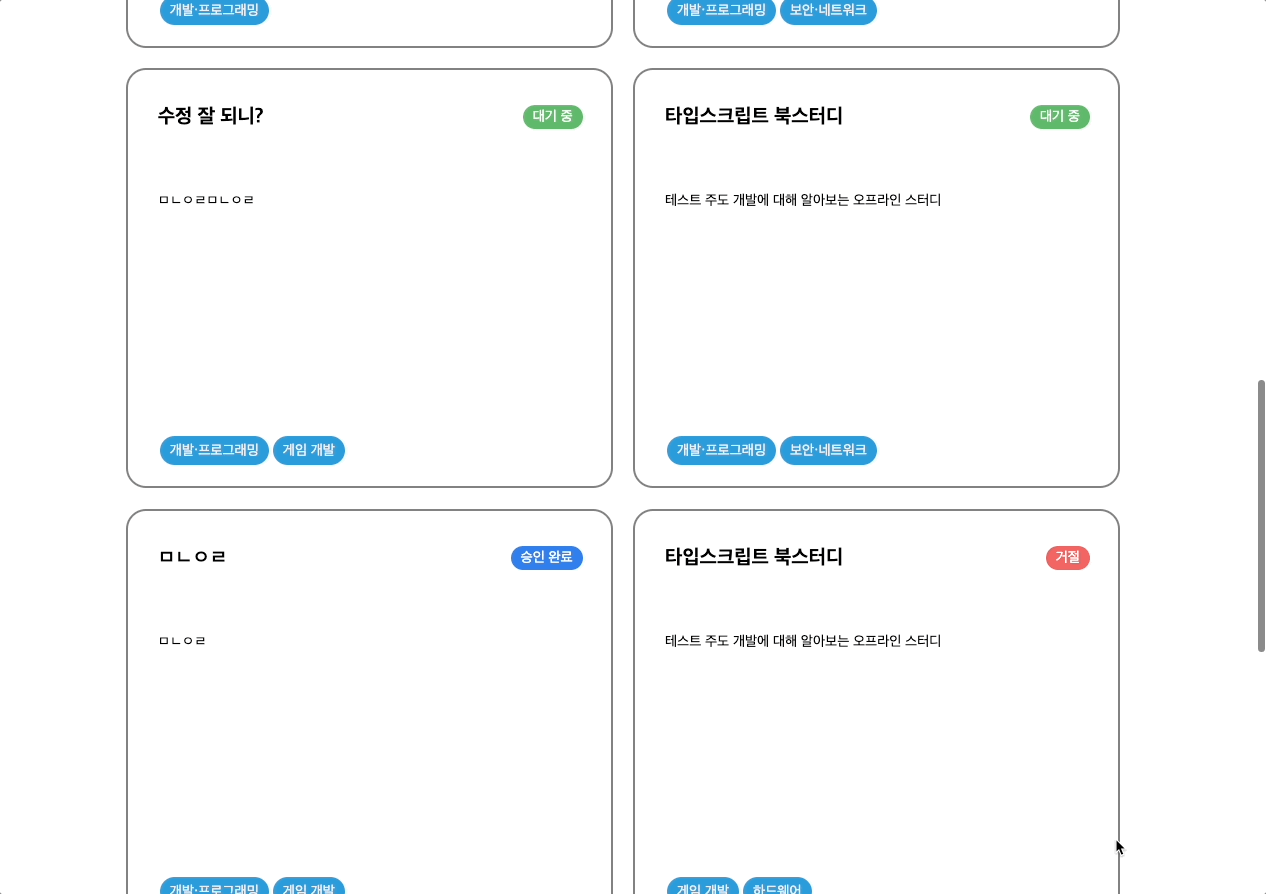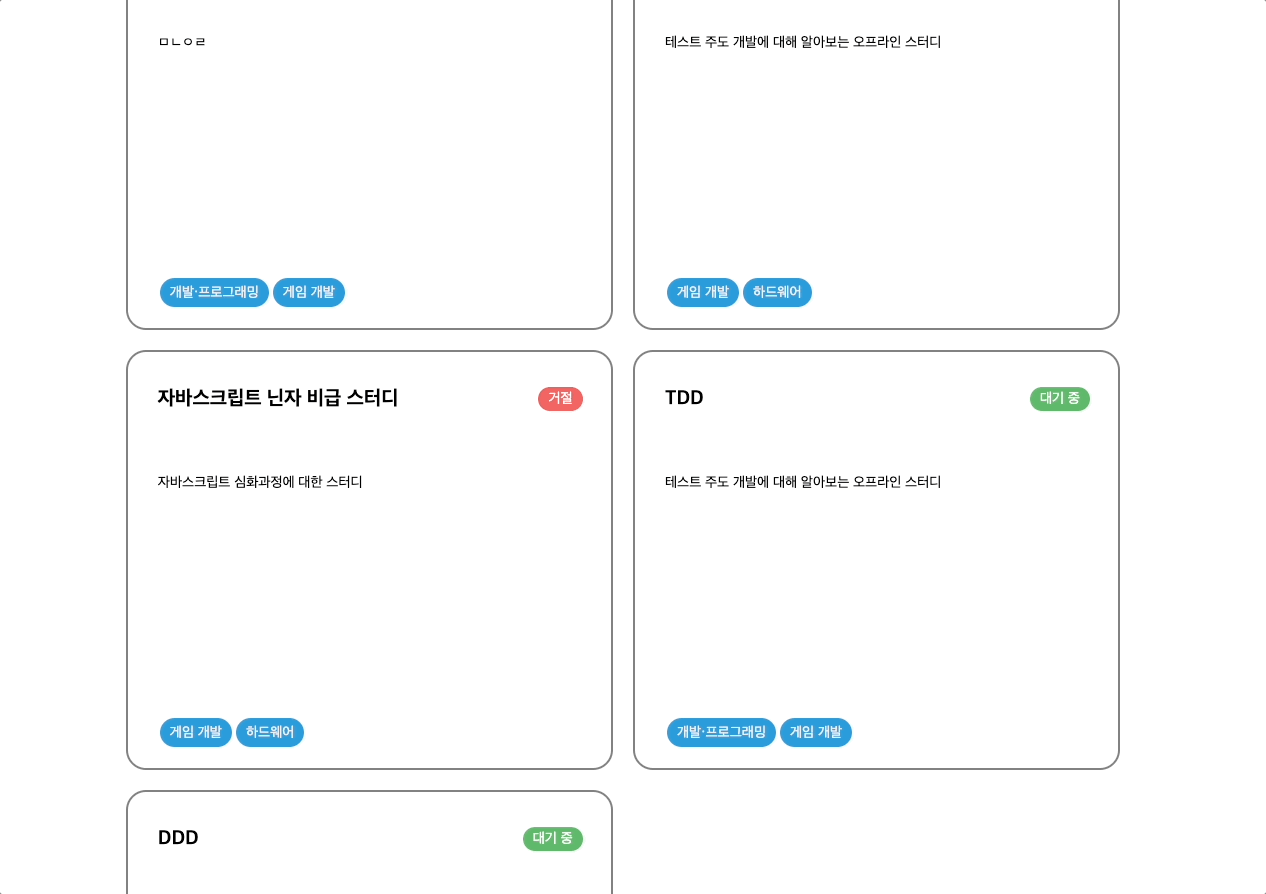
마이페이지 디자인이다. 귀여운 마스코트의 얼굴이 위아래로 움직이는 애니메이션을 넣어달라고 팀원분께 부탁드렸다.
마이페이지에선 닉네임, 증빙 링크 (깃허브 혹은 기술블로그 링크)를 수정할 수 있다. 또한 내가 개설한 스터디 목록과 지원한 스터디 목록을 확인할 수 있다. 해당 목록에선 현재 각 스터디가 승인 완료인지 대기중인지 혹은 거절되었는지 상태를 확인할 수 있다.
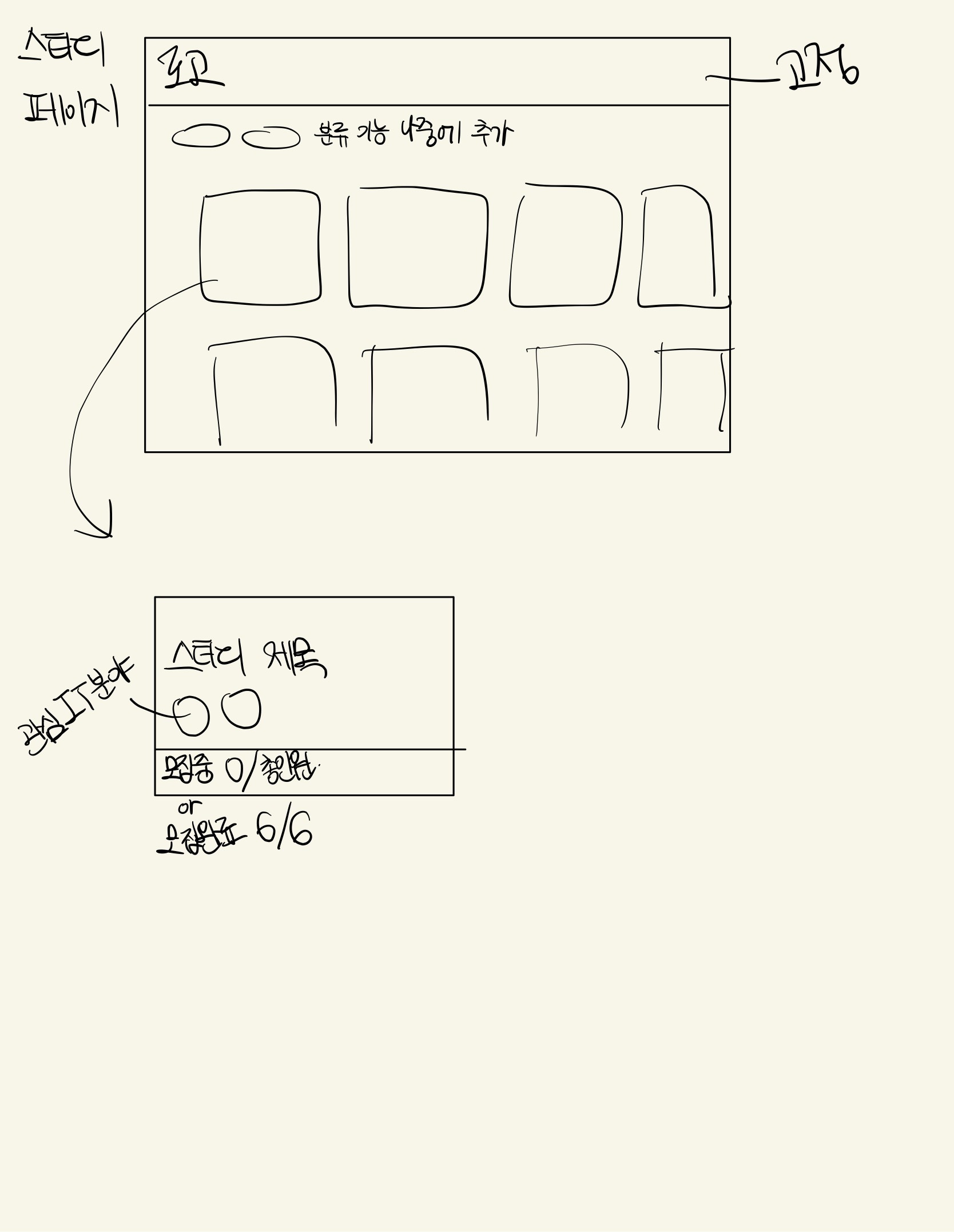
스터디
스터디 목록
| 피그마 시안 | 작업 결과 |
|---|---|
 | 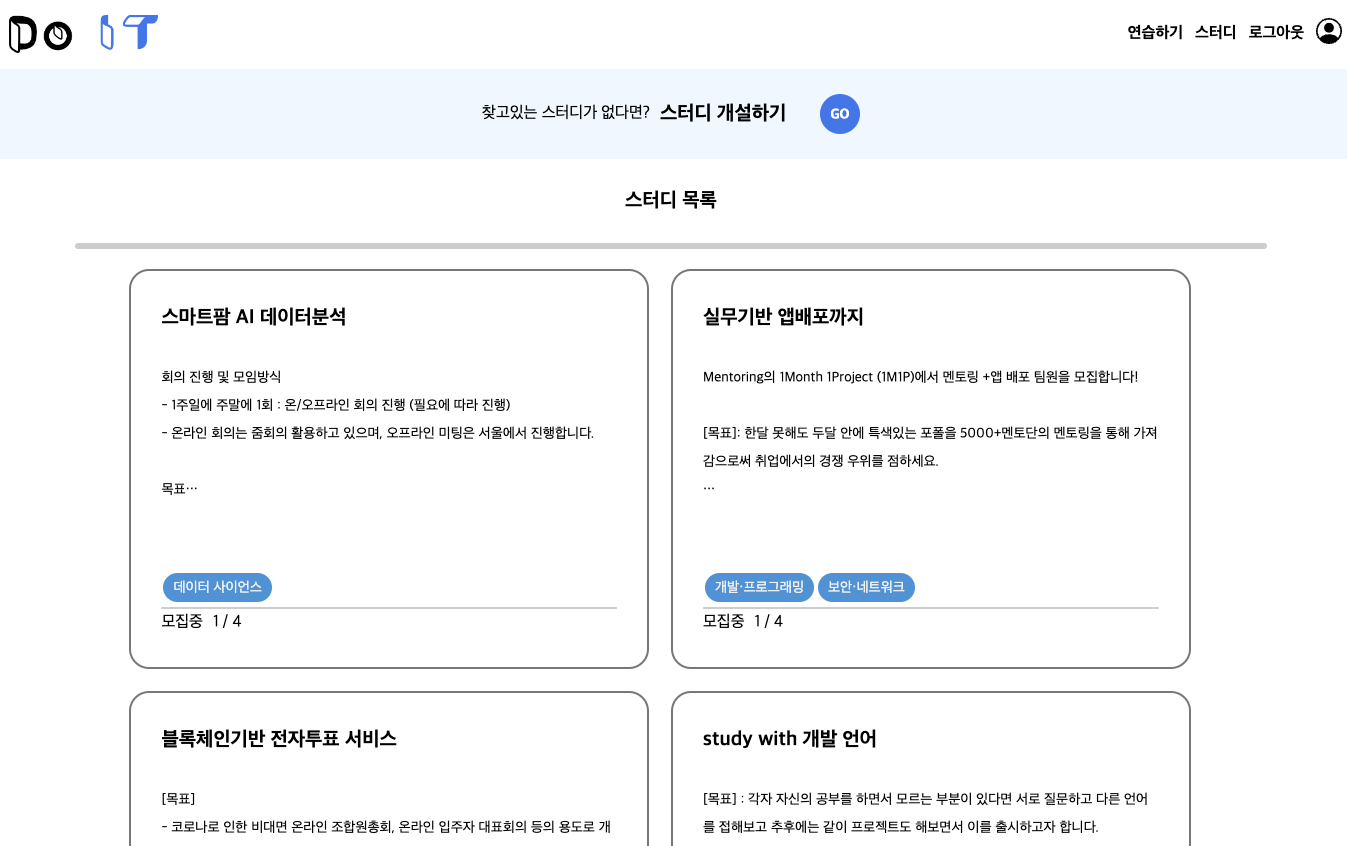 |
스터디 목록을 통해 모집 현황, 스터디 제목, 소개글, 관심 IT 분야를 확인할 수 있으며 각 스터디를 클릭하여 세부 페이지로 들어갈 수 있다.
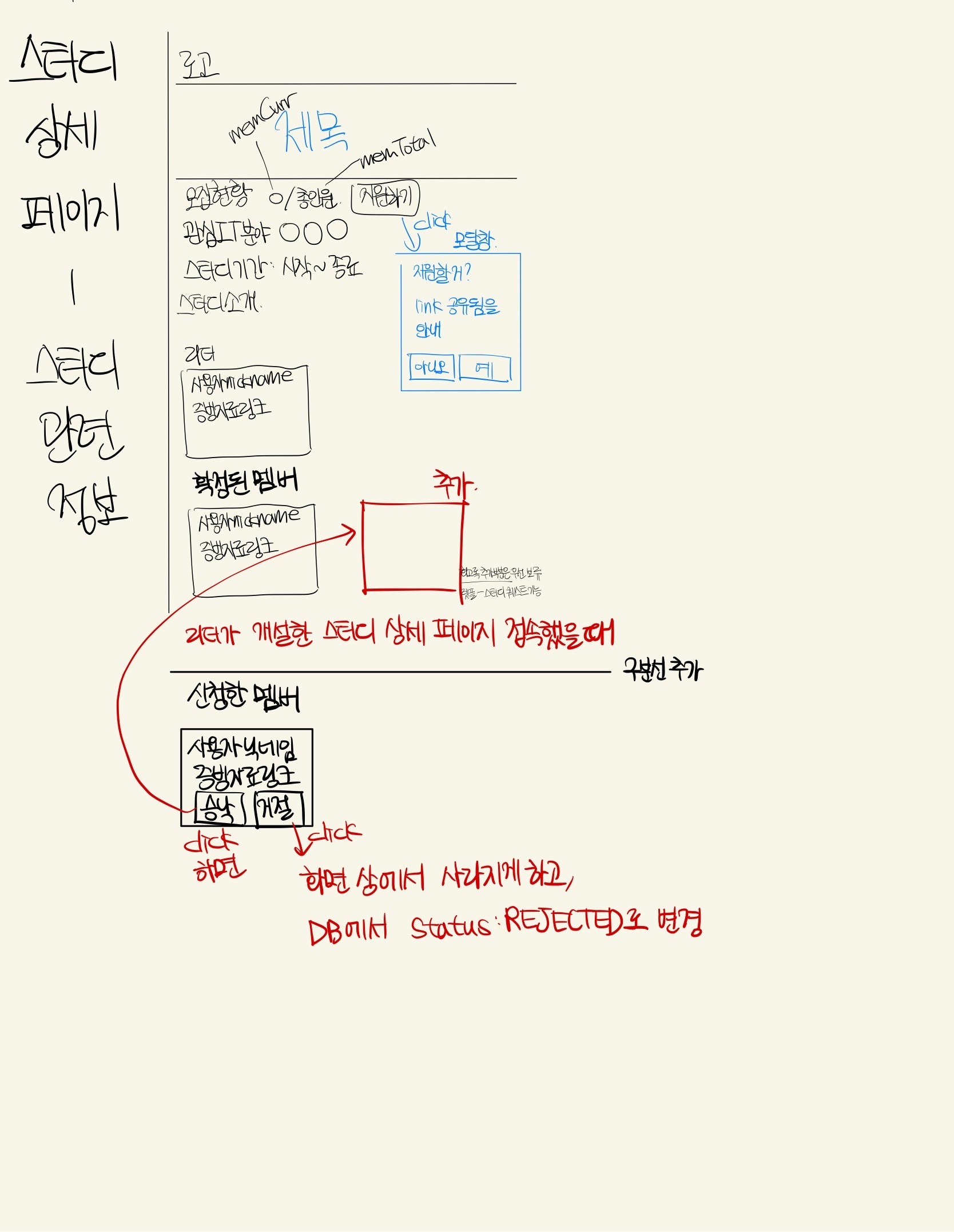
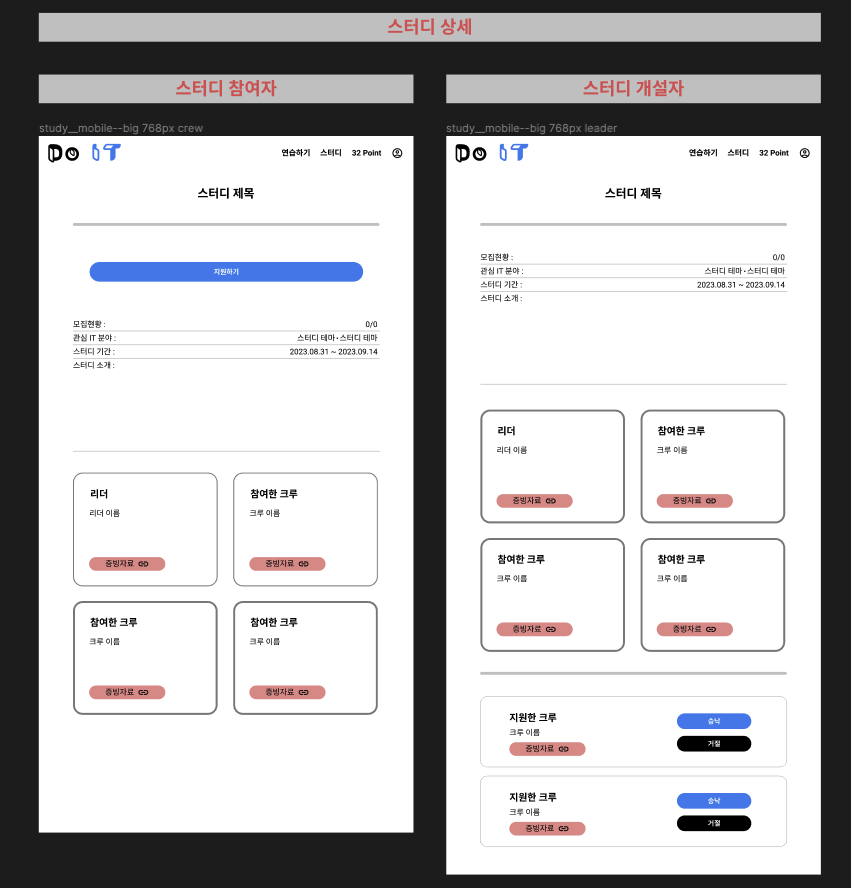
스터디 상세
모바일
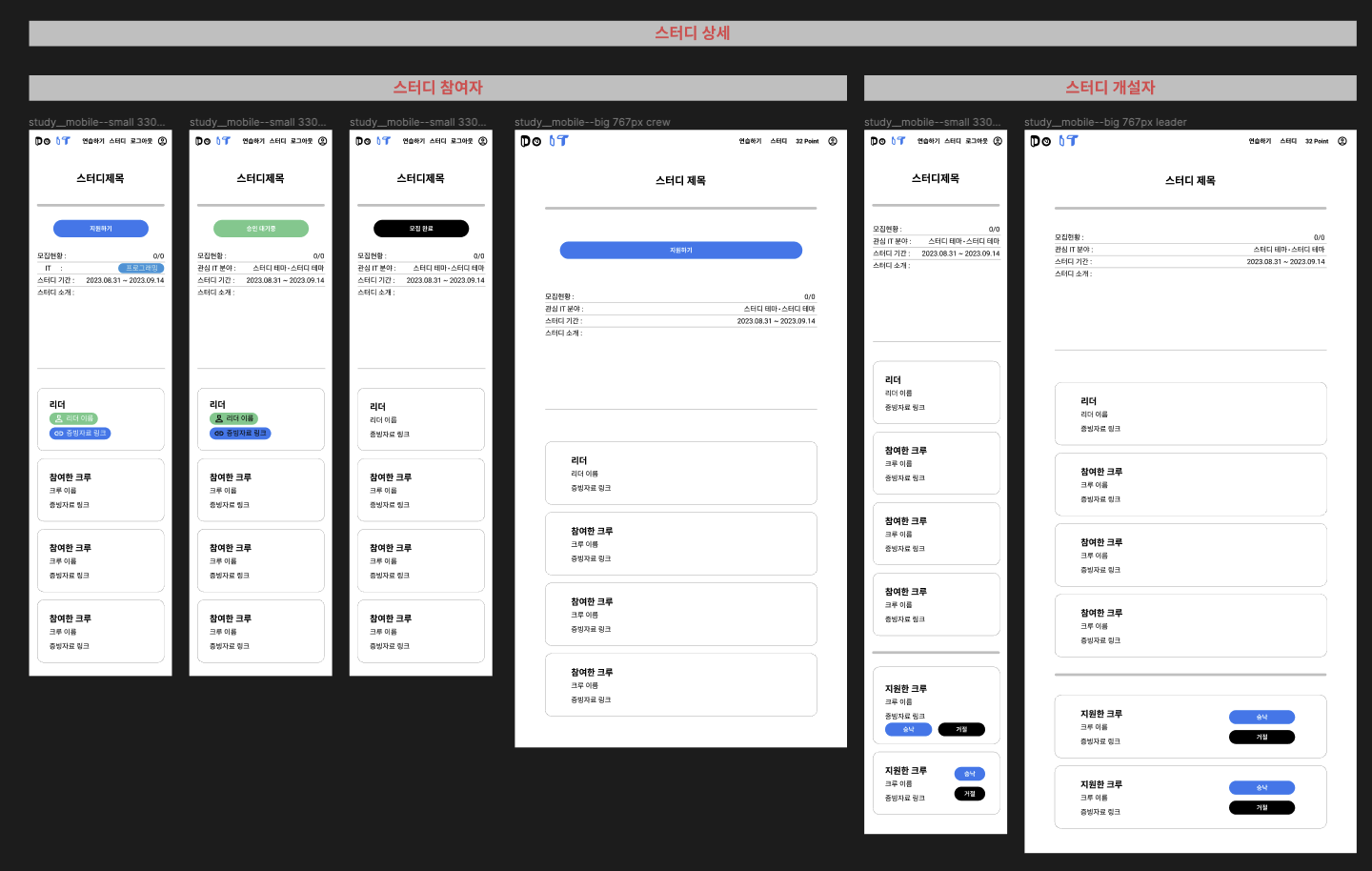
웹
서버 배포 - 지원자
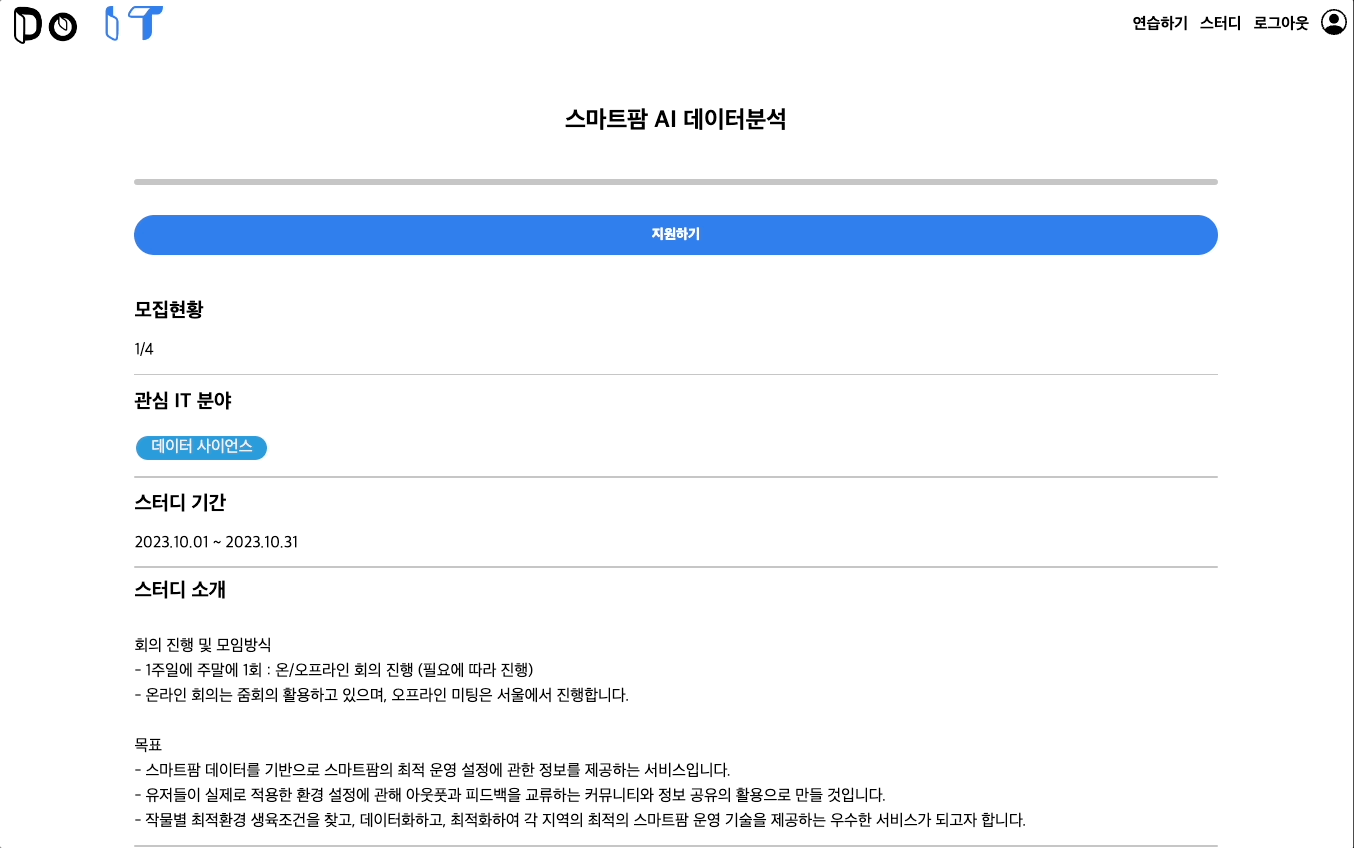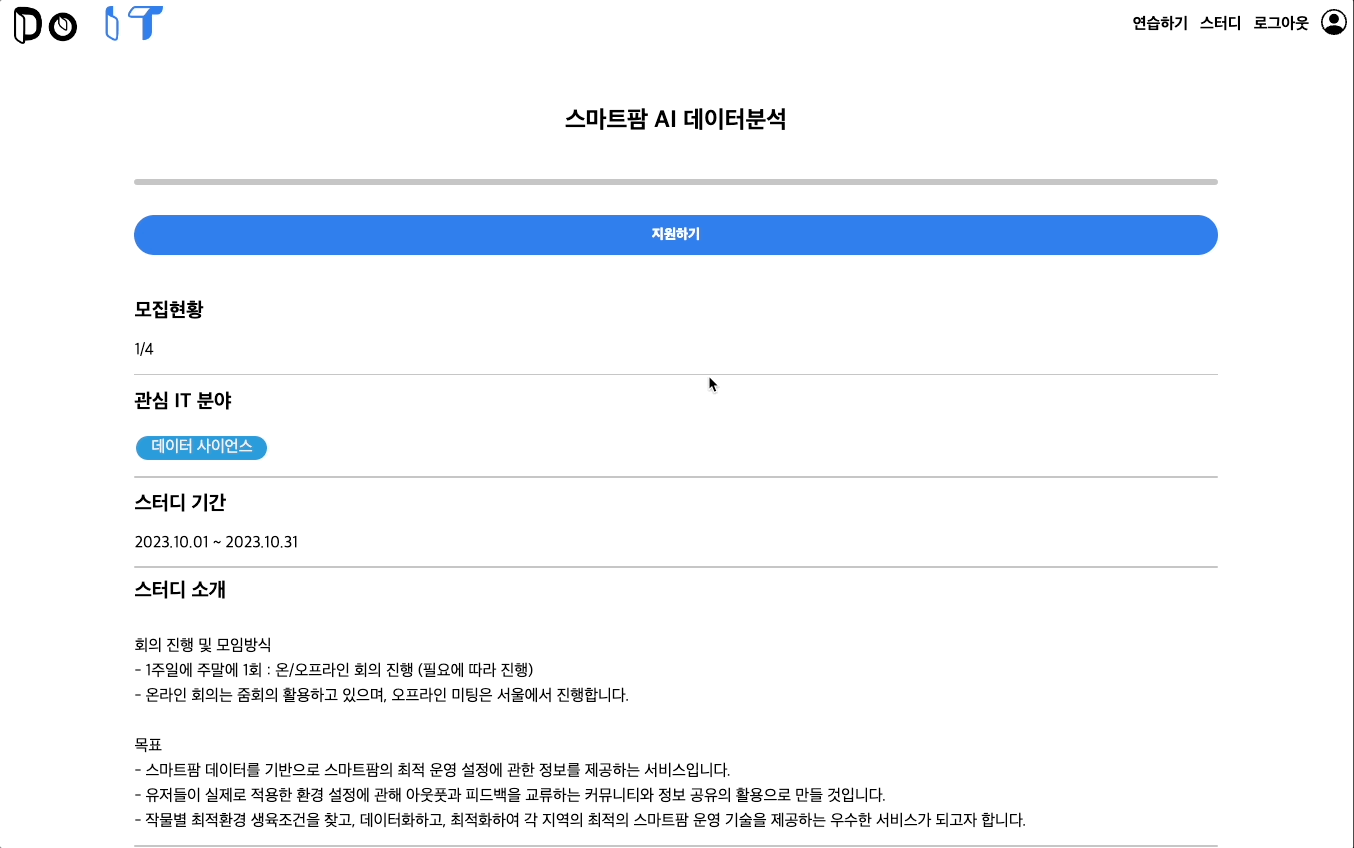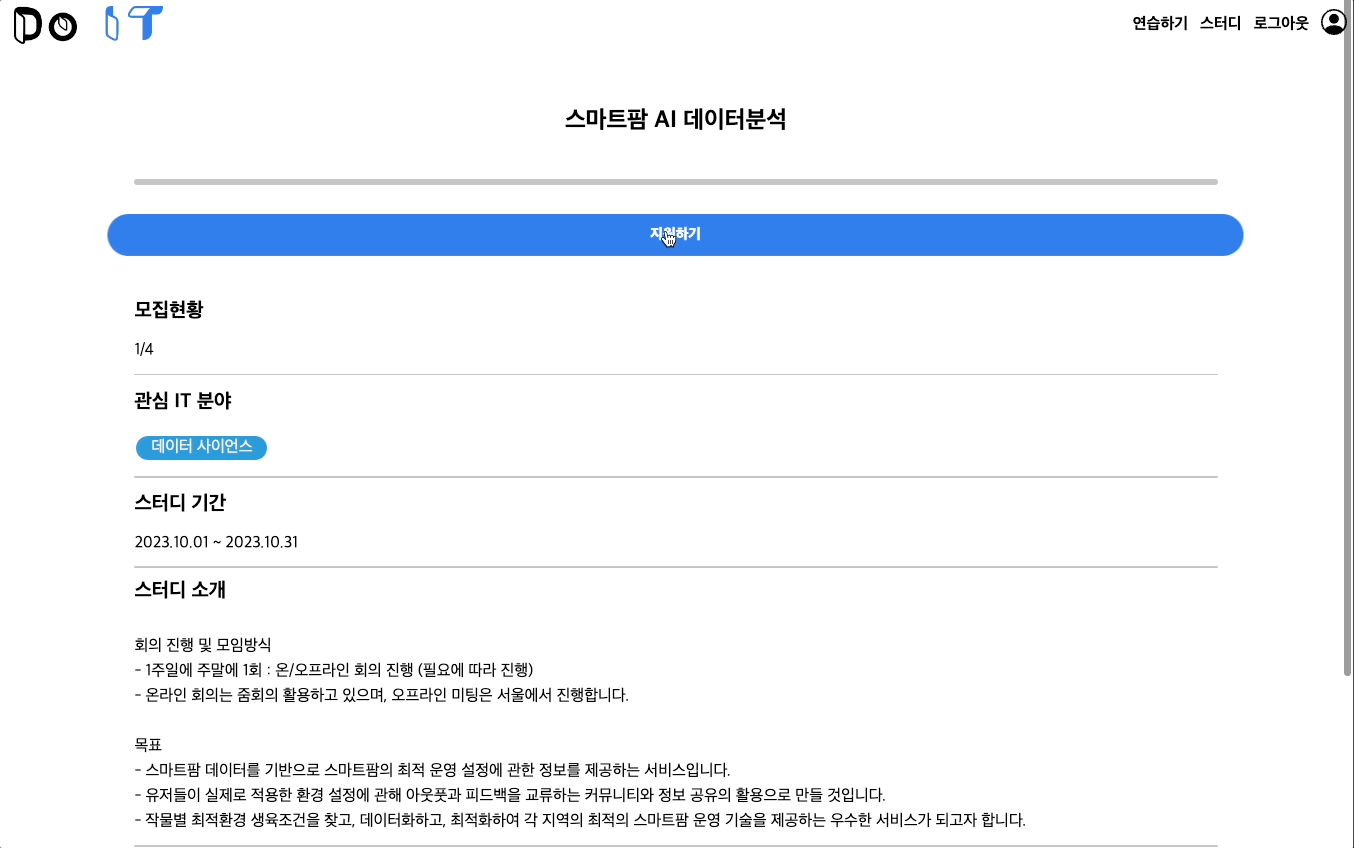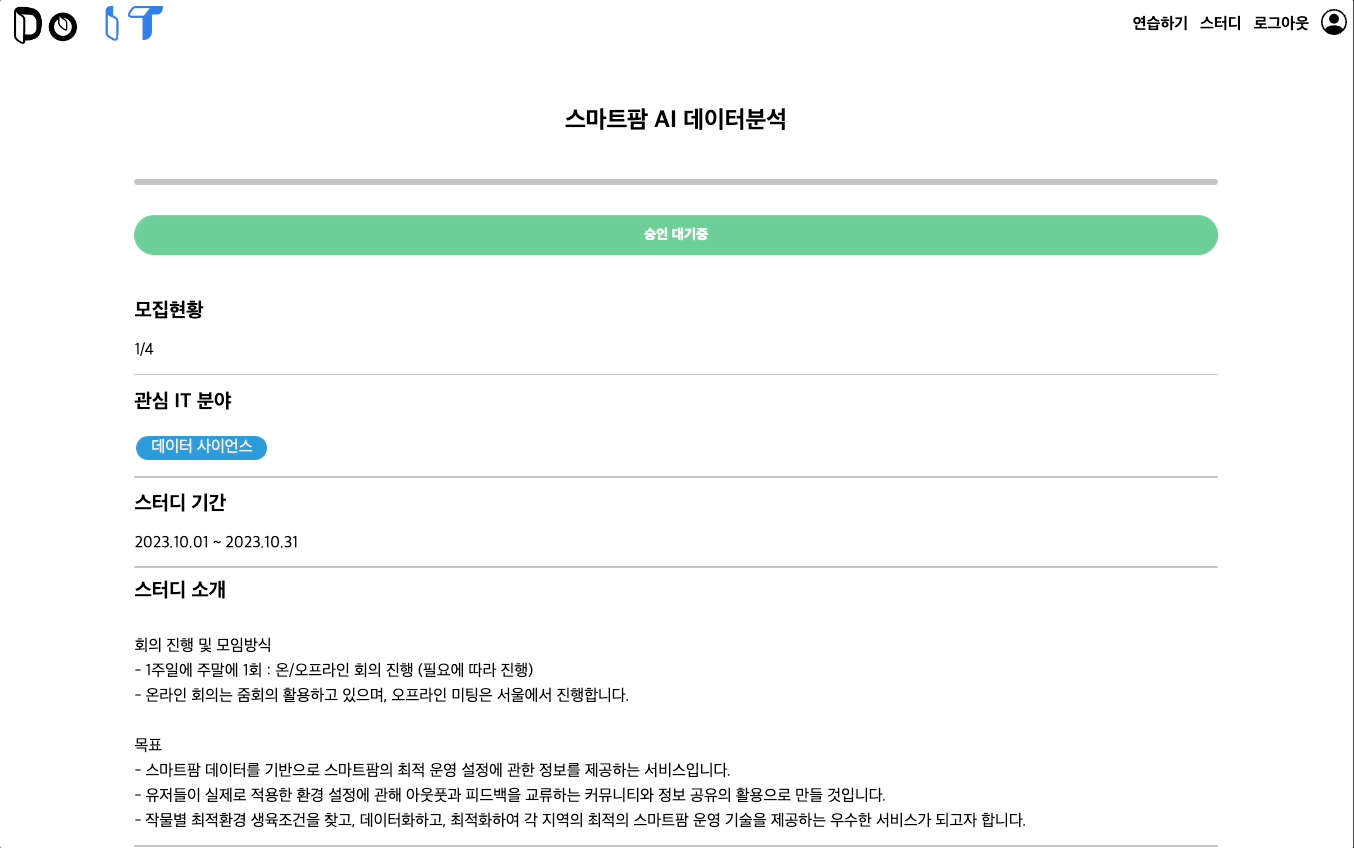
서버 배포 - 개설자

스터디 상세 페이지에서는 스터디 개설자와 스터디 참여자가 볼 수 있는 화면이 다르다.
누구나 현재 스터디에 합류한 리더, 참여한 크루원을 확인할 수 있다. 다만 스터디 지원자만 지원하기 / 승인 대기중 / 모집 완료 버튼을 확인할 수 있고 스터디 개설자만 내가 개설한 스터디에 지원한 크루들의 참여 여부를 승낙 / 거절할 수 있다.
스터디 개설
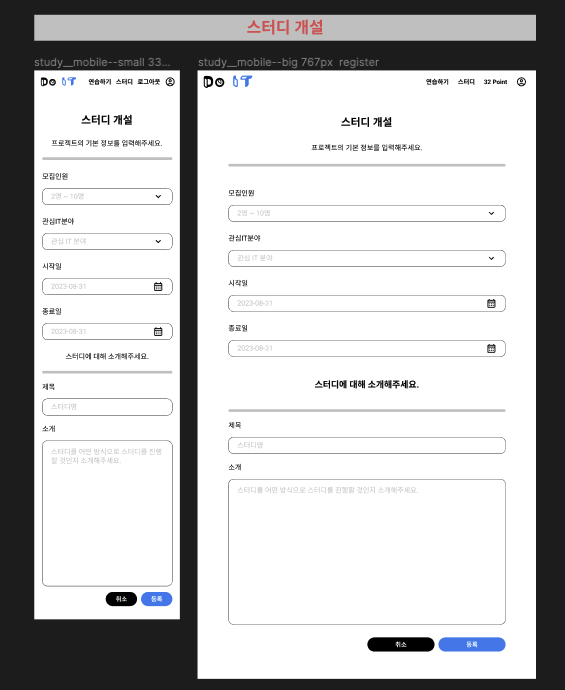
스터디 개설시엔 모집 인원, 관심 분야, 시작, 종료일을 지정할 수 있고 스터디 제목과 소개란을 채우도록 했다.
스터디를 개설 신청하면 슬랙으로 해당 정보를 담은 알림 스레드가 생성된다.
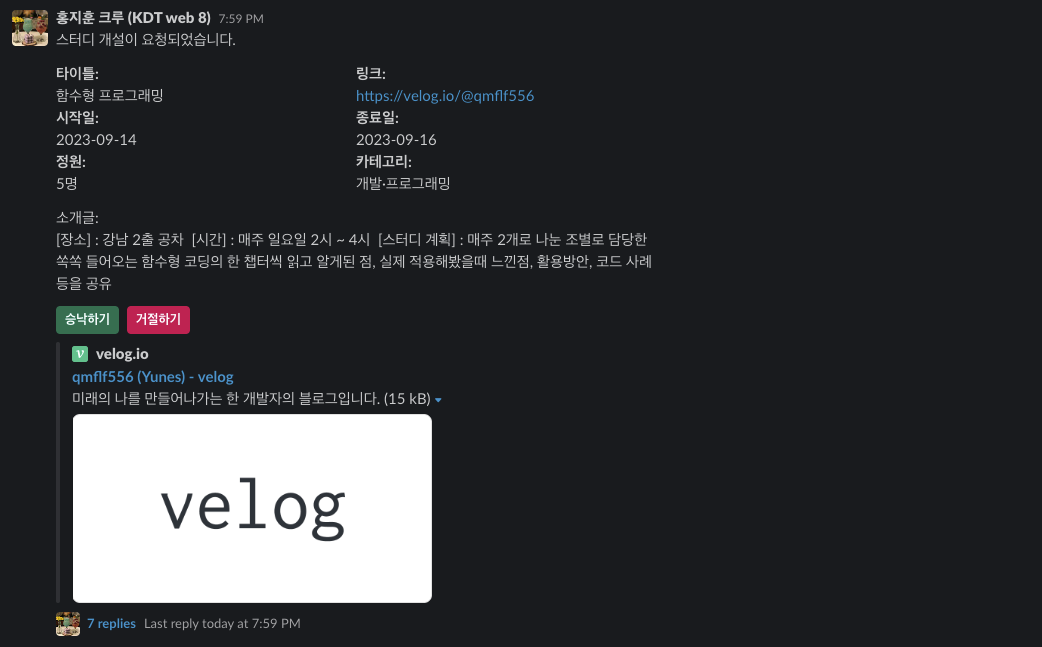
링크와 스터디 소개글을 참고하여 운영진은 스터디 개설여부를 결정할 수 있다.
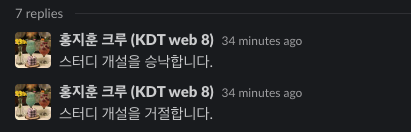
운영진의 결정은 위와 같이 번복할 수 있으며 결정된 사항에 대해 해당 스레드의 댓글을 슬랙봇을 통해 생성하도록 했다.
처음엔 슬랙봇 생성한 슬랙봇이 위의 과정을 진행해주더니 어느 순간부터 내 계정으로 알림과 결과를 알려주고 있었다... 마찬가지로 원인 파악중 전체 흐름에 문제가 있는 부분이 아니라 후순위로 미루고 원인을 찾고 있다..
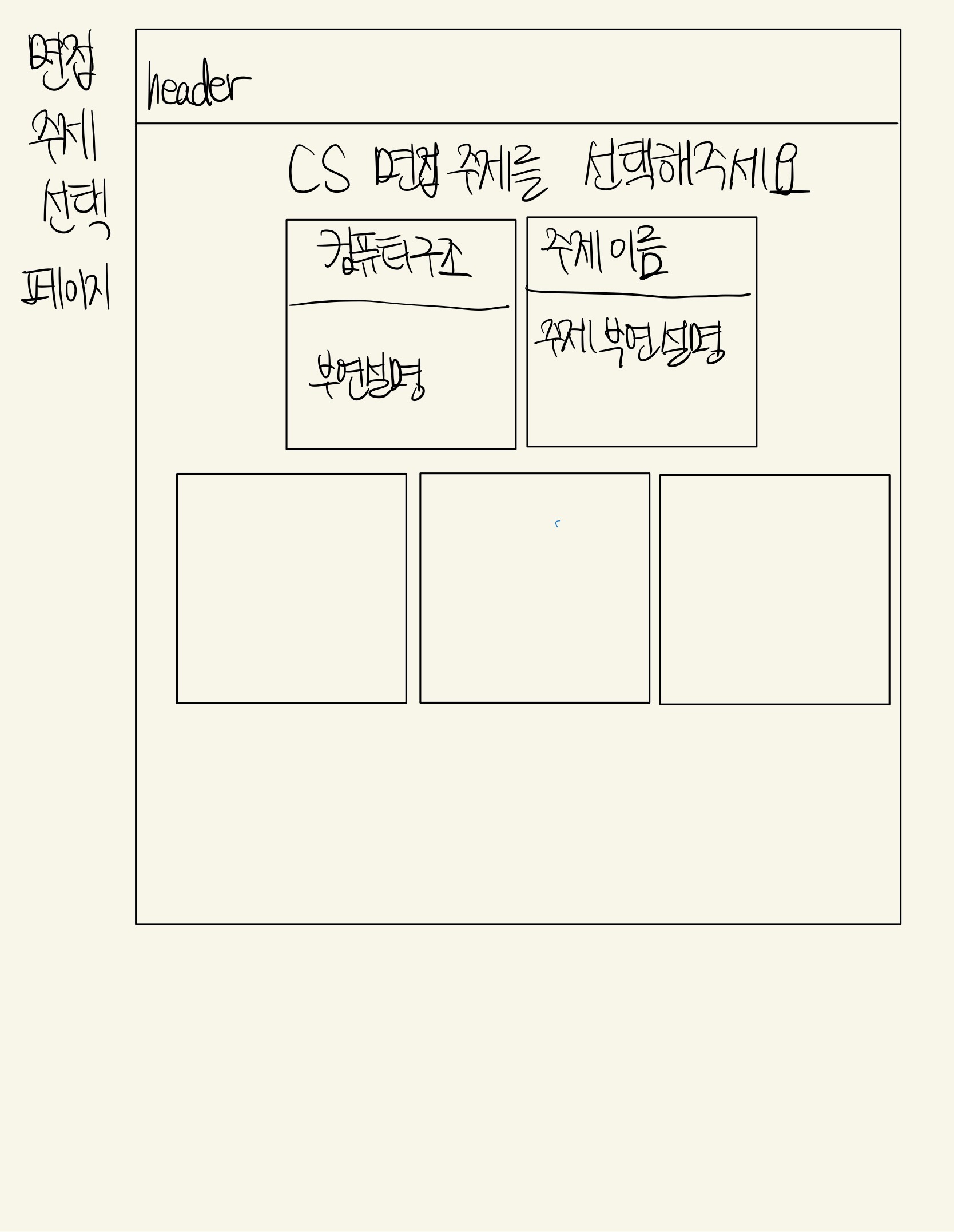
CS 면접 연습하기
주제 선택하기와 CS 면접 연습 2가지 기능이 있다.
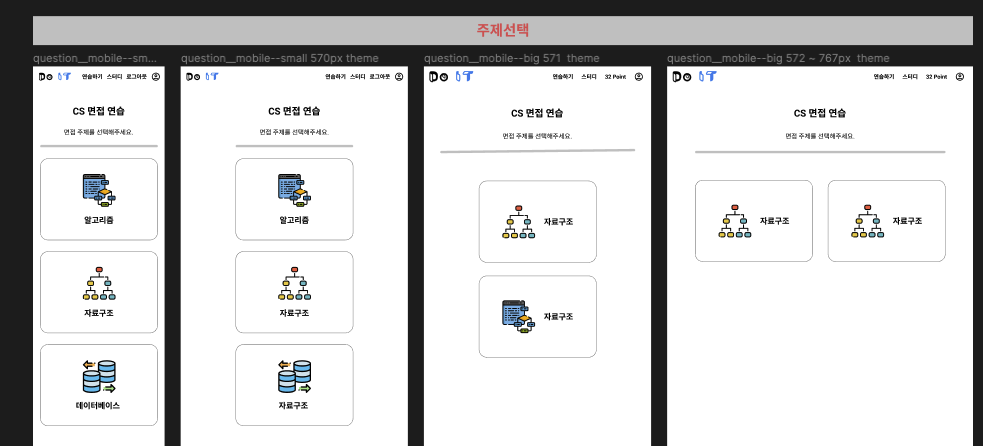
먼저 면접 연습할 주제를 선택한다.
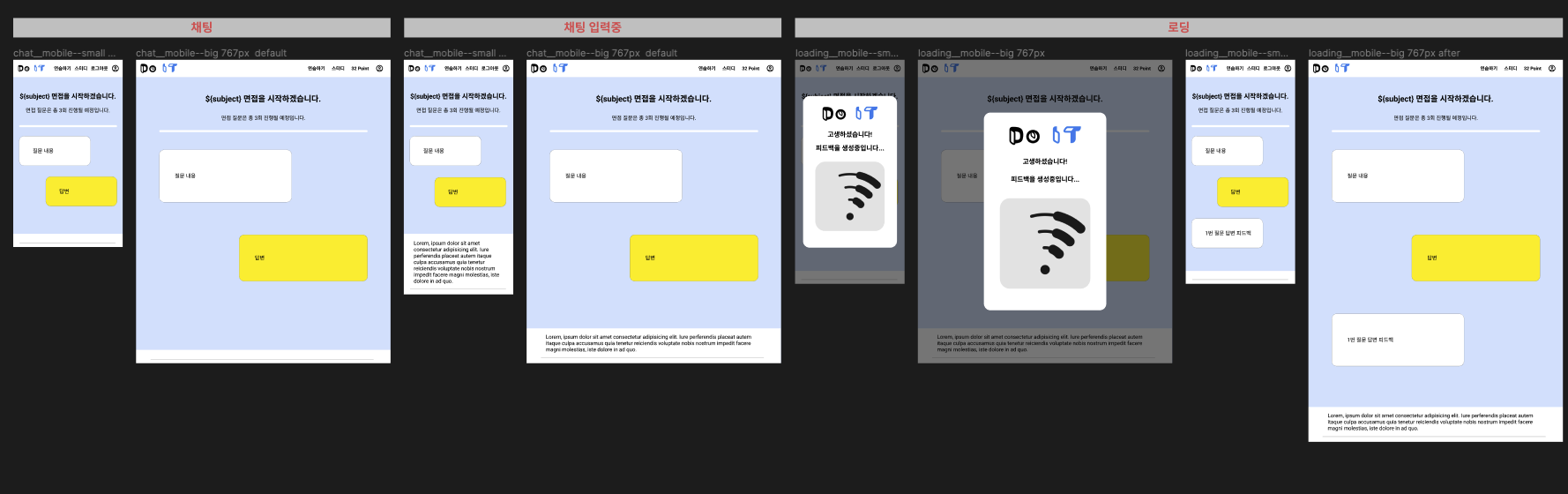
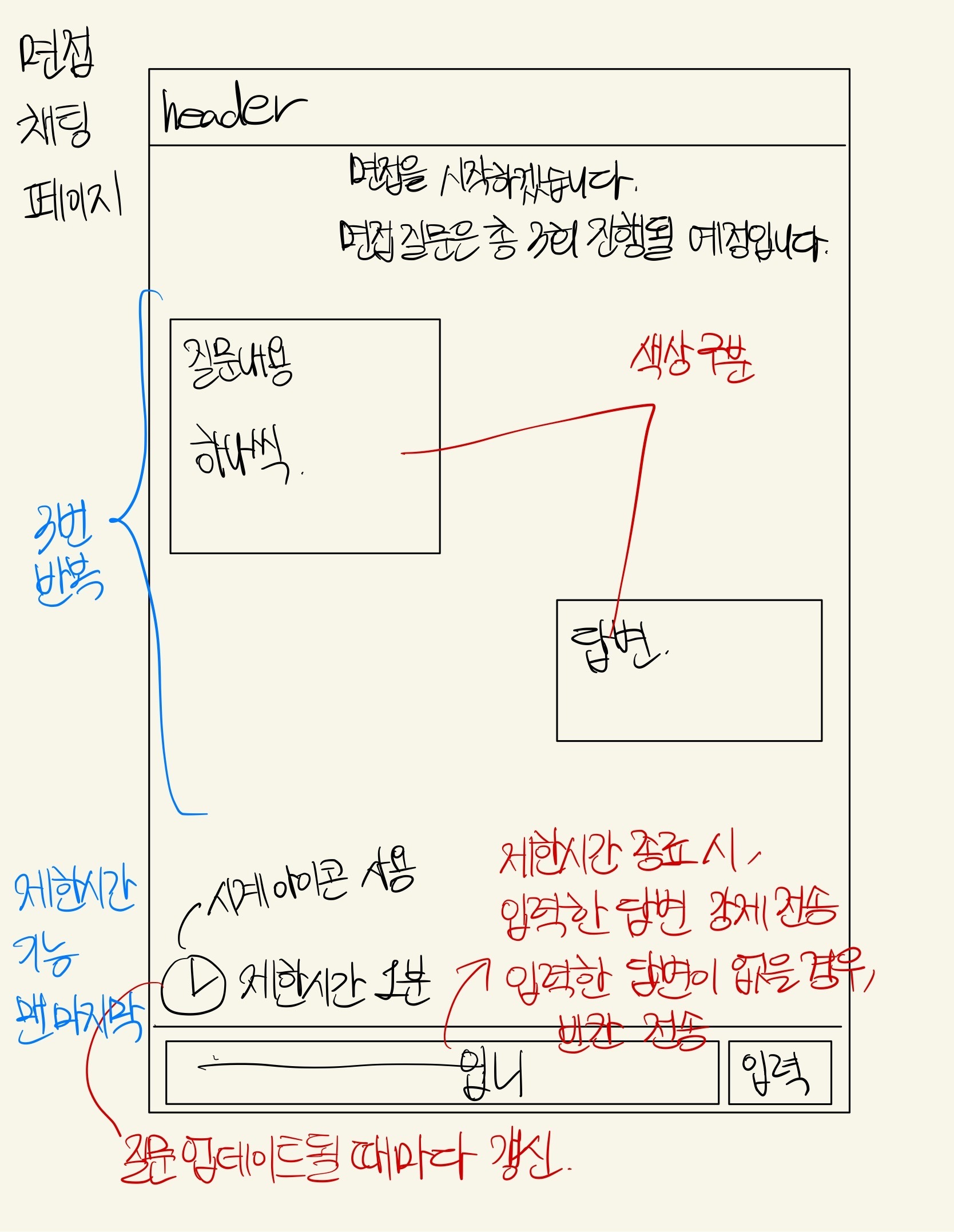
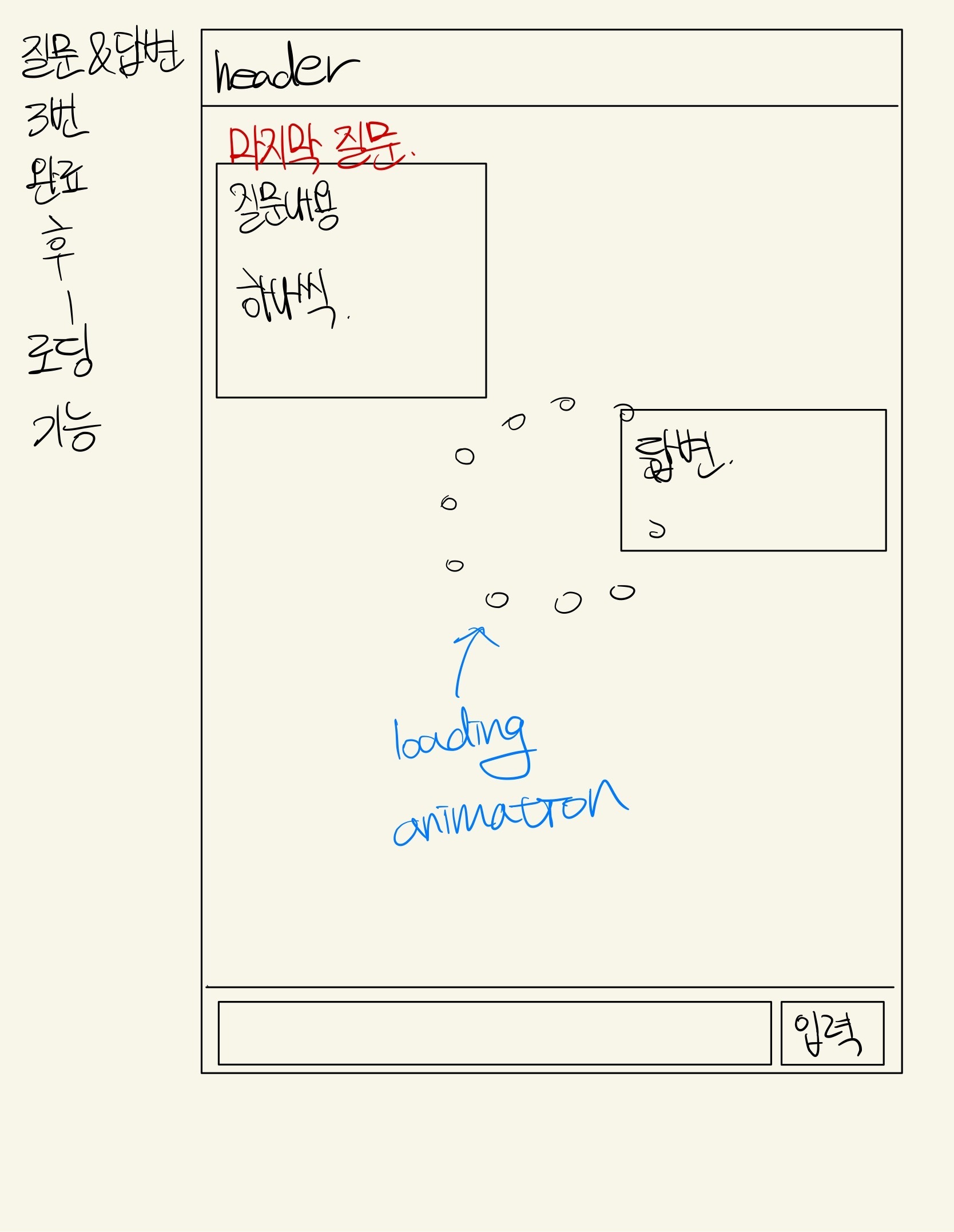
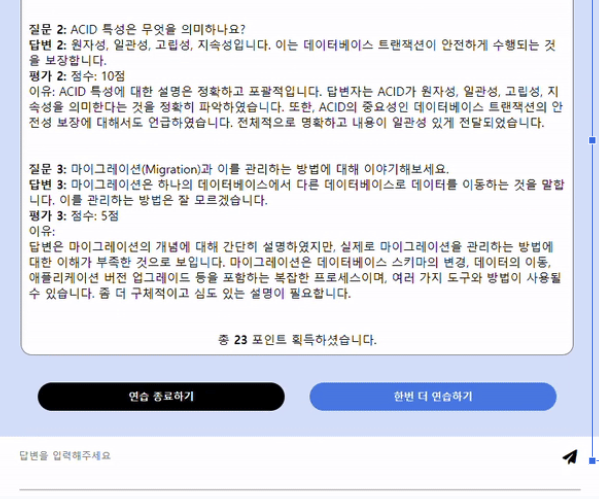
이후 선택한 주제에 대해 OpenAI API 를 활용하여 해당 주제에 맞는 면접 질문을 유저에게 보이고 유저의 답변에 대해 즉시 ChatGPT 에 사용되는 OpenAI API 로 피드백을 생성한다.
유저의 답변에 맞춰 한번의 면접 연습을 통해 총 30 포인트까지 획득할 수 있다.
각각의 답변에 대한 피드백을 생성하는데 5초에서 10초 혹은 그 이상 시간이 소요된다. 이 시간을 줄이기 어렵지만 UX 를 위해 중간에 gif 로 로딩동안 보여줄 화면을 구성했다.
사실 개인적으로 Webhook, Socket 을 활용한 슬랙봇으로 Admin 기능 구현과 OpenAI API 를 직접 다뤄보고 싶었는데 시간상 슬랙에 관한 부분만 담당하고 OpenAPI 까지 직접 만들기 어려워 OpenAPI 사용법에 대해서만 공유했던 점이 아쉬웠다. 그래서 아래에 어떻게 구체적으로 구현했는지 자세히 알아봤다.
구현
OpenAI API 를 사용하고자 한다면 OpenAI 에 계정 등록, 카드 등록을 해야 API Keys 라고 불리는 key 를 발급받을 수 있다. OpenAI API 를 실행하는데엔 이 key 만 있으면 된다.
아래 정리한 부분은 전적으로 팀원분이 작성해주신 코드를 읽고 어떻게 구현하셨는지 정리한 내용이다.

openai/docs 를 확인해보니 가장 최신 모델을 사용하고자 한다면 gpt-4, gpt-3.5-turbo 모델을 사용할 수 있으며 API ENDPOINT 는 https://api.openai.com/v1/chat/completions 이다. 그래서인지 코드를 다음과 같이 구성하셨던 것 같다.
// openAI api 호출하기
exports.callApi = async (req, res) => {
const { contentQ, contentA } = req.body;
const result = await axios.post(
"https://api.openai.com/v1/chat/completions",
{
model: "gpt-3.5-turbo",
messages: [
{
role: "system",
content: contentQ,
},
{
role: "user",
content: contentA,
},
],
max_tokens: 1024,
},
{
headers: {
Authorization: `Bearer ${env.OPENAI_APIKEY}`,
},
}
);
const apiRes = result.data.choices[0].message.content;
res.send({ apiRes });
};OpenAI Docs 를 좀 더 자세히 찾아봤다.
POST
https://api.openai.com/v1/chat/completions위의 API 는 주어진 채팅 대화에 대한 응답 모델을 생성한다.
그래서 앞에서 언급한 코드는 아래의 curl 코드를 참고하셨던 것 같다.
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'이 API 는 필수값으로 model 과 message 가 필요하다. 이전에 회의시 들었던 내용으로는 model 에 gpt-4 도 있지만 이미 gpt-3.5-turbo 를 쓰는 것으로도 지연시간이 몇초 걸리는데 gpt-4 는 더 오래 걸리기 때문에 gpt-3.5-turbo 를 사용하는 것으로 결정하셨다고 들었다.
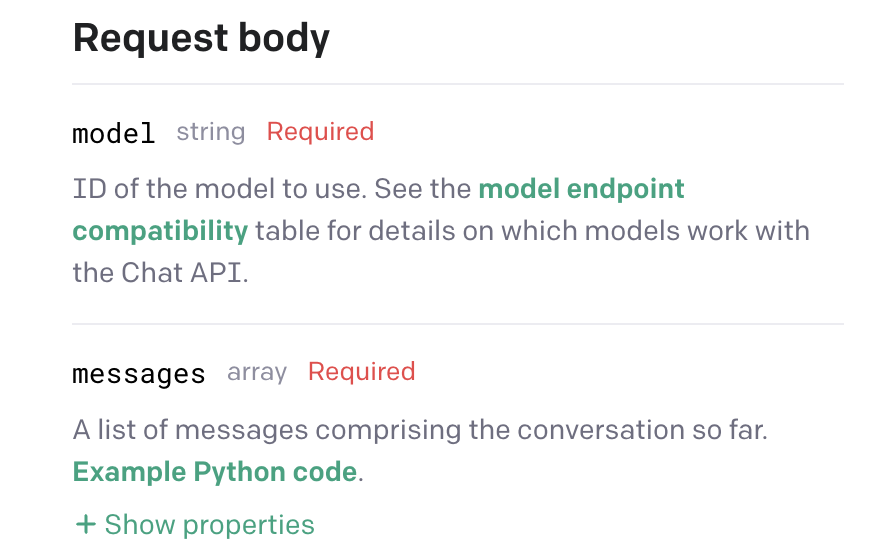

message 내에는 role, content 가 필수적으로 들어가야 한다. 이때 role 은 system, user, asistent 혹은 function 이 될 수 있다.
content 는 메세지의 내용이다. 모든 메세지에 content 는 필수적으로 필요하며 assistant 혹은 function 일때는 null 일수 있다.
name 은 role 이 function 일때 필요하며 function 의 이름이어야 한다.
이 경우 얻을 수 있는 응답의 형태는 다음과 같은 object 이다.
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"model": "gpt-3.5-turbo-0613",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "\n\nHello there, how may I assist you today?",
},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}프롬프트 엔지니어링을 활용하여 시스템에게는 면접관의 역할을 부여하고 답변의 형태를 고정시켰다.
그래서 작성된 코드는 아래와 같았다.
const contentQ = `당신은 신입 개발자를 채용하려는 면접관입니다. 질문은 다음과 같습니다. ${questionList[interviewCount]}`;
const contentA = `답변은 다음과 같습니다. ${answerList[interviewCount]} 이 답변에 대해 10점 만점으로 점수를 주고, 그 이유를 알려주세요. 점수는 응답의 첫 문장으로 '점수: 점'의 형태로 알려주세요.`;
// 답안 제출후 api 호출
const evaluation = await runApi(contentQ, contentA);async function runApi(contentQ, contentA) {
const res = await axios({
method: "POST",
url: "/interview/api",
data: {
contentQ,
contentA,
},
});
// api 응답값에 줄바꿈 문자('\n')가 있을 경우, 이를 <br/> 태그로 바꾸어 저장
const resStr = res.data.apiRes;
const resArr = resStr.split("\n");
let evaluation = "";
for (let i = 0; i < resArr.length; i++) {
if (resArr[i] !== "") {
evaluation += resArr[i];
evaluation += "<br/>";
}
}
// '점수: 점' 형태의 문자열에서 숫자를 제외한 나머지 문자를 제거하여 점수 parsing
const pointStr = resArr[0];
const regex = /[^0-9]/g;
const replaceResult = pointStr.replace(regex, "");
const currPoint = parseInt(replaceResult);
// 점수를 parsing하지 못한 경우, api 다시 호출
if (isNaN(currPoint)) {
const evalAgain = await runApi(contentQ, contentA);
return evalAgain;
}
// 포인트 저장
point += currPoint;
return evaluation;
}다시 한번 결과를 첨부하고자 한다. 위의 과정을 거쳐서 아래와 같은 훌륭한 형태의 결과물을 도출할 수 있었다.

협업이 이래서 좋은 것 같다. 팀원분들의 좋은 코드 스타일, 정리 방식등으로부터 리펙토링이라던지 더 읽기 좋은 코드에 대한 깊은 고민을 할 수 있게 해준다.
db 설계
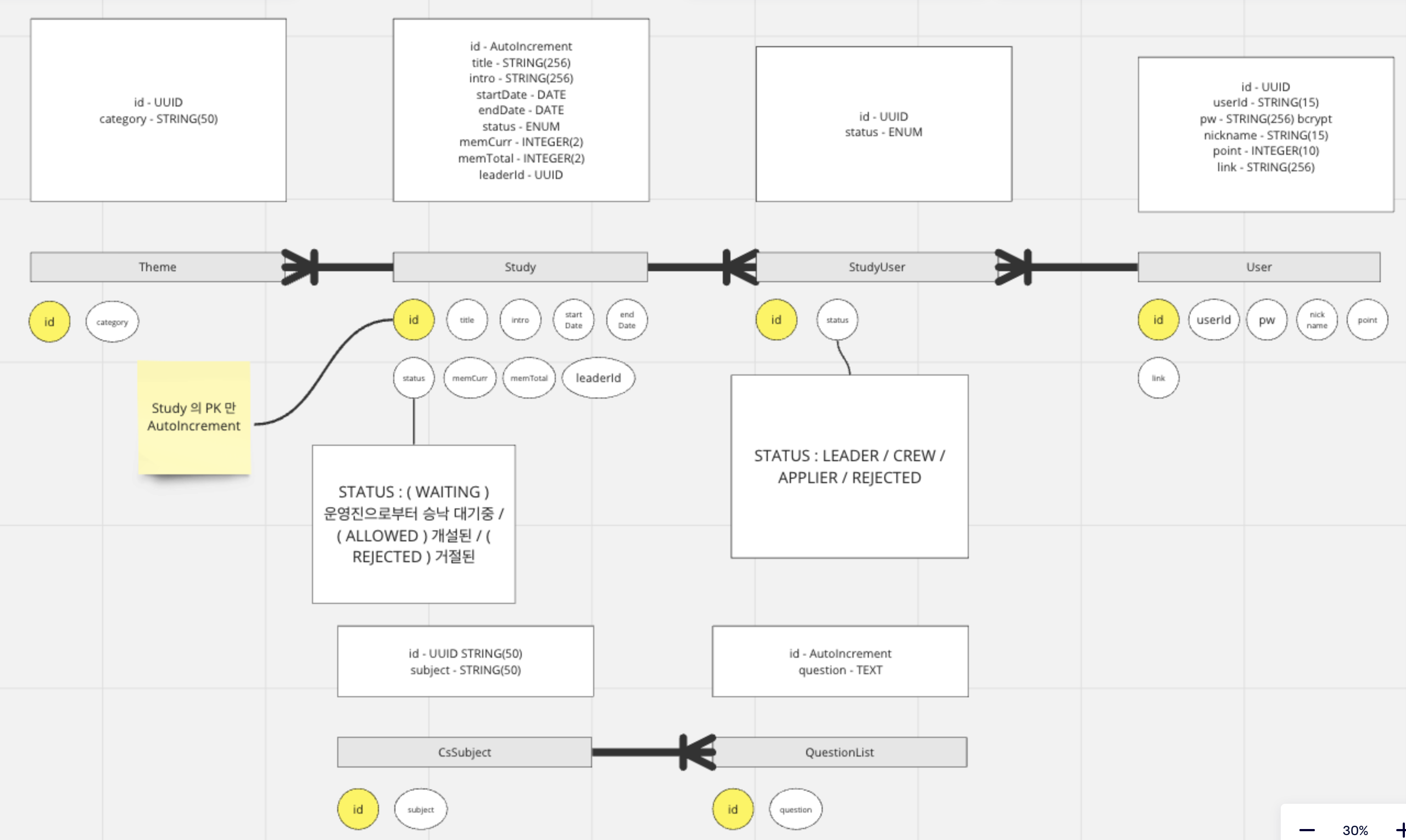
db 구조는 miro 를 통해 릴레이션의 어트리뷰트, 관계등을 논의후 바로 sequelize 를 사용하여 model 을 생성해줬다.
// models/index.js
"use strict";
const Sequelize = require("sequelize");
const env = process.env.NODE_ENV || "development";
const config = require(__dirname + "/../config/config.js")[env];
const db = {};
const sequelize = new Sequelize(
config.database,
config.username,
config.password,
config
);
/** model */
db.Study = require("./MStudy")(sequelize);
db.Theme = require("./MTheme")(sequelize);
db.User = require("./MUser")(sequelize);
db.QuestionList = require("./MQuestionList")(sequelize);
db.CsSubject = require("./MCsSubject")(sequelize);
db.StudyUser = require("./MStudyUser")(sequelize);
/** 관계형성 */
// 스터디-IT카테고리 1대다
db.Study.hasMany(db.Theme);
db.Theme.belongsTo(db.Study);
// Cs Subject - 질문 목록 1 : 다
db.CsSubject.hasMany(db.QuestionList);
db.QuestionList.belongsTo(db.CsSubject);
// 스터디-스터디유저 1대다 & 스터디유저-유저 다대1
db.Study.belongsToMany(db.User, { through: db.StudyUser });
db.User.belongsToMany(db.Study, { through: db.StudyUser });
db.Study.hasMany(db.StudyUser);
db.StudyUser.belongsTo(db.Study);
db.User.hasMany(db.StudyUser);
db.StudyUser.belongsTo(db.User);
db.sequelize = sequelize;
db.Sequelize = Sequelize;
module.exports = db;위의 구조에서 스터디와 유저는 n:m 관계이다. ( 한 스터디에 여러 유저가 참여할 수 있고 한 유저는 여러 스터디에 지원하거나 개설할 수 있다. )
이때 sequelize 에서는 3가지 방식으로 n:m 관계를 형성할 수 있다고 안내한다.
- 기본적으로 n:m 은 다음과 같이 구성한다.
const User = sequelize.define('user', {
username: DataTypes.STRING,
points: DataTypes.INTEGER
}, { timestamps: false });
const Profile = sequelize.define('profile', {
name: DataTypes.STRING
}, { timestamps: false });
User.belongsToMany(Profile, { through: 'User_Profiles' });
Profile.belongsToMany(User, { through: 'User_Profiles' });through 를 사용하면 Sequelize 는 중간 연결테이블인 User_Profiles 를 자동으로 생성해주고 User_Profiles 는 User 의 PK, Profile 의 PK 만 칼럼으로 갖는다.
그러나 미리 연결테이블인 User_Profiles 를 만들어둔다면 더 많은 칼럼을 지정해줄 수 있다.
n:m 은 일반적으로 연결하는 두 테이블의 PK 를 복합키 PK 로 갖는데 uniqueKey 를 지정하거나 primaryKey 를 설정하여 다른 테이블처럼 일반적인 PK 를 가질수도 있다.
User.belongsToMany(Profile, { through: User_Profiles, uniqueKey: 'my_custom_unique' });
// or
const User_Profile = sequelize.define('User_Profile', {
id: {
type: DataTypes.INTEGER,
primaryKey: true,
autoIncrement: true,
allowNull: false
},
selfGranted: DataTypes.BOOLEAN
}, { timestamps: false });
User.belongsToMany(Profile, { through: User_Profile });
Profile.belongsToMany(User, { through: User_Profile });2-1. super n:m 관계를 생성하는 방법으로 n:m 이나 앞에서 설명한 것처럼 연결테이블이 복합키가 아닌 단일 기본키를 갖도록 해야 한다.
const User = sequelize.define('user', {
username: DataTypes.STRING,
points: DataTypes.INTEGER
}, { timestamps: false });
const Profile = sequelize.define('profile', {
name: DataTypes.STRING
}, { timestamps: false });
const Grant = sequelize.define('grant', {
id: {
type: DataTypes.INTEGER,
primaryKey: true,
autoIncrement: true,
allowNull: false
},
selfGranted: DataTypes.BOOLEAN
}, { timestamps: false });
User.belongsToMany(Profile, { through: Grant });
Profile.belongsToMany(User, { through: Grant });2-2 super n:m 관계를 생성하는 두번째 방법으로 중간테이블을 생성하고 각각을 1:n 으로 연결하는 방식이다.
// Setup a One-to-Many relationship between User and Grant
User.hasMany(Grant);
Grant.belongsTo(User);
// Also setup a One-to-Many relationship between Profile and Grant
Profile.hasMany(Grant);
Grant.belongsTo(Profile);그런데 이 2-1, 2-2 방식은 include 를 통해 join 을 걸어줄때 문제가 있었다.
// With the Many-to-Many approach, you can do:
User.findAll({ include: Profile });
Profile.findAll({ include: User });
// However, you can't do:
User.findAll({ include: Grant });
Profile.findAll({ include: Grant });
Grant.findAll({ include: User });
Grant.findAll({ include: Profile });
// On the other hand, with the double One-to-Many approach, you can do:
User.findAll({ include: Grant });
Profile.findAll({ include: Grant });
Grant.findAll({ include: User });
Grant.findAll({ include: Profile });
// However, you can't do:
User.findAll({ include: Profile });
Profile.findAll({ include: User });
// Although you can emulate those with nested includes, as follows:
User.findAll({
include: {
model: Grant,
include: Profile
}
}); // This emulates the `User.findAll({ include: Profile })`, however
// the resulting object structure is a bit different. The original
// structure has the form `user.profiles[].grant`, while the emulated
// structure has the form `user.grants[].profiles[]`.
정리
- super n:m 중 n:m 으로 관계를 생성시, 중간테이블을 제외한 두 테이블간 join 은 가능하나 중간테이블이 끼어있으면 join 을 할 수 없다.
- super n:m 중 2개의 1:n 으로 관계를 생성시 중간테이블을 포함한 두 테이블간 join 은 가능하나 중간테이블이 없으면 join 을 할 수 없다.
- findeAll 에 nested 구조로 설정하면 그래도 join 이 가능한 모양인데 본래 구조와 다른 형태의 결과 객체를 얻을 수 있다.
그래서 이번 프로젝트에서 n:m 관계를 sequelize 에서 생성시엔 가장 괜찮은 형태의 super n:m 관계를 사용해줬다.
// The Super Many-to-Many relationship
User.belongsToMany(Profile, { through: Grant });
Profile.belongsToMany(User, { through: Grant });
User.hasMany(Grant);
Grant.belongsTo(User);
Profile.hasMany(Grant);
Grant.belongsTo(Profile);이 경우 아래처럼 중간테이블이 끼어있어도, 없어도 join 을 자유롭게 걸어줄 수 있다.
// All these work:
User.findAll({ include: Profile });
Profile.findAll({ include: User });
User.findAll({ include: Grant });
Profile.findAll({ include: Grant });
Grant.findAll({ include: User });
Grant.findAll({ include: Profile });db 설계 상단에 적어둔 models/index.js 코드를 다시 보면 왜 user 와 study 를 저런 방식으로 관계를 형성해뒀는지 이해가 될 것이다.
이 방식을 통해 쿼리를 통해 불러올 데이터를 세밀하게 조절할 수 있었다.
예를 들어 한 스터디에 신청한 유저를 승인할지 거절할지는 해당 유저의 정보는 관심이 없다. 그 유저의 PK 는 through 로 관계를 맺어둔 순간 중간테이블에 이미 갖고 있기 때문에 이 유저 PK 를 제외한 나머지 정보는 알 필요가 없어서 굳이 include 로 User 와 Study 를 맺어줄 필요가 없는 것이다.
PK
모든 PK 는 보안을 위해 autoincrement 가 아니라 UUID 로 생성하려 했다. 그런데 스터디 리스트중 특정 리스트를 조회하는 경우 params 로 특정 study id 를 UUID 로 전달하는 것이 너무 길고 복잡한 것 같아서 Study 의 PK 는 AutoIncrement 로 변경했다.
CS 면접 주제를 위한 CsSubject 와 질문 리스트를 위한 QuestionList 테이블을 만들었다. 처음엔 다른 테이블과의 관계가 없기도 하고 면접 질문과 대답의 쌍이 굉장히 많아지는 대용량 데이터가 필요로 될 경우 NoSQL인 redis 로 해도 좋을 것 같았는데 주제 - 질문 리스트의 관계가 있어서 그대로 RDBS 인 MySQL 을 사용했다.
flow chart 및 db 설계
발표에 앞서 이전 프로젝트때의 피드백중 work flow 를 먼저 알려주고 발표가 진행되면 더 기능을 잘 이해하기 쉬울 것 같다는 부분에 공감이 되어 miro 를 이용하여 flow chart 를 만들어 보았다. 엄밀하게 flow chart 가 지켜야 할 규칙을 모두 지키지는 못했으나 전체 흐름을 다같이 논의하면서도 다르게 이해했던 부분들이 발견되었고 이를 정리해보는 과정이 정말 필요했음을 알게 되었다.
좋은 개발문화를 위한 노력
Do IT 조와 함께하는 프로젝트는 좋은 개발문화가 무엇인지에 대한 고찰을 깊이 한후 시작하게 되었다. 그 과정에서 꼭 해보고 싶었던게 애자일 방법론과 RestFul 한 네이밍 컨벤션 따르기, 그리고 코드리뷰의 개발문화였다.
좋은 개발문화 - 스크럼과 스프린트 회고
애자일 방법론중 스크럼과 스프린트 회고를 이번 프로젝트때 도입해보았다.
스크럼중 데일리 스크럼이라는 것을 팀 문화에 적용해보았는데 매일 아침 30분 ~ 1시간동안 데일리 스크럼 회의를 진행하는데 각 스크럼 회의 페이지에는 각 인원별 전날 한일, 오늘 해야할일들을 정리해달라고 부탁드렸다.
팀원들은 미리 다른 팀원들이 어떤 작업들을 해왔고 어떤 작업을 할지 확인할 수 있으며 해온 일들, 해야할 일들에 대한 피드백을 노션의 댓글 기능을 통해 자유롭게 주고받을 수 있다.
적어도 팀원이 무슨 일을 하는지는 확실히 알아야 협업이라고 할 수 있으리라 생각했다.
그리고 2주간의 프로젝트인 만큼 1회의 스프린트를 1주일 기간으로 잡고 2회의 스프린트 회고를 생각해었다.
일주일간 진행한 개발문화에 대해 처음 도입하는 만큼 각 팀원들이 느끼는 바와 개선점, 부족했던 점을 알고 싶었다.
좋은 개발문화 - MVP 단위 작업방식
이러한 과정에서 Do IT 조는 워터풀 방식이 아닌 애자일 방식으로 유저로부터의 즉각적인 피드백을 받기는 어려워도 팀원들로부터의 피드백을 매일 데일리 스크럼때 받아 다음 작업에 반영을 할 수 있었고 모든 작업은 MVP 최소기능제품 단위로 진행했기에 MVP 가 끝날 때마다 서버에 deploy 하여 현재까지 최소한 돌아가는 기능들이 서버에서 정상적으로 작동하는지 각 MVP 가 main 에 merge 될 때마다 확인했다.
좋은 개발문화 - 코드리뷰
2주라고 해서 그렇게 까지 긴 기간은 아니다. 그래서 코드리뷰는 좋은 개발문화에 필수적이라고 생각했던 만큼 반드시 도입을 해보고 싶었으나 현실적으로 시간에 쫓기는 문제가 있었다. 그래서 절충안으로 당일 바로 다음 MVP 작업이 이어져야 하면 팀원들과 논의후 바로 merge 를 하고 그날 작업이 끝나서 merge 를 다음날 해도 되는 경우엔 PR 만 요청해 두고 다른 팀원들이 코드리뷰를 하는 방식이었다.
결과적으로 코드리뷰가 많은 부분에 적용되지는 못했다. 다만 코드리뷰라는 문화를 도입하기 시작했다는 것으로 다음 단계로 나갈 수 있을 것 같다.
좋은 개발문화 - Restful Naming Convention
마지막으로 좋은 개발문화를 형성하기 위해 url 을 Restful 하게 이름지어 사용하기를 원했다.
이전 포스트 Restful Naming Convention 에서 고민했던 것처럼 동작은 HTTP 메서드로 표현하고 대상은 명사형으로 나타내어 url 상에는 되도록 명사를 사용하고자 했다.
또한 단수보다는 복수를 사용하고 싶었는데 study, question 처럼 단수, 복수 구분이 애매한 경우 study 같은 형태를 갖거나 questionList 처럼 뒤에 list 를 붙이자고 논의했다.
// 변경전
router.get("/study/register", controller.getRegister);
router.post("/study/register", controller.postRegister);
// 변경후
// 특정 스터디 조회는 get, 특정 스터디 등록은 post 로 동작을 표현하는
// 것에는 HTTP 메서드로 충분할 것 같다는 이야기를 했다.
router.get("/study", controller.getRegister);
router.post("/study", controller.postRegister);
// 변경전
router.get("/list/:init", controller.getDetail);
// 변경후
// 계층적인 구조상 스터디 목록의 스터디 아이디를 가져와 특정 스터디를
// 조회한다는 의미가 적절할 것 같아 수정하자는 이야기를 했다.
router.get("/list/:studyid", controller.getDetail);그래서 위와 같이 등록하다 라는 동작이 url 에 들어가면 안될것 같아 스크럼 회의때 논의하였고 params 에 init 이든 studyid 든 상관없지만 의미상 studyid 가 더 적절할 것 같아 수정하자는 이야기를 나눴다.
단순한 네이밍 규칙이라고 생각할수도 있고 전체 기능의 흐름상 문제가 있는 것도 아니며 반드시 지켜야 하는 부분도 아니긴 하다. 그러나 이런 규칙들을 지킨다면 이해하기 쉽고 사용하기 쉬운 REST API 를 만드는데 큰 도움이 될 수 있다.
우리 Do IT 조는 이러한 부분도 고려하여 작업을 진행했다.
참고한 라이브러리
-
bolt.js : slackbot webAPI, eventAPI 등을 통합한 라이브러리로 socketMode 와 action 을 통한 양방향 통신을 위해 해당 라이브러리를 사용했다.
-
sweetAlert2 : js 의 기본적인 alert, confirm 대신 더 나은 애니메이션을 제공하는 라이브러리

이슈
슬랙봇 불확실한 동작 문제
슬랙이 가장 마지막으로 머지했을때는 정상적으로 작동하는데 이후 전체 프로젝트에 변동사항이 생겨 새로 git pull 을 받는 상황이 발생하면 이전 version 의 슬랙봇 관련 코드가 살아남아서 SocketMode 로 슬랙과 애플리케이션이 통신을 하고 싶은데 어떤 경우엔 이전 버전의 코드가 action 을 받아서 실행하고 어떤 경우엔 최신 버전의 코드가 action 을 받아 원하는 동작을 실행했다.
이 부분은 추후 직접적인 원인을 찾아봐야 할 것 같다. ( 시간상 원인을 확인하지 못했고 전체 슬랙봇, 채널을 새로 생성하는 식으로 대처했다... )
그래서 이 부분에서 TDD 내지는 테스트 코드의 중요성이 너무 크게 느껴졌다. 2주라 지난 프로젝트보다 기한이 길었지만 조금씩 테스트코드 작성을 시도해보면서 내 코드의 정확도, 안정성에 대해 확신을 가질 근거를 만들어나가자.
OpenAI API 지연시간
ChatGPT 에도 질문을 하면 답변을 하는데까지 어느정도 시간이 소요되는 것처럼 이 플랫폼에서 OpenAI API 를 활용하니 매 피드백마다 5 ~ 10 초 정도의 지연시간이 나타났다. 그래서 피드백을 생성하는 동안 로딩화면을 도입하고 매 질문마다 피드백 내용을 생성해서 최종 결과물을 보여줄때 한번에 많은 양을 생성할 필요 없이 UX 에 불편함을 줄이고자 더 나은 방법에 대해 논의했다.
ec2 서버 접속 지연 문제
이전 프로젝트때 경험했던 바와 같은 문제라 먼저 ec2 를 중지후 재시작하여 다시 접속할 수 있도록 하고 그 이후에 swap 메모리를 설정해줬다.
현재 프리티어라 1GB 용량을 사용중인데 평소에 안쓰는 메모리를 swap 메모리에 저장해두고 바쁠때 해당 메모리를 가져다 쓰는 방식이다.
ec2 에 접속하여 free 명령어로 현재 사용중인 실제 메모리인 Mem 와 보조 저장소인 Swap 메모리를 확인할 수 있다.

이후 2GB 의 swap file 을 생성하고
$ sudo dd if=/dev/zero of=/swapfile bs=128M count=16
스왑 파일의 읽기, 쓰기 권한을 업데이트한 뒤
sudo chmod 600 /swapfile리눅스 스왑 영역을 설정했다.
sudo mkswap /swapfile
스왑 공간에 스왑 파일을 추가하여 즉시 사용하고
sudo swapon /swapfile프로시저의 상태를 확인했다.
sudo swapon -s
마지막으로 vi 편집기로 다음 파일을 열고 이어 명시한 내용을 추가했다.
sudo vi /etc/fstab
/swapfile swap swap defaults 0 0
:wq해결한 결과

현재 실행중인 메모리의 2배 용량이 Swap 메모리로 설정되었다. 이로써 갑자기 ec2 가 느려지거나 먹통이 되는 문제를 다소 해결할 수 있었다.
반응형을 위해 resize 시 로그인 / 회원가입 모달이 자꾸 뜨는 문제 발생

본래 헤더의 로그인 버튼을 클릭해야 로그인 모달이 뜨도록 코드를 구성했었다.
그러고 로그인 모달을 켰을때 resize 시 반응형을 위해 웹에서만 로그인 애니메이션을 구현하고자 display 를 none 에서 모바일은 block, 웹은 flex 로 바꾸는 식의 코드를 구성했다.
// 모달이 켜져있을때 화면크기를 조정시 display 조정
window.addEventListener("resize", function () {
let windowWidth = window.innerWidth;
let isMobile = windowWidth < 768;
let modals = document.querySelectorAll(".modal");
modals.forEach(function (modal) {
// 모달이 켜져있을때 모바일이면 block, 웹이면 flex
if (modal.style.display !== "none")
modal.style.display = isMobile ? "block" : "flex";
});
});그런데 알고보니 기본적으로 display 속성이 정해져 있지 않아서 기본적인 modal 의 style 에 display 가 없었다. 그래서 resize 이벤트 발생시 로그인 버튼을 클릭하지도 않았는데 모달이 자꾸 뜨는 이슈가 발생했었다. 이에 대해선 로그인 모달을 켜야만 모바일일때 block, 웹일때 flex 상태가 되니 resize 이벤트가 발생하고 display 가 none 이 아닌 상태로 존재하면 화면의 width 에 따라 모바일용 모달 혹은 웹용 모달을 띄워줄 수 있도록 했다.
// 모달이 켜져있을때 화면크기를 조정시 display 조정
window.addEventListener("resize", function () {
let windowWidth = window.innerWidth;
let isMobile = windowWidth < 768;
let modals = document.querySelectorAll(".modal");
modals.forEach(function (modal) {
// 모달이 켜져있을때 모바일이면 block, 웹이면 flex
if (modal.style.display && modal.style.display !== "none")
modal.style.display = isMobile ? "block" : "flex";
});
});후기

지금까지 진행했던 팀 프로젝트중 가장 협업다운 협업을 할 수 있어서 정말 좋았다. 모든 팀원들이 각자의 의견을 내면 서로 수용하는 속도가 빠르고 더 나은 아이디어에 대한 날카로운 피드백을 주고받아 더 나은 결과를 낼 수 있었던 것 같다.
깃 관리도 매우 마음에 들었다. 나중에 가서는 조급한 마음에 제대로 rebase 가 되지 않는 문제가 있었지만 이정도면 대체로 잘 관리가 된 편이다.
스크럼과 스프린트 회고도 마음에 든다. 이번 프로젝트는 실무에서의 업무와 거의 유사한 절차로 이루어졌다.
디자인도 핸드폰으로 직접 결과물을 확인해보니 더 이쁜 것 같았다.
코드리뷰도 자주 하지는 못했지만 첫 걸음을 시작했으니 이후 프로젝트들에선 더 괜찮은 형태로 코드리뷰하는 개발문화를 형성할 수 있을 것 같다. 그런 의미에서 다음 프로젝트가 개인 프로젝트로 이루어진다면 혼자서 하는 것과 큰 차이가 없을텐데 다소 아쉬운 느낌이 든다..
테스트코드를 작성하지 못했던 부분이 아쉽다. 전체 일정을 고려하여 개발 일정을 잡고 QA 까지 진행했는데 슬랙봇 불안정 문제가 너무 늦게 확인되어 다소 당황스러웠다. 이런 문제들이 전체 개발일정에 큰 영향을 끼치니 정말 정말 테스트 코드를 짤 필요성이 크게 느껴진다. Vitest 로 계속 하거나 문서가 적다면 Jest 로 테스트코드를 작성하는 습관을 형성해보자.
orm 도 지금까지 golang 을 사용하는 gorm, typescript 를 사용하는 typeorm 만 써봤는데 이번에 javascript 를 사용한 sequelize 를 처음써밨는데 다른 orm 들과 흐름이 거의 유사해서 활용하는데 큰 어려움이 없던 것 같다. 개인적으로는 typeorm 보다 docs 가 좀더 자세히 설명되어 있는 것 같아 좋았다.
이번엔 더 나은 개발문화를 형성하는 방법, 협업다운 협업, 만들어보고 싶었던 서비스를 구현, express 와 bolt.js 활용한 슬랙봇과 웹훅, 그리고 매력적인 로그인 애니메이션을 만들어 볼 수 있었다.
중간중간 나도 모르게 배려가 부족한 말하기를 할까봐 말하는 방식에도 주의를 기울였다. 그런 편인데 되도록 노력했던 게 이번의 모습이었다. velog 읽기 목록에도 추가해뒀지만 함께하고 일하고 싶은 사람이라는 글을 써주신 분께 정말 감사하다. 모든 내용이 정말 공감이 되고 바람직한 동료의 모습을 소개하고 있었기 때문이다.
