Catboost
앙상블?
- Bagging : bootstrap+aggregation의 약자
parallel하게 샘플을 추출하여 학습.
Votion, 독립된 모델들- Boosting
Sequential ensemble
모델의 결과가 다른 모델의 input으로 들어감.
Bagging보다 성능이 좋지만 연산량이 많아 속도가 굉장히 느림.
속도 개선 로직 중요.
Catboost
속도 개선 로직과 정규화 방법을 보유한 Boosting류 모델이다.
기존 boosting 모델의 문제점을 개선한 CatBoost
동일한 Data Point 집합에 대해 이미 훈련된 모델을 사용하여 각 데이터 포인트의 잔차를 계산하기 때문에 과적합되기 쉽다.
하지만 Catboost는 학습데이터의 일부만으로 잔차계산을 한 뒤, 이 결과로 모델을 다시 만들어 과적합 문제를 해결하였다.
또한 기존 GBM 계열 알고리즘인 XGBoost, LightGBM보다 학습 속도를 개선하는 동시에 Hyper-parameter에 따라 성능이 달라지는 문제를 해결하는 것에도 초점을 맞추었다.
Tree 구조
유명한 Boosting계열 모델 중, XGBoost와 트리를 boosting해나가는 방향이 같다.
LightGBM은 leaf-wise(밑으로 확장하는 방식)으로, 알고리즘 종류 중 DFS(깊이 우선 탐색)처럼 트리틑 우선적으로 깊게 형성하는 방식을 취한다. 반면에 XGBoost는 level-wise(옆으로 확장하는 방식) 즉 BFS(너비 우선 탐색)처럼 우선적으로 넓게 트리를 형성한다.
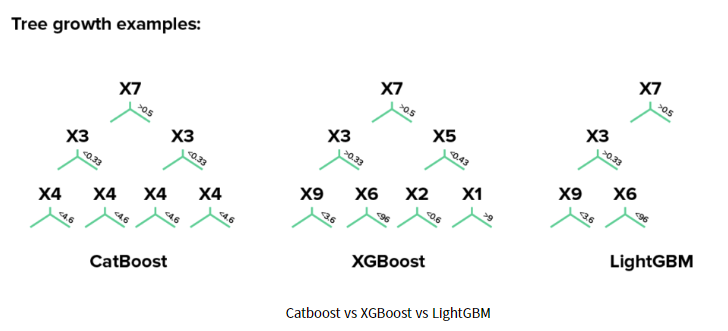
XGBoost와 CatBoost는 모두 level-wise 형식이므로 비슷해 보이지만 CatBoost는 그림과 같이 대칭적인 트리 구조를 형성한다.
대칭 트리 형성 구조는 예측 시간을 감소시킴으로써 기존 Boosting 계열 알고리즘의 느린 학습 속도 문제를 개선하였다.
Catboost라는 이름은 Cat+boost로 Cat, Category 즉 범주형 변수가 많은 데이터를 학습할 때 성능이 좋다.
수치형 변수는 다른 일반 트리 모델과 동일하게 처리한다. 분기가 발생하면 Gain, 즉 정보의 획득량이 높은 방향대로 나뉘게 된다. 수치형 변수가 많게 되면 lightGBM 모델처럼 시간이 오래 걸린다. 따라서 범주형 변수가 많을 때 이 모델을 사용하는 것이 좋다. 또, Sparse한 matrix는 적용하기 어렵다.
CatBoost 절차
Catboost는 시계열 데이터를 효율적으로 처리하는 것으로 알려져있다.
아래와 같이 데이터 세트에 10개의 Data Point가 있고 시간순으로 정렬되어 있다고 가정해 보자.
(데이터에 시간이 없으면 CatBoost는 각 Data Point에 대해 인위적인 시간을 무작위로 생성)
-> 순서가 있는 부스팅이라고 하여 Ordered Boosting이라고 불린다.
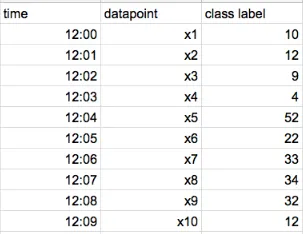
- step 1 : CatBoost가 x5에 대한 잔차를 계산하기 위해 x1, x2, x3, x4 데이터를 활용하여 학습시켜 모델을 만든다.
- Step 2 : 학습한 모델로 x6에 대해 class label을 예측.
- Step 3 : Step 1~2번 반복
CatBoost는 주어진 전체 데이터를 임의적으로 N개의 Fold로 나누어 각 Fold에 속한 데이터셋들에 Ordered Boosting을 적용한다. (K-fold Cross Validation과 비슷하다.). 예를 들어 100개의 데이터가 존재할 때, 4개의 Fold로 나누기로 했다면 주어진 데이터셋을 25개씩 나누고 각 25개의 데이터셋 마다 Ordered Boosting을 적용한다.
-> 이러한 방식이 부스팅 계열 알고리즘의 단점인 과적합 문제를 예방하는 데 도움이 된다.
CatBoost는 속도가 매우 빨라 실제 상용화되고 있는 서비스에 예측 기능을 삽입하고자 할 때 효과적이다. 실제로 XGBoost보다 예측 속도가 8배 정도 빠르다.
imbalanced dataset도 class_weight 파라미터 조정을 통해 예측력을 높일 수 있다.
그 외 Catboost는 오버피팅을 피하기 위해 내부적으로 여러 방법(random permutation, overfitting detector)을 갖추고 있어 속도 뿐만 아니라 예측력도 굉장히 높다.
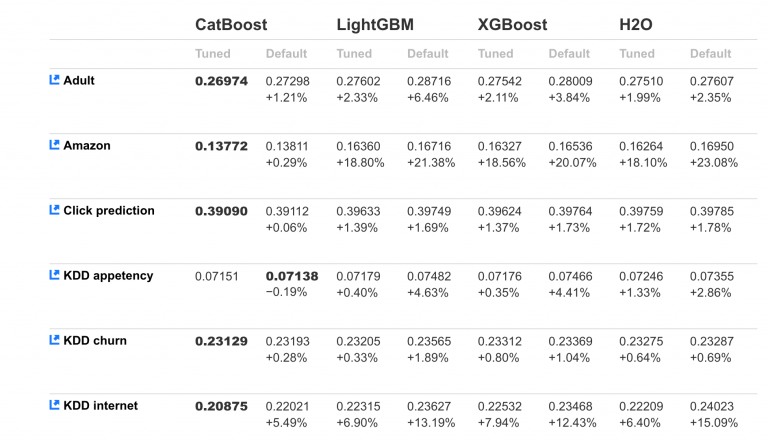
아래 그림은 대표적인 public ML dataset의 테스트 데이터셋으로 log-loss를 계산한 값이다. 보다시피 Catboost 모델이 가장 낮은 값을 보이고 있다.
시계열 데이터로 진행할 경우 has_time = True로 파라미터를 셋팅해주어야 ordered boosting시에 임의로 정한 시간대로 random permutation을 하지 않는다.
Catboost Python official docs
https://catboost.ai/en/docs/concepts/python-quickstart
CatBoostClassifier 사용
import numpy as np
from catboost import CatBoostClassifier, Pool
# initialize data
train_data = np.random.randint(0,
100,
size=(100, 10))
train_labels = np.random.randint(0,
2,
size=(100))
test_data = catboost_pool = Pool(train_data,
train_labels)
model = CatBoostClassifier(iterations=2,
depth=2,
learning_rate=1,
loss_function='Logloss',
verbose=True)
# train the model
model.fit(train_data, train_labels)
# make the prediction using the resulting model
preds_class = model.predict(test_data)
preds_proba = model.predict_proba(test_data)
print("class = ", preds_class)
print("proba = ", preds_proba)Classifier, Regressor구분 없이 아래와 같이 .predict()함수를 통해서도 구분 가능
import numpy as np
from catboost import CatBoost, Pool
# read the dataset
train_data = np.random.randint(0,
100,
size=(100, 10))
train_labels = np.random.randint(0,
2,
size=(100))
test_data = np.random.randint(0,
100,
size=(50, 10))
train_pool = Pool(train_data,
train_labels)
test_pool = Pool(test_data)
# specify training parameters via map
param = {'iterations':5}
model = CatBoost(param)
#train the model
model.fit(train_pool)
# make the prediction using the resulting model
preds_class = model.predict(test_pool, prediction_type='Class')
preds_proba = model.predict(test_pool, prediction_type='Probability')
preds_raw_vals = model.predict(test_pool, prediction_type='RawFormulaVal')
print("Class", preds_class)
print("Proba", preds_proba)
print("Raw", preds_raw_vals)참고
Catboost 모델에 대하여 - 알고리즘, 구현 코드
https://julie-tech.tistory.com/119
https://techblog-history-younghunjo1.tistory.com/199
