Intro
- 학습목표
Text Recognition 모델을 직접 구현해 봅니다.
Text Recognition 모델 학습을 진행해 봅니다.
Text Detection 모델과 연결하여 전체 OCR 시스템을 구현합니다.
- 목차
Overall sturcture of OCR
Dataset for OCR
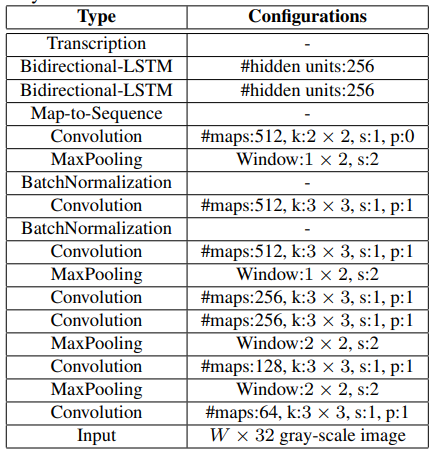
Recognition model
Input Image
Encode
Build CRNN model
Train & Inference
프로젝트 : End-to-End OCR
OCR구조
-
Text detection: keras-OCR활용
-
Recoognition: 직접 만들기
Dataset for OCR
참고:https://arxiv.org/pdf/1904.01906.pdf
-
Recognition model의 정량적 평가
- MJSynth
- SynthText
데이터준비
! mkdir -p ~/aiffel/ocr
! ln -s ~/data ~/aiffel/ocr/dataRecognition model
참고 문헌:https://arxiv.org/pdf/1507.05717.pdf
*CRNN구조
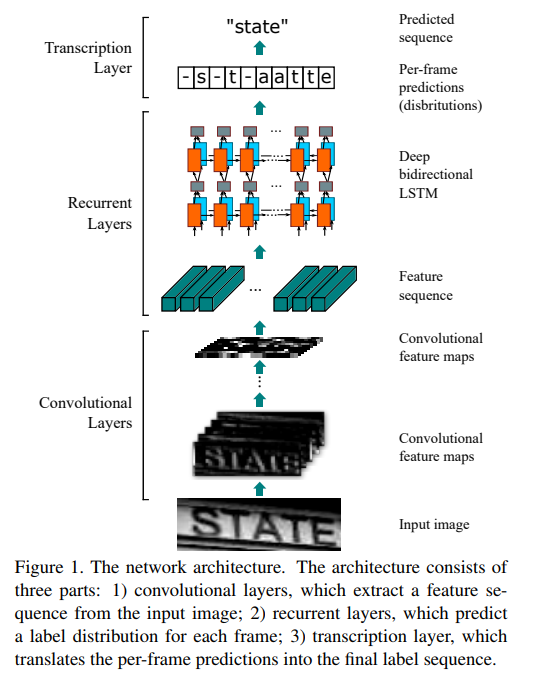
-
입력이미지가 conv_layer를 통과해 feature 추출
-
Recurrent layer는 추출된 feature의 context파악, 다양한 크기에 output대응 가능
-
Transcription layer: step마다 어떤 character의 확률 높은지 예측
NUMBERS = "0123456789"
ENG_CHAR_UPPER = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
TARGET_CHARACTERS = ENG_CHAR_UPPER + NUMBERS
print(f"The total number of characters is {len(TARGET_CHARACTERS)}")
! pip install lmdb## 필요한 라이브러리 import 및 MJ데이터셋 위치 파악
import re
import six
import math
import lmdb
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tensorflow.keras.utils import Sequence
from tensorflow.keras import backend as K
from tensorflow.keras.models import load_model
BATCH_SIZE = 128
HOME_DIR = os.getenv('HOME')+'/aiffel/ocr'
TRAIN_DATA_PATH = HOME_DIR+'/data/MJ/MJ_train'
VALID_DATA_PATH = HOME_DIR+'/data/MJ/MJ_valid'
TEST_DATA_PATH = HOME_DIR+'/data/MJ/MJ_test'
print(TRAIN_DATA_PATH)Recognition model - Input Image-
-
데이터셋 이미지 확인
-
lmdb를 이용해서 훈련데이터셋의 이미지 4개만 열기
- 실제 shape
- 이미지나 라벨 달려있는지 확인
-
결과
- height: 31~32
- width: 문자열 길이에 따라 다양함
from IPython.display import display
# env에 데이터를 불러올게요
# lmdb에서 데이터를 불러올 때 env라는 변수명을 사용하는게 일반적이에요
env = lmdb.open(TRAIN_DATA_PATH,
max_readers=32,
readonly=True,
lock=False,
readahead=False,
meminit=False)
# 불러온 데이터를 txn(transaction)이라는 변수를 통해 엽니다
# 이제 txn변수를 통해 직접 데이터에 접근 할 수 있어요
with env.begin(write=False) as txn:
for index in range(1, 5):
# index를 이용해서 라벨 키와 이미지 키를 만들면
# txn에서 라벨과 이미지를 읽어올 수 있어요
label_key = 'label-%09d'.encode() % index
label = txn.get(label_key).decode('utf-8')
img_key = 'image-%09d'.encode() % index
imgbuf = txn.get(img_key)
buf = six.BytesIO()
buf.write(imgbuf)
buf.seek(0)
# 이미지는 버퍼를 통해 읽어오기 때문에
# 버퍼에서 이미지로 변환하는 과정이 다시 필요해요
try:
img = Image.open(buf).convert('RGB')
except IOError:
img = Image.new('RGB', (100, 32))
label = '-'
# 원본 이미지 크기를 출력해 봅니다
width, height = img.size
print('original image width:{}, height:{}'.format(width, height))
# 이미지 비율을 유지하면서 높이를 32로 바꿀거에요
# 하지만 너비를 100보다는 작게하고 싶어요
target_width = min(int(width*32/height), 100)
target_img_size = (target_width,32)
print('target_img_size:{}'.format(target_img_size))
img = np.array(img.resize(target_img_size)).transpose(1,0,2)
# 이제 높이가 32로 일정한 이미지와 라벨을 함께 출력할 수 있어요
print('display img shape:{}'.format(img.shape))
print('label:{}'.format(label))
display(Image.fromarray(img.transpose(1,0,2).astype(np.uint8)))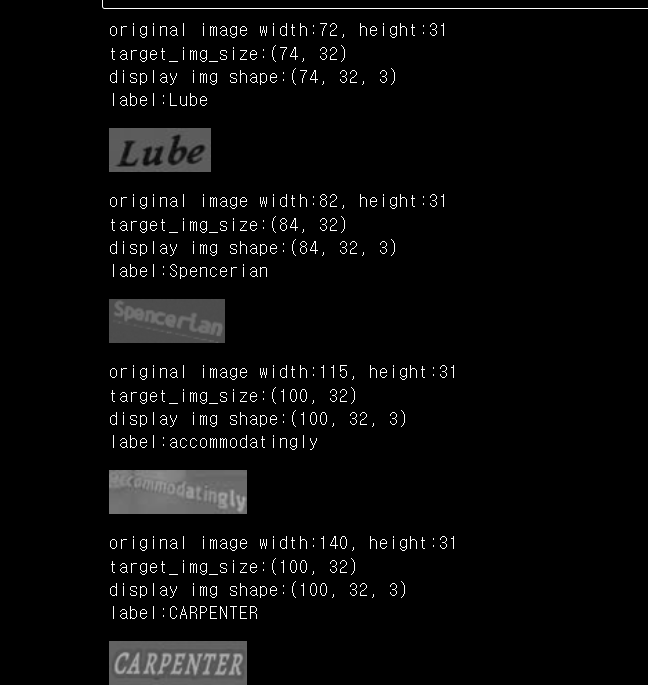
MJSynth 데이터 클래스 구현
-
lmdb활용
-
dataset_path: 읽을 데이터셋 경로
-
label_converter: 문자를 미리 정의된 index로 변환
-
Convert직접 구현(입력)
- batch_size
- 입력이미지 크기
- 필터링을 위한 최대 글자 수
- 학습 대상을 한정하기 위한 character
-
결과
-
_get_img_label()메소드
이미지 데이터를 img, label의 쌍으로 가져온다.
-
model.fit()
getitem()메소드에서 배치 단위만큼 _get_img_label()을 이용하여 가져온 데이터셋 리턴
-
_get_img_label()
height=32, width는 최대 100
-
class MJDatasetSequence(Sequence):
# 객체를 초기화 할 때 lmdb를 열어 env에 준비해둡니다
# 또, lmdb에 있는 데이터 수를 미리 파악해둡니다
def __init__(self,
dataset_path,
label_converter,
batch_size=1,
img_size=(100,32),
max_text_len=22,
is_train=False,
character='') :
self.label_converter = label_converter
self.batch_size = batch_size
self.img_size = img_size
self.max_text_len = max_text_len
self.character = character
self.is_train = is_train
self.divide_length = 100
self.env = lmdb.open(dataset_path, max_readers=32, readonly=True, lock=False, readahead=False, meminit=False)
with self.env.begin(write=False) as txn:
self.num_samples = int(txn.get('num-samples'.encode()))
self.index_list = [index + 1 for index in range(self.num_samples)]
def __len__(self):
return math.ceil(self.num_samples/self.batch_size/self.divide_length)
# index에 해당하는 image와 label을 읽어옵니다
# 위에서 사용한 코드와 매우 유사합니다
# label을 조금 더 다듬는 것이 약간 다릅니다
def _get_img_label(self, index):
with self.env.begin(write=False) as txn:
label_key = 'label-%09d'.encode() % index
label = txn.get(label_key).decode('utf-8')
img_key = 'image-%09d'.encode() % index
imgbuf = txn.get(img_key)
buf = six.BytesIO()
buf.write(imgbuf)
buf.seek(0)
try:
img = Image.open(buf).convert('RGB')
except IOError:
img = Image.new('RGB', self.img_size)
label = '-'
width, height = img.size
target_width = min(int(width*self.img_size[1]/height), self.img_size[0])
target_img_size = (target_width, self.img_size[1])
img = np.array(img.resize(target_img_size)).transpose(1,0,2)
# label을 약간 더 다듬습니다
label = label.upper()
out_of_char = f'[^{self.character}]'
label = re.sub(out_of_char, '', label)
label = label[:self.max_text_len]
return (img, label)
# __getitem__은 약속되어있는 메서드입니다
# 이 부분을 작성하면 slice할 수 있습니다
# 자세히 알고 싶다면 아래 문서를 참고하세요
# https://docs.python.org/3/reference/datamodel.html#object.__getitem__
#
# 1. idx에 해당하는 index_list만큼 데이터를 불러
# 2. image와 label을 불러오고
# 3. 사용하기 좋은 inputs과 outputs형태로 반환합니다
def __getitem__(self, idx):
# 1.
batch_indicies = self.index_list[
idx*self.batch_size:
(idx+1)*self.batch_size
]
input_images = np.zeros([self.batch_size, *self.img_size, 3])
labels = np.zeros([self.batch_size, self.max_text_len], dtype='int64')
input_length = np.ones([self.batch_size], dtype='int64') * self.max_text_len
label_length = np.ones([self.batch_size], dtype='int64')
# 2.
for i, index in enumerate(batch_indicies):
img, label = self._get_img_label(index)
encoded_label = self.label_converter.encode(label)
# 인코딩 과정에서 '-'이 추가되면 max_text_len보다 길어질 수 있어요
if len(encoded_label) > self.max_text_len:
continue
width = img.shape[0]
input_images[i,:width,:,:] = img
labels[i,0:len(encoded_label)] = encoded_label
label_length[i] = len(encoded_label)
# 3.
inputs = {
'input_image': input_images,
'label': labels,
'input_length': input_length,
'label_length': label_length,
}
outputs = {'ctc': np.zeros([self.batch_size, 1])}
return inputs, outputs
print("슝~")Recognition model Encode
- LabelConverter클래스
각 character를 class로 생각하여 step에 따른 class index로 변환 후 encode하기
- init()
입력받은 text를 self.dict에 각 character들이 어떤 index에 매칭되는지 저장하고 character과 index정보를 통해 모델이 학습하는 output생성
- 공백 문자 지정
공백 문자를 뜻하기 위해 '-'활용하여 label=0으로 지정
- decode()
index를 다시 character로 변환 후 이어주고 우리가 읽을 text로 바꿔줌
class LabelConverter(object):
def __init__(self, character):
self.character = "-" + character
self.label_map = dict()
for i, char in enumerate(self.character):
self.label_map[char] = i
def encode(self, text):
encoded_label = []
for i, char in enumerate(text):
if i > 0 and char == text[i - 1]:
encoded_label.append(0) # 같은 문자 사이에 공백 문자 label을 삽입
encoded_label.append(self.label_map[char])
return np.array(encoded_label)
def decode(self, encoded_label):
target_characters = list(self.character)
decoded_label = ""
for encode in encoded_label:
decoded_label += self.character[encode]
return decoded_label
print("슝~")
#L이 연속되고 그 사이에 공백 문자 포함
label_converter = LabelConverter(TARGET_CHARACTERS)
encdoded_text = label_converter.encode('HELLO')
print("Encdoded_text: ", encdoded_text)
decoded_text = label_converter.decode(encdoded_text)
print("Decoded_text: ", decoded_text)Recognition model Build CRNN model
위의 과정에서 입력과 출력을 준비했으니 모델을 만들어보도록 합니다.
- K.ctc_batch_cost()
CTC Loss함수를 구현하기 위한 것으로 어떤 값을 넘겨하는지 파악할 수 있게 됩니다.
def ctc_lambda_func(args): # CTC loss를 계산하기 위한 Lambda 함수
labels, y_pred, label_length, input_length = args
y_pred = y_pred[:, 2:, :]
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
print("슝~")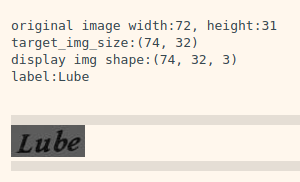
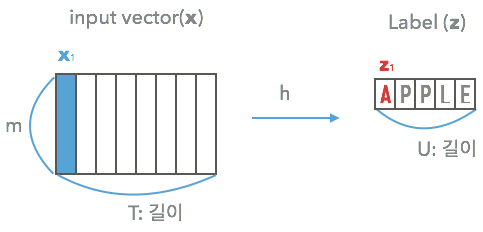
y_true: 실제 라벨 LUBE. 텍스트 라벨 그대로가 아니라, 각 글자를 One-hot 인코딩한 형태로서, max_string_length 값은 모델에서 22로 지정할 예정
y_pred: 우리가 만들 RCNN 모델의 출력 결과. 길이는 4가 아니라 우리가 만들 RNN의 최종 출력 길이로서 24가 될 예정
input_length tensor: 모델 입력 길이 T로서, 이 경우에는 텍스트의 width인 74
label_length tensor: 라벨의 실제 정답 길이 U로서, 이 경우에는 4
def build_crnn_model(input_shape=(100,32,3), characters=TARGET_CHARACTERS):
num_chars = len(characters)+2
image_input = layers.Input(shape=input_shape, dtype='float32', name='input_image')
# Build CRNN model
conv = layers.Conv2D(64, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal')(image_input)
conv = layers.MaxPooling2D(pool_size=(2, 2))(conv)
conv = layers.Conv2D(128, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal')(conv)
conv = layers.MaxPooling2D(pool_size=(2, 2))(conv)
conv = layers.Conv2D(256, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal')(conv)
conv = layers.Conv2D(256, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal')(conv)
conv = layers.MaxPooling2D(pool_size=(1, 2))(conv)
conv = layers.Conv2D(512, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal')(conv)
conv = layers.BatchNormalization()(conv)
conv = layers.Conv2D(512, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal')(conv)
conv = layers.BatchNormalization()(conv)
conv = layers.MaxPooling2D(pool_size=(1, 2))(conv)
feature = layers.Conv2D(512, (2, 2), activation='relu', kernel_initializer='he_normal')(conv)
sequnce = layers.Reshape(target_shape=(24, 512))(feature)
sequnce = layers.Dense(64, activation='relu')(sequnce)
sequnce = layers.Bidirectional(layers.LSTM(256, return_sequences=True))(sequnce)
sequnce = layers.Bidirectional(layers.LSTM(256, return_sequences=True))(sequnce)
y_pred = layers.Dense(num_chars, activation='softmax', name='output')(sequnce)
labels = layers.Input(shape=[22], dtype='int64', name='label')
input_length = layers.Input(shape=[1], dtype='int64', name='input_length')
label_length = layers.Input(shape=[1], dtype='int64', name='label_length')
loss_out = layers.Lambda(ctc_lambda_func, output_shape=(1,), name="ctc")(
[labels, y_pred, label_length, input_length]
)
model_input = [image_input, labels, input_length, label_length]
model = Model(
inputs=model_input,
outputs=loss_out
)
return model
print("슝~")Recognition model Train & Inference
# 데이터셋과 모델을 준비합니다
#MJDatasetSequence로 데이터 분리 후 구성된 데이터셋으로 학습
train_set = MJDatasetSequence(TRAIN_DATA_PATH, label_converter, batch_size=BATCH_SIZE, character=TARGET_CHARACTERS, is_train=True)
val_set = MJDatasetSequence(VALID_DATA_PATH, label_converter, batch_size=BATCH_SIZE, character=TARGET_CHARACTERS)
model = build_crnn_model()
# 모델을 컴파일 합니다
optimizer = tf.keras.optimizers.Adadelta(lr=0.1, clipnorm=5)
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer=optimizer)
# 훈련이 빨리 끝날 수 있도록 ModelCheckPoint와 EarlyStopping을 사용합니다
checkpoint_path = HOME_DIR + '/model_checkpoint.hdf5'
ckp = tf.keras.callbacks.ModelCheckpoint(
checkpoint_path, monitor='val_loss',
verbose=1, save_best_only=True, save_weights_only=True
)
earlystop = tf.keras.callbacks.EarlyStopping(
monitor='val_loss', min_delta=0, patience=4, verbose=0, mode='min'
)
model.fit(train_set,
steps_per_epoch=len(train_set),
epochs=20,
validation_data=val_set,
validation_steps=len(val_set),
callbacks=[ckp, earlystop])# 테스트셋을 통해 확인
test_set = MJDatasetSequence(TEST_DATA_PATH, label_converter, batch_size=BATCH_SIZE, character=TARGET_CHARACTERS)
model = build_crnn_model()
model.load_weights(checkpoint_path)
# crnn 모델은 입력이 복잡한 구조이므로 그대로 사용할 수가 없습니다
# 그래서 crnn 모델의 입력중 'input_image' 부분만 사용한 모델을 새로 만들겁니다
# inference 전용 모델이에요
input_data = model.get_layer('input_image').output
y_pred = model.get_layer('output').output
model_pred = Model(inputs=input_data, outputs=y_pred)
#모델 성능 확인
from IPython.display import display
# 모델이 inference한 결과를 글자로 바꿔주는 역할을 합니다
# 코드 하나하나를 이해하기는 조금 어려울 수 있습니다
def decode_predict_ctc(out, chars = TARGET_CHARACTERS):
results = []
indexes = K.get_value(
K.ctc_decode(
out, input_length=np.ones(out.shape[0]) * out.shape[1],
greedy=False , beam_width=5, top_paths=1
)[0][0]
)[0]
text = ""
for index in indexes:
text += chars[index]
results.append(text)
return results
# 모델과 데이터셋이 주어지면 inference를 수행합니다
# index개 만큼의 데이터를 읽어 모델로 inference를 수행하고
# 결과를 디코딩해 출력해줍니다
def check_inference(model, dataset, index = 5):
for i in range(index):
inputs, outputs = dataset[i]
img = dataset[i][0]['input_image'][0:1,:,:,:]
output = model.predict(img)
result = decode_predict_ctc(output, chars="-"+TARGET_CHARACTERS)[0].replace('-','')
print("Result: \t", result)
display(Image.fromarray(img[0].transpose(1,0,2).astype(np.uint8)))
check_inference(model_pred, test_set, index=10)
