
MVP부터 본격적인 트래픽 대응까지,
클릭랩은 단계별로 인프라 아키텍처를 개선해왔다.
Phase 0: MVP 아키텍처
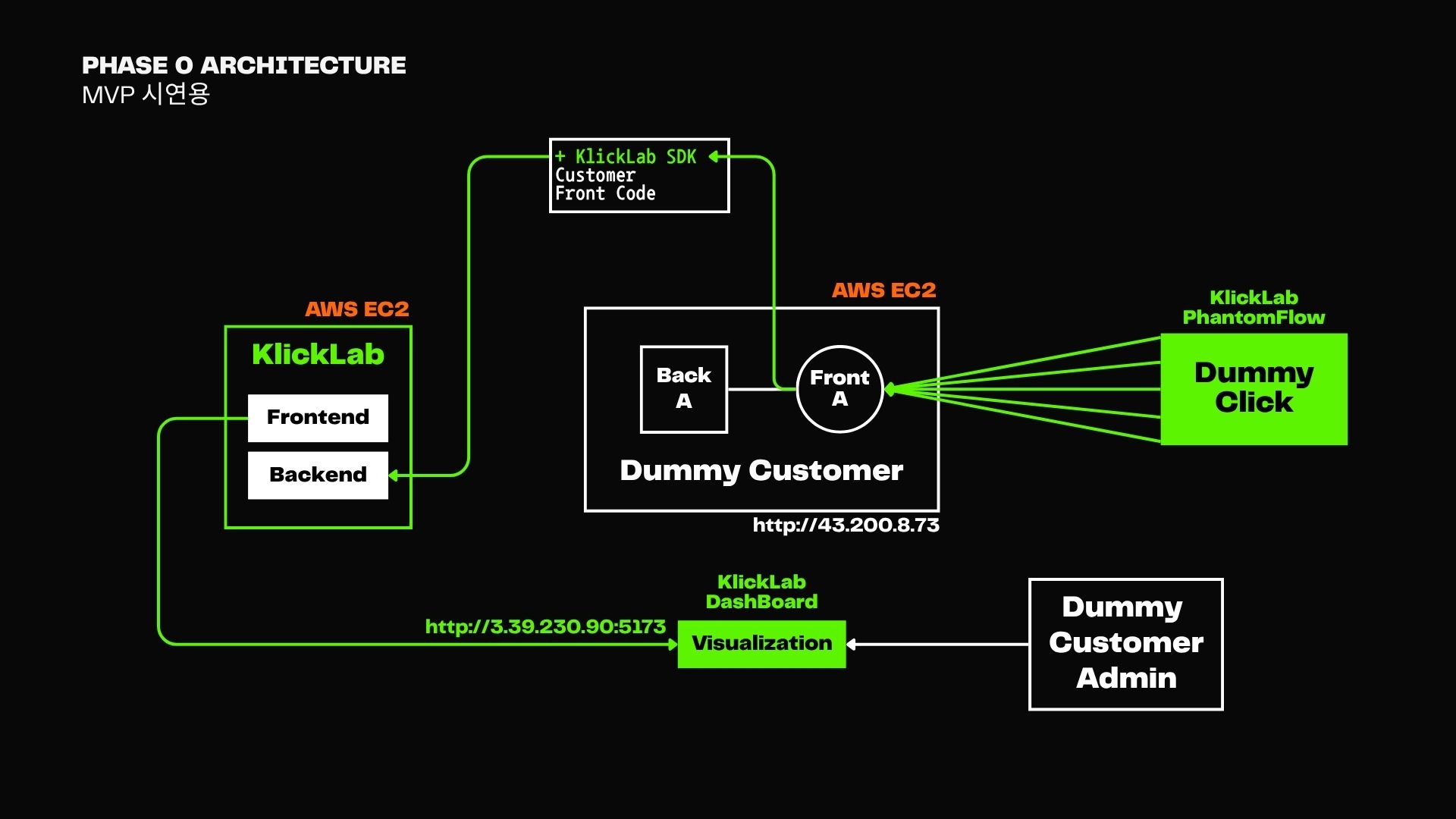
MVP에서는 단일 EC2 인스턴스에 프론트와 백엔드를 구성하고,
Dummy Customer의 Front에서 SDK를 통해 이벤트를 발생시키는 구조로 시작했다.
- 클릭 이벤트는
KlickLab Backend로 수집되고 - 대시보드(Visualization)는 수동 연결로 구성
- 트래픽 시뮬레이션은
PhantomFlow를 통해 수행
Phase 0.5: 향후 아키텍처 구상
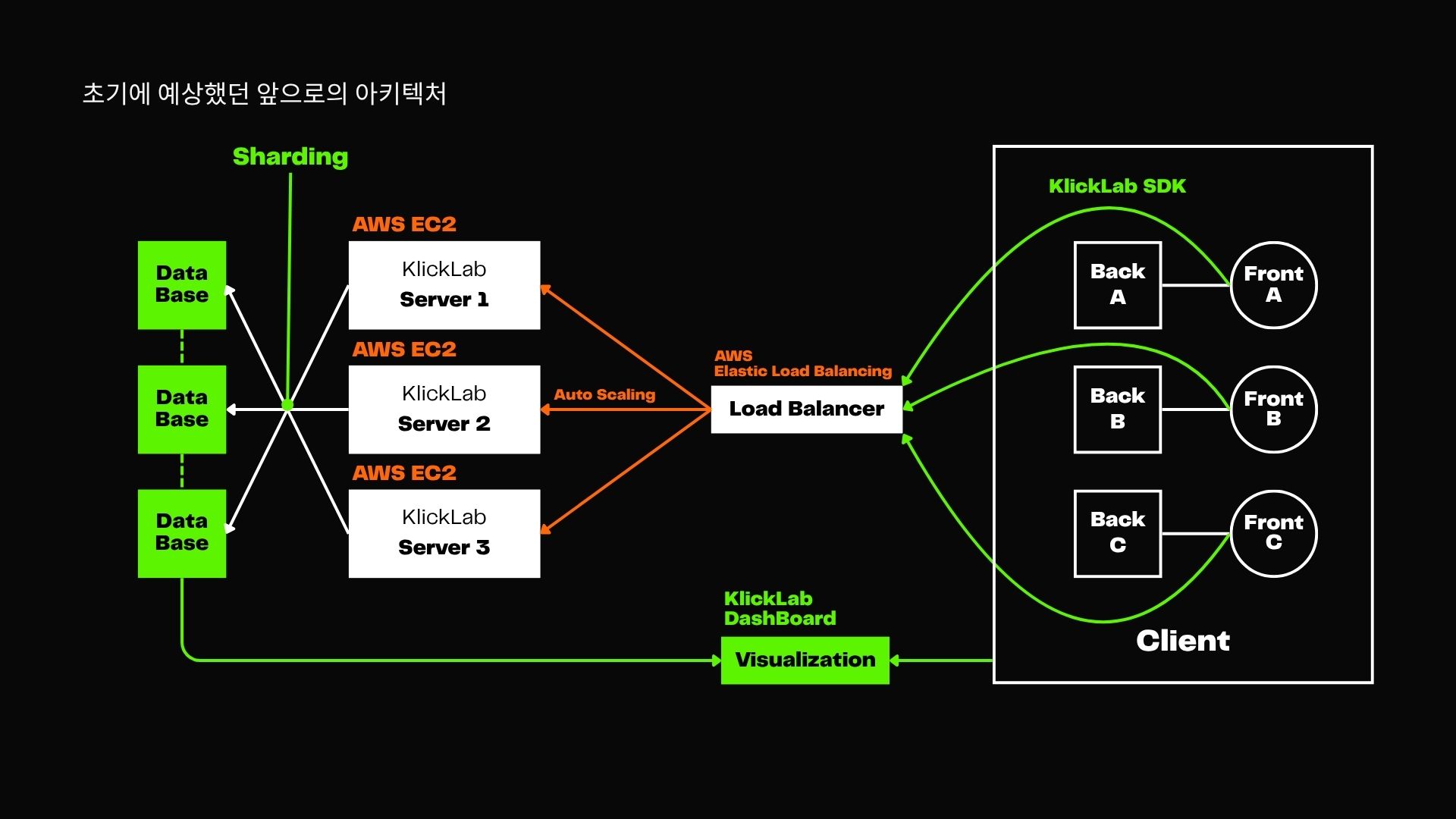
초기 구상은 다음을 목표로 했다:
- AWS EC2 기반 서버 다중 구성
- 로드밸런서 도입을 통한 자동 확장 (Auto Scaling)
- Database 수평 분산 (Sharding)
- 각 고객사 SDK 요청 처리 분산화
하지만 너무나 빈약한 설계였고, 대대적인 수정이 이루어진다.
Phase 1: 10K RPS 목표
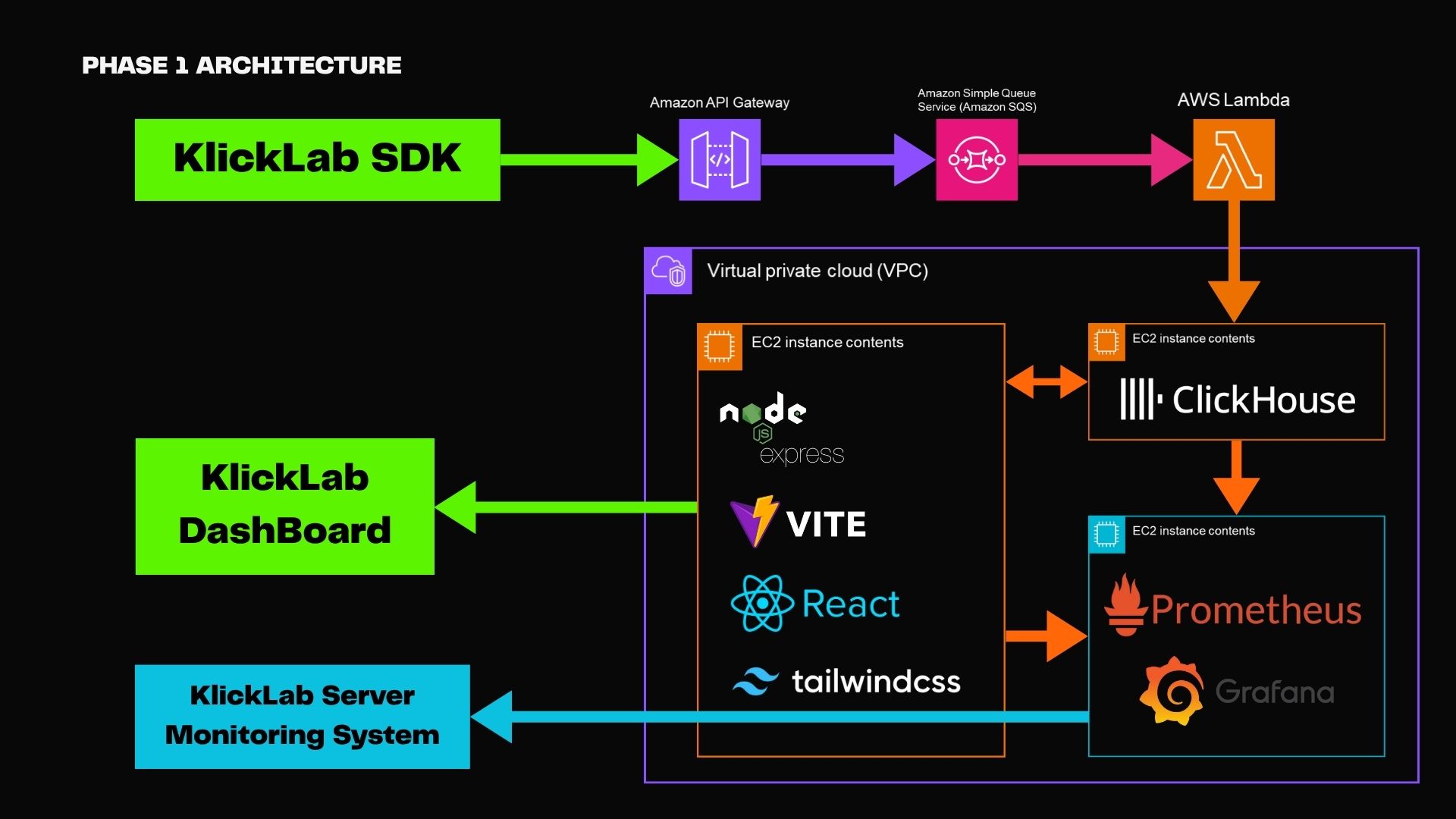
구조 개요
- KlickLab SDK → AWS API Gateway → AWS SQS → AWS Lambda → ClickHouse
- 대시보드는 ClickHouse로부터 직접 데이터 조회
- Prometheus + Grafana를 통한 서버 모니터링
API Gateway 문제점
- 내장 스로틀링 한도(RPS 제한): 리전당 약 10,000 RPS → 초과 시 429 발생 → 데이터 유실
- 불필요한 기능 오버헤드: 인증, 라우팅, 변환 등 클릭스트림 처리에는 과한 기능 → 지연 발생
개선 방향: NLB + EC2 구조
- Layer 4 처리로 오버헤드 최소화 (TCP 헤더만 보고 전달)
- EC2 Auto Scaling으로 트래픽 증가 대응
- 실제 성능: 10,000 RPS에서 수신율 99.3% 확보
Phase 1: SQS 문제점
문제점
- Standard SQS는 순서 보장 불가
- 데이터 리플레이 불가능 → 장애 발생 시 데이터 복구 불가
개선 방향: AWS MSK (Managed Kafka)
- 이벤트 순서 보장
- 리플레이 지원 → 장애 시에도 안정적으로 재처리 가능
ClickHouse 단일 노드 문제
- 쓰기 Merge 작업과 읽기 쿼리가 동시에 실행되며 자원 충돌
- Merge 작업이 CPU와 디스크 I/O를 과점
- 결과적으로 읽기 쿼리의 p95 Latency가 상승
Phase 2: 50K RPS 목표
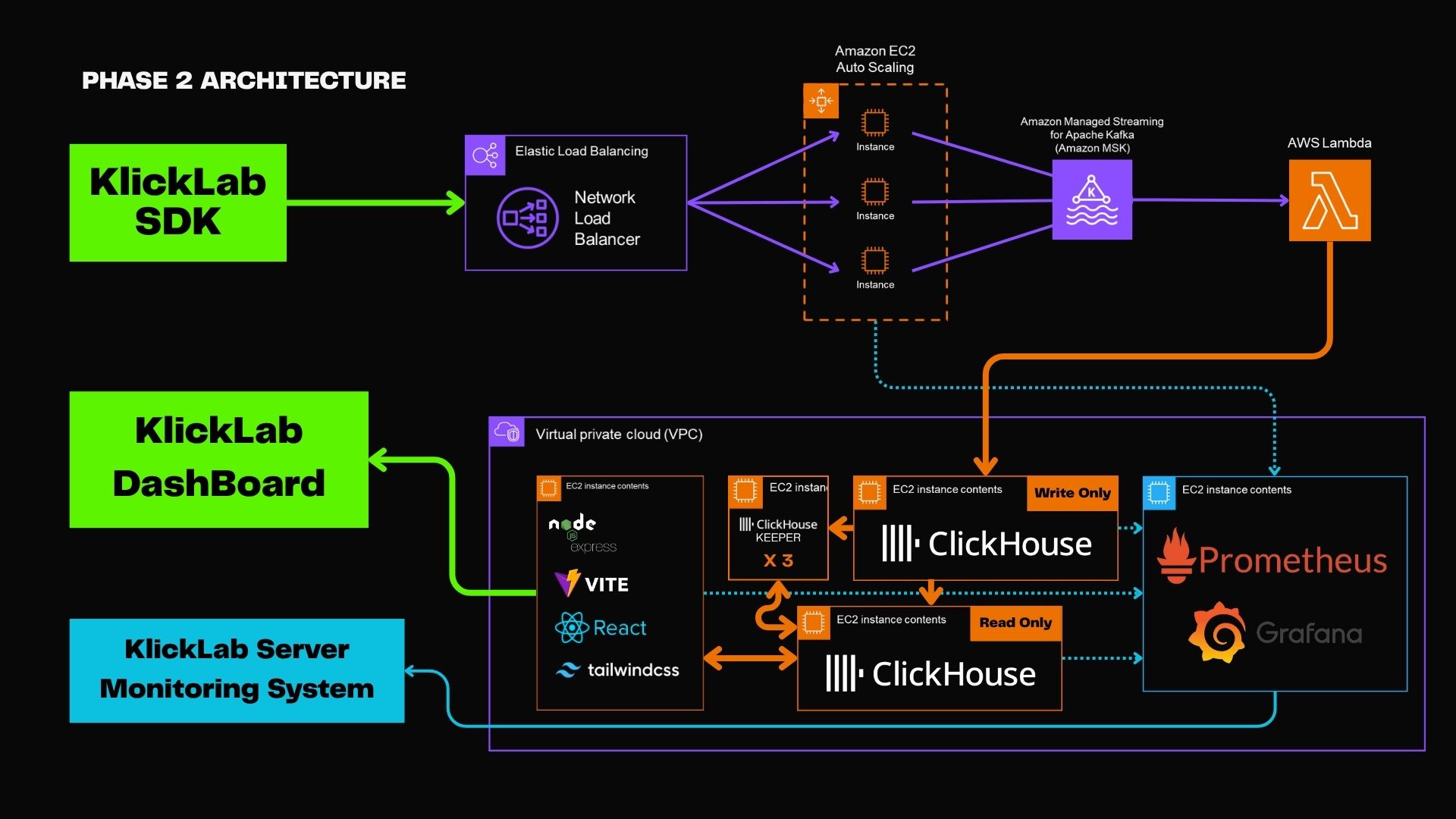
개선점
- ClickHouse 인스턴스를 읽기(Read Only) / 쓰기(Write Only)로 분리
- Merge 작업과 SELECT 쿼리의 간섭 제거
- 파이프라인 확장 기반 마련 → Kafka 기반 병렬성 확보
- 실제 대시보드 응답 속도 향상, 집계 안정성 확보

서툴지언정 늘 행동이 먼저이기를