
이진탐색트리
이진탐색트리(Binary Search Tree)
: 정렬된 데이터의 중간에 위치한 항목을 기준으로 데이터를 두 부분으로 나누어 가며 특정 항목을 찾는 탐색 방법인 이진 탐색의 개념을 트리 형태의 구조에 접목한(단순연결리스트를 변형시킨) 자료구조
- 가장 기본적인 트리 형태의 자료구조
- 균형 이진탐색트리, B-트리, 다방향 탐색트리는 이진탐색트리에 기반한 자료구조
- 데이터베이스 등 대용량 데이터 저장의 기본 개념으로 활용됨
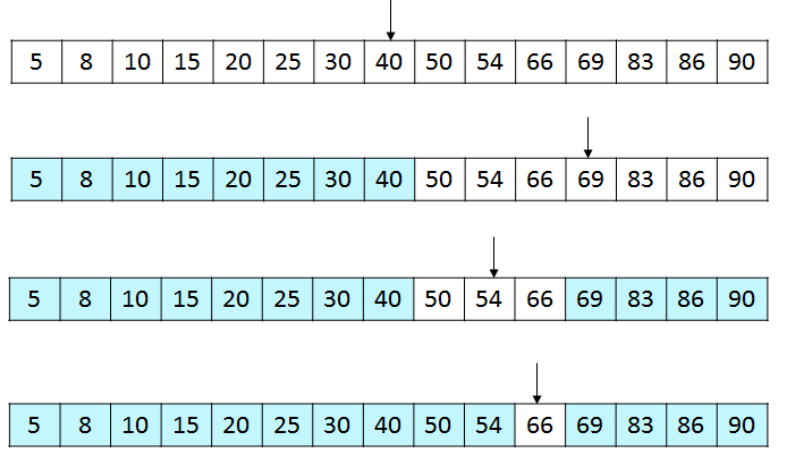
이진탐색으로 66을 찾는 과정을 단계별로 나타낸 것이다.
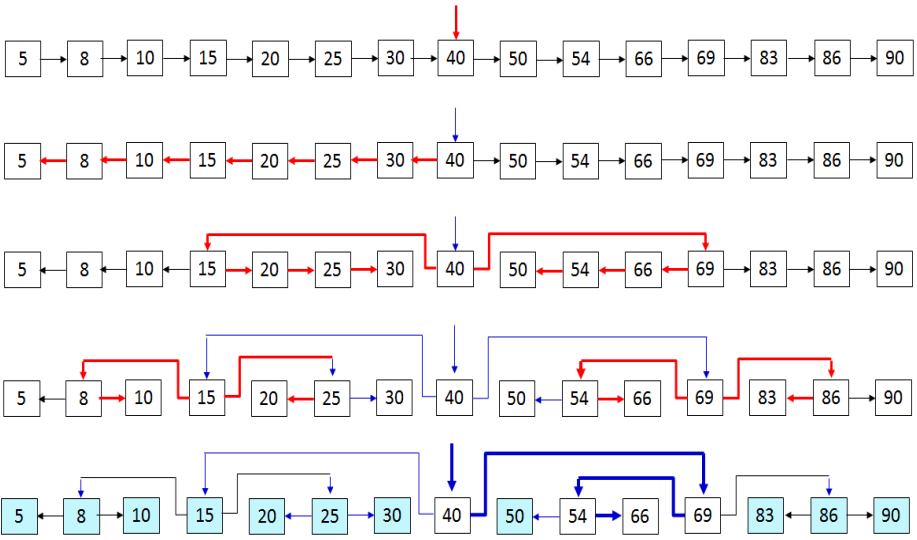
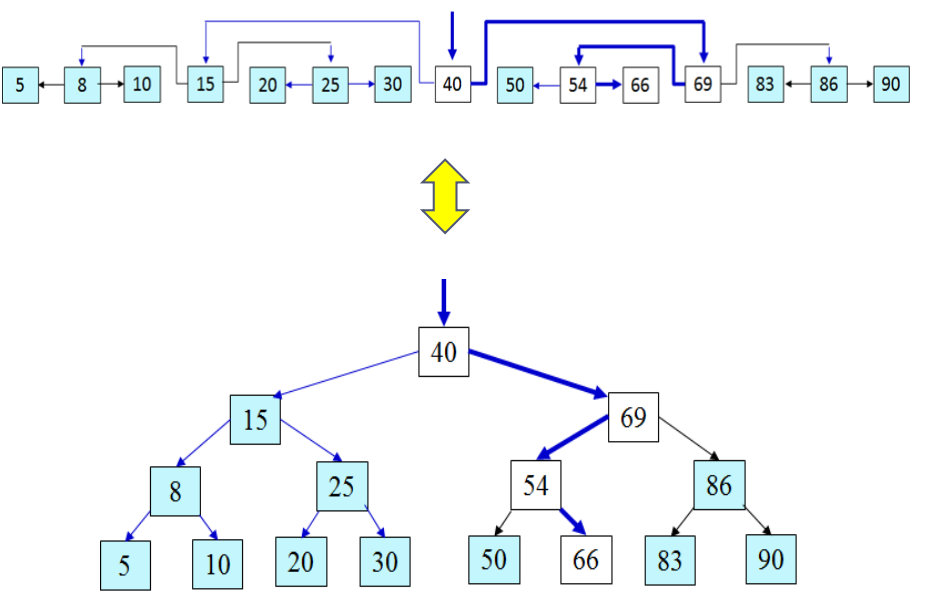
1차원 배열을 단순연결리스트로 만든 후, 점진적으로 이진트리 형태로 변환하는 과정이다. 이것은 이진탐색의 개념이 트리에 어떻게 내포되어 있는지를 보여준다.
이진탐색트리의 특징 중 하나는 트리를 중위순회 시 정렬되어 출력된다는 것이다.
각 노드 n의 키값이 n의 왼쪽 서브트리 노드들의 키값들보다 크고, n의 오른쪽 서브트리에 있는 노드들의 키값들보다 작다!
구현
이진탐색트리 클래스
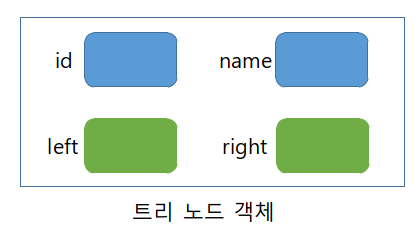
노드의 객체는 id(key), name(키에 관련된 정보), left(왼쪽 자식을 가리키는), right(오른쪽 자식을 가리키는) 필드를 가진다.
public class BST <Key extends Comparable<Key>, Value>{
public Node root;
public Node getRoot() {return root;}
// 생성자
public BST(Key newId, Value newName){
root = new Node(newId,newName);
}
// get, put, min, deleteMin, delete
}이진탐색트리를 위한 BST 클래스이다.
탐색연산
탐색하고자 하는 key가 k라면 루트노드의 id와 k를 비교하는 것으로 탐색을 시작한다.
- id > k => 루트의 왼쪽 서브트리에서 k 탐색
- id < k => 루트의 오른쪽 서브트리에서 k 탐색
- id = k => 탐색 성공! 해당 노드의 value(name) 리턴
// get - 탐색연산
public Value get(Key k){ return get(root, k);}
public Value get(Node n, Key k){
if(n==null) return null; // k 를 발견 못함..
// compareTo() 노드의 id와 비교하려는 대상인 k를 비교
// id < k => 음수
// id > k => 양수
// id = k => 0
int t = n.getKey().compareTo(k);
if(t>0) return get(n.getLeft(), k); // (id > k) 왼쪽 서브트리 탐색
else if(t<0) return get(n.getRight(), k); // (id < k) 오른쪽 서브트리 탐색
else return (Value) n.getValue(); // k를 가진 노드 발견
}compareTo() 메소드는 노드의 id와 k를 비교한다. id가 k보다 작다면 음수를 반환하고, id가 k 보다 크다면 양수를 반환한다. id와 k 가 같다면 0을 반환한다. n.getKey().compareTo(k)의 결과에 따라 해당 노드의 왼쪽 /오른쪽 서브트리 탐색을 위해 get() 재귀호출을 한다. k를 발견했다면 k를 가진 노드의 vlaue를 리턴한다.
삽입연산
탐색 연산의 마지막에서 null이 반환될 상황에 null 반환 대신 삽입하고자하는 새로운 노드를 생성하고 이 노드를 부모노드와 연결한다. 이미 트리에 존재하는 id를 삽입한 경우, name을 갱신한다.
//put - 삽입연산
public void put(Key k, Value v){
root = put(root, k, v);
}
public Node put(Node n, Key k, Value v){
if(n==null) return new Node(k,v); // 새로운 노드 삽입!
int t = n.getKey().compareTo(k);
if(t>0) n.setLeft(put(n.getLeft(),k,v));// (id > k) 왼쪽 서브트리에 삽입
else if(t<0) n.setRight(put(n.getRight(),k,v)); // (id < k) 오른쪽 서브트리에 삽입
else n.setValue(v); // 노드 n의 name을 v로 갱신
}root = put(root, k, v); root가 put()메소드가 리턴하는 Node를 가리키도록한다. setLeft()/setRight()를 호출하여 put() 메소드가 리턴하는 Node를 연결한다.
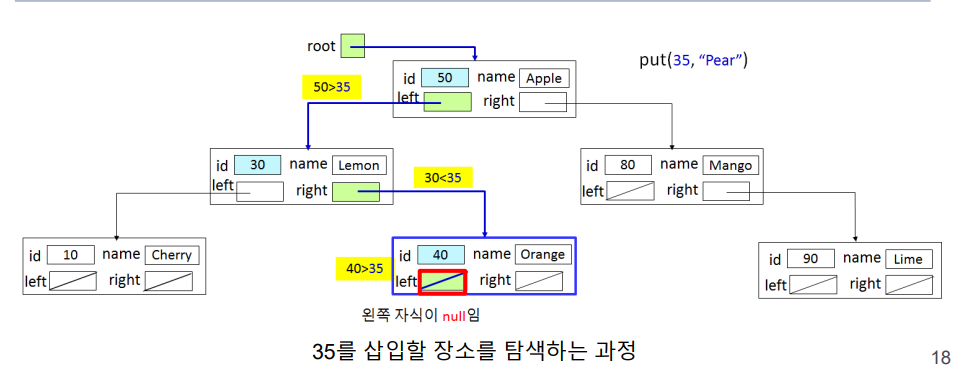
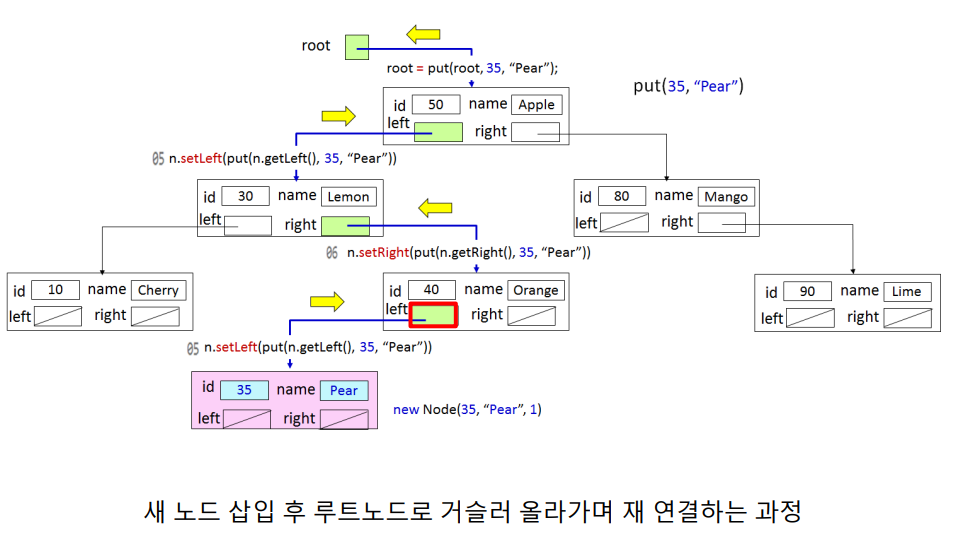
Node 생성자를 호출하여 새 노드를 생성하고 setLeft() 메소드를 호출하여 새 노드를 40의 왼쪽 자식으로 연결한다. 이후 직전 put 메소드를 호출했던 30에서 setRight() 메소드를 호출하여 40을 다시 연결한다. 이런 방식을 반복하고 최종적으로 root = put(root, k, v); root가 루트노드를 다시 가리키도록하여 put() 메소드의 수행을 종료한다.
최솟값 찾기
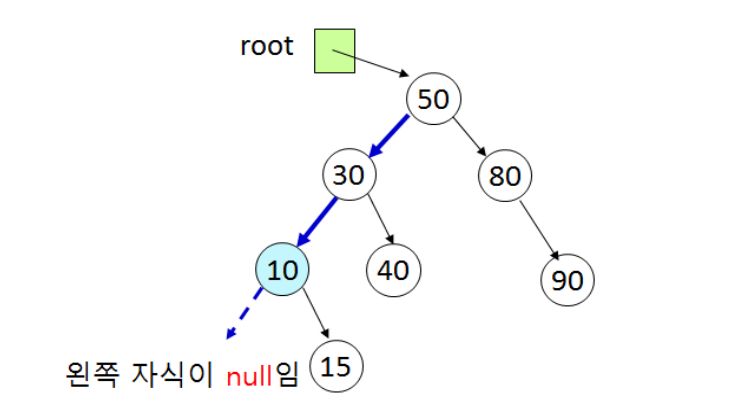
루트노드로부터 왼쪽 자식노드를 따라 내려가며 null을 만났을 때 부모노드가 가진 id가 최솟값
// min - 최솟값 찾기
public Key min(){
if(root==null) return null;
return (Key)min(root).getKey();
}
public Node min(Node n){
if(n.getLeft()==null) return n;
return min(n.getLeft());
}전달받은 노드가 null이 아니라면 계속 왼쪽 자식을 인자로 넘겨 min() 메소드를 재귀호출한다.
최솟값 삭제 연산
1) 최솟값을 가진 노드 찾기
2-1) 해당 노드의 부모노드와 해당 노드의 오른쪽 자식 노드를 연결
2-2)오른쪽 자식 노드가 없다면 null을 자식으로 연결
// deleteMin - 최솟값 삭제 연산
public void deleteMin(){
root=deleteMin(root);
}
public Node deleteMin(Node n){
if (n.getLeft()==null) return n.getRight(); //n의 왼쪽 자식노드가 없다면 오른쪽 자식노드 리턴
n.getLeft(deleteMin(n.getLeft())); // n의 왼쪽 자식노드가 null이 아니라면 n의 왼쪽자식 노드 재귀호출
return n;
}root=deleteMin(root); root노드를 인자로 하여 deleteMin()호출한다. 루트노드부터 왼쪽 자식이 null일 때까지 왼쪽 자식으로 계속 내려간다. 왼쪽 자식이 null이라면 현재 노드의 오른쪽 자식의 레퍼런스를 리턴하면 그 직전에 호출한 메소드는 n.getLeft(리턴된 현재 노드의 오른쪽 자식)이 된다. 그 후부터는 루트노드까지 거슬러가며 부모와 자식을 n.getLeft(deleteMin(n.getLeft()));을 통해 다시 연결한다. 이 메소드를 통하면 최솟값을 가진 노드를 분리되어 삭제되게 된다.

삭제 연산
삭제 연산을 위해서는 삭제 할 노드를 찾기 위한 탐색이 먼저 이루어져야한다. 탐색 후, 이진탐색트리 조건을 만족하도록 삭제된 노드의 부모노드와 자식노드 연결하여 delete를 진행하는데 이 때 세 가지 경우에 나누어 delete 연산을 진행해야한다.
case 0. 삭제되는 노드가 자식이 없는 경우
삭제 할 노드가 x라고 할 때, x의 부모노드가 x를 가리키던 레퍼런스를 null로 만들어준다
case 1. 삭제되는 노드가 자식이 하나인 경우
x가 한쪽 자식만 가지고 있다면 x의 부모노드가 x를 가리키던 레퍼던스가 x의 자식 노드를 가리키도록 갱신한다.
case 2. 삭제되는 노드가 자식이 둘인 경우
x의 부모노드는 하나인데 연결해야할 x의 자식 노드가 두 개인 경우, 중위순회하면서 x를 방문하기 직전 노드(Inorder Predessor, 중위 선행자) 또는 직후에 방문되는 노드(Inorder Successor, 중위 후속자)를 x의 자리로 옮긴다.
// delete - 삭제 연산
public void delete(Key k){
root = delete(root, k);
}
public Node delete(Node n, Key k){
if(n==null) return null;
int t = n.getKey().compareTo(k);
if(t > 0) n.setLeft(delete(n.getLeft(),k)); // 왼쪽 자식으로 이동
else if (t>0) n.setRight(delete(n.getRight(),k)); // 오른쪽 자식으로 이동
else{ // 삭제할 노드 발견
if(n.getRight() == null) return n.getLeft(); //case0, case1
if(n.getLeft() == null) return n.getRight(); // case1
Node target = n; // case2
n = min(target.getRight()); // 삭제할 노드 자리로 옮겨올 노드를 찾아서 n이 가리키도록
n.setRight(deleteMin(target.getRight()));
n.setLeft(target.getLeft());
}
}if(n.getRight() == null) return n.getLeft();
삭제되는 노드의 오른쪽 자식이 null인 경우, case0에 해당하고 case1 중 오른쪽 자식이 없는 경우 이 조건에 해당한다.
if(n.getLeft() == null) return n.getRight();
case1 중 왼쪽 자식이 없는 경우의 조건에 해당한다.
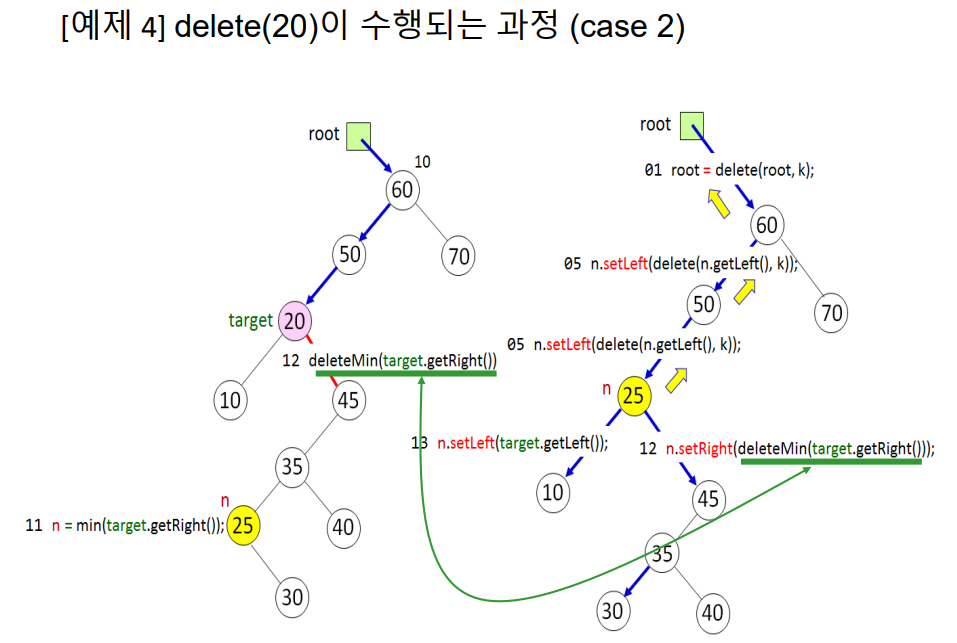
csae2의 경우
삭제될 노드의 중위 후속자 n을 min() 메소드를 호출하여 찾는다. deleteMin() 메소드를 호출하여 중위 후속자 n을 트리에서 분리시키고 n의 부모와 n의 자식을 연결시킨 뒤 재연결하며 거슬러 올라가 최종적으로 삭제되는 노드(target)의 오른쪽 자식노드의 레퍼런스를 리턴한다. n.setRight(deleteMin(target.getRight()));으로 리턴된 레퍼런스는 n.getRight()에 의해 n의 오른쪽 자식으로 연결된다. n.setLeft(target.getLeft());으로 target의 왼쪽 자식을 노드 n의 왼쪽 자식으로 만든다.
수행시간
이진탐색트리에서 탐색, 삽입, 삭제 연산은 루트노드에서 탐색을 시작하여 최악의 경우에는 이파리노트까지 내려가고 삽입과 삭제 연산은 다시 루트노드까지 거슬러 올라가야한다.
트리를 한 층 내려갈 때는 재귀호출이 발생하고 한 층을 올라갈 때는 setLeft()/setRight() 메소드가 수행되는데 이것은 각각 O(1)시간밖에 소요되지 않는다.
따라서 연산 수행시간은 각각 이진탐색트리의 높이 h에 비례 => O(h)
h는 logN <= h <=N으로 표현할 수 있다
