Session Clustering 방식의 문제점
지난번 Scale out 방식을 선택하고 세션 불일치 문제점을 해결할 수 있는 방안으로 Session Clustering 기술을 살펴보았습니다.
그러나 Session Clustering은 늘어나는 서버의 갯수만큼 세션 정보를 복제 해야 하기 때문에 서버를 추가함에 대한 부하가 발생합니다. 즉 성능 확장에 한계가 발생할 수 있습니다.
따라서 세션 데이터 저장을 목적으로 하는 인메모리 데이터 저장소를 사용하기로 하였습니다.
별도의 데이터 저장소에 세션을 저장하는 경우 서버들간의 세션 데이터를 교환할 필요가 없습니다.
세션 데이터는 비즈니스 핵심 로직과 관련된 데이터는 아니기 때문에 인메모리 데이터베이스를 사용하기로 하였습니다.
데이터가 메모리에 저장되기 때문에 디스크 기반의 데이터베이스보다 빠르다는 장점이 있습니다.
Session
저장 대상인 세션 객체는 아래와 같은 구조를 갖는 Map입니다.
JSESSIONID로 사용자를 구분합니다.
Map<JSESSIONID, Map<AttributeKey, Value>>
Memcached vs Redis 장단점 비교
Memcached와 Redis는 Key-Value 저장방식 인메모리 기반의 데이터 베이스로 세션 데이터를 저장하기에 적합합니다.
Redis, Memcached의 장단점은 아래와 같습니다.
| 장점 | 단점 | |
|---|---|---|
| Redis | List, Set, Hash 등 다양한 데이터 타입을 사용할 수 있다. 특정 시점에 데이터를 디스크에 저장하여 장애상황시 복구에 사용할 수 있다. | 싱글 스레드 기반으로 동작하기 때문에 한번에 한개의 명령만 실행할 수 있다. |
| Memcached | 내부 관리가 복잡하지 않다. 멀티 스레드를 지원하기 때문에 멀티 코어를 사용할 수 있다. | string 데이터 타입만 사용할 수 있다. 데이터 영속성을 위한 기능을 지원하지 않는다. |
Redis 사용하기로 결정
세션 데이터는 쓰기보다 읽기 작업이 빈번히 수행됩니다.
Memcached에 비해 읽기 성능이 좋은 Redis를 사용하기로 하였습니다.

프로젝트에 Redis 적용해보기
Spring Session - Spring Boot1
(1) Redis 설치
https://redis.io/download
(2) 프로젝트에 dependency 추가
build.gradle
implementation group: 'org.springframework.session', name: 'spring-session-data-redis', version: '2.3.2.RELEASE'
implementation group: 'org.springframework.boot', name: 'spring-boot-starter-data-redis', version: '2.3.9.RELEASE'(3) @EnableRedisHttpSession 애노테이션 추가
@SpringBootApplication
@EnableRedisHttpSession
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}(4) Redis 서버 실행
redis-server.exe
(5) Session에 데이터 저장
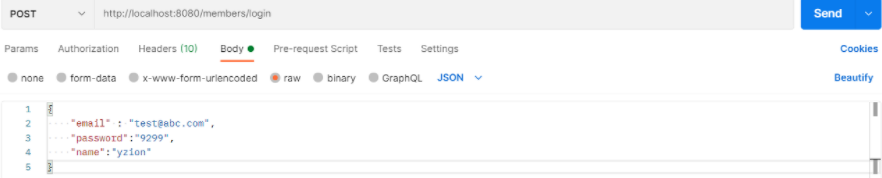
(6) Redis에 저장된 Session 객체 확인
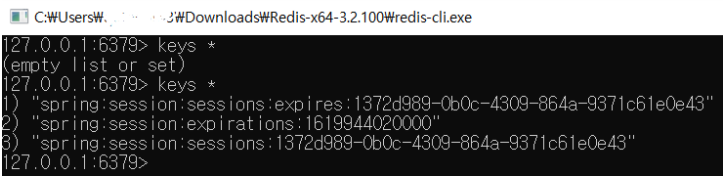
➕ Hash 관련 명령어에 대해 간략히 알아보도록 하겠습니다
(1) hkeys key : key에 저장된 모든 필드명을 가져온다.

(2) hget key field : key filed에 저장된 값을 불러온다.

(3) hvals key : key에 저장된 모든 값을 가져온다

Redis Replication(복제)
WAS 뿐만 아니라 데이터베이스 서버 또한 여러대 추가할 수 있습니다.
이를 통해 한 서버에 장애가 발생해도 다른 서버가 서비스를 제공할 수 있습니다.
하나의 master DB는 여러대의 복제 서버(replica DB)를 가질 수 있습니다.
master DB의 경우 read/write가 가능하며 replica DB은 read만 가능합니다.
Redis는 비동기식 복제를 지원합니다.
비동기 데이터베이스 복제는 복제가 백그라운드에서 발생하기때문에 동기화 수행중에도 master가 쿼리를 계속 수행할 수 있다는 장점이 있지만 replica에 master 데이터가 아직 업데이트 되어있지 않았을 상황이 있을 수 있습니다.
그렇다면 Redis Replica를 언제 사용할 수 있을까요❓
Redis의 장점으로 데이터를 디스크에 저장하여 장애상황시 복구에 사용할 수 있다는 점에 대해 알아보았는데요,
Redis는 특정 시점 Redis 데이터 셋을 디스크로 복사할 때 master대신 replica를 사용할수 있습니다.
또한 replica는 일반적으로 read only 쿼리를 수행하는데 master 대신 시간이 오래걸리는 O(N) 작업을 수행하도록 할 수 있습니다.
Redis Failover(장애 복구)
Redis Failover는 master 서버가 다운되면 복제 서버를 마스터로 역할을 바꾸어주는 명령어입니다.
이때 사람이 아닌 자동 failover 기능을 수행하는 별도의 센티넬 서버를 둘 수 있습니다.
센티넬은 1초에 한번씩 PING을 보내서 마스터, 복제 서버가 정상적인지 감지하고 있다가 마스터 서버가 다운되면 복제 서버를 자동으로 마스터로 승격시킵니다.
안정적인 운영을 위해서는 최소 3개 이상의 센티넬 인스턴스가 필요하다고합니다.
주석
1: https://docs.spring.io/spring-session/docs/current/reference/html5/guides/boot-redis.html
