데이터관리 프로그램 만들기
파일 시스템 활용(클래스와 함수이용)
-
문제 설명
-
summarize()함수 그리고 의사 코드
def summarize():
#파일 이름을 입력받는다.
#파일을 읽기 모드로 열어 한 줄씩 파일을 읽는다.
#파일의 각 행의 데이터 속성을 갖는 인스턴스 객체(사원객체)를 만든다.
# 사전에 employee 클래스 설계 필요!
# 사전에 인스턴스 사원 객체를 만드는 함수 필요!
#월급이 가장 높은 사원을 찾는 코드를 구현한다.
#결과를 출력한다.
pass -
Employee Class
-
make_employee()함수
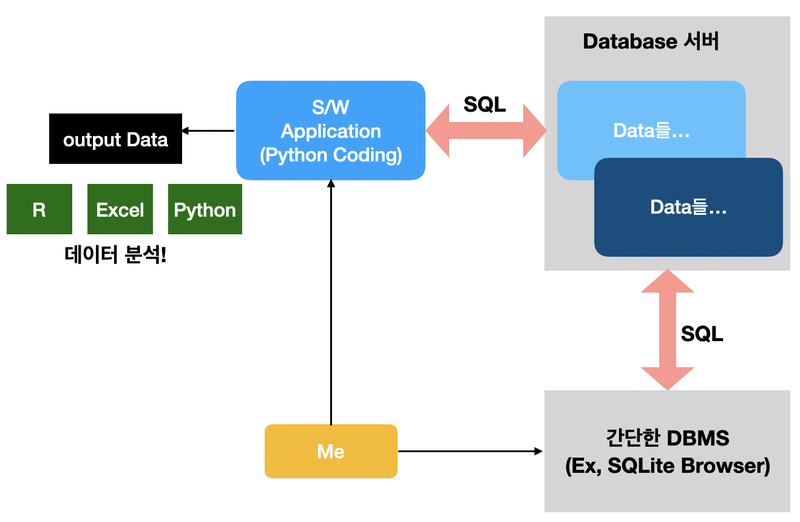
Pandas 와 csv파일
- Pandas
-
흩어져있는 파일을 효과적으로 모은다.
-
데이터 합치기:merge,join,concat
- merge(): 공통의 칼럼에 있는 값을 키로 사용하여 합침, on인자에 키 값을 넣어-> 공통 칼럼 여러 개인 경우 대비하고 값이 될 필드가 1개여도 명확한 코드 작성 위해 키 캆을 담은 컬럼의 이름 지정해줌
- inner join: 공통의 데이터에 대해서만 데이터 합치기
- outer join: 전체 데이터에 합치는 연산
- concat(): 이어 붙이기,연결. axis =1 (column방향)으로 합치기 가능
-
공통 칼럼이 있을 때,키로 지정하여 합치기 연산
Pandas 기능
- 필터링
-
조건에 따라 특정 데이터 선택
- 몇 개의 행 먼저 고르기 -> 원하는 컬럼만 선택
- 컬럼 선택 후 특정 행만 선택
- df['컬럼명'] 형식 사용
-
탐색
-
loc()사용: 라벨을 사용하여 행 또는 열 지정 후 추출, 슬라이싱 연산 가능
-
iloc()사용: 정수 인덱스 사용하여 행 또는 열 지정 후 데이터 추출 df.iloc[[행],[열]] , 컬럼이름 지정안됨
-
- 그룹 질의
-
그룹연산 :groupby(), apply()
-
groupby(): 키 값에 따라 그룹을 묶어 원하는 연산 수행
-
groupby()객체의 연산을 수행
-
max(), min(), sum(), mean(
-
apply()메소드를 통해 특수 수식어 연산 수행
-
import numpy as np
df.groupby(['Columns1']).max().apply(np.sqrt)
데이터베이스
-
트랜잭션 처리 기능( 다수 사용자 대응)
-
데이터 관리 프로세스 필요( 데이터의 정합성 보장)
-
데이터베이스,서버,데이터만 관리하는 컴퓨터
-
데이터 서버 컴퓨터, 추상적인 정보의 집합
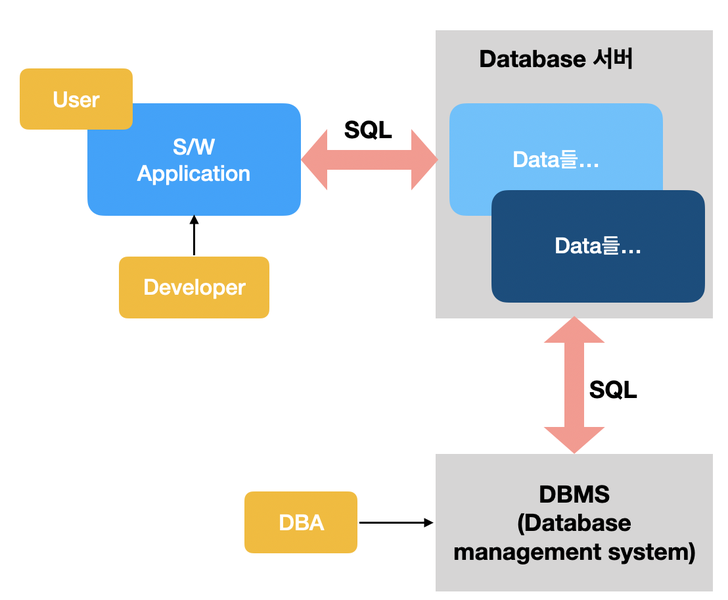
쿼리(query)
-
요청 과정
- 데이터만을 위한 데이터 서버
- 전용 프로그래믕ㄹ 통해서 데이터 읽고 수정
- 구조적 질의어로 데어터 서버에게 원하는 정보를 일목요연하게 알려준다.
관계형 데이터베이스
-
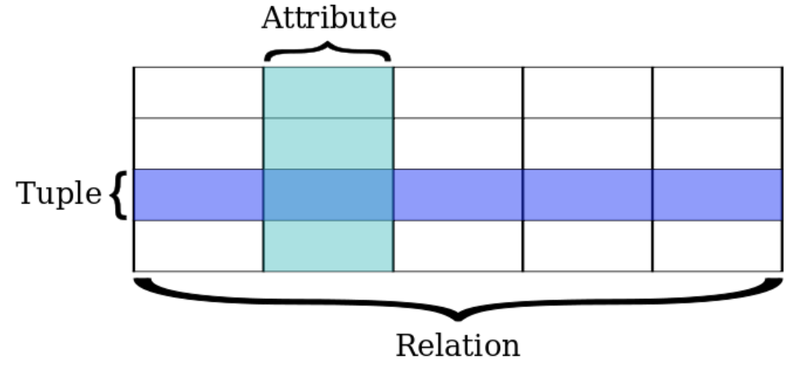
정의: 키와 값들의 간단한 관계를 테이블화 시킨 것으로즉,속성과 튜플로 이루어진 관계
-
특징:
-
데이터를 컬럼과 로우를 이루는 하나 이상의 테이블을 정리하고, 고유 키가 로우를 식별한다.
-
로우는 레코드나 튜플로 불린다
-
각 테이블의 관계는 하나의 객체 타입
-
로우는 객체 종류의 인스턴스
-
컬럼은 인스턴스의 속성이 되는 값
-
Attribute : 테이블의 열부분으로 정보의 속성항목
-
Tuple는 테이블의 행으로 개별 데이터

-
SQL
-
데이터 정의와 조작을 가능하게 함
-
원하는 결과를 질의하는 언어의 형태
-
클라이언트에서 데이터 서버로 전송하는 텍스트 문자열
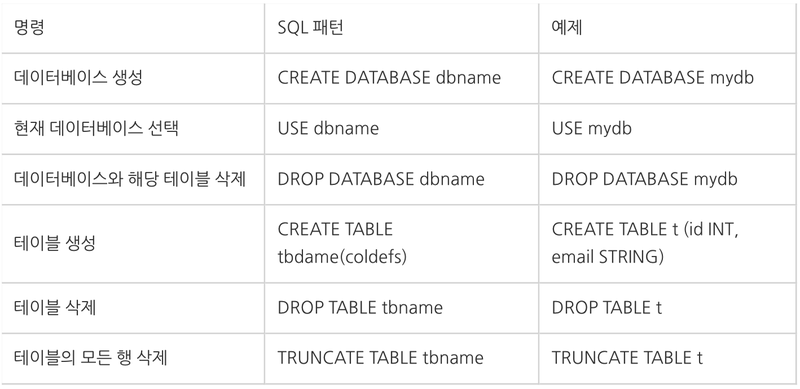
SQL문 종류
- DDL(데이터 정의어)
-
테이블, 관계의 구조 생성
-
테이블,데이터베이스,사용자에 대한 생성, 삭제 제약조건, 권한 설정
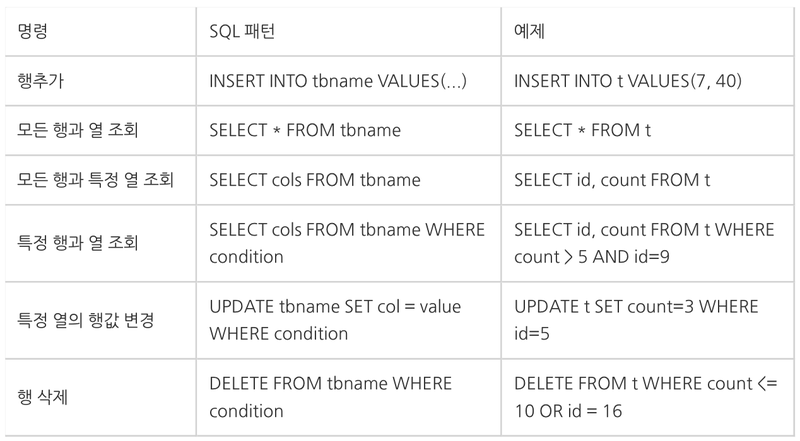
- DML(데이터 조작어)
-
생성(Create): INSERT문 사용
-
조회(Read): SELECT문 사용
-
갱신(Update): UPDATE문 사용
-
삭제(Delete): DELETE문 사용
파이썬 DB-API
API 메인 함수
-
connect(): 데이터베이스의 연결을 만든다.
-
cursor(): 질의를 관리하기 위한 커서 객체를 만든다. (file의 open과 비슷)
-
execute(), excutemany(): 데이터베이스에 하나 이상의 SQL명령을 실행한다.
-
commit(): DB반영
-
close():종료
-
fetchone(), fetchmany(), fetchall(): 실행 결과를 얻는다.

