대용량 트래픽 처리를 위한 서버 전략
 대용량 트래픽 처리를 위한 로그인 기능 설계에 대해 고민해보았습니다.
대용량 트래픽 처리를 위한 로그인 기능 설계에 대해 고민해보았습니다.
기존 단일 서버 환경에서는 제한된 리소스(CPU, RAM)로 수천명의 사용자를 수용하기에는 어려움이 있었습니다.
더 많은 사용자를 수용하기 위해서는 서버 리소스를 늘려야 합니다.
Scale up(수직 확장)
 가장 먼저 생각해볼 수 있는 방법은 서버의 수직 확장입니다.
가장 먼저 생각해볼 수 있는 방법은 서버의 수직 확장입니다.
기존 한대의 서버의 성능을 높이는 방법입니다.
이 방법은 일시적으로는 문제를 해결할 수 있지만 점점 더 많은 사람들이 서비스를 사용한다면 추가 된 리소스 또한 고갈될 것입니다. 한대의 서버의 성능을 높이는 방식은 리소스의 한계, 성능 확장에 한계가 있습니다.
또 다른 문제점은 단일 장애 지점을 갖는다는 점입니다. 현재 우리 서버는 한대 뿐이며, 이는 여러 가지 이유로 다운 될 수 있습니다. 한 대의 서버가 다운되는 경우 더이상 서비스를 제공할 수 없습니다.
Scale out(수평 확장)
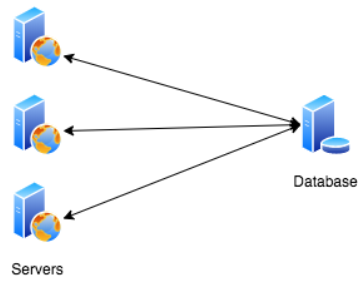 서버의 수평 확장은 동일한 목적을 갖는 서버를 여러대 추가하는 것입니다.
서버의 수평 확장은 동일한 목적을 갖는 서버를 여러대 추가하는 것입니다.
이 경우 한 서버에 장애가 발생해도 다른 서버가 서비스를 제공할 수 있으며 지속적인 수평 확장이 가능합니다.
서버가 여러대인 경우 어떻게 트래픽을 분배할 수 있을까요?
바로 로드밸런서를 사용합니다.
Load balancer
로드 밸런싱이란 부하 분산을 위해 가상 IP를 통해 여러 서버에 접속하도록 부하를 분배하는 기능입니다.
웹 서버의 경우 하나의 아이피를 가지고 있고 클라이언트는 이 아이피(도메인)을 통해 웹 서비스를 접속합니다.
웹 서버가 여러개인 경우 어떻게 서비스에 접속할 수 있을까요?
이경우 DNS 서버의 설정을 바꿔서 사용자가 DNS 서버에 접속하면 랜덤한 Web Server의 IP를 알려줄 수 있습니다.
여러대의 웹 서버를 통해 부하를 분산하는 효과가 납니다.
또는 로드밸런서라는 장치를 사용하여 부하(접속)를 골고루 분산시키는 역할을 수행합니다.
로드밸런서가 우리 서버로 접속하는 대표 ip를 가지고 있습니다.
사용자는 웹서버의 ip가 아닌 로드밸런서의 ip를 가리키게 됩니다.
만약 x번 웹 서버가 죽으면 로드밸런서는 이를 확인하고 더이상 x번 서버에 요청을 보내지 않습니다.
또는 y번 서버가 사양이 좋은 경우 y번 서버에 요청을 더 보냅니다.

Scale out(수평 확장)의 문제점
서비스의 확장에는 한계가 없어야 하며, 단일 서버가 다운되는 경우 서비스가 중단된다는 점은 운영 환경에서 매우 치명적이기 때문에 서버 리소스를 늘리는 방안으로 Scale out 방식을 선택하기로 하였습니다.
그렇지만 Scale out 방식에도 여러 문제점이 존재합니다.
우리 서비스는 Session을 활용한 로그인 기능을 포함하고 있습니다.
Session은 기본적으로 서버 메모리 공간에 저장된다고 학습하였으나, 다중 서버 환경에서 사용자가 특정 서버에 Session을 가질 때 로드 밸런서에 의해 다른 서버에 라우팅된다면 그 서버는 Session 정보를 가지고 있지 않기 때문에
사용자는 다시 로그인을 해야하는 세션 불일치 문제점이 발생합니다. 💥
Sclae out 방식을 선택하고 세션 불일치 문제점을 해결할 수 있는 방안에 대해 알아보도록 하겠습니다.
(1) Sticky Session(고정 세션)
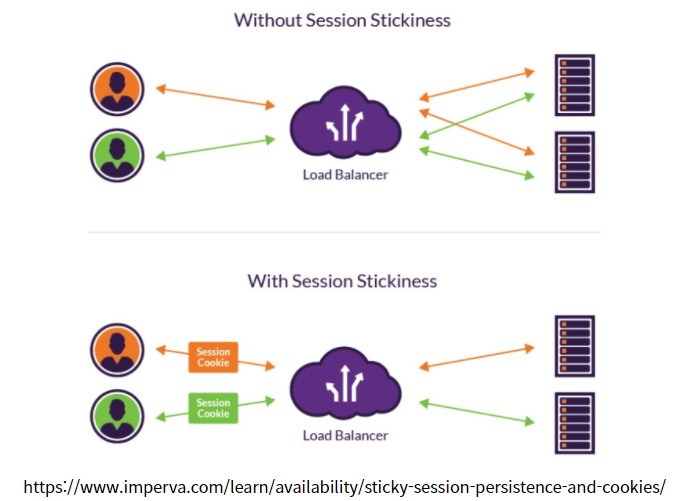 Sticky Session은 로드밸런서가 세션 기간 동안
Sticky Session은 로드밸런서가 세션 기간 동안
동일한 client의 http request를 항상 동일한 서버(특정 세션의 요청을 처음 처리한 서버)로 라우팅 해주는 기능입니다.
Sticky Session에서 로드밸런서는 일반적으로 쿠키를 발행하거나 IP 세부 정보를 추적하여 식별 속성을 할당 후 세션 기간동안 사용자의 모든 요청을 특정 서버로 라우팅합니다.
AWS ELB와 같은 경우 쿠키를 사용해 Sticky Session 기능이 동작합니다.
http response에 쿠키를 세팅하여 해당 client와 바인딩된 EC2 인스턴스에 대한 정보를 저장해놓습니다.
로드밸런서는 client 요청을 수신 할 때마다 이 쿠키가 있는지 확인합니다.
쿠키가 있다면 식별된 EC2 인스턴스로 라우팅 해줍니다.
지정된 기간이 경과하고 쿠키가 만료되면 세션은 고정되지 않습니다.
Sticky Session의 장단점
👍 장점
Sticky Session 기능을 사용하는 경우 여러 서버들은 세션 데이터를 교환할 필요가 없습니다.
세션 데이터를 교환하는 작업은 규모가 큰 프로젝트에서 특히 비용이 큰 작업입니다.
👎 단점
🍭 특정 서버에 과부하가 발생할 수 있습니다.
Sticky Session의 경우 트래픽이 균등하게 분배될 수 없습니다.
특정 사용자가 특정 서버에 바인딩됨으로써 로드밸런서가 여러 서버에 부하를 골고루 분산시킬 수 없습니다.
👧 구체적으로 언제 특정 서버에 과부하가 발생할 수 있을까요❓
(1) 특정 서버에 몰린 사람들만 활발하게 활동하는 경우
극단적인 케이스지만 특정 서버에 바인딩된 사용자들만 활발하게 활동할 수 있습니다.
(2) 여러 사용자가 동일한 IP를 갖는 경우
현실 세계에서 IP가 부족한 상황을 해결하기 위해 사설/공인 IP를 사용하고 있습니다.
공인 IP는 실제 인터넷 세상에서 사용하는 IP 주소, 사설 IP는 같은 네트워크 대역에서 사용하는 IP 주소입니다.
사설 IP를 사용하는 장비들이 네트워크 통신을 할 때 무조건 공인 IP로 바꾸어 외부 세상과 통신합니다.
(강의실, 사내에서는 사설 IP를 사용하다가 다른 네트워크 대역과 통신시 NAT 장비를 통해 사설 IP를 공인 IP 로 바꿔줍니다.)
여러 사용자의 요청이 프록시 서버 또는 NAT(네트워크 주소 변환)를 통해 전달되는 경우 모두 동일한 IP 주소를 가질 수 있고 이는 모두 단일 서버로 전송됩니다.
🍭 로드 밸런서가 클라이언트를 다른 서버로 이동시키는 경우 기존 세션 데이터가 유실됩니다.
👧 그렇다면 구체적으로 언제 로드밸런서가 사용자를 다른 서버로 이동해야 하는지 생각해보겠습니다.
(1) 특정 서버에 과부하가 걸리는 경우
첫번째 문제점의 연장이라고 볼 수 있습니다. 특정 서버에 과부하가 걸리는 경우
로드 밸런서는 이를 감지하고 그 서버로 향하는 트래픽을 다른 서버로 다시 라우팅하기 시작합니다.
(2) 서버(WAS)에 장애가 발생하는 경우 로드 밸런서가 클라이언트를 다른 서버로 이동시켜야 합니다.
(3) 유지관리 업데이트 배포 등으로 서버를 때때로 중단시켜야 합니다.
(2) Session Clustering
Session 정보 유실시 입력 정보 유실, 재 로그인 등으로 인한 서비스 만족도가 하락할 수 있습니다.
서비스 만족도 하락은 매출 감소에 직접적인 원인이 될 수 있습니다.
따라서 Sticky Session 대신 다른 방식으로 세션 불일치 문제를 해결하도록 하겠습니다.
이 경우 세션 클러스터링을 통해 해당 문제를 해결할 수 있습니다.
세션 클러스터링은 다중 서버 환경에서 로드밸런서를 통해 어떤 서버로 접속하든지 세션이 동일하게 유지되도록 설정해주는 것입니다.
Tomcat 9.0에서는 아래와 같은 Session Manager 클래스를 제공합니다.
(1) DeltaManager
특정 서버에서 발생한 Session 정보를 나머지 모든 서버에 복제합니다.
이는 비용이 큰 작업이기 때문에 대규모 클러스터 환경에는 적합하지 않습니다.
(2) BackupManager
서버가 4개 이상의 경우 BackupManager를 이용합니다.
특정 서버에서 발생한 Session 정보를 나머지 서버들 중 오직 1대에만 복제합니다. (따라서 한 서버의 세션 데이터 유실은 허용합니다.)
나머지 모든 서버들은 프록시 노드가 됩니다. 프록시는 Session ID, 기본, 백업 서버의 주소가 있습니다.
예를 들어 4대의 서버가 있다고 가정해봅시다.
1번 서버에 사용자가 접속해 session을 생성하는 경우
2번 서버(나머지 서버들 중 하나)에 session을 복제합니다.
이때 1번 서버는 Primary, 2번 서버는 Backup이 됩니다.
다른 노드들(3, 4번 서버)에게는 Session id, Session id 값의 Primary 저장 위치인 1번 서버 값, Backup 저장 위치인 2번 서버 값을 전달합니다. 이들은 Proxy가 됩니다.
이후 사용자가 1, 2번 서버에 접속시에는 이미 해당 Session 정보를 가지고 있기 때문에 바로 서비스를 제공합니다.
사용자가 3, 4번 서버에 접속하여 해당 Session 정보를 조회하면 해당 서버에서 1번 서버에 요청하여 서비스를 제공합니다.
세션 클러스터링 방식은 서버가 늘어날수록 늘어나는 서버의 갯수만큼 세션 정보를 복제 해야 하기 때문에 서버를 추가함에 대한 부하가 발생합니다.
즉 성능 확장에 한계가 발생할 수 있습니다.
다음 시간에 해당 문제점을 해결할 수 있는 방안에 대해 알아보도록 하겠습니다.
References
www.imperva.com/learn/availability/sticky-session-persistence-and-cookies/
medium.com/@harithjaved/scaling-your-web-application-693657ce333c
m.blog.naver.com/PostView.nhn?blogId=tkstone&logNo=50190901395&proxyReferer=https:%2F%2Fwww.google.com%2F
tkstone.blog/2018/09/19/about-tomcat-backupmanager/
tomcat.apache.org/tomcat-9.0-doc/cluster-howto.html

경험이 없는 개발자는 알 수 없는 내용을 글로라도 설명해주셔서 감사합니다.