CS
1. OpenCV 와 Pillow의 기초 배우기

\-화소(pixel): 색상을 가진 점 하나\-RGB:화소는 세 개의 단일 샥의 강도 조절로 표현 <각 점 하나하나의 색상 값 저장> \-한 점마다 각 색상별로 8비트 사용래스터(raster) - 사진 파일이 주로 쓰임비트맵(bitmap)<벡터(Vector
2.기초 프로그램(1)
Ubutu 18.04:데비안 GNU/리눅스 기반으로 만들어진 고유한 데스크탑 환경을 사용하는 리눅스 배포판입니다. 운영체제. \-가상환경(virtual environment):컴퓨터에 설치된 패키지 간의 충돌 방지 ex)아나콘다(Anaconda)Python 3.7.9
3.리눅스 운영체제
목표 OS구성과 Kernel,Shell 역할 자주 쓰이는 리눅스 명령어 배우기 OS구성과 Kernel 역할 1.OS구성 -제어 프로그램 +)감시 프로그램(Supervisor) :각종 프로그램의 실행과 처리에 관여. +) 작업관리 프로그
4.주사위 속 CS
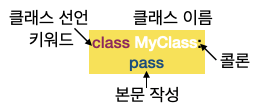
링크텍스트 \-객체: 속성(상태,변수) 과 메소드(동작, 함수)를 갖는 것으로 모든 변수에 할당할 수 있고 인자로 념겨지는 것들의 총칭 \-객체 지향 프로그램: 객체를 활용한 프로그래밍으로 자신만의 데이터와 프로시저를 갖고 각 객체들을 서로 연결되어 다른 객체
5.Git, GitHub, Jupyter Notebook,Markdown 사용법
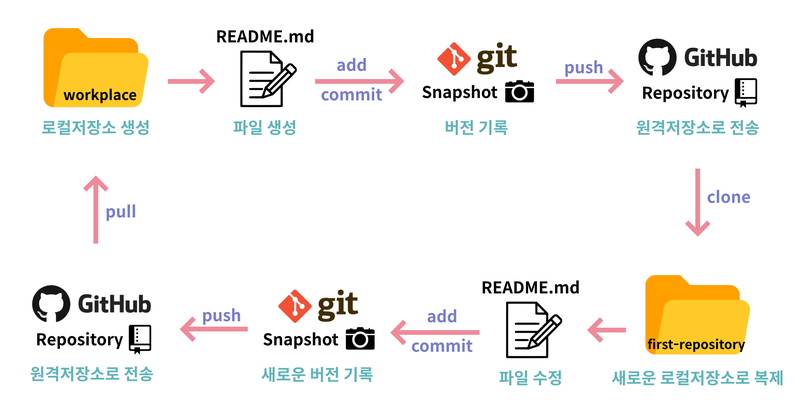
목차 1. Git 2. GitHub 3. Jupyter Notebook Git 정의 : 버전을 기록해두고 관리하는 소스코드 버전 관리 시스템 특징 : Local에서 작업함 GitHub 정의: 프로젝트 호스팅하고 협업할 수 잇는 온라인 서비스 특징: 웹사이트로, G
6.머신러닝 구현 (by 사이킷런)
머신러닝 알고리즘사이킷런에서 알고리즘Scikit-Learn\-데이터 표현법\-회귀 모델 실습\-datasets모듈1.데이터의 크기, 품질, 특성 2.가용 연산(계산) 시간 3.작업의 긴급성 4.데이터를 이용해 하고 싶은 것1.정의: 특정문제에 적합한 알고리즘 선택 도움
7.문자열, 파일 사용법
인(디) 코딩문자열 다루기정규 표현식파일디렉토리모듈과 패키지1.CSV2.XML3.JSON기본 단위\-바이트(byte): 컴퓨터의 기본 저장 단위\-유니코드: 최상위 문자인코딩 과 디코딩i)인코딩: 문자열->바이트(사람언어-> 컴퓨터 언어)ex)ord(): 문자-> 유니
8.딥러닝 그리고 신경망
정의: 사람에 의해서 가공된 데이터를 입력하는 것이 아닌 가공되지 않은 데이터를 입력받아서 결과 도출데이터 표현(계층적 관계로, 1~4번으로 내려갈 수록 사람 개입이 커짐)1.분자형태: 가공을 거치지 않은 데이터2.이미지; 조금 가공된 시각적 표현3.표 : 데이터가
9.딥러닝 메커니즘
신경망활성함수와 손실함수경사하강법오차역전파법Step by Step추론과정 구현 및 정확도 계산전체 학습\-인공신경망: 생물학적 뉴런의 네트워크에서 영감받은 머신러닝 모델로 딥러닝의 핵심이다 그 이유는 강력하고 확정이 좋기 때문이다.\-퍼셉트론: 인간의 뇌 속의 신경망
10.EDA
:데이터를 하나하나 뜯어본다.:데이터 -> 탐색과정 -> matoplib로 시각화.1) 데이터 다운로드 받기2) 데이러 불러오기 2-1) 라이브러리 가져오기 \-Numpy: 1차원 또는 2차원 형식의 표 데이터 다룸 import numpy as np \-p
11.Visualization
PandasMatplotlibSeaborn선 그래프 그리기데이터 정의:모듈을 import하고 그래프로 그릴 데이터 정의.Pandas Series 데이터 활용Series 데이터 활용(선 그래프 그리기 최적 구조)price = date'Close'price.plot(ax=
12.다양한 데이터 전처리 기법
데이터 준비하자import pandas as pdimport numpy as npimport matplotlib.pyplot as pltprint("👽 Hello.")import oscsv_file_path = os.getenv('HOME')+'/aiffel/data
13.회귀
정의: 여러 데이터 기반으로 연속형 변수 관계의 모델링하고 적합도 측정. 즉, 독립변수와 종속변수 사이의 상호 관련성을 규명하는 것입니다.예시: 부모 키와 자식 키 관계, 집값예측, 자동차 스펙을 통해 가격 예측종류: 선형 회귀 분석 / 로지스틱 회귀 분석특징: 지도학
14.Deep 비지도학습
정의 : training data without label, 이것을 가지고 학습하는 방식 군집화(clustering) 정의: 명확한 분류 기준이 없는 상태에서 유사한 것끼리 그룹화를 시키는 것 사용분야: 데이터 분석, 고객 분류, 추천시스템, 검색 엔지, 이미
15.Tensorflow2
특징: 딥러닝 프레임워크. : forward propagation 모델 설계 시 gradient를 미리 구할 수 있다.(by 유향 비순환 그래프노드-엣지).: 사용하기 쉬움: 즉시 실행: 설계 구현 용이성: 데이터 파이프라인 단순화: 입력부터 출력까지 레이어를 차곡 차
16.Deep-Network
ReLU: 같은 정확도 유지 하면서 빠르다.(Tanh보다 좋은 성능)Dropout: 과적합을 막기 위한 용도로, 뉴런 중 일부를 생략(뉴런의 값=0)하면서 학습.이렇게 하면 값이 0인 뉴런들은 순전파와 역전파에 영형을 주지 못한다.Overlapping pooling:
17.Linear, Convolution
레이어 개념레이어 동작 방식레이어 설계 Tensorflow 정의(m,n) 행렬 -> dataframe(C,W,H) -> Channel , Width, HeightChannel : 이미지 데이터정의: 하나의 물체가 여러 개의 논리적인 객체로 구성.정의: 선형변환과 동일한
18.Solution of Overfitting
: train set은 잘 맞추나 validation/test set는 그렇지 못한 현상정의: train set이 정답을 못 맞추게 하면서 오버피팅을 방해합니다. 그로 인해 train loss는 증가를 하지만 validation/ test loss는 감소가 됩니다.(오
19.Embedding, Recurrent Layer
LSTM in Recurrent layer
20.활성화함수
선형성질\--> T(0) =0. 모든 x,y는 V공간에 속하고 c는 실수에 대한 다음 식과 동치.T(cx+y) = cT(x) + T(y) T(x-y) = T(x) - T(y)1-1. 선형 변환: 선형이라는 공간적 규칙을 잘 지키면서 V공간상의 벡터를 W공간 상의
21.베이지안 머신러닝 모델
모델 형성 후 파라미터의 갓 조절을 통해 데이터 분포를 간접적으로 표현모델 표현하는 확률 분포를 데이터의 실제 분포에 가깝게 만드는 최적 파라미터 값 찾기데이터를 통해 파라미터 공간의 확률 분포 학습모델 파라미터가 고정된 값이 아닌 불확실성을 가진 확률 변수로 본다데이
22.정보이론
정의: 어떻게 정보를 정량적으로 표현하는가조건:일어날 가능성이 높은 사건은 정보량이 낮다반드시 일어날 사건에는 정보가 없는 것과 마찬가지이다일어날 가능성이 낮은 사건은 정보량이 높다두 개의 독립적인 사건, 전체 정보량은 각각의 정보량을 더한 것과 같다(log성질)정보량
23.컴퓨터 파워
멀티태스킹 멀티스레드
24.DB
문제 설명summarize()함수 그리고 의사 코드def summarize(): pass Employee Classmake_employee()함수Pandas흩어져있는 파일을 효과적으로 모은다.데이터 합치
25.Python - DB
정의: 임베디드 SQL DB엔진으로 서버 필요없이 DB구현sqlite3를 통해서 Python 과 DB는 연동된다.conn: SQL연결과 관련된 셋팅 포함Cursor : 질의를 수행하고 결과를 얻는 객체SQL SELECT문 사용할 때 이용된다.(조건에 따라 조회)습관적으
26.SQL
정의: DB에서 데이터 조회할 때 필요한 컴퓨터 언어예시:데이터 조회 및 조작파트 담당SELECT \* FROM 도서대출내역 기본 구조:예시 with 코드INT: 숫자의 범위(최소,최대)와 크기가 설정Varchar: 문자형문자형의 특정부분 떼어 내는 함수LEFT:
27.웹 페이지 만들기
마이크로 웹 프레임워크마이크로: 웹 서비스를 구성하는 최소한의 기능을 담고 있고, 확장이 가능한 설계 의미웹: 인터넷 브라우저 통해 보고 있는 공간프레임워크: 문제 해결을 위한 구조CODEfrom flask import Flask: flask패키지에서 Flask모듈 가
28.SQL 처리 페이지
순서SQL문 입력SELECT문이 들어간 SQL문이면 결과화면 보여주도록 넘기기HTML CODEPYTHON CODE결과확인
29.인터넷과 프로토콜
텍스트의 변환과정인 Encoding, Decoding는 여러 대의 컴퓨터에서도 가능하다프로토콜: 데이터 교환 과정에서의 통신 규약( ex: HTTP:하이퍼텍스트 전송)통신: 데이터를 원격 전송 후 다시 수신, 원거리 대화HyperText: 하이퍼링크가 표시되는
30.API
Web표현형식(문서): HTML전송방법(프로토콜): HTTP(요청과 응답하는 서버/클라이언트모델)식별자:URIHTTP메시지Request Method(요청 메소드)GET: read, 정보 요청 HEAD: 헤더 정보만 요청 POST: create, 정보 생성 및 변형할
31.크롤링
CODE: 링크텍스트정의: 웹에서 데이터를 긁어 오는 작업구조: 멀티스레드(웹,HTTP통신) + 큐 형태의 자료구조 이용-> URL이용해서 전달파이썬 크롤링 라이브러리(urllib사용하기)더 좋은 라이브러리(BeautifulSoup, Requests사용)로그인 원리,
32.맵리듀스
정의: 클러스터에 동작하는 알고리즘으로 프로그래밍 모델이다.로직: Map, Shuffle, Reduce특징: 빅데이터 솔루션(하둡, 스파크) 을 다루는 프로그래밍모델로 병렬처리 기반이다.방식: Split-Apply-Combine StrategyI) Split: 특별한
33.빅데이터
2004년, MapReduce on Simplified Data Processing on Large ClustersGFS와 같은 분산 처리 파일 시스템 모델맵 함수와 리듀스함수의 2가지 작업을 나누어 처리맵: 키-값 쌍을 처리해서 중간의 생성리듀스: 동일 키와 연관된