Machine learning and Optimization
loss 함수를 정의하고 실제하고 모형이 출력해 주는 출력 결과물 2개의 차이를 최소화하게끔 하는 최적의 모형을 찾아주는 과정입니다.
linear regression
loss 정의 실제하고 예측 간의 차이를 제곱해서 다 더하는 평균을 내는 것
실제랑 모형이 예측한 결과가 차이가 많이 있다고 한다면 이 MSE Loss가 클것이고 그렇지 않고 모형이 잘 에측한다고하면 모형의 차이가 적어진다.
이것을 loss를 최적화 최소화 해주는 것이 Optimization 입니다.
규칙 또는 일관된 룰, 그것과 관련된 게 바로 최적화라는 것입니다.
경사하강법
방향을 찾고 가파르게 함수를 줄일 수 있는 방향을 찾고 그 뱡향으로 한 발 자국 계속 내려가는 방법
Loss를 minimize 하는 parameter를 찾는 게 핵심입니다.
극소점을 구할 수만 있다면, 꽤 좋은 한 발자국을 내디딜 수 있습니다.
이차 함수의 계수가 작으면 어떻게 되나요? 함수가 좀 넓적해지게 되고 그러면서 현재부터 극솟값까지의 거리가 넓어지는 효과가 나타납니다. 그것들이 Step Size로 연관되는 것입니다. 반대로 Step Size가 작다. 그러면 이차항의 계수 값이 커지면서 함수가 굉장히 뽀족하게 바뀌게 됩니다.
Learning Rate
정확히 가장 좋은 Learning Rate을 구하는 방법이 무엇이냐?
수학적으로는 정해진 정리는 없습니다. Loss함수의 변화도를 쭉 추적하면서 너무 Loss 함수가 감소를 안하거나, 느리게 감소 하게 되면 스톱하고, Learning Rate의 크기를 키운 다음 학습을 시키든, 모니터링 작업이 필요합니다.아담 같은 알고리즘을 통해 상황에 맞게 Learning Rate를 조절해 주는 방법도 있습니다.
Stochastic Gradient Descent
Full Gradient가 가능한 그런 빠르게 계산되는 상황이라면 Full Gradient를 이용하는 게 좋습니다. 하지만 그게 어렵고 비효율적인 상황이라면 Stochastic Gradient Descent를 쓴다. 특히 딥러닝에서는 SGD를 이용해서 업데이트를 많이 합니다.Full Gradient가 업데이트 하는 동안, Stochastic Gradient Descent 같은 경우 batch의 개수만큼 업데이트가 일어나면, 훨씬 빠르게 해를 구할수 있다는 장점이 있습니다.
Momentum
Local Minimum에 도달했는데 여기서 국한되는 게 아니라 그 관성을 그대로 기억해 놨다가 이 Momentum만큼 더해줘서 여기를 뛰어 넘을 수 있게 해주는 방식입니다. Momentum는 과거에서 업데이트되어 왔던 방향을 게속 기억하는 것입니다.
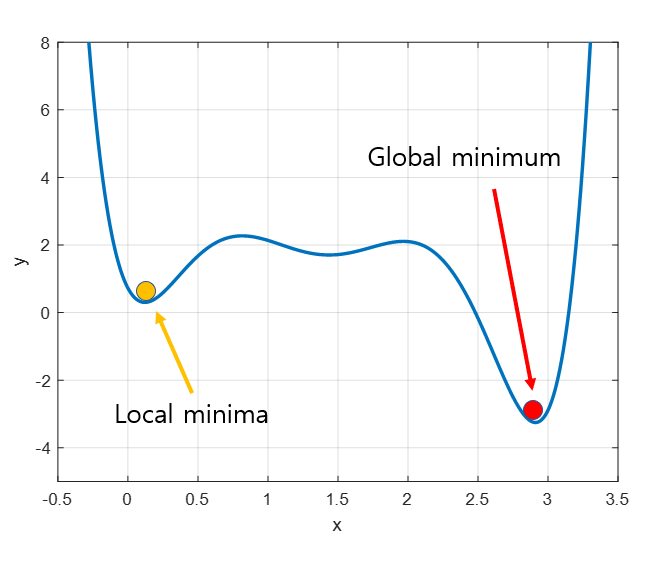
SGD + Momentum이 가장 딥 러닝에서 널리 사용되는 기법입니다.
