논문 톺아보기
논문 사이트: https://arxiv.org/pdf/1411.4038.pdf
코드 리뷰:링크텍스트
Semantic Segmentation을 이해하기 위해 가장 근본이 되는 논문이고 도로 영역 맵만들기 실습을 할 때 유용하기에 정리합니다.
논문 속 핵심
- Key insight
FCN을 만들기 위해서 input사이즈를 임의로 설정하고 효율적인 추론 및 학습을 통해 알맞은 크기의 출력합니다.
- Characteristic
*FCN
FCN은 어떤 입력 사이즈가 들어와도 그에 맞는 크기(spatial dimensions)의 출력 이미지를 생산합니다.
- 식
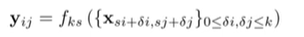
-
xij: 데이터의 위치 정보 벡터
-
yij: 레이어
-
k: 커널 사이즈
-
s: stride
-
fks: layer유형 결정
(ex: average pooling, max pooling, activation function,...etc인지를 결정합니다.)
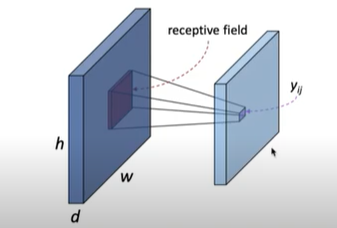
- receptive field: 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기
*FCN특징
- Dense예측을 위해 분류기에 적용
- 히트맵을 얻게 됩니다.
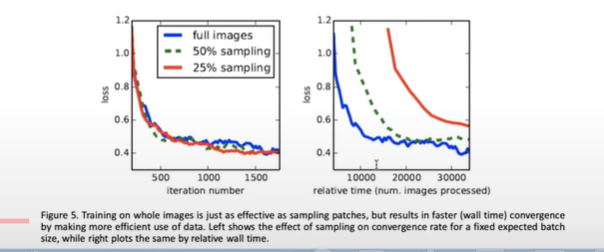
- Patch sampling
-
Patchwise 훈련은 손실 샘플입니다.
- loss가 빨리 떨어집니다.
- 전체이미지를 사용하는 것이 더 효율적이라는 결론을 어덱 됩니다.
*FCN의 영역 정의
지도학습으로 사전 학습된 분류모델과 입력 데이터의 해당 공간 차원을 유지하기 위해 FCN이 적용됩니다.
*Skip architecture 적용
추상적인 레이어의 의미적 정보아 shallow and fine의 외적적 정보를 정의한 것으로 정확한 segmentation결과를 얻기 위함입니다.
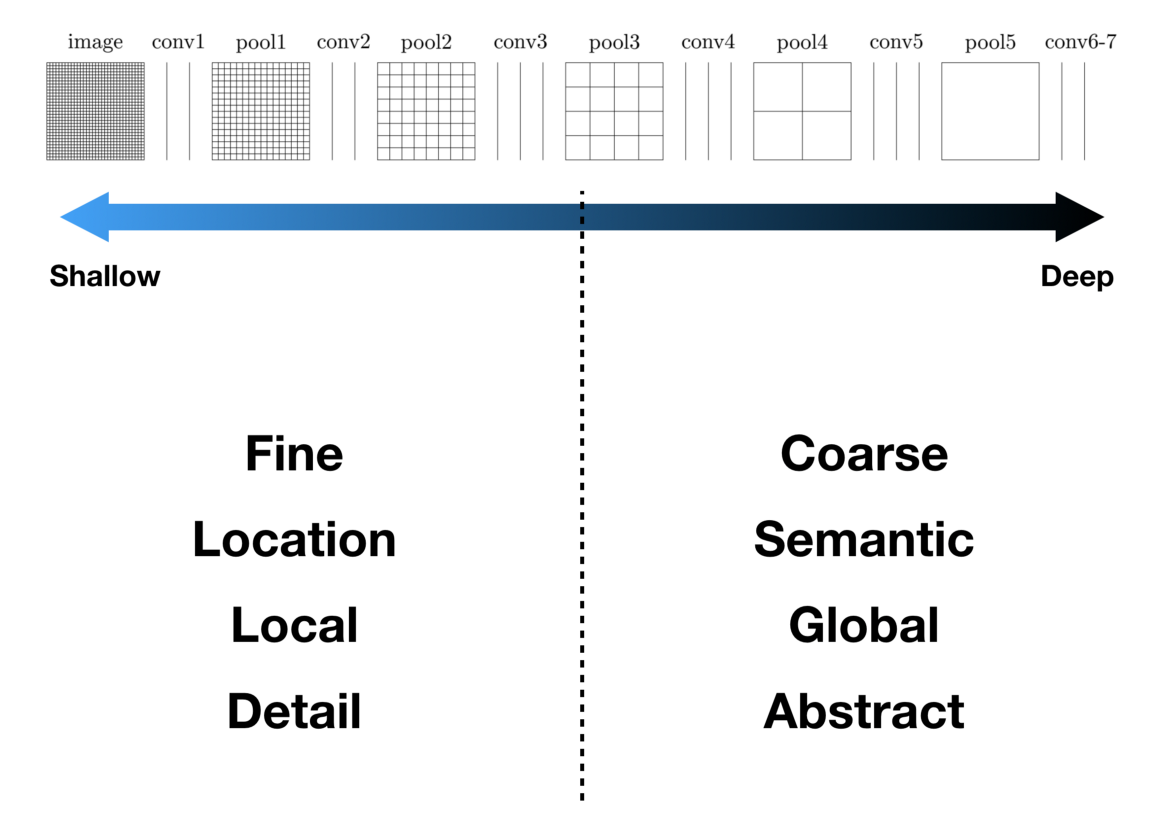
왜? 얕은 층과 깊은 층을 합하는 걸까요?
-
얕은 층: 직선,곡선,섹상등의 낮은 수준의 특징이 활성화. local feature 감지
-
깊은 층: 복잡하고 포괄적인 개체 정보 활성화, global feature감지
위의 두 층의 장점을 모두 결합하여 Segmentation의 품질 개선을 합니다.(by Visualizing and Understanding Convolutional Networks Paper)

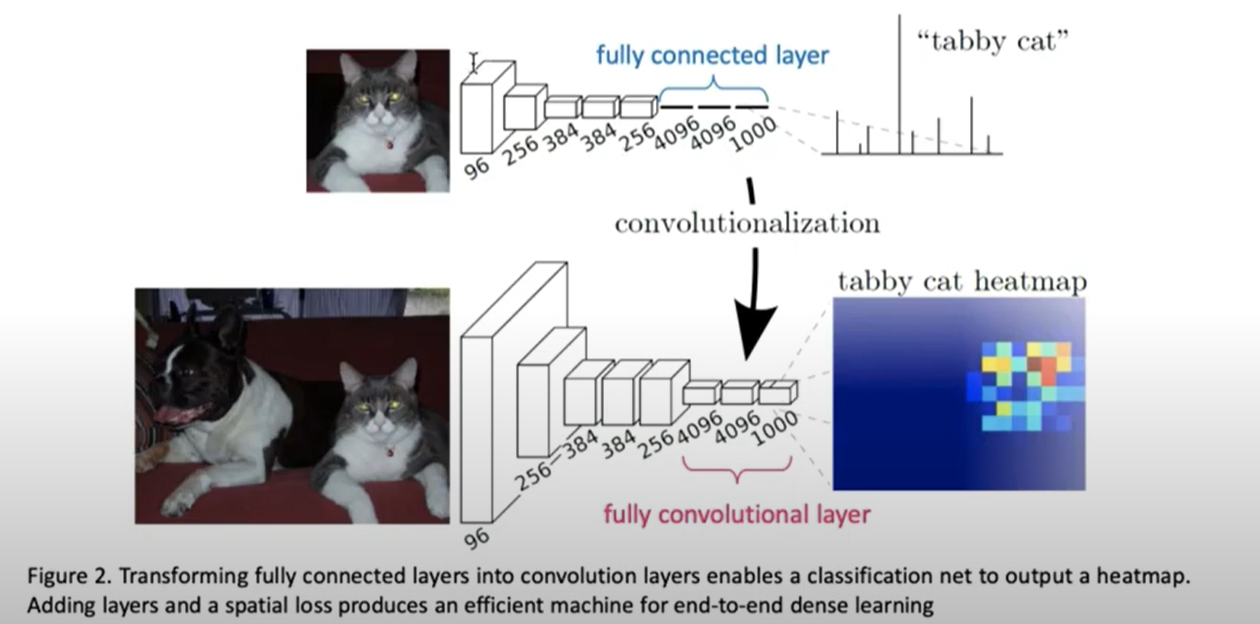
- 이미지로 보는 전반적인 FCN의 구조(AlexNet기반)

-
입력 이미지 후 앞의 5개 상자들은 특징 추출하는 구간입니다.
-
뒤의 3개 상자들은 FCN을 의미하여 특징이 추출된 것을 분류하는 구간입니다.
-
Pixelwise prediction은 skip network부분입니다.
-
마지막으로 segmentation이 됩니다.
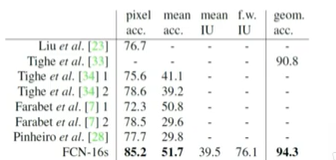
- 표를 통한 결과
- Metrics
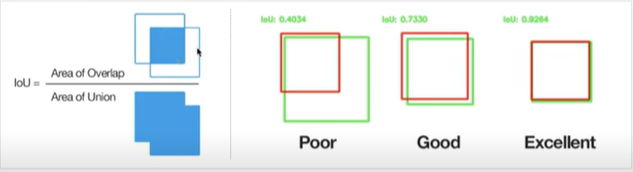
*IoU
객체 인식같은 모델을 사용했을 때 실제 물체의 위치와 예측된 물체의 위치를 평가방법으로 얼마나 일치하는지를 수학적으로 나타내는 지표입니다.
- PASCAL VOC
*아래 식이용

*결과

- NYUDv2
Depth에 대한 정보와 RGB데이터가 같이 들어 있는 결과입니다.

- SIFT Flow