텍스트 감성분석(Text Sentimental Analysis)
-
정의: 텍스트에 나타난 주관적 요소인 긍정과 부정을 판별한 후 정량화하는 작업.
-
기본요소: 감성 표현, 대상(개체)
-
단계:
i) 데이터 수집 단계
:인터넷 매체에서 정보를 수집
ii) 주관성 탐지
: 작성자의 주관이 드러난 부분만 걸러냄.
iii) 주관성의 극성
: 미리 정의된 극성(긍정, 중립, 부정등) 이나 점수로 표현
-
수행 방법
i) 기계학습 기반 접근법
: 패턴을 학습해 예측 모형 구축 후 학습한 데이터와 유사한 특성을 갖는 분석 대상 데이터 적용
: 긍정 혹은 부정으로 분류된 라벨이 있어야함.
ii) 감성사전 기반 접근법
: 충분한 분류된 라벨이 없을 때 사용한다.
: 수집된 데이터를 전처리를 하여 정제를 한 후 미리 구축된 감성사전과 매칭하여 어느 쪽 극성어가 나오는지 정량화하여 분석한다.
: 감성사전은 극성 범주 값과 범주별 특성을 나타내는 감성 점수로 구성. 품질과 직결.
-
단점
- 분석 대상에 따라 단어의 감성 점수가 달라질 가능성에 대응 못함
- 긍부정의 원인이 되는 대상 속성 기반의 감성 분석이 어려움
: 딥러닝 예시
- 기계학습 기법 중 지도학습 기법
- 나이브 베이즈 분류기
- 결정트리 분류기
- kNN 분류기
- 신경망 분류기
- SVM
- 최대 엔트로피 모델
iii) 속성 단위 감성 분석
: 정교한 분석 방법으로 대상이 무엇인지, 그 대상이 갖고 있는 특성은 무엇인지 파악.
-
-
워드 임베딩 기술
: 단어의 의미가 유사할 경우 벡터 공간상에 가깝게 배치를 통해 어휘적 관계를 벡터로 표현
ex) Word2vec(구글팀)
- DNN기반 감성분석
: 차원수가 많아져도 성능 저하 보완.
: 변수 추출 과정 없이 텍스트에서 자동 특성 추출
ex) CNN, LSTM
-
실생활예시(에뛰드 하우스)
I) 데이터 수집 : 데이터 정제 작업
II) 데이터 전처리 : 수집 후 전처리 작업(단어 식별, 의미정보 변환)
III) 형태소 사전의 구축: 수집 단어 분석을 통해 사전에 단어들을 선별하고 추가하여 데이터 손실없이 인프라 수축
IV) 속성어 사전 구축: 화자가 어느 속성에 관해 서술하는지 파악.
V) 감성어 사전 구축: 감성와 감성어별 극성및 강도로 구성되고, 수집된 다수 문서의 형태소 기반으로 감성어 도출. 속성에 따라 극성이 변하는 형태를 특이 감성어라고도 함
VI) 감정 분석 모형의 구축 및 결과 도출: 사전기반 방법과 속성어와 감성어의 문장패턴 고려규칙 기반.
텍스트 데이터의 특징
-
단순한 특징: 문장을 받아 긍정이면 1, 부정이면 0을 의미한다
-
텍스트 -> 숫자
i) 문장을 단위로 쪼갠후 딕셔너리 구조({텍스트:인덱스})로 표현.
ii) 함수로 만들어서 반복하여 활용.
-
Embedding 레이어
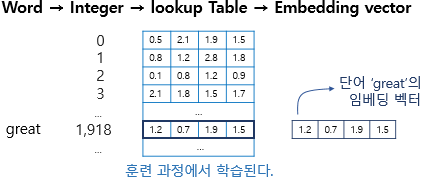
: 단어의 의미를 나타내는 벡터를 파라미터로 놓고 딥러닝을 통해 최적화한 후 Tensorflow, Pytorch등의 딥러닝 프레임워크들이 의미 벡터 파라미터 구현 후 레이어 제공.
: 인풋이 되는 문장벡터는 그 길이가 일정해야하므로 일정하지 않을 시 패딩을 추가하여 길이를 맞춰야 한다.
:shape(a,b,c) -> a- 입력문장 개수, b -입력문장의 최대 길이, c-워드 벡터의 차원 수
RNN
: 텍스트 데이터를 다루는데 주로 사용되는 딥러닝 모델
: 시퀀스 데이터(입력이 시간축을 따라 발생하는 데이터)를 다룬다.
IMDB
- 데이터셋 분리
-
테스트 데이터와 훈련 데이터를 분리한다.
-
사전에 등재할 단어의 갯수 설정(imdb.load_data())
-
인코딩한다.
-
문장의 길이 통일(pad_sequence)
+) padding = pre가 조금 더 유리하고 10% 이상의 테스트 성능 차이를 보임
-
딥러닝 모델 설계와 훈련
-
RNN모델 설계
-
모델 학습
-
테스트셋으로 학습이 끝난 모델 평가
-
그래프를 그려서 트레이닝의 최적점 추정
-
-
Word2Vec적용
- 워드 임베딩: 저차원 벡터값 표현
- Embedding 레이어: 사전의 단어 개수 * 워드 벡터 사이즈 크기를 가진 학습 파라미터
- gensim 패키지, 임베딩 파라미터 읽어서 word vector 활용
- 유사도 확인
