딥네트워크
AlexNet
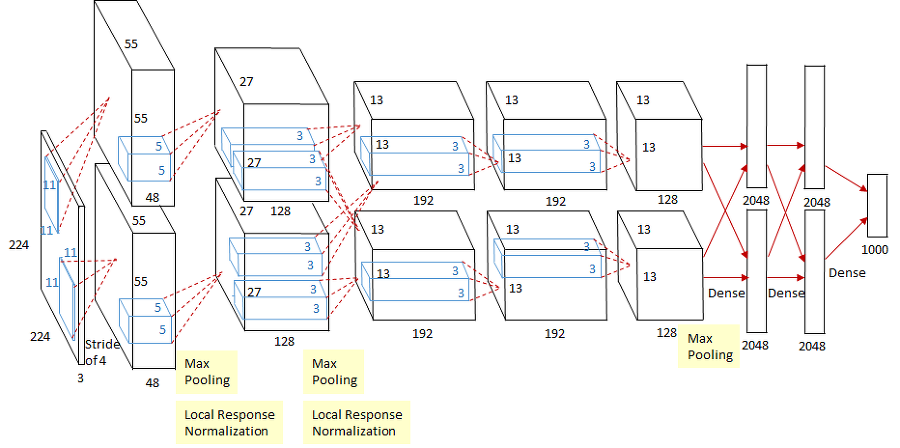
사용된 도구
- ReLU:
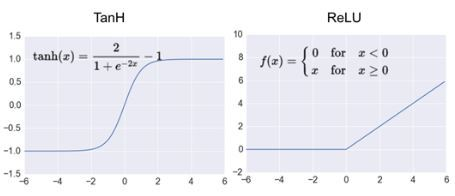
- 같은 정확도 유지 하면서 빠르다.(Tanh보다 좋은 성능)
- Dropout:

- 과적합을 막기 위한 용도로, 뉴런 중 일부를 생략(뉴런의 값=0)하면서 학습.
- 이렇게 하면 값이 0인 뉴런들은 순전파와 역전파에 영형을 주지 못한다.
- Overlapping pooling:
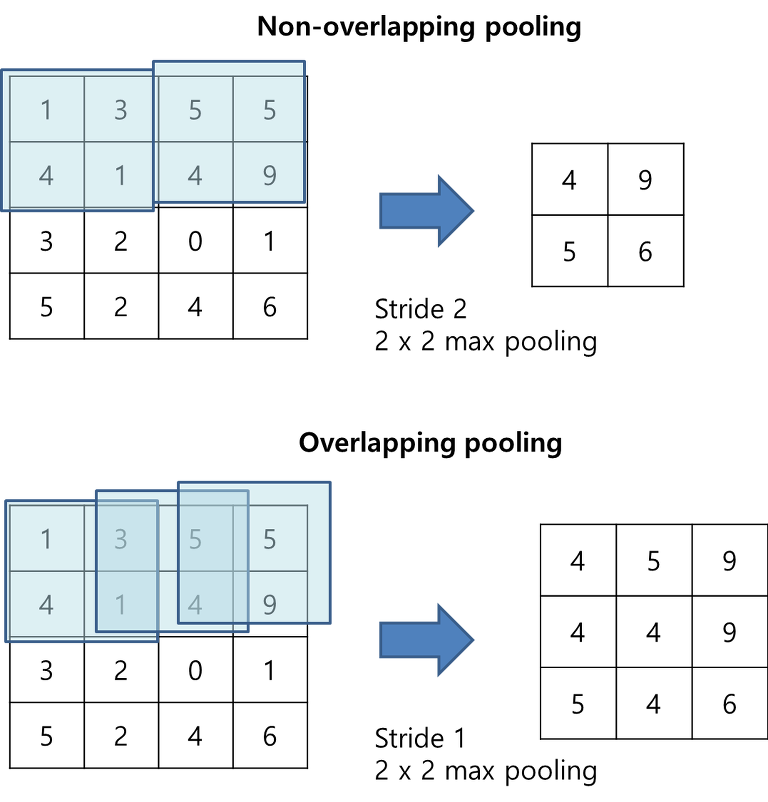
- Convolution으로 인한 특성맵의 크기 줄이기.
- 보폭인(stride)보다 작다. 최대 풀링을 사용하는 기법.
- 커널이 중첩이 된다.
- 에러율 줄여줌
-
LRN:
- 활성화된 뉴런이 주변 뉴런을 누르는 현상으로 인해 정규화가 실행됨. 그로 인해 모든 값이 작아진다
-
data augmentation:
- 데이터 양을 늘려서 과적합을 막는 방법이다.
레이어
- 첫번째 레이어(Convoluational layer) : 초기 stride=4, zero-padding사용안함. 사이즈 축소 방지한다(by 가장자리에 0을 추가). ReLU함수 활성화. overlapping max pooling-> stride=2. local response normalization-> 수렴 속도 증가
-
두번째 레이어(Convoluational layer) : 커널을 사용하여 전 단계의 특성맵 컨볼루션. stride=1, zero-padding=2. ReLU활성화. Overlapping max pooling-> stride=2, local response normalization -> 특성맵 크기 유지
-
세번째 레이어(Convoluational layer) : 3 3 256 - > stride = 1 , zero-padding = 1
-
네번째 레이어(Convoluational layer) : 3 3 192 - > stride = 1 , zero-padding = 1
-
다섯번째 레이어(Convoluational layer) : 3 3 192 - > stride = 1 , zero-padding = 1, overlapping max pooling-> stride=2 --> 6 6 256 특성맵을 얻음
-
여섯번째 레이어(Fully connected layer) : 전 단계 특성맵 -> flatten ->9216차원 벡터 만들어서 4096개의 뉴런가 fully connected해주어서 ReLU함수 활성화
-
일곱번째 레이어(Fully connected layer) : 4096개의 뉴런으로 구성되어 전 단계 뉴런 4096개와 fullyconnected가 되어 있고 출력값은 ReLU
-
여덟번째 레이어(Fully connected layer): 1000개의 뉴런으로 구성되어있고 거기다가전 단계 뉴런 4096개와 fullyconnected가 되어 있다. 출력값은 softmax함수 적용하여 1000개 클래스 각각에 속한다.
VGG
-
구조
i) 3 * 3 커널 -> 다량의 레이어 쌓기 --> 이미지의 비선형성 잡는다.
ii) 3 * 3 커널의 이점
-
가중치 또는 파라미터의 갯수가 적음
-> 학습 속도가 빨라지게 되어 층의 갯수가 증가하고 비선형성 증가.
-
-
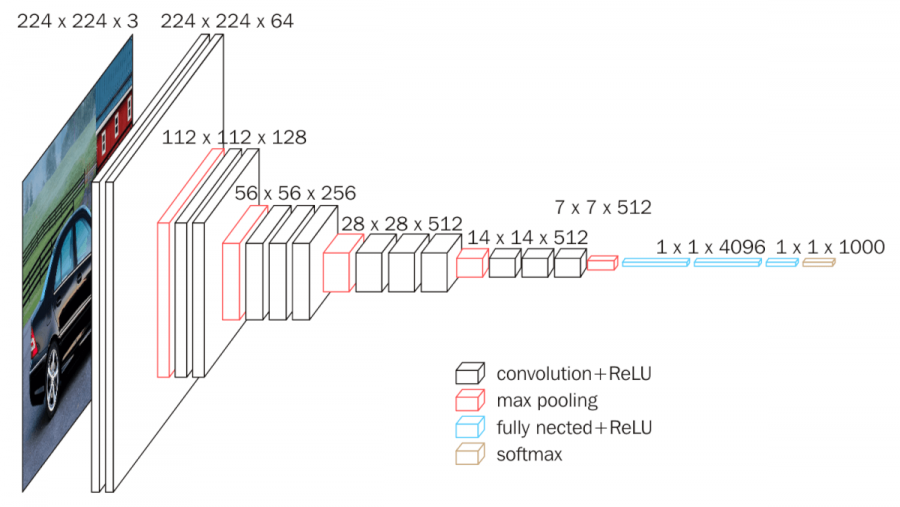
VGG16
-
input: 224 224 3 이미지
-
conv1_1: 64개의 3 3 3 필터커널로 입력이미지 컨볼루션해줌. zero-padding=1, stride =1 --> ReLU함수 적용.
-
conv1_2: 64개의 3 3 3 필터커널로 특성맵을 컨볼루션. max pooling ->stride=2 , 특성맵의 사이즈 줄인다.
-
conv2_1: 128개의 3 3 64 필터커널로 특성맵 컨볼루션. max pooling -> stride = 2, 특성맵의 사이즈 줄이기
-
conv2_2: 128개의 3 3 128 필터커널로 특성맵 컨볼루션. max pooling -> stride = 2, 특성맵의 사이즈 줄이기
-
conv3_1: 256개의 3 3 128 필터커널로 특성맵을 컨볼루션. 256장의 56 * 56 특성맵들이 생성
-
conv3_2: 256개의 3 3 256 필터커널로 특성맵을 컨볼루션. 256장의 56 * 56 특성맵들이 생성
-
conv3_3: 256개의 3 3 256 필터커널로 특성맵을 컨볼루션. 256장의 56 * 56 특성맵들이 생성. max pooling -> stride =2 -> 특성맵의 사이즈 줄임
-
conv4_1: 512개의 3 3 256 필터커널로 특성맵을 컨볼루션. 512장의 28 * 28 특성맵 생성
-
conv4_2: 512개의 3 3 512 필터커널로 특성맵을 컨볼루션. 512장의 28 * 28 특성맵 생성
-
conv4_3: 512개의 3 3 512 필터커널로 특성맵을 컨볼루션. 512장의 28 * 28특성맵 생성. max pooling-> stride =2, 특성맵의 사이즈가 줄어든다
-
conv5_1: 512개의 3 3 512 필터커널로 특성맵을 컨볼루션. 512장의 14 * 14특성맵 생성
-
conv5_2: 512개의 3 3 512 필터커널로 특성맵을 컨볼루션. 512장의 14 * 14특성맵 생성
-
conv5_3: 512개의 3 3 512 필터커널로 특성맵을 컨볼루션. 512장의 14 * 14특성맵 생성. max pooling-> stride =2, 특성맵의 사이즈 줄어든다.
-
fc1: 7 7 512 특성맵 -> flatten(1차원 벡터로 펼치기) -> 25088개의 뉴런이 되고 1층의 4096개의 뉴런과 fully-connected. 그리고 훈련시 dropout가 된다.
-
fc2: 4096개의 뉴런으로 구성되어 있고 fc1층의 4096개의 뉴런과 fully-connected. 훈련시 dropout 적용
-
fc2: 1000개의 뉴런으로 구성되고 fc2층의 4096개의 뉴런과 fully-connected.
출력값은 softmax 함수로 활성화.
-
-
Model API
Code of VGG16
[https://github.com/qsdcfd/study-47/blob/main/Code%20of%20VGG16.ipynb]
Vanishing gradient
-
정의: gradient -> 출력층 -> 각 층의 가중치 수정 -> 층이 늘어남 -> 중간 층들의 기울기가 0이 된다. -> gradient가 작아짐-> 레이어 학습 불가
-
특징: 레이어가 깊어지면 gradient는 급감 or 급증 -> 1보다 작은 값은 0에 가까워지고 1보다 큰 값은 너무 커짐.
- 다양한 함수

ResNet
- Residual Block
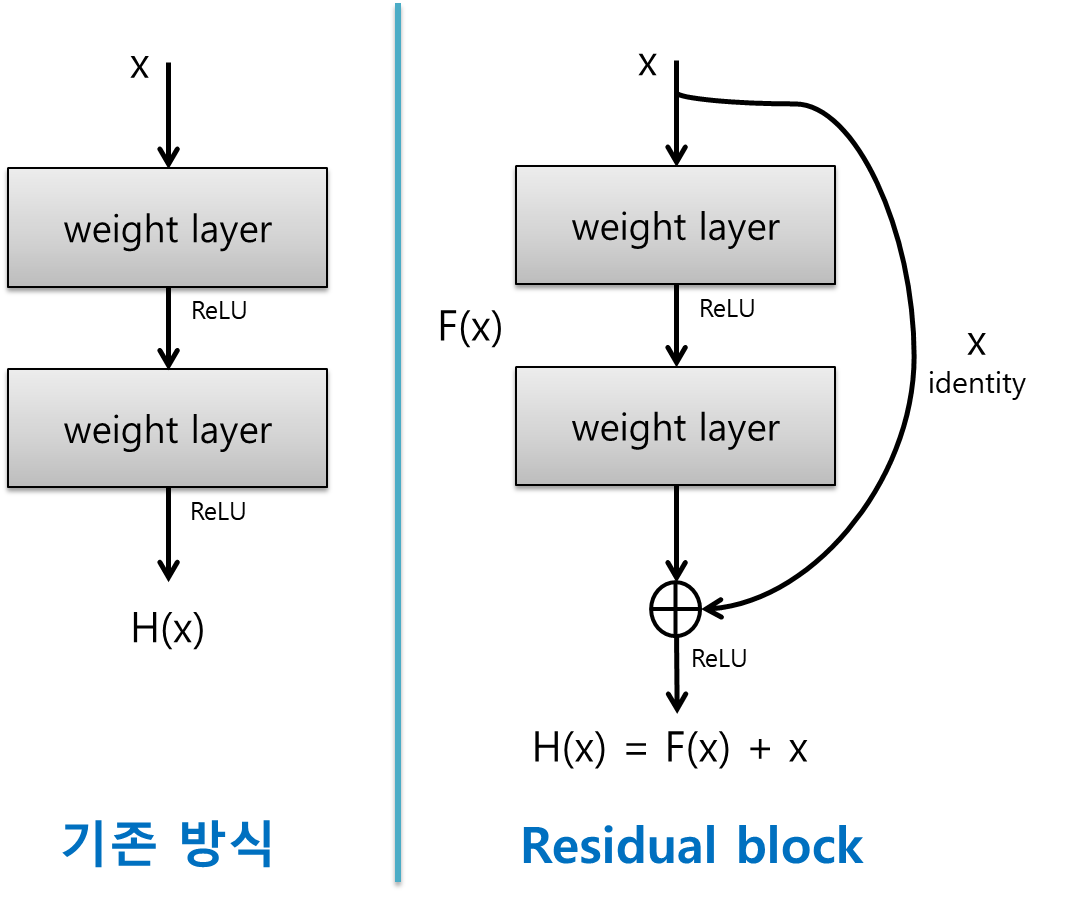
:입력값을 출력값에 더해주는 지름길을 만들어서 레이어를 깊게 쌓아도 오류가 증가하지 않음
- 목적
: F(x) +x를 최소화는 목적-> residual를 최소로 하는 것.
- 구조
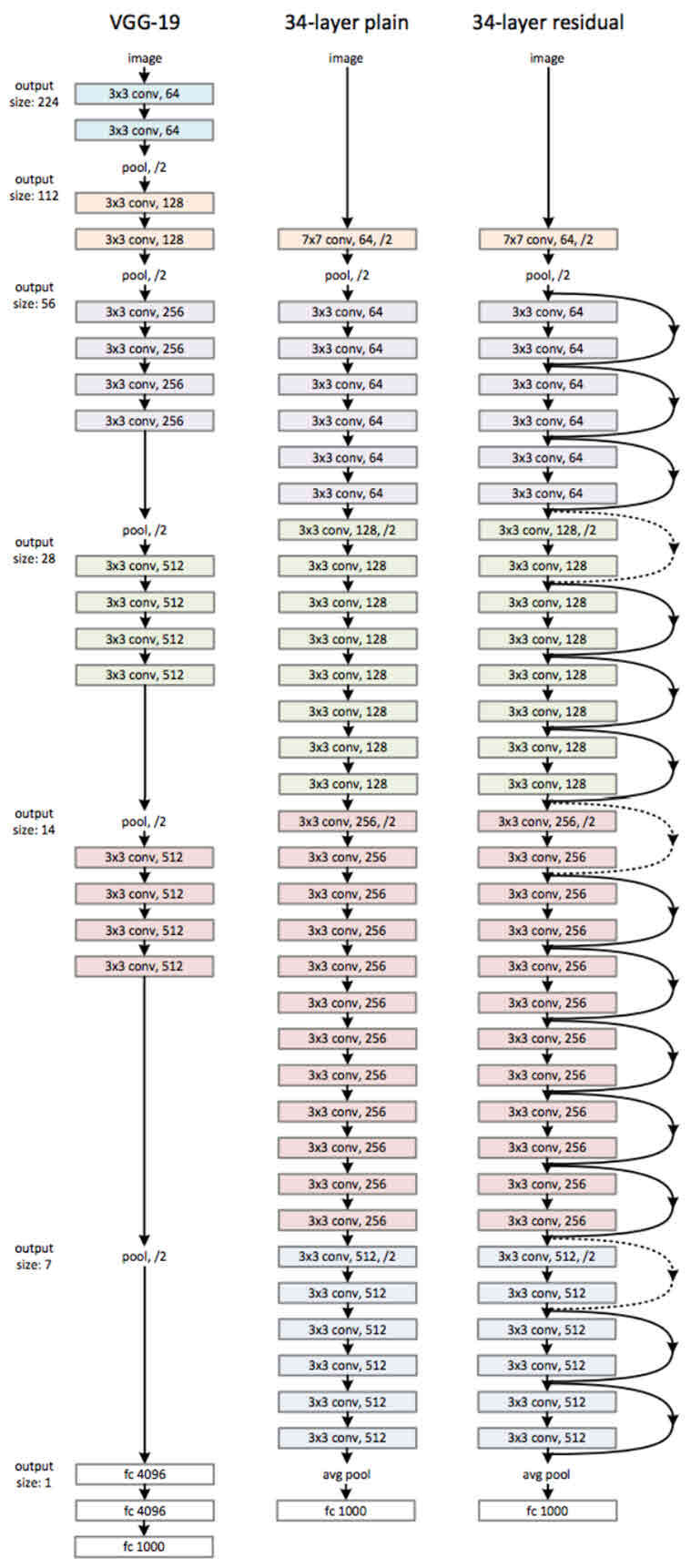
-
Base: VGG-19 구조 + 컨볼루션 층 -> 깊어짐 -> shortcut 추가.
-
Skip connection: 레이어의 입력을 이어서 gradient가 깊은 곳까지 도달하게 함.
-
블록마다 feature크기가 서로 다름 -> stage구분 가능
-
하나의 stage 안에서는 kernel 사이즈와 channel 수가 동일하므로 블록단위로 짠다
-
코드 구현
Code of ResNet-50
