python
1.파이썬(if, for,while)&판다스

코드를 짤때, 들여쓰기 할 때 2칸으로 쓰는 사람들도 있는데 ! 그것 보다는 공식 문서 가이드가 권장하는 4칸으로 하는 것이 좋다!협업 할 시 들여쓰기를 칸을 통일해야 코드가 더 잘보인다.소스 파일도 인코딩 UTF- 8 사용해야한다import 할때 가저오는 순서도 있다
2.함수
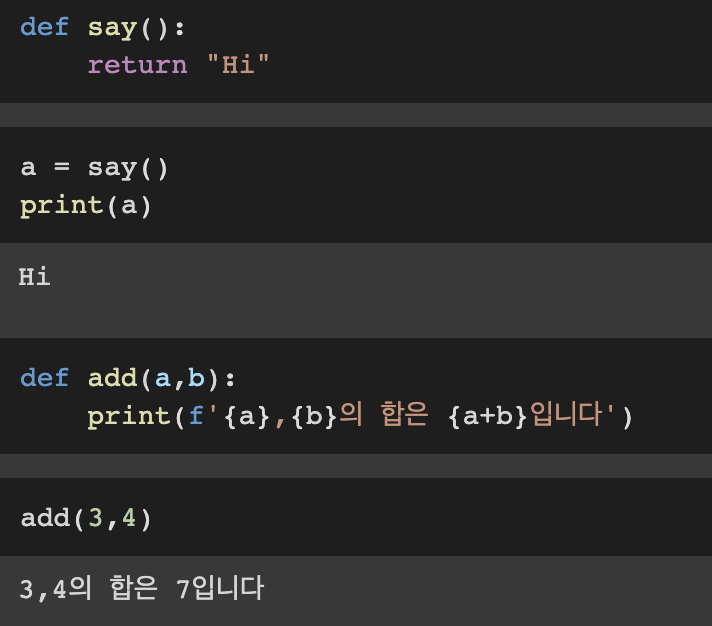
저번에 하지 못한 함수를 공부해 보려고 합니다!함수의 구조처음에 df 라는 함수 정의로 시작이 된다숫자를 대입해서 해보면값 7이 출력 된다!add()는 값을 합하는 함수이다.매개변수와 인수는 혼용해서 사용되는 헷갈리는 용어이다매개변수는 함수에 입력으로 전달된 값을 받는
3.데이터프레임
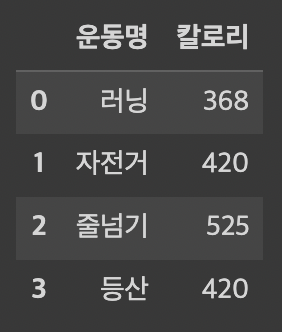
판다스 기초공부“as pd”는 “pandas” 대신 “pd”라는 약칭으로 부르겠다는 뜻이다.만약 “as” 명령을 내리지 않고 “import pandas” 라는 Full name을 사용한다면,pandas.Series()라고 입력해야한다.실무에서는 “pandas”대신 “p
4.누락 데이터 처리
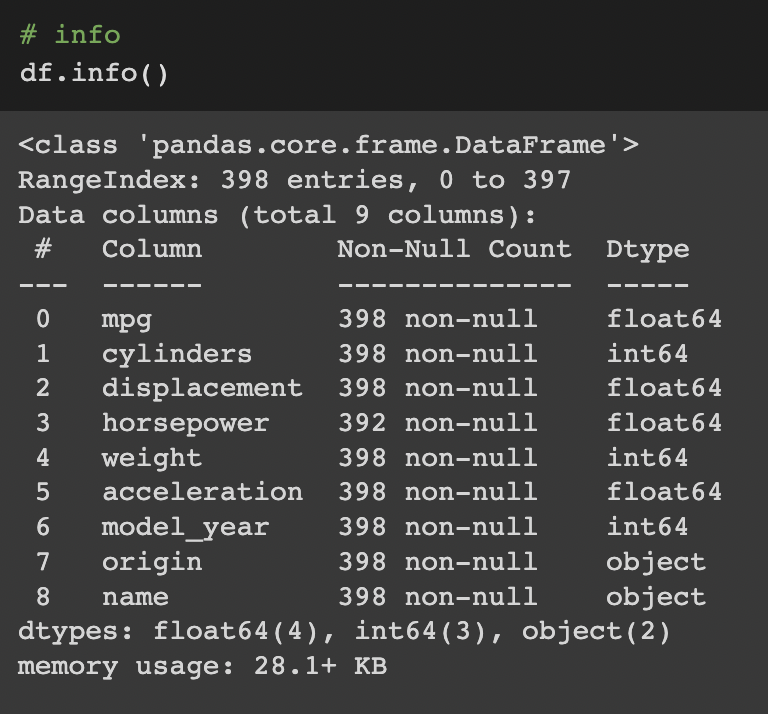
info() 메소드를 데이터 프레임에 적용하면 데이터 프레임에 관한 기본 정보를 화면에 출력한다데이터 프레임의 기본 정보 출력: DataFrame 객체.info()첫 행에 데이터프레임 df 의 클래스 유형인 ‘pandas.core.frame.DataFrame’이 출력
5.머신러닝
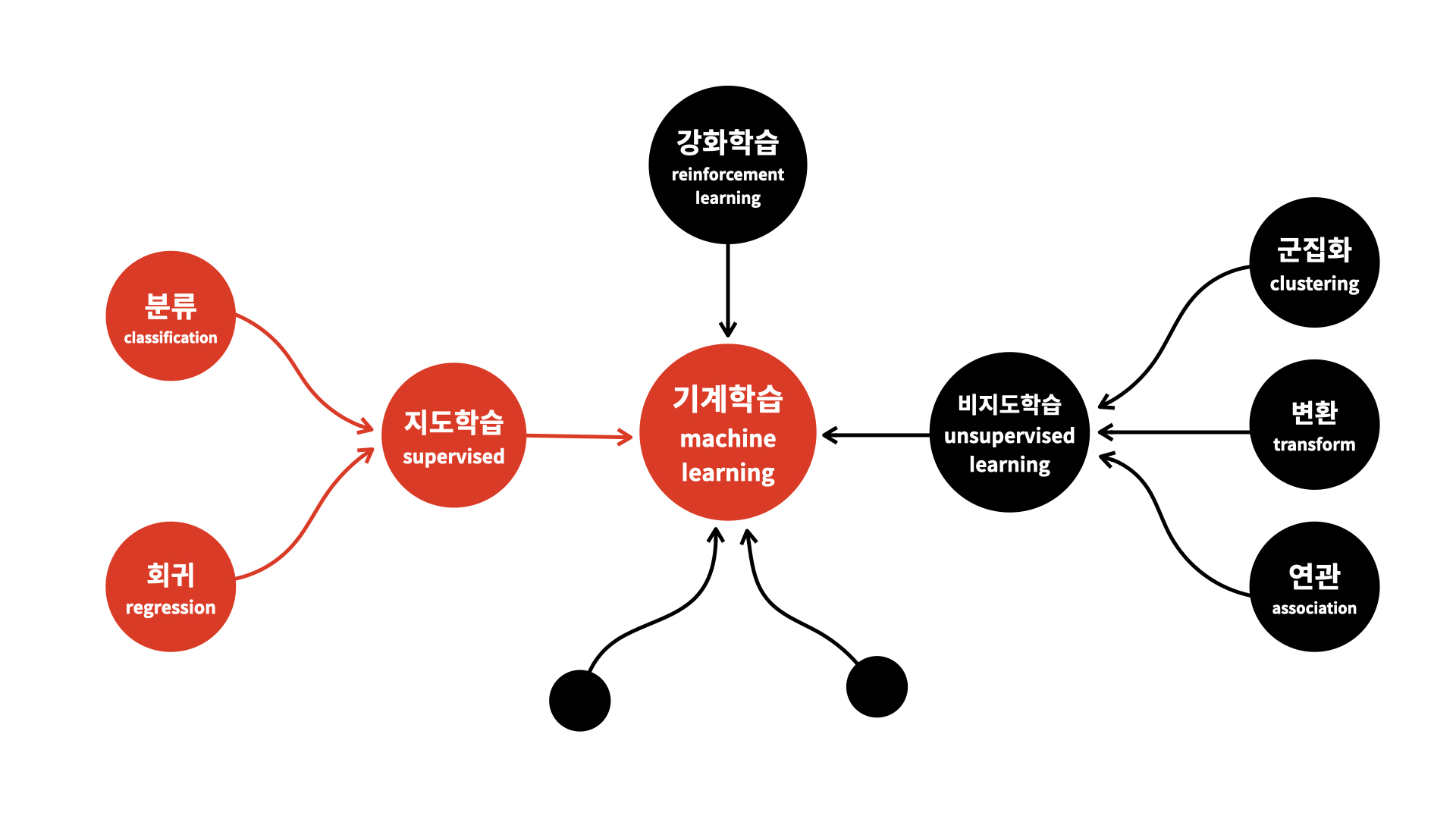
해결하려는 문제에 따라 예측, 분류 , 군집, 알고리즘 등으로 분류된다.예를 들면, 주가, 환율 등 경제지표 예측 은행에서 고객을 분류하여 대출을 승인하거나 거절하는 문제, 비슷한 소비패턴을 가진 고객 유형을 군집으로 묶어내는 문제 등이 있다.머신러닝은 워낙 다양한 영
6.결정 트리 학습법
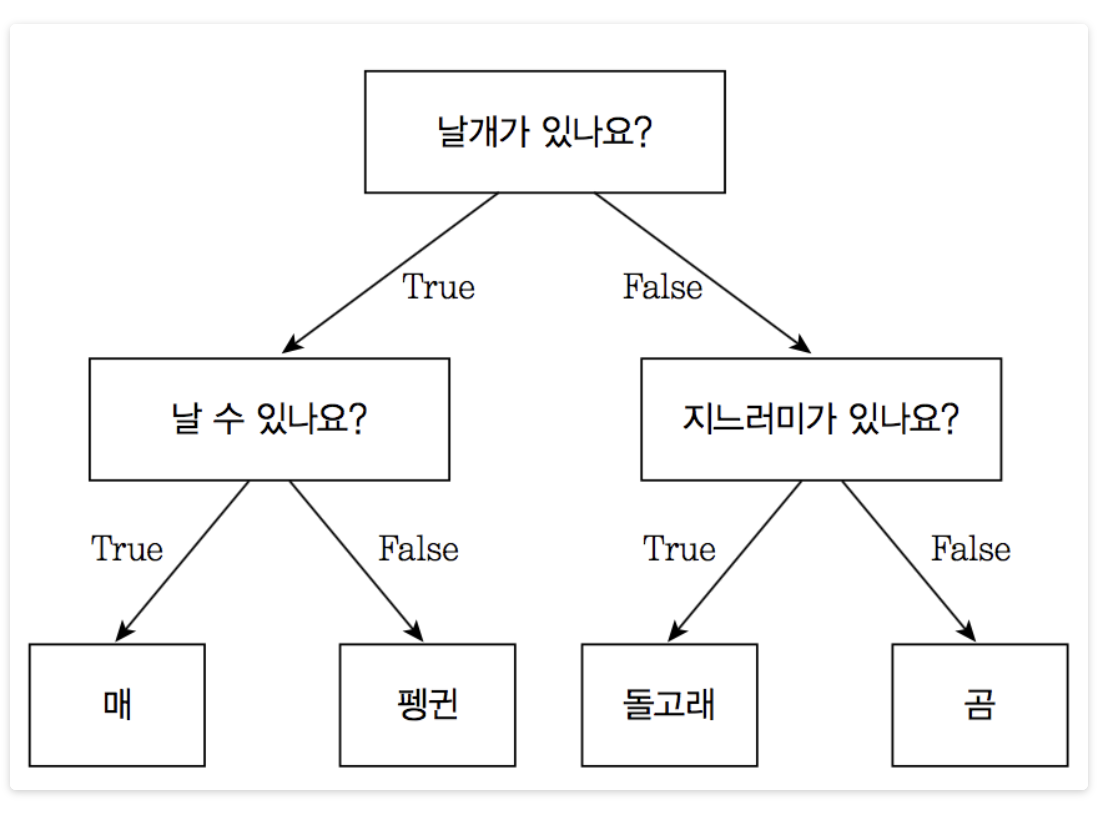
어떤 항목에 대한 관측값과 목표값을 연결시켜주는 예측 모델로,이는 통계학과 데이터 마이닝 기계 학습에서 사용하는 예측 모델링 방법 중 하나이다.트리 모델 중 목표 변수가 유한한 수의 값을 가지는 것을 분류 트리라 한다.이 트리 구조에서 잎(리프 노드)은 클래스 라벨을
7.피처엔지니어링
특징 엔지니어링 또는 특징 추출 또는 특징 발견은 원시 데이터에서 특징(특성, 속성, 속성)을 추출하기 위해 도메인 지식을 사용하는 프로세스입니다.동기는 이러한 추가 기능을 사용하여 기계 학습 프로세스에 원시 데이터만 제공하는 것과 비교하여 기계 학습 프로세스의 결과
8.배깅(bagging)
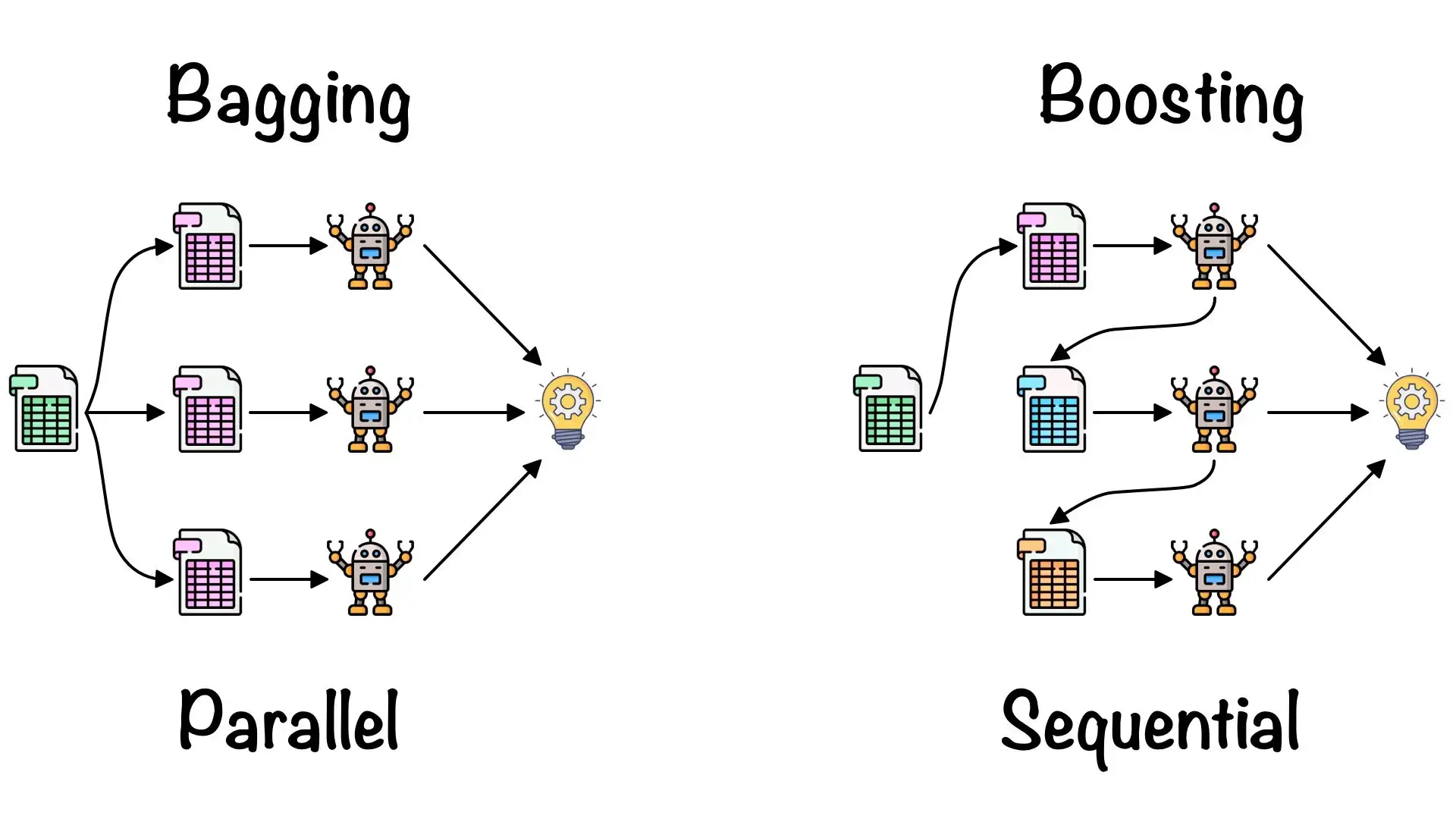
기계 학습 실무자가 편향과 분산 트레이드 오프를 해결하기 위해 활용할 수 있는 앙상블 학습 기반 기술이 몇 가지 있습니다.기술은 배깅 및 부스팅입니다.배깅(Bagging)은 일련의 동종 기계 학습 알고리즘을 구현하여 오류 학습을 줄이는 것을 목표로 하는 앙상블 학습 기
9.머신러닝
인공지능을 구현하는 한가지 방법입니다. 유용한 함수를 학습시키는 것 입니다.예시 ; 강아지와 고양이 사진들로 학습시킨 후 , 강아지와 고양이 구별하게 하는 것과거에는 AI는 컴퓨터에 데이터를 입력후 결과 도출최근에는 데이터를 입력해주고,컴퓨터가 학습후 Function으
10.머신러닝 2
어떤 입력이 들어 갔을때 어떤 정답이 나와야하는지 알려주면서 학습을 하는 것이 지도 학습입니다.예시 ; 강아지, 고양이, 자동차, 비행기 이와 같은 범주를 Classification이고, 혈압과의 정확한 수치,몸무게의 수치와 같은 continuous한 값이라면, Reg
11.분류
Classification과 Regression를 구분하는 기준은 무엇인가?종속변수,출력변수 Y가 범주형이면 classification 연속성이면 regression 입니다.모든 모델은 복잡도를 통제할 수 있는 Hyperparaketer를 갖고 있고, 가장 좋은 성능을
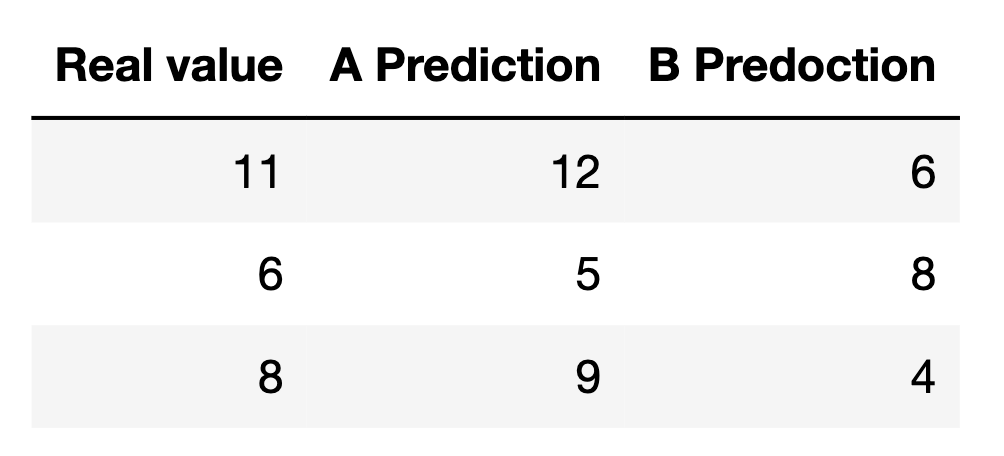
12.최적화
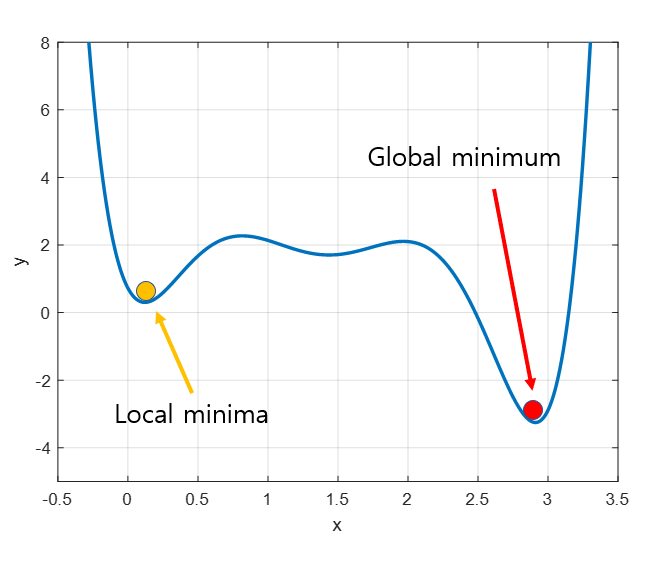
loss 함수를 정의하고 실제하고 모형이 출력해 주는 출력 결과물 2개의 차이를 최소화하게끔 하는 최적의 모형을 찾아주는 과정입니다.linear regression loss 정의 실제하고 예측 간의 차이를 제곱해서 다 더하는 평균을 내는 것실제랑 모형이 예측한 결과가
13.서포트 벡터머신
Support Vector Machine선형이나 비선형 분류,회귀, 이상치 탐색에도 사용 할 수 있는 머신러닝 방법론입니다. 딥러닝 이전 시대까지 널리 사용된 방법론이고, 복잡한 분류 문제를 잘 해결, 상대적으로 작거나 중간 크기를 가진 데이터에 적합하고 최적화 모형으
14.혼동 행렬
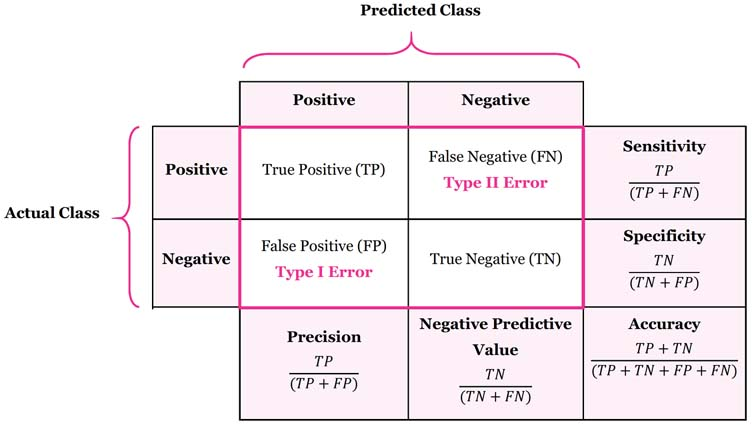
분류 모델에서 학습 시킨 뒤, 모델에서 데이터의 X값을 집어넣어 얻은 예상되는 y값과, 실제 데이터의 y값을 비교하여 정확히 분류 되었는지 확인하는 메트릭(metric)이라고 할 수 있습니다.True Positive(TP) : 실제 값은 Positive, 예측된 값도
15.이미지 증강
데이터를 가로 뒤집기, 색상 공간 확대 및 무작위 자르기와 같은 간단한 변환에서 비롯됩니다. 이러한 변환은 이미지 인식 작업에 대한 문제를 제시하는 이전에 논의된 많은 불변성을 인코딩합니다. 증강은 기하 변환, 색 공간 변환, 커널 필터, 혼합 이미지, 임의 지우기,
16.RFM 모형
거래의 최근성 : 고객이 얼마나 최근에 구입하였나거래 빈도 : 고객이 얼마나 빈번하게 구입하였나거래 규모 : 고객이 얼마나 많이 구입하였나각요인의 중요도는 상품과 서비스에 따라 다릅니다.RFM 모형에서는 이를 고려 하지 않아요. 각 요소의 비중을 동일하게 취급합니다.사
17.정규식 표현
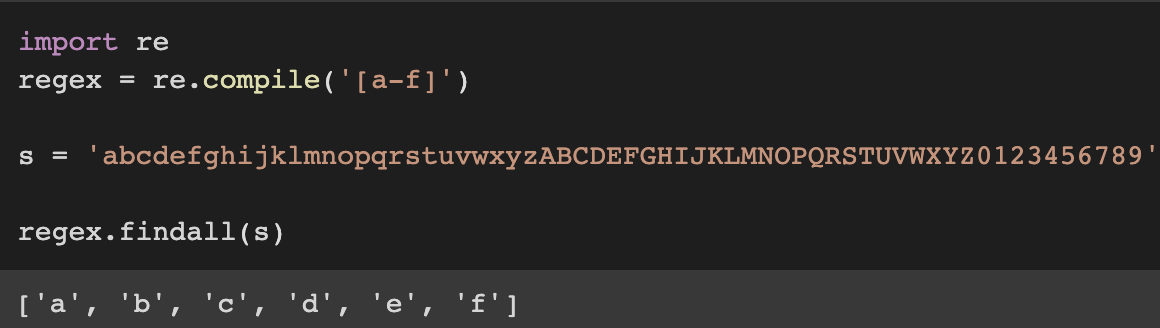
<class 're.Match'>'class', 'class_getitem', 'copy', 'deepcopy','delattr', 'dir', 'doc', 'eq', 'format', 'ge', 'getattribute', 'getitem', 'gt', 'has
18.파이썬으로 엑셀 프로그래밍
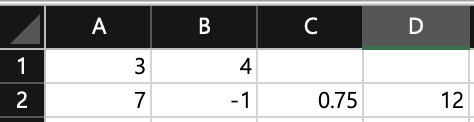
xlsxwriter 모듈을 이용해서 엑셀 파일을 생성하고 시트와 숫자를 넣고 더하기, 빼기, 곱하기 나누기를 해보겠습니다.이것을 엑셀 함수를 이용해서도 만들 수 있습니다.sum -> 합계 함수product -> 곱 함수average -> 평균 함수
19.파이썬으로 엑셀프로그래밍하기 2
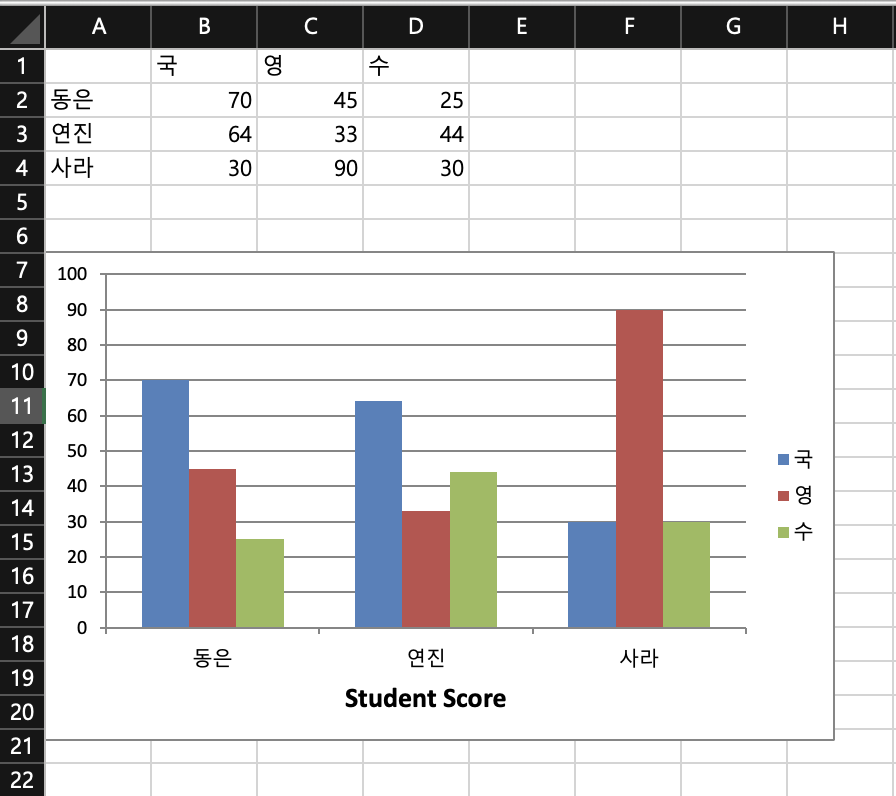
표만들기