CODE: 링크텍스트
BERT
BERT의 모델 구조
-
Transformer Encoder구조 활용
-
Layer개수는 12개 이상 늘리고, 파라미터 전체적 증가
-
Decoder없이 모델 학습 시킬 수 있는 이유: Mask LM, LSP존재
Mask LM
- 이전의 NEXT Token Prediction Language Model과 대비 시켜 알맞은 말을 넣어보는 문제를 엄청 풀게 하는 언어모델 구현
Next Sentence Prediction
- 좌우 두 문장이 순서대로 이어져 있는 문장인지 맞추는 문제로 입력을 받았을 때 NSP결과값을 리턴한다.
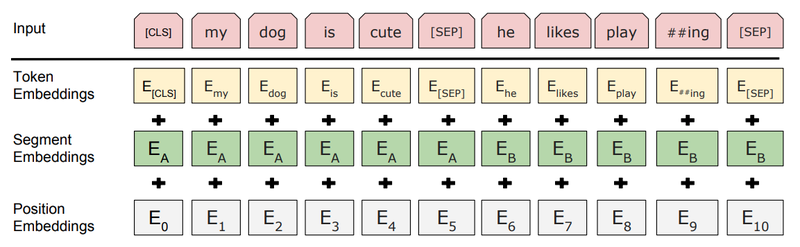
Token Embedding
-
텍스트의 tokenizer
-
문자 단위로 임베딩
-
긴 길이의 subword를 하나의 단위로 만들어준다
-
자주 등장하지 않으면(OOV) 다시 쪼개짐
Segment Embedding
-
기존 Transformer에 없던 것
-
각 단어의 역할 규정(어느 부분에 속하는 규정, 질문인지 대답인지 기타 등등)
Position Embedding
- Transformer과 동일

성장을 도울 아카이빙 블로그